Hirdetés
- gban: Ingyen kellene, de tegnapra
- Luck Dragon: Óraátállítás
- MasterDeeJay: RAM gondolatok: Mennyi a minimum? DDR3 is jó?
- hmzs: Fujitsu Futro S920 csúcsra járatva
- Elektromos rásegítésű kerékpárok
- aquark: Flipper PC-n!
- Hieronymus: Hogyan parkolj hátramenetben profi módon
- Luck Dragon: MárkaLánc
- GoodSpeed: Reklámmentesítés HyperOS-ben Xiaomi/POCO/Redmi
- D1Rect: Nagy "hülyétkapokazapróktól" topik
Új hozzászólás Aktív témák
-
#3700
 mr.nagy
tag
Apollo17hu
#3699
mr.nagy
tag
Apollo17hu
#3699
mr.nagy
tag
válasz
 Apollo17hu
#3699
üzenetére
Apollo17hu
#3699
üzenetére
Szia,
köszönöm. Ha beértem kipróbálom!
-
#3699
 Apollo17hu
őstag
mr.nagy
#3698
Apollo17hu
őstag
mr.nagy
#3698
Apollo17hu
őstag
válasz
 mr.nagy
#3698
üzenetére
mr.nagy
#3698
üzenetére
Szia!
Írtam a példádhoz egy favágó kódot. Legalábbis ha sql-ben kellene megoldani, akkor én úgy állnék neki, hogy meghatároznám a total igényt, az igénylők darabszámát, és ebből számolnék tovább.
Akkor nincs gond, ha az igény többszöröse a kiosztható értéknek, mert akkor egyszerűen a kiosztható értéket az igénylők számával kell leosztani, és minden igénylő ennyit fog kapni. (Ezt már nem kódoltam bele, de értelemszerűen 20 db CASE WHEN-ről lesz szó...)
Eddig írtam meg a kódot. Még megképeztem egy olyan mezőt, ami azt tartalmazza, hogy mennyi olyan kiosztható érték marad, amiből már csak 1-1 darabot lehet véletlenszerűen (vagy extra logikával?) odaadni az igénylőknek.
select case when alap.kioszthato >= alap.total then 'N' else 'I' end hiany_fl
,case when alap.kioszthato >= alap.total then null
when isnull(alap.darab, 0) = 0 then null
else floor(alap.kioszthato / alap.darab) end ennyire_kell_csokkenteni
,case when alap.kioszthato >= alap.total then 0
when isnull(alap.darab, 0) = 0 then null
else alap.kioszthato - floor(alap.kioszthato / alap.darab) * alap.darab end ennyi_szetosztando_marad
,alap.*
from
(SELECT P1+P2+P3+P4+P5+P6+P7+P8+P9+P10+P11+P12+P13+P14+P15+P16+P17+P18+P19+P20 as total
,case when P1= 0 then 0 else 1 end + case when P2= 0 then 0 else 1 end + case when P3= 0 then 0 else 1 end + case when P4= 0 then 0 else 1 end + case when P5= 0 then 0 else 1 end + case when P6= 0 then 0 else 1 end + case when P7= 0 then 0 else 1 end + case when P8= 0 then 0 else 1 end + case when P9= 0 then 0 else 1 end + case when P10= 0 then 0 else 1 end + case when P11= 0 then 0 else 1 end + case when P12= 0 then 0 else 1 end + case when P13= 0 then 0 else 1 end + case when P14= 0 then 0 else 1 end + case when P15= 0 then 0 else 1 end + case when P16= 0 then 0 else 1 end + case when P17= 0 then 0 else 1 end + case when P18= 0 then 0 else 1 end + case when P19= 0 then 0 else 1 end + case when P20= 0 then 0 else 1 end as darab
,t.*
FROM Teszts t) alap -

varsam
őstag
válasz
mr.nagy
#3696
üzenetére
szia
excelben összeraktam valami hasonlót, ha jól értettem mi a feladat
A pivotban látod, hogy az 1,2,3-as vevőknek mekkora igényei voltak, mennyit kapnak és mennyi a maradék, ami az átlagolás miatt nem kerül szétosztásra.
SQL-ben analitikus függvényekkel meg lehetne csinálni ugyanígy szerintem.
-

Ispy
nagyúr
válasz
mr.nagy
#3694
üzenetére
Hát ez elég bonyi, szóval megoldani nem fogom helyetted.

De első körben szétszedném a táblát más formátumba, visszapivotosítanám:
Kioszthato, Oszlop, Ertek, ElteresTotal, IdealisErtek
Aztán ki kell találni valami algoritmust, függvény, amivel megkapod a jó számokat, egyelőre eddig jutottam.

Persze lehetne írni egy giga-mega ciklust, ami végigrohan a rekordokon és mezőkön, de én ciklust csak akkor használok, ha behatárolható mennyiségű rekordot tartalmaz a source, mert különben képes az idő végéig futni.
-
mr.nagy
tag
Sziasztok!
Adott egy tábla, ebben 1 oszlopban a szétosztható mennyiség és 20 oszlopban az igények. Na most amikor az összes igény kevesebb mint a szétosztható akkor nincs gond, de ha kevesebb akkor arányosan csökkenteni kellene az igényeket a szétosztható mértékig. Csak egész szám lehet az eredmény (nem lehet 0.8 tortát odaadni).
Szerintetek megoldható ez SQL-ben és hogyan? Ha számít MS SQL a környezet..
-
#3687
 bambano
titán
Apollo17hu
#3686
bambano
titán
Apollo17hu
#3686
bambano
titán
válasz
Apollo17hu
#3686
üzenetére
nem

szerintem az lenne a legegyszerűbb megoldás, hogyha a lebegőpontos értéket megszorozza 5-tel és veszi az egészrészét, akkor megkapja, hogy hanyadik hisztogram oszlopba kerül az az eredmény, vagyis count és group by már használható. -

K1nG HuNp
őstag
Hol találok egy MS Accesson alapuló SQL gyorstalpalót olvasni? Az érettségihez kellene. Rájöttem, hogy milliószor egyszerübb kódban irni mint kattingtani accessben, és még átláthatóbb is.
-

kw3v865
senior tag
Sziasztok!
PostgreSQL-ben a következő problémára keresek megoldást, egyelőre nem nagy sikerrel:
adott egy tábla, amely a distance mezőben lebegőpontos értékeket tartalmaz (több millió rekord) 0 és 1000 között. Ebből olyan hisztogramot készítettem (külön táblába), amely 0.2 "széles" csoportokra bontotta fel. Tehát 5000 rekordot tartalmaz így a hisztogram tábla. A probléma csak az, hogy ha egy intervallumba pl. 80.2 és 80.4 közé nem esik egyetlen érték sem, akkor a hisztogram tábla a darabszámhoz nem 0-t, hanem 1-et ír.Ezt használom a hisztogram elkészítéséhez: https://github.com/borrob/histogram/blob/master/histogram_functions.sql
Van esetleg valami ötletetek, miként lehetne ezt a hibát kiküszöbölni?
-

Petya25
őstag
Hali
Valami egyszerű tipp arra, hogy sok manuál melót elkerüljek a kódolásnál, ami annyit tenne, hogy egy sokmezős lekérdezés a rekord mezőit ne egymás mellé sorlja fel, hanem egymás alatt soronként mellette az értékkel?
select mező1, mező2, ... mező10 from tábla
mező1, érték1
mező2, érték2
...
mező10, érték10Valami olyan kéne mint excelben a transzponálás sorból oszlop kb...
-

kem
addikt
Sikerult felig.
INSERT INTO subscription_attribute
select
s."UID", 167463909189556, 1, '<null/>'
from subscription s
join SUBSCRIPTION_RESOLVE_KEY srk on s."UID" = srk.SUBSCRIPTION_UID
join account a on s.OWNING_ACCOUNT_UID = a."UID"
left outer join boostGainEnabled ml on s."UID" = ml.SUBSCRIPTION_UID
where
ml.SUBSCRIPTION_UID is null
and srk.DOMAIN_RESOLVE_KEY_UID = (
select drk."UID" from DOMAIN_RESOLVE_KEY drk
where drk.ID like 'guestPIN')
and a.id like '%xy007%'
and s.id like '%xy%'
order by s."UID";Most mar csak azt szeretnem, ha a 167463909189556 helyett tudnam hasznalni a parameter nevet. Erre egy masikat irtam, a kettot kene valahogy osszegyurni.
INSERT INTO subscription_attribute
select
168504837876601, dp."UID", 1, '<null/>'
from DOMAIN_PARAMETER dp where ID like 'boostGainEnabled';Szerk, meg is van:
INSERT INTO subscription_attribute
select
s."UID", dpa."UID", 1, '<null/>'
from DOMAIN_PARAMETER dpa, subscription s
join SUBSCRIPTION_RESOLVE_KEY srk on s."UID" = srk.SUBSCRIPTION_UID
join account a on s.OWNING_ACCOUNT_UID = a."UID"
left outer join boostGainEnabled ml on s."UID" = ml.SUBSCRIPTION_UID
where
ml.SUBSCRIPTION_UID is null
and srk.DOMAIN_RESOLVE_KEY_UID = (
select drk."UID" from DOMAIN_RESOLVE_KEY drk
where drk.ID like 'guestPIN')
and a.id like '%xy007%'
and s.id like '%xy%'
and dpa.ID like 'boostGainEnabled'
order by s."UID";Bocs, hogy ideszemeteltem, de reggel meg biztos voltam benne, hogy nem fog sikerulni

-
kem
addikt
Sziasztok!
Ismet egy kis segitsegre lenne szuksegem TimesTen adatbazissal kapcsolatban, Van nekem egy nyakatekert SQL querym aminek az eredmenyet szeretnem insertalni egy tablaba, a kovetkezo keppen:
INSERT INTO subscription_attribute VALUES(<ide szeretnem belistazni a kovetkezo kimenetet>, 167463909189556, 1, '<null/>');select s."UID"
from subscription s
join SUBSCRIPTION_RESOLVE_KEY srk on s."UID" = srk.SUBSCRIPTION_UID
join account a on s.OWNING_ACCOUNT_UID = a."UID"
left outer join boostGainEnabled ml on s."UID" = ml.SUBSCRIPTION_UID
where
ml.SUBSCRIPTION_UID is null
and srk.DOMAIN_RESOLVE_KEY_UID = (
select drk."UID" from DOMAIN_RESOLVE_KEY drk
where drk.ID like 'guestPIN')
and a.id like '%xy007%'
and s.id like '%xy%'
order by s."UID";A boostGainEnabled egy view-t takar, amit igy hoztam letre:
create view boostGainEnabled as
select s."UID" as SUBSCRIPTION_UID
from subscription s
join subscription_attribute sa on s."UID" = sa.SUBSCRIPTION_UID
join account a on s.OWNING_ACCOUNT_UID = a."UID"
join domain_parameter dp on sa.DOMAIN_PARAMETER_UID = dp."UID"
where dp.ID like 'boostGainEnabled';Szoval a kerdesem az lenne, hogy hogyan agyazok be az INSERT-em egyik Value helyere egy subqueryt?
Elore is koszonom szepen a segitseget!

-
#3671
Apollo17hu
őstag
Fundiego
#3670
Apollo17hu
őstag
válasz
 Fundiego
#3670
üzenetére
Fundiego
#3670
üzenetére
listagg()
de vannak más megoldások is -

Fundiego
tag
Van olyan sql parancs ami a következőt teszi?
Megadok egy feltétel Select gyumolcs from gyumi WHERE honap='januar'" ezzel egymás alá egy oszlopban dobja ki az értékeket. Nekem olyan kéne ami egy rekordba vesszővel elválasztva adná meg az értéket.
Az első esetben ez a végeredmény:
Narancs
BanánAmi kellene nekem az a következő végeredmény.
Narancs,Banán -
bambano
titán
válasz
 kw3v865
#3665
üzenetére
kw3v865
#3665
üzenetére
annak a true-nak meg false-nek nem sok értelmét látom, mert ha védett régióban van, akkor a védett régió neve oszlop nem null lesz, ha meg nem ott van, akkor igen.
viszont ez nem kellene, hogy sokat lassítson, mert a postgresql elméletileg becacheli az adatokat meg az eredményeket.
ha a kifejezés elé írsz egy explain-t, akkor megmondja az optimalizáló, hogy mit fog csinálni. azt érdemes bogarászgatni.
szerk: azt az egész case-t ki lehetne váltani szerintem úgy, hogy a lekérdezett mezők közé felveszed a védett régió nevét, és egy coalesce-vel beleírsz valamit, ha üres: coalesce(pr.name,'FALSE') as name.
-
kw3v865
senior tag
válasz
 bambano
#3666
üzenetére
bambano
#3666
üzenetére
Köszi a tippet, utánanézek. Eddig nem kellett foglalkoznom különösebben a performanciával, de most fontossá vált.
Még arra gondoltam, hogy az elején a CASE WHEN ST_Intersects(p.geom,pr.geom) then 'TRUE' ELSE 'FALSE' vajon elhagyható-e valahogy? Mert ugye most az ST_Intersects függvényt kétszer hívja meg, hiszen a JOIN is ezen alapul. Nekem az a cél, hogy ne csak a TRUE, hanem a FALSE rekordokat is lekérdezzem. Jobb módszert egyelőre nem találtam.
-
-
kw3v865
senior tag
Sziasztok!
A következő PostgreSQL-es lekérdezésemet szeretném optimalizálni, hogy gyorsabban lefusson.
SELECT DISTINCT s.region, s.protected, s.gid FROM (
SELECT CASE WHEN ST_Intersects(p.geom,pr.geom) then 'TRUE' ELSE 'FALSE' END AS protected, p.gid AS gid,r.name AS region
FROM point p
LEFT JOIN protected_area pr
ON ST_Intersects(p.geom,pr.geom)
LEFT JOIN region r
ON ST_Intersects(p.geom, r.geom)
) s;Azt csinálja, hogy kiírja, hogy az adott pont mely régióban (poligon) található, illetve azt, hogy védett területen van-e (protected_area). GIST index-szel el vannak látva a táblák, így most 7,5 M pontra kb. 6 perc alatt fut le, viszont a poligonokat tartalmazó táblák csak 3, illetve 1488 rekordot tartalmaznak.Szerintetek hogyan lehetne még gyorsítani a lekérdezést?
-
válasz
 Iginotus
#3660
üzenetére
Iginotus
#3660
üzenetére
meh. egy frappáns tsql-es megoldás jutott eszembe erre, ott a newid-t checksumozva generáltunk egy random számot, amit a megfelelő méretűre faragtunk. de ez persze nem igazi random. oracle-ben a sys_guid() csinál hasonlót.
mondjuk én olyan állat vagyok, aki sqlben nem ír ciklust, mert tiltja a vallása. -

bpx
őstag
válasz
Iginotus
#3660
üzenetére
Az egy nem correlated subquery (magyarul még szebb: korrelált allekérdezés), ezért ami belül van, az egyszer lefut, és kívül mindenhova az ott kapott értéket használja. Lehet belőle correlated subquery-t csinálni valami értelmetlen feltétellel és akkor majd miden sorra újból kiértékelődik. Persze ez nem szép és kapásból odaírnám kommentbe, hogy ez miért van belegányolva. Vagy marad a ciklus, amit már első ránézésre is el lehet olvasni.
create table forge (row_id, code_neu) as select rownum, 0 from dual connect by level <= 10;
create table oe (orgeh_code) as select rownum from dual connect by level <= 4;
select * from forge;
ROW_ID CODE_NEU
---------- ----------
1 0
2 0
3 0
4 0
5 0
6 0
7 0
8 0
9 0
10 0
select * from oe;
ORGEH_CODE
----------
1
2
3
4
update forge set code_neu =
(
select orgeh_code from oe
----
where forge.row_id = forge.row_id
----
order by dbms_random.value fetch first 1 row only
)
where row_id between 1 and 9;
select * from forge;
ROW_ID CODE_NEU
---------- ----------
1 1
2 3
3 1
4 2
5 1
6 1
7 4
8 3
9 4
10 0 -

nyunyu
félisten
válasz
Iginotus
#3658
üzenetére
valami ilyesmi:
declare i number;
begin
for i in 1 .. 9 loop
update ...
where row_id=i
end loop;
end;Kevésbé procedurálisan gondolkozva persze meg lehet írni egy updatetel is, mivel van sorfolytonos IDd a táblán, amihez lehet row_number()-rel joinolni:
update sds.forge upd
set code_neu=
(select a.orgeh_code from
(select oe.*, row_number() rn from sds.oe
order by dbms_random.value) a
where a.rn=upd.row_id); -

Iginotus
addikt
válasz
 velizare
#3659
üzenetére
velizare
#3659
üzenetére
Ez így nem járja, ez ugyanazt az adatod fogja minden sorba beírni
A lényeg, hogy az előző Randomos 9 szer lefusson 9 értéket kapjon amit beír 9 sorban lehetőleg randomban, ismétlés is lehet.
Ha csak ezt használom akkor egyszer fut csak le és egy értéke lesz mind a 9 sornak. -
-
Iginotus
addikt
Van egy ilyen SQL em. (ORACLE)
update sds.forge
set code_neu=
(select orgeh_code from
(select * from sds.oe
order by dbms_random.value)
fetch first 1 row only)where row_id=1;
Van 9 sorom, hogyan tudom ezt ismételgetni 9 szer? Ciklusokat sosem írtam még
Row_id van 1-9 ig.
Lehet, hogy lesz több sok is egyes esetekben. Szóval n+1 kéne -

hemaka
nagyúr
Hello
Lenne egy gyors kerdesem. Van 3 db SQL fajlom, az egyik egy adatbazis, amit be is importaltam, azzal nincsen gond, csak hogy mellette meg van ketto masik amikkel nem tudom mit is kellene csinalni, dokumentaciom nincsen hozza.
create_indexes.sql
drop_indexes.sql
Ezeket futtatni kellene vagy micsoda? Koszi. -
kw3v865
senior tag
Sziasztok!
A következő SQL-es kérdésem lenne. A feladat az, hogy adott egy úthálózat (ways tábla), illetve egy megye tábla (polygon), és az utakat fel kell darabolni a megyehatároknál.
Az alábbi lekérdezéssel ezt meg is tudtam oldani, viszont amire egyelőre nem találtam az, hogy az új táblában, ami már a szétdarabolt utakat tartalmazza, egy új oszlopban tartalmaznia kellene a régi ID-kat.
create table ways_split as (
WITH
lines_in_polygons AS(
SELECT ST_INTERSECTION(ways.geom,polygon.geom) as inter
FROM
ways, polygon
),
diff AS (
SELECT ST_Difference(ways.geom,ST_UNION(p.geom)) geom FROM
ways
JOIN polygon AS p ON
ST_INTERSECTS(ways.geom,p.geom)
GROUP BY ways.geom)SELECT ST_GeometryN(geom,n)
FROM diff AS d
CROSS JOIN
(SELECT
generate_series(1,ST_NumGeometries(geom)) as n FROM diff) n
UNION
SELECT inter
FROM lines_in_polygons);Tehát most arra kellene rájönnöm, miként tudom egy új oszlopban hozzáadni a vonalak eredeti ID-ját. Értelemszerűen a megyehatároknál elvágott új szakaszok ugyanazt az eredeti ID-t fogják kapni.
Van valami ötletetek miként lehetne ezt megvalósítani?
-
bpx
őstag
válasz
 SunyaMacs
#3650
üzenetére
SunyaMacs
#3650
üzenetére
select
t.topic_id,
t.topic_name,
coalesce(p.post_time, t.topic_time)
from
topics t
left join
(
select
topic_id,
max(post_time) as post_time
from
posts
group by
topic_id
) p
on (t.topic_id = p.topic_id)
;Ha meg azt akarnám, hogy gyors is legyen, akkor +1 oszlop a topics-ba, pl. last_post_time, amit post írásakor karban kell tartani, és akkor nem kell join meg aggregáció.
-
Sziasztok!
Lenne 2 táblám hasonló struktúrával:topics:
-topic_id
-topic_by
-topic_name
-topic_timeposts:
-post_id
-topic_id
-post_by
-post_text
-post_timeInnen kéne selectelni a topic id-jét, nevét, és a legutóbbi post idejét(vagy ha nincs ahhoz a topichoz post, akkor a topic idejét)
Ti hogy oldanátok meg?
-
bambano
titán
kösz mindkettőtöknek, de nekem ez egy kicsit bonyolult
én a következőkre jutottam: neten talált ötlet, hogy rakjak a számsorra egy rank()-et. lényeg, hogy subselectben kell legyen a számsor, mert a distinct meg a rank postgresben nem fér össze.a szám-rank() az gyakorlatilag megmondja, hogy hány szám maradt ki eddig a sorból. ami azt is jelenti, hogy egy részsorozaton belül a szám-rank() konstans. vagyis kezelhető group by-jal.
select min(number),max(number),count(*) from (
select number,number-rank() over (order by number) as ranked from (
select distinct number as number from item order by 1) as w
) as q group by ranked order by 1;a legbelső selectből kitöröltem a nem publikus részt.
-
nyunyu
félisten
válasz
bambano
#3645
üzenetére
Ilyesmi feladatba már sikerült belefutnom melóhelyen.
Ottani kódom erősen leegyszerűsítve.DB adminjaink persze nem szoktak szeretni érte, amikor több millió soros táblákból kell kibogarásznom pár tízezer hasznos rekordot, majd azokat intervallumokba rendezni...
Query plant kielemezve mindenféle Cartesian join kerülendő szakszavakkal dobálózva próbálják levenni a rontást a DB performanciáról. -

tm5
tag
válasz
bambano
#3645
üzenetére
Ezt sqlfiddleben raktam össze:
/*schema setup:*/
create table t1(c1 integer);
insert into t1 values (1);
insert into t1 values (2);
insert into t1 values (3);
insert into t1 values (4);
insert into t1 values (6);
insert into t1 values (7);
insert into t1 values (10);
insert into t1 values (11);
/*a query:*/
select * from (
select c1,
CASE
WHEN plus1 != kovetkezo THEN 'vegelem'
WHEN minus1 != elozo THEN 'kezdoelem'
WHEN elozo IS NULL THEN 'kezdoelem'
WHEN kovetkezo IS NULL THEN 'vegelem'
ELSE 'kozbulso'
END tipus
from
(select c1, c1-1 minus1, c1+1 plus1, lag(c1) over () elozo, lead(c1) over () kovetkezo from t1) t) tt
where tipus != 'kozbulso';ezután már csak egy pivot kéne, de arra már nem volt energiám
-
#3644
 BeeGee2115
csendes tag
Apollo17hu
#3643
BeeGee2115
csendes tag
Apollo17hu
#3643
BeeGee2115
csendes tag
válasz
Apollo17hu
#3643
üzenetére
Igen, köszönöm, nálam az IFNULL() volt a nyerő
A végeredmény pedig:SELECT
szla.Számla,
szla.szamla_ertek- IFNULL(tran.tranzakcio_ertek,0) AS Egyenleg
FROM
(SELECT Számla,
SUM(Összeg) AS szamla_ertek
FROM Adatok
GROUP BY Számla) szla
LEFT JOIN (SELECT Tranzakció,
SUM(Összeg) AS tranzakcio_ertek
FROM Adatok
GROUP BY Tranzakció) tran
ON szla.Számla = tran.Tranzakció -
#3643
Apollo17hu
őstag
BeeGee2115
#3642
Apollo17hu
őstag
válasz
 BeeGee2115
#3642
üzenetére
BeeGee2115
#3642
üzenetére
- tran.tranzakcio_ertekhelyett- nvl(tran.tranzakcio_ertek, 0)-t használj, és így nem fog "eltűnni" az egyenlegszerk.: Most olvasom, hogy közben magad is rájöttél a megoldásra.

-
#3642
BeeGee2115
csendes tag
Apollo17hu
#3641
BeeGee2115
csendes tag
válasz
Apollo17hu
#3641
üzenetére
Már majdnem jó!
A +os szintaktika nem működik, ezért átírtam LEFT JOIN-ra:SELECT
szla.Számla,
szla.szamla_ertek - tran.tranzakcio_ertek
FROM
(SELECT Számla,
SUM(Összeg) AS szamla_ertek
FROM Adatok
GROUP BY Számla) szla
LEFT JOIN (SELECT Tranzakció,
SUM(Összeg) AS tranzakcio_ertek
FROM Adatok
GROUP BY Tranzakció) tran
ON szla.Számla = tran.TranzakcióErre azonban azokak a számláknak, amelyekről sosem történt tranzakció, nem lesz egyenlege

-
#3641
Apollo17hu
őstag
BeeGee2115
#3640
Apollo17hu
őstag
válasz
BeeGee2115
#3640
üzenetére
kb. úgy, ahogy az előbb leírtam: a kettőből 1-1 allekérdezést csinálsz, és számlaszám mentén összekötöd őket, ill. a számlára aggregált allekérdezéshez "gyengén" kötöd a tranzakcióra aggregált allekérdezést (LEFT JOIN, ha a pluszjeles szintaktika nem működne)
-
#3640
BeeGee2115
csendes tag
BeeGee2115
#3638
BeeGee2115
csendes tag
válasz
BeeGee2115
#3638
üzenetére
Közben agyaltam kicsit és arra jutottam, hogy ennek a két lekérdezésnek a kivonása jelentené a megoldást:
A)
SELECT Számla,
SUM(Összeg) Egyenleg
FROM Adatok
GROUP BY Számla;
B)
SELECT Tranzakció,
SUM(Összeg) Egyenleg
FROM Adatok
WHERE Tranzakció!=''
GROUP BY Tranzakció;A-B hogyan lehetséges?
-
#3639
Apollo17hu
őstag
BeeGee2115
#3638
Apollo17hu
őstag
válasz
BeeGee2115
#3638
üzenetére
Egy mintaadatbázis jól jönne sqlfiddle-ben. Addig is ezt értettem meg a leírtakból:
SELECT
szla.Számla,
szla.szamla_ertek - tran.tranzakcio_ertek
FROM
(SELECT Számla,
SUM(Összeg) AS szamla_ertek
FROM Adatok
GROUP BY Számla) szla
,(SELECT Tranzakció,
SUM(Összeg) AS tranzakcio_ertek
FROM Adatok
GROUP BY Tranzakció) tran
WHERE szla.Számla = tran.Tranzakció(+)Az lenne az elve, hogy külön-külön összesítjük a "Számla" és a "Tranzakció" mezőkben lévő összegeket, és ahol a "Számla" és a "Tranzakció" egyezik, ott a kettőt kivonjuk egymásból.
-
#3638
BeeGee2115
csendes tag
Apollo17hu
#3637
BeeGee2115
csendes tag
válasz
Apollo17hu
#3637
üzenetére
Kedves Apollo17hu! Azért nem hagyhatjuk ki a tranzakciókat, mert akkor hibás egyenlegeket kapunk, hiszen az egyik számláról a másikra történő átutalások kiesnének a rendszerből.
Ez már majdnem jó:
SELECT Számla,
SUM(Összeg) - SUM(CASE WHEN Tranzakció!='' then Összeg ELSE 0 END) Egyenleg
FROM Adatok
GROUP BY Számla
A probléma az hogy a tranzakció oszlopban lévő aktuális számlanevet kellene valahogy a megfelelő számlából kivonni, hiszen most csak azt vizsgáljuk, hogy üres vagy sem, de nem az értékét. Egy soron belül a tranzakció és számla oszlopok különböző számlaneveket tartalmaznak a tranzakció értelmének megfelelően. -
#3637
Apollo17hu
őstag
BeeGee2115
#3636
Apollo17hu
őstag
válasz
BeeGee2115
#3636
üzenetére
nem vagyok teljesen képben, de talán erre van szükséged:
SELECT szamla,
SUM(osszeg) - SUM(CASE WHEN tranzakcio IS NOT NULL then osszeg ELSE 0 END)
FROM adatok
GROUP BY szamla...ami - ha jól gondolom - egyenértékű ezzel (egyszerűen eldobjuk azokat a rekordokat, amelyek tranzakciót - is - jelölnek):
SELECT szamla,
SUM(osszeg)
FROM adatok
WHERE tranzakcio IS NULL
GROUP BY szamla -
#3636
BeeGee2115
csendes tag
Apollo17hu
#3635
BeeGee2115
csendes tag
válasz
Apollo17hu
#3635
üzenetére
Köszönöm! De a probléma az, hogy ez továbbra is csak a Számla oszlop szerint fog pozitív vagy negatív értékeket listázni nekem. Én azt szeretném elérni, hogy soronként haladva megvizsgáljuk a számla és a tranzakció oszlopokat is és ha a tranzakció üres akkor semmi gond, csak hozzáadjuk az összeget a számla oszlopban lévő számlához (akár pozitív, akár negatív az összeg), ha viszont van tranzakció, akkor (a biztosan pozitív) összeget ki kell vonnunk a tranzakció oszlopban szereplő számla egyenlegéből is.
Vagy egy másfajta megközelítésben szummázzuk az összegeket a számla oszlop szerint, majd kivonunk minden összeget a tranzakció oszlop alapján. És ennek vesszük a rendezett nézetét.
A két lekérdezést külön-külön már össze is raktátok nekem, ezért ezer hála, de a végső megoldást még nem lelem.
A Jézuska megérkezett közben, Boldog Karácsonyt -
#3635
Apollo17hu
őstag
BeeGee2115
#3634
Apollo17hu
őstag
válasz
BeeGee2115
#3634
üzenetére
Így?
SELECT szamla,
SUM(CASE WHEN osszeg > 0 then osszeg ELSE 0 END) pozitiv,
SUM(CASE WHEN osszeg < 0 then osszeg ELSE 0 END) negativ
FROM adatok
GROUP BY szamla -
#3634
BeeGee2115
csendes tag
tm5
#3633
-
#3633
tm5
tag
BeeGee2115
#3632
tm5
tag
válasz
BeeGee2115
#3632
üzenetére
Szerintem nem kell rögtön táblát léterhozni ehhez, mert akkor minden Adatok tábla módosítás (insert/update/delete) után frissítened kellene a Számlák táblát.
Bőven elég egy lekérdezés:SELECT szamla, SUM(osszeg)
FROM adatok
GROUP BY szamlaMondjuk ez negatívval nem tartalmazza azt amikor az egyik számláról mozog a pénz a másikra. Ahhoz az kellene, hogy hozz létre egy negatív sort a "from" számlához is amikor onnan átkerül pénz a másikra.
-
#3632
BeeGee2115
csendes tag
BeeGee2115
csendes tag
Sziasztok!
Adott egy Synology DS, amelyen phpMyAdmin és mögötte MariaDB10 leledzik.
Ebben létrehoztam egy adatbázist, amiben pedig egy csodaszép adattáblát több ezer sorral. Gyönyörűen mennek a lekérdezések, és bár kezdőnek számítok az SQL-ben, egész hamar kiismertem magam ebben a világban. Azonban most szükségem lenne a ti tudásotokra!Az alapok a problémához:
Adatok tábla tartalmazza a következő oszlopokat (többek között):
..., Számla (egy számla neve varchar 255 NOT NULL), Összeg (a pénzösszeg double NOT NULL), Tranzakció (egy számla neve varchar 255), ...Létezik nagyjából 12 féle különböző számla. (Készpénz, Bankkártya... stb).
Az adatbázis soraiban a következő szabályok élnek:
- A számla oszlop sohasem lehet üres
- Az összeg lehet pozitív vagy negatív (bevétel vagy kiadás)
- A tranzakció oszlopban csak akkor szerepel számlanév, ha egyik számláról mozgatunk át összeget a másikra, de ebben az esetben az összeg csak pozitív lehet (mert a mozgatás iránya kötött: Tranzakció -> Számla)Szeretnék egy lekérdezést/nézetet/másik táblát (tökmindegy), ahol az első oszlopban a lehetséges Számla nevek szerepelnek, majd a következő oszlopban az egyenlegek, amik ezzel az agyafúrt logikával számolódnak.
Magamtól odáig jutottam, hogy SELECT DISTINCT-el létrehoztam egy `Szamlak` táblát és abban egy Számla és egy Egyenleg oszlopot, ahol az Egyenleget így UPDATE-elem:
UPDATE `Szamlak` SET `Szamlak`.`Egyenleg` = (SELECT SUM(`Adatok`.`Összeg`) FROM `Adatok` WHERE `Adatok`.`Számla` = `Szamlak`.`Számla`) - (SELECT SUM(`Adatok`.`Összeg`) FROM `Adatok` WHERE `Adatok`.`Tranzakció` = `Szamlak`.`Számla`);
Ez már majdnem jó, de azoknál a számlaneveknél, ahol szóköz van, egyszerűen nem számol semmit, az érték 0 marad...

Előre is köszönök minden tippet, segítséget!
-
bambano
titán
-
#3629
bambano
titán
Jimi Tudeski
#3628
bambano
titán
válasz
 Jimi Tudeski
#3628
üzenetére
Jimi Tudeski
#3628
üzenetére
én valami ilyesmit írnék:
select a1.* from autok a1, autok a2 where a1.rendszam<a2.rendszam and abs(a1.ar-a2.ar)<=10000;én meg sosem dolgoztam oracle-vel
-
#3628
 Jimi Tudeski
csendes tag
Jimi Tudeski
csendes tag
Jimi Tudeski
csendes tag
Sziasztok!
Holnapra kéne az unokaöcsémnek, én már rég nem dolgozok oracleben, ha valaki holnap reggelig megmondaná akkor nagyon nagyon megköszönném...
Listázd ki azon autók rendszámát, amelyek beszerzési ára legfeljebb 10000 forinttal tér el egy másik autó beszerzési árától!
Vigyázz arra, hogy saját magukhoz ne hasonlítsd az autókat!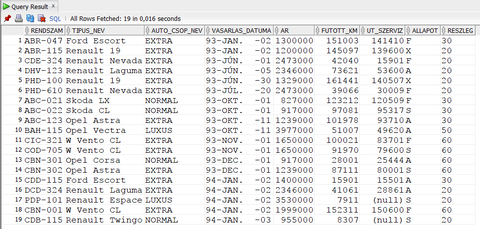
-

Szmeby
tag
válasz
 bandi0000
#3624
üzenetére
bandi0000
#3624
üzenetére
Szevasz,
én nem tudom elmagyarázni, de az biztos, hogy az iskolán kívül nem kell először kettesbe, majd hármasba forgatni, hanem a cél, hogy minél előbb kellően normalizált legyen az a DB, és gyorsan szállítsuk a megrendelőnek, mert már tűkön ül, hogy miért nincs még kész.
2NF
Ha eltekintünk attól a ténytől, hogy a valóságban egy gyerek több általánosba is járhat, és a példánál megszabjuk, hogy márpedig nem járhat, akkor nyilvánvalóvá válik, hogy egy gyerek csak egy általánosba jár, így a középiskolás kiszervezésével meg is van a 2nf. Gondolom. Mivel a gyerek önmagában meghatározza az általános iskolát is. Amiből csak egy lehet, mint ahogy korábban megszabtuk. Míg középsuliból több is, így szükségessé válik a gyerek duplikációk megszüntetése. Amit egy szuper kis kapcsolótáblával oldunk meg. Így 1 tanuló csak egyszer fog szerepelni a tanulók táblában, mert már nincsenek ott azok a csúnya középiskolák, amelyek megduplázták (megtöbbszörözték) a sorok számát.3NF
Viszont azt is látjuk, hogy ez még nem elég, mert ugyan a gyerekek már egyediek, de a Csillagvár bizony kétszer is feltűnik, két gyerek is ugyanoda jár. Ez nagy pazarlás, minden gyereknél nyilvántartani ugyanannak a sulinak a címét. Mi van, ha a suli elköltözik? Vagy kedves vezetőnk átnevezi az utcát, mert ahhoz van kedve? Elkezdjük tömegesen átírogatni a tanulók tábláját azért, mert az iskola adataiban valami megváltozott? Ha kézzel kellene átírnod, neked se lenne természetes a mosolyod egy néhány tízezres tanulóbázis esetén. Mennyivel egyszerűbb lenne 1 helyen átírni a suli címét, és az automatikusan az összes adott suliba járó gyerekre igazzá válna. Hát ezért szervezzük ki az általános iskolát is külön táblába. Felhívnám a figyelmet, hogy ez esetben egy-több a kapcsolat, így a kapcsolótábla szükségtelen.Összefoglalva: Úgy látom, a 2NF arra jó, hogy a sok-sok duplikált SOROK számát csökkentsük le. A tanulók táblában a tanulók a fontosak, vagyis a cél, hogy soronként különböző tanulókat lássunk. Ne szerepeljen két sorban ugyanaz a tanuló. A 3NF pedig arra jó, hogy az adott táblában található kiegészítő (értsd: a tanuló személyéhez nemigazán tartozó) ADATOK ne szerepeljenek feleslegesen többször, mert ha azokat át kell írni, az halál.
Hogy mi az, ami nem tartozik a tanuló személyéhez? Azt érezned kell. A neved például a tiéd, a születési dátumod is a tiéd, mivel az nem változhat, vagy ha változik, akkor te is változol vele. A lakcímed pl. nem a tiéd, mert simán elköltözhetsz, és más költözhet a te címedre. A sulid sem a tiéd, mert rajtad kívül sokan mások is abba a suliba járnak, még a mobilod sem a tiéd, mert bármikor lecserélheted, másnak adhatod. Ami nem a tiéd, nem a téged nyilvántartó táblába tartozik, hanem egy másikba.
Persze megfontolás kérdése, ha csak az iskola nevét akarjuk a tanulónál tárolni, akkor még akár maradhat is a tanuló táblában. Nem szép, de van olyan helyzet, amikor ez a hatékonyabb. De ha mondjuk a suli neve mellett a suli címe is nyilvántartásra kerül, meg a suli alapításának éve, meg az ott dolgozó tanárok száma, stb stb... Azt már nehéz megmagyarázni, hogy a suli alapításának éve mit is keres a tanulók nyilvántartásában. A gyereknek semmi köze hozzá, mikor alapították az iskolát. Szóval ha már ilyen kacifántos tranzitív függőségeket látsz, akkor szólaljon meg benned a csengő, hogy ez külön táblát kíván.Lehet, hogy mégis sikerült elmagyarázni?
 Az okosok javítsanak ki, ha hülyeséget írtam.
Az okosok javítsanak ki, ha hülyeséget írtam. -

bandi0000
nagyúr
sziasztok
nem biztos hogy pont ide, de hátha valaki tudna segíteni
Most vettük az adatbázis normalizálást, és nem tudná elmagyarázni valaki konyha nyelven a 2.-3. normál formákat, értem nagyjából a fogalmat, de nem látom hogy azt hogyan tudom rá húzni egy egyszerű adatbázisra, hogy rögtön lássam, mit kell ki rakni külön táblába
pl itt se nagyon értem, hogy 2NF-nél kiszedte a közép iskola címét nevét, de az általános címe,neve benne maradt, és azt csak a 3NF-be szedte ki
-
nyunyu
félisten
-

Pé
senior tag
Sziasztok. Kéne gyorsan írnom egy MS SQL scriptet, de nem értek hozzá, és az istennek nem akar működni.
Feladat: egy szerver összes adatbázisában van egy tábla, ahonnan a usereket ki kéne listázni. Ez eddig rendben is van, működik. Viszont szeretném a db nevét berakni az első oszlopba. Ez sehogy sem sikerülA script:
SET NOCOUNT ON
DECLARE @sql varchar(max) = ''SELECT @sql = @sql + CASE @sql when '' then '' else ' UNION ALL ' end + '
SELECT '+dbs.name+' AS Tenant
,[AU_CODE]
,[AU_STATE]
,[AU_PASSWD_VALIDITY]
,[AU_PASSWD_NEVER_EXPIRE] FROM [' + dbs.name + '].[dbo].[ACCESS_USER]'
FROM sys.sysdatabases dbs
WHERE dbs.name NOT IN ('master', 'tempdb', 'msdb', 'model')EXEC(@sql)
A SELECT '+dbs.name+' AS Tenant sorral van a gebasz. Nem tudom hogy hogy lehet az aktuális db nevét oda belerakni.
-

updog
őstag
A válasz: attól függ
Ha DATE típusú a meződ, és indexált, akkor nyilván ha egy DATE-tel hasonlítod össze (TO_DATE), akkor végigrohan az indexen és kidobja amit keresel.Ellenben ha ezt a meződ TO_CHAR-ozod, nem fogja tudni használni az indexet. (pl.) Oracle-ben itt lehet csavarni egyet a dolgon function based indexszel, csinálhatsz olyan indexet, ami nem a mezőt, hanem a TO_CHAR(mező)-t indexeli, akkor ugyanolyan gyors lesz.
Amúgy ha nem lenne index a mezőn, kb. mindegy lenne performancia szempontból, praktikusan a TO_DATE(feltétel)-t szokták használni, ha a mező DATE.
(#3618) -Zeratul- jepp.
 Egyszer én is futottam egy hasonlóba (DATE mezőn volt index, és TO_CHAR-ozták, hogy egy string-gel összehasonlítsák... Mekkora volt az öröm mikor mutattam hogy 500%-os performancia javulás történt, miután átírtam
Egyszer én is futottam egy hasonlóba (DATE mezőn volt index, és TO_CHAR-ozták, hogy egy string-gel összehasonlítsák... Mekkora volt az öröm mikor mutattam hogy 500%-os performancia javulás történt, miután átírtam -
bpx
őstag
Az első változatot irtani kell.
Nem az átalakítás a nagy munka, hanem az, hogy ha index van az oszlopon, akkor az tipikusan a tábla.dátum_mező-re van, és nem pedig a to_char(tábla.dátum_mező...)-re, így a lekérdezés nem tudja használni az indexet, teljes táblát olvas, lassú. Persze lehet function based indexet létrehozni a to_char(tábla.dátum_mező...)-re is, de erre az esetre nem ez a helyes megoldás.
Ezen kívül az ilyen átalakításoknál az optimizer számosságbecslései is pontatlanak lehetnek, hiszen dátum típusnál tudja, hogy pl. 2017-01-01 előtt a 2016-12-31 van, de ha ugyanezt stringként kell becsülni, akkor olyan értékek is lehetségesek, amelyek dátumnál nem, pl. 2017-00AAAAAA, 2016-999990000, stb.
-
varsam
őstag
Sziasztok,
szerintetek melyik gyorsabb?
TO_CHAR(tábla.dátum_mező,'YYYY.MM.DD.') >= '2017.11.01.'
--vagy
tábla.dátum_mező >= TO_DATE('2017.11.01.','YYYY.MM.DD.')
Én azt mondanám, hogy a második egyértelműen, mivel az első először minden értéket characterré alakít át majd utána szűr, a másik pedig egy rendes dátum szűrés.
Kollégánál láttam az elsőt, érdekelne, hogy mennyivel lehet az lassabb? -
nyunyu
félisten
válasz
bandi0000
#3614
üzenetére
Úgy több-több a kapcsolat, hogy egy vásárló több eladótól is vehet (az mindegy, hogy mikor), de egy eladó termékeit is több vevő veheti.
Labor házidra ugyanez igaz, egy ember több fodrászhoz is foglalhat időpontot, de egy fodrásznak is több vendége van egy nap, és ezek egymástól függetlenek.
Minden egyes tranzakció egy új rekord lesz a foglalásos táblában.
-
-
nyunyu
félisten
válasz
bandi0000
#3612
üzenetére
N:M reláció:

Jól látod, foglalásnak külön tábla kell 4 oszloppal:
- foglalt termék idegen kulcsa
- foglaló vevő idegen kulcsa
- foglalás ideje
- foglalás áraMajd az itt tárolt külső kulcsokkal joinolod össze a foglalót a foglalt termékkel.
[szerk:]Céges feladat? Ez inkább egy állásinterjúhoz szakmai beugrónak tűnik, amit fél délután össze lehet rakni.
-
bandi0000
nagyúr
adatbázisban tudnátok segíteni?
céges feladatot aminek leírása itt van, viszont nem igazán jutunk dűlőre, miszerint van egy foglalás táblánk, ahol tároljuk a foglalás időpontját, a foglaló nevét, és a szolgáltatást, meg van egy szolgáltatás táblánk ahol gyakorlatilag a szolgáltatások neve, ideje, ára van, és ha minden igaz, akkor a kulcsok a szolgáltatások neve, elküldtük a tervet a cégnek, de olyasmit írtak vissza, hogy több a többhöz kapcsolat legyen a két tábla között, amit nem értünk, mert 1 szolgáltatás tartozhat több foglaláshoz, de fordítva talán csak úgy, ha úgy tárolnánk a foglalást, hogy 1 mezőbe több szolgáltatást is felsorolnánk nem?mert mi úgy gondoltuk a tárolást, hogy ha egyszerre többet akarnak foglalni, akkor egymás után tároljuk szolgáltatásonként, illetve egyedi kezdési dátummal, tehát egymás után
-
Fundiego
tag
végül máshogy oldottam meg, mivel tudni lehet h milyen értékeket vehet fel.azonban problémába ütköztem, mert rangsorolni akarom a lent látható kód szerint sum(pont) etc etc. viszont a rank függvényem abc szerint ad számot a sornak, hova kellene rakni a függvényt?
SELECT pilota ,IFNULL(SUM(Pont),0) AS 'Pontok',(@row_number:=@row_number + 1) AS sorszam,
COUNT(*),
SUM(CASE WHEN vegeredmeny = '1' THEN 1 ELSE 0 END) as egy,
SUM(CASE WHEN vegeredmeny = '2' THEN 1 ELSE 0 END) as ketto,
SUM(CASE WHEN vegeredmeny = '3' THEN 1 ELSE 0 END) as harom,
SUM(CASE WHEN vegeredmeny = '4' THEN 1 ELSE 0 END) as negy,
SUM(CASE WHEN vegeredmeny = '5' THEN 1 ELSE 0 END) as ot,
SUM(CASE WHEN vegeredmeny = '6' THEN 1 ELSE 0 END) as hat,
SUM(CASE WHEN vegeredmeny = '7' THEN 1 ELSE 0 END) as het
FROM futam
WHERE ev='2016'
GROUP BY pilota
order by sum(pont) desc,egy desc, ketto desc, harom desc, negy desc, ot desc, hat desc, het desc -
bpx
őstag
select * from (
select * from (
select
pilota, sum(pont) over (partition by pilota) as sum_pont,
vegeredmeny,
row_number() over (partition by pilota order by vegeredmeny) rn
from futam) where rn <= 4
) pivot
(min(vegeredmeny) for rn in (1 as er1, 2 as er2, 3 as er3, 4 as er4))
order by sum_pont desc;De szerintem MySQL lesz a kérdés.
-
nyunyu
félisten
válasz
Fundiego
#3600
üzenetére
Ablakozó függvénnyel beszámozod a pilótánkénti helyezéseket, majd leválogatod, melyik lett az első, második, harmadik?
Oracle alatt valami ilyesmi lenne:
with eredmeny
as (select id,
ev,
vegeredmeny,
pilota,
pont,
row_number() over (partition by ev, pilota order by vegeredmeny, id) eredmeny
from futam)
SELECT e.pilota,
SUM( e.pont ),
e1.vegeredmeny er1,
e2.vegeredmeny er2,
e3.vegeredmeny er3,
e3.vegeredmeny er4
FROM eredmeny e
join eredmeny e1
on e1.ev=e.ev
and e1.pilota=e.pilota
and e1.eredmeny=1
join eredmeny e2
on e2.ev=e.ev
and e2.pilota=e.pilota
and e2.eredmeny=2
join eredmeny e3
on e3.ev=e.ev
and e3.pilota=e.pilota
and e3.eredmeny=3
join eredmeny e4
on e4.ev=e.ev
and e4.pilota=e.pilota
and e4.eredmeny=4
WHERE e.ev = 2017
GROUP BY e.pilota,
e1.vegeredmeny,
e2.vegeredmeny,
e3.vegeredmeny,
e4.vegeredmeny
ORDER BY SUM( e.pont ) DESC;






















![;]](http://cdn.rios.hu/dl/s/v1.gif)





























 amikor a tanárral megbeszéljük akkor tök érthető, de majd gyakorolgatok hátha jobban bele jövök
amikor a tanárral megbeszéljük akkor tök érthető, de majd gyakorolgatok hátha jobban bele jövök 




 Egyszer én is futottam egy hasonlóba (DATE mezőn volt index, és TO_CHAR-ozták, hogy egy string-gel összehasonlítsák... Mekkora volt az öröm mikor mutattam hogy 500%-os performancia javulás történt, miután átírtam
Egyszer én is futottam egy hasonlóba (DATE mezőn volt index, és TO_CHAR-ozták, hogy egy string-gel összehasonlítsák... Mekkora volt az öröm mikor mutattam hogy 500%-os performancia javulás történt, miután átírtam 


Új hozzászólás Aktív témák
- Xbox One S (1TB) lemezes eladó!
- Dell XPS 13 9310 i7-1185G7 16GB 512GB 13" FHD+ 1 év garancia
- Samsung Galaxy S24 Ultra 512GB,Újszerű,Dobozaval,12 hónap garanciával
- Lenovo IdeaPad Slim 3 Ryzen 7 8840HS 15" FHD+ 16GB 1000GB Teljeskörű garancia
- Dell Precision 3571 i7-12700H 32GB 1000GB FHD RTX T600 4GB 1 év teljeskörű garancia
- 3év! AKCIÓ! ÚJ ASUS TUF GAMING Geforce RTX 5080 OC Edition 16GB VRAM Ray Tracing DLSS4
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5700X 16/32/64GB RAM RX 7600 8GB GAMER PC termékbeszámítással
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7600X 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- Lenovo ThinkPad L13 Gen 3 i5-1245U FHD+ 16GB 512GB 1 év teljeskörű garancia
- Apple iPhone 13 128GB, Kártyafüggetlen, 1 Év Garanciával
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest