Hirdetés
- Luck Dragon: Asszociációs játék. :)
- gerner1
- Gurulunk, WAZE?!
- f(x)=exp(x): A laposföld elmebaj: Vissza a jövőbe!
- Graphics: Telefonvásárlási kálváriám....avagy clickbait cím: Horror a hardveraprón
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- sziku69: Fűzzük össze a szavakat :)
- sziku69: Szólánc.
- MasterDeeJay: ASRock B250M Pro4 coffeetime mod! (DDR4)
- Hieronymus: Pihole + Unbound
Új hozzászólás Aktív témák
-
válasz
 bambano
#6034
üzenetére
bambano
#6034
üzenetére
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage(); -

lanszelot
addikt
válasz
bambano
#6029
üzenetére
Rég óta próbálom az sqlite pdo php -t , de sehol sincs semmi róla.
Borzasztó nehéz bármit is találni. Mind hiányos, és felületes.
Vagy pont az ellenkezője. Egyik se jó egy kezdőnek.
Én is biztos vagyok, hogy a kód nem tökéletes, de működik.
Senki sem segít, így örülök ha működik.
Amit akarok az php-val simán meg lehet oldani.
Amiért akarom, mert hülyeségnek tartom, hogy azért hozzak létre plusz egy oszlopot minden táblába, plusz még egy táblát, hogy össze kössem a táblákat, mikor sokkal egyszerűbben meg lehet csinálni.
Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet.
Akkor marad a php.
-

fjanni
tag
válasz
bambano
#6003
üzenetére
Értem a 3 tábla felépítését és ez a megoldás jónak tűnik. Megoldja azt hogy eltérő időbélyegekkel hogyan lehet összefűzni adatokat.
Az adat összefűzés azért kell mert ipari üzemről van szó ahol gázmérők regisztrálják a fogyasztást főmérők/almérők/mellérendelt mérők struktúrában. Minden időpontban meg kell tudni mondani pl. hogy az almérőkőn mért fogyasztás összege megegyezik-e a főmérőével. De ugyanígy az elektromos mérőknél pl. hogy a napelem általt termelt energia / a hálózatról vásárolt energia / visszatermelés hogyan viszonyul egymáshoz és pl. mennyi az üzem tényleges fogyasztása stb. és mindezeket összesítve órára/napra/hétre hónapra stb. Tehát különböző mérőpontoknál szerzett adatokkal műveleteket kell végezni, ezt pedig csak úgy lehet hogy összerendelem azokat.
Ez azonban egy jelentős struktúra váltás és egy német cégnél ezt nehéz átvinni, de megpróbálom.
Viszont nekem addig is kell egy megoldás és a korábban említett View jó lehet erre. Fogom a tábla adatokat, először is konvertálom az időt a legközelebbi negyed órás időre (00/15/30/45min) beleteszem a mérési pont azonosítóját (MPxxx) is az adat mellé és unionnal összefűzöm őket. Aztán ezt a view-t használom a Grafana Query-kben. -
-
válasz
bambano
#6005
üzenetére
Nekem az a gyanúm, hogy valami olyan feladatról lehet szó, mint egy közüzemi cégnél, hogy jönnek a mérőkről az adatok és két adott időpont között ki kell számolni az adott időszakban elfogyasztott (mért) mennyiséget.
Szerintem ehhez elegendő egy tábla (feltéve, ha a mérőkről nem szükséges további információ, pl. telepítési hely, lokáció, hitelesítési év, ilyesmi).
Viszont az adatok mennyiségétől függően már most érdemes elgondolkodni az időközönkénti archiváláson, mert egy ilyen tábla elképesztő nagyra tud "hízni", ami az esetleges riportolási performanciát megboríthatja.
Én nem vagyok data enginieer, csak egy mezei riportingos, ezért az irományomat ilyen kritikus szemmel nézd kérlek .
. -
fjanni
tag
válasz
bambano
#5986
üzenetére
Mert szenzorokkal gyűjtünk mérési pontokról adatokat (kb. 200-nál tartunk és folyamatosan bővül) és annak idején úgy lett felépítve az adatstruktúra hogy minden szenzor adata külön táblába megy és minden táblának ugyanaz a szintaktikája (datetime, counter). Ezen nem tudok változtatni.
-

shipfolt
kezdő
válasz
bambano
#5967
üzenetére
Ja, hogy azt o akkor irta, amikor SQL-nek meg hire-hamva se volt.
Jol sejtettem, hogy hogy nem SQL-lel, hanem adatkezelessel van problemam
sztanozs:
Nekem azt tanitottak, hogy SQL-ben tablak osszekapcsolasa reven lehet urlapok letrehozasa reven adatokat kezelni. (Access)Most utana olvasva lattam, hogy van egy kozvetlen modszer is, amikor SQL-ben futtathato programokat kell irni, es feltetelek reven nagyon egyszeruen lehet adatokat modositani.
Ezt veszelyesnek tartom, mert barmikor barmilyen adatot felul lehet irni, nem is marad nyoma, hogy ki es mikor csinalta, mert a program csak addig el, amig az illeto begepeli es lefuttatja, nincs elmentve, mint egy urlap. -
shipfolt
kezdő
válasz
bambano
#5961
üzenetére
Wow, beinditottam a forumot.

Koszonom a javaslatokat, harom problemam van ezekkel.
Az elso, hogy meg erosen kezdo vagyok, a triggerekrol kosza hirek erejeig hallottam.
(Az adatbazis kiepitesenel lecovekeltem, mert furcsasagokat lattam kulonbozo konyvekben, de ezt most hagyjuk.)A masodik az "elmelet es gyakorlat" utkozese:
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Ez a gyakorlatban nem igy mukodik, hanem harom lepesben megy:
Eloszor belapatolod a feladatokat hevenyeszett hataridokkel,
majd jon a felulvizsgalat, hogy mennyi feladat van es mennyi ido,
majd jonnek a kivalasztasok, hogy miket lehet gyorsan megoldani, vagy melyek valoban fontosak, vagy melyiknel van rovid hatarido, ezeket elore veszik.
Csak ekkor jon a felulvizsgalat, hogy milyen kapcsolatok vannak kulonbozo szempontok alapjan, es ha ez a fontos, akkor ehhez mely masik szukseges vagy megoldhato, tehat a prioritasok erosen valtoznak hangulatok vagy kotelezettsegek valtozasa miatt.
A harmadik, amivel bajban vagyok az az, hogy ezt a megoldast a gyakorlatban hogyan tudom megoldani?
Beiraskor egyszeru, az "elozo ID" mezo uresen marad (lehet null feltetel kell ra)
De, amikor be kell allitani, akkor valahogy ra kell keresni minimum az "ID + megnevezes" mezokre, es nem latok arra lehetoseget, hogy ugyanabban a tablaban keressek, aminek az egyik rekordjat megnyitottam szerkesztesre.Ezt hogyan lehet megoldani?
Ha fontos, akkor Access 2007-en kezdtem tanulgatni, mert annal konnyu a tablakat beallitani es a kozottuk levo kapcsolatokat vizualisan megjeleniteni, nemreg kezdtem a Libreoffice Base-t hasznalni.
-
-

nyunyu
félisten
válasz
bambano
#5924
üzenetére
Az a bajom, hogy túlzottan alulnézetből látom az adatokat, és nem mindig ismer(het)em a keletkezésük, elromlásuk pontos körülményeit a különböző rendszerek közti adatszinkronizációk útvesztőjében, viszont nekem kéne helyrekalapálni a félreálló biteket.
Bár elnézve azt,hogy ~3500 GDPR érett igénylést akartam javítani, de belekerült 10 friss is a szórásba, az csak 0.3% hibaarány, bőven elviselhető kerekítési hiba

-
nyunyu
félisten
válasz
bambano
#5921
üzenetére
De kéne.
Eredeti DBben nem ugyanúgy hívják a hiteligenylesek meg a másik rendszerből származó táblákban a számlaszámos mezőket, így nem akadt fenn azon az Oracle, hogy elfelejtettem táblaaliast írni a select oszlopai elé, mivel egyértelmű volt, hogy melyik táblából jön.
Csak itt a szemléltetés kedvéért olvashatóbbá egyszerűsítettem a kódot, és nem követtetem a DBnk örökölt hülyeségeit, hogy minden táblában másképp hívják ugyanazokat a mezőket, aszerint, hogy ki mikor/hogyan specifikálta.

Pl. createdate vs create_date még az egyszerűbbik eset...
-

coco2
őstag
válasz
bambano
#5897
üzenetére
Ha 60 nappal előre mindig meg kell adni, mi lesz munkanap, és mi nem, amin utólag nem változtathatnak, és határidőt soha sem kell 60 napra előre számolni, akkor létezik logikus megoldás. Hanem azt korábban nem írtad, és nekem nincsen ismeretem a kérdéses környezet ügyintézésében. Mint ahogy abban sem, létezik-e 60 napon túli határidő? Ha igen, megint csak baj van.
-
nyunyu
félisten
válasz
bambano
#5899
üzenetére
Oracleben gyorsan összedobva:
with munkanap as (
select a.*
from (
select to_date('2023-12-31','yyyy-mm-dd') + rownum as actdate, to_char(to_date('2022-12-31','yyyy-mm-dd') + rownum, 'd') as dateid
from (
select rownum r
from dual
connect by rownum <= 5000)
) a
left join days d
on d.actdate = a.actdate
and d.dateid = 0
where a.dateid in (1,2,3,4,5)
and d.actdate is null)
select actdate
from (
select m.*, row_number() over (order by actdate asc) rn
from munkanap m
where m.actdate > to_date('2024-12-20','yyyy-mm-dd')) x
where rn = 15;Ahogy néztem reggel, Postgre szintaxissal sokkal egyszerűbb lenne a munkanap CTE.
-
-
nyunyu
félisten
válasz
bambano
#5892
üzenetére
Ja, ha multikulti környezetben akarod ezt használni, akkor kell még egy oszlop a days táblába, ahova felveszed az országot/tartományt, aztán a függvénybe/querybe azt a feltételt is beleteszed, hogy melyik ország/tartomány munkanapjait számolja.
De akkor lehet szívni az olyan különbségekkel, mint pl. araboknál péntek-szombat a hétvége, tehát arab országoknál a vasárnap lesz az 1, csütörtök az 5 a táblában.
Meg külön-külön összevadászni+felvinni a helyi ünnepeket... -
coco2
őstag
válasz
bambano
#5882
üzenetére
>Nem elég egyszer feltölteni, mert az, hogy mi munkanap, folyamatosan változhat.
HR portálon előző év végén már ott a lista következő évre. Elvileg nem kellene túl nagy ügynek lennie, hogy írsz egy függvényt, aminek tömbösen behajigálod azokat az adatokat, és az legyártja neked a korrekciós táblát. Évente 1x kicsi manuális pepecselés, de ha ennyitől kizökkensz, add ki diákmunka cégeknek
Eltérő ünnepnap halmozódások.
Ha jól értettem, hosszú határidők vannak, és menet közben több ünnepnap, hétvége, olyasmi tud közbe jönni, és az a problémád, hogy olyankor eltérő korrekció kell. Nos, ha legalább a határidők folyton azonos hosszúságúak, az induló napból egy korrekciós tábla meg tudja neked adni a határidő lejártát. Mert azt előre kiszámolod. Ha eltérő határidők léteznek, mint 8,15,23,32 nap és társai, részint csinálhatsz minden határidő típusra külön táblát, részint csinálhatod azt, hogy tábla elemek helyére egy json stringet raksz be, ami attól a naptól kezdve az összes határidő típusra ad egy kimenetet, és a string lekérdezése után a json-t parsingolod, aztán felhasználod. A json belefér 1 táblába, de kissé N1NF. Ha szebben akarod, az több tábla lesz, és az lesz "csúnyább"
Ha adatkezeléssel foglalkozol, nem baj, ha nem akadsz ki azon, hogy gyártani kell pár táblát, amit fel is kell töltened. Vagy ha annyitól kiakadsz, és látni sem bírod az adatkezelést, inkább bízd azt a részét másra. Amit nem látsz, az nem fáj
-
nyunyu
félisten
válasz
bambano
#5883
üzenetére
x. munkanap:
select actdate
from (
select d.actdate, row_number() over (order by actdate asc) rn
from days d
where d.actdate > to_date('2024-12-20','yyyy-mm-dd')
and d.dateid in (1,2,3,4,5) --munkanap
)
where rn = 15;
-- 2025-01-17 00:00:00(actdate a dátum mező, dateid-ben van tárolva az 1-7 hétfő-vasárnap, 0 ünnep)
-
nyunyu
félisten
válasz
bambano
#5877
üzenetére
Nálunk ez úgy van megoldva, hogy van egy days tábla, amibe kolléga minden decemberben feltölti előre a következő évi dátumokat, meg mellé, hogy hanyadik napja a hétnek.
Ha valami ünnepnap, akkor 1-7 helyett 8 értéke van, ha meg munkanap áthelyezéses szombat, akkor 5 (péntek) lesz az értékeEzt használva az x. napot követő első munkanap lekérdezés úgy alakulna, hogy megnézed, hogy a kérdéses dátum+x. nap után melyik a legkisebb olyan nap, aminek 1-5 közötti az értéke.
Ha meg x. munkanap kell, akkor a kérdéses dátumnál nagyobbak közül sorbarakod az 1-5 közötti értékűeket, aztán ebből veszed az x. legkisebbet.
-
coco2
őstag
válasz
bambano
#5877
üzenetére
Szerintem azt a táblát ügyesebben is használhatnád. Előre gyárthatnál egy intervallum listát dátum tól-ig, amikhez bejegyzed, hogy abban az intervallumban az eredeti határidőt X-re át kell írnod (tovább tolod). Ha nem találtál olyan tábla sort, marad a régi. Ha akár perc pontosan akarsz számolni, akkor naponta egy sor, ami éves viszonylatban még mindig csak 365 sor. Nem a világ vége.
>valaki akar egy ilyen sql lekérdezésen agyalni?
A lekérdezést nem írom meg helyetted, a lusta mindenit

>előre is kösz.
you welcome
-
fjanni
tag
válasz
bambano
#5836
üzenetére
Köszi, a sum(consumption) a külső Select-ben segített.
Most már jól működik, összesít és a 12. hónap is megvan.
Márcsak egy gond van, valahogy hiányzik a két hónap közötti adat, azaz a hónap első számlálóállása és az előző hó utolsó számlálóállása közötti adat. Azaz a sum-ban csak azok a különbözetek szerepelnek amelyekben mindkét Zeit ugyanahhoz a hónaphoz tartozik. -
fjanni
tag
válasz
bambano
#5829
üzenetére
Igen, valószínűleg a subquery a megoldás amiatt amit írtál.
Készítettem egy queryt de valamiért hibás:
(
SELECT
Year (zeit) as Year,
Month(zeit) as Month,
Zaehlerstand-lag(Zaehlerstand) over (order by zeit) as "Consumption"
FROM table
) as T
select * FROM T group by Year, MonthMi lehet a gond?
-

cog777
őstag
válasz
bambano
#5627
üzenetére
"inkább oldjátok meg, hogy legyen net. mibe se kerülne egy építési területre saját wifit telepíteni..."
Minden gep 4G modemmel rendelkezik azonban bizonyos orszagok, bizonyos teruletein nincs net, pl hegyekben, kint a tajgan, oserdoben stb.
Pl Alpokban a ho'tolo'k allomasanal van internet, de amikor kimennek, akkor vannak foltok ahol total nincs net es nem fognak telepitgetni nagy tavolsagu wifi allomasokat."ne kelljen multimastert csinálni, mindig pontosan egy irányba menjenek az adatok "
jah, egyetertek, 1 master eseten sokkal konnyebb lenne az elet.@tobbieknek: koszi az eszreveteleket.
-
nyunyu
félisten
válasz
bambano
#5627
üzenetére
az külön necces, hogy egyes gépen hol van net, hol nincs, ahelyett, hogy ilyenkor másik gépen keresztül küldi az adatot, inkább oldjátok meg, hogy legyen net. mibe se kerülne egy építési területre saját wifit telepíteni...
Mondjuk egy Paks2 alapozását ássa 25 munkagép jellegű témánál macerás lehet a saját wifi kiépítése, de mobilnettel megoldható.
-
cog777
őstag
válasz
bambano
#5621
üzenetére
Koszi a valaszt!
A gepek rendkivul pontos helyzete van naplozva es abbol terkep felepitve, igy nem igazan van mas valasztasunk mint szinkronizalni az adatokat. Tudom hogy nagy szivas az ilyen , szerencsere van egy DB expert is velunk, hat majd meglassuk.Sok adat keletkezik es a leheto leggyorsabban kell atkuldeni, hogy a gepek lassak a tobbi poziciojat es az irodaban ulo menedzser is

Elertuk azt a pontot amikor elkezdtuk hasznalni a syslog-ot is

-
#5451
 Prog-Szerv
csendes tag
bambano
#5450
Prog-Szerv
csendes tag
bambano
#5450
-
Taci
addikt
válasz
bambano
#5436
üzenetére
Annyira szeretném érteni, amit írtok, de csak
 fejek jönnek elő belőlem (meg rengeteg kérdés).
fejek jönnek elő belőlem (meg rengeteg kérdés).Google Analytics erre a megoldás, saját kókányolás helyett.
Szeretnék egy menüpontot, hogy pl. "Legolvasottabb cikkek". De az nem világos, hogy hogyan lehet jobb az Analytics-es adat, mint a saját szerveren tárolt. Vagy van rá mód, hogy direktben elérjem ezt az adatot (Google), és be tudja építeni egy query részeként? Tehát hogy pl. rendezze sorba a cikkeket aszerint, hányszor voltak megnyitva (aka. Legolvasottabb cikkek). Mert csak erre kellene.az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Ezt elmagyaráznád, kérlek, hogy miért jó? Szeretném megérteni, hogy aztán implementálni tudjam. (Ez offtopic ide, ezért rakom off-ba, de nagyon szeretném érteni.)
Így hirtelen ami eszembe jutott, hogy külső linkekkel operál az a hírkereső. Meg is néztem gyorsan, ott ez hogyan van megoldva.Egy példa (direkt nem alakítom linkké):
https://rd.hirkereso.hu/rd/39891270?place=6544&partner=hirkereso&url=https%3A%2F%2Fprohardver.hu%2Fhir%2Fjon_lg_elso_hibrid_projektora.htmlEz ide dob tovább:
https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlMegköszönném, ha lenne annyi türelmed, hogy pár szóban elmagyarázod, hogy ez a link miért így épül fel. Pl. itt miért kell az "rd" aldomain? redirect, gondolom, de ez miért kell?
https://rd.hirkereso.hu/rd/39891270
Ez is ugyanoda továbbít, már a többi rész nélkül is. (és minden más cikkhez is van egy ilyen "redirect-id") Akkor miért kell a többi rész? Nem is igazán értem, bár ez gondolom a saját kódjához kell valamiért.És ennek a headerjében van a
Status Code: 301 (from disk cache)
location: https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlViszont semmilyen forrásadatot nem látok, nem tudom, hogy továbbít.
Szóval talán az aldomain azért kellhet, mert ezekhez a külsős linkekhez csinált 1-1 saját linket a redirect aldomain-ban, és ezek a linkek 301-el továbbítják a valós cikkhez?
Ez plusz forgalmat generál neki? Vagy miért jó?Milyen rendszert kell építeni mögé? Mit kell hogy tudjon?
És miért jobb, ha így nyílik meg a link, mintsem a direkt link? Mi a célja, szerepe?
A startlap pl. a külsős linkeket simán csak belinkeli, nincs redirect. Akkor ők rosszul csinálják?Vagy ha nincs türelmed, kedved, természetesen azt is megértem, csak kérlek, ez esetben legalább a megfelelő keresőszavakkal segíts, hogy a megfelelő cikkeket találjam meg.
Egy általános "url redirect" sajnos nem mondja meg, hogy hogyan (és miért) kell saját weblapról saját weblapra átirányítva átirányítani. (Se másik jó pár keresés az utóbbi majd' 1 órában.)
Köszönöm.
-
-
válasz
bambano
#5156
üzenetére
Ez viszont nem jól fogja számolni, lesz egy nap két DE (2*8 óra, hajnalban és éjszaka) és egy DU (1*16 óra napközben).
Valahogy így lehet jó:
SELECT
TRUNC(dateadd(hour,-8,datum)) AS nap,
CASE WHEN date_part('hour',dateadd(hour,-8,datum))>12 THEN 'DU' ELSE 'DE' END AS muszak,
SUM(szam)
FROM tabla
GROUP BY 1,2 ORDER BY 1,2;Így a hajnal még az előző naphoz fog tartozni mint DU műszak.
-

tm5
tag
válasz
bambano
#5150
üzenetére
SELECT TRUNC(datum) AS nap,
CASE WHEN DATEPART(HOUR,datum)>11 THEN 'DU' ELSE 'DE' END AS napszak,
SUM(szam) AS osszeg
FROM tabla
GROUP BY nap,
CASE WHEN DATEPART(HOUR,datum)>11 THEN 'DU' ELSE 'DE' END
ORDER BY 1,2
Legyen neked Karácsony Nálunk 12 és 1 között ebéd szünet van, olyan senkiföldje. -
Taci
addikt
válasz
bambano
#5104
üzenetére
Talán ez lehet a jó irány...
Most így néznek ki a lekérdezések:
Az "eredeti" (a javasolt változtatásod előtti):
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 10.8688 seconds.)
A categories tábla kivétele a Join-ból:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idWHEREic.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 5.0478 seconds.)
A subquery-s megoldás (WITH-et nem engedett használni, így most ezt a megoldást találtam a "helyettesítésére"):
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.7163 seconds.)
(És ide már nem is kell a Group By.)
Frissítettem a db-fiddle-t vele.
Mind a 3 változat ugyanazt a 4 rekordot adja vissza, helyesen.
Ez utóbbi, az általad javasolt valóban sokkal gyorsabb - bár (lehet, az én implementálásom miatt) még így is lassú (0,8 mp környéki lekérdezés).
(Furcsa mód ha kiveszem az Order By-t belőle (ami eddig csak lassította), a 0,8 mp-ből 6,6 mp lesz...)De ezzel talán már el lehet indulni ebbe (subquery) irányba.
Még valami ötlet esetleg ehhez az irányhoz?Köszönöm a tippeket és hogy ránéztél!
-
Taci
addikt
válasz
bambano
#5077
üzenetére
Alapból a my.ini-ben ez volt:
innodb_buffer_pool_size = 16MEzt most kicseréltem ennek a tartalmára:
my-innodb-heavy-4G.ini
innodb_buffer_pool_size = 2GÍgy a lekérdezés első futtatása ugyanúgy ~20mp-ig tartott, viszont amikor újra futtattam, már csak 0.01-ig.
Szóval ennél a lekérdezésnél a memória bővítése valóban segített, viszont, csak addig, amíg pont ugyanezt a lekérdezést futtatom, mert így memóriából tudja újra felhasználni. Amint akár egy feltételt is módosítok, újra 20mp várakozás, memóriába töltés. Aztán megint változtatok, megint várakozás. És ez csak 1 felhasználó, nem 10e-100e.Szóval sajnos nem ez a jó megoldás, de azért köszönöm a tippet.
------
@martonx: Az a legelső ajánlásaitok egyike volt, azóta indexelve van. Írtam is 3 hozzászólással korábban, hogy indexelt a feed_date.
Az EXPLAIN-eknél látszik, hogy hiába indexelt, mégis, ha van DISTINCT és ORDER BY is, akkor átnéz és rendez 410e rekordot lekérdezésenként, ezért tart 20 mp-ig...

Ha csak az ORDER BY-t használom, akkor 0,01 mp:

Ha csak a DISTINCT-et használom, akkor is 0,01 mp:

------
És ha van mindkettő, DISTINCT és ORDER BY is, akkor nem a jó logika mentén alkalmazza a DISTINCT-et, mert ez a találat (a LIMIT 4-gyel):
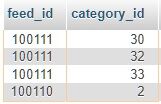
Tehát így a rekordok valóban különbözőek, viszont ezt ugye a JOIN-os nagy egészre nézi. És ebben benne van az általatok javasolt plusz tábla, amibe ki lettek szedve a kategóriák, hogy ha egy bejegyzéshez több kategória is tartozik, akkor az mind külön rekord legyen. És ezzel így összefűzve a DISTINCT valóban jó eredményt ad - csak rossz logika szerint:
nekem az kellene, hogy a feed_id-kra legyen vonatkoztatva, tehát a képernyőfotós példában a 100111 csak egyszer szerepeljen. -

kojakhu
újonc
válasz
bambano
#5009
üzenetére
Közben meg is írta h mi a pontos elvárás, de a kódolástól nem láttam
Itt van, ami szerintem már helyes, csak azért h hátha meg lehet mégis csinálni.
Viszont performancia miatt nem lesz használható.
Max akkor, ha valahogy a sorok számát a rekurzív részben lehet limitálni. Pl ha lehet tudni, hogy max mekkora gapek vannak a logok között (ezt is ki lehet számolni akár), vagy esetleg az előző munkámmal lehet összeszerelni úgy h az ott előálló csoportokban kell csak részcsoportokat képezni.Szóval brahiból itt az újabb SQLFiddle link
Pls valaki mindenképpen válaszoljon (ha jó a megoldás, ha nem), mert a blogon "újoncként" nem írhatok csak 1-et amíg nincs rám válasz...Setup:
create table t (dt timestamp);
-- group 1
insert into t values (current_timestamp);
insert into t values (current_timestamp + interval '10' second);
insert into t values (current_timestamp + interval '59' second);
-- group 2
insert into t values (current_timestamp + interval '70' second);
insert into t values (current_timestamp + interval '71' second);
insert into t values (current_timestamp + interval '129' second);
-- group 3
insert into t values (current_timestamp + interval '200' second);
insert into t values (current_timestamp + interval '210' second);
insert into t values (current_timestamp + interval '220' second);
insert into t values (current_timestamp + interval '259' second);
-- group 4
insert into t values (current_timestamp + interval '260' second);
insert into t values (current_timestamp + interval '261' second);Lekérdezés:
WITH RECURSIVE rd(grp, mindt) AS (
SELECT 1 AS grp
, MIN(dt)
FROM t
UNION
SELECT rd.grp+1 AS grp
, FIRST_VALUE(t.dt) OVER (ORDER BY t.dt)
FROM t, rd
WHERE t.dt >= rd.mindt + INTERVAL '1' MINUTE
) -- rd
, grpd AS (
SELECT grp
, t.*
, MIN(dt) OVER (PARTITION BY grp) mindt
, MAX(dt) OVER (PARTITION BY grp) maxdt
, COUNT(*) OVER (PARTITION BY grp) cnt
FROM rd, t
WHERE t.dt >= rd.mindt AND t.dt < rd.mindt + INTERVAL '1' MINUTE
) -- grpd
SELECT v.*
, maxdt-mindt AS grp_duration
FROM grpd AS v
ORDER BY dt -

Ispy
nagyúr
válasz
bambano
#5003
üzenetére
El kell indulni a legkisebb dátumtól, ha jön az első dátum, ami 60 mp-en kívül van, akkor az egy csoport és indul újra a loop. Most azon lehet vitázni, hogy kisebb mint 60 vagy kisebb egyenlő. Ha megvan minden group, akkor meg kell határozni a group min és max értéke között az eltéréseket, azokat a groupokat meg ki kell szórni, ahol count(*)=1.
Már ha felfogtam mi a feladat...nem volt egyértelmű nekem az alap def.
-
Taci
addikt
válasz
bambano
#4956
üzenetére
Jelenleg egy lokál gépen futó DesktopServer nevű környeztet használok a fejlesztésre. Itt MariaDB van használatban.
Ha van valakinek egy szabad 5 perce, csak akkor olvasson tovább.

Ez egy "itthoni tanulós projekt", semmi több. Érdekelt a téma, így elkezdtem egy weblapot készíteni 6 hónappal ezelőtt. De ekkor kezdtem el csak az alap dolgokon felül használni mindent, ami kell hozzá: HTML, CSS, JS, PHP, SQL.
Nagyon szépen haladtam mindennel, 6 hónapja minden szabadidőmet beleöltem, és most már úgy láttam, 2 héten belül készen vagyok, és költözhetek a kis projektemmel a szolgáltatóhoz: Versanus, velük van pozitív tapasztalatom korábbról. Nem tudom, hogy ott milyen adatbáziskezelő van.
Na szóval örültem, hogy végre a kis projektemet a "nagyvilág elé tárhatom" (értsd: rokonok és kollégák
), és a todo-listám egyik utolsó eleme volt, hogy utánakérdezzek, hogy a lekérdezéseim nem pazarólak-e.És mint kiderült, sajnos rossz logika mentén építettem fel az egész adatbázist. És az a baj, hogy 6 hónapja amióta csinálom, erre a logikára épül minden de minden. Tegnap átnéztem a kódjaimat, nyilván az új típusú (1 db) táblát könnyen létrehoztam, a tartalomfeltöltő php kódot is könnyen átírtam az ajánlás alapján, hogy a több tábla helyett egybe írjon csak, külön oszlopba pedig, hogy melyik forrásból származó bejegyzéseket tárolja.
De aztán jöttek a JS-ek, plusz a lekérdezésért felelős PHP, és ott sajnos csak nagy nehézségek és időveszteséggel tudnám csak átírni az egy táblás módszerre, hogy szépen működjön. Sajnos nem erre a logikára építettem fel, így kvázi kezdhetném előröl, mert másképp csak a régi módszer kódjait tudom "megerőszakolni", és mivel arra építettem fel mindet, sosem lesz szép tiszta igazán, csak ha előröl kezdem.
És őszintén, ez most nagyon elvette a kedvem. Tökre örültem, hogy végre 6 hónap fáradozása a számomra tök ismeretlen területen végre manifesztálódik, erre kiderült, hogy nagyjából kezdhetem előröl.
Mielőtt tényleg így döntenék, kérlek, írjátok meg, tényleg akkora gond-e, ha külön táblákban vannak az adatok.
Források szerint készítettem el őket, 1 forrás - 1 tábla. Nagyon max 15-20 forrásból fogok dolgozni. Forrásonként naponta kb. 100 bejegyzéssel.
1 bejegyzéshez tartozik egy id, egy link, egy rövidebb és egy hosszabb szöveg (300 karakter max), illetve 2 kép linkje (csak link), plusz még 2 rövidebb tartalmú szöveg (50 karakter max). Ennyi.Most már én is látom, hogy sokkal jobb lett volna az 1 tábla, mert minden bejegyzés pontosan ugyan olyan felépítési, ugyanolyan oszlopok vannak minden táblában.
Viszont a kódjaim most tökéletesen működnek, millió ellenőrzést és vizsgálatot tettem beléjük, próbáltam minden eshetőségre felkészíteni. És sajnos a sok táblás megvalósítás egyáltalán nem kompatibilis az 1 táblással, tényleg át kellene írnom mindent, JS-től kezdve PHP-kig mindent, még HTML-eket is.
És ha nem szörnyen rossz, tarthatatlan, pocsék lassú a mostani felépítés (max 15-20 tábla, napi 100 bejegyzés / tábla, tehát 2000 bejegyzés / nap, 14e bejegyzés / hét, 728e bejegyzés / év), akkor nem kezdeném előröl.
Az nagyon visszavetne, már így is elszállt a kedvem.Bocs, hogy hosszan taglaltam ezt, de kérlek, írjátok meg, valóban elengedhetetlenül szükséges-e előröl kezdenem az új szerkezettel. A rokoni/kollegális elérésekhez biztosan nem.
De később, ha a fél ország ezt olvassa majd (best case scenario ), lehet valami hátulütője a több táblás felállásnak? Ha egyszerre 5 millióan nézik az oldalt, lapoznak, futnak a lekérdezések (LIMIT 4, szóval 1 lekérdezés csak max 4 találatot ad vissza mindig), milyen negatív következményei lehetnek, ha a több táblásnál maradok? Lelassul minden mindenkinek? Vagy a szolgáltató szól rám?Ezt összefoglalnátok nekem pár gondolatban, kérlek?
Eléggé elkeseredtem most, de persze ha ez a több táblás módszer a fenti számolásokat alapul véve is tarthatatlan, és később csak problémám lenne belőle (belassulna az oldal a felhasználóknak), akkor egyelőre hagyom az egészet, és majd ha megint találok rá ennyi időt egyszer, átírom.
De ha csak a tábla karbantartása miatt lenne jobb, ha egy lenne a több helyett, akkor az nem gond, mert mindent eleve a több táblásra készítettem el.Köszönöm, és elnézést az eszméletlen hosszú posztért, de 2 sorban ezt nem lehet (vagy csak én nem tudtam) rendesen elmagyarázni.
-
nyunyu
félisten
válasz
bambano
#4956
üzenetére
mondjuk az is relatív, hogy kinek mi a nagy adatbázis. a postgesql párszázmillió rekorddal még szépen elgurul
8 éve próbálkoztam az egyik mobilszolgáltató adattárházán dolgozni, aztán a DB műveletek query planjét logoló táblából (~napi 10 millió rekord?) kellett volna adatokat kinyernem egy adatvizualizációs projekthez.
Próbaképpen lekértem negyedórányi adatot, erre 10 perccel később jött a teradata üzemeltető leordítani a hajamat, hogy ilyet ne merjek még egyszer lekérdezni, mert letérdelt tőle a 24 node-os DWH, alig bírták kilőni a querymet.
Pedig előtte direkt megnéztem, milyen indexek vannak a táblán, meg mekkora a várható eredményhalmaz mérete, nehogy egyszerre túl sokat akarjak lekérdezni...
-
-
nyunyu
félisten
válasz
bambano
#4835
üzenetére
Ezzel viszont vissza is kanyarodtunk a kurzoron végigiterálós megoldáshoz, amit macerásabb megírni, mint az előbbi jólfésült selectet
nagy vonalakban valami ilyesmi:
declare
cursor c is
select regexp
from regexptabla
order by gyakorisag desc;
r varchar2(100);
begin
truncate temptabla;
open c
loop
fetch c into r;
exit when c%NOTFOUND;
insert into temptabla (voltmar)
select e.ertek
from eredetitabla e
left join temptabla t
on e.ertek = t.voltmar
where t.voltmar is null
and e.ertek ~ r;
end loop;
close c;
select e.ertek
from eredetitabla e
left join temptabla t
on e.ertek = t.voltmar
where t.voltmar is null;
end;(Nem vágom a postgre szintaxisát.)
-

Szmeby
tag
válasz
bambano
#4743
üzenetére
Szerintem ez csak egy házifeladat.
Már eleve életszerűtlen, hogy egy rakás fontos dolgot nem vesz figyelembe. Illene ellenőrizni, hogy a teljes rendszer egyenlege egyáltalán pozitív-e. Ha nem, akkor el kell dönteni, hogy inkább a kis hiánnyal rendelkező üzletek készletét optimalizáljuk és hagyjuk a nagy hiánnyal küzdő üzletet megdögleni. Vagy a nagy hiányra összpontosítunk és a kis hiánnyal rendelkező üzletek majd megoldáják valahogy. Teljesen más megközelítést igényel a két üzleti igény.
Ha feltételezzük, hogy a teljes egyenleg pozitív, akkor is kell egy korlát, ami alatt egyszerűen nem éri meg megmozdulni. Továbbá sokkal jobb minden üzlet készletét egy átlagos érték felé közelíteni. Vagyis ne a 0 hiány, 0 többlet legyen a cél, hiszen, ahogy te is mondtad, a raktárkészlet állandóan forog: ha csak a nullát tűzzük ki célul, akkor az első vásárláskor újra negatívba fordul, ami optimalizálási igényt kényszerít ki... abszolúte nem hatékony.
De még az átlagos szint sem feltétlenül optimális, hiszen egyes üzletek forgalma historikusan nagyobb, másoké kisebb, így érdemes ez alapján egy átlagtól való korrekciót alkalmazni. Ami aztán további problémákat szül, mivel egy tűpontosságúra optimalizált rendszerben - amennyiben az ember elfelejt gondoskodni az utánpótlásról - nagyon könnyen a teljes rendszer szintjén fellépő hiány alakulhat ki nagyjából ugyanabban a pillanatban.
A feladat nem veszi figyelembe az üzletek egymástól való fizikai távolságát, a megközelíthetőséget. Nagyon szépen hangzik, hogy egy db procedure megmondja, hogy a kettes id-jú üzletből vigyünk át 50 bizbazt a 14-es id-jú üzletbe, de ha ezek a város két végén helyezkednek el, akkor az ész nélküli ide-oda szállítgatás felzabálja a profitot. Arról nem is beszélve, hogy az ezt intéző munkavállalók azt fogják kérdezgetni, hogy ki volt az az idióta, aki ezt így kitalálta... és teljesen jogosan fogják megkérdőjelezni az értelmét.
A való életben ennél sokkal komplexebb feladat egy elosztott raktárkészlet optimális fenntartása, marhára nem egy temptáblával megoldható probléma. Mármint megoldható, csak az olyan is lesz. Ízlés dolga, kinek mit vesz be a gyomra ugye.
-
nyunyu
félisten
válasz
bambano
#4737
üzenetére
Van amikor a számítási/lekérdezési sebesség fontosabb, mint a redundancia.
Ha csinálsz egy aktuális raktár nézetet, amiben összejoinolod az eredeti raktár táblát a mozgatások szummájával, és ebből dolgozik a következő lépést meghatározó lépés, akkor minden egyes lépés kiértékelésénél a DBnek egyesével újra kell számolnia az eddigi lépések eredményét, ahelyett, hogy a letárolt köztes értéket használná.
Ez ugyan elegáns, de nem hatékony.(Épp most kínlódunk azzal, hogy mindenféle BI riportokat kell készíteni, de többszázezer soros táblákat kell joinolni, szummázni, és az eredmény kb. 40k sor/nap.
BI meg állandóan beledöglik, amikor így-úgy szűrve belekérdez a DBben tárolt nézetbe.
Úgyhogy írhatok egy jobot, ami naponta lefuttatja a kb. egy percig futó queryt, és insert into-zza egy táblába, aztán onnan fog select *-ozni a BI, nem az eddigi nézetből.) -
tm5
tag
válasz
bambano
#4670
üzenetére
Hát a lenti feladatleírás alapján ha az ID nő akkor a DATUMnak is növekvőnek kell lennie.
Tehát ha ID1 < ID2 < ID3 < ID4 < ID5... akkor DATUM1 < DATUM2 < DATUM3 < DATUM4 < DATUM5... az elvárt állapot. Ezek alapján szerintem fölösleges a DATUM5-t mondjuk a DATUM2-vel hasonlítani, elég csak DATUM4-gyel, mert nem hiszem, hogy van olyan eset, hogy kisebb lenne DATUM2-nél de nagyobb mint DATUM4.
Szóval igen, ez csak egymás utáni párokat vizsgál, de szerintem ez elég.
Szmeby:
Én szeretem használni a WITH-et, mert jobban elszeparálja az egyes logikákat egymástól. Jelen esetben akkor a teljes LEAD-es részt bele kellett volna tenni a WHERE-be is, mert ugye ugyanazon queryn belül nem tudod a SELECT-ben megadott aliasokat a WHERE feltételben használni. Szóval így szebb és érthetőbb.
A next_id azért kellett, mert így látod, hogy melyik két egymást követ ID-nál van gond a dátumokkal. De elhagyható...Szerintem ez jóval gyorsabb (vagy csak "olcsóbb" ha nem nagy a tábla), mint egy Descartes szorzat. Én napi szinten használok analitikus SQL kifejezéseket millió soros táblákon Oracle-ben és szerintem nagyon jól optimalizált a futtató mögötte. Tény, hogy ebbe az Exadata is besegít.
-
-

martonx
veterán
válasz
bambano
#4607
üzenetére
Viszont nem csak postgresql van a világon (ami egyébként tényleg nem rossz). Data Science-ként sokszor nem is igazi sql-ből jönnek az adatok (lehet nosql, vagy data lake vagy bármi), azaz kell egy nyelv az sql-en kívül, amivel egységesen meg lehet valósítani a statisztikákat, elemzéseket.
-
martonx
veterán
válasz
bambano
#4603
üzenetére
hja, most nézem MSSQL is tud, a 2017-es verzió óta, csak valami fura okból PERCENTILE_DISC-nek hívják. Mindenesetre csak egy példát akartam hozni, hogy az SQL analitikus függvényei erősen korlátosak, próbálj meg ilyen-olyan eloszlásokat számolni velük, vonalakat illeszteni, azok meredekségét figyelni stb...
-
tm5
tag
válasz
bambano
#4600
üzenetére
Ez teljesen igaz és azt volt az első dolgom, hogy körbenézzek a cégnél, hogy milyen "dobozos" system monitoring cuccok vannak már beüzemelve(Grafana, ELK, stb.) , hogy ne az n+1-et telepítsem. Viszont egyik sem arra lett kitalálva, hogy azt monitorozza amit nekem kell.
Egy tesztelő kolléga már össze is rakott valamit regression teszt gyanánt pythonban.
Na ez megtetszett nekem és én is lejutottam oda, hogy akarok csinálni egy dashboardot a cuccaimnak. Na ebből lett az idei smart goal-om. Ha multinál dolgozol akkor érted, hogy mire gondolok.
Igen, DIY lesz, de mértékkel, mert az üzleti logikára akarok fókuszálni és nem az infrastruktúrára. De néha össze kell koszolni a kezünket, ha tanulni akarunk. -
válasz
bambano
#4544
üzenetére
Ki kell szednem a valid_from értékekből a legmagasabbat, ami kisebb vagy egyenlő, mint az aktuális dátum, majd ezek közül a legkisebb valid_to, ami nagyobb vagy egyenlő, mi ma. Ezt nekem nem szedte össze az sql server (tsql) egy select-ben.
Most ezt a rank() függvényt nézegettem.
-
-
nyunyu
félisten
válasz
bambano
#4472
üzenetére
Nem elég azt nézni, hogy benne van-e a dátum a calendarban, hanem azt is kéne nézni, hogy az extra nap milyen napnak számít, különben elveszted a soknapos ünnepek körül elcserélt szombati munkanapokat.
Ezért volt plusz egy oszlop az ügyfeleinknél használt naptár táblákban, ahova a munkanapcserés szombatokat is fel kellett vennem péntek értékkel, előtte pénteket meg csütörtökkel, amikor egy évre előre felvettem az ünnepnapokat.NOT IN vs LEFT JOIN?
Annak idején úgy tanultuk, hogy jobb az anti join teljesítménye, de nem tudom ez a mai DB kezelőknél mennyire áll még fenn.
Oracle optimalizálója alapból anti joinná alakítja a not in-t, hacsak nem tiltod meg neki, így ott már nincs különbség teljesítményben. -

bambano
titán
válasz
bambano
#4461
üzenetére
én erre jutottam:
1. generálom a következő napok dátumait
2. ebből kidobom, ami szerepel a calendar táblában
3. kilistázom a maradékból a munkanapokat, sorbarendezve
4. a listából az n. elemet lekérdezemamiben nagyon más: van generátor függvény, ami többek között dátum típusra is működik, és az ünnepeket egy not in subselect halmazzal szedem ki.
kb. így néz ki postgresql-ben:
select l.nap,date_part('dow',l.nap),to_char(l.nap,'YYYYMMDD') as kompaktdatum from(select date_trunc('day',generate_series(now()+'1 day'::interval,now()+'30 days'::interval,'1 day'::interval)) as nap ) lwhere l.nap not in (select distinct date from calendar where date>now()and date<now()+'30 days'::interval)and date_part('dow',l.nap) in (1,2,3,4,5) order by l.nap limit 1 offset 5; -
nyunyu
félisten
válasz
bambano
#4461
üzenetére
Oracle:
with extra_nap as (
select '20200410' datum, '7' nap from dual
union
select '20200413' datum, '7' nap from dual
union
select '20200501' datum, '7' nap from dual),
szamok as (
select level l
from dual
connect by level <= 1000),
datumok as
(select to_char(sysdate+l,'yyyymmdd') datum,
case when nvl(e.nap, to_char(sysdate+l,'d')) in ('1','2','3','4','5') --hétfő..péntek
then 'Y'
else 'N'
end munkanap
from szamok l
left join extra_nap e
on e.datum=to_char(sysdate+l,'yyyymmdd'))
select datum, row_number() over (order by datum) rn
from datumok
where munkanap='Y';Extra_nap "táblába" felvettem a nagypénteket, húsvéthétfőt, május elsejét vasárnapi munkarenddel.
Aztán legenerálom a következő 1000 nap dátumát, és melléteszek egy munkanap flaget, ami az extra_napban beállítottból vagy a hanyadik nap a héten értéktől függ.
Végül leválogatom a munkanapokat és melléteszek egy sorszámot, hogy ő hanyadik. -
#4462
 Apollo17hu
őstag
bambano
#4461
Apollo17hu
őstag
bambano
#4461
Apollo17hu
őstag
válasz
bambano
#4461
üzenetére
Fognám a calendar táblát, raknék rá egy "nagyobb, mint a bemenő dátum" ÉS "legyen munkanap" szűrést, majd a kapott halmazon valamilyen rank() függvénnyel (van ilyen postgresql-ben?) egy sorszám mezőt generálnék, ami dátum szerint növekvő sorrendben osztaná ki a sorszámot. Ahol a sorszám n, az a keresett dátum.
Ehhez mondjuk az is kell, hogy az ünnepnapokból és a munkanap áthelyezésekből rendelkezésre álljon egy munkanap flag ['I', 'N'] is. Ha ilyen nincs, azt mondjuk egy CASE WHEN-nel külön le kell még kezelni.
-

Laca0
addikt
válasz
bambano
#4435
üzenetére
PgadminIII-ban szerettem volna ezt a műveletet elvégezni úgy, hogy már csatlakozva vagyok a szerverhez. A dblink-nek csak adatbázis paramétert adtam meg, mert ugyanaz a connection. De igazából fel sem ismerte a D link függvényt/eljárást. Szerintem ez alapból nem része a rendszernek.
-

kw3v865
senior tag
válasz
bambano
#4392
üzenetére
Köszönöm mindkettőtöknek a válaszokat! Több érdekes dolgot írtatok, az API-s megoldást elvetném, mert nem sok fogalmam van róla. Kicsit bővebben is kifejtem, mi lenne a cél: adott néhány kliens gép (jelenleg 3-4 db), ezek folyamatosan gyűjtik az adatokat és eltárolják egy táblában (localhoston). A cél az lenne, hogy szinkronizálni lehessen ezeket, azaz minden egyes gépen futó szoftver elérhesse (read only) a többi által rögzített táblák tartalmát. A szinkronizációnak nem szükséges valós időben megtörténnie, hiszen az is előfordulhat, hogy éppen nincs internet elérésük (földrajzilag mozgásban vannak a gépek). A gyakorlatban ez úgy nézne ki, hogy ha végeztek egy adott feladattal, akkor történne meg a szinkronizálás (néhány óránként).
Így, hogy alaposabban is tágondoltam, tulajdonképpen nem is szükséges ehhez, hogy PostgreSQL fusson a szerveren, ha az rsync-es megoldást használnám. Persze lenne egy szerver, melyre szinkronizálva lennének a táblák, és a kliensek innen szednék le a frissített txt-ket is, és ezután lennének frissítve a táblák a klieneseken. Vajon ez így működhet?







 .
.  .
.

![;]](http://cdn.rios.hu/dl/s/v1.gif)

































Új hozzászólás Aktív témák
Hirdetés
- Kertészet, mezőgazdaság topik
- Folyószámla, bankszámla, bankváltás, külföldi kártyahasználat
- Rövid időre leállhat a 8 GB-os GeForce RTX 5060 Ti gyártása
- Mobil flották
- Ha Darwinra hallgat az AI, nehéz lesz megállítani
- Gitáros topic
- Luck Dragon: Asszociációs játék. :)
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- Autós topik
- OLED monitor topic
- További aktív témák...
- Apple Watch Ultra 2 GPS + Cellular, 49 mm újszerű titán zöld-szürke BKNTATLAN terep pánt! Akku 99%!
- XFX RX 9070 XT 16GB GDDR6 SWIFT Triple Fan Gaming Edition - Új, 2 év gari - Eladó!
- MacBook Pro 14" M3 Pro /11C/14C/18GB/1024GB/ 100% Akku / 2027.12-ig garancia
- Honor Magic 8 Pro 512GB Black Karcmentes! Ajándék 100 Wattos SuperCharge töltő!
- iPad 9th gen 64GB space grey
- Geforce GTX 1050, 1050 Ti, 1060, 1650, 1660 / GT 1030 - Low profile is (LP)
- BESZÁMÍTÁS! Microsoft XBOX Series S 512GB játékkonzol garanciával hibátlan működéssel
- ÁRGARANCIA!Épített KomPhone i9 14900KF 32/64GB RAM RTX 5070 Ti 16GB GAMER PC termékbeszámítással
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5700X 32/64GB RAM RTX 5060 Ti 8GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! Asus Z390 i7 9700 32GB DDR4 512GB SSD RTX 2070 Super 8GB Phanteks Eclipse P360A 650W
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest