
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)
- gban: Ingyen kellene, de tegnapra
- gerner1
- Luck Dragon: Asszociációs játék. :)
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Luck Dragon: Alza kuponok – aktuális kedvezmények, tippek és tapasztalatok (külön igényre)
- sziku69: Fűzzük össze a szavakat :)
- djculture: Az elvileg már senkinek nem kellő HDD-k ára is egekbe emelkedett 4 hónap alatt
- eBay-es kütyük kis pénzért
- Gurulunk, WAZE?!
- Archttila: SMART tesztelés automatizálva: smartctl poller script Zsh-ban, RPi-re
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 Orionk
senior tag
Orionk
senior tag
-
Orionk
senior tag
-
 pvt.peter
őstag
pvt.peter
őstag
-
 Aethelstone
addikt
Aethelstone
addikt
-
Aethelstone
addikt
Szerintem meg egy olyan terméknek kell lennie az alapnak minden projektnél, ami már bizonyított és kb. 50 update-n már túl van. Nem bíznám a produktív, kritikus rendszerem egy 1.8-as Java-ra. Majd 2 év múlva...amikor már minden disznóság kiderült róla és a rendszerkomponenseimen sem kell minimum 2 főverziót emelni, hogy működjenek vele rendesen...és még sorolhatnám...
-
 MrSealRD
veterán
MrSealRD
veterán
-
 Karma
félisten
Karma
félisten
Egyébként az Oracle szerint is, ugyanis 2015. április óta nincs supportja, hacsak nem köt külön szerződést az ember a céggel.
A Tomcat 7-et is felesleges archaizálásnak érzem, mondjuk nem is állnék neki kézzel Tomcatet telepíteni, amióta van Spring Boot.
-
Aethelstone
addikt
-
MrSealRD
veterán
-
 Sk8erPeter
nagyúr
Sk8erPeter
nagyúr
-
 fatal`
titán
fatal`
titán
Én is erősen gondolkodom rajta, de még béta, nem tudom milyen gyakran változtatgatják az API-t.
-
 emvy
félisten
emvy
félisten
-
emvy
félisten
Probalom attolni a cegben is. A Clojure tul nagy lepes az atlag fejlesztonek sajnos, tehat migralni nem fogunk ra, maximum uj projektekben hasznalni, a Kotlinra van esely.
-
 ToMmY_hun
senior tag
ToMmY_hun
senior tag
Pont tegnap kezdtem én is használni, mert a sima Collenctions.synchronizedList() iterátora is ConcurrentModificationException-öket dobált.
Amire figyelj, hogy a CopyOnWriteArrayList-et nem lehet Collections.sort-tal rendezni: "Element-changing operations on iterators themselves (remove, set, and add) are not supported. These methods throw UnsupportedOperationException."Ezen kívül rossz tapasztalatom egyelőre nincs vele. Nálam ezért volt indokolt a használata: "useful when you cannot or don't want to synchronize traversals, yet need to preclude interference among concurrent threads"
Ugyanez volt nálam is, iterálást nem viselte el a Collections.SynchronizedList, hiába tettem a műveleteket synchronized blokkba. Mióta ki kell cserélve a CopyOnWrite-ra, azóta nem volt Exception, igaz én csak az elem berakás/kivételt és az iterálást használom, semmi mást.
Köszi a választ!

-
 bambano
titán
bambano
titán
Először is: Javaban mindig érték szerinti átadás van. Ez azt jelenti, hogy amikor myArrList.addAll meghívódik, akkor a yourArrList-ben tárolt referenciák lemásolódnak.
yourArrList elemei: a "three" és "four" stringek. addAll meghívása után mindkét listában van 1-1 referencia ezekre a stringekre.
Ha az egyik listában kitörlöd a referenciát, az a másik listára természetesen nem lesz hatással. Ha viszont a referencián keresztül megváltoztatod objektum állapotát, akkor az a másik listából elérve is látszódni fog. A példa ott sántít, hogy a String immutable.

vagyis ha a referenciákat adja át, akkor nem mindig érték szerinti átadás van

-
 zserrbo
aktív tag
zserrbo
aktív tag
Először is: Javaban mindig érték szerinti átadás van. Ez azt jelenti, hogy amikor myArrList.addAll meghívódik, akkor a yourArrList-ben tárolt referenciák lemásolódnak.
yourArrList elemei: a "three" és "four" stringek. addAll meghívása után mindkét listában van 1-1 referencia ezekre a stringekre.
Ha az egyik listában kitörlöd a referenciát, az a másik listára természetesen nem lesz hatással. Ha viszont a referencián keresztül megváltoztatod objektum állapotát, akkor az a másik listából elérve is látszódni fog. A példa ott sántít, hogy a String immutable.
Erre gondoltam én is, de megzavart az angol megfogalmazás
Köszi! -
Karma
félisten
Természetesen nem. Mivel a connectorok által okozott késleltetés relatíve elég kicsi, az üzleti logikád és DB-d bőven hangsúlyosabb lesz.
-
Karma
félisten
-
Karma
félisten
-
 WonderCSabo
félisten
WonderCSabo
félisten
-
 mobal
nagyúr
mobal
nagyúr
-
mobal
nagyúr
-
emvy
félisten
-
emvy
félisten
A Scala egyszeruen tul nagy nyelv. Otvenfelekepp meg lehet csinalni ugyanazt, lehet a Scalaz-fele funkcionalis agymenestol a pszeudo-Javaig mindent hasznalni. Ez a legnagyobb baja.
-
emvy
félisten
Ja, de ez fordito kerdese, nem a nyelvbol kovetkezik.
-
emvy
félisten
-
WonderCSabo
félisten
Hát igen, ez a bonyolult megoldás. De mindegy is, már sokan kérdeztek erre rá, és nem nagyon válaszolt erre az Android fejlesztő csapat. Majd kiderül, mindenesetre egyelőre nincs jel a változásra.
-
WonderCSabo
félisten
Írhatnak, de kétlem, hogy megteszik. Nemrég váltották le a JVM alapú Dalvikot a szintén JVM alapú ART-vel. Ez utóbbi rengeteg idő, mire el fog terjedni, jelenleg kicsi az Android 5 felhasználóbázisa. Ha váltanának egy teljesen új architektúrára, akkor az új appok vagy csak az új telefonokon lesznek elérhetőek, vagy meg kell oldani, hogy a JVM alapú dolgokon is menjen, ami elég bonyolult. Plusz kérdésessé tenné az ART-be vetett meló szükségességét. Ezek kívül a teljes kialakult ökoszisztéma borulna (libek, eszközök).
Mellesleg amennyire tudom, nem terveznek váltani Javáról. -
Karma
félisten
-
emvy
félisten
-
emvy
félisten
Nem tudom, hogy a Java 8 mennyit nyomhat itt a latba, ezt lehetetlen számszerűsíteni. Hallottál olyanról, hogy valahol azért döntöttek Java mellett, mert a 8 olyan fasza? Amúgy nekem nagyon bejönnek a labdák meg a streams API.
Amúgy azt tudták, hogy a Jigsaw-os modularizáció rossz hatással lesz a teljesítményre?
Ja, bar irtozatosan ronda kb. minden mas nyelvhez kepest, de teny, hogy jobb, mint a semmi.
-
mobal
nagyúr
Nem tudom, hogy a Java 8 mennyit nyomhat itt a latba, ezt lehetetlen számszerűsíteni. Hallottál olyanról, hogy valahol azért döntöttek Java mellett, mert a 8 olyan fasza? Amúgy nekem nagyon bejönnek a labdák meg a streams API.
Amúgy azt tudták, hogy a Jigsaw-os modularizáció rossz hatással lesz a teljesítményre?
Lambdákra már nagyon szükség volt...
-
Aethelstone
addikt
-
mobal
nagyúr
-
 M_AND_Ms
veterán
M_AND_Ms
veterán
-
 jetarko
csendes tag
jetarko
csendes tag
jhipster-t nézted? A technology stack elég jó, na meg az a prezentáció is
Én játszottam vele 1-2 órát és elég jónak tűnt, de vannak benne olyan alapkövek amiket még nem írtam meg magamtól ezért még félretettem. -
 Mukorka
addikt
Mukorka
addikt
Szerintetek egy 512MB RAM-os Ubuntun futni fog egy egyszerű Spring boot app és egy MySQL szerver?
Csak átfutottam egy két osztályt. Egy tipp: ha nincs id amire szűrsz akkor az logikában legyen kiszűrve, nem írunk sql-t olyan feltételre ami mindenképp teljesül. Így gyorsabb is lesz a query 1-2 ezred másodperccel.
-
 F1rstK1nq
aktív tag
F1rstK1nq
aktív tag
-
emvy
félisten
-
jetarko
csendes tag
-
emvy
félisten
-
mobal
nagyúr
-
emvy
félisten
-
Aethelstone
addikt
-
 floatr
veterán
floatr
veterán
-
emvy
félisten
Ha a1 nyom egy yield-et, akkor a1-a10 es b1-b10 szalak kozul valamelyik fog utemezesre kerulni.
Ez alapján annyira random a yield, hogy az is lehet hogy a1 blocked állapotba kerül (hisz másképp nem kerülhetne ütemezésre a1-a10 közül más, mert az a1 foglalja a monitort), de az is lehet, hogy nem változik semmi?
A queued ne tevesszen meg, nincs sorrendiseg ertelmezve a varakozo szalak kozott.
Ez világos.
A queued az, ami nem var semmilyen monitoron, csak preemptalva lett (vagy csak elinditottak, de meg nem kerult utemezesre).
Csak a tisztánlátás végett: ha a példánkban a1 van az A objektum monitorában, és b1 a B monitorában, akkor a1 és b1 ami queued (vagy épp running, attól függ mi van beütemezve).
Yielddel nem csak a1 és b1 közötti ütemezést lehetne befolyásolni?
> Ez alapján annyira random a yield, hogy az is lehet hogy a1 blocked állapotba kerül (hisz másképp nem kerülhetne ütemezésre a1-a10 közül más, mert az a1 foglalja a monitort), de az is lehet, hogy nem változik semmi?
De, persze, sok volt a sor.
> Yielddel nem csak a1 és b1 közötti ütemezést lehetne befolyásolni?
De. Ha a1 running es b1 queued, es a1 yieldel, utana vagy a1, vagy b1 lesz running.
Mondjuk teny, hogy az elozo valasz ota meg 4 sort ittam, szoval ki tudja.
-
emvy
félisten
alap threading kérdésem lenne...
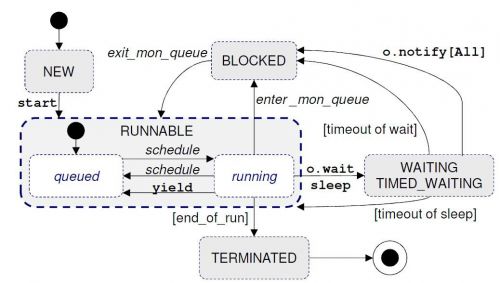
A képen milyen állapot a queued? Ez alapján a yield csak jelzi, hogy hajlandó a szál feladni a futási jogát, és JVM dönt, hogy fut-e tovább.
TFH van 1 CPU mag, 1 A objektum amire szinkronizál 10 thread (a1 .. a10) és, 1 B objektum, amire szinkronizál másik 10 thread (b1 .. b10).
Az a1 .. a10 szálak között az ütemezés úgy zajlik, hogyha a1 szál lemond a futási jogáról, akkor (timed) waiting állapotba, és az A objektum monitor sorábol bekerül másik szál a monitorba, ami futhat.
Közben ettől függetlenül a működik a preemptív ütemezés a JVM-en (és alatta a host oprendszeren), és passzolgatja a futási jogot az A objektum monitorában és B objektum monitorában lévő szálak között.
Jól gondolom, hogyha a yield meghívódik, akkor az egy jelzés a JVM-nek, hogy az éppen futó a1 szál helyett beütemezheti a B objektum monitorában lévő b1 szálat, és nem fogja befolyásolni azt, hogy az A objektum monitorában és monitor sorában kik állnak?
A queued az, ami nem var semmilyen monitoron, csak preemptalva lett (vagy csak elinditottak, de meg nem kerult utemezesre).
A yield csak egy jelzes. Nincs definialva, hogy mi fog tortenni, siman lehet, hogy a yield utan ugyanaz a szal fut. Ha a1 nyom egy yield-et, akkor a1-a10 es b1-b10 szalak kozul valamelyik fog utemezesre kerulni. A queued ne tevesszen meg, nincs sorrendiseg ertelmezve a varakozo szalak kozott.
-
 PumpkinSeed
addikt
PumpkinSeed
addikt
Itt van a kis béna webapp ami miatt annyit kérdeztem mostanság.
Ha elmenne a netem, azért nem vállalok felelősséget.Frontend egy összegányolt single page app, sima html + jquery kombóval, azt majd újraírom angularral. A kinézetet ötévesek tervezték.
Regisztrációs felület még nincs, ezért csináltam a topiknak egy usert:
user: JavaHurkák
pwd: password3 hónappal ezelőtti IMDB adatbázisból dolgozik (akkor töltöttem le).
Elsősorban azért raktam be ide, hogy aki tud, az írhatna ötleteket új funkciókhoz.
A Movies alatt a Page Size állítása a Most kulcsszóra működik, de gondolom nem így tervezted. Valamiért nekem villog össze vissza, meg ilyenek.Elég furcsa, amúgy egy kis margin-t tehetnél. Most így hirtelen ennyi.
Szerk.: Ja meg ha a show details-re kattintunk akkor felmehetne a detail-sra, mert vártam, hogy majd ott lenyílik valami aztán jöttem rá, hogy feljebb kell menni hozzá.
-
floatr
veterán
Nem csak most, régebben is.
(#7455) Aethelstone én ezt ebben a sorrendben toltam: többféle basic, assembly (z80), pascal, c, assembly (x86), c++, java. Aztán a többi sallang. A C++ okozott sokaknak fejtörést, láttam ahogy vért izzadnak, pedig akkor a template-ek még sehol nem voltak. Egyszerűen elvesztek az absztrakcióban, és nem tudták készség szinten használni. Ahhoz képest a pointerek nélküli C gyerekjáték volt
-
floatr
veterán
Ne mondd ezt. Én GTK alatt maszatoltam pythonnal, és elég gyorsan lehetett látható dolgokat csinálni. Ha valaki nagyon bele akar kapálni a dolgokba, úgyis utána megy.
Praktikussági alapon nekem a JS talán az, ami minden szempontból jó lehetne, bár nyilván mindenkinek más áll jobban kézre.
-
emvy
félisten
A productivity és a több paradigma miatt akarom megtanulni. Olvastam ellenvéleményeket, pont azokat a hátrányokat írták, amit te. Igaz olyat nem hallottam, hogy scalaról visszamentek javara, viszont csomó beszámolót olvastam a neten, hogy miért választották a scalat a következő projektünk nyelvének. [link] [link]
Teljesen irreleváns, hogy a következő projekt nyelve mi. Olyanokat keress, akik már csináltak vele nagyobb projektet. Szerintem. A többféle paradigma megtanulasara nem jo, mert mindenből van benne egy kicsi. Funkcprogra jobb a Clojure (vagy racket vagy akarmi) meg a Haskell.
Tényleg nem muszáj nekem elhinni, de hidd el :d
-
emvy
félisten
Nézd meg, hogy a nagy rendszereket gyártó cégek, akik Scalaztak, hogy állnak vissza Javára vagy valami másra. A Scala problémája az, hogy őrült bonyolult lett a nyelv. Fun megtanulni, es amikor használod, akkor nagyon produktívnak érzed magad. A probléma ott jön, amikor pár főnél nagyobb csapat kezd el dolgozni, és mindenkinek más rész tetszik a Scalabol.
Nekem bejott a Scala, de amikor elkezdtem nézegetni a Scalaz-t meg társait, akkor ezt láttam. Aztán miután hagytam, kezdtek jönni az iparbol is a hírek, hasonló tapasztalatokról. (sok publikus hír is van, de privátban nem publikusbol is van pár sztorim)A Scala a JVM C++-a. Read this.
Egyébként a Clj számomra nagyobb revelacio volt, de persze ízlés dolga..
-
emvy
félisten
-
floatr
veterán
-
 norbert1998
nagyúr
norbert1998
nagyúr
-
jetarko
csendes tag
Most nem vagyok otthon, de út közben nem hagy nyugodni a gondolat. Fut a webapp a gépen, és ha a host gép böngészőjéből nyitok meg egy oldalt, akkor szépen a frontendtől elmegy rest hívás a backendhez, meghívódik a controller megfelelő metódusa, és visszaadja amit várok. Viszont ha másik gépről/telefonról nyitom meg az oldalt böngészőben, a host ip címét beírva, akkor a frontend elküldi a rest hívást a backendnek, a dispatcher elkezdi feldolgozni, de nem jut el a request a controllerig. Elkezdtem, de nem volt időm végignézni mit csinál a dispatcher (doDispatch metódus) és min hasal el, mert indulnom kellett, de jó lenne tudni, hogy mégis mitől lehet ez. Van valami gyakori hiba amit elkövettem?
CORS talán?
-
Aethelstone
addikt
A label már durva, de egy breakkel semmi baj. Nyilván célszerűbb valami do while vagy while szerkezetet felépíteni, ha az ember ki akar idő előtt lépni, de szerintem a for loop-ban elkövetett breakkel sincs semmi baj. Ha az ember módjával használja. Persze háromezer if the else és switch szerkezetekben 678 break nem szép....
-
floatr
veterán
lyaly
Itt azért elkövettél pár olyan dolgot, amivel alá lehet vágni egy kitervelt rendszernek. Egyrészt - bár ismétlem magam - ez a generált kód... szerintem jobban jársz, ha egy kicsit veszed a fáradtságot, és megtanulod magad legyártani a kódot a táblák alapján, vagy fordítva.Ha már generáltál valamit adatbázis valami alapján, akkor nagyon észnél kell lenni, hogy mibe túrsz bele. Itt épp azzal babráltál, amivel nem kéne. Mellesleg nekem amiatt gyanús a metódusra akasztott annotációval, mert olyan, mintha félig, vagy egyáltalán nem értené, hogy máshogy akarod elnevezni. Ha már annotálod a cuccot, akkor az átláthatóságot is növeli, ha a mezőkre aggatod őket.
Az@Id mellé még odatenném a @GeneratedValue-t is, mert ezzel a legtöbb adatbázisnál tud auto increment-es típust használni.
-
 #39560925
törölt tag
#39560925
törölt tag
Egyébként az MpaaRatings-zel ugyan ezt csinálja. Ott is nem létező, id oszlopot keres az adatbázisban. Ezekről tudni kell, hogy én nyomtam alter table-t utólag a táblákon, hogy legyen elsődleges kulcs bennük. Pl:
alter table movietime2.movies2actors add m2aid int primary key auto_increment;Ez azóta is jó egyébként, a movies2actors kapcsolótáblát boldogan tudom használni.
Ha explicit megadom az MpaaRatingsEntity-hez, hogy mi a join table és mik a join columnok, akkor se jó:
@JoinTable(name = "mpaaratings", catalog = "movietime2", schema = "",
joinColumns = @JoinColumn(name = "movieid", referencedColumnName = "movieid", nullable = false),
inverseJoinColumns = @JoinColumn(name = "mpaaratingsId", referencedColumnName = "mpaaratingsId", nullable = false))"Missing column: mpaaratings_id in movietime2.mpaaratings"
Holott meg:

Fogtam az adatbázist és toltam rá alter tablet, átneveztem az oszlopot arra, amit a hibernate annyira használni akart, és már jó. Megoldást nem találtam, mindenesetre nagyon furcsa.
-
#39560925
törölt tag
"Nekem a hibaüzenetből eleve az gyanús, hogy a táblában más néven keresi az ID-t, mint ahogy deklaráltad volna."
Ok, de mire gyanakszol?
Miért "ahogy deklaráltad volna"? Nem volna, hanem így van deklarálva: genreId. Meg is van adva neki, hogy így keresse.
"A helyedben én az @Id és @Column annotációkat nem a metódusokra tenném."
Nem én tettem, az Idea volt. Tökéletesen működik minden, ha kiveszem a GenresEntity osztályt."Az meg a másik, hogy ha csak nem muszáj, én nem babrálnám a hibernate saját elnevezési stratégiáját."
Ezt kifejtenéd kérlek bővebben? Mire gondolsz?
Ha az entitások és az attribútimaik neveire gondolsz, akkor azok 2 okból alakultak így:
1) adatbázisban a nevek
2) Ideában a Generate persistence mapping by database schema wizardbólEgyébként az MpaaRatings-zel ugyan ezt csinálja. Ott is nem létező, id oszlopot keres az adatbázisban. Ezekről tudni kell, hogy én nyomtam alter table-t utólag a táblákon, hogy legyen elsődleges kulcs bennük. Pl:
alter table movietime2.movies2actors add m2aid int primary key auto_increment;Ez azóta is jó egyébként, a movies2actors kapcsolótáblát boldogan tudom használni.
Ha explicit megadom az MpaaRatingsEntity-hez, hogy mi a join table és mik a join columnok, akkor se jó:
@JoinTable(name = "mpaaratings", catalog = "movietime2", schema = "",
joinColumns = @JoinColumn(name = "movieid", referencedColumnName = "movieid", nullable = false),
inverseJoinColumns = @JoinColumn(name = "mpaaratingsId", referencedColumnName = "mpaaratingsId", nullable = false))"Missing column: mpaaratings_id in movietime2.mpaaratings"
Holott meg:
-
floatr
veterán
Intellij Idea tette bele a generálás során. Ezen én is gondolkodtam, de mivel nem fogok hozzájuk nyúlni, egyelőre nem akartam bántani őket.
"MoviesEntity -ben hol a characters mappelése?"
Látod, a hsz-ben, de itt van mégegyszer:
@OneToMany(mappedBy = "movie")
public List<Movies2ActorsEntity> getCharacters() {
return characters;
}Nekem a hibaüzenetből eleve az gyanús, hogy a táblában más néven keresi az ID-t, mint ahogy deklaráltad volna. A helyedben én az @Id és @Column annotációkat nem a metódusokra tenném.
Az meg a másik, hogy ha csak nem muszáj, én nem babrálnám a hibernate saját elnevezési stratégiáját.
Az org.hibernate.cfg.DefaultComponentSafeNamingStrategy nekem eddig minden problémámat megoldotta -
Mukorka
addikt
Először is itt egy működő példa |Movies2Actors| *----1 |Movies|:
MoviesEntity class:
@JsonIgnore
private List<Movies2ActorsEntity> characters;
@JsonIgnore
private List<GenresEntity> genres;
...
@OneToMany(mappedBy = "movie")
public List<Movies2ActorsEntity> getCharacters() {
return characters;
}
@OneToMany(mappedBy = "movie")
public List<GenresEntity> getGenres() {
return genres;
}Movies2ActorsEntity class:
private int m2aid;
private int movieid;
private int actorid;
private String asCharacter;
private ActorsEntity actor;
private MoviesEntity movie;
...
@Id
@Column(name = "m2aid", nullable = false, insertable = true, updatable = true)
public int getM2aid() { return m2aid; }
@ManyToOne
@JoinColumn(name = "movieid", referencedColumnName = "movieid", nullable = false)
public MoviesEntity getMovie() {
return movie;
}És akkor a |Genres| *----1 |Movies|
GenresEntity:
private int movieid;
private String genre;
private int genreId;
@JsonIgnore
private MoviesEntity movie;
...
@Id
@Column(name = "genreId", nullable = false, insertable = true, updatable = true)
public int getGenreId() {
return genreId;
}
@ManyToOne
@JoinColumn(name = "movieid", referencedColumnName = "movieid", nullable = false)
public MoviesEntity getMovie() {
return movie;
}Ha már mappeled az entitást akkor minek vannak ott az id-k pl a Movies2ActorsEntity-ban? Ez talán nem okoz problémát bár vicces lehet ha átállítod az entitást és az id meg marad a régi. (Gondolom felülírja az újal de lehet hogy nem).
MoviesEntity -ben hol a characters mappelése?
-
emvy
félisten
De, persze, ezt a MoviesEntity-vel joinolom. Azóta az is belekerült az SO kérdésbe. De a kérdés inkább az, hogy a hibernate honnan szedi ezt a genre_id-t, amikor elvileg helyesen fel van annotálva, hogy genreId van az adatbázisban. MoviesEntity és Movies2ActorsEntity között ugyan ilyen OneToMany kapcsolat van és működik, ahhoz képest semmit sem csináltam másképp.
A @ManyToOne (vagy hasonlo) attributum mellett megadod a @JoinColumn(name=genreId)-t is? Mert tippre az a helyzet, hogy a join soran generalja neked a genre_id oszlopnevet.
-
emvy
félisten
-
floatr
veterán
A JSON generálásra céloztam. És így van, ha adatokat adsz-veszel, akkor több kommunikációval jár, ami hálózati probléma lehet.
Másik oldalról viszont ott van a fejlesztés és karbantartás. A Java legnagyobb előnye az előtte lévő nyelvekkel/rendszerekkel szemben, hogy gyorsan tudsz eredményt produkálni, pláne ha ilyen irgalmatlan nagy ökoszisztéma jár vele. Ha lábon lövöd magad egy olyan implementációval, amivel időt veszítesz, és rugalmatlanná teszed az alkalmazásodat, és mindezt a hálózati forgalom miatt aggódva, akkor pont a Java előnyeit áldozod be. Néha erre szükség van, amikor nagyon kritikus a teljesítmény egy adott vason, de nem minden áron.
Tegyük fel, hogy a kommunikáció régebbi MVC-szerű alapokra épül. Oldalak jönnek le sokszor feleslegesen, mire a teljes adatkészletet megkapod. Ha már valami ajaxos megoldást is használsz, akkor az overhead sokkal kisebb lesz; akkor bukik ki a leginkább, amikor egy eseményre több kérést kell lezavarnod. A teljesítmény a hálózat teljesítőképességén, és a protokollon is múlik. Ha viszont már websocket/STOMP klienst használsz, akkor megint eltűnik az overheadből egy elég nagy rész, mert a kapcsolat felépítésének a költsége nem terheli a további requesteket; gyakorlatilag eljutsz odáig, mintha egy ESB/JMS integrációs megoldást használnál, aminek a másik végén egy repository jellegű szolgáltatás ül.
Szóval ha engem kérdezel, csak magadat szívatod meg a DTO-kkal.
-
#39560925
törölt tag
Persze értem a csomagolás hátrányát is, de szerintem kisebb, mint a másiknak.
-
Mukorka
addikt
Alvás helyett gondolkodtam floatr hozzászólásán. Biztos, hogy JSON serialization-ről beszélt. Ha a kapcsolatokra teszek @JsonIgnore-t, akkor amikor csak alap információk kellenek az entitásokról, jól fog működni parszolás. Amikor pedig egy nagy objektumot küldenék, pl Movie, és benne minden kapcsolódó adattal, akkor ilyen esetekre definiálnék wrapper osztályt, és benne lenne minden szükséges adat egy mezőként.
Pl:
public class MovieWrapper {
private MoviesEntity movie;
private ArrayList<ActorsEntity> actors;
private ArrayList<WritersEntity> writers;
// többi kapcsolat
...
// getterek, setterek
}Ezt az objektumot gyönyörűen meg tudom konstruálni a business logic layerben, amikor még van hibernate sessionöm, és így nincs konverzió, kódduplikáció, csak 1 kis extra karbantartás.
Kérdés: Jackson tudni fogja ezt parszolni? Most nem tudom kipróbálni, mert már aludni akarok, és mobilról írtam.
Ez akkor lenne jó ha cserébe az entitásban nem is említenéd meg a kapcsolatokat, máskülönben ugyanúgy duplikálás.
-
 Szmeby
tag
Szmeby
tag
Az alapvető probléma az, hogy két helyen kell ugyanazt karbantartani. Amíg csak néhány entitásról van szó, oké, de amikor elkezd növekedni a számuk, és elkezdenek ezek változni is, akkor születnek újabb bogárkák.
Mert például valaki elfelejtette átvezetni a módosítását a másik osztályba, elfelejtődik, és később jönnek a hibák.
Röviden: a duplikált kód rossz.Ez persze nem jelenti azt, ne lehetnél vele boldog, csak érdemes jobb megoldás után kutatni.
Láttam olyan helyet, ahol ennek a menedzselésére bevezették a kódgenerálást. Ott aztán már durva állapotok vannak, ha az ember ilyesmire kényszerül. Egy xtend leíróban legózhatod össze a java forráskódot töredékekből, ezzel többféle forrást is generálhatsz, amit majd a compiler fordít, stbstb. Így xtend-ben kell egyszer megírni a cuccot és az akár 20 féle DTO-t is kigenerál neked. Vagy amennyit akarsz. Tiszta káosz. Cserébe viszont az xtend nehezebben olvasható. Vagy lehet, hogy csak szokni kell. Szerencsére nem sokáig kellett gyönyörködnöm benne.
-
Aethelstone
addikt
-
Mukorka
addikt
Szerintem arra gondolt hogy nem mappeli fel őket. Tehát a hibernate nem managelné a listát.
DTO konvertálás szerintem is csúfságos.
-
floatr
veterán
Legjobban akkor jöttem ki hasonló dolgokból, amikor az efféle collection-öket letiltottam a serialization-ből, és külön húztam le, amikor szükség volt rá. Ha egyből használnád is, ahogy ez nem éppen a legoptimálisabb, akkor is lehet callback/promise lánccal hívogatni a service-eket. Nekem ettől a DTO-s konvertálgatástól hidegrázásom van...
-
Szmeby
tag
Lehet kezdek rájönni. Ignorálni kéne alapból minden kapcsolatot, és kézzel intézni őket.
hmm... de ha @JsonIgnore-t rakok rájuk, akkor sehogy sem tudom majd serializálni őket JSON-ba.
Minden bizonnyal az van amit írsz, de nekem nem világos miért akarja a Jackson bejárni az egész adatbázisomat.
Ha sikerülne neki, alsó hangon 8 gigás lenne a HTTP response bodyja.Ha más lehetőség nincs a copy-paste mindig segít.
MovieEntity a JPA-nak, MovieRepresentation a JSON parsernek, és a kettő közé egy finom konverter, ami egyikből másikat csinál. A két eszköz nem fog egymásnak bekavarni, a konverterben meg célzottan meg tudod adni, miből mikor mit csináljon. -
#39560925
törölt tag
Lehet kezdek rájönni. Ignorálni kéne alapból minden kapcsolatot, és kézzel intézni őket.
hmm... de ha @JsonIgnore-t rakok rájuk, akkor sehogy sem tudom majd serializálni őket JSON-ba.
Minden bizonnyal az van amit írsz, de nekem nem világos miért akarja a Jackson bejárni az egész adatbázisomat.
Ha sikerülne neki, alsó hangon 8 gigás lenne a HTTP response bodyja.Ez így nagyon nem pálya, 1 weboldal betöltéséhez n*100 http üzenetváltás kéne. Tanácstalanná váltam
-
Mukorka
addikt
Ez nem fog működni, baja van a Jacksonnak.
Pl filmeknél direkt gettelek minden színészt, írót és producert, mégse hajlandó létrehozni belőle a json objektumot:
Could not write content: failed to lazily initialize a collection of role: com.movietime.model.MoviesEntity.actors, could not initialize proxy - no Session (through reference chain: com.movietime.model.MoviesEntity.
Nem tudom minek akar itt proxyzni, amikor be vannak töltve neki a dolgok, és megfelelően annotálva vannak az entitások is, pl MoviesEntity:
@JsonIdentityInfo(generator = ObjectIdGenerators.PropertyGenerator.class, property = "movieid")Ez csak az egyik baj, a másik az, ha csak listázni akarok filmeket, akkor fölösleges betölteni minden filmhez minden adatot, elég csak a címet, rendezőt és mondjuk két színész nevét kiírni a listában. A többit akkor kéne csak lekérdezni az adatbázisból, ha rákattint valamelyikre a felhasználó. Ha sikerülne is rávenni a Jacksont, hogy legalább akkor csinálja a dolgát, amikor minden információ megvan hozzá, ez a funkció még akkor se működne.
Nem lehet hogy a fel eager fetchelt objektum listád tagjainál száll el , hisz azokban ugyan úgy van lazy collection ami visszamutat. A json parser meg gondolom mindent felránt ami be van annotálva vagy ami nincs (nemtom melyik). Ez esetben valami ignore-t lehetne rájuk tenni.
-
#39560925
törölt tag
Többnyire gúglit nézek, aztán onnan mindenfelé vezetnek utaim, többek között a hibernate doksihoz is.
Nekem az 1-es megoldás tetszik a legjobban, és ha nem jön be, akkor megnézem a többivel. A gond lehet, hogy valójában nem is itt van, hanem a JSON parserrel, de ez még kiderül, mindenesetre most nőtt annyival a tudásom, hogy jó ideig ellegyek vele.
Egyébként több helyen is olvastam, hogy a hibernatenek tudnia kéne kezelni eager fetchelés közben az ilyen ciklikus, 2 irányú many-to-many kapcsolatokat, de úgy látszik a gyakorlatban még sincs így.
(#7191) emvy: Hmm, logikusan tűnik.
Ez nem fog működni, baja van a Jacksonnak.
Pl filmeknél direkt gettelek minden színészt, írót és producert, mégse hajlandó létrehozni belőle a json objektumot:
Could not write content: failed to lazily initialize a collection of role: com.movietime.model.MoviesEntity.actors, could not initialize proxy - no Session (through reference chain: com.movietime.model.MoviesEntity.
Nem tudom minek akar itt proxyzni, amikor be vannak töltve neki a dolgok, és megfelelően annotálva vannak az entitások is, pl MoviesEntity:
@JsonIdentityInfo(generator = ObjectIdGenerators.PropertyGenerator.class, property = "movieid")Ez csak az egyik baj, a másik az, ha csak listázni akarok filmeket, akkor fölösleges betölteni minden filmhez minden adatot, elég csak a címet, rendezőt és mondjuk két színész nevét kiírni a listában. A többit akkor kéne csak lekérdezni az adatbázisból, ha rákattint valamelyikre a felhasználó. Ha sikerülne is rávenni a Jacksont, hogy legalább akkor csinálja a dolgát, amikor minden információ megvan hozzá, ez a funkció még akkor se működne.
-
emvy
félisten
Az alacsonyabb szintu retegek altalaban epphogy kevesbe optimalisak, mert nem all rendelkezesukre az osszes informacio (constraint, etc.), ami a felette levo retegeknek igen. Csak megjegyeztem (a konkret temahoz eleg keveset lovok, en altalaban nagyon alapdolgokra hasznaltam csak Hibernate-et, es utolag nem is biztos, hogy volt ertelme)
-
Szmeby
tag
Vannak adatbázis entitásaim amik körbehivatkoznak egymásra, például MoviesEntity ismer csomó ActorsEntity-t és vica-versa. Ezeket az entitásokat akarom REST-en keresztük JSON-nel elérhetővé tenni, méghozzá úgy, hogyha jön egy GET request egy MoviesEntity-re, akkor fetchelje le a hozzátartozó Actorokat, Producereket, stb-t, de ne tovább. Ez sikerül is az alábbi módon:
MoviesEntity:
@JsonManagedReference
private List<ActorsEntity> actors;
...
@ManyToMany(fetch = FetchType.EAGER)
@JoinTable(name = "movies2actors", catalog = "movietime2", schema = "", joinColumns = @JoinColumn(name = "movieid", referencedColumnName = "movieid", nullable = false), inverseJoinColumns = @JoinColumn(name = "actorid", referencedColumnName = "actorid", nullable = false))
public List<ActorsEntity> getActors() {
return actors;
}ActorsEntity:
@JsonBackReference
private List<MoviesEntity> movies;
...
@ManyToMany(mappedBy = "actors") // LAZY fetching is default
public List<MoviesEntity> getMovies() {
return movies;
}Ez rendben is van. Viszont azt is szeretném, hogyha valaki egy Actor-t kérne GET requesttel, akkor ugyan úgy kapja meg az 1 távolságra lévő kapcsolódó entitásokat is (pl milyen filmekben játszott).
Erre nincs ötletem, nem is nagyon találtam neten semmit. Esetleg valaki tudja mi ilyenkor a teendő, vagy ha valaki jobban gúglizik, mint én, az is nagy segítség volna.
conditional annotiation ha lenne, milyen jó lenne.
Kicsit későn lövöm el a hsz-t, feltartottak. Talán ad ötletet.
--------
Szerintem fixen belőtt annotációkkal nem fog menni, mivel nem egyértelmű, hogy melyik fetch módot kell alkalmazni.
Alap, hogy minden lazy. Mivel csak a REST hívás beérkezésekor tudod eldönteni, hogy adott esetben melyik kapcsolatot kell eager fetchelni, nincs mese, runtime ott helyben kell megmondanod neki.Erre sokféle módszer létezik, hogy melyik szép, azt nem tudom.
1. Ha a user a filmre kíváncsi, előkeresed a filmet, majd ráhívsz a getActors() metódusra (ez úgy tudom meglöki a proxy-t és ha sessionben vagy, akkor feltölti az actorokkal is).
2. Talán named query használatával (movie és actor joinnal) ez a bohóckodás egyszerűbbé tehető.
3. Rémlik valami olyasmi, hogy JPA/Hibernate alatt runtime felülbírálható a fetch mód. De itt is áll, hogy minden lazy és szükség esetén adott hívásnál döntöd el, hogy mit nyomatsz eagerrel. Mintha valamiféle fetch profilt kellene ehhez létrehozni (ezzel jól megannotálva az entitást), és az entitás lekérésekor elég csak a profilra hivatkozni.
4. ...
Sajnos nagyon régen Hibernate-eztem, nem biztos, hogy ezek a legjobb megoldások, vagy hogy egyáltalán működnek.
A hibernate doksit nézted már? -
Mukorka
addikt
Ha egy service layer-beli osztályban van egy @Transactional metódus, ami meghívja egy DAO osztály metódusát, amely osztályban be van injektálva egy EntityManager @PersistenceContext-tel, akkor ennek az EntityManagernek a perzisztenciakontextusa megmarad a hívó service layer-beli metódusban is?
Most kísérleti jelleggel azt csinálom, hogy a RestController osztály metódusát jelöltem @Transactional-nek és az közvetlen hívja a DAO osztály metódusát, ami egy MovieEntityvel tér vissza, de amikor a RestController metódusa átadja a Jackson JSON parsernek a MovieEntityt, akkor mintha már nem lenne meg a perzisztenciakontextus, mert a hibernate proxy objektum megszűnt, és nem éri el a kapcsolódó entitásokat:
com.fasterxml.jackson.databind.JsonMappingException: failed to lazily initialize a collection of role: com.movietime.model.ActorsEntity.movies, could not initialize proxy - no Session
Próbálkoztam azzal, hogy EAGER fetchinget állítok be minden Entitás osztályban, és akkor nem lenne ilyen probléma, de akkor a túl sok bi-directional many-to-many asszociáció miatt megbolondul a hibernate és a Query.getSingleResult() már vissza se tér.
Kerestem olyan megoldást is, hogy lehessen korlátozni az EAGER fetching mélységét, de csak olyat találtam, hogy a LAZY-t lehet optimalizálni @BatchSize-zal. Viszont ez nekem nem jó, mert a JSON parserig már nem jut el a hibernate sessionje, vagy persistence contextje, nem tudom hogy hívjam.
Csinálhatnám azt is, hogy a DAO rétegben olyan lekérdezéseket írok kézzel, hogy lekérem a filmet, aztán lekérem a hozzá kapcsolódó színészeket, producereket, mindenkit, és összetákolom a kapcsolatokat, de ez egyrészt nagyon lábbal hajtós, másrészt az adatbáziskapcsolattal nagyon pazarló lenne. Jobb lenne, ha ezt a hibernate elintézné.
Az is jó lenne, ha a @Transactional úgy működne, ahogy a hsz elején a kérdésben feltettem, de nekem úgy tűnik, mintha nem így történne. Lehet azért, mert nem JTA típusú tranzakcióim vannak, hanem JPA?
A transactional csak azt dönti el hogy a bean vagy a container manageli e a tranzakciót.Ettől még a dao hívás végén vége a tr-nek és a sessionnek is. Elvileg nem is lehet egynél több persistentbag-et fetchelni egyszerre. Attól hogy mindenki eager még nem lesz egy select az egész tehát a db kapcsolatot a tákolós megoldás is épp annyira terheli le.
Ahogy én eddig láttam erre rendszerint a külön dao hívások jelentenek megoldást. Mindegyiknél eldöntöd hogy mire van ténylegesen szükséged, alapból meg minden lazy.
-
CJ19
csendes tag
-
Aethelstone
addikt
Fogtam magam, leklónoztam egy projektet githubról, átírtam 1-2 dolgot, hogy nekem jó legyen, és azóta boldog vagyok.
Persze azt fel kellett hagynom, hogy Eclipselinket használjak Spring mellé, Hibernatetel minden megy mint a karikacsapás.
(#7154) Aethelstone: Most örülök, hogy működik RESOURCE_LOCAL-lal, tudok EntityManagert injektálni @PersistenceContext-tel, szóval mindent megkaptam amit akartam. Ha kicsit több önbizalmam lesz, átállok, de kicsit haladni is szeretnék a projekttel.
Ha már Hibernate, akkor érdemes lenne a Hibernate Session körül is futnod pár kört. Nyilván a használata nem olyan általános, mint ha EntityManager-t injektálsz, de én még olyat nem láttam, hogy egy nagy (vagy kicsi) projektben az ORM réteget egy az egyben lecserélték volna. Ha meg igen, akkor az új ORM réteg megfelelő, natív megoldását használják úgy is.
-
Aethelstone
addikt
Fejlemény. Na mondom kipróbálok másik application servert, legyen Glassfish 4. Arra nem tudtam deployolni az alkalmazást:
cannot Deploy MovieTimeProject
deploy is failing=Error occurred during deployment: Exception while preparing the app : The persistence-context-ref-name [com.movietime.repositories.ActorRepository/em] in module [MovieTimeProject] resolves to a persistence unit called [MovieTime] which is of type RESOURCE_LOCAL. Only persistence units with transaction type JTA can be used as a container managed entity manager. Please verify your application.. Please see server.log for more details.Akkor mégiscsak JTA típusú tranzakció kell. Fasza.
Mindig célszerű JTA-t használni. Lehet kézzel is állítgatni a DAO rétegben, de vért lehet hugyozni vele....
Sőt, container managed környezetben bűncselekmény nem JTA-t használni.... -
#39560925
törölt tag
Az a baj, hogy hiába gúglizok, csak olyan találatok vannak, amikor JPQL-ben a tábla nevét használták az entitás helyett, de nálam nem így van. Próbáltam azt is, hogy a
<exclude-unlisted-classes>false</exclude-unlisted-classes>
sort kivettem a persistence.xml-ből és explicit felsoroltam az osztályokat, ugyan ez az error volt.Fejlemény. Na mondom kipróbálok másik application servert, legyen Glassfish 4. Arra nem tudtam deployolni az alkalmazást:
cannot Deploy MovieTimeProject
deploy is failing=Error occurred during deployment: Exception while preparing the app : The persistence-context-ref-name [com.movietime.repositories.ActorRepository/em] in module [MovieTimeProject] resolves to a persistence unit called [MovieTime] which is of type RESOURCE_LOCAL. Only persistence units with transaction type JTA can be used as a container managed entity manager. Please verify your application.. Please see server.log for more details.Akkor mégiscsak JTA típusú tranzakció kell. Fasza.
-
 skoda12
aktív tag
skoda12
aktív tag
Tipikusan akkor használják ezt a kifejezést, amikor valaki olvas valami újat és minden problémát ezzel akar megoldani.
Persze értem, hogy te most csak tanulási célok miatt próbálgatod. -
emvy
félisten
Na újra itt vagyok. Kicsit rendbeszedtem a config fájlokat, most a következőképpen néznek ki a dolgok:
web.xml, spring-servlet.xml, persistence.xml
A HelloController-ben kérek egy lekérdezést az adatbázisból a MovieService-en keresztük a MovieRepository-tól, és az em.createQuery exceptiont dob.
Nem értem miért, mert a LocalContainerEntityManagerFactoryBean-ben meg van adva a "packagesToScan" property "com.movietime.entities"-nek, és a persistence.xml-ben is ott van, hogy
<exclude-unlisted-classes>false</exclude-unlisted-classes>.Azt mondja, hogy
"[14, 19] The abstract schema type 'Movie' is unknown.
[28, 35] The state field path 'm.title' cannot be resolved to a valid type."miközben az IDE képes volt rájönni, hogy mi ez a Movie.
Miért ilyen nehéz rávenni a springet és a JPA-t, hogy működjön?
"Miért ilyen nehéz rávenni a springet és a JPA-t, hogy működjön?"
Azért,mert ezeket arra találták ki, hogy minel tobb konzultanst meg fejlesztőt kelljen a multicegeknek alkalmaznia, az, hogy bizonyos esetben meg lehet veluk oldani a problémát (vagy azt hiszed, hogy meg lehet), csak egy mellékhatás
/troll"LocalContainerEntityManagerFactoryBean" -- ez szepen összefoglalja
Szoval ha jol latom, egy irtozatosan egyszeru dolgot akarsz megcsinalni -- a problema ezzel az okoszisztemaval az, hogy
- egyszeru dolgokat is bonyolult megcsinalni
- ha az egesz hobelevancot megtanulod sok-sok ido alatt, onnantol meg van egy bazi nagy kalapacsod, es igazabol ugy tudsz normalis penzt keresni, ha mindent szognek nezel. -
#39560925
törölt tag
Na újra itt vagyok. Kicsit rendbeszedtem a config fájlokat, most a következőképpen néznek ki a dolgok:
web.xml, spring-servlet.xml, persistence.xml
A HelloController-ben kérek egy lekérdezést az adatbázisból a MovieService-en keresztük a MovieRepository-tól, és az em.createQuery exceptiont dob.
Nem értem miért, mert a LocalContainerEntityManagerFactoryBean-ben meg van adva a "packagesToScan" property "com.movietime.entities"-nek, és a persistence.xml-ben is ott van, hogy
<exclude-unlisted-classes>false</exclude-unlisted-classes>.Azt mondja, hogy
"[14, 19] The abstract schema type 'Movie' is unknown.
[28, 35] The state field path 'm.title' cannot be resolved to a valid type."miközben az IDE képes volt rájönni, hogy mi ez a Movie.
Miért ilyen nehéz rávenni a springet és a JPA-t, hogy működjön?
Az a baj, hogy hiába gúglizok, csak olyan találatok vannak, amikor JPQL-ben a tábla nevét használták az entitás helyett, de nálam nem így van. Próbáltam azt is, hogy a
<exclude-unlisted-classes>false</exclude-unlisted-classes>
sort kivettem a persistence.xml-ből és explicit felsoroltam az osztályokat, ugyan ez az error volt. -
#39560925
törölt tag
Na újra itt vagyok. Kicsit rendbeszedtem a config fájlokat, most a következőképpen néznek ki a dolgok:
web.xml, spring-servlet.xml, persistence.xml
A HelloController-ben kérek egy lekérdezést az adatbázisból a MovieService-en keresztük a MovieRepository-tól, és az em.createQuery exceptiont dob.
Nem értem miért, mert a LocalContainerEntityManagerFactoryBean-ben meg van adva a "packagesToScan" property "com.movietime.entities"-nek, és a persistence.xml-ben is ott van, hogy
<exclude-unlisted-classes>false</exclude-unlisted-classes>.Azt mondja, hogy
"[14, 19] The abstract schema type 'Movie' is unknown.
[28, 35] The state field path 'm.title' cannot be resolved to a valid type."miközben az IDE képes volt rájönni, hogy mi ez a Movie.
Miért ilyen nehéz rávenni a springet és a JPA-t, hogy működjön?
-
floatr
veterán
Már elindultam abba az irányba, hogy persistence.xml-t kitöröltem, és helyette a spring-servlet.xml-ben configolok, de ekkor egyrészt sír az IDE, hogy hiányzik a persistence.xml, másrészt meg nem tudom, hogy ez esetben hogyan férek hozzá a PersistenceContexthez, vagy azzal ekvivalens funkcióhoz. Ehhez dobna valaki egy leírást?
Most így néz ki a spring-servlet.xml.
(#7112) jetarko:
Jaja, azt benéztem, de eredetileg azért volt ott a .controller, mert azt hittem, hogy csak @Controller osztályokra van szüksége.Találtam neked egy persistence unitos összetettebb példát: [link]
-
jetarko
csendes tag
(#7103) jetarko:
Itt szerintem fel kell sorolni azokat a packageket amikben @componentekre hivatkozol. Pl dao(repo) service csomagok is.Felsorolhatom, de nem kéne neki rekurzívan bejárni a packageket?
A spring xml-ben emf-t adtál meg, a repoban meg em-re hivatkozol.
Tutorialokból raktam össze. A célom az lenne, hogy @PersistenceContext annotációval be tudjak injektálni EntityManagert, és azt használni. Egyébként itt ezt írja: Spring injects @PersistenceContext into Spring components on its own. In order to do so, applications need to be have access to an EntityManagerFactory bean. Gondolom ezért tettek a tutorialban a spring-servlet.xml-be LocalContainerEntityManagerFactoryBean-t.
Ha ehhez a funkcionalitáshoz, amit írtam, valami más kéne a spring-servlet.xml-be, nyugodtan szóljatok.Az xml fájlokban miért van annyi kommentezés?
Azok olyan dolgok amik most nem kellenek, de később fognak. Először működjenek legalább az alapok.
(#7104) Lortech:
Beírtam a persistence.xml-be az alábbi sort az alapján amit floatr linkelt:
<jta-data-source>java:/DefaultDS</jta-data-source>de deployment közben továbbra is error van:
13:57:38,405 INFO [org.jboss.as.server] (ServerService Thread Pool -- 28) JBAS018559: Deployed "MovieTimeProject.war" (runtime-name : "MovieTimeProject.war")
(#7105) floatr:
Ahogy fent is írtam, kipróbáltam, hogy beállítom a jta-data-source-ot, de nem jó. Később szeretném ha az adatbázis 2db clusterezett MySQL instance lenne, köztük egy load balancerrel, és ehhez gondolom nem elég jó a RESOURCE_LOCAL transaction-type. Egyébként Wildfly 8.2-t akarok használni, nem Tomcatet.
Azt mondod, ha kidobnám a persistence.xml-t a kukába, és helyette az általad adott kóddal configolok a spring-servlet.xml-ben, akkor működőképes lesz a cucc? Ha később JTA tranzakciókra kell átállnom, akkor is megoldható lesz így?
Szerintem az xml-ben és java kódban megadottnak egyeznie kell, azaz ha ott emf, akkor a java-ban is írd át emf-re.
A package bejárás meg azért nem megy ha jól látom, mert "com.movietime.controller" van megadva, de a dao ez mellett van és nem benne, ezért vagy megadod, hogy "com.movietime" és innentől bejárja vagy, megadod külön a dao és service package-t is. -
 Lortech
addikt
Lortech
addikt
-
#39560925
törölt tag
(#7103) jetarko:
Itt szerintem fel kell sorolni azokat a packageket amikben @componentekre hivatkozol. Pl dao(repo) service csomagok is.Felsorolhatom, de nem kéne neki rekurzívan bejárni a packageket?
A spring xml-ben emf-t adtál meg, a repoban meg em-re hivatkozol.
Tutorialokból raktam össze. A célom az lenne, hogy @PersistenceContext annotációval be tudjak injektálni EntityManagert, és azt használni. Egyébként itt ezt írja: Spring injects @PersistenceContext into Spring components on its own. In order to do so, applications need to be have access to an EntityManagerFactory bean. Gondolom ezért tettek a tutorialban a spring-servlet.xml-be LocalContainerEntityManagerFactoryBean-t.
Ha ehhez a funkcionalitáshoz, amit írtam, valami más kéne a spring-servlet.xml-be, nyugodtan szóljatok.Az xml fájlokban miért van annyi kommentezés?
Azok olyan dolgok amik most nem kellenek, de később fognak. Először működjenek legalább az alapok.
(#7104) Lortech:
Beírtam a persistence.xml-be az alábbi sort az alapján amit floatr linkelt:
<jta-data-source>java:/DefaultDS</jta-data-source>de deployment közben továbbra is error van:
13:57:38,405 INFO [org.jboss.as.server] (ServerService Thread Pool -- 28) JBAS018559: Deployed "MovieTimeProject.war" (runtime-name : "MovieTimeProject.war")
(#7105) floatr:
Ahogy fent is írtam, kipróbáltam, hogy beállítom a jta-data-source-ot, de nem jó. Később szeretném ha az adatbázis 2db clusterezett MySQL instance lenne, köztük egy load balancerrel, és ehhez gondolom nem elég jó a RESOURCE_LOCAL transaction-type. Egyébként Wildfly 8.2-t akarok használni, nem Tomcatet.
Azt mondod, ha kidobnám a persistence.xml-t a kukába, és helyette az általad adott kóddal configolok a spring-servlet.xml-ben, akkor működőképes lesz a cucc? Ha később JTA tranzakciókra kell átállnom, akkor is megoldható lesz így?
Rossz sort másoltam ki. Ez az error.
-
floatr
veterán
Betenném ide is életem első stackoverflow kérdését, hátha valaki tud segíteni.
[link] Egy válasz a sok közül
Amúgy a load-time weaving nem fog működni tomcat alatt. Egy kollégám hónapokig kesergett miatta. JUnit tesztben ment tomcat 8 alatt nem. Ha jól emlékszem 7-essel még ment a dolog.
De ha nem akarsz métereseket szívni a persistence.xml és tsai konfigurációjával, akkor miért nem csak springben rakod össze a datasource + JPA EMF csomagot?
<!-- setting up JPA EMF -->
<bean id="entityManagerFactory" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean"
p:dataSource-ref="dataSource"
p:packagesToScan="com.movietime.entities" >
<property name="jpaVendorAdapter">
<bean class="org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter" />
</property>
<property name="jpaProperties">
<props>
...
</props>
</property>
</bean>
<!-- Transaction Manager -->
<bean id="transactionManager" class="org.springframework.orm.jpa.JpaTransactionManager"
p:entityManagerFactory-ref="entityManagerFactory" />
<tx:annotation-driven />
<bean id="persistenceExceptionTranslationPostProcessor"
class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor" /> -
Lortech
addikt
Betenném ide is életem első stackoverflow kérdését, hátha valaki tud segíteni.
Szerintem az van, amit a hibaüzenet is mond, hogy ha JTA -t akarsz használni, akkor a persistence-unit-on belül kell egy <jta-data-source>$datasource</jta-data-source>
Ha meg nem JTA, akkor a transaction-type-ot át kell állítani RESOURCE_LOCAL-ra. -
jetarko
csendes tag
Betenném ide is életem első stackoverflow kérdését, hátha valaki tud segíteni.
Tipp:
Error creating bean with name 'emf' defined in ServletContext resource [/WEB-INF/spring-servlet.xml]: Invocation of init method failed; nested exception is javax.persistence.PersistenceException:
A spring xml-ben emf-t adtál meg, a repoban meg em-re hivatkozol.
Az xml fájlokban miért van annyi kommentezés?<!-- Use @Component annotations for bean definitions -->
<context:component-scan base-package="com.movietime.controller" />Itt szerintem fel kell sorolni azokat a packageket amikben @componentekre hivatkozol. Pl dao(repo) service csomagok is.
-
WonderCSabo
félisten
JPA-val lehet olyat csinálni, hogy egy táblában úgy keresek ki rekordokat, hogy a szelekcióban 1 attribútum van, és annak az értékének csak egy része ismert? Mondjuk adott egy városnév egy része, pl 'bud', és minden rekordot szeretnék megkapni, ahol a városnévben van olyan rész, hogy 'bud'. Próbáltam rákeresni neten, de angolul nem tudtam a megfelelő kulcsszavakat kitalálni ehhez.
Persze meg lehetne úgy oldani, hogy minden rekordot kiolvasok, és végigiterálva a listán megnézem, hogy mire illeszkedik ez a feltétel, de ha a JPA-ban lenne ilyen, akkor az biztos erőforrástakarékosabb megoldás lenne.
Mondjuk ahhoz, hogy ez működjön, minden adatbázisrekordot be kell olvasni ígyis-úgyis, szóval háttértár műveleteken a JPA-s megoldás sem tudna spórolni, a memóriaműveletek költsége meg ehhez képest elenyésző.
Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?
Izé, a sima LIKE feltétel nem pont erre való JPQL-ben? Pl. city LIKE '%bud%'.
Szerk.: Ha csak elejére illeszkedés kell: city LIKE 'bud%'
-
 Cathfaern
nagyúr
Cathfaern
nagyúr
igen, 2 indexstruktúra fel van építve az első és második szavak alapján, és minden begépelt betű után indít egy új lekérdezést mindkét indexstruktúrát kihasználva. arra voltam kíváncsi, hogy ilyen sebességgel ez csak in memory database-el valósítható meg, vagy hagyományos diszkrezidens adatbázis is lehet ilyen gyors? de ez csak egy mellékvágány volt, csapongtak a gondolataim, nem emiatt írtam ide eredetileg.
Szerintem lehet, főleg hogy egy ekkora oldalnál jó eséllyel nagyon masszív cachelést alkalmaznak. Gyakorlatilag mire te beírsz bármit, az már jó eséllyel ott figyel a cacheben a látogatószámot figyelembe véve.
-
Cathfaern
nagyúr
"Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?"
Most direkt kipróbáltam. Trükkösek, ez csak akkor működik, ha a filmcím első két szavából kezdem el valamelyiket gépelni.
Módosítom a kérdésem: JPA-val meg lehet oldani, hogy egy attribútum értékének csak az elejének egy része ismert, és a szelekció azokat a rekordokat adja vissza, amik az adott attribútumban így kezdődnek? Az is elég, segítség lenne, ha valaki megmondaná milyen kulcsszavakkal érdemes ilyen probléma esetén keresni. Ilyenekkel próbáltam, hogy:
- jpa select partial attribute
- jpa select by partially known attributede nem találtam semmi használhatót.
"Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?"
Ahogy gépelsz, javascripttel mindig indítanak egy kérést. Ha chrome-ban felnyitsz f12-vel console-t, akkor ahogy gépelsz, látod is. Pl. a "viki" szót beírva erre az URL-re indítja a kéréseket: http://sg.media-imdb.com/suggests/v/viki.json . Ahogy nézem a suggests mögé mindig bekerül az első betű amit beírtál, utána /, majd a keresett szó +.json Ha megnyitod a fenti linket, látni azt is, hogy mit ad vissza, és simán abból építi fel a lenyíló listátSzerk: ja vagy az a kérdés, hogy hogy lesz mindez ilyen gyors? Tippre nem véletlen, hogy első betű alapján külön szedik.
-
#39560925
törölt tag
"Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?"
Most direkt kipróbáltam. Trükkösek, ez csak akkor működik, ha a filmcím első két szavából kezdem el valamelyiket gépelni.
Módosítom a kérdésem: JPA-val meg lehet oldani, hogy egy attribútum értékének csak az elejének egy része ismert, és a szelekció azokat a rekordokat adja vissza, amik az adott attribútumban így kezdődnek? Az is elég, segítség lenne, ha valaki megmondaná milyen kulcsszavakkal érdemes ilyen probléma esetén keresni. Ilyenekkel próbáltam, hogy:
- jpa select partial attribute
- jpa select by partially known attributede nem találtam semmi használhatót.
erre már meg magam is tudom a megoldást. köszönöm a lehetőséget, itt mindig megvilágosodok
-
#39560925
törölt tag
JPA-val lehet olyat csinálni, hogy egy táblában úgy keresek ki rekordokat, hogy a szelekcióban 1 attribútum van, és annak az értékének csak egy része ismert? Mondjuk adott egy városnév egy része, pl 'bud', és minden rekordot szeretnék megkapni, ahol a városnévben van olyan rész, hogy 'bud'. Próbáltam rákeresni neten, de angolul nem tudtam a megfelelő kulcsszavakat kitalálni ehhez.
Persze meg lehetne úgy oldani, hogy minden rekordot kiolvasok, és végigiterálva a listán megnézem, hogy mire illeszkedik ez a feltétel, de ha a JPA-ban lenne ilyen, akkor az biztos erőforrástakarékosabb megoldás lenne.
Mondjuk ahhoz, hogy ez működjön, minden adatbázisrekordot be kell olvasni ígyis-úgyis, szóval háttértár műveleteken a JPA-s megoldás sem tudna spórolni, a memóriaműveletek költsége meg ehhez képest elenyésző.
Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?
"Hogyan csinálják pl IMDB-nél azt, hogy beírom egy film címének egy részét, és kvázi azonnal mutatja azt a szövegrészletet tartalmazó filmcímek listáját? IMDB-t használnak (In Memory Database)?"
Most direkt kipróbáltam. Trükkösek, ez csak akkor működik, ha a filmcím első két szavából kezdem el valamelyiket gépelni.
Módosítom a kérdésem: JPA-val meg lehet oldani, hogy egy attribútum értékének csak az elejének egy része ismert, és a szelekció azokat a rekordokat adja vissza, amik az adott attribútumban így kezdődnek? Az is elég, segítség lenne, ha valaki megmondaná milyen kulcsszavakkal érdemes ilyen probléma esetén keresni. Ilyenekkel próbáltam, hogy:
- jpa select partial attribute
- jpa select by partially known attributede nem találtam semmi használhatót.
-
Aethelstone
addikt
Csatlakozom. Ha ugyanazzal az energiával lehet jót csinálni, akkor miért csinálnánk rosszat?









![;]](http://cdn.rios.hu/dl/s/v1.gif)



























Új hozzászólás Aktív témák
-
Fórumok
LOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokMobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)
A topicot kiemeltem. Valaki nem akar egy nyitó hsz-t írni?:))
- iPhone 15 Pro 128GB 87% (1év Garancia)
- Lenovo IdeaPad Slim 3 15 Intel Core 7 240H 16GB DDR5 RAM Sötétkék Hosszú GARANCIÁS!
- BESZÁMÍTÁS! ASRock H510M i5 11400F 32GB DDR4 1TB SSD RTX 3060 12GB Mars Gaming fekete Aerocool 650W
- HP ElitBook 840 G10 netbook / 12 hónap jótállás
- ÚJ - MACBOOK PRO 16" M5 MAX 18C CPU / 32C GPU / 36 GB RAM / 2TB + 3 ÉV APPLE Care PLUS + ÁFÁ-s
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest