
- creation: Elég lett abból, hogy a nagy gépeim nem képesek behúzni a filamentet
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- Parci: Milyen mosógépet vegyek?
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- GoodSpeed: Samsung Galaxy A56 5G
- Meggyi001: Áram nélkül....méltóság nélkül.....
- gban: Ingyen kellene, de tegnapra
- GoodSpeed: MacBook egy kis gikszerrel.
- Elektromos rásegítésű kerékpárok
-
9600 - 9501
10138 - 10101 10100 - 10001 10000 - 9901 9900 - 9801 9800 - 9701 9700 - 9601 9600 - 9501 9500 - 9401 9400 - 9301 9300 - 9201 9200 - 9101 9100 - 9001 9000 - 8901 8900 - 8801 8800 - 8701 8700 - 8601 8600 - 8501 8500 - 8401 8400 - 8301 8300 - 8201 8200 - 8101 8100 - 8001 8000 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 hokuszpk
nagyúr
hokuszpk
nagyúr
-
 A.Winston
tag
A.Winston
tag
Ha tenyleg ennyi es sokat gyorsan akarnak eladni az nem azt is jelentheti, hogy ne adj isten most tenyleg sikerult keknel is alkotni valamit? Nem fanboisagbol
kerdem, csak am4-eskent - bar x3d jo meg - lassan elgondolkodnek valtason. -
 carl18
addikt
carl18
addikt
-
hokuszpk
nagyúr
-
 b.
félisten
b.
félisten
-
hokuszpk
nagyúr
hm. szigethalmi irányítószám. hm.
ha jólemléxem olyan 6 hónappal a launch elotti gyártási dátumokat már láttunk, de ez több, mint 1 éve készült ??? 1 éve már ment a 4nm sor ? Mégis mi a pékre vártak ennyit ?
Ha nem fake, akkor elég jól állhat a Zen6 fejlesztés. -
 S_x96x_S
addikt
S_x96x_S
addikt
> Ezt meg valamikor 2023 áprilisban készítették.
ezen én is gondolkodtam,
de lehet,
hogy "engineer sample" - még a korábbi iterációkból.
vagy "fake". -
 paprobert
őstag
paprobert
őstag
"csúsztatni kellert"
Sigmund Freud itt járt

-
 Petykemano
veterán
Petykemano
veterán
Itt.a.fotó:

2315PGYA.zen4 esetében a release előtt néhány hónappal gyárották a végleges változatot.végleges feliratokkal.
Ezt meg valamikor 2023 áprilisban készítették.A zen4 ugye késett fél évet, a zen5 attól függetlenül készülhetett. De talán azt is csúsztatni kellert. Mindenesetre ez szerintem sokat magyaráz, miért tűnik picit úgy, hogy kicsi az előrelépés.
A rengeteg idő, ami rendlekezésre állt gyártani, magyarázhatja, hogy jó áron lesz elérhető. Remélhetőleg.
És remélhetőleg épp emiatt nem lesz késés az X3D-ban sem -
 Komplikato
veterán
Komplikato
veterán
Engem jobban zavar ennél az, hogy tök mindegy, hogy tud vagy sem PCIE5-öt a lap, PCIE3 vagy PCIE4 bővítők SINCSENEK rajta. Gyakorlatilag teljesen értelmetlenné tették az ATX/MATX lapokat, mindegyik egy ITX "bővíthetetlenségével" dolgozik. Arra bezzeg van eszük, hogy PCIE 1x csatolókat álcázzanak 16x-nak.

-
 HSM
félisten
HSM
félisten
Az a gond, a PCIE4 és főleg 5 megköveteli a jó minőségű, sok rétegű PCB-t a megfelelő jelátvitelhez, ami soha nem volt olcsó.

Egyébként a mai B650 lapok árazása alapján megfizethető kompromisszumnak tűnik a PCIE4, esetleg egy PCIE5-ös M2 slottal kiegészítve. Ezekkel azért elég jó sebesség érhető el, akár vágott interfészű VGA-val is, miközben a termék ára így még korrekt sávban marad.
Ne felejtsük el, hogy az AM4 olcsó csipszetje, a B350 és B450 még PCIE2-es portokat használt, na azon én is ráncoltam picit a szemöldököm annak idején. A B550 hozta be az "általános" portokra a 3.0-t...
A B550 hozta be az "általános" portokra a 3.0-t...A kisebb GPU szerintem ha van rajta elég VRAM nem fog fejre állni egy 4.0-s lapban sem, vágott interfészen. Még úgy is óriási előnnyel indul egy kisebb APU-val szemben.
-
Petykemano
veterán
Szerintem ez nagy zakó.
Én is reménykedtem abban, hogy a második generációs AM5 alapkapoknál lesz előrelépés, standarddé és megfizethetővé válik már a pcie5, de egyelőre topogásnak tűnik.
Elképzeohető, hogy annak, aki nem tudja megfizetni a pcie5-ös alaplapot,.nem fog.tudni megfizetni olyan bővítőkártyát se, ami.miatt szüksége volna rá... elméletileg.
Csakhogy az eddigi gyakorlat az, hogy az alaplapokon a pcie verzión spórolnak,.az olcsóbb gpukon pedig a sávok számával, így aztán lehet két szék közé esni.Az E jelzést lehetett volna pl pont erre használni, hogy az 16 csatornás, a sima meg csak 8.
Azért is zakó, mert lehet, hogy lassan tényleg jobban megéri egzotikus módon egybetokozni egy valamirevaló kisebb gpu-t (ide értve a tokozást, a cache-t), mint hogy a külön vásárolt holmik pcie5-ön keresztül tudjanak megfelelő sebességgel kommunikálni.
-
HSM
félisten
-
b.
félisten
-
hokuszpk
nagyúr
-
 yagami01
aktív tag
yagami01
aktív tag
-
HSM
félisten
-
b.
félisten
-
Petykemano
veterán
Volt ilyen irányú pletyka.
És nyilván célja is az AMD-nek, hogy növelje a magszámot. Elvileg a Zen5c 2CCX-ből áll és az az elképzelés, hogy a Zen6-ban történik majd meg az egyesítés.A saját véleményemet képviselve mondom, hogy szerintem viszont nem sok értelme van 16 fullos magot összepakolni, amennyiben képesek arra is, hogy mondjuk ennek legalább felét képesek helytakarékos módon ugyanarra az L3$-re rákapcsolni és közben megoldják a magok közti késleltetés kérdését is.
Hiszen nagyon valószínűtlen, hogy a 9-16. mag még olyan frekvencián fusson igénybevétel esetén, mint amin 1-8 magot terhelve fut. Onnantól viszont felesleges szilícium.Van erre két prototípus is, hiszen a zen5c mellett a strix point is 2 CCX-ből épül fel, a megoldandó probléma pedig ugyanaz.
A harmadik megközelítés pedig a strix halo, ahol elvileg 2CCD lesz és lesz az IOD-on infinity cache. Amennyiben egy L4$ (ad abszurdum az L3$ IOD-ba való áthelyezésével ) sikerül megoldani a magok közti adatátadás késleltetésének problémáját (CCX-ek közötti magskálázódás), akkor lehet tovább építkezni csökkenő (de legalábbis nem növekvő) méretű 8/16c magos chipletekből. És csak ott és akkor indokolt a.hibrid megoldás, amikor kifejezetten "alacsony" magszámú (~8-12) példány készítése a cél.
Egyébként az Intel álítólag ki fog adni egy olyan raptor lake variációt, Amiben az e magok helyére P magokat ültetett, vagy 12P mag lesz benne. Azon le lehet majd Tesztelni, hogy skálázódnak-e a játékok 8 mag fölé, máskülönben céltalan ez a téma
-
HSM
félisten
-
hokuszpk
nagyúr
lehet volt egy ujratervezes ; valahol egy mérnökféle elejtette, hogy eredetiben 3nm -re tervezték a Zen5 -öt ; aztán vagy nemvolt rá elég kapacitása a TSMCnek vagy csak későn tudták volna kezdeni a tömeggyártást, vagy épp az MI300/325/350/etc -re kellett a 3nm, mert az mégtöbbet hoz, stb ; ezért jön 4nm -en. Különben lett volna enyhe frekinövelés is.
lehet aki az elején vesz Zen5 -öt, az kaphat 3nm -en gyártott chipet ( az AMD mindent is elad ugyebár ), később meg már csak a 4nm. Ha így van, akkor szvsz a korai chipekben lesz némi tuningpotenciál ( allcore 6Ghz+ ? ), ami idővel eltünik. -
 fatal`
titán
fatal`
titán
Mintha lett volna pletyka, hogy a zen6 16 magos CCD-ket fog tartalmazni, rosszul emlékszem?
Persze pletyka, majd meglátjuk.
-
Petykemano
veterán
-
carl18
addikt
Üdv!
Még manapság tanakodtam hogy a AMD hova léphet ha az intelnek jön az ö általa igért AMD killer cpu-ja. (Nova Lake lenne a neve) 8P Core+32E Core amit eddig pletykák alapján írtak + a 8P Core újra kap egy új fajta Hyper Tredingot.
Most ez kb a Zen 6 korszakba fog megjeleni, utána számolgattam az AMD-nek sokkal több lehetősége van játszani. Hiszen ők még a teljesítmény magokon kivül nem használt boostot (C) Magok bevetésével.Szóval AMD ha nagyon ütni akar, 16 Core Zen 6 +16 Zen5C is párosíthat, de de nem látok lehetetlennek hogy 16 Zen mag kap maga mellé 32C magot amivel 48 magos össz hatás MT teljesítményt jelentősen az intel főlé mehetne. A Zen 6 esetében még az is lehetséges 32 Zen 6 magot kapunk, és nem foglalkoznak a C magok bevetésével.
-
Petykemano
veterán
Ma kijött valami sajtós anyag.
Ez most valami release volt, vagy ilyen second announcement? Eddig elég csendesnek tűnik, csak a sajtóanyag feldolgozását láttam pár helyen, gondolom a tesztek akkor július 31-én jönnek, vagy utána.
Olyan fura, mintha nem is igazán lennének büszkék rá, vagy már rég túlléptek rajta.Amúgy volt egy kép még 1-2 hete, a 9950X-et ábrázolta. Nem találkoztam olyan infóval, hogy hamis (átszerkesztett 7950X) lett volna. Viszont kupakon levő számok alapján 2023-ban gyártották (csomagolták), még csak nem is az utolsó hetekben, és nem is ES volt.
Ami szintén elég fura.Egyrészt ebből azt abjövetkeztetést vonom le, hogy a 2024Q1-es rajt számításom tökre célon lehetett. Nekem legalábbis a 3 negyedév a tömeggyártás és a release között soknak tűnik. De ha tényleg így volt és a kép nem hamis, mi történhetett?
Bevárták az intelt? Vagy valami szoftver/kernel frissítést? -
hokuszpk
nagyúr
-
 kleinguru
addikt
kleinguru
addikt
Mikortól lesznek elérhetőek az új CPU-k itthon is

-
S_x96x_S
addikt
(blender, zen5, energiahatékonyság )
> de ebből hivatalosan csak az up to 17%-ot osztotta meg idáig az AMD.pontosabban,
a 17% == átlag (geomean) és nem "up to 17%".
Vagyis lesznek 17% feletti javulások - és a Blender az egyik ilyen.
> Egyre valószínűbb, hogy a valódi meglepi az energiahatékonyság lesz,
> Állítólag a 9950X 120 wattból hozza
> a 253 wattig elengedett 14900K teljesítményét Blender-ben,
> és 160 wattból 7 és 16 % előnyt ér el a 230 wattos 7950X eredményeihez képest.az AMD több számot is megosztott a Zen5 Blender-ről.
- 14900K vs. 9950X - Blender : +56% ( a 14900K -n nincs AVX-512 )
- ZEN4 vs. ZEN5 - Blender: +23% ( zen5 -ben még fejlettebb az AVX-512 )vagyis a blenderes energiahatékonyság egyik oka a jól implementált AVX-512,
emiatt ezt az eredményt
nem lehet automatikusan az összes többi programnál is elvárni,
főleg ha azok nem, vagy csak minimális mértékben használják az AVX-512-őt.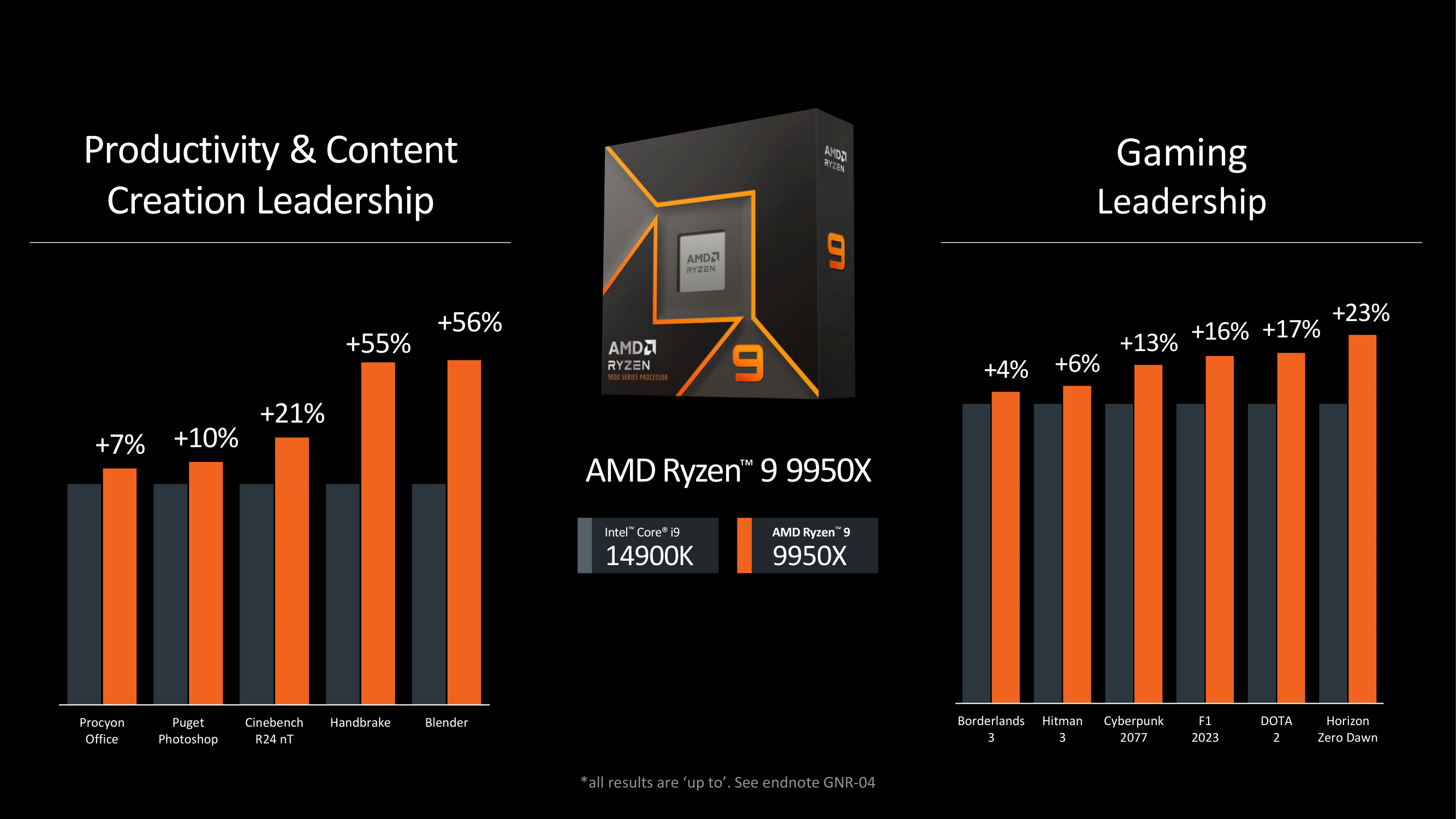
az AVX-512 használata nem olyan gyakori,
ráadásul még tart az Intel átok ...
mivel sok olyan Github-os kommentet olvasok,
hogy azért nem kapcsolják be az adott programban ezek használatát,
mivel egyes régebbi Intel architektúrákon
az AVX-512 az AVX2-höz képest,
sebesség csökkenést okoz az ismert freq droppolás miatt.Az új "x86-64-v5" baseline számozásról nem is beszélve,
ami ideális lenne a zen4/zen5-nek
- de az Intel miatt még szöszölnek rajta - hogy mi lenne a legjobb megoldás.
"The hypothetical x86-64-v5 could fit well for AMD Zen 4 and Intel Icelake Server and newer. It also makes sense having a stepping stone prior to AVX10 rolling out."
https://www.phoronix.com/news/x86-64-v5-Questionedúgyhogy,
ha lesz új "x86-64-v5", és a fordító programok támogatják,
akkor a zen4/zen5/zen6 procik még hasznosabbak lehetnek mint most.
de gyors eredményt ne várjon senki. -
hokuszpk
nagyúr
-
 Alogonomus
őstag
Alogonomus
őstag
Egyre valószínűbb, hogy a valódi meglepi az energiahatékonyság lesz. Állítólag a 9950X 120 wattból hozza a 253 wattig elengedett 14900K teljesítményét Blender-ben, és 160 wattból 7 és 16 % előnyt ér el a 230 wattos 7950X eredményeihez képest.
30%-kal takarékosabb, és így is 7-16 % közötti az előnye, vagyis a perf/W előnye a Zen 4-hez képest is körülbelül 60%, de ebből hivatalosan csak az up to 17%-ot osztotta meg idáig az AMD. -
 Devid_81
félisten
Devid_81
félisten
Kiskereknel van mar a cucc, nem csodalom, hogy jonnek az eredmenyek
Lassan johetnek a jatek tesztek is
-
Petykemano
veterán
Jönnek az eredmények
ST
Cpuz ~900
GB6 ~3450Ez kb az, amit.bejelentettek (nincs, vagy.még nem látható a meglepi )
-
S_x96x_S
addikt
mókás hírfigyelő:
"AMD új ZENdületet tervez a processzorpiacon: üvegre váltana 2025-26 körül. Az üveg laposabb, mint nagyanyánk palacsintája, így több tranzisztor fér el rajta. A cég vezetői már most GLASSzálnak az izgalomtól. De vigyázat, az üveg törékeny - akárcsak az ilyen hírek megbízhatósága!"
"AMD is reportedly set to use glass substrates for CPUs between 2025 and 2026"
"Glass substrates offer significant benefits over conventional organic substrates." -
paprobert
őstag
"habár tisztán idle tesztet most nem találtam."
Azt észrevettem, hogy a Phoronix tesztekben a fogyasztási listáknak van "min" értéke.
Bár nem lehet készpénznek venni, de gyengén utal az idle fogyasztásra.
Az 1 vs 2 CCD különbség pl. olvasható róla, ahogy a monolitikus előny a chipletes CPU-khoz képest is. -
paprobert
őstag
"Pedig ugye abban is ugyanúgy Infinity Fabric van, csak magon belül."
Igen, amíg szilíciumon belül marad, addig nincs túl nagy baj.Az Intel feltehetőleg ezért lép a Si interposer irányába chipletnél( + így valamire el képes sütni az üresen kongó, low performance - low cost gyártósort)
Ha jól emlékszem, 50W volt a Core2, Phenom2 érában is az üresjárat, vagyis ebben szinte nem volt előrelépés tizen+ éve
-
HSM
félisten
"Összehasonlításképp, nemrég teszteltem egy 6nm-es AMD lapost, és lenyűgöző, 3-4W idle fogyasztást tudott."
Pedig ugye abban is ugyanúgy Infinity Fabric van, csak magon belül. Számomra egyébként az is lenyűgöző, 15W-ból mekkora tempót tud kihozni egy 7nm-es 8 magos Zen3 APU is, ezt a hsz-t is olyanról írom (Rzyen 5850U). Ennek nem kell 50-100W-os "turbó", hogy szedje a lábát.Egyébként asztali gépekből is lehet takarékosat építeni, az én B550 alaplapom és Ryzen 5600-asom egy Radeon 6800XT-vel és sok mindennel kompletten elvan konnektorból mérve szűk 50W-ból [link] . A notebookhoz képest kicsit sok, de egyébként szerintem teljesen jó az is, főleg ennyi nagyteljesítményű hardver mellett.
-
S_x96x_S
addikt
> Remélem hogy ez a hatékonyság megmutatkozik
> a jövőben az asztali vonalon is, és nem csak a terhelt állapotban...ha lassan is, de már asztalon is elérhetőek
az újabb zen4c -es procik és magok
(pl. AMD Ryzen 8500G - 2x Zen 4 , 4x Zen 4c , 65W )
habár tisztán idle tesztet most nem találtam.persze ha még 35W-os módba rakjuk, akkor még jobbak a fogyasztési eredmények.
https://www.phoronix.com/review/ryzen-8000g-35w-45w/5
-
S_x96x_S
addikt
(ha valaki nem látta volna még)
A Nuvia ( arm , mostmár Oryon core in Snapdragon X Elite )
magok elemzése a sajtos-chipses fiúktól ( és a zen4 -el is össze van hasonlítva! )
(Amúgy TSMC 4 nm -en alapul - és majd a 4nm-es zen5-ös Strix Point lesz az igazi versenytárs. )Qualcomm’s Oryon Core: A Long Time in the Making
https://chipsandcheese.com/2024/07/09/qualcomms-oryon-core-a-long-time-in-the-making/"On paper, 12 big Oryon cores should be a formidable opponent for both AMD’s eight Zen 4 cores and Meteor Lake’s 16 cores of various types."
"Oryon’s indirect predictor isn’t as big as Zen 4’s 3072 entry indirect branch predictor and can’t track as many targets. But unlike Zen 4, there is no slowly increasing penalty after 32 targets for a single branch. This likely means that Oryon doesn’t use a similar mechanism to Zen 4. Now comparing Oryon to Golden Cove and they are very similar to each other but Oryon can track more targets than Golden Cove can."
"As test sizes exceed AMD’s L2 capacity, Qualcomm’s three L2 instances can provide 16% more bandwidth than AMD’s L3. Snapdragon X Elite has three 12 MB L2 instances for 36 MB of total capacity. Using three L3 instances makes it easier to provide high bandwidth too."
-
paprobert
őstag
A ST erősödése a lényeg kliens processzornál, szerintem ez így jó irány. Teoretikusan bármikor feladnék a 8-ból két magot, ha cserébe egy szálon +15%-ot lehet vele nyerni.
Mint mindig, most is kérdés az idle power és hogy 1 szálnál mennyit eszik pluszban majd az Infinity Fabric.
A lehetőség létezik arra, hogy több adatcsatornán, de alacsonyabb frekvencián menjen az adat (a'la HBM) a részegységek között.Összehasonlításképp, nemrég teszteltem egy 6nm-es AMD lapost, és lenyűgöző, 3-4W idle fogyasztást tudott.
Ez közel Raspberry Pi szint, és egyertelműen mutatja, hogy a különbséget a desktop körítés jelenti.
Remélem hogy ez a hatékonyság megmutatkozik a jövőben az asztali vonalon is, és nem csak a terhelt állapotban... -
Petykemano
veterán
Nem lepne meg, ha a MT teljesítmény nem nőne olyan nagy mértékben. Ezzel együtt tartok tőle, hogy ahogy gigantikus IPC emelkedés sem volt, úgy gigantikus hatékonyságnövekedés sem lesz.
A Zen3 elég hasonló képet mutatott: ST teljesítményen volt a fókusz és közel azonos gyártástechnológián készült. A Zen3 esetén volt egy sandbagging elem, a 8 magra egyesített CCX, ami játékok esetén a nominális IPC számítási metódushoz képest jobb eredményt adott a felhasználók kezébe. Nem is beszélve a X3D változatról.
A zen4 esetén a szokásosnál nagyobbat ugró frekvencia volt a meglepi.Kíváncsi vagyok, most lesz-e.
(Esetleg a versenyhelyzetben épp elvárt energiahatékonyság lesz?) -
S_x96x_S
addikt
és Blenderes
AMD Ryzen 9 9950X “Zen 5” ES CPU Outperforms Intel Core i9-14900K In Blender At Just 120W"In terms of performance,
the AMD Ryzen 9 9950X ES CPU scored
268.7 points in the Monster test,
177.5 points in the Junkshop test, and
129.8 points in the Classroom test in Blender.
Compared to the Core i9-14900K, the Zen 5 CPU at 120W not only matches it in the Monster test but is also able to outperform it in Junkshop and Classroom tests.
The CPU also comes close to the Ryzen 9 7950W which has a peak PPT of 230W or almost twice as much as this Zen 5 ES CPU.
Compared to the 90W configuration, the 120W PPT tune delivers close to a 19% gain in performance with a 33% increase in power." -
hokuszpk
nagyúr
-
HSM
félisten
-
S_x96x_S
addikt
> GB eredményekkel hogy vagyunk megelégedve?
Azért a Multi lehetne több is,
jelenleg a 12 magos 9900X eredménye
még mindig nem jobb a 24 magos 14900K -től.Geekbench 6.2 Multi
a 24 magos i9-14900K 20881 ( 100% )
a 12 magoa 9900X 19756 ( 95% )
> Jelen állás szerint valószínűleg ez lesz a legkevesebb előrelépést hozó generáció.nem lesz mindenkinek ideális upgrade,
de a szerver piacra ideális
és a linuxosok is örülni fognak neki.
valamint mindenki más is,
akinek az alkalmazása AVX, AVX512 -öt kihasználja. ( pl Blender , ... ) -
Alogonomus
őstag
Azért a múlt eseményeiből következően a Geekbench eredmények alapján nagy felelőtlenség bármilyen komoly következtetést levonni.
Az biztos, hogy az AMD fókusza nagyon az MI/ROCm irányába fordult, mivel abban van most a sok pénz, plusz az egyéb területeken vagy nincs miért izgulniuk, vagy nincs nagyon lehetőségük.
A pletykált TDP értékek és a különböző teszteredmények alapján a perf/W valószínűleg jelentősen javul majd minden termék esetén, és ez lesz a komolyabb előrelépés, nem a plusz teljesítmény. -
Petykemano
veterán
GB eredményekkel hogy vagyunk megelégedve?
Az AMD tökre azt a benyomást kelti, hogy valami miatt eléggé megcsúsztak. Elég késői az RDNA4 megjelenése, a strix.halo is. Utóbbiról MLiD elmondta, N3-ra tervezték eredetileg. De olyan, minttha a teljes AMD portfólió fél-egy évet csúszott volna az N3 késése miatt, vagy mert backportolni.kellett N4-re.
Vagy más miatt... lehet ez olyan megfontolás is, hogy a fókusz a Mi/ROCm termékeken van, vagy mert kartelleznek.
Ha a hírek igazak, akkor persze legalább az árazásban reflektálódni fog, hogy nem annyival jobb. Jelen állás szerint valószínűleg ez lesz a legkevesebb előrelépést hozó generáció. -
Petykemano
veterán
Igen, hát ez a kérdés, hogy alkalmazzák-e a itt is.
E talán nem csak a hőelvezetés szempontjából lenne hasznos, hanem - amennyiben a CPU magok feletti strukturális szilícium a hőtermelődés/hőelvezetés miatt nem hasznosul, akkor talán alulra kerülve azt is hasznosítani lehetne.
Akár az L3$ méretének növelésére, akár az L2$-ére. De gondolom,.utóbbira külön TSV-ket kellene látnunk. -
S_x96x_S
addikt
> .. alul van a V-cache lapka és nem fölül?
Ha konkrétan arra gondolsz, hogy az MI300 -nél
az IOD -on ( ami nagyrészt cache array ) fekszik az XCD/CCD
Vagyis lényegében a logika van felül és a cache alul,
( "Logic die on top enables improved thermals" )
Akkor technikailag már valami hasonló működik az MI300 -ban.(persze lehet, hogy rosszul értelmezem .. )

A 19.slide-on a bal oldalon mintha az IOD -n lenne egy nagy "Cache Array"
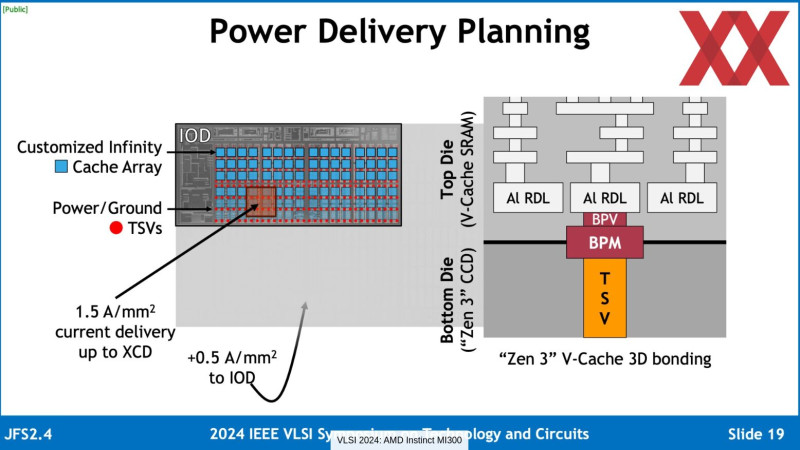
A 6.slide-on például egyértelműen az IOD van az XCD alatt.
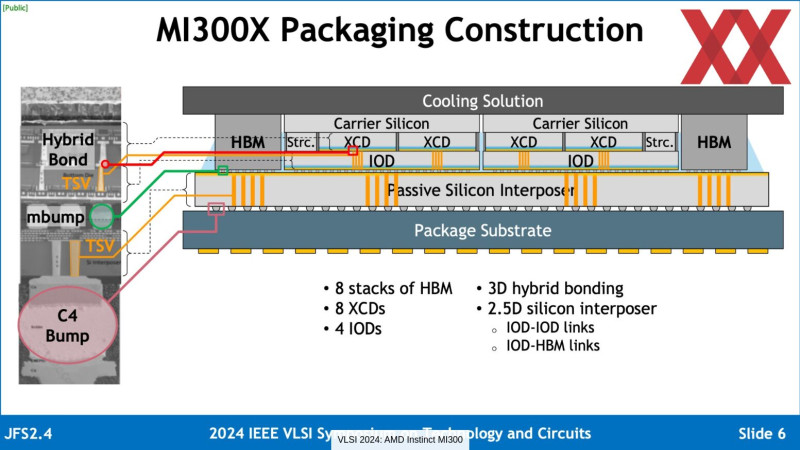
de ez csak egy okoskodás részemről;( slide forrás - ahol van még több is ... )
-
hokuszpk
nagyúr
akár. én a + cacheméretre leszek kiváncsi ; igazán duplázhatnák már

-
Petykemano
veterán
Mi a valószínűsége/lehetősége annak hogy a Zen5X3D úgy próbál javítani az órajeleken (+tuning), hogy alul van a V-cache lapka és nem fölül?
-
hokuszpk
nagyúr
-
 -=MrLF=-
senior tag
-=MrLF=-
senior tag
-
Petykemano
veterán
-
yagami01
aktív tag
-
Petykemano
veterán
Strix Point : júli15 [link]
-
S_x96x_S
addikt
> Ez a 128GB nekem irreálisnak tűnik.
még többre is lenne igény, mivel az újabb LLM-ek elég nagyok.
-
 Busterftw
nagyúr
Busterftw
nagyúr
Plusz 120W-al amúgy sem lenne M Ultra rivális.
-
Petykemano
veterán
-
S_x96x_S
addikt
AMD testing “Strix Halo” APU with 128GB memory config
( Apple M-Ultra rivális)https://videocardz.com/181601/amd-testing-strix-halo-apu-with-128gb-memory-config

-
S_x96x_S
addikt
"Testing AMD’s Bergamo: Zen 4c Spam"
https://chipsandcheese.com/2024/06/22/testing-amds-bergamo-zen-4c-spam/ -
S_x96x_S
addikt
részletes(ebb) elemzés a Zen4, zen5, zen5c között.
A jelentős átalakítás miatt - vannak olyan másodlagos hatások, amelyek egyes helyeken rosszabb teljesítményt nyújtanak. ( a few downsides [1] )AMD Strix Point “Ryzen AI 9 365” APU Benchmarks Revealed Zen 5’s IPC, Latency, Throughput & Various Performance Aspects
https://wccftech.com/amd-strix-point-ryzen-ai-9-365-apu-ipc-latency-throughput-various-performance-tests/ ( forrás: David Huang )

[1]David lists that while Zen 5 has improvements thanks to its ground-up design, the architecture also has a few downsides which are as below:
- The throughput of various scalar ALU instructions has been greatly increased, but because the number of vector units in the mobile Zen 5 is halved compared to desktop and server, the SIMD throughput in this test remains unchanged compared to Zen 4. Even on the Zen 5 core with halved vector units, SIMD store operations of all widths are still doubled compared to the previous generation, and the SIMD load store throughput reaches 1:1;
- The branch processing capability has been greatly enhanced, with the number of non-taken branches that can be processed per cycle increased from two to three, and two taken branches can be processed per cycle. This should be related to the new front-end design;
- The latency of 128/256/512bit SSE/AVX/AVX512 SIMD integer addition calculations has all been increased to 2 cycles. This change may be to make it easier to maintain high frequencies.
- The throughput of 128/256bit SIMD integer addition operations is halved compared to Zen 4, but 512bit remains unchanged. It is speculated that this problem only exists on Zen 5 cores with halved SIMD, which may be related to port allocation;
- Removed the nop fusion feature introduced in Zen 4. It is no longer possible to merge a nop instruction with another instruction on the same macro-op;
- Adjusted the throughput of some logical register operations, unifying the throughput of some mov operations and some register zeroing operations to 5, which is a mixed improvement compared to Zen 4.
-
S_x96x_S
addikt
> Jelen tudásom szerint a Strix Point esetén a 8+4 külön clustert jelentenek.
-
Petykemano
veterán
Bár határozottan úgy gondolom, hogy jó volna, ha 8 mag már nem a $300-500 árszintre kerülne, hanem $300 alá, egy magszám duplázásnak sok értelmét én se látnám.
Szerintem a Strix-szel mutatott irány ebben a kérdésben megfelelő.
Számomra is csak az a kérdés, hogy vajon különböző típusú magok egy, vagy különböző clusterre vannak-e felfűzve és/vagy utóbbi esetben mi lehet a megoldás a késleltetés csökkentésére
Jelen tudásom szerint a Strix Point esetén a 8+4 külön clustert jelentenek. -
HSM
félisten
Szerintem felső kategóriára ahogy írod, APU-ba kevés lenne a két csatorna DDR5 egy erős GPU-hoz és 32 maghoz, de talán még 16-hoz is. Illetve eddig inkább takarékosra tervezték a legtöbb APU-t, úgy pedig egy visszafogott GPU erős 8 magos CPU-val elég jó kompromiszum volt 15-30W közötti géposztályban ár/érték/teljesítmény kategóriában.
Viszont eléggé új irányok vannak kibontakozóban, kíváncsi leszek mi fog belőlük kisülni hosszabb távon.
Koncepcióját tekintve a Strix Halo és Strix Point is ígéretes, figyelembe véve a várható sávszélességeket kiegyensúlyozottnak tűnik mindkettő. Egyben lehet következtetni is belőlük, pl. hogy 'kétcsatornás' (128bit széles) LPDDR5-re 8db Zen5 és 4db Zen5c mag érkezett 16CU-s GPU-val [link] , míg dupla ekkora szélességű buszra már 16db Zen5 magot, 40CU-val pletykálnak [link] .Amennyiben a Strix Point egyébként egyesített L3-al fog érkezni, akkor határozottan tetszeni fog, ha külön életet fog élni a 8+4 mag, akkor majd a részletes elemzések után visszatérhetünk erre.
-
S_x96x_S
addikt
> átlagos feladatokra simán elszalad a 32 magunk
> egy mai gyors DDR5 memória alrendszeren...azért vannak végletek:
pl. A Blender például nem érzékeny a memóriára,
( 6c vs. 12c )de egy APU -nál
már nem csak a 32 magos CPU -t
hanem a GPU-t is bele kell számítani a kapacitás tervezésbe,
és ez lehet a probléma a gaming konfigokat megalapozó konzoloknál.
És ez lehet az egyik fő ok, hogy miért nincs jelenleg 16cpu magos desktop APU.Mert lehet, hogy jól párhuzamosítható a gaming engine,
de hogyha a párhuzamosítás és a szinkronizáció miatt 30%-al több memória sávszél-t eszik meg a CPU feladat, mert 2x annyi magon fut, és emiatt nem tudja annyira kihasználni az L3 cach-eket,
akkor ennyivel kevesebb jut a GPU-nak.
És jelenleg a GPU teljesítmény a szűk keresztmesztszet.vagyis egy APU-nál csak azt lehet eldönteni, hogy az adott memória sávszélt
milyen arányban osztod fel a CPU és a GPU között.
és sajnos ez nem olyan egyszerű feladat. -
HSM
félisten
"szerintem a magszám növelésének a PC/Desktop -on
a memória sávszélesség a legnagyobb akadálya.
egy 2 csatornás memóriával 32 erős magot nem igazán lehet kiszolgálni."
Annyiból vitatkoznék veled, hogy azt láttuk, hogy gyors DDR4-el elég szépen kifutotta magát annak idején a Ryzen 5950X, nem tökéletesen, de csak enyhén limitálva az alacsonyabb magszámú modellek alapján számolt ideális skálázódáshoz képest. Manapság, gyors DDR5-el ennek a sávszélessége duplázható, azaz vidáman lehetne etetni róla akár két 5950X-et is, ami azért elég durva nyers erőt képviselne. Ha mondjuk még feltételezünk némi fejlődést a cache rendszerben, máris ott tartunk, hogy átlagos feladatokra simán elszalad a 32 magunk egy mai gyors DDR5 memória alrendszeren...Szerintem otthonra azért nem hoznak 16-nál több magot, mert drágítaná az előállítást felkészülni rá, és felesleges konkurenciája lenne a drágább WS platformoknak is. A legtöbb usernek pedig elég is a 16 mag manapság.
-
S_x96x_S
addikt
> 4 év alatt alig nőtt valamit a teljesítmény magszám skálázódás.
az AMD nem szaladhat túlságosan előre - megelőzve az igényeket.
de egy picit azért a jövőbe kell látnia.Ami nyilvánvaló lett számomra,
hogy a konzol bizniszt -
a szerencsés együttállásnak köszönhetően (is) hozta el az AMD ( PS4 , PS5 )
aminek egy jelentős része volt,
hogy Lisa Su - az IBM(Cell) -nél is a Sony-val dolgozott együtt.
Vagyis tudta a Sony ( mint ügyfél ) igényeit és megmaradtak a személyes kapcsolat rendszerei.A jövőre érkező Strix Halo szerintem egy újabb apró lépés a jövő felé.
- 16c Zen5 APU
- 256 bites - egyesített memória
- relative erős GPUés valószínűleg
- az nVidiának is lesz hasonló konfigja, csak ARM alapokon.
- És ott az új játékos a Qualcomm is.szerintem a magszám növelésének a PC/Desktop -on
a memória sávszélesség a legnagyobb akadálya.
egy 2 csatornás memóriával 32 erős magot nem igazán lehet kiszolgálni.
és a memória sávszáll a HEDT ( Threadripper ) és a szerver ( Epyc ) platformokon is elég fontos.mert azért a több csatorna - > nagyobb memória sebesség -> nagyobb teljesítmény.
12c = 12 csatorna
6c = 6 csatorna.https://www.phoronix.com/review/ddr5-epyc-9004-genoa/6
-
HSM
félisten
-
 T.Peter
őstag
T.Peter
őstag
-
S_x96x_S
addikt
> 4 év alatt alig nőtt valamit a teljesítmény magszám skálázódás.
Az Intelnél ez még inkább észrevehető; lásd 24 magos CPU-k ..
de komolyabban:
Lassan dolgoznak a szoftveresek, de legalább valamilyen előrelépés már látszik.pl. az UE 5.4 elég sok párhuzamosítást és optimalizációt tartalmaz,
de azért van még mit csiszolgatni.
és ne felejtsük el, hogy az UE 5.0 - 2022-Áprilisban jelent meg, vagyis még csak 2 éve!
-------------------------és manapság már mindenki a 4K-ra fókuszál,
ami miatt eleve minden GPU limites."Unreal Engine 5.4 Forgotten Cemetery Tech Demo Struggles to Run Smoothly at Native 4K Resolution on an RTX 4080"
https://wccftech.com/unreal-engine-5-4-struggles-native-4k-rtx-4080/2024-május-10 - wccftech
" In regards to performance, the new renderer parallelization introduced in the new version of the engine can bring around 40% performance improvement in CPU-limited scenarios on a Ryzen 7 7800X3D on PC over version 5.0 in the Matrix Awakens demo. This also bodes well for consoles, as a PC attempting to replicate the PlayStation 5 and Xbox Series X specs sees considerable performance improvement in Unreal Engine 5.4 over version 5.0."persze az 5.3 - hoz képest már nem 40% .. de ez már mellékes ..
https://www.unrealengine.com/en-US/blog/unreal-engine-5-4-is-now-available
-
paprobert
őstag
Nem feltétlenül nagy baj ez.
Még az a típusú játék is ritkaságszámba megy, ami 30 képkockát céloz a konzol CPU main threadjével. Ennek következtében PC-n Zen2-vel, vagy egy 2018-as Skylake-kel is nagyrészt kényelmesen el lehet lenni. Van kiaknázatlan tartalék a fejlesztők kezében, a többszálúsítás csak ezután jönne.
Én pedig nagyon vártam, hogy sok új játék Hogwart's Legacy szinten, vagy annál is durvábban fogja beárazni az egyszálas teljesítményt, de a last gen és a Switch megmentette a PC-t ettől.
-
Petykemano
veterán
4 év alatt alig nőtt valamit a teljesítmény magszám skálázódás. Sajnos. [link]
-
S_x96x_S
addikt
AMD working with law enforcement after reports of massive data breach — hack may have uncovered future product details
"Intelbroker reportedly stole and is now trying to sell a vast array of AMD's data, including detailed specifications of upcoming products, property files, ROMs, firmware, internal communications, and source code. Additionally, the pilfered data comprises financial records and comprehensive employee information such as user IDs, names, job roles, phone numbers, and email addresses. This information could jeopardize AMD's competitive edge and thus the breach raises concerns about intellectual property theft and corporate espionage." -
Petykemano
veterán
Állítólag Július 31-én jelenik meg a Zen5
Az árak picit furák. Megint az alacsony magszámra kérnek prémiumot. Bár lehet, hogy még nem is igaz vagy nem is végleges. -
Petykemano
veterán
7950X ST teljesítmény, 5950X MT teljesítmény
[link] -
hokuszpk
nagyúr
"Arm <-> x86/x64 utasításkészletek közötti fordítást biztosító emulációs felületre. Szerverek területén is ezért akadt meg az Arm piacnyerése."
max. a windowsos szerverek teruleten ; a linux kernelt ezer +1 eve portoltak arm -re ; egy nagycsomó szabadforrású szoftvert is siman le lehet forditani ; nemneztem utana, de lehet van valami centos/rocky szintu rhel klón is arm -re forditva.
-
S_x96x_S
addikt
> Jelenleg viszont az Arm ugyanabban a helyzetben van,
> mint volt anno az AMD a Zen architektúra bemutatásakor.azért nem ugyanaz.
az AMD és az Intel is az AMD64(X86-64) utasításkészletet használta,
emiatt emulációra nem volt szükség.> Jelenleg szinte minden komolyabb program
> x86 vagy x64 architektúrához megalkotva áll rendelkezésre.A Windows játékok emulációval futni fognak.
Jelenleg a legnagyobb probléma az anti-cheating funkciók lekezelése.
Unlike Apple's chips, Qualcomm's X Elite Arm CPU will run Windows games just fine using x64 emulation — native ARM64 code will give best performanceAz Emulációs dologról
The Qualcomm Snapdragon X Architecture Deep Dive: Getting To Know Oryon and Adreno X1gépi fordítással:
////
Az x86 emulációs helyzet a Qualcomm számára sokkal összetettebb, mint amit az Apple eszközöknél megszoktunk, mivel a Windows világában egyetlen gyártó sem irányítja egyedül a hardver- és szoftverrétegeket. Tehát bármennyit is beszélhet a Qualcomm a saját hardveréről, például, nincs befolyása a szoftver oldalra – és nem kockáztatják meg, hogy helytelen nyilatkozatot tegyenek a Microsoft nevében. Következésképpen az x86 emuláció a Snapdragon X eszközökön lényegében a két vállalat közös projektje, ahol a Qualcomm biztosítja a hardvert, a Microsoft pedig a Prism fordítási réteget.
Bár az x86 emuláció nagyrészt szoftveres feladat – a Prism végzi a munka oroszlánrészét – mégis vannak bizonyos hardveres megoldások, amelyeket az Arm CPU gyártók bevezethetnek az x86 teljesítmény javítása érdekében. És a Qualcomm a maga részéről ezeket megtette. Az Oryon CPU magok hardveres segédletekkel rendelkeznek az x86 lebegőpontos teljesítmény javítása érdekében. És hogy kezeljék a legnagyobb kihívást, az Oryon hardveres megoldásokkal rendelkezik az x86 egyedi memória-tárolási architektúrájának támogatására – ami széles körben úgy tartják, hogy az Apple egyik kulcsfontosságú előrelépése volt a magas x86 emulációs teljesítmény elérésében saját szilikonján.
Mégis, senkinek sem szabad azt hinnie, hogy a Qualcomm chipjei képesek lesznek az x86 kódot olyan gyorsan futtatni, mint a natív chipek. Még mindig lesz némi fordítási többlet (amelynek mértéke a munkaterheléstől függ), és a teljesítménykritikus alkalmazások továbbra is előnyt élveznek, ha natív módon vannak AArch64-re fordítva. De a Qualcomm nincs teljesen kiszolgáltatva a Microsoftnak, és hardveres megoldásokat alkalmazott az x86 emulációs teljesítmény javítása érdekében.
A kompatibilitás szempontjából a legnagyobb akadály az AVX2 támogatás lesz. Az Oryon NEON egységeihez képest az x86 vektori utasításkészlet szélesebb (256b versus 128b) és az utasítások nem teljesen egyeznek. Ahogy a Qualcomm fogalmaz, az AVX-ről NEON-ra fordítás nehéz feladat. Mindazonáltal, tudjuk, hogy lehetséges – az Apple csendben hozzáadta az AVX2 támogatást a Game Porting Toolkit 2-höz ezen a héten – így érdekes lesz látni, mi történik ezen a téren az Oryon CPU magok jövőbeli generációiban. Az Apple ökoszisztémájával ellentétben az x86 nem fog eltűnni a Windows ökoszisztémából, így az AVX2 (és végül AVX-512 és AVX10!) fordítási igénye sem fog megszűnni.
////Az emuláció extrém esetben ~ 30% teljesítményt vehet el. ( ST485/ST686 = 0.7069 )
Snapdragon X Elite X1E-78-100 (Surface Laptop 7)
CPU-Z (ARM64) Benchmark
ARM64: ST 686, MT 7923
x64 Emulation: ST 485
https://x.com/9550pro/status/1794202815369490738
( ha jól látom, akkor emulációval hozza a AMD Ryzen 7 5700U - ST 488 - teljesítményét a Snapdragon X )
de mivel a felhasználói és játék programok sok Windows API hívást futtatnak, ami már nativ arm64, ott szerintem csak 15-20% teljesítmény csökkenés várható.amúgy szerintem a jogi dolgok jelentik a legnagyobb problémát.
ARM torpedoes Windows on ARM: Demands destruction of all PCs with Snapdragon X -
b.
félisten
Pontosan. Csak most fordítva csinálja az M.S A desktop és majd a Mobil lesz az út amire rálépnek. Az nvidiát megfogják mellé. Szerintem jó lesz most.
-
Petykemano
veterán
Szerintem a Windows @ arm szoftveres "problémák" csak most tűnnek látszólag elháríthatatlannak, de gyorsan meg fognak oldódni. Mert van rá akarat.
A MS az Apple után akar menni. Vertikális integrációt akar, de legalábbis irányítani az eszközök s
SZoftveres és hardveres jellegzetességeit,.képességeit, hogy olyan integrált élményt értékesíthessen, mint az Apple.Számomra hihető magyarázat, hogy miért most és miért az Arm, miért a Qualcomm, hogy az Intel és az AMD legalább részben, de főleg server-first megközelítésben fejleszt és tervez. Ehhez képest a Qualcomm mobil termékekben utazik. Sokkal jobban belevág a MS céljaiba és talán jobban terelhetők is.
És abba is gondolj bele, hogy a MS-Nak.nem.csak a Qualcomm miatt érdeke, hogy a szoftveres környezet működjön,.hanem mert ezzel egy új lehetőség nyílik arra is, hogy a MS mint integrált.szoftvermegoldás (OS&co) térjen.vissza arm eszközök (mobiltelefonok, tévék, stb) milliárdjaiba (az android, a google helyére) az Apple-lel közvetlenül konkurálva.
-
Busterftw
nagyúr
Teljesen egyértelmű minden forrás szerint is, hogy a Windows on Arm verzió az natív Armra lett írva.
Tehát van natív Armos Windows.Minden más 3rd party, még nem Arm natív szoftver pedig emulálva lesz.
Nem kell tovább magyarázkodni, tévedtél, van célzott Arm utasításkészletre megírt Windows.
-
b.
félisten
. Én értem mire akarsz utalni csak te nem ezt írtad feljebb.

ARM alapú hardvereket naponta millió számra vesznek az emberek és mindenapos szinten van jelen a hétköznapokban.
Sokkal olcsóbban , kisebb méretben, energia hatékonyabban gyártható és működtethető hardvereket jelentenek ezek az eszközök, miközben a teljesítményük folyamatosan nő az energahatékonyságuk pedig szintén nő... Ahogy az Apple ráoptimalizálja a szotfvereit a saját architektúrájára ezt megteszi majd a Microsoft és az Nvidia is a Qualcomm és még talán az AMD is ....Nem kell 150 ezres lap alájuk és hatalmas hűtés.Ezek kompakt rendszerek nagy haszonnal árulhatóan .
X86 nak kell valahogy beérnie az ARM alapú rendszereket majd hatékonyságban , méretben, olcsóságban, elérhetőségben.
Az X86 hosszú távon egy zsákutca és a mostani vonal is az amit képviselnek ezek hatalmas sokmagos szörnyek egyre drágább 3D tokozással és alaplapokkal, hűtéssel és memóriarendszerekkel.
Az embereknek nem erre van szükségük általában, hanem arra amit az Apple nyújt az ökoszisztémájával. A legtöbb Szifon tulaj nem tudja megmondani mennyi memória van a telefonjában vagy milyen processzor az Ipadjében, Ibookjában. -
Alogonomus
őstag
Inkább próbálj rájönni, hogy miért írtam, amit írtam.
Jelenleg szinte minden komolyabb program x86 vagy x64 architektúrához megalkotva áll rendelkezésre. Amíg pedig ezeknek a programoknak azt Arm architektúrához megírt és több évnyi használat során a hibáktól megszabadított változatai össze nem állnak, addig az Arm egy erősen kompromisszumos platform lesz. Addig az időpontig egy eszköz Arm eredete komoly ledolgozandó hátrányt jelent a vásárló szemében, amit a perf/$, perf/W, infuenszerekkel alakított mindshare hármasával kell ledolgozniuk a gyártóknak.
Jelenleg viszont az Arm ugyanabban a helyzetben van, mint volt anno az AMD a Zen architektúra bemutatásakor. Az alacsony market share miatt szinte senki sem akarja önköltségen a szoftverét párhuzamosan egy újabb architektúrához is kifejleszteni/támogatni, viszont amíg nincs natív Arm verzió egy szoftverből, addig a kockázatkerülőbb vásárlók maradnak az X86 vonalon, így pedig a szoftvercégek nem érzik fontosnak natív Arm változatot is kínálni egy szoftverükből.
-
b.
félisten
"Az operációs rendszer maga hIába esetleg natív Arm szoftver, ha mindegyik jelenlegi x86 és x64 programot emulálva képes csak futtatni."
Gondold át mit írtál le . Kb azt hogy az ég kék a fű zöld. Egyértelmű hogy az X86 programokat emulálva képes futtatni mert az ARM nem X86 architektúra...
Ezz nem azt jelenti hogy ne lehetne ezeket a szoftvereket natívan megírni ARM-ra mint ahogy már egy jó csomót meg is írtak rá. [link] -
Alogonomus
őstag
Az operációs rendszer maga hIába esetleg natív Arm szoftver, ha mindegyik jelenlegi x86 és x64 programot emulálva képes csak futtatni.
-
S_x96x_S
addikt
> AMD kezdesnel sz@rul araz, majd lecsokken
> a termek ara oda ahova valo par honap alatt,
> evek ota ez a jol bevallt (ertelmetlen) marketing naluk.ez inkább jól ismert közgazdaságtani racionalitás és kevésbé marketing.
A gyártási volumen felfutásából az is következik,
hogy az elején nincs elég CPU mint amennyire igény lenne
és a "prémium ár" szabályozza a keresletet.
Vagyis nem lesz hiány.
Aki hajlandó megfizetni a korai "prémium árat" annak jut CPU/GPU/Konzol.pl. a GPU-nál volt már olyan időszak,
hogy a hiány miatt a piaci ár feljebb ment mint az MSRP,
és ilyenkor sokszor a nagyker vagy a kisker aratja le az extra prémium árat,
és sok vevő csalódott lesz - mert hiába olcsó, de még ha van pénzed, akkor se tudsz hozzájutni.A korai prémium ár ezen kívül biztosítja a fejlesztési költségek gyorsabb megtérülését is.
De a legfontosabb tényező a piaci verseny,
Mert ha éles a verseny, akkor nagyon hamar beállnak a reális piaci árak. -
 hahakocka
őstag
hahakocka
őstag
AMD explains why Ryzen 9000 with 8 cores doesn’t need higher TDP but lower
Érdekes cikk. S majdnem elérheti a 7800x3D erejét kisebb (fele akkora) fogyasztással, talán olcsóbb árral ? S sokkal jobb munkára is, +videóvágás tömörítés, stb. 9700-9800x esélyes nálam 8 mag 65 TDP vel. -
Busterftw
nagyúr
A Windows 11 on Arm az natív Armra írt szoftver.
-
Alogonomus
őstag
Amíg nincs célzottan az Arm utasításkészlethez megírt Windows, viszont van egy több generáció alatt kicsiszolódott x86/x64 Windows verzió, addig az asztali piacon a Qualcomm ugyanúgy komoly hátrányban van, mint az Apple szintén Arm-alapú M1/2/3 processzorai. Jelenleg szerintem legfeljebb az fogyasztásra hangolt laptopokban és az embedded piac alacsony teljesítményű szegmensében remélhet érdemi sikert elérni a Qualcomm processzora, ha árban nagyon versenyképes lesz.
A 9600X-szel induló "erős" gépek szintjén már túlságosan sokat számít, hogy egy alkalmazás közvetlenül az Arm processzort tudja-e használni, vagy szükség van egy extra Arm <-> x86/x64 utasításkészletek közötti fordítást biztosító emulációs felületre. Szerverek területén is ezért akadt meg az Arm piacnyerése. -
Petykemano
veterán
Nekem az a gyanúm, hogy ez az árazás már nem az intelnek szól, hanem a Qualcommnak.
-
Devid_81
félisten
Eppen lehetseges, hogy olcso lesz, de azert ebben remenykedni nem mernek
AMD kezdesnel sz@rul araz, majd lecsokken a termek ara oda ahova valo par honap alatt, evek ota ez a jol bevallt (ertelmetlen) marketing naluk. -
Alogonomus
őstag
A mai MLiD-csomag eléggé bizalomkeltő.
A Zen5 állítólagos árazása megmagyarázza, hogy az utóbbi hónapokban miért csökkent annyira a Zen4 ára.
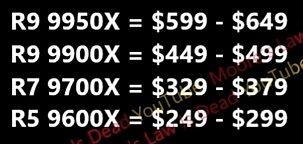
Az pedig még tőle is erős álíltásnak tűnik, hogy a non-X3D termékekhez hasonlóan már a Zen5 X3D is valószínűleg tuningolható lesz, ráadásul állítólag talán már Q3-ban, de idén szinte biztosan érkeznek az X3D-s verziók is, szóval az Arrow Lake már a Zen5 X3D ellen kell majd, hogy bizonyítson.
-
Petykemano
veterán
Úgy tűnik, az QC X Elite hozza 2800-2900 ST és 15000 MT eredményt GB6-ban.
Ehhez képest a Hawk Point csak 2600/13000 körül alakul.
(Persze itt sok múlik a TDP-n)
Ha errenrászámoljuk a 10-15%-ot, amit a Zen5 hoz, akkor 2900 körüli értéket kapunk.Szóval úgy tűnik a versenyképesség itt is fennáll, mint az Apple chipekkel szemben. Kérdés, hogy mindeközben hogy alakul a fogyasztás (és az akkuidő). Az eddigi tapasztalat az Apple esetén az, hogy a magasabb IPC alacsonyabb órajel (és sűrűbb tranyók) fogyasztásban is kifizetődőbb.
Kíváncsi vagyok, ha a QC ebből szerverprocit is csinál, abból mi sül ki.
Emiatt reméltem, hogy az AMD zen5 követi a mintát a szélesedésben és ebből.fakadóan ellép. De nem.
-
Petykemano
veterán
192kB L1i,
96kB L1d
12MB L2$ (17 ciklus)Ezeket a retire, meg decode szélessegeket nem jegyeztem meg, a Zen4-hez van hasonlítás.
Szóval ez is az Apple M1-re hajazó az X86-tól merőben eltérő cache felépítéssel rendelkezik. A Zen4 L2$ késleltetése csak 14 ciklus, ami alig kevesebb (persze figyelembe véve, hogy a proci másfélszer magasabb frekvenciát elérhet, ns-ban mérve biztosan lényegesen gyorsabb), miközben az Oryon esetén egy mag 12MB-ot hasznosíthat 1MB helyett.
Azt szokták mondani, hogy jójójó, de hát azért ilyen az x86 cache felépítése, mert a gyors privát cache jobban fekszik a szerverterhelésnek. Hát ez majd kiderül.
Nekem azért úgy tűnik, hogy 3.5-4GHz-nél az x86 szerverek se pörögnek gyorsabban és így el is vesztik az előnyüket, miközben az Oryon akkor is 4-5x.nagyobb L1 és L2$-sel rendelkezik. Az AMD L3$ pedig ehhez.képest lassú.Én a Zen5-től is egy ilyesmi megújhodást vártam, de valóban csak egy szolíd szélesedést hozott.
-
S_x96x_S
addikt
Lisa Su ( az IBM-es korszakában ) ott volt a PS3 (Cell ) megalkotásánál.
"AMD CEO Lisa Su reminisces about designing the PS3's infamous Cell processor during her time at IBM"
https://www.tomshardware.com/tech-industry/amd-ceo-lisa-su-reminisces-on-helping-design-the-ps3s-infamous-cell-processor-at-ibm -
S_x96x_S
addikt
> Nem túlzás az a 30%?
a TomsHW -es cikkben szerepel így:
"The Ryzen 7 7800X3D's second-gen 3D V-Cache took gaming performance to a whole new level — it's ~30% faster in gaming than the fastest standard Ryzen 7000 processor."
persze ez a gyakorlatban - amolyan "up to" érték.habár egyes játékoknál elég magas érték mérhető.
pl. Flight Simulator:
7700X - 123.5 fps --> 7800X3D - 183.0 fps ( és ez már +48% körüli lehet)
( és ebben az esetben a +16% Zen5 IPC - nem sokat ér.)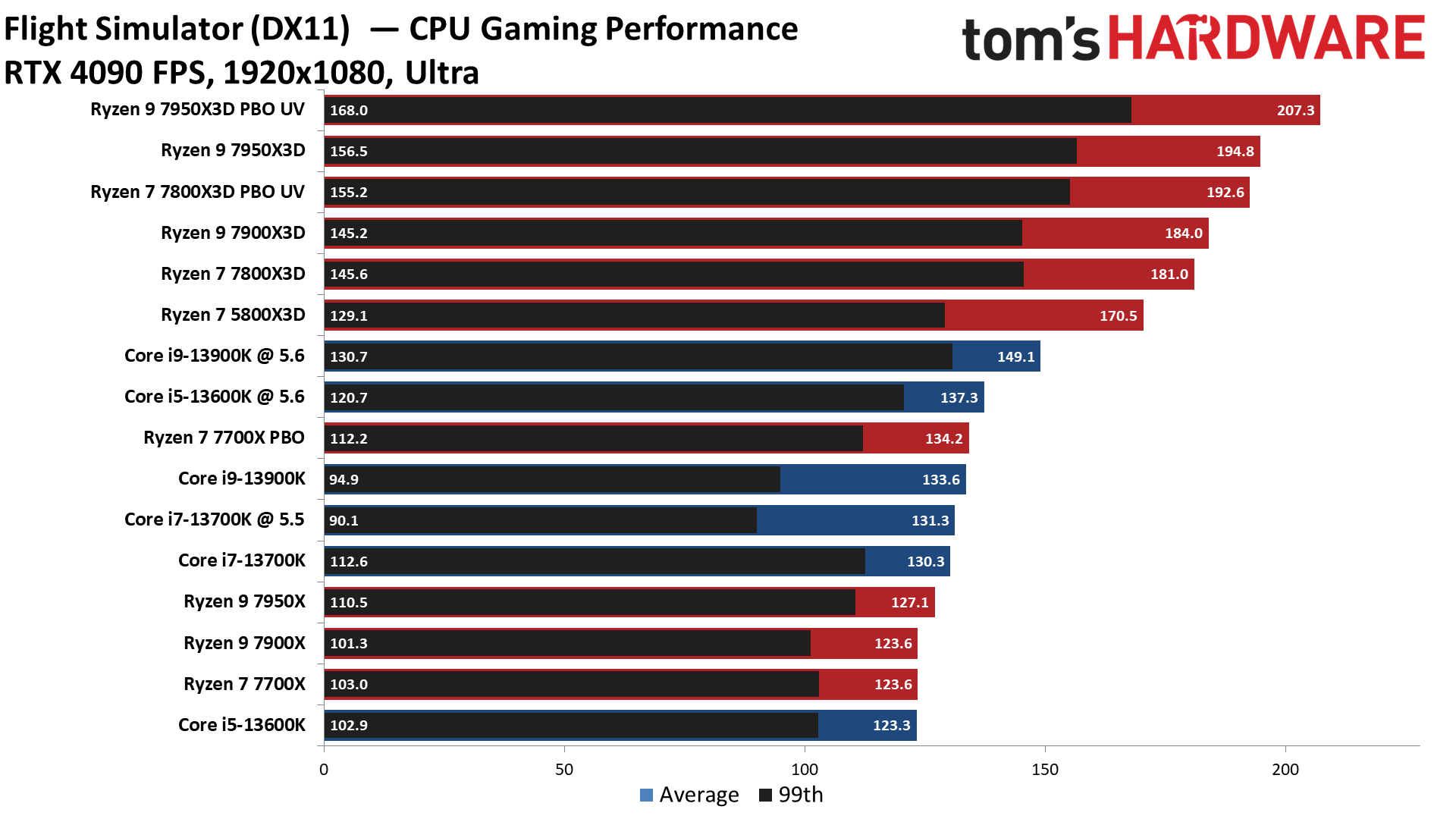 ( innen )
( innen ) -
Petykemano
veterán
"De a gaming teljesítményt hiányolni egy szolidabb magszélesítés után, szerintem nem helyes elvárás."
Ha előre pontosan lehetett volna tudni, hogy - ahogy korábban megfogalmaztam - a Zen5 egy Zen3-hoz hasonló teljes, de működésében és felépítésében ortodox újratervezése a magnak egy új gyártástechnológiára, akkor a várakozásoknak is ennek megfelelően kevésbé lett volna tere szárnyalni.De példaként - az Arm részéről - jóval szélesebb és nagyobb L1$ méretű példák vannak - ez adta az alapot annak a spekulációnak, hogy Mike Clark talán éppen ezen innovációk x86-os lekövetése miatt olyan lelkes.
-
Petykemano
veterán
-
S_x96x_S
addikt
ha valakinek nem elég a zen5 - akkor itt egy ígéret,
hogy fel lehet gyorsítani 100x -osan ..
persze ez még csak az igéret/elmélet .."Another eyebrow-raising claim is that an integrated PPU can enable its astonishing 100x performance uplift “regardless of architecture and with full backward software compatibility.” Well-known CPU architectures/designs such as X86, Apple M-Series, Exynos, Arm, and RISC-V are name-checked. The company claims that despite the touted broad compatibility and boosting of existing parallel functionality in all existing software, there will still be worthwhile benefits gleaned from software recompilation for the PPU. In fact, recompilation will be necessary to reach the headlining 100X performance improvements. The company says existing code will run up to 2x faster, though."
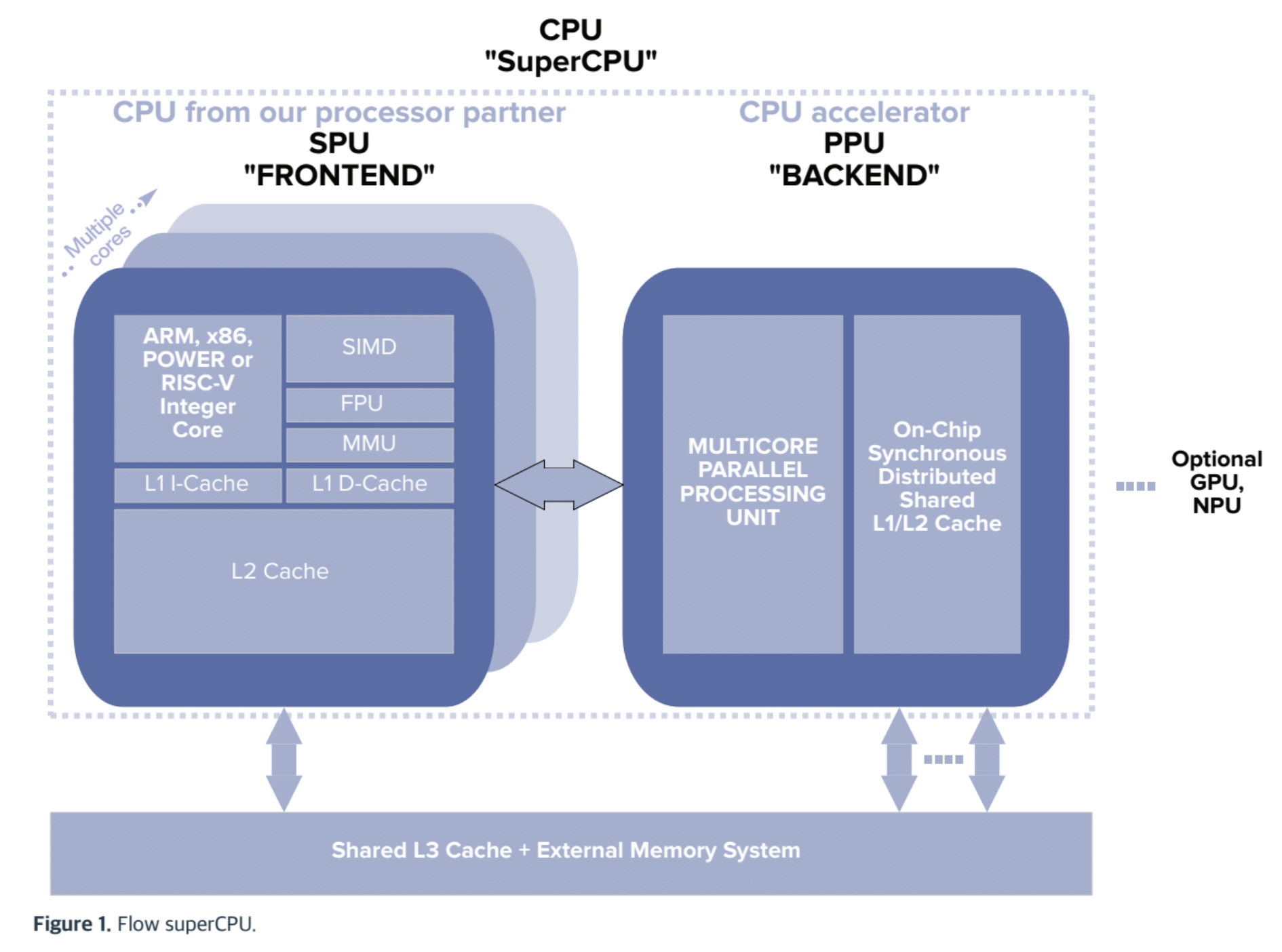
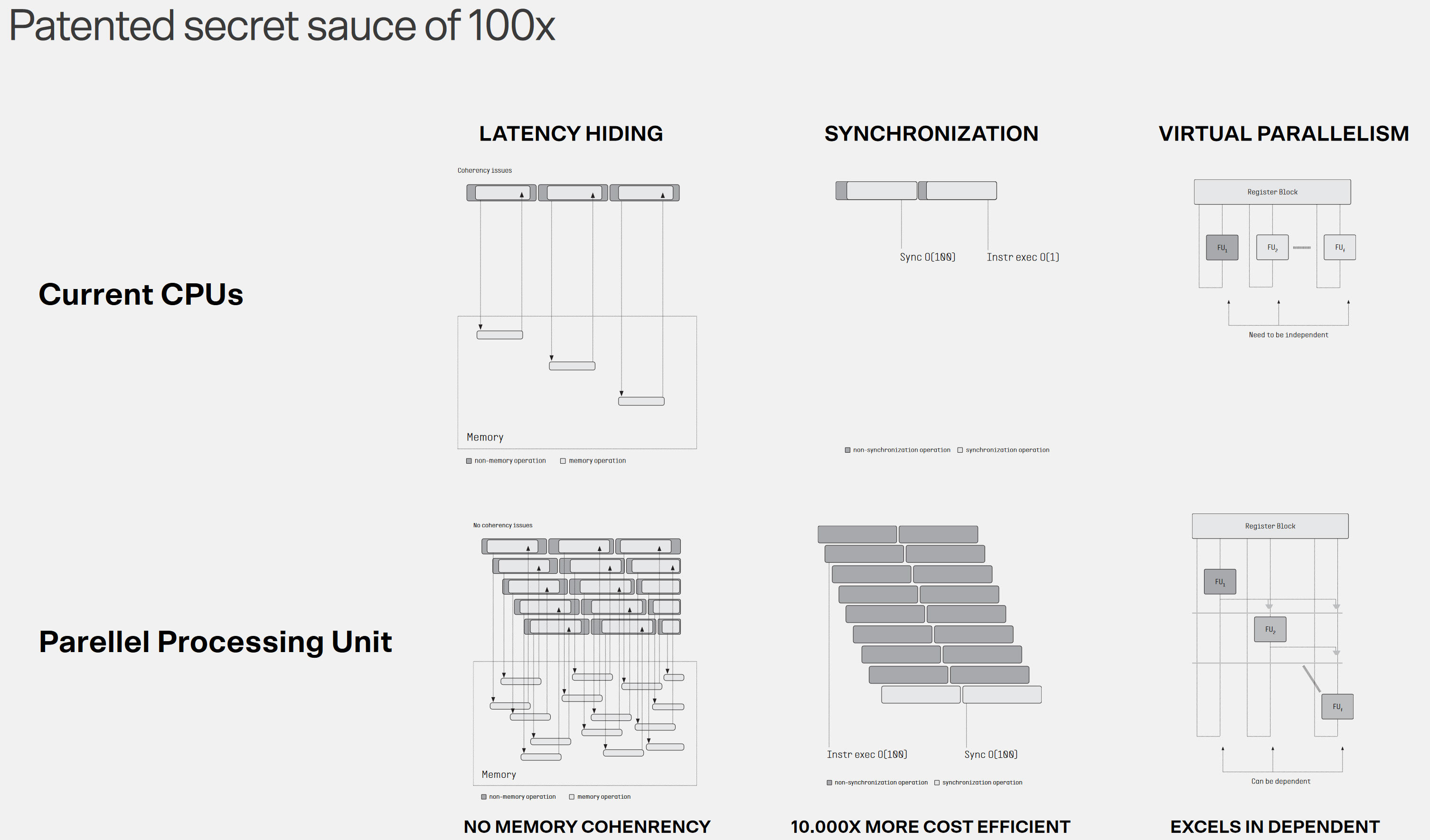
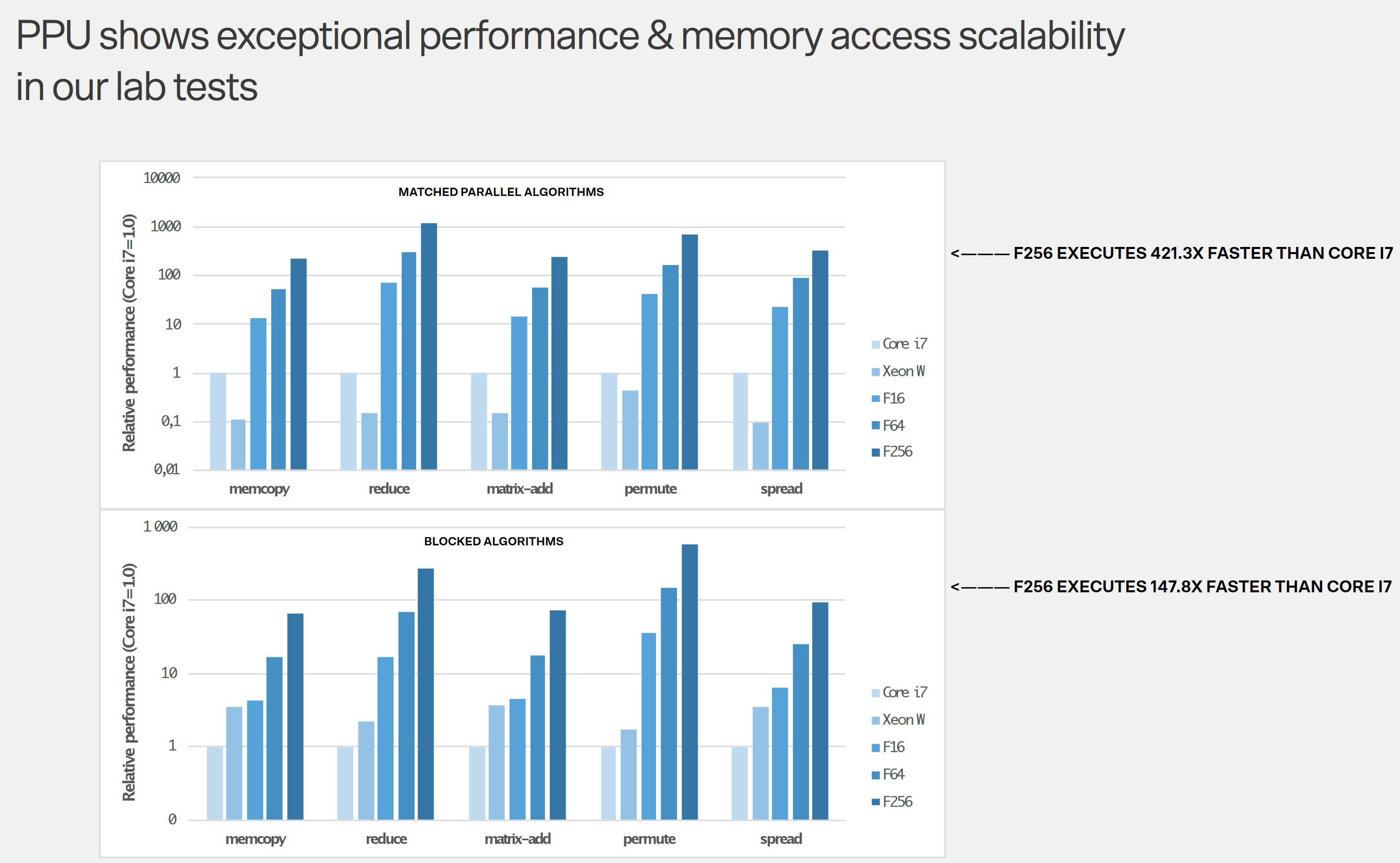


















 A B550 hozta be az "általános" portokra a 3.0-t...
A B550 hozta be az "általános" portokra a 3.0-t...





























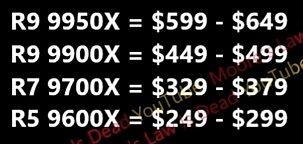
Új hozzászólás Aktív témák
-
9600 - 9501
10138 - 10101 10100 - 10001 10000 - 9901 9900 - 9801 9800 - 9701 9700 - 9601 9600 - 9501 9500 - 9401 9400 - 9301 9300 - 9201 9200 - 9101 9100 - 9001 9000 - 8901 8900 - 8801 8800 - 8701 8700 - 8601 8600 - 8501 8500 - 8401 8400 - 8301 8300 - 8201 8200 - 8101 8100 - 8001 8000 - 6001 6000 - 4001 4000 - 2001 2000 - 1
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- iPhone topik
- Samsung Galaxy S26 - szeret, nem szeret
- Már megint variál a Samsung az Ultrával!
- Windows 11
- creation: Elég lett abból, hogy a nagy gépeim nem képesek behúzni a filamentet
- Milyen billentyűzetet vegyek?
- E-roller topik
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- Akciófigyelő: Ismét ingyenes az Epic Store-ban a Hogwarts Legacy
- Kuponkunyeráló
- További aktív témák...
- !AKCIÓ+GARI! GAMER PC Intel Core i5-14400F/ASUS TUF Gaming B760M/RTX 4070 12GB/32 GB DDR5 5200 MHz
- Asus ROG ALLY X + tartozékok
- G.Skill Trident Z5 Neo RGB DDR5-6000 CL30 32GB (2 16GB) Fekete
- Üzletből, Macbook Pro Retina 16" 2021,M1 Pro 10mag 32GB RAM/1TB SSD/Metal 16magGPU/Liquid Retina XDR
- Eufy Security 2C Kit
- Intel Nuc M15 Core i5 1135G7 8Gb Ram 512Gb NVMe SSD 15,6" IPS Érintőkijelző Boltból Garanciával
- AKCIÓ! MacBook Pro 13 M1 8GB RAM 512GB SSD notebook garanciával hibátlan működéssel
- Lenovo ThinkPad T14s Gen 3 i5-1245U 14" FHD+ 16GB 256GB 1 év teljeskörű garancia
- Eladó Sony Xperia L1 2/16GB fekete / 12 hó jótállás
- Játékra vagy Munkára! Csere-Beszámítás! I7 3930K / Nvida GTX Titan B / 16GB DDR3 / 500GB SSD!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest