- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- sziku69: Szólánc.
- sh4d0w: Árnyékos sarok
- weiss: Filmzene hasonlóság
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Doky586: SecureBoot kulcsok frissítése (2026 nyara)
- eBay-es kütyük kis pénzért
- Lalikiraly: Macbook NEO 2
- potyautas: Sára és a párja.
-
8700 - 8601
10138 - 10001 10000 - 9901 9900 - 9801 9800 - 9701 9700 - 9601 9600 - 9501 9500 - 9401 9400 - 9301 9300 - 9201 9200 - 9101 9100 - 9001 9000 - 8901 8900 - 8801 8800 - 8701 8700 - 8601 8600 - 8501 8500 - 8401 8400 - 8301 8300 - 8201 8200 - 8101 8100 - 8001 8000 - 7901 7900 - 7801 7800 - 7701 7700 - 7601 7600 - 7501 7500 - 7401 7400 - 7301 7300 - 7201 7200 - 7101 7100 - 7001 7000 - 6901 6900 - 6801 6800 - 6701 6700 - 6601 6600 - 6501 6500 - 6401 6400 - 6301 6300 - 6201 6200 - 6101 6100 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 HSM
félisten
HSM
félisten
-
 Devid_81
félisten
Devid_81
félisten
-
 b.
félisten
b.
félisten
-
Devid_81
félisten
Some users are now reporting their Ryzen CPUs with X3D are burning up
Interestingly, all CPUs that were affected by sudden burn out had the defect in the same spot. It appears to be the exact spot where the 3D V-Cache chiplet is located, so the rumors about extensive voltage going through this chiplet might have some ground for further investigation.
Remek

-
HSM
félisten
Ezt hogyan fogják memória sávszélességgel kiszolgálni? Kicsit soknak tűnik ez két DDR5 csatorna mellé. Lesz HBM csiplet is rajta a GPU-nak?
-
Devid_81
félisten
-
Devid_81
félisten
40CU az rengeteg, nem konzol lesz abbol?

-
 Alogonomus
őstag
Alogonomus
őstag
Valóban soknak tűnik a 16 mag, de Tom is megjegyezte, hogy az a 16 mag esetleg ugyanúgy Zen5 és Zen5c magok keveréke lesz, ahogy állítólag a 12 magos "sima" Strix is 4+8 formátumú lesz. Úgy azért már nem olyan sok a 12 és 16 mag, hiszen még vagy 1,5 év múlva érkeznek 2024 második fele magasságában.
-
 Petykemano
veterán
Petykemano
veterán
MLiD infoi szerint Strix Halo néven jön a mega APU (40CU)
Sajnos nem budget gaming, hanem prémium mobile. 16 mag. Chiplet. Szerintem a 16 mag sok, de Végülis ha csak az IOD nagyobb, akkor lehet ilyen is, olyan is. -
 S_x96x_S
addikt
S_x96x_S
addikt
érdekesség:
a Hetzner -nél bérelhető gépek között megjelent
- AMD Ryzen™ 7 7700
- AMD Ryzen™ 9 7950X3D
https://www.hetzner.com/de/dedicated-rootserver/matrix-axa tippem, hogy valószínűleg a jobb fogyasztási adatok miatt döntöttek a 7950X3D mellett.
-
Petykemano
veterán
AMD Zen 2 (7nm) – Valhalla
AMD Zen 3 (7nm) – Cerberus
AMD Zen 4 (5nm) – Persephone
AMD Zen 5 (3nm) – Nirvana
AMD Zen 6 (2nm) - Morpehus
[link]Különös, hogy ennyire egyértelmű nm jelzéseket köt a magokhoz.
Számomra nem egyértelmű, hogy vajon a CCD-n levő Zen4 mag, a mobil Zen4 mag és a Zen4c mag neve is egységesen Persephone-e annak ellenére, hogy sűrűségben, L3$ méretben egyébként egy más implementációt jelent és egyébként más és más gyártástechnológián készül. -
Petykemano
veterán
MLID leak a Zen5 (Zen 5) Cinebench IPC témában [link]
Egy 2x64 magos Zen5 rendszer teszteredménye került ki. 123xxx multi score-ral, ami jelentékeny növekmény az eddigi Genoa eredményekhez képest, amiket a magasabb magszám ellenére korlátoz az, hogy a cB csak 256 szálig skálázódik.
A számok MLID szerint igazolják a 20+%-os várható IPC növekedést.
Érdekes, hogy a Windows által visszajelzett adatok.szerint az L2$ és L3$ mérete nem változott, míg az L1 (összesen) 64KB-ról 80KB-ra növekedett.
Ami egészen meglepő számomra, merthogy én az architektúra szélesedése nyomán az Apple által mutatott irányba való eltolódásra számítottam. Ez arra utal, hogy olyan nagy mértékben nem változtat az AMD a design megközelítésein. Ez a növekmény meglehetősen szerény. Ami persze abból a szempontból jó, hogy a magok továbbra is kicsik maradnak és teljesítménynövekmény is elég tisztességes.
A másik érdekesség, hogy MLID szerint a Zen5c, ami N3-on készül, 16 magos Lesz és a 16 mag egységesített L3$-hez fog kapcsolódni.
Ez azt jelenti, hogy tényleg elkészült ez a fejlesztés. Csupán döntés kérdése, hogy lássunk-e egy 16 magos zen5 CCD-t. Bár valószínű ez a feature inkább Zen6 formájában fog megjelenni.
A 16 magos Zen6X3D nagyon ütős lesz. -
Petykemano
veterán
Akkor csak "educated guess"
Állítólag egyébként sok CPU tervezőt csábított át az AMD-től a Tenstorrent, abből fakadóan - állítólag - közeli képük lehet, hogy mit fog tudni.
Eddig minden valós generációváltás kb 30% körüli teljesítménynövekedést hozott. Ebből változó, hogy mekkora volt az IPC és a frekvencianövekedés hatása. De mindenesetre ez a 30% nem valós mérés, hanem csak várakozás.
-
S_x96x_S
addikt
a ZEN5 -ös teljesítmény ex-has becsült ..
vagyis nem vagyunk előrébb ..
sőt .. ha megint túl magasra teszi mindenki a lécet ..
akkor sokan fognak csalódni, hogyha csak ~90%-át tudja ...
"There is a major catch with Tenstorrent's performance expectations: they are all projections and not real or even simulated benchmarks, Tenstorrent told Tom's Hardware. So while we can expect engineers from Tenstorrent to accurately model the performance of their own CPU design and try to predict what AMD could offer next, these are still projections, not actual benchmark results.
For obvious reasons, AMD's Zen 5 performance number has attracted the most attention, even though it is highly unlikely that this projection is completely accurate. But what is perhaps more important is that Tenstorrent expects AMD's Zen 5 to run north of 4.0 GHz and have a TDP south of 250W, as opposed to Ascalon running at around 3.80 GHz at a TDP of approximately 200W.
"
https://www.tomshardware.com/news/jim-keller-shares-zen5-performance-projections-kind-of -
S_x96x_S
addikt
érdekes ..
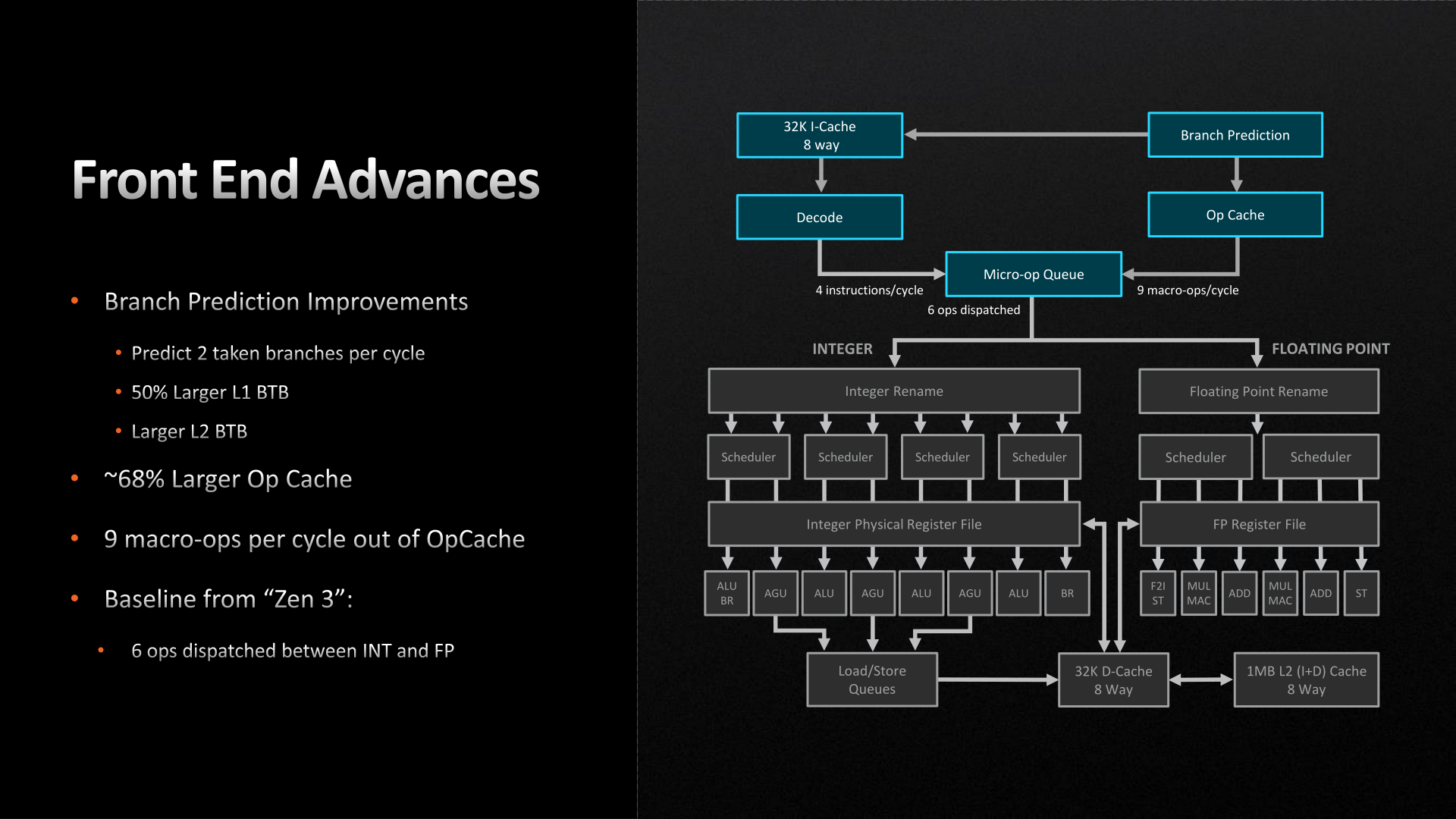
a jobb felső sarokban egy "Frequency(Ghz)" táblázat is van.
és míg a Milan - 3.5 Ghz .. a ZEN5 már 4.0 Ghz, vagyis a SPECINT-et korrigálni kell ezzel.De ha így van,
akkor az Integer végrehajtást jelentősen kiszélesítették ..
míg ZEN4 -ben csak 4 párhuzamos integer végrehajtó van
a ZEN5-ben valószínüleg ennél több, vagy valami más okosítást raktak bele.
-
Petykemano
veterán
Zen5 (Zen 5) specint, spec2K17int
Tenstorrent előadásban egy charton megjelenítették a Zen5-öt

Persze a fene tudja, hogy ez valós-e, véletlenül kiszivárogtatták, vagy Jim Keller (az előadó) tudja, vagy becslés, és ha becslés, akkor mi alapján.
A valóságosságra utaló jel, hogy a Grace esetén jelezték, hogy csak becslés.
Viszont a 8.84 és 6.8 különbözete túlságosan pontos, kerek +30%. Ez meg inkább utal arra, hogy csak saccoltak.Ha az ábrán levő számok valóságosak, akkor elég szép ugrás a Zen4 és Zen5 között.
Lehet, hogy az MLiD és RGT által híresztelt 25% körüli IPC növekedés nem túlzás. -
Petykemano
veterán
De valószínűleg ez lehet a magyarázat.
Azért érdekes info ez számomra, mert a v-cache lapkák N7-en történő gyártásával kapcsolatban felmerült az a kérdés, hogy vajon mi lehet a magyarázata, hogy ha már úgyis áttervezték, akkor miért nem N6-on készül, amikor több szempontból is előnyösebbnek kéne lennie az N6-nak (az EUV miatt még kisebb hibaarány, kevesebb maszk miatt gyorsabb megmunkálás miatt magasabb throughput, névlegesen 15%-kal nagyobb tranzisztorsűrűség, N6 valójában N7 gyártósorrol kerül átalakításra)
És voltak akik csipőből azt válaszolták, hogy az N7 gyártása biztos olcsóbb, mert az N6 újabb.
Miközben az nagyonis lehetséges, hogy 15% tr sűrűség növekedés csak "logic" típusú áramkörökre érvényes és az SRAM-ből álló a v-cache lapka esetén ebből már nem lehet előnyt szakítani, egy nagyobb SoC esetén a lapka egységnyi előállítási költségének csökkenésével jár(hat).
Az AMD mondjuk emiatt nem fog hozzányúlni a jóárasított Zen3-hoz, vagy zen3 apukhoz. De iránymutató lehet arra nézve is, hogy pl a navi33 a boltokba kerülhet-e azon az áron, ahogy most a navi23 kapható
-
b.
félisten
Az nem lehetséges hogy ostyánkként 10 % kal több SOC jön ki ?
-
 hokuszpk
nagyúr
hokuszpk
nagyúr
-
Petykemano
veterán
Ez egy érdekes info
Az PS5 N7-en gyártva $233 N6-on gyártva 9%-kal alacsonyabb, csak $212.
Gondolom ez az az összeg, amit a Sony fizet az AMD-nek.
Amennyiben ez így van, akkor persze nem biztos, hogy ebben a 9%-ban kizárólag az olcsóbb gyártás van benne, hiszen az AMD árszabása (marzsa) is lehet más.
Mindenesetre irányszámnak alkalmas lehet. -
HSM
félisten
A kiskaput úgy értem, hogy teljesen feloldotta az AMD a zárat, azt olvastam, csak a PBO limiteket és a CO-t tervezik feloldani az új AGESA-ban? Mert az más, ha feloldották, és más, ha csak a gyártók szoftverei engednek valamit, aminek nem is kellene ott lennie, így értve, kiskapu-e...
-
 Busterftw
nagyúr
Busterftw
nagyúr
-
HSM
félisten
Írták is, hogy azért tiltották megjelenéskor a tuningot, mert érzékeny a V-cache, és nem kaphat 1.35V feletti feszültséget (5800X3D), és félő, hogy sokan tönkretennék a processzort a zár nélkül. Aztán persze egyből ezzel lett tele a fórum, hogyan lehet mégis ráadni a PBO-t, CO-t és barátait...
Most végülis kinyitották a CPU-t, vagy csak a gyártók szoftverei találtak egy túl jó kiskaput? -
Busterftw
nagyúr
Der8aur 7950X3D utan Igor's Lab 5800X3D-t kuldott halalba, ugy nez ki valami pltaformszintu doloh van, nem csak az MSI Centert erinti.
AMD Ryzen 7 5800X3D free overclocked, overvolted and unfortunately executed with the MSI Center -
Petykemano
veterán
Zen5 (Zen 5) IPC & others
MLID jelentetett meg egy videót, amiben egy meglehetősen konzervatív jövőképet festett fel a Zen5-ről:- elmesélte, hogy többféle Zen5 verzió is készült tesztelési és biztonsági céllal, ezek között volt olyan, ami desktopra N3-on készült és kiemelték volna belőle a L3$-t, hogy csak 3D stacked legyen - feltehetően 16 maggal -, de végül a frekvencia-regresszió és a N3 gyártástechnológia körüli bizonytalanság miatt párhuzamosan fejlesztett N4X-re épülő konzervatívabb (az előzőekhez hasonló 8 magos, embededded L3$) CCD jött ki győztesen.
- nem beszélt arról, hogy a 3D cache rétegzettségi száma esetleg növekedne
- 15-26% IPC növekedés (nyilván az IPC növekedés megfogalmazása elég tág lehet, mert valaki egy saját maga által látott szoftverbeli IPC növekményt mondhat, valaki egy átlagot, stb)
- 2-9% frekvencia emelkedés (szintén nincs részletezve, hogy mi vonatkozik ST-re és mi MT-re)
- Desktopon nem lesz mag szám emelkedés. De megjelenhet a Zen5c (32mag). Hybrid (8+16) desktop verziót az AMD szerinte nem tervez.A 128/192 magos EPYC verziókat megerősítette.
És ejtett még pár szót arról, hogy ehhez képest az Intel mennyire versenyképes palettát lesz képes felvonultatni.Nagyjából hasonlókat mondogat a RedGamingTech is. Ő is viszakozott az egységesített L2$ irányából.
Tehát összesséégben a Zen5 valószínűleg valóban egy teljesen új mag design lesz, de a magok szervezése, nem fog drámaian megváltozni. Várható a nagyobb L1$, esetleg nagyobb L2$. Ezek növekedésével a helytakarékosság érdekében én elképzelhetőnek tartom, hogy csökkentik az L3$ méretét és ráhagyják a kérdést az X3D-re, amivel komoly mennyiséget tudnak rápakolni azokra a szegmensekre célozva, ahol az számít.
(Nem szabad szem elől téveszteni, hogy az AMD fókusza még mindig a szerver.)AI, vagy FPGA, vagy más gyorsítókról volt szó, de mondjuk olyan dolgokról, hogy IOD-ra szerelhető L4$ vagy hogy a Turin Mockup-on 2x2 / 4-es szigetekbe szervezett CCD-ket valamilyen alul levő base cache die kötné össze, vagy hogy változna az eddig megszokott organikus szubsztráton keresztüli IFOP/SerDes összeköttetés (lásd Navi31) nem esett szó.
-
Petykemano
veterán
-
S_x96x_S
addikt
"AMD EPYC Milan Still Gives Intel Sapphire Rapids Tough Competition In The Cloud"
https://www.phoronix.com/review/milan-spr-google-cloudmég nincs benne a Zen4-es Genoa ;
The configurations for this round of testing were:
- c2-standard-8 (Cascade Lake)
- n2-standard-8 (Cascade Lake)
- n2-highcpu-8 (Cascade Lake)
- c3-highcpu-8 (Sapphire Rapids)
- c2d-highcpu-8 (Zen 3 / Milan)
- t2d-standard-8 (Zen 3 / Milan) -
 Yutani
nagyúr
Yutani
nagyúr
"Undershipping"
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Petykemano
veterán
Azért nem tartom valószínűnek, hogy a legyártott mennyiség lett volna a legmeghatározóbb tényező a metszésnak, mert szerintem az Intel az Alder Lake előtt is el tudta önteni a piacot az előző generációs termékkel és az csak 30%-ra volt elég - legalábbis a Pugetnél.
A teljes piacra vonatkozó részesedésekre nézve lehet benne igazság, mert abban emlékeim szerint nem volt ilyen nagy mozgás. -
Busterftw
nagyúr
Valoszinuleg itt koszon vissza az elerhetoseg, legyartott mennyiseg.
Az Intel el tudja onteni a piacot client CPU-val, AMD pedig kevesbe, mert mason van a fokusz.
Illetve nagyon sokaig az Alder Lake tenyleg bestbuy volt. (az) -
Petykemano
veterán
Az Alder Lake tetszett a népnek.
Különös, hogy nem sikerült az AMD-nek visszakorrigálnia 2022-ben, pedig végül milyen olcsóvá váltak a Zen3-ak.
(Bár lehet, hogy épp azért vált a DIY zen3 annyira olcsóvá, mert az Alder Lake miatt kiszorult az olyan prebuilt/OEM piacokról, mint amilyen a Puget Systems is)Az nem annyira meglepő, hogy a Zen4 vs RPL nem fordított.
Egyrészt érdekes lesz majd látni, hogy a Workstation számokat hogy mozgatja meg a SPR workstation érkezése
Másrészt a client részesedés és hogy a Zen4 (vs RPL) nem fordított lehet, hogy elég motiváció lehet a Zen5 pár hónappal történő előrehozatalára, ha annak technikai feltételei egyébként adottak. a 70/30 arány visszaszerzéséhez az AMD-nek előnyben kell lennie. A 70/30-hoz az Intelnek elég nagyjából egálra kihozni. -
S_x96x_S
addikt
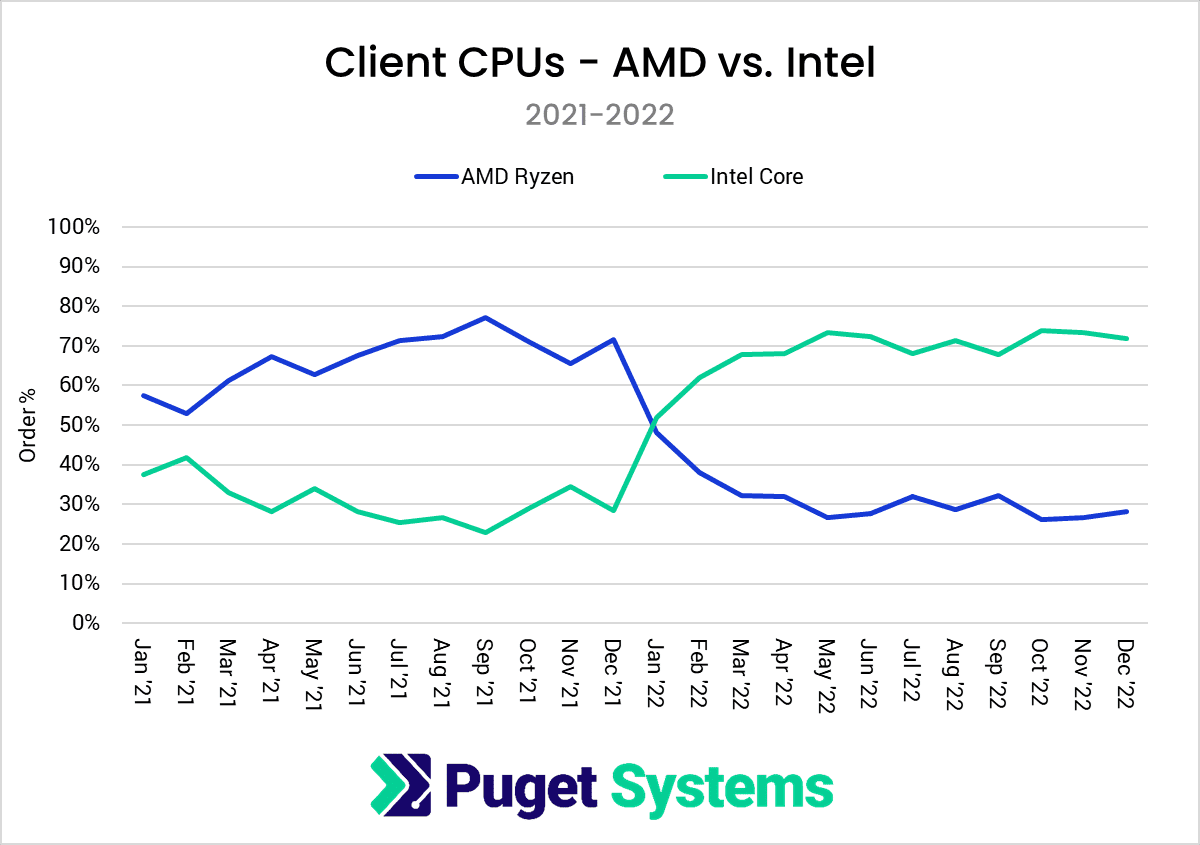
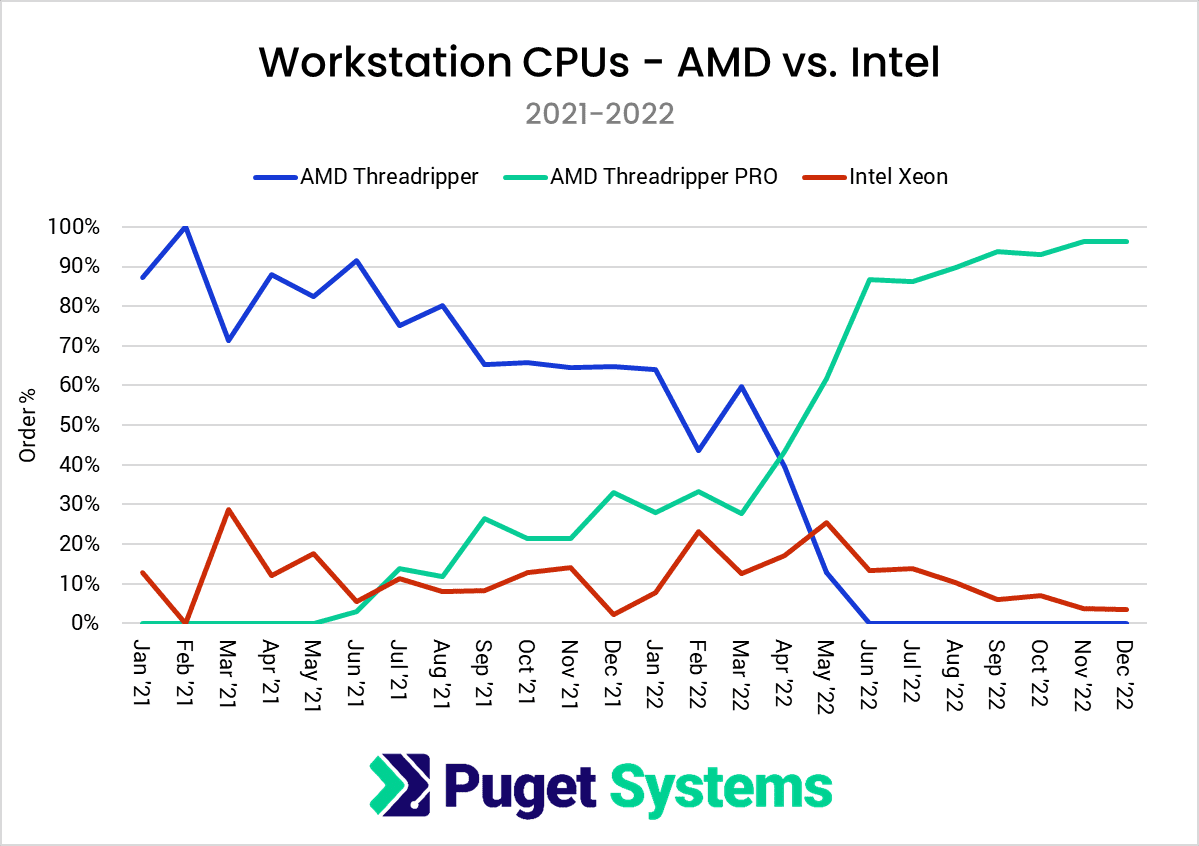
érdekesség:
PugetSystems trends .. ( eladási statisztika )
- Worsktation CPU : AMD 95%-os részesedés.
- Desktop CPU: AMD ~28% részesedés ( 2022január - trendforduló az Intelnek- )"In 2022, Intel took the lead in the client CPU space for us, completely flipping our ratio of AMD Ryzen and Intel Core CPUs from the previous year. However, AMD didn’t budge in the workstation space, with Threadripper PRO sales outpacing Intel Xeon by nearly 20:1."
-
Petykemano
veterán
Ez a gigabyte pletyka annyira zavaros, mint ha szándékosan kifejezetten zavarkeltés lett volna a célja.
Van ott minden szervertől desktopig.Nekem három tippem van:
- Ryzen néven érkezik főképp (entry level) szerver célokra AM5 platform alapon a bergamo, amit persze majd lehet frissíteni
- összeollóztak előző verziókat és ellenőrizetlenül kiengedték.
- chatGPT írta (ami ebből a szempontból ugyanaz, mint az előző, csak fancybben hangzik)Az én becslésem asszem 2024 március volt az alapján, hogy beismerték, hogy a zen4 6 hónapot csúszott a CXL miatt. Ha azt is figyelembe vesszük, hogy nincs túlkereslet az N4/N5 gyártásttechnilóguára (jelenleg a zen5@N4 a valószínű forgatókönyv) akkor lőtávolba kerülhet egy ilyen előrehozatal. És az is igaz lehet az "ugyan minek sietne?" Kérdésre, hogy az AMD értékelheti úgy a client revenue beesése miatt, hogy a zen4 nem elég csábító a platformköltség miatt, ezért nem fogy eléggé.
Ezzel együtt ez a gigabyteos szöveg annyira zavaros számomra, hogy nem mernék ebből ilyen irányú következtetést levonni.
-
S_x96x_S
addikt
a framework - nek lett AMD alapú laptopja!

( AMD Ryzen 7040 )"Introducing the Framework Laptop 16 and both Intel and AMD-powered Framework Laptop 13"
https://frame.work/at/en/blog/introducing-the-framework-laptop-16-and-both-intel-and-amd-powered-framework-laptop-13 -
S_x96x_S
addikt
>> az i/o die-t nehezebb skálázni ..
>> ( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )
> Túlterhelve milyen értelemben?16 mag esetén nagyobb az esélye, hogy a kommunikációt chipleten belül is el lehet intézni és kevesebb kérés megy ki az i/o die -ra.
a Genoa-ban
- 12 memoria csatorna van
- 12 cpu chiplettel ( CCD- )ha skálázni szeretnénk a magok számát,
akkor a chipletek számának növelése nehezebb út lehet, mint hogy
12 vagy 16 magos chipleteket raknak be és marad a 12 cpu chipletes felépítés.a "túlterhelést" úgy értem,
hogy 192 magos socket-et kétféleképp lehet összerakni:
a.) 24 cpu chiplet * 8 cpu-s CCD
b.) 12 cpu chiplet * 16 cpu-s CCD.és szerintem az "a.)" kevésbé optimálisabb, jobban terheli az i/o die-t
-
HSM
félisten
A 12-16 magos CCX ellen szól az is, hogy minél több magot fűznek rá a közös L3-ra, annál komplexebb lesz az összekötés, nő a késleltetés. A konkurencia is megütötte ezzel magát, hiszen náluk is 8 mag felett kezdett el betegeskedni a gyűrűs topológiájuk, az Alder Lake-nél is egy igen egzotikus megoldás született erre az E-magok tekintetében, lásd: [link] .
Ráadásul szerverekben azért sem lenne ennek sok értelme, mert egy 128 magos szerveren jó eséllyel nem olyan feladatok fognak futni, amik 8-nál több mag szoros együttműködését igénylik, vagy ha mégis, ott lesz arra pénz, hogy úgy optimalizálják a szoftvert, hogy ne legyen gond ebből a felépítésből.
-
Petykemano
veterán
> az i/o die-t nehezebb skálázni ..
> ( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )
Túlterhelve milyen értelemben?
Szerintem ha 16 mag van egy CCD-ben 8 helyett, attól a 16 magra vetített infinity fabric kommunikáció nem csökken. Amit lehet nyerni az az, hogy ha 16 magot építesz egy CCD-be, akkor azt le lehet tudni 1 IF lane-nel, míg ha egy CCD 8 magos, akkor ott mindenképpen 2 lane kell 16 maghoz.Fontos megjegyzés, hogy az 1 lane / CCD-t el lehet érni úgy is, hogy a 16 magos CCD-ben 2db 8 magos CCX van. Erről a lehetőségről egyébként én sem ejtettem szót.
> Amúgy az is lehet, hogy már a következő konzol APU-t is próbálják összerakni/demózni.
> és az két chipletes felépítésű lesz.
> - 16 magos CCX
> - RDNA4Szóval szerinted a következő konzol APU-ban nem lesznek hybrid magok?
(Jelenleg ismert variánsok: Zen4, Zen4X3D, Zen4c) -
S_x96x_S
addikt
> Vajon mi értelme/célja lenne a CCX-en belüli magszám emelkedésnek?
szerintem praktikussági és egyszerűségi okok lehetnek mögötte ...
pl.
1. ) az i/o die-t nehezebb skálázni ..
( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )2.) packagelési / gyártási / ökoszisztéma egyszerűsítés
ha több CCD (chiplet) -> több macera, akkor okosan vállaljuk be .
mert jelentősen át kell tervezni szinte mindent
.. a desktop hűtőket, és az i/o die-t, ..
és az elég nagy változtatás .. ami növeli a kockázatokat.Amúgy a CCX magszám növelésének - szervereknél a a cloud-nál
lehet egy olyan hatása is,
hogy eddig egy 8 magos Virtuális gép volt az optimális ( a késleltetés miatt )
és ez a limit most felmegy 16 magosra.
De akár a chipleteket biztonsági védőhálóval is fel lehet vértezni.
és a 16 mag jövőállóbb.Amúgy az is lehet, hogy már a következő konzol APU-t is próbálják összerakni/demózni.
és az két chipletes felépítésű lesz.
- 16 magos CCX
- RDNA4de ez csak találgatás . igazából nem tudom ..
-
Petykemano
veterán
#zen5 #zen 5 #magszám
Roppant érdekes.
Más fórumokon még élénken vitatják, hogy vajon a Zen5 hoz-e magszám emelkedést - elsősorban a CCX-en belül értve. Nemhogy 16, de még a 12 magos CCX is felmerül, amit a Mi300-ban elérhető 24 magból deriválnak.Legutóbbi videójában AdoredTV is megállapította, hogy a 16 magos CCX jelenleg valószínűtlen. Valójában ezen kívül kevés megállapítás hangzott el.
Vajon mi értelme/célja lenne a CCX-en belüli magszám emelkedésnek? A CCX-en belüli magok L3$-en keresztül tudnak egymással adatot megosztani, egymás közötti késleltetésük alacsony. Tehát 8-ról 12 vagy 16-ra növelni az egy L3$-hez kapcsolt vagy CCX-en belüli magok számát - ennek értelme akkor és ott lenne, amikor olyan alkalmazás fut, ahol a szálak kommuninálnak, adatot osztanak meg egymással és egy ilyen alkalmazás 8 magon túl terjeszkedik, vagy legalábbis több erőforrást használna.
Világos, ha jelenleg egy ilyen élénk szálközi kommunikációval működő program túlterjeszkedne a 8 magon, akkor abból olyan bedadogás (lassulás) keletkezne, mint amit a 4 magos CCX-szel rendelkező Zen processzorok esetén láttunk.
12 vagy 16 magos CCX esetén a program máris terjeszkedhetne 8 magon túl anélkül, hogy a megnövekedő késleltetés miatti teljesítményvesztést el kéne szenvednie.De ennek a célnek az eléréséhez vajon valóban a CCX-en belüli magok, vagyis az L3$-hez kapcsolt magok számának növelése az egyetlen és leghatékonyabb útja?
Leginkább amiatt vetődik fel bennem ez a kérdés, mert szerintem míg a játékok terén ennek hosszútávon - ha a programok is úgy akarják és az Intel is felkészült - lehet, hogy lehet valamilyen pozitív hatása, addig szerintem a szervereknél szinte semmi. Miért tenné meg akkor az AMD?
Mielőtt válaszolni probálnék a kérdésre, elmondanám az alternatívát:
Tehát szerintem szerverek esetén nem sok haszna volna a 8 helyett 16 magos CCX használatának (most itt a lapkaméretet még hagyjuk)
Ha viszont desktopon - vagy a ThreadRippernél - a minimum 2 CCD-s összeállításoknál szempont a CCD-közi késleltetés csökkentése, akkor azt egy IOD-hoz kapcsolt (3D) SLC-vel is meg lehetne oldani, ami kicsit ahhoz hasonlóan működhetne, ahogy a Navi31 esetén is az MCD-be épített infinity cache tulajdonképpen a MEmóriavezérlő előtti bufferként fogható fel. Ezt használhatnák a CCD-k, vagy CCD helyett egy GCD is, vagy az IOD-ba épített IGP.Egy ilyen megoldás enyhítené a CCD-CCD kommunikáció késleltetését és tudná tompítani a másik CCD-re való szál-átugrás problematikáját. Megkockáztatom, hogy az AMD hybrid architektúrájának jelenleg kritizált problémáit (a 3DCCD-ről szál kiszorulása vagy rossz ütemezése miatti dadogást) enyhítené. Persze az IOD-ra helyezett SLC-nek akkor tényleg méretesnek kellene lennie.
Viszont ha ennek ugyanúgy nincs haszna a szerverpiacon, akkor miért csinálná ezt az AMD? Hiszen soha semmit nem csinálna kizárólaga desktop piacra.
Erre a kérdésre a válasz az lehetne, hogy a CCD-CCD kommunikáció késleltetésének csökkentése inkább mellékterméke lehetne az elsősorban a mobil piacra gyártott chiplet APU-knak, amelynél a GCD külön van gyártva, és egy szincén külön gyártott MCD-hez, vagy más esetben IOD-hoz kapcsolódik, amely valamilyen módon tartalmazza a komolyabb GCD a korlátozott memóriasávszélességgel rendelkező környezetben való működéséhéz szükséges infinity-cache-t.Mi viheti rá mégis az AMD-t arra, hogy 12 vagy 16 magos CCX-ez készítsen?
A lapkaméret, vagy költséghatékonyság.Sajnos ugye számokat egyik elképzelés mellé sem tudok rendelni. Bár azt gondolnám, hogy a 3D tokozás a következő 1-2 évben csupán 1-2 dolláros többletköltséggé fog redukálódni és elég sokat lehet majd nyerni azon is, hogy nem a legfejlettebb gyártástechnológiát használod. Azt sem tudom, hogy vajon 16 mag egy L3$-hez rendelésének milyen többletköltsége van: szükséges-e a méret kétszeresre növelése úgy is, hogy előzőleg duplázták az L2$-t? Kell-e növelni az asszociativitást? Mennyivel nagyobb tag szekcióra van szükség, stb És ugyanúgy nem tudom, hogy ha ugyanezt az L4$ esetén kell megvalósítani, akkor az mit jelent.
De egy olyat el tudnék képzelni, hogy ha az AMD lecsökketi a bázis L3$ méretét a Zen5-ben - adabszurdum 0-ra - akkor annyira kicsi lenne már a CCD, hogy azért muszáj emelni a magszámot, mert különben túl nagy lenne rá a 35mm2-es v-cache. (már amennyiben azt továbbra is N7-en gyártják)
Azon sem lepődnék meg, hogy ha a következő 1 évben több különböző Zen5 lapkamérettel és L3$ konfigurációval találkoznánk a szivárgásokban.
-
Petykemano
veterán
-
S_x96x_S
addikt
RedGamingTech - spekuláció ..
- desktop zen5 marad 4nm-en és 8 core ccx
- a szerver zen5 meg 3nm és 16 core ccx. -
Petykemano
veterán
Én meg úgy értettem, hogy ha jön a Meteor lake (mobil), akkor arra lehet, hogy kénytelen lesz az AMD nem csak egy 8, hanem egy 6 magos mobil, v-cache-sel szerelt dragon range-t is kiadni. (7645HX3D)
Ennek esetleg lehet leeső morzsája egy egy asztali 7600X3D is.A kérdés csak az, hogy egy 7845HX3D, vagyis 8c+3D mellett miért akarna vagy lenne kénytelen egy 6 magosat is kiadni, amikor a meteor lake eleve csak 6 magos lesz? Nyilván nem muszáj. A meteor lakeből biztos lehet majd 6+16, 6+8, 6+0. Az első ellen a 8c+3D valószínűleg multiban elvérzik (ami nem biztos, hogy baj), a második ellen versenyképes, utolsó ellen viszont túl erős. Utóbbi ellen be lehet dobni valami gyengébbet (8c Dragon vagy Phoenix), de az meg gaming terén nem tudná tartani a lépést.
Egyik sem olyan, amire azt mondanám, hogy na most itt már komoly lépéskényszer áll fenn, csak hogy nyílik egy ajtó.
-
S_x96x_S
addikt
🔥Retail CPU Sales Report Week 10
☝️post Ryzen 7000X3D launch
Ryzen 7 5800X3D killing it (7950X3D sold out)AMD unit share: 66.6% ( -3.51%)
AMD Revenue share: 61.21% ( -5.43%)
7900X3D -ből 80-at adtak el.;
A pisztáciás 7950X3D is kifogyott ...
https://twitter.com/TechEpiphany/status/1634539368965713920 -
S_x96x_S
addikt
> A 7600X3D szerintem akkor kerülne piacra, ha a meteor lake megérkezik.
spekulálva az én ex-has véleményem:
bármi lehetséges, és akár ősszel is ..
- "Raptor Lake Refresh" lesz az ellenfél.
- 7800X3D árát is csökkentik, mivel jönnek a 8000 -es ryzenek.
- ha az X3D-sek nagyon jól mennek a piacon, akár már a nyáron is megjelenhet a 7600X3D.kiegészítő:
- a 7600X3D - alatt én desktop-ot értek,
- és "az Intel törölte a Meteor Lake-S kódnevű fejlesztést, azaz papíron az asztali Meteor Lake sorozatot," ( via Prohardver-abu-2023-02-23 ) -
Petykemano
veterán
Én kétlem, hogy lenne 7700X3D
De persze nyilván attól függ, milyen minőségből mennyi keletkezik. Ha esetleg van hibás v-cache (olyan mennyiségben), ami csak 32-48MB-ig jó, abból lehet.
7600X3D-t viszont rebesgetnek. De gondolom persze ezt se szándékosan, hanem gubizva:
7800X3d, ami túlmelegszik
7900X3d, aminek a sima ccdje hibás.A 7600X3D szerintem akkor kerülne piacra, ha a meteor lake megérkezik. Az elvileg eleve 6P magos csak. Tehát kellhet olyan 6 magos Dragon range, ami konkurenciát állít.
-
b.
félisten
7700X ben várható 3 D ?
-
S_x96x_S
addikt
már listázzák a zen4-es dragon notebookokat ; (7945HX)
még kicsi a kínálat ..
és 920e Ft-tól kezdődnek az árak ( nVidia Geforce RTX 4060 8GB GDDR6 -el )
és egészen 2.2Milláig ha full extrás nVidia Geforce RTX 4090 16GB GDDR6 -el kellene.
( kb 23 különböző konfigot látok .. de lehet, hogy van több is .. )Ez egy középkategória 1.5 milláért.
ASUS ROG Strix SCAR 17 G733PZ
AMD Ryzen 9 7945HX (16 x 2,50GHz / 5.40GHz Turbo, 64MB Cache), 17.3" (2560x1440) LED matt IPS-Level 240Hz 300nits G-Sync 3milisec 1000kontr, 64GB DDR5 4800MHz, 2000 GB m.2 PCIe NVMe SSD, nVidia Geforce RTX 4080 12GB GDDR6, Microsoft Windows 11 Home...
--> 1524900 Fta 7945X (16core ) gyári adatokatt elérhetősége
https://www.amd.com/en/products/apu/amd-ryzen-9-7945hx -
Petykemano
veterán
Állítólagos hivatalos 7800X3D
-
S_x96x_S
addikt
Befektetői konferencia ..
"Advanced Micro Devices, Inc. (AMD) Morgan Stanley Technology, Media & Telecom Conference (Transcript)" - Március 6.
túl sok infó nincs benne, inkább az érdekes, hogy hogyan kommunikál az AMD. -
HSM
félisten
Az L2 növelésének szvsz nem lett volna értelme, hiszen az rendkívül késleltetés-kritikus, ott nem nagyon fér bele az a néhány órajeles büntetés, mint az L3-nál.
-
Petykemano
veterán
Volt egy kis AMD ismertettő a második generációs V-cache-ről
- N7-en készül
bár sikerült tovább növelni a tranzisztorsűrűséget, így bennem felmerült a kérdés, nem N6-e valójában és ha nem, akkor miért nem?- 36mm2
ami a Zen4 L3$-hez képest jelentősen nagyobb, mivel az csupán ~25mm2Emiatt rálóg a v-cache az L2$-re. amit ki kellett egészíteni ún power TSV-kkel.
Ez kissé sajnálatos. Talán izgalmasabb lett volna, ha 2nd gen V-cache esetén az L2$ bővítése is lehetséges. Máskülönben viszont azt is jelenti, hogy ha a következő generáció úgy készül, hogy az L3$-t kiemelik a CCD-ből, és 3D stackelve építik rá, akkor valójában ebben nem jelent gondot/akadályt az se, hogy ha a v-cache az L2$-t fedi.
-
S_x96x_S
addikt
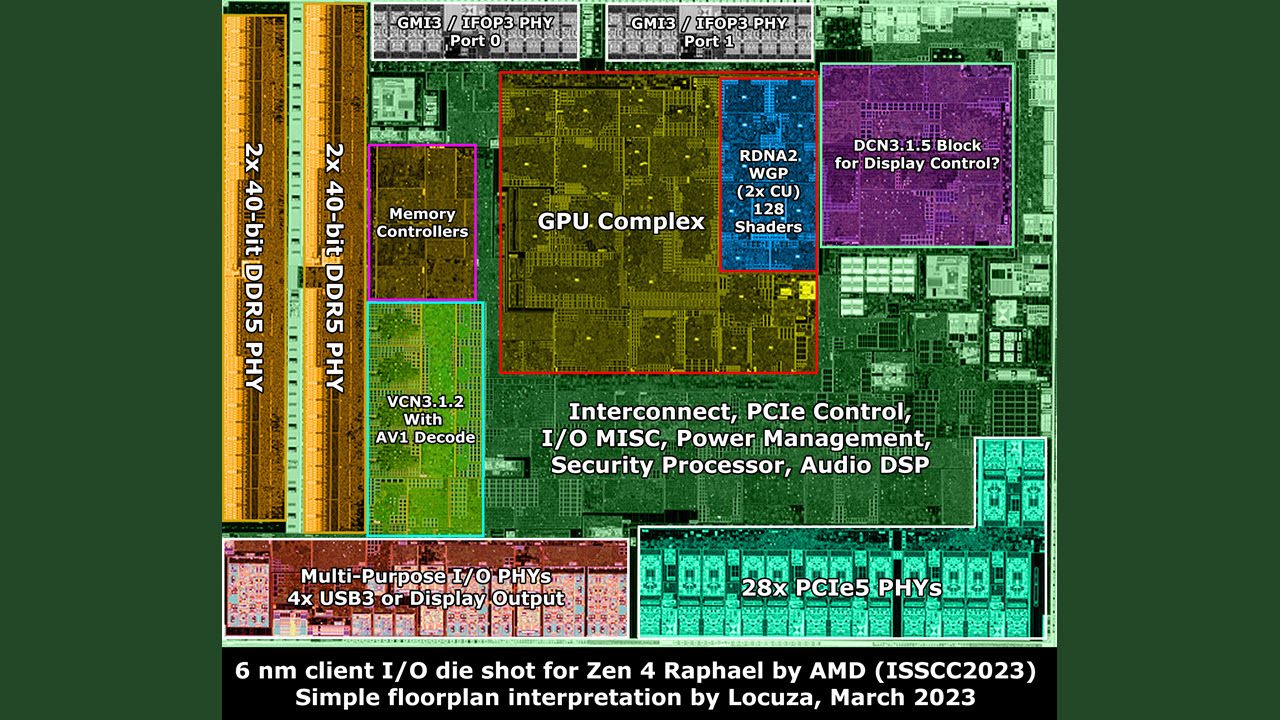
Locuza:
Zen 4 Raphael 6 nm client I/O die:
- 128b DDR5 PHY + 32b for ECC (8b per 32b channel)
- 2x GMI3 Ports, 3x CCDs are not possible. :p
- 28x PCIe 5, Zen1/2/3 cIOD had 32x PCIe lanes.
So AMD reduced the waste for the client market.
- Really just one RDNA2 WGP, 128 Shader "Cores"
+

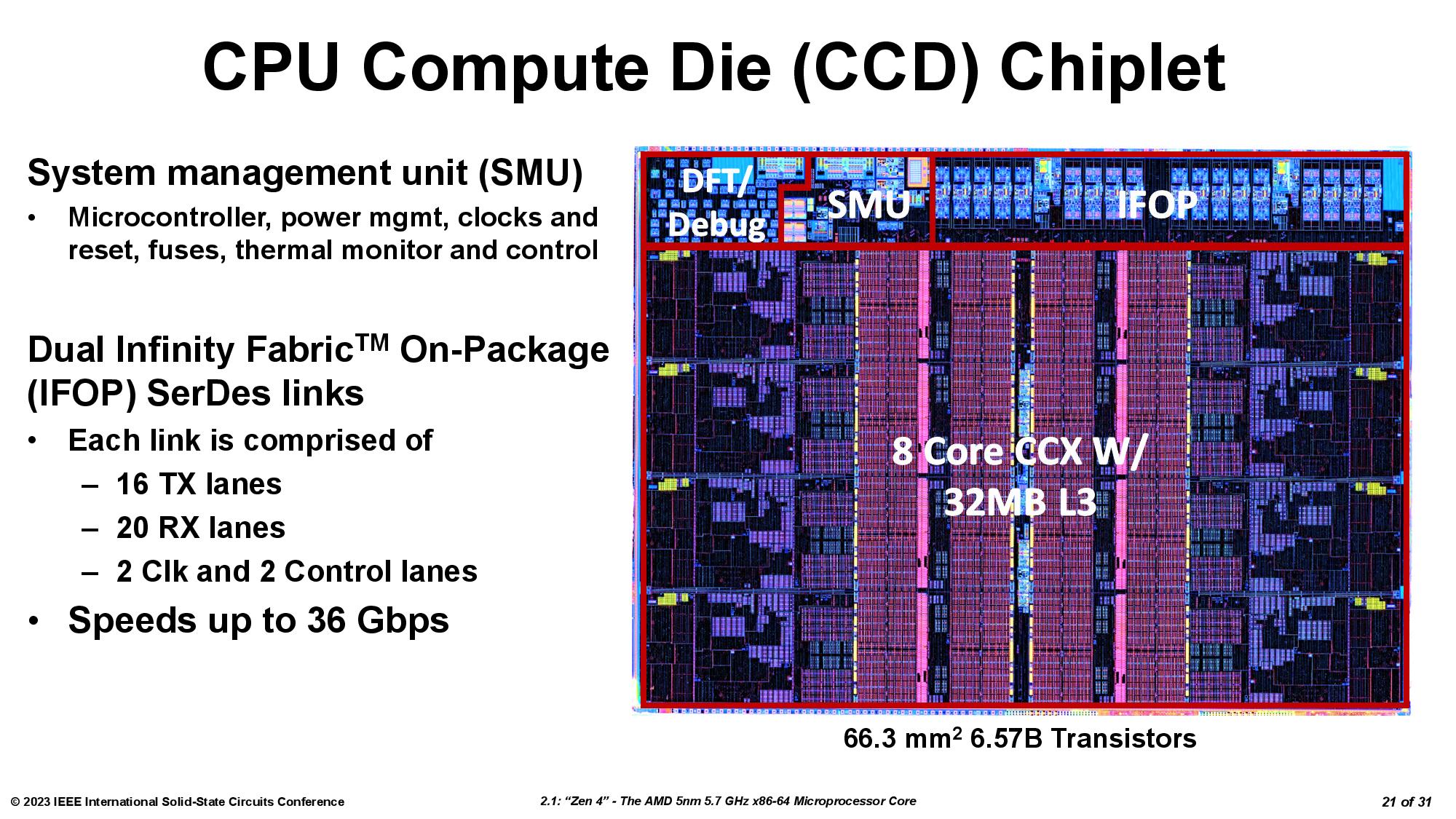
via: AMD Shares New Second-Gen 3D V-Cache Chiplet Details, up to 2.5 TB/s
https://www.tomshardware.com/news/amd-shares-new-second-gen-3d-v-cache-chiplet-details-up-to-25-tbsérdekes módon Iasi (Jászvásár, Románia ) is a ZEN4-es tervezőcsapat egyik székhelye.

-
HSM
félisten
"- zárt ökoszisztéma -> nincs verseny és a prémiumos felárat jobban megfizetik az ügyfelek."
Szerintem ez a helyzet. Korábban linkeltem egy összehasonlítást, utolsó bekezdés: [link] .
Ugyanakkor ez a fajta bővíthetetlen rendszermemória, mint irány, szerintem nagyon nem fogyasztóbarát, hiszen így gyakorlatilag kedvükre kopaszthatják meg az embereket, akiknek kicsit is több ramra van szükségük...
Jó okkal alakul ki a notebookoknál is az a gyakorlat, hogy a RAM, SSD, WIFI kártya a felhasználó által bővíthető/cserélhető volt hosszú éveken keresztül. Sajnos újabban ismét egyre több minden "integrálódik", válik cserélhetetlenné. Vegyél új notebookot, ha nem elég már.
Illetve M1 kapcsán szerintem ez is érdekes: [link] . És azóta az AMD-nek lett Zen4, illetve RDNA3 is...
-
S_x96x_S
addikt
> APU ... az elérhető memória sávszélesség
Az egyik irány lehet, az Apple - M sorozatának - egyesített memória sávszélessége,
viszont desktop vonalon nem tudom, hogy az AM5 socket tervezésekor mennyire volt ez szempont. ( szerintem nem nagyon )Az Apple ilyen szempontból szerencsésebb,
- nem kell külső termék-kompatibilitással törődnie és kísérletezhet
- zárt ökoszisztéma -> nincs verseny és a prémiumos felárat jobban megfizetik az ügyfelek.A Desktop GPU-k sincsenek annyira megkötve .. kisérletezgethetnek ..
- M1: 66.67GB/s
- AMD AM5 DDR5-5200 : 83.2 GB/s
- M2: 100GB/s
- M1 Pro: 200GB/s
- GeForce RTX 3050 8 GB : 228 GB/s
- RTX 4060 mobil : 256.0 GB/s ... 288.0 GB/s
- GeForce RTX 3060 12 GB : 360 GB/s
- M1 Max: 400GB/s
- RTX 4070 TI : 504 GB/s
- M1 Ultra: 800GB/s
- RTX 4090 : ~ 1008 GB/s
#8642Petykemano :
> Egyébként MLID valami olyasmit mondott, hogy 4050-ig bezárólag jöhet AMD apu.nézegetve a Phoenix APU -s leak-et ..
a várható desktop 65W-os APU a táblázatban lévő
"@ 2.8GHz (DDR5-5600) 54W" 2791 -es 3DMark TimeSpy
eredménnyei (jóindulatúan) már alulról közelitik
a GeForce GTX 1650 Ti / GeForce RTX 2050 eredményeket ..Ha jövőre sikerülne 3D-Vcache-el kitömni , akkor az nvidia x050 -es szint hozható lenne teljes biztonsággal.
https://videocardz.com/newz/amd-radeon-780m-rdna3-igpu-sees-further-4-improvement-in-a-new-leak
-
HSM
félisten
"szerintem valami a (technológiailag | gazdaságos gyártáshoz ) még hiányzik."

Én azt gondolom, az elérhető memória sávszélesség is korlátozó tényező lehet. A különálló GPU-hoz tesznek saját memóriát, míg az APU-nak osztoznia kell a CPU-magokkal is, illetve a DDR5 is korlát. Így is sokszor vélhetőleg emiatt LPDDR5X-el szerelik a meglévő mobil Renoir lapkákat. Lásd pl. Thinkpad T14-ek, ahol ellentétben a bővíthető, DDR4-es Intel verzióval, az AMD-s verzió forrasztott LPDDR5X-et kapott.A másik a gazdaságosság... Egy APU-t meg kell tervezni, majd gyártani, és nem árt, ha utána haszon is van belőle. Pl. egy Renoir ilyen szempontból egy jó kompromisszumnak tűnik gazdaságilag, teljesen jó belépő alapkonfiguráció alap-feladatokra akár 3D-ben, így takarékos is tud lenni, de nem is fogja vissza túlzottan a DDR5 memória, és gyártásban sem óriási pluszköltség a visszafogott iGPU. Ez így nagy tömegben, gazdaságosan mehet üzleti és multimédia célokra szánt prémium gépekbe, tehát a lehető legnagyobb vásárlói bázis felé.
Ennél komlyabb iGPU-val szvsz hamar sűrűsödni kezdenének a problémák, nehézségek, pluszköltségek. A komolyabb játékos vasakhoz pedig úgysem lenne elég erős, mivel korlát az elérhető sávszélesség, és gazdaságosabb lehet erre kis APU+GPU használata, ahogy most is többnyire meg van oldva.
-
Petykemano
veterán
Nem vagyok róla meggyőződve 100%-ig, hogy technológiai/gazdaságossági kérdés áll a háttérben.
Bár az igaz, hogy ha két hőtermelő pont van, azt könnyebb lehet hűteni, de egyben design szempontjából drágább is.
De szerintem ennek nem hűthetőségi tech szempontból van jelíntősége. Az tudható, hogy az AMD design winek a notebook piacon valójában szinte mind eredetileg intelhez (+nvidia?) tervezett kialakítások, amelyekből azért kap az AMD is egy vonalat, mert az AMD "kompatibilis" (itt persze nem socket kompatibilitásra kell gondolni, hanem fizikai kéret, magasság, meg ilyenek) chipeket tervez. Nem vagy nagyon kevés design készül elsődlegesen AMD hardver köré.Vagyis szerintem azért nem készül big apu, mert az OEM gyártóknak nincs olyan notebook designja, ami egy pontról lenne képes nagyobb hőt elvezetni és csak az AMD kedvéért nem is fognak ilyet tervezni. Ez nekik gazdaságossági kérdés persze, de semmi köze a kupak alatti dolgokhoz.
Egy másik ehhez kapcsolódó szempont lehet, hogy az oemek esetleg Szeretnék megtartani maguknak azt a lehetőséget (versenyeztetési lehetőséget) hogy ők válasszanak gput.
Egyébként MLID valami olyasmit mondott, hogy 4050-ig bezárólag jöhet AMD apu.
Az kis jóindulattal 3060, vagy rx 6600. Nagyjából erre a szintre érkezik a 200mm2-es navi33. Ha ez idén megérkezne, az szerintem kielégítő volna. Csak akkor tűnik "kevésnek", ha ezek 2025-ös tervcélok. -
S_x96x_S
addikt
> az AMD talán próbálgatja,
> de komolyan nem tervezi olyan nagyobb gpu erővel rendelkező apu piacra vitelét,szerintem valami a (technológiailag | gazdaságos gyártáshoz ) még hiányzik.
Ha minden rendelkezésre áll, akkor már nyomnák a piacra.
( Legalább a Prémiumos-ra .. )
És azt is remélem, hogy erre is gondoltak az AM5 socket tervezésénél )Technológiailag az egyik probléma az extrém hőtermelés lehet ,
ami minden sűrű design ( avx-512 ; gpu ; 3D-Vstack ) velejárója.
A jövő évi következő generációnál én viszont már várnék valami piaci próbálkozást is.
( remélhetőleg a GPU chiplet is kiforrja magát )A jövőben mindenképpen elkerülhetetlen lesz .. és ezt az AMD is látja ..
"AMD Envisions Stacked DRAM on top of Compute Chiplets in the Near Future"
https://www.techpowerup.com/305060/amd-envisions-stacked-dram-on-top-of-compute-chiplets-in-the-near-future
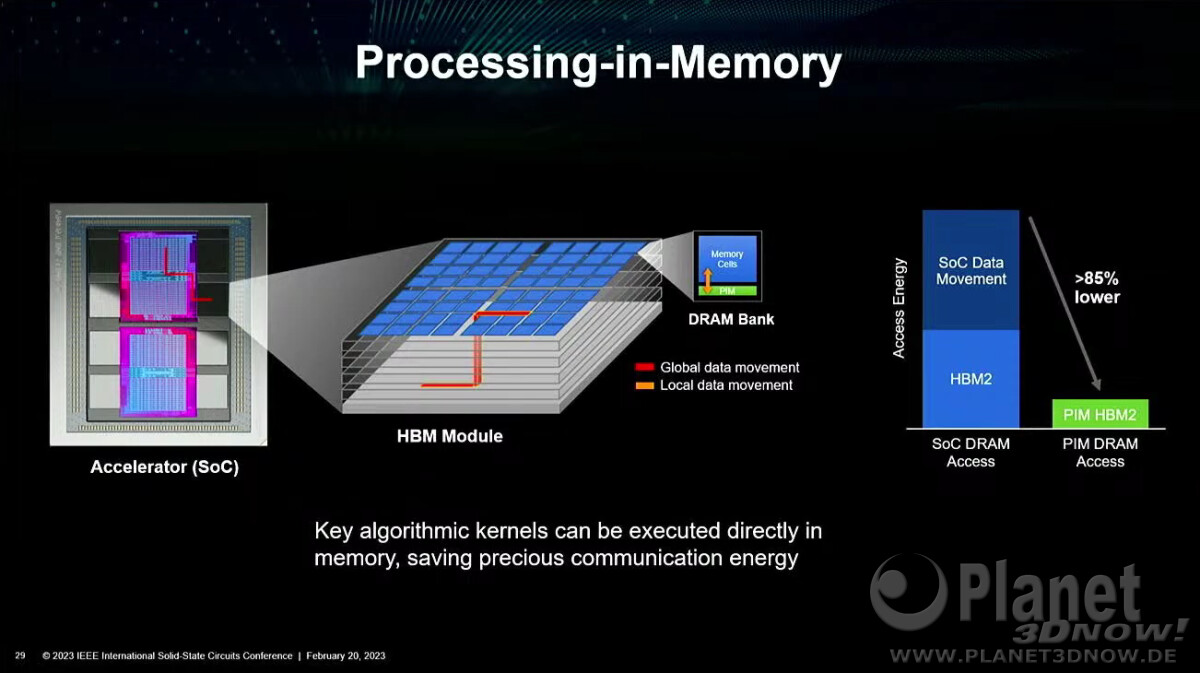
( a lenti ábránál )
viszont ami érdekes, hogy nincs megemlítve az Infinity Fabric.
csak a UCIe ..
ha az AMD hosszú távra gondolkodik és a UCIe-re fókuszál a GPU chiplet esetén, akkor az a piaci értékesíthetőség miatt is lehet, hogy más chipek ( ARM/RISC-V ? ) mellé lehessen tokozni.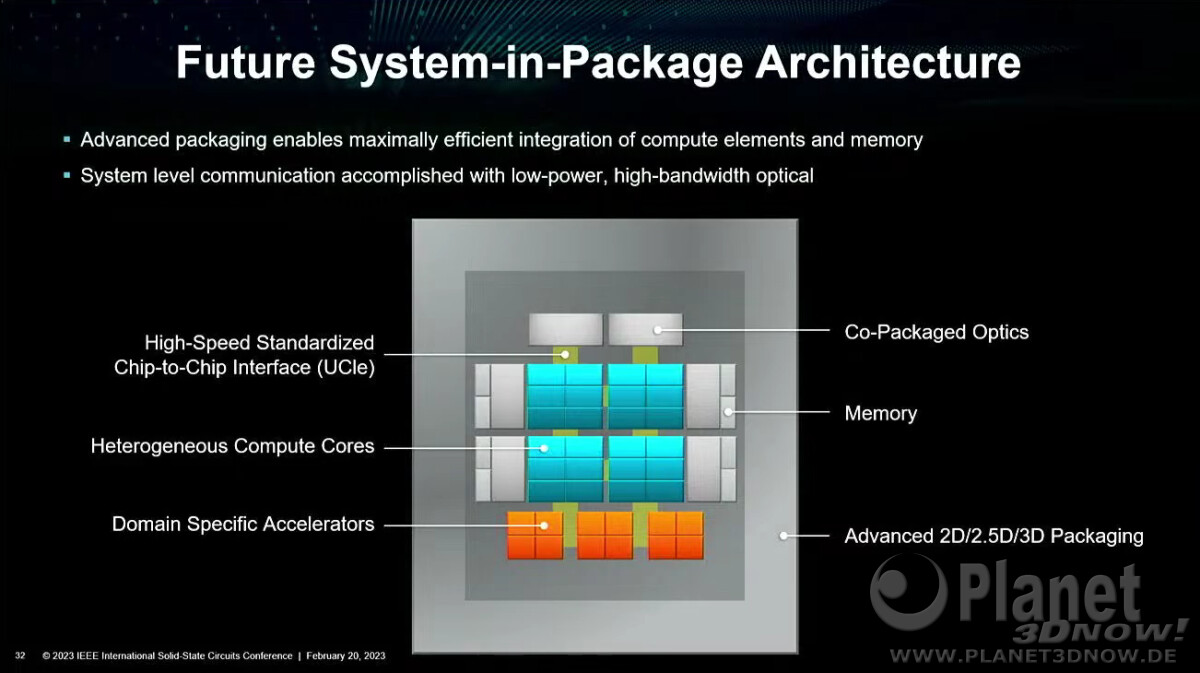
-
S_x96x_S
addikt
Threadripper 7000 / Storm Peak: 2023 szeptember .. ( >= Q3 2023 vagy október .. )
"AMD Storm Peak is expected to launch in September this year."
https://videocardz.com/newz/amd-ryzen-threadripper-7000-storm-peak-support-added-to-cpu-z -
Petykemano
veterán
Az nem annyira meglepő, hogy a Phoenix nem támogatja. Nincs' benne elég igp kakaó ahhoz, hogy érdemben befolyásolja, komolyabb dgpu mellé pedig valószínűleg úgyis a dragon range-t szánják (8 maggal)
Ami a videoban sokkal érdekesebb az az, hogy MLID szerint az AMD talán próbálgatja, de komolyan nem tervezi olyan nagyobb gpu erővel rendelkező apu piacra vitelét, amely számára indokolt lenne a 3d stacked.infinity cache a korlátozott rendszermemória sávszélesség kompenzálására és amellyel megtámadhatná a belépőszintű dgpuk piacát.
-
S_x96x_S
addikt
MLID szerint:
- Phoenix APU nem támogatja a V-cache-t.
- a Dragon Range viszont igen és akár lehet is ilyen laptop chip idén .. -
S_x96x_S
addikt
A 16 fejű sárkányka .. "Dragon Range" kezd tüzesedni
( jó értelemben és nem forróságra )
talán itt lenne értelme dupla 3DVcache-nek is ..Zen4,
16core/32thread
Max. Boost ClockUp to 5.4GHz
Default TDP: 55W ;
Default TDP55WAMD Configurable TDP (cTDP): 55-75W
PCI Express® VersionPCIe® 5.0
ECC Support: No"AMD strikes back: Ryzen 9 7945HX beats Intel Core i9-13980HX despite much lower power consumption"
https://www.notebookcheck.net/AMD-strikes-back-Ryzen-9-7945HX-beats-Intel-Core-i9-13980HX-despite-much-lower-power-consumption.698349.0.html
--> "Initial Verdict: AMD has the best mobile processor" -
HSM
félisten
Az ECO módnak nem vagyok a barátja.
 AM4-ben semmi hasznosat nem sikerült vele elérjek, és AM5-ün sem győzött meg, amit videókban láttam róla. Az 5600-asomon az vált be, ha a PBO-val átírom a limitjeit, azzal lehet belőle gyorsabb, torkosabb, vagy lassabb, takarékosabb rendszert csinálni, bár sajnos korlátot szab a dolognak, hogy nem vették a fáradtságot a gyári base-clock-nál alacsonyabb órajelekre is felprogramozni a V/F görbét. Így 3600Mhz és 0.92V kb. az alja az 5600-asomnak, és nagy valószínűséggel bőven lehetne ennél lejjebb is menni, ha jóval 50W alatti működés a cél.
AM4-ben semmi hasznosat nem sikerült vele elérjek, és AM5-ün sem győzött meg, amit videókban láttam róla. Az 5600-asomon az vált be, ha a PBO-val átírom a limitjeit, azzal lehet belőle gyorsabb, torkosabb, vagy lassabb, takarékosabb rendszert csinálni, bár sajnos korlátot szab a dolognak, hogy nem vették a fáradtságot a gyári base-clock-nál alacsonyabb órajelekre is felprogramozni a V/F görbét. Így 3600Mhz és 0.92V kb. az alja az 5600-asomnak, és nagy valószínűséggel bőven lehetne ennél lejjebb is menni, ha jóval 50W alatti működés a cél.Ez a PRO verzió dupla X3D CCD-vel nekem is tetszene.
Viszont asztali, félig-pro felhasználásra a jelenlegi megoldás is szimpatikus, hogy egész pici felárért van órajelben erős és cache-ben erős mag is benne, így mindenféle kódhoz párosítható a legjobban passzoló feldolgozó. 
-
S_x96x_S
addikt
> Nekem nagyon tetszik egyébként,
> hogy a 7950X3D némileg csökkentett TDP keretet kapott,
> így sokkal jobb perf/watt mellett üzemel.Aki amúgy is ECO módban hajtaná
( mert a stabilitás fontosabb a több napos taszkok futtatása miatt )
azoknál hasznos lehet
Amúgy lehetne PRO-s verzió dupla V-Cache-es CCD-vel - én azt jobban preferálnám.Linux-on valószínüleg lehet majd később a 3D-Vcache-re tunningolni majd a fordító programokat (gcc,clang), hogy még optimalizáltabb kódot adjon
.. de ez a felemás architektúra egy kicsit megbonyolítja az egészet.Ha egy árban lenne a 7950X-el, akkor nem lenne kérdés, hogy melyik ..
Én még megvárom a PugestSystems tesztjét is .. remélem 1-2 héten belül lesz nekik ..
-
HSM
félisten
Jelenleg játékokban kevés esetben jut szerep 8 erős magnál többnek. Remek és kellően extrém példa, a TPU 720P+Ultra tesztje RTX4090-el, a 7950X ugyanazt tudja, mint a 7700X, míg a "házi készítésű" 7800X3D vagy a cache-preferált 7950X3D szépen ellép mindentől [link] . Ez alapján én azt gondolom, racionális vásárló nem játékra vesz ilyesmit elsősorban, tehát nem feltétlen lesz mellette egy extra torkos VGA. Illetve vannak még hozzám hasonló emberek, akik azt sem szeretik, ha feleslegesen sokat fogyaszt a rendszerük, és inkább rászánnak kis időt a gyárinál kedvezőbb perf/watt működésre hangolni a rendszert. És nem is feltétlenül a gazdasági oldala miatt, az is manapság már hangsúlyosabb, de anélkül sem szeretem a pazarlást, az indokolatlan fogyasztást.
-
Petykemano
veterán
Lehet, hogy az ilyen nagyfogyasztású kártyák relatíve ritkák, ugyanakkor talán az elmondható, hogy ahhoz, hogy a 13900K, 7950X, 7950X3D magasságú processzorok játékok terén az ilyen nagyfogyasztású GPU-k mellett tudják igazán megcsillogtatni a tudásukat. Nem?
Viszont ettől függetlenül van más, ennél talán sokkal fontosabb aspektusa a dolognak: a 7800X3D, pontosabban annak mobil változata elképesztően versenyképes gaming teljesítményt biztosíthat elképesztően hatékonyan/energiatakarékosan.
-
HSM
félisten
"Persze az is világos, hogy nem ez az 50-60W lesz a meghatározó a 400-500W-os videokártyák mellett."
Azért 4-500W-os videókártyák szerencsére elég ritkák. Talán a 3090TI és RTX4090 megy fel eddig, a többi inkább 350W és alatta. Nekem csak egy "szerény" 6800XT-m van, papíron 300W TBP, de kicsit finomhangolva már vidáman elvan kevesebből gyorsabban, az egész gép szokott fogyasztani egy PBO-zott Ryzen 5600-al Witcher 3 RT alatt ~350W-ot konnektorból, monitor nélkül...RTX4090 ugyanúgy kb. teljesítményvesztés nélkül 300W-ra lehúzható.
Szóval szerintem van jelentősége, hogy a CPU 80 vagy 150W-ból látja el a feladatát, főleg egy józanul konfigurált VGA mellett. Nekem nagyon tetszik egyébként, hogy a 7950X3D némileg csökkentett TDP keretet kapott, így sokkal jobb perf/watt mellett üzemel.
TPU-nál nagyon érdekes, hogy megnézték a fogyasztásokat és perf/watt-ot, hogyan alakulnak a különböző CCD-ket preferálva: [link] . Elég szembeötlő az alacsonyabb órajelre korlátozott, így szükségszerűen hatékonyabb CCD előnye. -
Petykemano
veterán
A teljesítmény valóban megvan az Intel részéről de a fogyasztásbeli különbség nagyon durva:
[link]
A dolgot még csak az sem árnyalja, hogy az Intel esetén ez a fogyasztás csak amiatt áll elő, mert az utolsó párszáz mhz már durván meredek fogyasztási görbén lenne. Az intel gyártástechnológiájára ez a meredekség ugyanis kevésbé jellemző, ezért tudott mindig is - persze növekvő fogyasztás mellett - jól skálázódni.
(Persze az is világos, hogy nem ez az 50-60W lesz a meghatározó a 400-500W-os videokártyák mellett.)
-
Devid_81
félisten
AMD chipset drivers feature special game optimizations for Ryzen 9 7000X3D CPUs
Most ez akkor megint kerdeseket hagy maga utan, akik teszteltek vajon ezzel az uj driverrel teszteltek vagy enelkul?
Ma jonnek ki a reviewk elvileg -
S_x96x_S
addikt
> "Ha az AMD core design-ja egyszerűbb és kisebb is, viszont
> az AMD több packaging trükköt kellett felhasználnia.
> Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache
> lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta."azért az AMD-nek megvan a technológiai tapasztalata és előnye
és ez az előny nagyrészt a TSMC-vel történő szoros együttműködésből is következik.Az hogy az Intel előtt ott van a lehetőség nem jeleni azt is hogy sima út. A Sapphire Rapids az első komplexebb chipje az Intelnek és igencsak izzadságos volt.
És az AMD is volt egy kis melója a 3D-Vcache-el és nem hiszem, hogy ne lehetne még tovább
fejleszteni.- Ha az AMD kiheréli az AVX-512 -öt a ZEN4c/4d -ből, akkor az egy öntökönszúrás ..
- az AMX utasításkészlet hiányzik még ahhoz, hogy teljesen utolérje az AMD az Intelt.
- A ZEN5 -re +20-40% IPC célt ( a ZEN4-hez ) - pletykált MLID ( 2021 November)
vagyis én itt jelentős szélesítést várok.
- amit én érzékelek, hogy az InfinityFabric a fő fókusz és az MI300 szerű konstrukció jöhet AM5-re is. ( Threadripper meg eleve adott lesz )
- És a ZEN5-ös is már kaphat NeuralEngine- gyorsítót.
- És talán elkezdődik az FPGA mélyebb integráció a GPU és CPU-ba.
-
Petykemano
veterán
> Az Intel gyártástechnológiai hátránya leginkább abban mutatkozik meg,
> hogy maximum terhelésen irdatlan magas a fogyasztás.Igen, de ez döntően a maximális MT terhelés folyamán mutatkozik meg. Játékokban tudtommal normálisnak mondható a fogyasztás.
Azt gondolom, hogy ezt az Intel több kis mag hozzáadásával tudná megfelelően kezelni. +2 atom cluster biztosan kellően nagy mértékben emelné a MT teljesítményt és lehetne csökkenteni az órajelet 3-500MHz-cel.
Bocsánat, nem szétoffolni akarom a topikot. Csak azért említettem meg, mert szerintem az Inteltől ebben a vonatkozásban ugyanazt a megoldást fogjuk látni, mint amit az AMD is csinál (ZenX+ZenXc) hogy külön lapkán fogja hozzácsatolni a 8 nagy maghoz a 2-4-8 (majd kiderül) atom clustert. Már csak azért is, mert az L3$-hez csatolt magok/clusterek száma nehezen skálázható tovább.
Ha tippelnem kéne, akkor azt jósolnám, hogy az Intel hamarabb fog egy tile-on L4$-t adni a 8 nagy mag és a kismagok összekötésére.> Ennél sokkal jobbat chipletezéssel már nagyon nehéz elérni.
Szerintem valamikor a közeljövőben el kell / el fogják engedni a SerDes-t és áttérnek horizontális csatolásra (SoIC_H) vagy hasonlóra (lásd Navi31)
> A kérdés, hogy hogyan fog tudni szélesíteni az AMD a jövőben, hogy ne essen visssza a latency Zen1 szintre?
Ha nem akarnak elindulni az M1 irányába, akkor én a megoldást a 3D packaging-ben látom.
Azt gondolom, hogy ha az L3$-t sikerült 3x-os méretre emelni 5%-os késleltetés emelkedés mellett, akkor ugyanezt meg lehetne tenni az L1$ és L2$ esetében is. Persze elég valószínű, hogy ez nem lehet opcionális, mint most a v-cache.#8625 HSM
Ez így van, de azért az Intel is küzd már pár éve a Foveros-szal és az EMIB-bel. Szerintem ott szúrták el, hogy azt gondolták, hogy ez egy egyszerű gyártástechnológiai trükk, és mindent is akartak egyszerre. De azért lassan csak meg kéne már érkezni! -
HSM
félisten
"Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta."
Itt azért hozzátenném, hogy a packaging trükk nem feltétlen egy egyszerű gyártástechnológiai dolog. Valószínűleg szinte mindent hozzá kell igazítani, optimalizálni, hogy jól működjön. Az AMD-nél erre sokéves gyakorlat van. Ezt nem feltétlen lesz egyszerű behozni. -
 paprobert
őstag
paprobert
őstag
Egyetértek a meglátásaiddal.
Az Intel gyártástechnológiai hátránya leginkább abban mutatkozik meg, hogy maximum terhelésen irdatlan magas a fogyasztás.
Meg tudták építeni azt a magot, amit szerettek volna, nem kellett visszavágni az architektúrát, el tudták érni a megcélzott órajeleket, de a működési tartományt vizsgálva a vállalhatatlan kategóriába csúszott padlógázon a termék.Én a találgatások idején a Zen4-re a mag szélesítését vártam volna, de egyértelműen nem ez történt. A Zen4 igazából egy ultra-low latency mag. Ennél sokkal jobbat chipletezéssel már nagyon nehéz elérni.
A kérdés, hogy hogyan fog tudni szélesíteni az AMD a jövőben, hogy ne essen visssza a latency Zen1 szintre?
Illetve mikor hoz olyan hibrid dizájnt, ahol egy low-latency és/vagy throughput-optimalizált és/vagy egy szélesített "nagy mag" CCD fog együtt dolgozni?Ideális esetben a jelenlegi Zen4 fölé és alá is kellene egy új mag család, hogy az egy szálas teljesítmény, és a throughput is javulhasson, 3 szintes hibrid dizájnként.
-
Busterftw
nagyúr
-
S_x96x_S
addikt
> Az jár a fejemben, hogy azért az Intel akkor valamit mégiscsak jól csinál...
Kíváncsi leszek a Raptor Lake frissítésre, vajon mivel lesz több ?
( mert a Meteor Lake-S -t a fejlettebb magokkal elkaszálták )mindenesetre teljesen kiszámíthatatlan a jövő .. gyors és hirtelen változások vannak ...
-
S_x96x_S
addikt
> Azt írják, átlagban 5-6%-kal gyorsabb,. mint az 13900K
talán van még remény ..
"These benchmarks might have been done with the older chipset drivers. The new chipset and optimized drivers deliver at least 20% better performance than the previous ones so wait for the real benchmarks next week. :)"
https://twitter.com/hms1193/status/1629116333991272449valószínüleg erre gondolhattak
"AMD Preps New 1.0.0.7 Chipset Driver Optimized For Ryzen 7000 3D V-Cache CPUs"
https://wccftech.com/amd-preps-new-1-0-0-7-chipset-driver-optimized-for-ryzen-7000-3d-v-cache-cpus/ -
Petykemano
veterán
Az jár a fejemben, hogy azért az Intel akkor valamit mégiscsak jól csinál...
az N5 azért valamivel mégiscsak fejlettebb gyártástechnológia, mint az Intel 7. Tranzisztorsűrűségben mindenképp és talán fogyasztásban is.
70-80mm2-es N5 lapka + ~120mm2-es N6 lapka. Utóbbiban döntően olyan részegységek vannak, amelyek N5-ön sem lennének sokkal kisebbek. Tehát az egész nyugodtan tekinthető egy kb 200mm2-es lapkának. Persze az AMD gyártási költség vonatkozásában talán sokat nyer azon, hogy a lapka nagyobb része mégse a drágább gyártástechnológán készül, de valamit meg veszít (latency) azáltal, hogy a chipleteket össze kell kötni.Ha pontos akarok lenni, akkora 2CCD-s változathoz két ~80mm-es lapka kell, ami már nem is 200 akkor, hanem 280. És ahhoz, hogy ez elérje azt a játék teljesítményt, amit az Intel lapkája tud, rá kellett még pakolni legalább egy kb ~40mm-es cache lapkát. Ez alsó hangon 240, felső hangon 320mm2 lapkát jelent. Nem is beszélve a 3D packaging költségéről, hibalehetőségeiről.
(Persze az is világos, hogy az AMD nem a legjobb asztali CPU teljesítmény elérése érdekében csinálja így, hanem pont a skálázhatóságért.)
Tulajdonképpen az AMD használ most több szilíciumot, komplexebb a gyártástechnológiája. Persze cserébe lényegesen jobban skálázható, szűkös waferkapacitások esetén talán előnyösebb allokációs lehetőséggel.
az Intel core design-ja szerintem valamivel jobb, de valószínűleg lényegesen nagyobb, ami sokat ront a skálázhatóságon. A MT teljesítményt kismagokkal érik el, ami az asztali környezetben jól mutat, de az elvileg jobb core design szerverkönyezetben való költséghatékony újrahasznosítását nem segíti. (feltéve, hogy az Intel nem akar ott is hybrid designnal megjelenni) Ha az AMD core design-ja egyszerűbb és kisebb is, viszont az AMD több packaging trükköt kellett felhasználnia. Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta. Az AMD chipletezik, lehívta az ebből fakadó költség és volumen előnyöket, addig az Intel előtt ez az út még mindig nyitott.Én azt látom, hogy az AMD lehívta az előtte álló core design-on kívüli low-hanging fruits-ok lehetőségeit és következő lépés mindenképpen a core design komoly átalakítása. Erre egyébként elő is készítették a terepet a Zen4c bevezetésével. Megengedhetik maguknak azt, hogy hízlalják a magot, ha annak lesz karcsúsított változata is párhuzamosan.
És lassan az Intel is talán megérkezik a saját packaging technológiáival, chipleteivel.
-
 Atti777
senior tag
Atti777
senior tag
Nem rémlik hogy láttam volna itt:
"ASUS began rolling out Beta UEFI firmware updates for its Socket AM5 motherboards encapsulating AGESA 1.0.0.5 patch-C microcode. This exposes several new options to end-users through the UEFI Setup Program, which gives them greater control over the way the processor prioritizes workload among the two CCDs (CPU complex dies) on 12-core and 16-core Ryzen 7000 series processors, including the upcoming 7000X3D processors.While AMD is working to release Chipset Software updates that include "3D V-cache Optimization driver" components that introduce OS-level awareness of the asymmetric implementation of 3D V-cache on the 7900X3D and 7950X3D where only one of the two CCDs has the additional cache" [link]
-
Petykemano
veterán
Azt írják, átlagban 5-6%-kal gyorsabb,. mint az 13900K
Ezzel a táblázattal kiegészítve: [link] mondom, hogy a különböző mérésekből az derül ki, hogy a 13900K 10%-kal általában gyorsabb, mint a 7950X.
Ez azt jelenti, hogy a 7950X3D kb 15%-kal lehet gyorsabb átlagosan, mint a 7950X
(Mint ahogy a fenti kép is mutatja, elképzelhető, hogy bizonyos játékokban ennél nagyobb gyorsulás is mérhető, másokban meg egyáltalán nem.) -
S_x96x_S
addikt
2023 Előrejelzés Szerver piac:
Intel 70.9%; AMD 20% ; ARM 8.1%; más: 0.5%;"AMD Will Hold 20% of Server CPU Market in 2023, Analysts Say"
https://www.tomshardware.com/news/amd-will-hold-20-of-server-cpu-market-in-2023-analysts-say -
S_x96x_S
addikt
V-Cache CCD Freq
7800X3D>7950X3D
https://twitter.com/9550pro/status/1627636895714009090vagyis kevesebb lesz 5Ghz-nél is az 7950X3D V-cache CCD-nek a boost-ja ??
vagy ez csak akkor igaz, hogyha együtt megy mind a két CCD .. -
Petykemano
veterán
Zen4X3D tesztek: február 27-én [link]
-
HSM
félisten
A nagy L3-nak mindig is ez volt a baja... Néhány specifikus helyzetben csodát tesz szó szerint, míg másokban csak minimális hátrány a pár órajelnyi extra késleltetése révén. Én az MSRP szerinti 50 dollár felárat szó nélkül kicsengetném érte.
Jó példa egyébként a Renoir. Használok egy 15w-os hatmagost belőle, és többnyire szépen szedi a lábát 2x4MB L3-al is, főleg ahhoz képest, hogy ez milyen kevésnek tűnik.
-
hokuszpk
nagyúr
ilyen egál vagy lassabb esetekben az 5800X3D védhető volt azzal, hogy alacsonyabb a boostja ; a 7800X3D -t majd meglátjuk ; de talán a marketingnek jóttenne, ha ezekről a 16 magos motyókról olyan eredmenyek szivarognának ki, ahol látszik, hogy erősen besegit a cache, mert maxfrekiben papiron megegyezik a normál verzióval.
-
Petykemano
veterán
-
hokuszpk
nagyúr
-
HSM
félisten
-
S_x96x_S
addikt
-
S_x96x_S
addikt
(nekem érdekesség )
az új procik kategórizálása: "Consumer Use" Yes/NoAMD Ryzen™ 9 7950X Consumer Use = Yes
AMD Ryzen™ 9 7900X Consumer Use = Yes
AMD Ryzen™ 9 7900 Consumer Use = YesAMD Ryzen™ 9 7950X3D Consumer Use = No
AMD Ryzen™ 9 7900X3D Consumer Use = No
AMD Ryzen™ 7 7800X3D Consumer Use = Yesnem értem, hogy a top2 X3D miért nem "Consumer Use" ..
-
Petykemano
veterán
> az L3 ha jóltévedek victim cache. azaz az előtte lévő szintekből kicsorgó adatokat tárolja.
> Szvsz dupla méretú L1 -ből kevesebb adat csorog le.
Igen, de ez magonként csak +0.5MB, egy CCX-ben összesen 4MB többlet. Ez magonként 0.5MB-nyi adat gyorsabb hozzáférését teszi lehetővé, mivel az a 0.5MB nem az L3$-ben, hanem az L2$-ben van.De a Zen architektúra achilles sarka nem ez, hanem a chiplet felépítés miatt magasabb késleltetésű memóriaelérés. (Nem tudom esetleg a sávszélesség jelenthet-e bármilyen limitációt, mindenesetre itt van olyan Genoa konfiguráció felvázolva, ahol 2 GMI linken kereszül csatlakozik egy CCD) Az, hogy a memóriavezérlő elérése nem valamilyen belső buszon közelre történik, hanem szubsztráton keresztül, biztosan limitáló tényező.
A lényeg, hogy a 32MB helyett 96MB L3$ viszont nem 4MB valamiyel gyorsabb elérését teszi lehetővé, hanem 64MB-ét pont azon a ponton, ahol a legérzékenyebb.
Persze nyilván az L3$ cache méretére igaz a csökkenő határhasznosság elve.
> Zen5 -re volt valami hír, hogy összevonják az L2 -t ;
> ha igaz a hír megkockáztatom, hogy bazi nagy közös L2 mellett akár el is tűnhet az L3.Szerintem 8 mag számára közös L2$-t csinálni megfelelő gyorsaságban és hogy akkor is kielégítő teljesítményt nyújtson, amikor a magok nem valami közös problémán dolgoznak, nehéz lehet.
A szóbeszéd szerint a szerverek szeretik a gyors privát L2$-t.Az L3$ eltűnhet, de valószínűbbnek tartom, hogy 3D stackelik.
Az még esetleg lehetséges út, hogy elengedik a szubsztráton keresztüli kapcsolatot (SerDes) és az IOD és a CCD között a NAvi31-nél látott módon (MCD-GCD) teremtenek szélessávú kapcsolatot. Ebben az esetben a stacked L3$ már mehetne az IOD-ra is és akkor az minden CCD-t ki tudna szolgálni. Ez abból a szempontból is, jó volna, hogy a CCD helyett az IOD-nak lehet kliense egy GCD is, vagyis egy IGP és akkor máris sikerült megoldani az APU-k 3D stackelt v-cache/infinity cache kérdését is.Azt persze nem tudom, hogy ez tényleg jó irány-e. L3$ nélkül azért az egész félkarú óriás. EGy ilyen bonyolult packaging drága is lehet, meg növelheti a hibaarányt is, meg volumenkorlátos is lehet ahhoz képest, ha van egy közepesen jó, de minden extrát nélkülöző alap lapkád, amit végtelen mennyiségben, hibátlanul, olcsón tudsz kipumpálni és szükséges esetén, kisebb volumenben ezzel-azzal dekorálni.
Az AMD eddig megfigyelt kockázatvállalási hajlandósága mellett azt gondolnám, hogy inkább valószínűtlen a kizárólag egzotikus kialakításra, 3D packagingre építő megközelítés nagy volumenben, olcsón gyártható jó mainstream bázislapka nélkül. (És szerintem L3$ nélkül nem lenne jó)
-
hokuszpk
nagyúr
nagyon egyszerű logikával közelítem a dolgot : az L3 ha jóltévedek victim cache.
azaz az előtte lévő szintekből kicsorgó adatokat tárolja. Szvsz dupla méretú L1 -ből kevesebb adat csorog le. Zen5 -re volt valami hír, hogy összevonják az L2 -t ; ha igaz a hír megkockáztatom, hogy bazi nagy közös L2 mellett akár el is tűnhet az L3. -
S_x96x_S
addikt
A GeekBench -es dolgot a videocardz és a wccftech is lehozta ..
Azzal egyetértek, hogy kis mintából nem sokat tudunk következtetni
- csak azt, hogy elkezdödött a tesztelés és kezdem magamat felkészíteni a MultiCore csökkenésre, habár nekem a Phoronix-os teszt lesz a mérvadó ..
- A geekbench-es teszt amúgy se volt sose a kedvencem .."AMD Ryzen 9 7950X3D in Geekbench: slower multi-core, similar single-core to 7950X"
https://videocardz.com/newz/amd-ryzen-9-7950x3d-spotted-on-geekbench-with-similar-single-core-performance-to-7950x"AMD Ryzen 9 7950X3D 3D V-Cache CPU Benchmarks Leak: 10% Slower In Multi-Thread & Similar Single-Core As 7950X"
https://wccftech.com/amd-ryzen-9-7950x3d-3d-v-cache-cpu-benchmarks-leak-10-percent-slower-versus-7950x/ -
Petykemano
veterán
Fene tudja
Azt biztos, hogy a frekvencia-regresszióval kapcsolatos gyermekbetegségek javítására vonatkozó előzetes hírek félreértésnek bizonyultak.
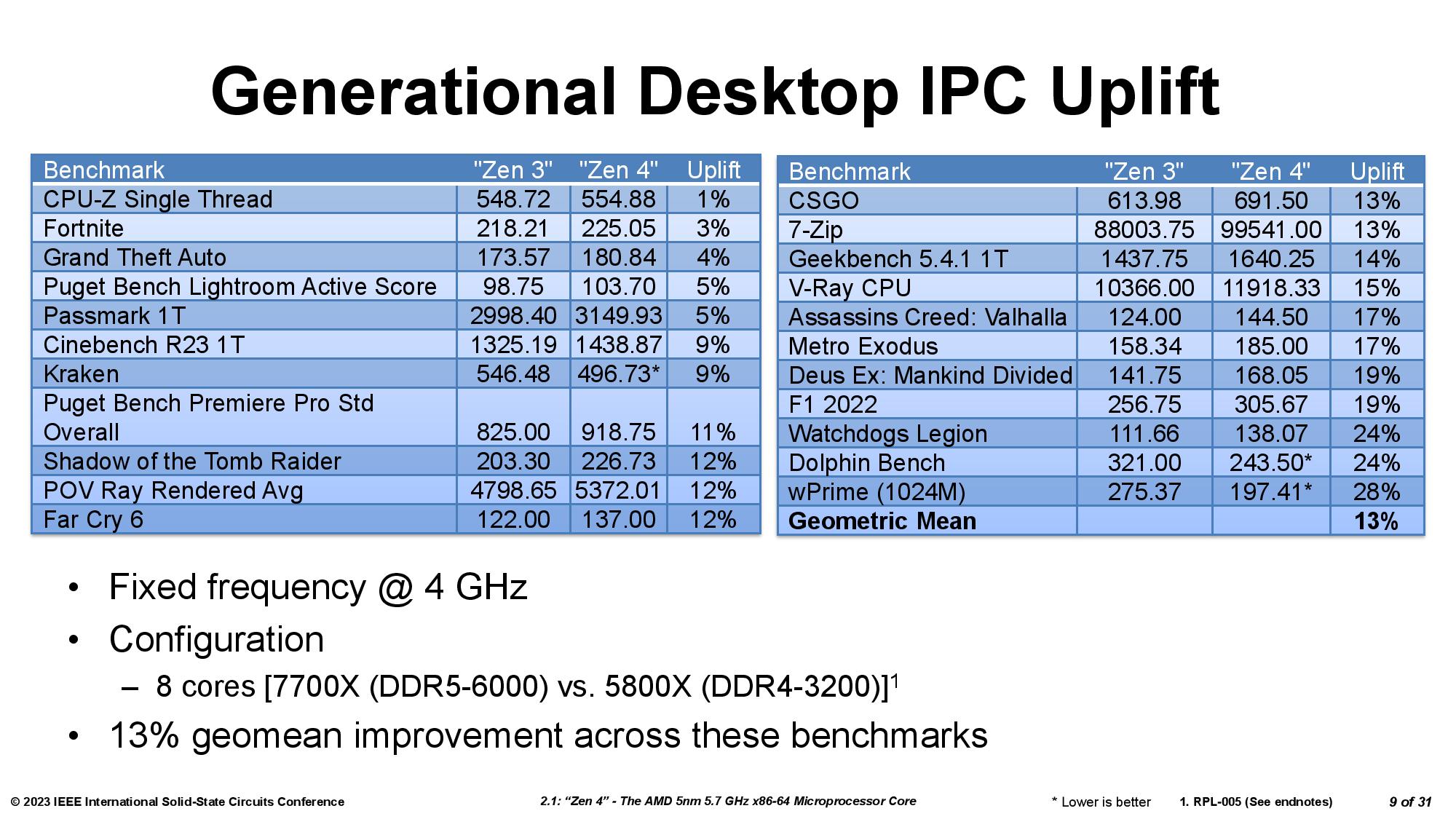
Az AMD saját bevallása szerint 1% IPC növekedést tulajdonít önmagában a L2$ duplázott méretének. Ami laikusoknak egyrészt meglepő, másrészt viszont mindenhonnan azt hallani, hogy cache méretének egyszerű növelésétől ritkán változik a teljesítmény nagymértékben, hanem a megnövelt cache mérete köré kell tervezni a processzor többi aspektusát is és úgy aknázható ki a nagyobb cache nyújtotta előny (most azt a részét, hogy a cache méretének növelése késleltetés növekedésével is együtt jár és azt a trade-off-ot is figyelembe kell venni, hagyjuk)Az a gyanúm, hogy a 3D V-cache haszna is félig-meddig úgymond "véletlen". Nem emlékszem olyan programra, ahol egyszálas teljesítmény nőtt volna annak hatására. A kellemes hatását ott fejti ki, ahol a magok között adatmegosztás zajlik és a megnövelt v-cache már kellően nagy ahhoz, hogy durván sokminden beleférjen.
Mivel nem hallottunk arról, hogy a V-cache-t bármi módon tweakelték volna, ezért az én várakozásom az, hogy pontosan ugyanúgy fog működni, és ugyanakkorát fog dobni a teljesítményen is, mint az 5800X3D.
HA jól megy a hybrid mód a 12 és 16 magos példányok esetén, akkor el tudok képzelni egy olyan szituációt, hogy ha a független programszálakat a v-cache nélküli CCD-n az adatmegosztókat pedig a v-cache-sel szerelt magokon futtatja, akkor nagyobb is lehet az előny. -
hokuszpk
nagyúr
nemtalálom hol, de valahol azt tippeltem, hogy olyan nagyot, mint az 5800X3D nem fog ütni, mert azoknak a szűk keresztmetszeteknek egy reszet, amit a 3d cache athidal, kiutoltak az L1, TLB es tarsai mértének növelésével. Azert valamire biztos jó lesz ; olyan indokkal, hogy "mindenki erre vár", csak nem dobja piacra az AMD.
-
Petykemano
veterán
Egy 7950X-szel összehasonlítva nem mutatkozik meg GB5-ben a megnövelt L3$-ben rejlő potenciál.
-
hokuszpk
nagyúr
ipc = Zen4 * 1.22 ? na arra már talán érdemes lesz a Zen3 -ról váltani.
kerül amibe. kezdem félretenni a lét.





















![;]](http://cdn.rios.hu/dl/s/v1.gif)







 AM4-ben semmi hasznosat nem sikerült vele elérjek, és AM5-ün sem győzött meg, amit videókban láttam róla. Az 5600-asomon az vált be, ha a PBO-val átírom a limitjeit, azzal lehet belőle gyorsabb, torkosabb, vagy lassabb, takarékosabb rendszert csinálni, bár sajnos korlátot szab a dolognak, hogy nem vették a fáradtságot a gyári base-clock-nál alacsonyabb órajelekre is felprogramozni a V/F görbét.
AM4-ben semmi hasznosat nem sikerült vele elérjek, és AM5-ün sem győzött meg, amit videókban láttam róla. Az 5600-asomon az vált be, ha a PBO-val átírom a limitjeit, azzal lehet belőle gyorsabb, torkosabb, vagy lassabb, takarékosabb rendszert csinálni, bár sajnos korlátot szab a dolognak, hogy nem vették a fáradtságot a gyári base-clock-nál alacsonyabb órajelekre is felprogramozni a V/F görbét. 






Új hozzászólás Aktív témák
-
8700 - 8601
10138 - 10001 10000 - 9901 9900 - 9801 9800 - 9701 9700 - 9601 9600 - 9501 9500 - 9401 9400 - 9301 9300 - 9201 9200 - 9101 9100 - 9001 9000 - 8901 8900 - 8801 8800 - 8701 8700 - 8601 8600 - 8501 8500 - 8401 8400 - 8301 8300 - 8201 8200 - 8101 8100 - 8001 8000 - 7901 7900 - 7801 7800 - 7701 7700 - 7601 7600 - 7501 7500 - 7401 7400 - 7301 7300 - 7201 7200 - 7101 7100 - 7001 7000 - 6901 6900 - 6801 6800 - 6701 6700 - 6601 6600 - 6501 6500 - 6401 6400 - 6301 6300 - 6201 6200 - 6101 6100 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Hirdetés
- sziku69: Fűzzük össze a szavakat :)
- Anglia - élmények, tapasztalatok
- Milyen monitort vegyek?
- Formula-1
- exHWSW - Értünk mindenhez IS
- Forza sorozat (Horizon/Motorsport)
- Autós topik
- Rezsicsökkentés, spórolás (fűtés, szigetelés, stb.)
- Állítólag összeolvadt a OnePlus és a Realme
- Milyen házat vegyek?
- További aktív témák...
- Kingston Fury / G.Skill Ripjaws V 64GB 32GB 2x32GB 2x16GB 4x16GB DDR4 3200MHz CL16 RAM memória BAZÁR
- AMD Ryzen 9 5900X / 3900X / R7 3700X + MSI / Gigabyte X570 / B450 Alaplap + Arctic hűtős félkonfigok
- Ryzen7 5700x/ 32GB DDR4/ RX6900XT 16GB/ 1TB SSD alapu PC/ garancia/ ingyen postapont
- Saeco Royal Digital Plus I Irodai igásló I Szervizelve I Garancia I Számla I Beszámítás
- Samsung Galaxy Z Flip4 Lila 8/128GB Kártyafüggetlen
- Dell Optiplex 3050 SFF,i5-6500,8GB DDR4,256GB SSD, WIN11
- HP Thunderbolt 4 kábel
- BESZÁMÍTÁS! GIGABYTE B650E R9 7900X 64GB DDR5 1TB SSD RTX 5080 16GB NZXT H9 Flow White Corsair 850W
- Eladó Dell Latitude 7440 Új állapotban i7-1365U 32 GB DDR5 RAM 1TB SSD Dell pro support garancia
- HIBÁTLAN iPhone 13 Pro 128GB Gold -1 ÉV GARANCIA -Kártyafüggetlen- MS4674, 100% AKKSI
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest