Hirdetés
- sziku69: Fűzzük össze a szavakat :)
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- sziku69: Szólánc.
- Luck Dragon: Asszociációs játék. :)
- Hieronymus: Hogyan parkolj hátramenetben profi módon
- vrob: Próbálkozás 386 alaplap újraélesztésre
- bambano: Bambanő háza tája
- gban: Ingyen kellene, de tegnapra
- Luck Dragon: MárkaLánc
- Luck Dragon: Óraátállítás
Új hozzászólás Aktív témák
-
-

Magnat
veterán
Üdv,
Mysql-ben van egy kis függvényem, ami egy adott mezőre (eladas_sum_brutto) végez műveleteket (lényegtelen, h mit) és ebből ad vissza egy értéket. (Bemenő paraméter az eladás id.)
Viszont jó lenne univerzálisra megcsinálni a függvényt úgy, h ne csak erre a mezőre lehessen meghívni hanem pl az eladas_sum_netto-ra is. Így azt találtam ki, h csinálok egy általános függvényt, aminek a második paramétere a mezőnév, amire az adott műveletet el kell végezni és egy változóba összerakva a lekérdezést dinamikus sql-lel futtatnám meg a PREPARE, EXECUTE, DEALLOCATE trió segítségével, csakhogy mint kiderült, a mysql nem támogatja a dinamikus sql-t tárolt eljárásban/függvényben, illetve triggerben.Van valakinek 5lete esetleg, hogyan tudnék egy sztringet (amiben a select össze van rakva a paraméterként kapott mezőnévvel) sql parancsként futtatni tárolt függvényben vagy muszáj lesz minden érintett mezőre külön megcsinálni a függvényt (vagy egy függvényben case-szel külön selecteket futattni attól függően, h mi a mezőnév paraméter)?
-

nyunyu
félisten
Általában igyekszem szabványos SQLül írni, de van amire nincs szabvány, és ahány DB, annyiféle szintaxis létezik rá.
Ilyen a maradékos osztás is.Meg úgysem a pontos szintaxis a lényeg, mert azt viszonylag könnyen át lehet írni egyik DB dialektusról a másikra, hanem a mögöttes logika.
-
nyunyu
félisten
Valami ilyesmire gondolsz?
Hogy itt is megmaradjon:
with nev_lista as
(select nev,
--row_number() over (order by nev asc) id,
mod(row_number() over (order by nev asc)-1,10) oszlop,
trunc((row_number() over (order by nev asc)-1) / 10) sor
from nevek)
select *
from nev_lista
pivot(
max(nev)
for oszlop
in (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
)
order by sor;SQL szeret mindent 1-től számozni, ez most nekünk nem praktikus, ezért van a sorszám-1 osztva 10-zel.
Melóhelyen szórakoztattam egyszer magamat azzal, hogy az időzített jobokat vezérlő táblából (id, folyamatnév, melyik_nap, kezdő_idő, vége_idő) rajzoltam heti naptárat negyedórás bontásban, az jóval nagyobb szopás volt

Pláne, hogy éjfélen túlnyúló folyamataink is vannak
-

Louro
őstag
válasz
 sztanozs
#5790
üzenetére
sztanozs
#5790
üzenetére
Sajna van egy olyan társosztály, akik adattáblából dolgoznak. Kb. a jobbklikk->select top 100 rows funkciót ismerik. Próbáltam, hogy kiexportálom nekik és dolgozzanak Excelből, így nem kellene felesleges telepíteni ssms-t nekik. De fafejű a főnökük és a "régen is így csináltuk és működött" elvet követi :/
Mivel van egy igényük van és én hülye mondtam, hogy sokat kell görgetni és a képernyő nagy része kihasználatlan, akkor dobjuk be 10 oszlopba és már talán görgetés nélkül ott lesznek nekik, amik kellenek.
Sajnos a hülye vezetőkkel ellen én kevés vagyok.
-
Louro
őstag
Sziasztok!
Egy érdekes kérdéssel jönnék. Tuti van valami jobb megoldás, ami nekem beugrott.
Adottak listák. A listák 50-100 eleműek. Azért, hogy ne kelljen a kedves felhasználóknak sokat görgetniük, 10 oszlopban felsorolni.Példa: legyen a lista 22 elemű.
1 - 2 - 3 - 4 - 5 - 6 - 7 - 8 - 9 - 10
11 - 12 - 13 - 14 - 15 - 16 - 17 - 18 - 19 - 20
21 - 22Én arra gondoltam, hogy adok egy row_number()-rel sorszámot. Majd megnézem, hogy mod 10 mennyi. Így meglehetne, hogy melyik melyik oszlopba kerül. Majd egy újabb lépésben adok neki "sorszámot". Így már tudnám pivotálni. De gyanítom, hogy túlontúl túlbonyolítottam egy egyszerűnek tűnő feladatot.
Környezet: sql server 2016.
-
#5788
 tm5
tag
rednifegnar
#5787
tm5
tag
rednifegnar
#5787
tm5
tag
válasz
 rednifegnar
#5787
üzenetére
rednifegnar
#5787
üzenetére
Juj, hát én ezeket nagyon hamar elkezdeném automatizálni, pl. Powershell scriptekkel. Vagy ha a cég elég nagy akkor valami rendes workflow manager szoftvert vetetnék, pl. BMC Control-M, vagy bármi ahol ezek a lépések, mint egy job, lefut ha tud és elhal ha nem. Akkor kijavíthatod és újrafuttathatod a jobot.
Én nem bírnám sokáig ezt kézzel managelni... -
#5787
 rednifegnar
senior tag
Ispy
#5786
rednifegnar
senior tag
Ispy
#5786
rednifegnar
senior tag
tobb fele mukodes van. altalaban van egy verzio x db fajlal (es persze van olyan hogy sok verziot kell huzni), x = 1-tol akar szazas mennyiseg.
ha nem sok a file akkor lefutattjuk kulon-kulon oket, de nyilvan egy fajl eleve tartalmaz sok utasitast (ezek vegyesen lehetnek minden felek: struktura modositasok, adatamodositasok, kulonfele programreszek mint tarolt eljarasok, triggerek stb). ha barhol hiba van le kell allni.
masik megoldas amikor soxor elofordul hogy ossze vannak mergelve egy db sql fajlba es az van lefuttatava.harmadik amikor egy fo fajl futtatja a kulonallo fajlokat.
megspekelve azzal hogy rendszerint tobb db is van egy egy ugyfelcsoportnal, lehet onallo dbk is meg semaban is kinek hogy van megrendelve konfigolva (ez ugye it fuggo is).
az mindig fontos hogy ha hiba van barhol akkor le kell allni es megnezni mi okozta, aztan azt kinyomozni korrigalni es utana folytatni (mondjuk ezen mar elhasal ez a nyamvadt management studio).
a dolgot cifrazza hogy meg tobbfele db kezelot is kell hasznalni, egyik kozuluk az mssql, es lehetoleg minel fuggetlenebbre kell mindent megirni hogy kezelheto maradjon minden (sql es programkod szinten is). -
#5786
 Ispy
nagyúr
rednifegnar
#5785
Ispy
nagyúr
rednifegnar
#5785
Ispy
nagyúr
válasz
rednifegnar
#5785
üzenetére
Mit akarsz futtatni? Különálló batcheket egyben, vagy.egy batchen belül akarsz hibát kezelni?
-
#5785
rednifegnar
senior tag
Ispy
#5784
rednifegnar
senior tag
igen talan az is lehet egy modszer de szeretnem minel egyszerubben (egysegesebben) tartani a scriptjeket, ezert nem annyira szeretnem teleirni ilyenekkel. igy is eleg szopo tobb szaz scriptet kulon kezelgetni mert o maskepp mukodik.
most megint nekifutottam a net turasnak. olybá tunik hogy az sql command modban
a:on error [ignore|exit]nagyjabol ezt csinlaja. meg ha nem is olyan kulturalt modon mint mas isql-ekben, de legalabb megall hibanal. ami a gond hogy az sql command modot mindig kulon be kell kapcsolni, azt nem lehet script elejere beirni. plusz azt irjak lehet eltero futasi eredmenye a normal modhoz kepest. de meg nezegetem mikkel kell szamolni.
utobbi 1-2 evben kell komolyabban parhuzamosan mssql-re is dolgzonom es hat nem lettem egy mssql fan... -
#5784
Ispy
nagyúr
rednifegnar
#5783
Ispy
nagyúr
válasz
rednifegnar
#5783
üzenetére
try catch? azon belül ha kell berakod tranzakcióba, ha meg catchre fut, rollback
-
#5783
rednifegnar
senior tag
rednifegnar
senior tag
hi, van szerencsem egy ideje mssql-el ugykodni ( = kinlodni)..

sajnos olyan alapszintu dolgokba futok bele ami mas rendszereken 20 eve nem gond, itt meg csak nezek mint bornyu ama kapura.
van egy gondom amin nehezen tudok tullendulni, nyilvan turtam a netet is.
management studioban (18.12.1) van e valami primko modszer a query editorban (isql) ugy futtatni utasitasokat hogy az elso hibasnal alljon meg? ez egy orulet hogy szalad tovabb mint valami fekevesztett valami.
nem igazan szeretnek vegtelen kodot koriteni az sql-jeimbe. sot leginkabb semmilyet, mivel tobb sql kezelore is dolgozom ugyanazzal a db strukturaval es marhara cumi hogy minden masnal ez frankon beallithato ennel meg nem.
probaltam az sqlcmd modot, de valahogy nem lattam hatasat. lehet en nem tudok valamit mert teny hogy nem vagyok egy mssql szaki de valahogy ebben mindennel szopi van.
-

lanszelot
addikt
válasz
 nevemfel
#5779
üzenetére
nevemfel
#5779
üzenetére
kőzben adódott egy probléma.
Feltettem a linkről amit küldtél a full verziót, mert csak a developer volt fent, és gondoltam hátha.
Ahhoz a python-t is fel kellett rakni.
És valamit elállított valamelyik a gépemen /win10pro/, mert most display porton nincs hang.
Tehát a monitorom néma.
Letöröltem a python és mysql -t egyesével, és újra raktam a legfrissebb nvidia drivert tiszta installal.
De így sincs hang.
Volna valami ötlet mit állított el a telepítő? -
-
lanszelot
addikt
válasz
nevemfel
#5777
üzenetére
Ez a hiba üzenet:
"Fatal error: Uncaught Error: Class "mysqli" not found in D:\_Munka\WebMunka\php\mysqltest.php:7 Stack trace: #0 {main} thrown in D:\_Munka\WebMunka\php\mysqltest.php on line 7"ez a kod:
/username-t és password-t beírtam, servername az maradt localhost, oda nem tudom mi kell/<?php
$servername = "localhost";
$username = "username";
$password = "password";
// Create connection
$conn = new mysqli($servername, $username, $password);
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
echo "Connected successfully";
?> -

nevemfel
senior tag
válasz
 lanszelot
#5776
üzenetére
lanszelot
#5776
üzenetére
1. Ellenőrizd, hogy fut-e a mysql service. Service controllban vagy a task managerben könnyen leellenőrizheted..
2. phpinfo()-val írass ki mindent. Ellenőrizd, hogy a php betölti-e a pdo, pdo_mysql extensionöket.
3. Nézd meg, hogy parancssorból, a mysql parancssori klienssel lokálisan tudsz-e csatlakozni a szerverhez.
4. Kíváncsi lennék a kódra, amit próbáltál, és a hibaüzenetre, amit kaptál, hogy pontosan hogy is nézett ki ez. -
lanszelot
addikt
válasz
nevemfel
#5775
üzenetére
Először is köszönöm szépen a választ.
A kérdés inkább az volt hogy hogyan állítom be, hogy az apache server lássa.
Mert ha php -ban server névnek localhost -ot adok "create connection" nem működik.
Tehát valahol valamit be kell állítani.
De mit és hol? /Mysql, php, apache ?/ -
lanszelot
addikt
Hello,
Gépemen fent van a PHP és az Apache server. A mysql-t szeretném feltenni, de ha felteszem hogy állítom be hogy az Apache server lássa? Tehát hogy futtatni tudjam a mysql -t, és használni.
Mindenki a wamp -ot pakolja. Én azt nem teszem fel.
Nekem így külön kell, de erről sehol se találok videót, hogy hogyan.
Angol tutorial is jó lenne. -
A SAP-ból szerintem nem fogjátok tudni máshogy kinyerni, de nem vagyok 100%-ig biztos benne. Nálunk szerencsére file-okat pakolnak le és mi töltjük be SQL adatbázisba, így már a betöltő tárolt eljárásban elvégezzük a szükséges transzformációkat.
Egyébként a feltöltést követően csak egy plusz update sort kellene futtatniuk, ami az összeg mezőn elvégzi a szükséges konverziót.
-

Lokids
addikt
A problémám az, hogy a kapott adatot nem én tárolom le, hanem az SAP kapott hozzáférést a táblához és ők töltik fel.
Én már csak a feltöltött táblához férek hozzá. Így nem tudok konverziót végezni. De megpróbálom rávenni a küldő oldalt, hogy ezt tegyék meg. Nekik semmiből sem tartana ezt is beleírni még.
Így nem tudok konverziót végezni. De megpróbálom rávenni a küldő oldalt, hogy ezt tegyék meg. Nekik semmiből sem tartana ezt is beleírni még.Köszönöm a segítséget mindenkinek!
-
Fentebb írták, hogy amikor lekérdezésnél hivatkozol a mezőre, akkor pontot cseréld semmire, a vesszőt pedig pontra, utána már tudod használni a decimalt.
select cast(replace(replace(szám, '.', ''), ',' , '.') as decimal(8,2))
Ha elb...tam a szintaxist, akkor sorry, csak már alig látok.
Tárolod is a kapott adatokat? Ha igen, akkor az átalakítást érdemes a letároláskor elvégezni, hogy a későbbiekben a lekérdezésnél ne kelljen átalakítani, így az gyorsabban fog futni.
Én is szoktam szívni ezzel SAP-ból kapott adatoknál, főleg ha EUR és HUF vegyesen van...
-
nyunyu
félisten
Nem lehet állítani az IDEdben, hogy milyen területi beállításokkal értelmezze/jelenítse meg a számokat/dátumokat?
Gondolom az SQL Management Studioban is állítható, nem csak az SQL Developerben.
Meg mire van állítva a szerver? (SQLPlus pl. a szerver beállításait használja)
-
Ispy
nagyúr
Win, területi beállítások, tizedes és helyiérték beállíások. Az ezeresnél van egy pont, a tizedespont meg egy vesző. Gondolom az sql szerver más beállítássokkal megy, nem ámerikái.
Nekem 123.47-et ad vissza, ha kiveszem a pontot, akkor meg kerekít. Szövegként nem is tudom konvertálni, mert nem ismeri fel, mint szám.
Vagy replace-szel kiveszed a pontot, a vesszőből meg pontot csinálsz a convert előtt.
-
nyunyu
félisten
Jim74 válaszát kiegészítve, hogy a példádat adja ki:
select t1.NAME,
coalesce(t2.Created_date, 'NINCS') Created_date,
coalesce(t3.Description,'NINCS') Description
from tabla_1 t1
left join tabla_2 t2
on t2.ID = t1.ID
left join tabla_3 t3
on t3.ID = t2.ID2
where t1.NAME in ('A','B','C','D','E','F','G')
order by t1.NAME;(Eredetileg nvl()-lel akartam írni, de az Oracle specifikus függvény, ahogy az isnull() SQL Serveres, egyik sem szabvány SQL.
Coalesce() az elvileg szabványos, minden DBben működnie kéne.) -
Pontosítok, tabla_1-ből minden jön, a többiből, ahol van találat, de ahol nincs ott is megjelenik a tabla_1 rekordjai, csak a többi táblából megjelenített érték azokon a sorokon NULL érték lesz.
Ha a NULL kiírás nem megfelelő, akkor az ISNULL függvénnyel tudod tetszőleges értékre cserélni.
Pl. ISNULL(t2.Created_date, 'NINCS')
Ekkor, ha a tabla_2-ben nincs tabla_1 ID-hez kapcsolható rekord, akkor a Created_date oszlopban a NULL érték helyett NINCS érték fog megjelenni. -
Szia!
Nem ölünk meg senkit, aki nem sql pro
. Azért van a fórum, hogy segítsünk, tapasztalatot osszunk meg. Én is csak a felszínt kapargatom és még élek. select * from tabla_1 t1
left join tabla_2 t2 on t1.ID = t2.ID
left join tabla_3 t3 on t1.ID = t3.IDBocs a formázásért telefonról vagyok.
Elvileg így minden sor lejön minden táblából és ahol nincs találat, ott NULL értékeket fogsz kapni.
Ha rosszul értelmeztem az igényt, akkor sorry. -
Sziasztok,
van egy kérdésem. Megpróbálom egy kis példával szemléltetni, mert leírni nem tudom. Légyszi ne öljetek meg nagyon, nem vagyok nagy SQL mágus, kisebb lekérdezésekkel elboldogulok, és ennyi, de szívesen tanulok

Adott 3 tábla, benne adatok. Lehetnek benne más adatok de azok nem relevánsak.
tabla_1ID NAME1 A2 B3 C4 D5 E6 F7 G8 Htabla_2ID Created_date ID21 2022.01.01 112 2022.01.01 183 2022.01.02 314 2022.01.02 555 2022.01.01 776 2022.01.03 110tabla_3ID Description11 Alma55 Körte77 Szőlő110 Répa
Az adatok amiket le kell kérdezni: A, B, C, D, E, F, GEddig így oldottam meg (tudom ez a fajta join sem a legjobb, de gyors, és hatékony számomra):
select temp2.tempname, temp2.tempid, temp2.id, temp2.id, temp2.created, temp2.id2, t3.DescriptionFROMtabla_3 t3(select temp.name tempname, temp.id tempid, t2.ID id, t2.Created_date created, t2.ID2 id2FROMtabla_2 t2,(select NAME name, ID idFROMtábla3 t3,IDs idswhereids.column1 = tabla_1.name) tempwhretemp.id = t2.id) temp2wheret3.id2 = temp2.id2
A select így lefut (lehet van benne elírás, azért bocs), de csak arra kapok eredményt, ahol mindhárom táblában van találat. Én úgy szeretnék lekérdezést futtatni, hogy ahol nincs eredmény, ott is legyen visszakapott eredményem, mondjuk NINCS, vagy bármi.Pl ilyesmit:
A 2022.01.01 Alma
B 2022.01.01 NINCS
C 2022.01.02 NINCS
D 2022.01.02 Körte
E 2022.01.01 Szőlő
F 2022.01.03 Répa
G NINCS NINCSRemélem érthető amit szeretnék kérdezni, és semmi szentségtörést nem írtam le
-
Fejből példa. Legyenek a bal oszlopban a megrendelés fejek, a jobb oszlopban pedig a pozíciók.
Kulcs:
- OrderNr
Bal oszlop:
- OrderNr
- Date
Jobb oszlop:
- OrderNr
- Part
- Qty
Ezeket kell lekérdezni, és akkor LineNr legyen a pozíció száma, ami nyilván OrderNr-enként újra kezdődik. -

fjanni
tag
Sajnos sem a LAG, sem az EXTRACT függvényt nem ismeri a Mariadb. Egyébként Grafana lekérdezésben használnám, ahol csak azokat a mezőket kellene a selectbe betenni amit ábrázolni is akarok. Azaz ez esetben két adat kellene, az időbélyeg (ami megvan - time) és a számított eltérés az előző rekordhoz képest (a jelenlegi és az előző óraállás különbözete)
-

bandi0000
nagyúr
Sziasztok,
Nagyon amatőr kérdés, adatbázis tervet csinálok, ERDPlus-ban, beadandó, szal nem kell semmi részletesség, viszont nem emlékszek a jelölésre N-1 kapcsolat esetén...
Szóval van pl egy tábla Munkalap és Autók, 1 munkalapon 1 autó, viszont több munkalapon is szereplehet ugyan az az autó. Ebben az esetben a diagramon a több kapcsolat jele a munkalapoknál lesz, és az 1 kapcsolat jele pedig az autóknál, vagy fordítva?
-
Louro
őstag
Én Oracle-ben találkoztam vele először. Bár azóta inkább az sql server mellett tettem le a voksom. Szerintem a legtöbb helyen elérhető.
Én úgy szoktam mondani, hogy ha 1-2 alkalommal kell, akkor performancia sokadlagos. Az eredmény legyen jó. De ha már ütemezett feladat lesz belőle, akkor megnézem a végrehajtási tervet és próbálom keresni a költséges pontokat. -
A napi, heti fogyasztást úgy tudod megoldani, hogy képzel két oszlopot a Time mezőből, az egyikben a napok, a másikban az Év-hetek leszenek (azért nem csak hét, mert több éves adasor esetén a különböző évek ugyanazon heteit nem tudnád megkülönböztetni.
Erre a két oszlopra mar tudod group by-olni a fent kiszámított két Time közötti fogyasztási adatokat.
Ha két időpont között szeretnéd kiszámolni, akkor WHERE feltételben korlátozod az intervallumot. (Where Time between x and y).Nap:
CAST(Time as date) as Datum
Év-hétCONCAT(DATEPART(year, Time), '/' , DATEPART(iso_week, Time)) as Ev_het -
LEAD-del pedig a következő sorokra lehet hivatkozni.

Performancia szempontjából nem tudom, hogy a LEAD/LAG vagy a self join a jobb megoldás, mert sosem teszteltem ezt. Ha vakon kellene fogadnom, akkor a LEAD/LAG-re tennék.
Az is igaz, hogy én csak MS SQL-ben dolgozom, nem tudom, hogy máshol léteznek-e ezek a függvények. -
A LAG fügvénnyel tudsz hivatkozni előző értékekre
LAG(Counter, 1) OVER (ORDER BY Time)
Ez az adott sor előtt időben eggyel lévő sor Counter értékét adja vissza. Ebből kivonod az aktuális sor Counter értékét és megvan a fogyasztás a két időpont között. Ugyanezt be tudod vetni az időre is csak ott Datediff-et használj a két időpont között eltelt idő kiszámításához. -
nyunyu
félisten
select akt.id,
akt.time aktualis_ido,
akt.counter aktualis_allas,
elozo.time elozo_ido,
elozo.counter elozo_allas,
akt.time - elozo.time eltelt_ido,
extract(day from (akt.time - elozo.time)*24*60*60)/60 eltelt_ido_perc,
akt.counter - elozo.counter allas_valtozas,
(akt.counter - elozo.counter)/extract(day from (akt.time - elozo.time)*24*60*60)/60 atlag_fogyasztas
from oraallas akt
left join oraallas elozo
on elozo.id = akt.id - 1
order by id; -
fjanni
tag
Kösz a segítséget, de ez nekem egy kicsit bonyolult, egyszerűbb megoldás nincsen?
Tulajdonképpen nem kell új tábla, csak egy Select ami a táblában lévő adatok mellé kiszámolja az utolsó két oszlopot. Az első három oszlop van a táblában.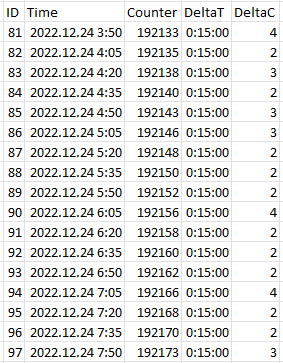
Ha a deltaT és deltaC megvan akkor már Group by-al tudok periódusokra összegezni, csak azt nem tudom kiszámolni hogy mennyi a növekmény.
-
nyunyu
félisten
Sebtében összetákolt Oracle példa:
create table gazora (idobelyeg timestamp, allas number);
insert into gazora (idobelyeg, allas)
values (systimestamp, 70);
insert into gazora (idobelyeg, allas)
values (systimestamp-1, 65);
with oraallas as (
select idobelyeg,
allas,
row_number() over (order by idobelyeg desc) rn
from gazora
)
select akt.idobelyeg aktualis_ido,
akt.allas aktualis_allas,
elozo.idobelyeg elozo_ido,
elozo.allas elozo_allas,
akt.idobelyeg - elozo.idobelyeg eltelt_ido,
extract(day from (akt.idobelyeg - elozo.idobelyeg)*24*60*60)/60 eltelt_ido_perc,
akt.allas - elozo.allas allas_valtozas,
(akt.allas - elozo.allas)/extract(day from (akt.idobelyeg - elozo.idobelyeg)*24*60*60)/60 atlag_fogyasztas
from oraallas akt
join oraallas elozo
on elozo.rn = akt.rn + 1
where akt.rn = 1;CTE-ben megfordítottam a számozás irányát, hogy fixen rn=1 legyen a legutolsó rekord, eggyel nagyobb az eggyel régebbi.
join feltételben lévő on elozo.rn = akt.rn + 1 feltétellel tudsz játszani, hogy hány méréssel korábbi rekordhoz képest akarsz eltérést, átlagot számolni.(interval adattípus miatti típuskonverzióért elnézést, nem lehet értelmesen percre váltani.)
-
nyunyu
félisten
Tetszőleges két időpont közötti: lekérdezed a két időpont közötti rekordokat, és a max(óraállás)-ból kivonod a min(óraállás)-t, max(időbélyeg)-min(időbélyeg) megmondja, mennyi idő alatt, kettőt osztva megvan az átlag.
(Feltételezve, hogy az óraállás monoton nő, és nincs visszatekeréses buhera.)Egy perccel korábbihoz képesti változáshoz meg össze kéne joinolnod az aktuális rekordot az eggyel előzővel, és úgy kivonni az óraállásokat, időbélyegeket.
Itt az időbélyeg - 1 perc mint join feltétel nem biztos, hogy járható út, mert nem biztos, hogy kereken percenként van új rekord, inkább be kéne számozni a rekordokat egy row_number() over (order by timestamp)-kel, aztán úgy joinolni a saját rn -1-gyel. -
fjanni
tag
Sziasztok, kis segítséget kérnék. Adott egy tábla egy adatbázisban ahol szenzor adatokat tárolunk. Minden percben rögzíti egy gázfogyasztásmérő aktuális állását. Tehát van benne egy idő adat és egy szám adat ami folyamatosan növekszik.
Hogyan lehet egy olyan SQL lekérdezést írni, hogy számolja ki a változást a két adat között, tehát az aktális értékből vonja ki az előzőt és így megkapjuk az aktuális fogyasztást. A másik kérdés továbbmenve hogy napi/heti fogyasztás értéket hogyan kaphatok, vagy esetlég két adott időpont közöttit. -
Közben szerintem sikerült megoldanom. Úgy gondolom, hogy ez egy roppant buta és favágó megoldás, de működik. NyV a fogadás eredménye (0, vagy 1). A sorszam pedig a fogadás sorszáma. Azért indul 20-ról mert az a max fogadás mennyiség egy meneten belül.
select menet,
STRING_AGG(Nyv, '') WITHIN GROUP (ORDER BY menet, sorszam) as Nyv_lista
from fogadas_tabla
group by menet
)
select top 1 menet,
case when Nyv_lista like '%11111111111111111111%' then 20
when Nyv_lista like '%1111111111111111111%' then 19
when Nyv_lista like '%111111111111111111%' then 18
when Nyv_lista like '%11111111111111111%' then 17
when Nyv_lista like '%1111111111111111%' then 16
when Nyv_lista like '%111111111111111%' then 15
when Nyv_lista like '%11111111111111%' then 14
when Nyv_lista like '%1111111111111%' then 13
when Nyv_lista like '%111111111111%' then 12
when Nyv_lista like '%11111111111%' then 11
when Nyv_lista like '%1111111111%' then 10
when Nyv_lista like '%111111111%' then 9
when Nyv_lista like '%11111111%' then 8
else 0 end as Nyero_szeria
from lek1
order by case when Nyv_lista like '%11111111111111111111%' then 20
when Nyv_lista like '%1111111111111111111%' then 19
when Nyv_lista like '%111111111111111111%' then 18
when Nyv_lista like '%11111111111111111%' then 17
when Nyv_lista like '%1111111111111111%' then 16
when Nyv_lista like '%111111111111111%' then 15
when Nyv_lista like '%11111111111111%' then 14
when Nyv_lista like '%1111111111111%' then 13
when Nyv_lista like '%111111111111%' then 12
when Nyv_lista like '%11111111111%' then 11
when Nyv_lista like '%1111111111%' then 10
when Nyv_lista like '%111111111%' then 9
when Nyv_lista like '%11111111%' then 8
else 0 end desc -
Köszi
 és Apollo17hu Neked is.
és Apollo17hu Neked is.
Igen ilyen oszlopok vannak. Az a baj, hogy egy meneten belül a fogadások száma eltérő lehet, így nem tudom, hogy hányszor kellene joinolnom, vagy hány extra mezőt kellene képeznem.
Valamilyen windowed function kéne, ami egy kumulatív sum--ot, vagy sorszámozást képezne egy menet belül, ha az egymást követő fogadások nyerőek, de nullát venne fel, amikor jön egy vesztes fogadás és a következő nyerő fogadásnál egyről indul.
Ciklust nem szeretnék írni rá, csak worst case, mert nem igazán hatékony szerintem SQL-ben.
Végső cél, hogy meg tudjam mondani, hogy melyik volt a leghosszabb nyerő szériájú menet. -
#5715
 Apollo17hu
őstag
Jim74
#5713
Apollo17hu
őstag
Jim74
#5713
Apollo17hu
őstag
LAG() vagy LEAD() függvénnyel megképzel 7 extra mezőt, amik az előző, az azt megelőző stb. ... és végül a héttel korábbi fogadást tartalmazzák. Az így előállt 8 mezőt összeadod egy rekordon, és ahol 8-at kapsz, ott volt a nyolcas nyerő széria (vége).
-
nyunyu
félisten
Van egy táblád, amiben van egy menet_id, egy fogadas_id, meg egy nyert mező?
8x összejoinolod önmagával, menet_id = menet_id, következő fogadas_id = előző fogadas_id+1, nyert mindig 1?
select f1.menet_id,
f1.fogadas_id kezdo_fogadas_id
from fogadas f1
join fogadas f2
on f2.menet_id = f1.menet_id
and f2.fogadas_id = f1.fogadas_id + 1
and f2.nyert = 1
join fogadas f3
on f3.menet_id = f1.menet_id
and f3.fogadas_id = f1.fogadas_id + 2
and f3.nyert = 1
join fogadas f4
on f4.menet_id = f1.menet_id
and f4.fogadas_id = f1.fogadas_id + 3
and f4.nyert = 1
join fogadas f5
on f5.menet_id = f1.menet_id
and f5.fogadas_id = f1.fogadas_id + 4
and f5.nyert = 1
...
where f1.nyert = 1; -
Sziasztok!
Az alábbi "problémára" keresnék megoldást.
Adott egy tábla amiben fogadások vannak. Menetenként több fogadás, melyek kimenetele 1(nyert), vagy 0 vesztett.
Ki kellene listáznom azokat a meneteket, ahol legalább 8 egymást követő fogadás nyerő volt.
Hogy lehetne ezt a legegyszerűbben megoldani?Köszönöm a segítséget
. -
Louro
őstag
Sziasztok!
Egy kis performanciális kérdésem lenne. Sql server 2016-os az alap. Kkb. 5-10GB-os adattáblák. Azokat másolom át napi rendszerességgel. Persze nem sok, de hátha van gyorsabb megoldás.
Először ürítem a táblát (truncate). Indexeket kikapcsolom. SSIS Data Flow segítségével áttöltöm a táblát. Majd a clustered indexet, azután a többi indexet újraépítem.
A maxconcurrentprocess -1 értékre állítva, hogy kimaxoljam a CPU-t. A buffer alaphelyzetben, 10 MB/10000 rekordonként másol.
-
nyunyu
félisten
válasz
 Postas99
#5707
üzenetére
Postas99
#5707
üzenetére
Próbálom összefoglalni, hogy mit szeretnél:
- A táblához kéne C-nek azt az elemét kapcsolni, ami a B tábla szerint éppen érvényes.Sima ügy, A-hoz hozzájoinolod a B éppen érvényes rekordját *, aztán ahhoz joinolod a C-t.
Valahogy így:
SELECT a.csnev,
a.knev,
a.adoaz,
a.szulido,
c.elemnev As Neme,
b.elemid,
alkalmazas.datumtol,
alkalmazas.datumig,
kapcsolatok.lista AS KapcsolatLista
FROM a
INNER JOIN b
ON a.szemelyid = b.szemelyid
AND b.datumtol <= getdate()
AND nvl(b.datumig, getdate() + 1) > getdate()
INNER JOIN c
ON b.elemid = c.elemid
INNER JOIN alkalmazas
ON a.szemelyid = alkalmazas.szemelyid
INNER JOIN (SELECT szemelyid,
STRING_AGG(adatok, ',') WITHIN GROUP (ORDER BY adatok) AS lista
FROM kapcsolat
GROUP BY szemelyid) kapcsolatok
ON a.szemelyid = kapcsolatok.szemelyid;Persze lehetne a
nvl(b.datumig, getdate() + 1) > getdate()helyettb.datumig IS NULL-ot írni, de így bolondbiztosabb, meg a későbbiekben sem kell módosítani, ha netán valaki '2099-12-31'-et ír be az érvényesség vége mezőbe.*: előbb szokás szerint eggyel túlgondoltam, aztán máris az esetleges adathibák jártak az eszemben .
Szakmai ártalom -

Postas99
őstag
Most azon vagyok hogy lecseréljem mert a verzió támogatja. Visual Studio Vb.net de írhatnám C#-ban is mert a feladat az hogy egy meglévő adatbázisból kell napi szinten egy bizonyos adatcsomagot kiszedni ez idáig 1 óra a kolleganőnek naponta és ha ezt egy háttér progi csinálja helyette és leteszi az adatokat akkor az havi szinten is 40 óra spórolás.
nyunyu:
A dátumra hogy miért igy van megoldva nem tudom de az adatbázisban így van letárolva:b.szemelyid b.leiras b.datumtol c.elemid d.datumigxxx esemeny1 2021-12-01 valtozat1 2022-02-28xxx esemeny1 2022-03-01 valtozat2 NULL -
nyunyu
félisten
válasz
Postas99
#5701
üzenetére
Ebből kb. ennyit sikerült megérteni:
Egy kitétemény van még amennyiben egy FIX érték többször szerepel abbból csak a VALID értéket kell megjeleníteni amit a b.ervenyessegvege mező szabályoz. HA az érték NULL akkor az az adat a valid.De ezt sem teljesen.
Ha az érvényességre akarsz szűrni, akkor kell a b tábla join feltételei közé (vagy a query végi WHERE-be) egy
b.ervenyessegkezdete >= getdate() AND
nvl(b.ervenyessegvege, getdate() +1 ) > getdate()
(vagy hogy hívják MS SQL-ül az oracles sysdate-et)Viszont akkor az összes olyan találatot ki fogod szűrni, amihez már csak lejárt b rekordok vannak.
Vagy ha kettőnek nincs lejárati dátuma, akkor mindkettőt megkapod.Egyébként meg az ilyen adathibák javítására hogy egy b-ből nincs érvényes (vagy több érvényes van), nem az a megoldás, hogy egy feleslegesen túlbonyolított queryvel próbálod kiszűrni őket, hanem kézzel be kéne updatelni az érintett rekordokon az érvényesség eleje, vége dátumokat JÓ értékre, hogy egy időszakra PONTOSAN EGY érvényes rekord legyen.
(Tudom, könnyű ezt mondani, de a rendszerszervezőnknek tavaly nyár óta nincs ideje arra, hogy meghatározza, hogy a többszörös cím, meg telefonszám adataink közül melyik példányt tartsam meg érvényesnek. Közben volt még pár adatmigrációs projekt is, ami extra izgalmakat okozott.
) -
Postas99
őstag
válasz
Postas99
#5701
üzenetére
Elnézést de a CODE formatot valamiért nem vette be:
SELECT a.csnev , a.knev, a.adoaz, a.szulido, c.elemnev As Neme, b.elemid,alkalmazas.datumtol, alkalmazas.datumig, STUFF((SELECT ', ' + kapcsolat.adatok FROM kapcsolat WHERE kapcsolat.szemelyid = a.szemelyid FOR XML PATH('')), 1, 2, '') AS KapcsolatLista " &"FROM a " &"INNER JOIN alkalmazas ON a.szemelyid = alkalmazas.szemelyid " &"INNER JOIN c ON a.elmid = c.elemid " &"INNER JOIN b ON a.szemlyid = b.szemelyid " -
Postas99
őstag
Sziasztok!
Lehet nagyon hülyén fog hangazni a kérdés MSSQL adatbáziban lévő 3 különböző táblából szeretnék adatot lekérni * nem vagyok SQL expert* ami a problémám
a tábla
b tábla
c táblaa.szemelyid , b.azonositoid, b.elemid, b.adat, b.ervenyessegkezdete, b.ervenyessegvege
c.elemid, c.elemnev, c.bookidAmit szeretnék megoldani az a következő: egy SQL parancsot összerakni úgy hogy egy datagridview-ban egyben lásstam az összes adatot. A többi lekérdezéshez már összeraktam néhány INNER JOINT-ot de itt megakadtam.
A drigviewban amit látni szeretnék az a következő a.nev, a.nem stb ... c.elemnev
Ami alap: a.szemelyid=b.azonositoid, b.elemid=c.elemid
Néhány extra csavar van még a b.azonositoid -hoz több rekordon is van bejegyzés viszont minden egyes bejegyzés esetén a b.elemid más más érték lehet (az érték készlet fix kb 10) mert ezt csak egy referencia érték amit a c.elemidhez tartozó c.elemnev adja meg a valós adat tartalmat.
Tehát szeretném ezekhez a FIX értékekhez az adat tartalmat a datagridview megjelentetni a FIX értékek lehetnek a header-ök. Egy kitétemény van még amennyiben egy FIX érték többször szerepel abbból csak a VALID értéket kell megjeleníteni amit a b.ervenyessegvege mező szabályoz. HA az érték NULL akkor az az adat a valid.Ha nagyon spongyolán fogalmaztam, akkor elnézést.
Amit eddig összetettem:
SELECT a.csnev , a.knev, a.adoaz, a.szulido, c.elemnev As Neme, b.elemid,alkalmazas.datumtol, alkalmazas.datumig, STUFF((SELECT ', ' + kapcsolat.adatok FROM kapcsolat WHERE kapcsolat.szemelyid = a.szemelyid FOR XML PATH('')), 1, 2, '') AS KapcsolatLista " &
"FROM a " &
"INNER JOIN alkalmazas ON a.szemelyid = alkalmazas.szemelyid " &
"INNER JOIN c ON a.elmid = c.elemid " &
"INNER JOIN b ON a.szemelyid = b.szemelyid "Ez hoz rendesen találatot de ettől én még felkötöm magam mert ez minden de nem szép és sz@r.
Ebben kérném a segítségeteket.
Köszönöm



































 Így nem tudok konverziót végezni. De megpróbálom rávenni a küldő oldalt, hogy ezt tegyék meg. Nekik semmiből sem tartana ezt is beleírni még.
Így nem tudok konverziót végezni. De megpróbálom rávenni a küldő oldalt, hogy ezt tegyék meg. Nekik semmiből sem tartana ezt is beleírni még.













![;]](http://cdn.rios.hu/dl/s/v1.gif)




Új hozzászólás Aktív témák
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- XPEnology
- Autós topik látogatók beszélgetős, offolós topikja
- Mibe tegyem a megtakarításaimat?
- Witcher topik
- Hobby elektronika
- Milyen nyomtatót vegyek?
- Konzolokról KULTURÁLT módon
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Samsung Galaxy S26 Ultra - fontossági sorrend
- További aktív témák...
- 200 x 60 cm Ikea Lagkapten / Alex asztal
- i5 14400F/MSI RTX 5070 GAMING TRIO OC/Corsair 32GB DDR5 6000Mhz/Samsung 980 Pro 1TB/Be quiet650WGold
- Tamron 24-70mm f2.8 Di VC USD G2 (Nikon F) eladó!
- Steelseries Arctis 9X Wireless for xbox + Xbox dongle for PC
- ASUS ROG STRIX GeForce RTX 4090 WHITE OC EDITION 24GB - Alza garancia 2027.03.19 - BESZÁMÍTOK!
- Apple iPad Air 5 13' 128GB (2029.02.09-ig Garancia) Csak kibontva volt, Aktiválatlan!
- Corsair iCUE ELITE CPU Cooler LCD Display Upgrade Kit
- Lenovo ThinkPad W541,15.6,FHD,i7-4810MQ,32GB DDR3,256GB SSD,K1100 2GB VGA,WIN10
- BESZÁMÍTÁS! ASRock A520M R5 5500 16GB DDR4 512GB SSD RTX 2060 6GB CM Masterbox MB311L ARGB 500W
- Azonnali készpénzes nVidia RTX 2000 sorozat videokártya felvásárlás személyesen / csomagküldéssel
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest