Hirdetés
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- Hieronymus: Hogyan parkolj hátramenetben profi módon
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- NvidiaRTX: Xiaomi Electric Scooter 6 Max: Az első rollerem
- Luck Dragon: MárkaLánc
- Wiz Khalifa: Grand Theft Auto V - Látványosságok és érdekességek tárháza egy helyen!
- sziku69: Szólánc.
- ubyegon2: Airfryer XL XXL forrólevegős sütő gyakorlati tanácsok, ötletek, receptek
- eBay-es kütyük kis pénzért
Új hozzászólás Aktív témák
-
#4400
 Apollo17hu
őstag
BuktaSzaki
#4399
Apollo17hu
őstag
BuktaSzaki
#4399
Apollo17hu
őstag
válasz
 BuktaSzaki
#4399
üzenetére
BuktaSzaki
#4399
üzenetére
Akkor, amit #4397 -ben írtál, az rendben van. Vagy nem értem. Példák kellenének.
-

BuktaSzaki
tag
válasz
 Apollo17hu
#4398
üzenetére
Apollo17hu
#4398
üzenetére
Több szerződésen is rajta lehetnek, de csak 1x
-
#4398
Apollo17hu
őstag
BuktaSzaki
#4397
Apollo17hu
őstag
válasz
BuktaSzaki
#4397
üzenetére
Pontosan mi a kodod? Nem lehet, hogy vannak olyan szolgaltatasok, amelyek - azon felul, hogy hibasan duplikalva vannak bizonyos szerzodesekhez - tobb szerzodeshez is kapcsolodnak?
-
BuktaSzaki
tag
válasz
Apollo17hu
#4396
üzenetére
Szia, köszi, én is erre gondoltam, de valamiért nem működik. Most olyanokat ad vissza, hogy egy szolgazon többször fordul elő, de nem ugyanazon a szerzodeszam-on, hanem az összesen
-
#4396
Apollo17hu
őstag
BuktaSzaki
#4395
Apollo17hu
őstag
válasz
BuktaSzaki
#4395
üzenetére
SELECT tabla.szerzszam, tabla.szolgazonFROM tablaGROUP BY tabla.szerzszam, tabla.szolgazonHAVING COUNT(*) > 1Ezzel azokat is megkapod, ha 2-nél többször van hozzárendelve ugyanaz a szolgáltatás.
-
#4395
BuktaSzaki
tag
BuktaSzaki
tag
Sziasztok, egy kis sql help kéne.
Adott egy tábla amiben szerződésszámok vannak. ezekhez tartoznak szolgáltatások, egy szerződéshez akármennyi, ezeknek van egy azonosítója. azokat a szerződésszámokat szeretném leszűrni, ahol (hibásan) egy szerződéshez 2x van egy szolgáltatás hozzárendelve (azonos az szol. azonjuk) -

kw3v865
senior tag
válasz
 bambano
#4392
üzenetére
bambano
#4392
üzenetére
Köszönöm mindkettőtöknek a válaszokat! Több érdekes dolgot írtatok, az API-s megoldást elvetném, mert nem sok fogalmam van róla. Kicsit bővebben is kifejtem, mi lenne a cél: adott néhány kliens gép (jelenleg 3-4 db), ezek folyamatosan gyűjtik az adatokat és eltárolják egy táblában (localhoston). A cél az lenne, hogy szinkronizálni lehessen ezeket, azaz minden egyes gépen futó szoftver elérhesse (read only) a többi által rögzített táblák tartalmát. A szinkronizációnak nem szükséges valós időben megtörténnie, hiszen az is előfordulhat, hogy éppen nincs internet elérésük (földrajzilag mozgásban vannak a gépek). A gyakorlatban ez úgy nézne ki, hogy ha végeztek egy adott feladattal, akkor történne meg a szinkronizálás (néhány óránként).
Így, hogy alaposabban is tágondoltam, tulajdonképpen nem is szükséges ehhez, hogy PostgreSQL fusson a szerveren, ha az rsync-es megoldást használnám. Persze lenne egy szerver, melyre szinkronizálva lennének a táblák, és a kliensek innen szednék le a frissített txt-ket is, és ezután lennének frissítve a táblák a klieneseken. Vajon ez így működhet?
-

bambano
titán
válasz
 kw3v865
#4390
üzenetére
kw3v865
#4390
üzenetére
a postgresql is tud olyat, hogy ip címre vagy tartományra korlátozni a klienseket, illetve ugyanezt tűzfallal is meg lehet oldani. ez akkor jó, ha a klienseknek ismert az ip címtartománya.
elvileg használ ssl-t, tehát akár azt is meg lehet csinálni, hogy csak ismert kulcsú klienseket beengedni.
hogy ez mennyire biztonságos, az attól is függ, hogy milyen adatokat teszel bele.
a másik lehetőség, én valószínűleg ezt választanám, hogy az insert utasításokat kiírom egy text fájlba, azt rsync+ssh-val szinkronizálnám a szerverre, és ott betölteném adatbázisba.
A db-ben hosztolt adatbázisról meg annyit, hogy a benne tárolt adatok fajtájától és a hozzá tartozó szabályzatoktól, eljárásrendtől függően (úgy értem: ezek nem elegendően precíz meghatározása esetén) akár 2 év börtönnel fenyegetett bűncselekmény is lehet felhőbe adatbázist rakni.
Az api api hátán api-val megbolondítva típusú túltervezettségről továbbra is az a véleményem, hogy semmi értelme, mert egy saját fejlesztésű apiban nagyobb valószínűséggel lesz bug, mint egy postgresql net protokollban, vagyis olyan plusz energiabefektetés, ami sose térül meg, csak ront a helyzeten.
-
-
kw3v865
senior tag
Sziasztok!
Fejlesztek egy alkalmazást (C#-ban, WinForm-os alkalmazás, Npgsql NuGet package használatával), amely a működése során a localhost-on lévő PostgreSQL adatbázisba ír adatokat (insert-el egy táblába). Jelenleg ez teljesen offline módon történik. Azonban felmerült egy olyan igény, hogy ez egy távoli PostgreSQL szervhez tudjon kapcsolódni, azaz ne kelljen állandóan menteni a táblákat, majd átvinni a másik gépre és ott betölteni, hanem közvetlenül a távoli adatbázishoz tudjon kapcsolódni.
Szerintetek ez mennyire biztonságos megoldás, ha "kiengedem" a netre a pg-t? Sajnos ilyen téren nincsenek tapasztalataim. Ebben az esetben mit javasolnátok? Esetleg VPN-nel biztonságos tudna lenni? -

Petium001
csendes tag
-
kw3v865
senior tag
Üdv!
Van egy PostgreSQL-ben megírt függvényem (ennek tartalma most szerintem lényegtelen), melynek a teljesítményét kívánom tesztelni. Ez a függvény meg lesz majd hívva folyamatosan egymás után több ezerszer, értelemszerűen változó argumentumokkal. Ennek a teljesítményét szeretném most tesztelni. A lényeg: valahogy szimulálni akarom, hogy a valóságban nagyjából milyen gyorsan fut majd le a folyamat, ha több 1000-szer meghívom egymás után a függvényt.
Ehhez rendelkezésemre áll egy tábla, melyben a benne lévő adatokkal tudnám is tesztelni a függvényt. Tehát a terv az lenne, hogy írok egy függvényt, ami végigmegy egy FOR-ral az összes rekordon, kiszedi a felhasznákalandó értékeket változókba, és minden alkalommal meghívja a függvényemet úgy, hogy argumentumként ezeket a változókat adom meg.Szerintetek jó az elgondolás?
Íme kódom:
CREATE OR REPLACE FUNCTION sqlteszt()RETURNS voidLANGUAGE 'plpgsql'AS $BODY$DECLAREi integer;x double precision;y double precision;datetime timestamp without time zone;BEGINFOR i IN SELECT id FROM probaLOOPSELECT p.x, p.y, p.datetime FROM proba p WHERE p.id=iINTO x, y, weedpercent, datetime;PERFORM masikfuggveny(x,y,datetime,true,false,false,true,false);END LOOP;END;$BODY$;
Nem csinál semmit így, azaz lefut, de semmi hatása nincs (egyébként insert-eket is csinál, de az most lényegtelen). Ha a "masikfuggveny"-t csak simán meghívom tetszőleges bemeneti paraméterekkel, akkor tökéletesen működik.
Ha a PERFORM helyett SELECT-tel hívom meg a "masikfuggveny"-t, akkor ezt a hibaüzenetet kapom (pedig az is void, azaz nincs visszatérési értéke):
ERROR: query has no destination for result data
HINT: If you want to discard the results of a SELECT, use PERFORM instead.Van valami ötletetek mi okozhatja a problémát?
-
Petium001
csendes tag
válasz
 baracsi
#4364
üzenetére
baracsi
#4364
üzenetére
Szia!
7végenként van időm a gép elé kerülni, letöltöttem egy live ubuntu-t és pendrive-ről elindítottam, bejön a desktop, amikor rákattintottam a hdd-re (38 gb volume) az írta, nem lehet hozzáférni, nincs jogosultságom...
 újraindítottam a linuxot, és be tudtam lépni.
újraindítottam a linuxot, és be tudtam lépni.
az első olyan lehetőség [mysqld] alá ami volt beírtam askip-grant-tablesszöveget
"3. indítsd újra a MySQL szolgáltatást:/etc/init.d mysql restart" ezt hol? -

Lortech
addikt
válasz
kw3v865
#4380
üzenetére
Mert a formatos megoldásod dollar quotingot használ, ami a jobban olvasható, biztosabb, egyszóval a javasolt megoldás.
Ha visszamegyünk az eredeti statikus, működő insert statementedhez:
INSERT INTO tesztsema.table (azonosito, nev) SELECT 2332,'xyz';
Az volt a cél, hogy ezt a stringet dinamikusan előállítsd, és átadd az EXECUTE statementnek.
Azt pedig úgy tudod megtenni, hogy aposztrófokat is odateszed a példában az xyz köré.
A '||name csak annyit csinál, hogy a name értékét hozzáfűzi a stringhez, de aposztrófok ettől még nem lesznek körülötte, és text típusnál ez szükséges. Szóval, vagy te fűzöd oda (nem javasolt, csak a probléma megértéséért említettem az előző hozzászólásomban), vagy dollar quotingot vagy quote_literal() / quote_ident() fgv-t használsz.Másikhoz. Ilyen szerkezet nincs, hogy IF EXECUTE
Olyan tudsz csinálni, hogy
EXECUTE STATEMENT into VAR és a VAR értékét vizsgálod IF-fel. -
kw3v865
senior tag
válasz
 Lortech
#4379
üzenetére
Lortech
#4379
üzenetére
Köszi, igaz azóta már találtam egy megoldást, format-tal, nem túl szép megoldás, de működik:
EXECUTE format('INSERT INTO '||$1||'.table(azonosito, nev) VALUES($1,$2);') using id, name;Egyébként a te megoldásodhoz miért kell aposztróf, ha egy változóról van szó? Tehát nem közvetlenül értékeket illesztek be, hanem változónak a nevét írom be.
Ami viszont ismét kifogott rajtam, az egy függvényargumentumban megadott nevű séma (plusz a benne lévő fix nevű tábla) létezésének ellenőrzése.
IF (EXECUTE 'SELECT to_regclass('''||$1||'.tablename'')')
ERROR: type "execute" does not exist
Tehát már az eleje is rossz.
Mit ronthattam el? -
Lortech
addikt
válasz
kw3v865
#4377
üzenetére
'INSERT INTO '||$1||'.table (azonosito, nev) SELECT '||id||','||name;
>>
kiértékelés után: INSERT INTO abc.table (azonosito, nev) SELECT id_erteke, name_erteke;
Hiányzik tehát id és name változó értékei körül az aposztróf, különben azt hiszi, hogy nem egy literál, hanem egy oszlop, azért nem találja. (az id azért oké, mert number típus gondolom)
Aposztróf escape-eléséhez duplázni kell. -
kw3v865
senior tag
Sziasztok!
PostgreSQL-ben írok egy függvényt, melynek az egyik insert-jével van probléma, de nem tudok rájönni, hogy mi ennek az oka. Azért kell az execute, mert a séma neve a függvény egyik bemenő paramétere ($1). Az id és a name pedig változók.
EXECUTE 'INSERT INTO '||$1||'.table (azonosito, nev) SELECT '||id||','||name;Ezt a hibaüzenetet kapom: column "xyz" does not exist (itt az "xyz" a name változó értéke)
SQL state: 42703Ha függvényen kívül csak simán lefuttatom ezt:
INSERT INTO tesztsema.table (azonosito, nev) SELECT 2332,'xyz';Akkor tökéletesen működik.
Vajon mi lehet a gond?
-

Male
nagyúr
válasz
baracsi
#4375
üzenetére
Win alól utoljára én is több éve csináltam ilyet, akkor még ext2fs kellett hozzá, meg volt valami totalcommander plugin, amivel fel lehetett csatolni a linuxos partíciót win alól is.... de az talán csak olvasni tudott. Szóval ebben olyan sokat én sem tudok hozzátenni, lehegy, hogy a Live Linux egyszerűbb lenne, bebootolja, és onnan írkál rá.
-

martonx
veterán
Úgy hogy ezek mögött valójában cégek vannak / olyan felhasználó cégek akik a supportért fizetnek.
Azaz attól, hogy magából a szoftver licenszből nincs bevételük, még egy csomó mindenből lehet.
Lásd Firefox böngésző, ahol a Mozilla abból létezik, hogy google / Microsoft időnként beléjük tol pár millió EUR - t.
-
kw3v865
senior tag
Sziasztok!
PostgreSQL-ből szeretnék sémát exportálni pg_dump-pal. Annyi bonyolultság van, hogy a pg_dump.exe-t egy C#-ban megírt alkalmazás indítja el. A cél az lenne, hogy tudassam a felhasználóval, hogy sikeres volt-e a dump-olás. Van-e arra lehetőség, hogy kiírja a pd_dump az exit code-ot?
"-v"-vel kiír sok mindent, de vajon lehet-e olyat csinálni, hogy exit code 0 vagy 1-et kiírjon?
Vagy másképpen megközelítve a dolgot: ha "-v" nélkül futtatom és sikeresen lefut az exportálás, akkor nem ír ki semmit. Erre lehetne alapozni? Azaz, ha nem ír ki semmit, akkor tekinthető sikeresnek az exportálás? -

baracsi
tag
válasz
 Petium001
#4365
üzenetére
Petium001
#4365
üzenetére
Szia,
lehet kívülről, de csak akkor ha ez nincs benne a my.cnf-ben, vagy ki van kommentezve:
bind-address=127.0.0.1, ugyanis ha benne van, akkor csak localhost-on lehet csatlakozni (web-szervereknél van értelme, nem lehet kívülről támadni a MySQL-t)Tölts le egy MySQL GUI Tools-t, ez egy régi program, annak a MySQL Administrator programjával próbálj meg csatlakozni a linux által kapott IP-címre, szerencséd van, akkor a port-ot nem változtatták
ha az sem megy és nem tudod szerkeszteni a my.cnf-et, akkor aki írta, az a sírba vitt magával minden info-t, ami szükséges
ha sikerült, akkor az alábbi módon tudod javítani
1. bal oldal válaszd ki a
boressémát a Schemata rész alatt
2. táblán jobb klikk Maintenance \ Repair table, egyébként piros lesz ez a tábla a listában, mert sérült szegény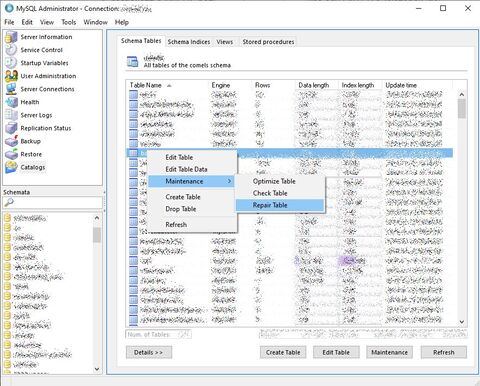
-
Petium001
csendes tag
-
baracsi
tag
válasz
Petium001
#4363
üzenetére
Ennek semmi köze a szoftverhez, SHIFT meg recovery menü feltételezem a szofftver szolgáltatása, azt biztos, hogy nem a MySQL-é. A cél a MySQL-ben található sérült tábla rendbetétele.
1. keresd meg a linux-on a MySQL konfig fájlját, ez alapból
/etc/mysql/my.cnf, de lehet, hogy azon a gépen máshol van, ezt neked kell kideríteni
2. szerkeszd a konfig-fájlt és keresd meg a [mysqld] részt és alá írd be askip-grant-tablesszöveget
3. indítsd újra a MySQL szolgáltatást:/etc/init.d mysql restart
4. csatlakozz a MySQL-hez:mysql -u root -püss egy ENTER-t, jelszónak írjál be valamit, mindegy, hogy mit, mert askip-grant-tablesmiatt nem fog foglalkozni a jelszó ellenőrzésével
5. írd be eztuse boresmajd üss egy ENTER-t, a hibaüzenet aboressématetelnevű táblájára vonatkozik
6. írd be eztREPAIR TABLE tetel;majd üss egy ENTER-tHa működik a szoftver ezt követően, akkor szedd ki a
skip-grant-tablesrészt és ismét indítsd újra a MySQL szolgáltatást -
Petium001
csendes tag
válasz
baracsi
#4362
üzenetére
Köszi

Na ez nekem magas mint békának a hokedli... hogy jutok el a
skip-grant-tablesbeállításhoz? a recovery menüig jutok el max, oda is csak 10-ből 1x mert nem tudom mikor kell a shift-et nyomni... ott azután végleg megáll a tudomány én csak a winfost nyúzom 99%-ban Köszi
-
baracsi
tag
válasz
Petium001
#4359
üzenetére
el tudod indítani a MySQL-t úgy, hogy nem fog kérni autorizációs adatokat, illetve kér, de bármit megadhatsz
skip-grant-tablesbeállításnak nézz utána, ezt lehet parancssorosan is megadni, de be tudod állítani az /etc/mysql/my.cnf részben is (írtad, hogy linux-ról van szó, de lehet, hogy ott máshol van a config fájl), utána újra kell indítani a mysql service-t, ezt követően bármilyen login névvel / jelszóval be tudsz lépni, rá tudod engedni arepair table-t, után szerintem érdemes kivenni a beállítást, hogy ne tudja más hack-elni[mysqld]
skip-grant-tables
port=3306 -
Male
nagyúr
válasz
bambano
#4360
üzenetére
Ha a neten van, és nem tudja az elérhetőséget meg a user/passt, mert hardkódolva van a programban? Legalábbis feltételezem, hogy a program felhasználói felülete nem olyan, hogy a pincérek gépelgethetik be az SQL utasításokat, és egy sima config szövegfile sem tuti hogy van ezekről amiből kinézhetné.
...de már lényegtelen, mert kiderült, a gépen van az SQL szerver nála. -
Petium001
csendes tag
A Mysql-nek rajta kell lennie, nincs net csatlakozás, volt, hogy napokig nem volt internet, és működött... viszont finn gomb sincs hogyan kell elindítani a repair table-t....
ha lenne command, mint a winfosban vagy valami, akkor oké, de a shift-re csak a recovery menü jön ki, a root passt nem tudom, a net-dinner-re keresve semmi nem jön elő a neten, csak egy cég aki azt sem tudja miről van szó....nem ők írták a szoftvert, pedig ilyennel foglalkoznak. Olyan, mintha böngészőre lenne írva a szoftver. Az eredeti üzemeltetők közül az első meghalt, a második eltűnt. -
Male
nagyúr
-

Ispy
nagyúr
Szerintem ilyenkor nem natív formátumban van tárolva az adat, de az sql szerver felismeri és átkonvertálja, ezért jó a datediff.
Én is tapasztaltam már sebesség problémát, amikor nvarchart simán számként használtam, ha ' jelek közé raktam javult a sebessége, de gondolom akkor a leggyorsabb, ha nem kell találgatnia a motornak az adattípust.
-
válasz
 sztanozs
#4349
üzenetére
sztanozs
#4349
üzenetére
Mire gondolsz dátumaritmetikán pontosan?
Azért kérdezem, mert kipróbáltam, hogy varchar típusú oszlopokban tároltam dátumokat és hiba nélkül működött rajta a DATEDIFF.
Erre gondoltam:
create table #tmp (dátum1 varchar(50), dátum2 varchar(50))insert into #tmp (dátum1 , dátum2)values ('2019.11.01', '2019.11.02'),('2019.11.01', '2019.11.03'),('2019.11.01', '2019.11.04')select dátum1, dátum2, datediff(day,dátum1,dátum2) from #tmpHa butaságot kérdeztem, akkor elnézést kérek

-
#4347
Apollo17hu
őstag
Apollo17hu
őstag
Igen, fenn van az XE, és egyelőre a célnak megfelel. Köszönöm az eddigi segítséget mindenkinek, jövök még a topikba, ha elakadok.

-
#4344
 bpx
őstag
Apollo17hu
#4342
bpx
őstag
Apollo17hu
#4342
bpx
őstag
válasz
Apollo17hu
#4342
üzenetére
Ha az XE helyett felraksz egy EE-t, akkor lesz lehetőséged olyan hagyományos típusú adatbázist létrehozni, amit mindenki más is használ, és amivel a felesleges szívástól megkíméled magad. Kivéve, ha a CDB/PDB világ érdekel.
Az XE-nek saját kísérletezős vagy development környezetben nem látom értelmét. Erre az EE is letölthető és használható licenc nélkül, és abban legalább nincsenek korlátozások.
-
#4342
Apollo17hu
őstag
bpx
#4341
Apollo17hu
őstag
Guglizás közben olvastam a container és a pluggable database-ről, de - ahogy írod is - fogalmam sem volt, hogy lehetne normálisan beállítani.
Nincs Linux ismeretem. Akkor azt mondod, hogyha XE helyett EE-t rakom fel, sokkal egyszerűbben hozzáférek majd a sample schema-khoz? Éjjel már ott tartottam, hogy a zippelt HR-sémát githubról töltöm le, csak az importálásnál megint falakba ütköztem.
-
#4341
bpx
őstag
Apollo17hu
#4340
bpx
őstag
válasz
Apollo17hu
#4340
üzenetére
Na nem, annyira tudtam már tegnap, amikor olvastam az XE-t, hogy ez lesz.
Az Oracle a 12.1-től (6 éve) bevezette a container database architektúrát, de senki nem használja, mert extra licenc költsége van, de nincs akkora hozzáadott értéke, hogy megérje.
Ehhez képest az Oracle, amit csinál az XE-vel meg a Developer VM-ekkel, az az öntökönrúgás kategória, erőlteti a container database-t, miközben ha egy kezdő bármilyen problémára rákeres neten, még mindig a nem container database-es megoldásokat látja, vagy gányolást.
Nem, te a root conatinerbe léptél be, és common usert próbáltál létrehozni (ehhez kell a C## prefix), erre nem az a megoldás, hogy lefuttattod az 'alter session set "_oracle_script"=true;' és úgy hozod létre a usert, csak sajnos az itt kapott hibára ez a Google első találat. Meg ugye rögtön DBA role csak a belépéshez, hogyne.
Pl. egy SQL Server-es analógiával élve: a masterdb-be gányoltál bele és oda készülsz betölteni user adatokat.
Csak az SQL Servernél már régóta van masterdb és mellette más adatbázisok, mindenki tudja mit hova tegyen (remélem), az Oracle-nél meg még csak most terjed ez az architektúra.
Nem, ilyet nem csinálunk, eleve rossz helyre csatlakoztál. Neked nem a root containerhez kell csatlakozni (service = xe), hanem az automatikuson létrehozott pluggable database-hez (service = xepdb1), és azon belül kell dolgozod. Persze ezt még a Oracle a saját doksijában sem írja le normálisan, ott is a root containerhez való csatlakozást mutatja példának.
Ez nem a te hibád, egy kezdő ezeket nem tudja, de a doksi nem jó, a Google meg a régi módszereket adja megoldásnak.Ha Oracle adatbázissal akarsz foglalkozni, akkor mondom, hogy mit ajánlok.
Elfelejted az XE-t, az Enterprise Edition is letölthető, arra ingyen használható, hogy otthon egyedül tanulj rajta (és az XE is egy több GB-os monstrum).
Magamnak a host OS-re sem telepíteném (meg Windowsra sem). VirtualBox, abba egy Oracle Linux, és arra mehet a 19c EE telepítése.
Ehhez alapvető Linux, virtualizáció, networking ismeretek kellenek, ha ez hiányzik, akkor simán csak telepítsd fel a gépedre és használd ott.
Az adatbázis létrehozásánál pedig ne válassz container database-t, és ha nem akarod magad tovább szivatni, akkor General Purpose template-ből csinálsz adatbázist. Ilyet egy valós rendszeren nem csinálunk, de most pont jó lesz arra, hogy felrakjon minden szemetet, ami a sample schema-khoz kell. Ugyanitt még ne válassz ki semmilyen sample schema hozzáadást.
A sample schema-k teljes halmaza már nem jön az adatbázissal, azokat githubról lehet letölteni és utólag telepíteni. -
#4340
Apollo17hu
őstag
updog
#4339
Apollo17hu
őstag
Azért ez eléggé nem volt triviális, hogy először system-ként kell csatlakozni, majd azzal létrehozni egy felhasználót magamnak.
Rögtön két problémába is ütköztem: először nem engedett felhasználót létrehozni, mert valami prefix (C##) gondja volt. Erre ki kellett adnom egy ALTER SESSION utasítást, és így már lefutott a CREATE USER. Viszont azt sem tudtam, hogy ennek a felhasználónak külön dba jogokat is kell adnom, hogy csatlakozni tudjak vele. Most már szerencsére ez is rendben van.
Következő lépésként felkutatom a HR sémát, és utánajárok, hogy lehet felrakni, mert egyelőre ezzel is meg vagyok lőve.
-
#4339
 updog
őstag
Apollo17hu
#4338
updog
őstag
Apollo17hu
#4338
updog
őstag
válasz
Apollo17hu
#4338
üzenetére
SYS vs SYSTEM - lényegében a saját user létrehozásán kívül ne nagyon használd ezeket
Ha a minta sémákat (HR, OE ilyenek) felraktad, akkor azokkal csatlakozhatsz (lényegében séma = user), amúgy nem nagyon van más user (SYS-szel futtatva SELECT * FROM ALL_USERS;megmutatja).A PDADMIN gondolom valami hasonló a PDB-k kezelésére, de mivel 11g óta nem használtam Oracle-t erről nem tudok nyilatkozni és gyors google nem segített
 .
.SQL Developeren szerencsére semmit nem kell beállítani egy darab connection hozzáadásán kívül, és igen, utána mókolhatsz
-
#4338
Apollo17hu
őstag
Apollo17hu
őstag
Letöltöttem és telepítettem az Oracle XE-t. Eddig tényleg egyszerű volt. Néztem a tutorialban, hogy próbaként csatlakozni kéne a szerverhez. Ez sokadjára, de összejött a SYSTEM userrel. Mi a különbség SYS, SYSTEM és PDADMIN között? Van még ezeken kívül olyan user, amivel csatlakozni lehet? (újat még nem hoztam létre) Valami olyasmit is olvastam, hogy a Windows useremnek automatikusan létrehoz egy Oracle felhasználót, de azzal nem tudtam belépni.
Következő lépés az SQL Developer letöltése és beállítása, és onnantól már van egy barátságos környezetem, amiben mókolhatok?
-
#4337
updog
őstag
Apollo17hu
#4335
updog
őstag
válasz
Apollo17hu
#4335
üzenetére
Egy Oracle XE kicsit overkill lehet pár táblás projektre, inkább mysql-t mondanék vagy sqlite-ot. De az Oracle-lel sincs baj ha nem egy krumpli a géped (régebbi laptopomat pl. kicsit megfektette ha service-ként futott automatikusan indítva).
Amire te gondolsz próbaverzió alatt, az szerintem az a PLSQL Developer, ami tényleg fizetős (ez ugye csak egy IDE), de ez független az adatbázistól, és az Oraclenek is van erre teljesen ingyenes megoldása (Oracle SQL Developer, ami egyébként több fajta DB-hez is csatlakozik nem csak Oracle-hez).
Amúgy az Oracle DB-ből akár az Enterprise-t is felrakhatod magadnak ingyen, korlátozás nélkül az összes feature-rel, ha csak otthon használod saját projektre
Na de az tényleg overkill lenne 
-
#4336
 Ablakos
addikt
Apollo17hu
#4335
Ablakos
addikt
Apollo17hu
#4335
Ablakos
addikt
válasz
Apollo17hu
#4335
üzenetére
Windowsban az oracleXe telepítés mondhatni triviális. Még default sémát is kapsz. Feltöltve minta rekordokkal.
-
#4335
Apollo17hu
őstag
Apollo17hu
őstag
Otthoni PC-re (Win10) milyen megoldást ajánlanátok, ha szeretnék egy saját adatbázist üzemeltetni? Egyelőre csak létrehoznék néhány táblát, amiket feltöltenék adatokkal, és lekérdezéseket írogatnék.
Melóban eddig Oracle adatbázissal dolgoztam PL/SQL Developer környezetben, de úgy láttam, hogy ezeknek legfeljebb 1 hónapos trial verziója érhető el.
Semmilyen tapasztalatom nincs szerver telepítésében, oktatóvideók linkjét is szívesen fogadom. -
Male
nagyúr
válasz
 martonx
#4333
üzenetére
martonx
#4333
üzenetére
Közben meglett a válasz: Igen. Azt hittem, hogy itt is van limit, mint a PHP esetén, hogy pl 60s után annyi, nem fut tovább... de nem, az SQL lekérés 20 perce futott, és mivel állandóan újat is küldtek, így persze belefutott az össz. limitbe, és vége lett mindennek.
Végül kiküldték mi volt az utolsó három SQL lekérés, ami beragadt, aminél kiakadt... és így megtaláltam, mert már látványra is vacak volt, de localon lepróbálva az adatbázis másolaton is iszonyat ideig futott (kb 20 perc után kilőttem).
Csak véletlen egybeesés volt a tárhely váltással, hogy most jelentkezett, máshogy használták (egy olyan módon, amit eleve beépíteni sem akartam, mert mondtam, hogy ebből teljesítmény gond lesz, de kikövetelték... de nem használták, és közben az évek során annyira megnőtt az adatok mennyisége, hogy nem pár másodperces lefutás lett, hanem fél órás, mire elkezdték így használni). Végül elcsesztem rá fél napot, de sikerült optimalizálni a lekérést, és így leszorítani 0.4 másodpercre (Jó, amikor írtam 4 éve az eredetit, akkor kevesebbet is tudtam, ma már elve nem úgy írnám meg.) -
martonx
veterán
Olyat kérdezel tőlünk, amit rajtad és a szerver üzemeltetőkön kívül senki se tudhat, noha megértem, hogy tanácstalan vagy.
Ha időközben szerver csere történt, akkor persze van egy csomó ismeretlen a képletben (változott-e PHP verzió, csomagok verziója, MySQL verzió, ezek konfigurációi stb...) Ezek bármelyike okozhat bármilyen mellékhatást. Remélem segítettem. -
Male
nagyúr
válasz
sztanozs
#4331
üzenetére
Az kb kizárt... egyrészt le van védve rendesen (nem mondom, hogy nem hibázhatok, de odafigyeltem az ilyesmire, és át is néztem), másrészt ez nem egy weboldal, csak a kezelőknek van hozzáférésük, ami 7 embert jelent, és ezzel dolgoznak, nem nyírják ki a saját bevételüket (ha nem őrültek meg
). -
Male
nagyúr
Inkább működtetési kérdésem lenne: A tárhely totál beterhelődött, "resource limit reached" hibaoldal jött be minden oldal helyett. A szolgáltató szerint: "Egy beragadt MySQL query-t találtunk ami az alábbi adatbázishoz tartozott: ********. Ezt a folyamatot kilőttük, így a weboldal jelenleg betölt."
Most tényleg működik is. A kérdés, hogy ezt okozhatja-e egy SQL lekérés, ami túl sok erőforrást használna, túl összetett, túl sok az adat, stb... vagy ez nem fordulhat elő úgy, hogy a komplett tárhelyet túlterheli egyetlen query, és egy fél órára leáll az egész... amíg ki nem lövik?
A lényeg, hogy ezért okolható-e a kód, vagy itt tuti valami a szerverrel nem stimmel?
Előzmény:
Előtte két órával a PHP folyamatok ragadtak be sorban szerintük... akkor kikapcsolták az FPM-et, ami meg is oldotta vagy két percre a problémát, és ismét lehalt... akkor simán PHP folyamatok beragadására hivatkoztak.
Mindezt egy olyan kóddal, ami egy éve változatlan, és eddig, igaz a másik szerverükön, de hibátlanul futott... az adatbázis nem olyan kicsi, a legnagyobb táblában 5+ millió sor van, de a régi szerverükön elvileg kevesebb volt az erőforrás, és az újon meg mondjuk 200 sorral van benne több, tehát nem nőhetett a terhelés ettől. -

zolynet
veterán
-
zolynet
veterán
Sziasztok,
http://sqlfiddle.com/#!4/b9869/3/0
Hogy kellene megírni az sql-t hogy csak a város nevét adja vissza?
Banális, de valahogy nem jövök rá.
-
-
Van egy adatbázisom, amiben egy tábla, és abban egy oszlopban lévő adott értékre szeretnék szűrni, azonban valamiért nem megy.
Adatbázis neve: db
Tábla neve: wp_sitemeta
Oszlop neve: meta_value
Amit keresek az oszlopban: site_adminsA parancs, amit futtatok:
SELECT meta_value FROM wp_sitemeta WHERE meta_key = site_adminsElszáll ezzel a hibával:
ERROR 1054 (42S22) at line 1: Unknown column 'site_admins' in 'where clause'Mit csinálok rosszul?
-

haxiboy
veterán
válasz
sztanozs
#4319
üzenetére
Ha nem kéne másik rangere tenni a fieldeket/táblákat. Vagy nem kéne megtartani a sok adatot nem lenne gond 😅
A fieldek számozása egyébként a különböző partnerek fejlesztéseinek van fenntartva, de természetesen két azonos nevű Field egy táblában nem lehetséges. Szokott is probléma lenni ebből ha másik partnertől érkezik az ügyfél. -
haxiboy
veterán
válasz
sztanozs
#4317
üzenetére
Field No. az SQL-től független, csak a Dynamics NAV licencelés szempontjából mérvadó, a tábláknak is van számuk, SQL-ben attól még a saját nevével jelenik meg.
Sajnos ezeket a számokat a NAV nem engedi módosítani ha van benne adat, viszont lokalizáció ranget kellett váltanunk az ügyfélnél. Ez annyit tesz hogy vannak fieldek pl
1000-es számtól 1015-ig, mindegyiknek van valamilyen Neve (ami SQL-ben is a neve a fieldnek).
A számot meg kéne változtatni 2000-től 2015-ig. Csak akkor lehetséges, holott az SQL schema nem változik semmit, a NAV szempontjából ez azt jelenti hogy Törölted az 1000-es fieldeket és felvettél 2000-es fieldeket ugyanolyan névvel.Így amit csináltam (végül ugyebár működött).
SQL -> Delete from Táblanév
Navision -> Átszámozás
SQL SSIS -> Export Data az eredeti adatbázisból az átszámozott adatbázisbaSSIS-ben ennél az export datás funkciónál meg lehet neki mondani hogy mekkora batchekben commitoljon? Ha esetleg nagyobb mennyiségű adatot szeretnék mozgatni? Jelen esetben egy átlagos ~85GB-os adatbázisról beszélünk.
-
válasz
 haxiboy
#4316
üzenetére
haxiboy
#4316
üzenetére
Nekem SSIS-szel nem volt eddig gondom (igaz csak max 2-3 millió rekordos adatcsomagokat mozgattam vele eddig - viszont elméletileg batchben dolgozik, szóval memóriaprobléma nem nagyon lehetne vele.
Amúgy nem lett volna megoldás átnevezni a táblát és csinálni a régi névvel egy view-t, ami megfelelő sorrendben tartalmazz a mezőket? -
haxiboy
veterán
válasz
sztanozs
#4315
üzenetére
A változtatások dynamics nav tábla oldalon történnek (field no.) ami SQL oldalról irreveláns, attól még a field neve ugyanaz marad. De lekopogom most elvileg sikerült betöltenem az adatot az egyik kissebb vállalatnál problémamentesen. Minden a helyén maradt.
A következő 3 vállalatot amiben jelentősen több az adat a holnapi nap próbálom meg átemelni.
Nem kompatibilis adat előfordulhat, találkoztam már olyannal hogy nem lehet null érték az adott fieldben, mégis az volt ott, de hogy hogyan...fogalmam sincs, a lényeg hogy a kiexportált adatot már nem lehetett újra visszatölteni a táblába.
De a memória elfogyásra nincs ötletem, remélem most hogy csak a NAV oldalról módosult (SQL schema szerint nem) táblákat rakom át így működik majd a dolog.
-
haxiboy
veterán
Sziasztok!
A következő problémával fordulnék hozzátok.Adott két MSSQL Adatbázis ahol a táblák sémája megegyezik, sajnos program oldalról módosítanom kell néhány dolgot ami a program szemszögéből (Dynamics NAV) adatvesztéssel járna, így ez csak akkor lehetséges ha a módosítandó táblák üresek.
Amit szeretnék:
2 azonos adatbázis, az egyikből kitörlöm a táblák tartalmát, elvégzem a módosításokat, majd a másikból visszatöltöm (tábla szinten a schema nem változik így elvileg vissza kell mennie).
Jelenleg SSIS-el próbálkozok, ahol kénytelen vagyok táblánként megmondani neki hogy a timestamp mezőt ne vegye figyelembe, hiába van identity insert bekapcsolva, a validációig nem jut el.Így látszólag működik is egy darabig, viszont vannak tartalmilag nagyon nagy táblák, amiknél nem megy be a végső commit, tudom valahogy állítani hogy hány rekordonként töltse fel a táblákat (feltételezem egyszerre akarja az egészet és elfogy a memória).
Előre is köszi!
-

elBrigi
csendes tag
Sziasztok!
egy kész adattábla egyik oszlopnevét szeretném átnevezni postgresql-ben a következő paranccsal:
ALTER TABLE Tantargy CHANGE Name Megnevezes varchar(20);
..de a 'CHANGE' kulcsszóra visít. Mi lehet a baj? Egyáltalán lehetséges létező oszlop nevét átírni? -

bandi0000
nagyúr
-
bandi0000
nagyúr
válasz
 bandi0000
#4284
üzenetére
bandi0000
#4284
üzenetére
Ha emlékeztek volt ez a kérdésem, amire az IN-t javasoltátok
Sajnos nem jó, mert ha megadok pl 3 elemet a tömbben, akkor nem azokat adja vissza amibe mind3 van, hanem azokat amibe legalább az egyik, és így értelemszerűen nekem nem jó, lehet erre valami más megoldás?
Én még arra gondoltam, hogy beágyazott selecttel kellene kiszedni ezeket az innel, aztán megszámolni, hogy meg van e az eredmény annyi, mint ami a tömbnek a nagysága, viszont ezt nem tudom hogy kellene kivitelezni
-
Security hibákat is foltoz az új verzió:
phpMyAdmin 4.9.1 -
bandi0000
nagyúr
Az mennyire rossz megoldás, ha 2 tábla összatortozik, de mégse kapcsolnám össze az adatbázisba, csak a lekérdezésekbe?
A lényeg hogy van 2 tábla, első azonosítója van a másodikban, viszont az első táblát időnként frissíteném, és úgy a legegyszerűbb ha kitörlök mindent és visszarakom, az ID nem változik, viszont ha összakapcsolom őket, akkor nem engedi törölni az adatbázisból














 újraindítottam a linuxot, és be tudtam lépni.
újraindítottam a linuxot, és be tudtam lépni.





















![;]](http://cdn.rios.hu/dl/s/v1.gif)





















Új hozzászólás Aktív témák
- Beszállna az árnövelő versenybe az AMD
- One mobilszolgáltatások
- Gyúrósok ide!
- Hardcore café
- Kávé kezdőknek - amatőr koffeinisták anonim klubja
- Apple MacBook
- DUNE médialejátszók topicja
- Milyen okostelefont vegyek?
- Apple iPhone 17e – mágnesek ereje
- Intel Core i5 / i7 / i9 "Alder Lake-Raptor Lake/Refresh" (LGA1700)
- További aktív témák...
- ThinkPad P15v Gen3 27% 15.6" FHD IPS i7-12800H T1200 32GB 512GB NVMe ujjlolv IR kam gar
- AMD Radeon RX 7800 XT 16 GB (21330-01-20G)
- Bontatlan MacBook Air 13" M4 Magyar 2025 éjfekete színben, 2 év garanciával eladó!
- Intel I5-9500
- Dell Latitude 7390 2in1 360 fokban kinyitható 13,3" FHD IPS touch, 8650u, 16GB RAM, jó akku.
- Apple iPhone 16 Plus Pink 128GB használt karcmentes 94% akku (316 ciklus) 6 hónap garancia
- 27% - MSI MAG 321UPX OLED Gaming Monitor! 3840x2160 / 240Hz / 0.03ms / FreeSync
- Motorola Edge 50 Fusion 256GB,Újszerű,Dobozaval,12 hónap garanciával
- 27% - LG UltraGear 27GS95QE-B Monitor! 2560x1440 / 240Hz / 0.03ms / G-SYNC / FreeSync BeszámítOK!
- Canon MG2450 multifunkciós nyomtató + új színes patron
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest