Hirdetés
Új hozzászólás Aktív témák
-

bambano
titán
-

kw3v865
senior tag
Sziasztok!
PostgreSQL 11-et használok és törölni szeretnék minden cache-elt adatot. Miként lehet ezt megtenni? Függvényt írok, és most optimalizálni akarom a működését (emaitt sokszor le is futtatom azonos paraméterekkel, miután módosítottam a kódon), ezért azt szeretném, ha "tiszta lappal" indulna mindig. Van erre valami egyszerű, de biztos megoldás?
-

Micsurin
nagyúr
válasz
 martonx
#4794
üzenetére
martonx
#4794
üzenetére
Opre szerver + 2 klienses és szolgáltatásos beadandó ami páros munka lett volna egyedül toltam le mert beleszart a társam, tanárt nem láttam a félévben mindent demonstrátor tart van olyan tárgyunk (digitális rendszerek, ALU és alap tervezési feladatok) 2x tartottak konzit amúgy egy fél hiányos fél katyvasz pdf halmazból OMB módszerrel tanulj.
Nem véletlen kértem segítséget és hagytam a végére dolgot nem épp lustaságból. Szeptember 1 óta ~200 km-ert mentem motorral, mikor ügyintézni kellett beszaladnom a TO-ra vagy a városba, egy út oda és vissza ~40km.

Nem jött be...!
![;]](//cdn.rios.hu/dl/s/v1.gif) Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
-
Micsurin
nagyúr

Akkor jó az elképzelés csak figyeljek a JOIN-ra, nagyon nagyon köszönöm!
Rákérdeztem a demonstrátornál, hogy ebben a formában elfogadható-e erősen kíváncsi leszek és erősen remélem nem ezt a NATURAL JOIN-os formát várják el mert erre nem akar ráállni az agyam nem logikus nekem az ALIAS-ok is hiányoznak.
Az ALIAS-ok elhagyására érted, hogy átláthatóbbá teszik?

Majdnem olyan rossz a hiányuk számomra mint a #MyRegion elhagyása C#-ban és az ömlesztett kódot bámulni.
-

nyunyu
félisten
válasz
 Micsurin
#4789
üzenetére
Micsurin
#4789
üzenetére
Alapvetően jó a próbálkozásod, de az első JOIN feltétel után már ne használd a vesszőt a következő JOINolandó táblához/queryhez, hanem ott is írd ki megfelelő JOIN formulát.
(ne keverjük a régi és a szabványos JOIN szintaxist!!!)Picit olvashatóbbra rendezve:
SELECT er.last_name, er.salary, d.department_name, át.átg
FROM employees er
INNER JOIN departments d
ON er.department_id = d.department_id
INNER JOIN (SELECT department_id, ROUND(AVG(salary),2) AS átg
FROM employees
GROUP BY department_id) át
ON er.department_id = át.department_id
WHERE er.salary > át.átg;Példa megoldás gyakorlatilag ugyanez, csak nem használ benne aliasokat (amik a kód átláthatóságát, követhetőségét, érthetőségét növelik)
Ja, meg natural joint használ, csak azért hogy ne kelljen kiírnia az azonos oszlopok menti join feltételeket. -
Micsurin
nagyúr
Lassan biztosan kitelik a becsületem de azért egy kérdésem még lenne, kevésbé gáz a fórumon beégni mint az előadó vagy a demó előtt a hülyeségemmel.
Ha jól értettem nyunyu akkor ezek szerint nekik ekvivalens megoldásoknak kell lenniük ugye?
Listázzuk azon dolgozók vezetéknevét, fizetését és részlegük nevét, akik többet keresnek, mint amennyi a részlegük átlagfizetése.1. ahogy én értelmeztem a feladatot, 2. ahogy meglett adva rá megoldás.
SELECT er.last_name, er.salary, department_name, át.átg FROM employees er
INNER JOIN departments ON er.department_id = departments.department_id,
(SELECT department_id, ROUND(AVG(salary),2)AS átg FROM employees GROUP BY department_id) át
WHERE er.department_id = át.department_id AND er.salary > át.átg;SELECT last_name, salary, department_nameFROM employees INNER JOIN departments USING (department_id)NATURAL JOIN(SELECT department_id,ROUND(AVG(salary)) részlegátlagFROM employeesGROUP BY department_id)WHERE salary > részlegátlag;Próbáltam a linkelt oldalra bedobni de nincsenek meg az instertjeim hozzá (sima basic HR séma ami az Oracle 12c-ben van) és nem egészen értettem az oldal milyen PlaintText-et várna tőlem a 2. ablakban.

MINUS-al rámentem és a nagy semmit kapom vissza ha a +1 átlag oszlopom kiveszem szóval jónak kéne lennie I guess.

edit.: elsőben department_id és name javítva, csak az előzőt hagytam vágón...


-
Micsurin
nagyúr
Hatalmas köszönet a két válaszért! El sem tudod képzelni milyen nagyon sokat segítettél vele!
Az az SQL*PLUS mikor megláttam azt hittem kiugrok a bugyiból ijedtemben.
Rögtön felötlöttek bennem a linuxos élmények a szóközökkel kapcsolatban és a szép gondolatok, hogy itt hagyom ezt az egészet a f*ba azt mehet egy motorszerelői OKJ. Ez van ezt kell szeretni és túlélni szerencsére csak ez az 1 adatos tárgyam van/lesz.(mert nincs az az isten, hogy én BigData-ra menjek hamarabb megyek el szoftverre, pedig hálózat vagy beágyazott rendszerekre akarok célozni.
) -

Louro
őstag
Egy dolog kimaradt, bár ez inkább megint oldschool és úgy tudom Oracle-nyavalya, de nagyon sokan használják még, mert a veterán kollégák "így mutatták neki".
select tabla1.*
from tabla1,tabla2
where tabla1.id = tabla2.id (+)
and tabla2.id is null;Én is jobban szeretem a könnyebb olvashatóságot, azaz a
select tabla1.*
from tabla1
left join tabla2
on tabla1.id = tabla2.id
where tabla2.id is null;Amikor inner join, sokan elhagyják az inner szót. Vagy az outer is sokszor el van hagyva. Nem left outer join, hanem csak left join. Bevallom nem is tudom mit lehetne az outer helyett írni. left inner join?
nyunyu: sql server 2008-nál még biztos kötelező volt aliast használni subquery esetén is. Lehet az újabbaknál már nem, de annál biztos kellett.
-
nyunyu
félisten
válasz
Micsurin
#4777
üzenetére
Első példádban:
SELECT e.department_id, last_name, legkisebb
FROM employees e,
(SELECT department_id, MIN(salary) legkisebb
FROM employees
GROUP BY department_id) min
WHERE e.salary=min.legkisebb AND e.department_id=min.department_id;"e" néven hivatkozik az employees táblára, míg az alquery eredményhalmaza a "min" aliast kapta.
WHERE után láthatod, hogy táblanév.oszlop vagy alias.oszlop formátummal lehet hivatkozni az egyes táblák vagy alqueryk elemeire.
Vagy a SELECT mezőlistájánál is azért van kitéve az e. az első mező elé, mert mind a táblában, mind az alqueryben van department_id, és az Oracle megköveteli, hogy egyértelműen megmondd, hogy melyik oszlopra hivatkozol.
(Másik két oszlopa önmagában is egyértelmű, mivel a "last_name" csak a táblában, "legkisebb" meg csak az alqueryben van meg.) -
nyunyu
félisten
válasz
Micsurin
#4783
üzenetére
Alquerykről annyit érdemes tudni, hogy az SQL nyelv szintaxisa úgy van felépítve. hogy minden helyre, ahol táblanevet vár, oda lehet zárójelek közé írni egy alqueryt, és akkor annak a querynek az eredményhalmazát fogja a táblaként használni a másik művelethez.
Így tudod pl. tovább szűrni az eredményeket, vagy pl. azzal joinolni.Az mondjuk DB implementáció függő, hogy az alqueryt bezáró zárójel mögé kell-e aliast írni, vagy sem (Oraclenél kötelező, MSnél nem)
Azzal az aliasszal tudsz majd a fő queryben az alquery mezőire/oszlopaira hivatkozni, mintha egy tábla oszlopaira hivatkoznál.Tranzakciók: azt meg kell érteni, mivel egy sokfelhasználós konkurens rendszerben nem lehet élni nélküle.
Adatoknak akkor is konzisztensnek kell maradniuk, ha sokan piszkálják őket egyszerre, vagy bármi hiba beüt.
Olyan nem lehet pl. egy félbeszakadt átutalásnál, hogy a pénzt levonták a számládról, de a fogadó oldalon meg nem jelenik meg, olyankor a bank nem tárhatja szét a karját, hogy bocs rendszerhiba volt, így jártál...Terminálos dolog?
SQLPlus? Tudom, hogy a nagyvállalati rendszeradminok kedvenc perverziója, hogy SQLPlusszal futtatható releaset kérnek, majd hozzádvágják a hibalogot, hogy fejtsd meg miért nem futott le (mit írtál el benne, vagy melyik 2 query közé nem tettél /-t, vagy milyen alternatív nyelv volt beállítva a termináljának...)
de fejlesztőként minimum egy (ingyenes) Oracle SQL Developer IDEt azért elvárhatna az ember a fejlesztéshez, ugyan nem a legjobb, de mégsem az SQLPlusszal kell szerencsétlenkedni. -
Micsurin
nagyúr
Köszönöm! Az a baj most nem gyakorlati dologról beszélünk hanem egy zh-ról. Ott meg ha a subquerry erőltetése a feladat x-y formátumban akkor arra fog járni a pont bármennyire is életszerűtlen a feladat szaga. Emiatt nem tudom pontosabban megfogalmazni a most bugyutának tűnő kérdésem! De így, hogy csak a forma tér el valamivel tisztább köszönöm!
nyunyu Életemben először látom de magát az oracle sql-t is eddig csak mysql-lel kellett dolgozzunk, felcsesz ez a szintaktika. LIMIT helyett is mire megtaláltam ezt a ROWNUM cuccot és rájöttem, hogy subquerry megy ebbe is vagy van FETCH azt hittem megőszülök.
Majdnem jó tipped volt ez most nem BME hanem OE.Neked is köszönöm!
Ergo maradhatok a JOIN-oknál és csak arra kell figyeljek milyen formában ad vissza a subq adatot és azt miképp illesztem JOIN-al. Miért nem lehetett ezt így leírni a jegyzet vagy a ppt-ben?
Igen már az EXISTS sem "tiltott" dolog, sőt..., kicsit fura az egész... de még ez az értelmes része a tranzakciók meg ez a terminálos dolog végképp elveszi a türelmem sose akartam bigdatara menni de miután tudom, hogy oracle-öznek még annyira se mint eddig.
Köszönöm a válaszokat!
martonx Legközelebb oda fogom feldobni akkor, nem tudom jobban leírni mert egy minden gyakorlatiasságot nélkülöző PPT példa alapján kell rájönnöm, hogy mit is akarok kérdezni.
-
nyunyu
félisten
Meg az exists egy olyan okossag, ami egesz jo hatekonysagot mutat, annak a probalgatasat is ajanlom.
Nem volt mindig így.
Tizenéve még kifejezetten kerülendő antipatternként tanították az EXISTS/NOT EXISTS párost, mivel régi DBken nagyon rosszul futottak.
Modern DBk optimalizálói viszont végrehajtás előtt át szokták alakítani LEFT JOINra, és úgy futtatják.
Szóval a
select *
from tabla1
where not exists (select id from tabla2);helyett már
select tabla1.*
from tabla1
left join tabla2
on tabla1.id = tabla2.id
where tabla2.id is null;végrehajtási tervét fogod látni, és futtatási sebességben sem lesz köztük különbség.
Régebbi/kevésbé fejlett optimalizálóval rendelkező DB motorokon viszont a második kód sokkal gyorsabban fut, mint az első.
-
nyunyu
félisten
válasz
Micsurin
#4777
üzenetére
Mi a rák az a natural join?
Utána kellett néznem, mert ilyet még nem láttam.
Azt írják, hogy az SQL:2011 óta opcionális nyelvi elem, nem kötelező implementálni. (Akkor azért nem láttam eddig.)Mindenesetre arra jó, hogy a lustáknak ne kelljen kiírni a JOIN feltételeket, hanem a DB motorra bízzák az azonos nevű oszlopok összehasonlítását.
(magyarul az ON tábla1.id=tábla2.id elhagyható, vagy ha az oldschool from tábla1, tábla2 szintaxist használod, akkor WHERE mögül a tábla1.id=tábla2.id)Egyáltalán miért nem szabvány SQLt tanítanak?
Mikor BMEn különböző DB jellegű tárgyakat hallgattam, ott nagyrészt szabvány SQL volt, de megmutatták azon felül a legelterjettebb DBk szintaktikai különbségeit. (T-SQL (MS) vs PL-SQL (Oracle))Másik kérdésre meg az a válasz, hogy nincs különbség a 2 query között.
Első az oldschool formátumban van írva, amikor még nem volt szabványosítva a JOIN szintaxis, hanem minden DB kezelő a saját feje szerint toldozta-foltozta az akkor érvényes szabványt, így alakult ki a FROM után vesszővel felsoroljuk a táblákat, majd WHERE mögé kerülnek a JOIN feltételek szintaxis, amit elég sokan implementáltak anno ahhoz, hogy még ma is elterjedt legyen, emiatt az újabb DB kezelőkbe is bele szokták tenni. (Pl. SQL Server 2008-ba betették, mivel MS lőni akart a Teradata júzereire is)
Második meg az SQL92-ben definiált szabványos írásmód, amit minden DB kezelőnek ismernie kell.
Működésben nincs különbség a kettő között, mivel a DB SQL optimalizálója átrendezi a futtatandó kódot, ide-oda pakolászva a feltételeket, végül mindkettő szintaxisnak ugyanaz lesz a végrehajtási terve.
-

Szmeby
tag
válasz
Micsurin
#4778
üzenetére
Nem hiszem, hogy a feladat szovegeben talalni fogsz egy kulcsszot, ami elarulja, mit hova tegyel egy lekerdezesben.
En sem ertem pontosan a problemat, de ha az a gondod, hogy nem latod a kulonbseget a
SELECT e.department_id, last_name, legkisebb
FROM employees e, (SELECT department_id, MIN(salary) legkisebb
FROM employees GROUP BY department_id) min
WHERE e.salary=min.legkisebb AND e.department_id=min.department_id;es a
SELECT e.department_id, last_name, legkisebb
FROM employees e
INNER JOIN (SELECT department_id, MIN(salary) legkisebb
FROM employees GROUP BY department_id) min ON e.department_id=min.department_id
WHERE e.salary=min.legkisebb;kozott, akkor az azert van, mert nincs kulonbseg.
En az utobbi formatumot szoktam meg es szeretem hasznalni. Az utobbi egy ujabb talalmany, a hosidokben az elobbit hasznaltak. De ez a ketfele formatum a subquerytol pont fuggetlen, sima tablakkal ugyanugy alkalmazhato mindket forma.---
Hogy subqueryt tablakent hasznalsz egy lekerdezesben es joinolgatsz, vagy a where feltetelben szursz a subquery eredmenyevel egy masik tabla egy mezojen*, szerintem ez ket annyira eltero dolog, hogy adja magat. Join-ba azert teszed, mert mondjuk a subquery-bol is szeretnel ertekeket megmutatni az eredmenyhalmazban. Vagy mert tobb mezore is szurnel, es join-nal atlathatobb a lekerdezes, vagy mert a DB jobban optimalizalja igy a lekerdezest, mint ugy. Probalgasd, gyakorolj, idovel raerzel!
* Mondjuk valami ilyesmi:
SELECT e.department_id, last_name
FROM employees e
WHERE e.salary=(SELECT MIN(salary) FROM employees min WHERE e.department_id=min.department_id);---
Vagy ha a subqueryt a szelekcioba rakod, hat, meg nem mondom, mikor van ennek haszna. Annyira nem vagyok expert, hogy ezt most igy hirtelen meg tudjam fogalmazni, es sose filozofalgattam azon, hogy milyen kulcsszavak milyen strukturaltsagot implikalnanak. Szelekcioba nagyon ritkan tettem subselectet, mert borzaszto rossz hatasfoku volt.
Szerintem egy jo okolszabaly, hogy ird meg join-nal a lekerdezest, es ha azt latod, hogy a join felesleges, mert mondjuk a kapcsolt tablabol semmit nem mutatsz meg az eredmenyhalmazban, akkor kis atalakitassal talalj neki egy szebb / jobb formatumot. Erdemes kiprobalni, hogy mennyire hatekonyan hajtja vegre a DB az egyik es a masik valtozatot. Sok gyakorlas utan pedig mar raerzel majd, hogy melyik megoldas optimalis, es eleve ugy kezdesz hozza. Meg az exists egy olyan okossag, ami egesz jo hatekonysagot mutat, annak a probalgatasat is ajanlom.
Ha elkepzeled, hogy melyik tabla vagy subquery hany sorral ter vissza, es az alapjan probalod beloni, hogy a DB vajon egyik-masik konstrukcioban mennyire izzadna meg, akkor az talan segit eldonteni, hogy merre erdemes elindulni.
Na de en is kivancsi vagyok egy hozzaerto gondolataira, hatha van egyszerubb mod.
-
Micsurin
nagyúr
válasz
Micsurin
#4777
üzenetére
Annyival tudom finomítani, hogy ha jól értem a dolgot azzal van gondom nem ismerem fel mikor kéne az allekérdezést:
-Mező
-Tábla
-Feltétel
Helyett használnom. Ill a mező helyetti az egyértelmű én a tábla és a feltételt nem ismerem fel, hogy feladat szövegben mire kéne figyeljek, hogy feltűnjön.Az kezd egyértelmű lenni, hogy az 1. példa lesz a feltétel és értelemszerűen 2. példa a tábla helyetti.
Tudom nagyon lámán értelmezem!
De itt nem a megszokott demo srácok tartották a labort és a tanárt aki beugrott nem igazán értettem. 
-
Micsurin
nagyúr
Mitől függ, hogy miképp hivatkozok egy subquerryre?
Kicsit kavarodás van fejben mert két esetet nem igazán ismerek fel a típus feladatokban:
Mikor mint tábla kezeljük a subquerryt és INNER vagy NATURAl JOIN-al fűzzük hozzá a lekérdezéshez és mikor elnevezzük a keresett értékeket pl dolgozok és a subquerry megy a FROM mögé mint dolgozok d, (subquerry) kereset majd WHERE segítségével helyezzük kontextusba az értékeket.
(próbáltam formázni de a PPT-ben is istentelenül tördelve és szóközölve volt... )Egyik: részlegenként listázva a minimális béreket
SELECT e.department_id, last_name, legkisebbFROM employees e, (SELECT department_id, MIN(salary) legkisebbFROM employees GROUP BY department_id) minWHERE e.salary=min.legkisebb AND e.department_id=min.department_id;A másik meg:
Listázzuk azon dolgozók vezetéknevét, fizetését és részlegük nevét, akik többet keresnek, mint amennyi a részlegük átlagfizetése.
SELECT last_name, salary, department_nameFROM employees INNER JOIN departments USING (department_id) NATURAL JOIN(SELECT department_id, ROUND(AVG(salary)) részlegátlag FROM employeesGROUP BY department_id) WHERE salary > részlegátlag;edit.: Ennél azt használom ki, hogy minden adatom megvan az eredeti táblában és a keresés által visszakapott "adat halmazban" is ezáltal mint táblát tudom kapcsolni és soronként kezeli az adatokat? Ilyen elven az első is mehetne így nem?
Nem tudom mennyire érthető a gondom.
De előre is nagyon köszi, hatalmas segítség lenne ha letisztulna melyik kapcsolatot honnan ismerem fel szöveg alapján! -
#4776
 Pulsar
veterán
Apollo17hu
#4775
Pulsar
veterán
Apollo17hu
#4775
válasz
 Apollo17hu
#4775
üzenetére
Apollo17hu
#4775
üzenetére
Köszönöm
Jelenleg 4 select van így egybe, hogy az első a másaodik from-jában van, majd ez az egész a harmadikban, és végül ez az egész egy negyedikben. És itt a harmadik réteg selectembe van egy feltétel aminek csak egy kimenete lehet. Es itt jött képbe, hogy innen kellene még egy adat....
Ahha, asszem értem, hogy fog össze állni, köszi
-
#4775
 Apollo17hu
őstag
Pulsar
#4774
Apollo17hu
őstag
Pulsar
#4774
Apollo17hu
őstag
Transzponálhatod pl. PIVOT függvénnyel, vagy lekorlátozhatod az eredeti selectet úgy, hogy csak az egyik eredménysort adja vissza, aztán egy másik selectben pedig csak a másik eredménysort. Ha utóbbit választod, akkor mehet rá a Descartes-szorzat:
SELECT egyik.mezo AS mezo_1, masik.mezo AS mezo_2FROM (egyik_select) AS egyik, (masik_select) AS masik -
Micsurin
nagyúr
Wow jogos, köszönöm ezt felvésem jól jön ez még a beágyazottaknál.
Nem opcionális a használata meglett mondva 3db GROUP + HAVING lekérdezés akkor azt így kell... valamit beleszuszakolok még ebbe és jó lesz nem értelmes kell legyen mint megoldása egy problémának csak szintaktikailag jónak.
-
nyunyu
félisten
-
-
nyunyu
félisten
válasz
Micsurin
#4766
üzenetére
Most mit szeretnél?
Átlagár legyen 5 misi alatt?
Ehhez kell az oszlopfüggvények kiértékelése utáni eredményhalmazt szűrő HAVING, de ahhoz pontosan ugyanazt a képletet kell írni, mint ami a mezőlistánál van:SELECT allapot AS "Állapot", ROUND(AVG(ar),2) AS "Átlag ár"
FROM motorok
GROUP BY allapot
HAVING ROUND(AVG(ar),2) < 5000000;5 misi alattiakat átlagolni?
-> először 5M-re kéne szűrni WHERErel, és azt átlagolni:SELECT allapot AS "Állapot", ROUND(AVG(ar),2) AS "Átlag ár"
FROM motorok
WHERE ar < 5000000
GROUP BY allapot;WHERE mindig a rekordokat szűri, és a szűrt rekordokon futnak le a csoportosítások/számítások.
HAVING a már kész, kikalkulált eredményhalmazt szűri. -
Micsurin
nagyúr
válasz
martonx
#4767
üzenetére
De várj már a having az azért lenne, hogy az Új és a Használt gépek esetében is csak azokat vegye figyelembe a csoportosítás után az átlaghoz amik ára 5m alatti.
Ha ott átlagolok az kicsit felrúgna mindent.
Vagy én értem nagyon félre? Adatb-hez mindig is szobanövény voltam mert nem is érdekelt különösebben.Igen így kevésbé hányok a féléves beadandómtól.
-
Micsurin
nagyúr
Hello! Nagyon ovi és dedo kérdés de egyszerűen nem akaródzik működni (Centos OS + Oracle 12c virtuális gépen, gyakran produkál érdekeseket), de
SELECT allapot AS "Állapot", ROUND(AVG(ar),2) AS "Átlag ár"FROM motorok GROUP BY allapot HAVING ar < 5000000;Nem az az ökölszabály, hogy a csoportostás alanyát kell SELECT után és azon kívül COUNT, Min, Max etc mehet? Akkor mégis miért kapok:
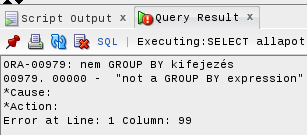
Köszi előre is!
-

pvt.peter
őstag
Köszi a válaszokat, neked is #4764 Ispy.
A legegyszerűbb megoldás tényleg az lenne, hogy ha külön-külön oszlop lenne létrehozva a C táblában az A és B tábla oszlopaira.
De a trigger is járható út, bár nemtom, hogy performanciában ez okoz-e vmilyen hátrányt.
Mindenesetre köszönöm még egyszer a válaszokat. -

tm5
tag
válasz
 pvt.peter
#4762
üzenetére
pvt.peter
#4762
üzenetére
Itt tárgyalnak 1-2 opciót, mindegyiknek az a lényege, hogy 2 külön oszlop legyen a 2 referencia. Az egyik azt mondja, hogy tedd őket egy külön táblába, a másik rögtön a céltáblába (nálad ez a C tábla) és egy CONSTRAINT CHECK-kel lehet ellenőrizni.
Nekem alternatívaként még 2 dolog jutott eszembe:
- ellenőrzés Insert triggerben, itt van is egy példa rá
- írsz egy tárolt eljárást az INSERT-re és ott már azt ellenőrzöl ami jól esik. -
pvt.peter
őstag
Sziasztok,
Jól gondolom, hogy nincs az alábbiakra lehetőségem MS SQL -ben?
Van egy A, B, C nevű tábla 1-1 int típusú oszloppal.
Amit szeretnék, hogy C tábla int típusú oszlopában csak olyan értéket lehessen felvenni ami szerepel az A vagy a B oszlop int típusú oszlopában.
A foreign key megoldás erre, de ha jól gondolom ez egy ÉS típusú kapcsolat.
Tehát ha kettő foreign keyt adok a C táblához ami az A és B tábla megfelelő oszlopára utal, akkor csak olyan értéket tudok ezek után felvenni a C tábla megfelelő oszlopában ami mind a kettő korábban említett táblában szerepel.
Van lehetőségem arra, hogy ezt az ÉS kapcsolatot VAGY -ra cseréljem?
Tehát csak olyan érték kerülhessen a C tábla adott oszlopába ami szerepel az A vagy a B oszlop megfelelő oszlopában?Köszi a választ.
-
nyunyu
félisten
Talán még ez a legegyszerűbb, de előző főnököm hivatalból rühellte a distinctet, úgyhogy olyat nagyon ritkán használunk.
Szerinte az adathibát javítani kell, nem eltakarni!
(Mostani melóhelyem viszont DWHt örökölt, úgyhogy javíthatatlan adathiba adathiba hátán a default felállás.)
-
-
tm5
tag
válasz
 Heavyrain
#4749
üzenetére
Heavyrain
#4749
üzenetére
Hát egy normális SQL-ben kb. így nézne ki:
SELECT t.a, t.bFROM tabla t, (SELECT a, COUNT(*) FROM(SELECT DISTINCT a,b FROM tabla)GROUP BY aHAVING COUNT(*)>1) xWHERE t.a = x.a
Ha ez már túl sok az Accessnek, akkor csinálj az eredeti táblából a DISTINCT-es verziót (tabla2), majd erre egy SELECT a, COUNT(*) FROM table2 GROUP BY a HAVING COUNT(*) >1. Ez lesz a tabla3 és ezt joinold össze az eredeti tabla-val -

Heavyrain
őstag
Sziasztok, a segítségeteket szeretném kérni.
Nyilván összetetteb, de példa kedvéért egyszerüsített formában az adatbázis:
2 oszlop van:
[A] oszlopban 3 számjegyű azonosítók vannak.
[B] oszlopban szövegek.A probléma az, hogy [A] oszlop értékei többször is szerepelnek az adatbázisban és a duplikációk között eltérnek a [B] oszlopbeli szövegek.
Jelenleg ki tudom listázni az összes duplikációt de nem szeretném az összeset látni csak azokat amiknél eltér a B oszlopbeli szöveg. (Nem jelent gondot, hogy az [A]-ban duplikáció van)
Példa:
[A] ; [B]
123; asd
456; xyz
456; xyz
789; qwe
813; bnm
813; ijk
555; zzz
555; zzz
622; poiAmit most kapok a duplikációk megkeresésével:
[A] ; [B]
456; xyz
456; xyz
813; bnm
813; ijk
555; zzz
555; zzzAmit kapni szeretnék:
[A] ; [B]
813; bnm
813; ijkAccessben dolgozom és sok mindent még csak most tanulok de nagyon megköszönném a segítségeteket.
-
#4747
nyunyu
félisten
olywer.smith
#4746
nyunyu
félisten
válasz
 olywer.smith
#4746
üzenetére
olywer.smith
#4746
üzenetére
with max_rogzites as (
select id, max(rogzites_ideje) utolso_rogzites
from tabla
group by id)
select t.*
from tabla t
join max_rogzites m
on m.id = t.id
and m.utolso_rogzites = t.rogzites_ideje;Persze amilyen hülye vagyok, lehet, hogy írnék előtte egy create index tabla_ix1 on tabla (id, rogzites_ideje);-t is, hogy a BI se dögöljön bele, ha egy 100 millió soros táblából kell riportálnia az utolsó rögzített értékeket...
-
#4746
 olywer.smith
csendes tag
olywer.smith
csendes tag
olywer.smith
csendes tag
Hello Mindenkinek!
Segítséget szeretnék kérni egy látszólag egyszerű lekérdezéshez.
Egy tábla első oszlopa egy azonosító, további oszlopok egyike a rögzítés ideje (datetime).
Le kellene gyűjteni azonosítónként az utoljára rögzített sorokat (minden oszlopával).Előre is kösz a segítséget!
Üdv: olywer
-
-
Szmeby
tag
válasz
 bambano
#4743
üzenetére
bambano
#4743
üzenetére
Szerintem ez csak egy házifeladat.
Már eleve életszerűtlen, hogy egy rakás fontos dolgot nem vesz figyelembe. Illene ellenőrizni, hogy a teljes rendszer egyenlege egyáltalán pozitív-e. Ha nem, akkor el kell dönteni, hogy inkább a kis hiánnyal rendelkező üzletek készletét optimalizáljuk és hagyjuk a nagy hiánnyal küzdő üzletet megdögleni. Vagy a nagy hiányra összpontosítunk és a kis hiánnyal rendelkező üzletek majd megoldáják valahogy. Teljesen más megközelítést igényel a két üzleti igény.
Ha feltételezzük, hogy a teljes egyenleg pozitív, akkor is kell egy korlát, ami alatt egyszerűen nem éri meg megmozdulni. Továbbá sokkal jobb minden üzlet készletét egy átlagos érték felé közelíteni. Vagyis ne a 0 hiány, 0 többlet legyen a cél, hiszen, ahogy te is mondtad, a raktárkészlet állandóan forog: ha csak a nullát tűzzük ki célul, akkor az első vásárláskor újra negatívba fordul, ami optimalizálási igényt kényszerít ki... abszolúte nem hatékony.
De még az átlagos szint sem feltétlenül optimális, hiszen egyes üzletek forgalma historikusan nagyobb, másoké kisebb, így érdemes ez alapján egy átlagtól való korrekciót alkalmazni. Ami aztán további problémákat szül, mivel egy tűpontosságúra optimalizált rendszerben - amennyiben az ember elfelejt gondoskodni az utánpótlásról - nagyon könnyen a teljes rendszer szintjén fellépő hiány alakulhat ki nagyjából ugyanabban a pillanatban.
A feladat nem veszi figyelembe az üzletek egymástól való fizikai távolságát, a megközelíthetőséget. Nagyon szépen hangzik, hogy egy db procedure megmondja, hogy a kettes id-jú üzletből vigyünk át 50 bizbazt a 14-es id-jú üzletbe, de ha ezek a város két végén helyezkednek el, akkor az ész nélküli ide-oda szállítgatás felzabálja a profitot. Arról nem is beszélve, hogy az ezt intéző munkavállalók azt fogják kérdezgetni, hogy ki volt az az idióta, aki ezt így kitalálta... és teljesen jogosan fogják megkérdőjelezni az értelmét.
A való életben ennél sokkal komplexebb feladat egy elosztott raktárkészlet optimális fenntartása, marhára nem egy temptáblával megoldható probléma. Mármint megoldható, csak az olyan is lesz. Ízlés dolga, kinek mit vesz be a gyomra ugye.
-
bambano
titán
úgy kezdted a megoldásodat, hogy csináljon másolatot a tábláról.
ez már önmagában zűrök okozására ad lehetőséget.
ha például jávába beolvasod az adatokat, feltéve, hogy beférnek, akkor is ott lesz a probléma, hogy a riport futtatása közben vásárolnak, és akkor szétszalad a valós raktárkészlet adata meg a temp tábla adata."minden egyes lépés kiértékelésénél a DBnek egyesével újra kell számolnia az eddigi lépések eredményét": ez tény, de feladattól, környezettől függ, hogy ez hátrány vagy előny.
nekem az a véleményem, hogy hagyni kell az adatbáziskezelőt dolgozni.
az, hogy a bi ócska, az másvalaki problémája vegyenek bele több ramot. -

martonx
veterán
Bocs, pontatlan voltam. Az SQL-t nem számítom a programnyelvek közé. De igazad van végülis ez is programnyelv, csak épp nem imperatív. Ugyanígy nem tekintem programnyelvnek a CSS-t sem
Legalábbis a magam pongyola megfogalmazásában.A Java lambdát ne keverd ide, az csak egy syntetic sugar, nem attól lesz deklaratív nyelv a Java. De kezdünk nagyon eltérni az eredeti problémától
-
nyunyu
félisten
válasz
bambano
#4737
üzenetére
Van amikor a számítási/lekérdezési sebesség fontosabb, mint a redundancia.
Ha csinálsz egy aktuális raktár nézetet, amiben összejoinolod az eredeti raktár táblát a mozgatások szummájával, és ebből dolgozik a következő lépést meghatározó lépés, akkor minden egyes lépés kiértékelésénél a DBnek egyesével újra kell számolnia az eddigi lépések eredményét, ahelyett, hogy a letárolt köztes értéket használná.
Ez ugyan elegáns, de nem hatékony.(Épp most kínlódunk azzal, hogy mindenféle BI riportokat kell készíteni, de többszázezer soros táblákat kell joinolni, szummázni, és az eredmény kb. 40k sor/nap.
BI meg állandóan beledöglik, amikor így-úgy szűrve belekérdez a DBben tárolt nézetbe.
Úgyhogy írhatok egy jobot, ami naponta lefuttatja a kb. egy percig futó queryt, és insert into-zza egy táblába, aztán onnan fog select *-ozni a BI, nem az eddigi nézetből.) -
nyunyu
félisten
válasz
martonx
#4736
üzenetére
Bármely programnyelvbe beletartoznak a deklaratív nyelvek is, ahova az SQL is tartozik.
Deklaratív programozási paradigmánál az elemi adatokat/tényeket és a köztük lévő kapcsolatokat definiálod, majd ezek elemeire kérdezel rá ("szűrsz"), gép meg majd valahogyan megoldja.
Programozási nyelvek másik, nagyobb csoportja az imperatív nyelvek csoportja, ahol az egymás után következő elemi utasításokat/lépéseket rágod a gép szájába.Programozó részéről ezek két különböző megközelítést, gondolkozásmódot igényelnek.
(Ezért nem értem, mi a francnak erőltetik pl. a lambda-függvényeket a modern imperatív programnyelvekben. Hacsak nem az a cél, hogy elméleti matematikusok svájci bicskaként tudják használni a Java 8-at?) -
bambano
titán
válasz
 mr.nagy
#4729
üzenetére
mr.nagy
#4729
üzenetére
én ezt úgy csinálnám, (mssql-hez nem értek), hogy csinálnék egy eredménytáblát, amibe beleírom, hogy honnan hova, ahogy te is felírtad.
majd csinálnék egy nézettáblát, ahol összeadnám a nyitó készletet és a mozgásokat, és az lenne az eredmény.
az eredménytábla feltöltését pedig a nézettábla alapján csinálnám meg.
majd csinálnék egy ciklust, ahol kiválasztanék egy honnan meg egy hová üzletet (például az alapján, hogy mekkora a hiány vagy mennyire nagy a készlet) és az alapján pakolnék a mozgás táblába.a javaslatom az, hogy minden olyan megoldástól visítva menekülj, ami redundanciát okoz.
-
martonx
veterán
"Ettől még fenntartom azt, hogy Javaban egyszerűbb lenne lekódolni+gyorsabban is futna."
Mármint bármilyen programnyelven (javascript, php, c#, python, java, stb...) és nem csak egyszerűbb lenne lekódolni, és nem csak gyorsabban is futna, de könnyedén debuggolható, logolható, verzió kezelhető is lenne.
Noha mindezt SQL-el is meg lehet oldani, de elképesztően nyögve nyelősen. -
nyunyu
félisten
válasz
mr.nagy
#4732
üzenetére
Meg lehet csinálni SQLben is, csak kell hozzá egy tárolt eljárás, amiben :
- csinálsz egy kurzort a negatív raktárkészletekből csökkenő sorrendben (hova = id, mennyi = -val)
- CTASsal lemásolod az eredeti raktár táblát egy újba (hogy ne az eredetit updatelgesd)
- végigiterálsz a kurzoron
-- kiveszed az aktuális maximum értéket, és az id-ját a raktár_másolatból, és ha az nagyobb, mint a az aktuálisan kezelendő hiány, akkor
--- update raktár_másolat set val=val-mennyi where id=honnan;
--- update raktár_másolat set val=val+mennyi where id=hova;
--- insert into mozgások values (honnan, hova, mennyi);Végén megvan a raktár_másolatban a művelet utáni új raktárkészlet, mozgásokban meg a teendők listája.
Ettől még fenntartom azt, hogy Javaban egyszerűbb lenne lekódolni+gyorsabban is futna.
De pár bolt esetén nem biztos, hogy olyan nagy lenne SQLben sem a futási idő. -

mr.nagy
tag
Köszönöm a választ, de a példánál maradva nincs központi raktár és sajnos a kereskedők az üzletben olyanok amilyen. Nem lehet rájuk bízni ezt a kérdést.
Esetleg két ideiglenes tábla, az egyikbe írom a kiegyenlítést a másikba csökkentem ennyivel az értéket, majd a második alapján új ciklus. Ez a ciklus addig fut, míg van hova tenni?
-
tm5
tag
Én is valami hasonlóra jutottam, mint nyunyu, hogy ehhez minimum egy tárolt eljárás szükséges, ezt 1 sql paranccsal nagyon nem lenne egyszerű megoldani.
Valami olyasmit csinálnék, hogy generálnék 2 listát (plusz(i): pozitívok csökkenő sorrendben, minusz(j): negatívok növekvő sorrendben) és mennék végig a minusz listán úgy, hogy a plusz-os lista aktuális elemével megpróbálnám kiegyenlíteni a negatív értéket. ha nem tudom, akkor nézem a következőt a minuszból. Addig megy a ciklus, amíg a végére nem érsz valamelyik listának. + eköré még kellene még egy loop ami az elején újraszámolja a plusz, minusz listákat és addig megy amíg vannak update-ek. Valami ilyesmi lenne... -
nyunyu
félisten
válasz
mr.nagy
#4729
üzenetére
Ez tipikusan egy olyan probléma, amit nem biztos, hogy SQLben érdemes leprogramozni.
Gond az, hogy ha kiegyenlíted az első hiányt, akkor aktualizálnod kell a raktárkészletet, és csak utána tudod kezelni a második hiányt.
Ha a közbenső adatfrissítést kihagyod, akkor lehet, hogy a második hiányt is ugyanonnan vonnád le, ahonnan az elsőt, de arra viszont nem elég az eredeti készlet.Ennek inkább valami magasszintű nyelven állnék neki, mert (rekurzív) tákolt eljárással nem annyira triviális.
Mittudomén, Javaban FOR ciklussal végigmész a tömb elemein, ahol negatív értéket látsz, ott indul egy belső ciklus a tömb elemeire, és ahol a hiánynál nagyobb értéket lát, ott felveszi egy listába a [honnan, hova, mennyi] tripletet, valamint tömb[honnan]=tömb[honnan]-mennyi, tömb[hova]=tömb[hova]+mennyi.
Aztán ha végigért a külső ciklus, akkor a tömbben a raktárak közötti mozgatás utáni raktárkészlet lesz, meg a listában a szükséges mozgatások listája.Persze ezt meg lehet írni SQL eljárásban is, csak nem olyan elegáns.
Vagy a példádnál maradva lehet, hogy egyszerűbb lenne megkérni a boltokat, hogy a felesleges árucikkek felét küldjék vissza a következő áruszállításkor a központi raktárba, aztán onnan küldik tovább a begyűjtött holmit a hiánnyal küzdő boltokba.
-
mr.nagy
tag
Az eredménynek az kellene, hogy honnan vegyek el 8-at a pozitív értékektől, úgy hogy ne csökkenjen 0 alá az érték az elvétel miatt. A fiddle példánál maradva az eredmény ami kellene:
honnan id: 1, hova id: 2, val 8
honnan id: 6, hova id: 4, val 12
honnan id: 8, hova id: 7, val 4
......Egy kereskedelmi példa: van 20 üzletem, van ahol felesleges készlet van és van ahol hiány. Honnan hova vigyek és mennyit, hogy a hiány megszünjön, de maradjon ott is elég ahonnan elveszek.
-
mr.nagy
tag
Sziasztok!
MSSQL környezetben a következő problémára keresem a választ:
adott egy tábla ahol az id mellett van egy érték oszlop is. Az érték lehet pozitív és negatív szám is. Ahol az érték negatív oda kellene át tenni onnan ahol ez pozitív. Az eredménynek az kellene, hogy honnan hova tegyünk át és mennyit, hogy a negatív eltűnjön.
Megvalósítható ez és hogyan szerintetek?
-
nyunyu
félisten
válasz
 DeFranco
#4723
üzenetére
DeFranco
#4723
üzenetére
"Sima" joint szokták inner joinnak is hívni, csak az inner és outer kulcsszavakat nem kötelező kiírni.
Az csak akkor ad adatot, ha a join feltétel mentén mindkét táblában van találat.Régi Oracle jelöléssel asszem az az oldal lehet null, ahova a (+)-t teszed.
tehát a from t1, t2 where t1.id=t2.id (+) az egy left (outer) join, t1-hez joinolja opcionálisan a t2-t.
from t1, t2 where (+) t1.id = t2.id meg right (outer) join akar lenni.
Ha sehova sem teszel (+)-t, akkor (inner) join. -

DeFranco
nagyúr
köszönöm, akkor már az elv sem volt jó, akkor így már világos.
gondolom akkor ezt azzal tudom áthidalni hogy előre with-elek mindent amit egyébként subquerybe raknék, majd onnan szedem be a megfelelő mutatókat egy fő querybe.
amint lesz lehetőségem átrendezem így a lekérdezést.
-
nyunyu
félisten
Egyébként ettől a where-es egyenlő dologtól kiráz a hideg, pedig még az iskolában is így tanították a táblák join-ját.
Na igen, mert némelyik DBben régen úgy kellett joinolni a táblákat, hogy FROM után felsoroltad őket, majd WHERE után a feltételek.
Aztán jött a szabványos JOIN írásmód, ami ezzel ekvivalens, de sokkal olvashatóbb.Én meg a WHERE t2.id=t1.id (+) feltételtől kaptam hülyét, hogy akkor ez most left vagy right join, melyik táblát joinoljuk melyikhez?
Nem szeretem ezt a régi Oracle szintaxist, inkább szabványosat írok.
-
-
nyunyu
félisten
Az a baj, hogy a nagyon korai, huszonévvel ezelőtti Teradata szintaxis ilyen galádságokat is megengedett:
update t1
set column=t2.column
where t2.id=t1.id;Vakarhattam egy darabig a fejemet, amikor SQL parsert kellett a naponta futó DWH kódok felméréséhez írnom, hogy ez vajon mi a francot jelent.
Ehhez képest a későbbi, FROMmal turbózott szintaxisuk kifejezetten olvasható.
Tudom, Oracle sem szabványos, de a szabvány SQL dialektikát azért nagyjából érti.
-
nyunyu
félisten
válasz
DeFranco
#4711
üzenetére
Összeadni-kivonni a különböző alqueryk eredményeit csak annak a query mezőlistájában tudod, amelyik queryben definiáltad az aliasokat:
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM (select munkavallalo, ...
from ...
where ...) K
JOIN (select munkavallalo, ertek ...
from ...
where ...) KHD
ON KHD.munkavallalo = K.munkavallalo
JOIN (select munkavallalo, ertek ...
from ...
where ...) AHD
ON AHD.munkavallalo = K.munkavallalo
JOIN (select munkavallalo, ho ...
from ...
where ...) KH
ON KH.munkavallalo = K.munkavallaloN+1-edik joinolt alselect nem hivatkozhat az előző alselectek mezőire, mert Oracle alatt nem látják egymás változóit a különböző aliasolt nézetek.
(Kivéve CTE kifejezést írva, ott használhatod joinra a korábban definiált másik alselectek aliasait.)(Előbb emlegetett Teradata DWH queryjeiben az aliasok globálisan láthatóak az egész queryben, nem csak az őket hivatkozó szinten.
Ja, plusz ott mező alias is hivatkozható, pl. select 1+1 as a, a+1 as b; simán visszaad A=2, B=3-at, Oracle meg szintaktikai hibát dob) -
-
nyunyu
félisten
Ja igen, MS az SQL Server 2008 környékén nekiállt implementálni a Teradata szintaxist *, hátha át tud csábítani pár DWH júzert a méregdrága Teradatától.
De attól ez még nem szabványos, Oracle alatt biztosan NEM megy.
*: szabványos UPDATEben NINCS FROM, nem lehet táblákat felsorolni/joinolni.
-
nyunyu
félisten
válasz
 RedHarlow
#4712
üzenetére
RedHarlow
#4712
üzenetére
Ezt a Teradata féle joinnal bővített UPDATE szintaxist semelyik másik DB kezelő nem ismeri, nem tudsz így másik tábla alapján updatelni.
Oracle elég körülményesen tud hasonlót, SET+WHERE mögé írt alselecttel, de annak a pontos szintaxisára nem emlékszem, de arra igen, hogy amihez nem talál értéket, ott szimplán NULLlal felülírja a többi sort.
Valami ilyesmi lehetett:
UPDATE t1
SET t1.column=(SELECT column FROM t2 WHERE t2.id=t1.id)
WHERE t1.id IN (SELECT id FROM t2);(Teradata csak a joinnal megtalált sorokat updateli, többit békén hagyja!)
Legtisztább megoldás erre a szabványos MERGE utasítás:
MERGE t1
USING (SELECT id,
column
FROM t2) t2
ON (t2.id = t1.id)
WHEN MATCHED
THEN UPDATE SET t1.column = t2.column;Hmm, még alselect se kell az USING mögé, direktben is mehet a t2, ha a joinon kívül nem kell semmi bonyolultat csinálni vele:
MERGE t1
USING t2
ON (t2.id = t1.id)
WHEN MATCHED
THEN UPDATE SET t1.column = t2.column; -

RedHarlow
aktív tag
Sziasztok, az alábbi feladat megoldására ezt a példát találtam stackowerflow-on azonban az SQL developer hibára fut vele. A feladat az lenne, ogy egy tábla oszlopát kitöltsem egy másik tábla adataival azonos ID-k alapján. Tudnátok segíteni benne, fehér öves vagyok SQL-ből, nekem ez tök érthetően okénak tűnt aztán mégsem jó. Előre is köszönöm a segítséget.
UPDATE t1
SET t1.colmun = t2.column
FROM Table1 t1, Table2 t2
WHERE t1.ID = t2.ID; -
DeFranco
nagyúr
nos...
az oldschool módszert használom, ahogy írod és szépen megy is addig, ameddig leírtad.
ezek ugye önmagukban (a zárójelek között) önálló selectek, egymás változóit nem használják csak egymás mögé vannak láncolva.
(az hogy pivotolgatok is ezekben az önálló selectekben, az egy másik kérdés. szerintem redundáns és ki kellene szedni de még nem jöttem rá a mikéntjére, ha csak simán kiszedem akkor az egy-a-többhöz kapcsolatok miatt a 20k-s valós rekordszámból a várt 400k-s rekordszám helyett (x20 oszlop a pivotban) 380 millió rekord lesz, nyilván én vétek hibát valahol)
ez alá jönne az a rész (amit én írtam lentebb) amikor az önálló, tábla-szerű egységgé zárójelezett, aliasolt blokkokból ki szeretnék venni mutatókat, azokat pl. összeszorozni vagy kivonni, és ez már nem megy. mutatom példában:
SELECT * FROM
(
SELECT
AL1.munkavallalo...
FROM... AL1
) K
JOIN
(
SELECT
AL2.munkavallalo
AL2.mutatoX
FROM AL2
) KHD
ON K.munkavallalo = KH.munkavallalo
JOIN
(
SELECT
AL3.munkavallalo
AL3.mutatoY
FROM AL3
) AHD
-- eddig a te logikáddal megegyezik, annyiban tér el hogy select * from van a definiált értékek helyett, de ez indifferens azt hiszem
-- innen jönne az amit én szeretnék, de nem megy
JOIN
(
SELECT
K.munkavallalo
KHD.mutatoX-AHD.mutatY
FROM
???
) KAMEHAMEAde azt hiszem az első opció szerint lenne elegáns megcsinálni, én is gondoltam már erre (mióta megtanultam Tőled a where-t
) valószínűleg az lenne a praktikus. -
nyunyu
félisten
FROM (select munkavallalo, ...
from ...
where ...) K
JOIN (select munkavallalo, ...
from ...
where ...) KHD
ON KHD.munkavallalo = K.munkavallaloErre gondoltam múltkor, amikor azt írtam, hogy tetszőleges select köré lehet zárójelet tenni, és az alquery mögéírt aliasnevet táblaként használni, ahol az SQL szintaxisa táblanevet vár.
Csak a korábbi példánál még nem értettem, hogy mit akarsz joinolni hova.
-
nyunyu
félisten
válasz
DeFranco
#4708
üzenetére
Jó, de hogy csatolod az aliasolt alqueryket a fő queryhez?
CTE szintaxissal libasorban?
with k as
(select munkavallalo, ...
from ...
where ...),
khd as (
select munkavallalo, ...
from ...
where ...),
ahd as (
select munkavallalo, ...
from ...
where ...),
kh as (
select munkavallalo, ...
from ...
where ...)
-- innentol a "fo" query
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM K
JOIN KHD
ON KHD.munkavallalo = K.munkavallalo
JOIN AHD
ON AHD.munkavallalo = K.munkavallalo
JOIN KH
ON KH.munkavallalo = K.munkavallalo
)
PIVOT
(
SUM(KPERA)
FOR HO IN (...)
)Vagy oldschool módon?
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM (select munkavallalo, ...
from ...
where ...) K
JOIN (select munkavallalo, ...
from ...
where ...) KHD
ON KHD.munkavallalo = K.munkavallalo
JOIN (select munkavallalo, ...
from ...
where ...) AHD
ON AHD.munkavallalo = K.munkavallalo
JOIN (select munkavallalo, ...
from ...
where ...) KH
ON KH.munkavallalo = K.munkavallalo
)
PIVOT
(
SUM(KPERA)
FOR HO IN (...)
)Elvileg mindkettő szabványos, menniük kellene.
(Még oldschoolabb, FROM után vesszővel felsorolt () K, () KH, () KHD, () AHD majd WHERE után a join feltételek szintaxis az nem szabványos, nem minden DB ismeri.
Az valami Teradata hagyaték lehet a JOIN szabványosítása előttről?) -
nyunyu
félisten
válasz
DeFranco
#4706
üzenetére
igen csak itt az általad leírt selectben már eleve aliasolt selectek a "táblaazonosítók" (K, KHD, KH, AHD)
Gondolom mindegyik alselectben be van rakva a munkavallalo azonosítója, ami mentén joinolhatóak a selectek által visszaadott virtuális táblák.
Szóval:
...
FROM K
JOIN KHD
ON KHD.munkavallalo = K.munkavallalo
JOIN KH
ON KH.munkavallalo = K.munkavallalo
JOIN AHD
ON AHD.munkavallalo = K.munkavallalo
...Ha nincs, akkor mindegyik alquerybe legyen beletéve!
-
DeFranco
nagyúr
igen csak itt az általad leírt selectben már eleve aliasolt selectek a "táblaazonosítók" (K, KHD, KH, AHD)
és mivel a SELECT szintaktikája ha jól tudom megköveteli a FROM-ot, nem tudom mit írhatnék a ??? helyére, mert ha azt írom hogy
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM
K
JOIN KHD
ON
K.valami = KHD.valami
JOIN KH
ON
K.valami = KH.valami
JOIN AHD
ON
K.valami = AHD.valamiakkor az nem működik. azt nem tudom hogy elvileg kellene-e működnie, sajnos favágó módszerrel tanulom az sql-t
-
nyunyu
félisten
válasz
DeFranco
#4704
üzenetére
Tetszőleges select köré lehet zárójelet tenni, majd eléírni egy másik selectet, aztán az egészet joinolni egy újabb táblával a belső selectből kijövő tetszőleges oszlopra:
SELECT *
FROM (
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM
???
) a
JOIN b
ON b.valami=a.kpera
PIVOT
(
SUM(KPERA)
FOR HO IN (...)
)Lényeg az, hogy a zárójel után adj az alquerynek egy aliast, azzal tudod a külső selectben hivatkozni a mezőit.
-
DeFranco
nagyúr
újabb problémába futottam bele, lehet egy kicsit vadulok már ezzel:
adott egy lekérdezés, ami elég hosszú, több subqueryből áll,
gyakorlatilag legyártok néhány kereszttáblát, majd ezeket joinolom egymás után, egyes kereszttáblákban nyers adatok vannak, más kereszttáblákban számított adatok.
pl.
1: munkavállalók havi keresete, havonkénti bontásban (KH)
2: munkavállalók keresete legyártott darabonként havonkénti bontásban (KHD)
3: munkavállalók éves keresete (K)
4: munkavállalók anyagfelhasználása havonkénti bontásban (AH)
5: munkavállalók anyagfelhasználása legyártott darabonként havonkénti bontásban (AHD)
6: munkavállalók éves anyagköltsége (A)a joinok miatt minden ilyen szakasz el is van nevezve (Pl. KHD, AHD), ezek alapján tudom K.Y=KHD.B módon kapcsolni.
a lekérdezés végére szeretnék tenni még egy kereszttáblát de azt már lehetőleg úgy, hogy az néhány korábbi subquery eredményére hivatkozzon, pl.
SELECT
K.[munkavállaló] "MUNK"
KHD.[érték]/AHD.[érték] AS "KPERA"
KH.[hónapazonosító] AS "HO"
FROM
???
PIVOT
(
SUM(KPERA)
FOR HO IN (...)
)Nem tudom hogy a felső subqueryket így meg tudom-e csapolni, jelenleg nem tudom megoldani, és ötletem sincs mit lehetne tenni a FROM mögé mert a subquery neveket nem akarja "fogyasztani"
egy nagy selecten belül kell mindent megoldanom, táblát gyártani nincs jogosultságom.
érzésem szerint amit egyszer valahol már legyártottam azt fel kellene tudnom használni úgy hogy nem ismétlem meg azt a kódrészt még egyszer de nem jövök rá hogy kellene ezt megtennem.
-
DeFranco
nagyúr
köszönöm szépen, így sem működött de megoldottam, egyszerűen kiszámoltattam vele még a selectben és azt pivotoltattam az abszolút érték helyett
select * from (
with egyed_osszeg as
(select egyed_azonosito,
sum(ertek) osszeg
from tabla
group by egyed_azonosito)
select t.egyed_azonosito,
t.csoport_kepzo,
--t.ertek,
o.osszeg,
t.ertek/o.osszeg arany
from tabla t
join egyed_osszeg o
on t.egyed_azonosito = o.egyed_azonosito
)
pivot
( sum(arany)
for csoport_kepzo in ('A','B'...)
)így már szépen működik, elé joinoltam az abszolút értékeket és teljes lett a tábla
köszönöm még egyszer a tippeket
-
nyunyu
félisten
válasz
DeFranco
#4701
üzenetére
Ja, hogy az osszeget is aggregálni akarja az egyed_azonosito mentén?
Akkor használj valami oszlopfüggvényt az osszeg oszlopra, és akkor nem fog beszólni érte.Mondjuk: sum(ertek)/min(osszeg)
(Mivel ugyanahhoz az egyed_azonosito osszes sorához ugyanaz az osszeg joinolódik, mindegy, hogy min() vagy max()-ot használsz aggregálásra)
Ez azért van, mert a pivotnál mindent sorfejlécnek értelmezünk ami nincs benne a sum és a for mezőkben és az a lekérdezés sorrendje szerinti hierarchiában alábontást jelent?
PIVOT az gyakorlatilag group by-ol az oszlopfüggvényekben és a FORnál sem hivatkozott oszlopokra, azokból fog állni a fejléc, majd a FOR után felsorolt értékekből.
Ezek alá teszi be a "group by" értékeit változatlanul, melléjük az oszlopfüggvényekkel számolt aggregált értéket a FORban felsorolt oszlopok szerint szétválogatva.Esetedben az egyes oszlopok tartalma ez lesz:
- egyed_azonosito
- (select sum(ertek)/min(osszeg) where csoport_kepzo='A' group by egyed_azonosito) as 'A'
- (select sum(ertek)/min(osszeg) where csoport_kepzo='B' group by egyed_azonosito) as 'B'
- (select sum(ertek)/min(osszeg) where csoport_kepzo='C' group by egyed_azonosito) as 'C'
- ...
Mintha egy rakat group_by lenne egymás mellett, különböző where feltétellel. -
DeFranco
nagyúr
Köszönöm szépen, nagyjából működik de nem teljesen:
1: a sum(ertek)/osszegre ugrik az ellenőrzés, nem fut le, a hibaüzenet az alábbi:
ORA-56902: összesítő függvényt várható a forgatási műveletben
56902. 0000 - "expect aggregate function inside pivot operation"
*Cause: Attempted to use non-aggregate expression inside pivot operation.
*Action: Use aggregate function.2: ez csak nekem kérdés mert még nem vagyok otthon pivotban: ha sum(ertek)-en hagyom tehát nem képzek indexet, akkor az eredménytábla úgy néz ki hogy ezeket az oszlopokat pakolja egymás mellé:
egyedi_azonosito II o.osszeg II A II B II C II stb.
tehát az [o.osszeg] oszlopot a pivotolt résztől függetlenül beteszi a "sorfej" és az "oszlopok" közé
Ez azért van, mert a pivotnál mindent sorfejlécnek értelmezünk ami nincs benne a sum és a for mezőkben és az a lekérdezés sorrendje szerinti hierarchiában alábontást jelent?










![;]](http://cdn.rios.hu/dl/s/v1.gif) Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.


































Új hozzászólás Aktív témák
- CPU léghűtés kibeszélő
- Hogyan verte le egy telefon chip az egész laptop ipart? – x86 vs ARM
- Milyen okostelefont vegyek?
- Futás, futópályák
- CURVE - "All your cards in one." Minden bankkártyád egyben.
- PlayStation 1 / 2
- Telekom mobilszolgáltatások
- Xiaomi Watch 5 - kínai időszámítás
- Xbox tulajok OFF topicja
- Kormányok / autós szimulátorok topikja
- További aktív témák...
- MSI Thin GF63 - 15,6"FHD 144Hz - i5-12450H - 16GB - 512GB - Win11 - RTX 4050 - Garancia - MAGYAR
- Kezdő Gamer PC-Számítógép! I5 6500 / GTX 1050Ti / 8GB DDR4 / 240GB SSD
- HIBÁTLAN iPhone 15 Plus 128GB Blue -1 ÉV GARANCIA - Kártyafüggetlen, MS4504
- Xiaomi 14 512GB, Kártyafüggetlen, 1 Év Garanciával
- GAMING PC! Ryzen 5700X / RTX 3070 / 32GB 3600MHz / SSD / 700w Gold!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest