Hirdetés
- Asszociációs játék. :)
- Fűzzük össze a szavakat :)
- "A homoszexualitás természetellenes" 😠
- Segway-Ninebot Kickscooter Max G30E II elektromos roller
- A gyerekem "tartalmat gyárt". Mit tegyek?
- Szólánc.
- eBay-es kütyük kis pénzért
- Nagy "hülyétkapokazapróktól" topik
- Android másképp: Lineage OS és társai
- Öregszem
-

LOGOUT.hu
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#60301
 Thrawn
félisten
TESCO-Zsömle
#60298
Thrawn
félisten
TESCO-Zsömle
#60298
Thrawn
félisten
válasz
 TESCO-Zsömle
#60298
üzenetére
TESCO-Zsömle
#60298
üzenetére
Elírás, jó lesz az 3600 MHz-nek is.
Different songs for different moods. łłł DIII Thrawn#2856 łłł Look! More hidden footprints! łłł D4BAD łłł WoT: s_thrawn łłł
-

Pakmara
őstag
válasz
 Yutani
#60302
üzenetére
Yutani
#60302
üzenetére
Oké up to. Nekem személy szerint nem ez a bajom. Hanem hogy kijön a 7900 xtx egy adott power limittel. De nem azzal mérik, hanem visszaveszik és úgy hasonlítják. Értem, hogy így 300 W vs.300 W van, de mennyiből tart volna 6900 XT fps-e /300 W vs 7900 xtx fps-e / 355 W-al számolni. Szvsz nincs olyan kartya a piacon sok sok éve amiből ne lehetne jobb perf/w-ot kihozni azzal hogy csökkented a power limitjét.
-
#60304
 Petykemano
veterán
Pakmara
#60303
Petykemano
veterán
Pakmara
#60303
Petykemano
veterán
válasz
 Pakmara
#60303
üzenetére
Pakmara
#60303
üzenetére
Nekem az a bajom, hogy úgy reklámozzák a kártyát, hogy
+54% perf/w és +60-70% (bocs, nem tudom fejből, hogy mennyi)
Viszont a kettőből valójában egyszerre csak az egyik igaz.300W vs 300W mérés esetén lehet, hogy igaz a +54% perf/w, de az csupán +54% teljesítményt is jelent.
Ezzel nem lenne gond, de ők +60-70% teljesítményre akarták árazni a kártyát, nem +54%-ra és a +60-70% teljesítménynövekedésért beáldozták a +54%perf/w mutatót. Ennek ellenére viszont továbbra is kinn van ez a mutató a kirakatban.Találgatunk, aztán majd úgyis kiderül..
-
#60305
Pakmara
őstag
Petykemano
#60304
Pakmara
őstag
válasz
 Petykemano
#60304
üzenetére
Petykemano
#60304
üzenetére
Igen, pontosan így. De az alap mondás (+54%) már nagyon sántít. Fogyasztás: 7 l/100km, de reklámozzuk 3 l-essel mert van egy 10 km-es lejtő, lemértük hatszélben egy olyan példányon amiből kiszereltünk 300kg teszthez felesleges alkatrészt. (Mondjuk autentikus, végülis a fogyasztást is így mérik
 )
) -

PuMbA
titán
Nagyon rossz, hogy ennyire erőltetik a dolgot, miközben az összes VGA-nak a legjobb perf / watt közelében kéne gyárilag mennie
 Aki ért hozzá és akarja, az tuningol és kisajtol, aki meg nem ért hozzá annak meg pont ez lenne a legjobb, mert a kártya halkabb lenne, elég lenne egy kisebb tápegység stb.
Aki ért hozzá és akarja, az tuningol és kisajtol, aki meg nem ért hozzá annak meg pont ez lenne a legjobb, mert a kártya halkabb lenne, elég lenne egy kisebb tápegység stb.[ Szerkesztve ]
-
Pakmara
őstag
Ezzel is egyetértek user oldalról, de ne az legyen a marketing anyag alapja, hogy letelerem mérek egyet és tádám 54%. Aztán vissza és tádám ennyi fps. Out of box összenézik a két kártyát és megvan mennyit javult twljesítmény és mennyit perf/w alapon. Lehetne nézni 7900 xtx vs 6900 XT 250-280 W limit és el is olvadna az egyébként létező előny java.
Egyébként minden kártyámnál így csinálom én is. Nekem valahogy szimpatikusabb hasam a ütök minusz 5-10% teljesítményért 15-20%-al kisebb fogyi mint fordítva.
-

HSM
félisten
Nem nagyon tudok az utóbbi évekből perf/watt optimalizált felsőkategóriás kártyát.
Talán csak a sima 6800, ami az utóbbi évekből eszembe jut. Manapság akár CPU, akár GPU, sajnos az a divat, hogy a lehető legkisebb csipből próbálják kisajtolni a csodát, ez pedig fizikailag rossz perf/watt-ot fog okozni. Manapság nem az a tuning, hogy kihozol 30%-al nagyobb tempót a kütyüdből, éppen fordítva, gyárilag kihozzák többnyire a benne lévő potenciál ~90%-át, és az "OC" inkább a finomhangolás, hogy ne csak perf legyen, de perf/watt is. 
#60308 Pakmara : Megnéztem egyébként, a 6900XT hivatalos TBP-je 300W [link] , míg a 7900XTX-é 355W [link] , így a teljesen igazságos összehasonlítás nem nagyon lett volna kivitelezhető.
-
Pakmara
őstag
Igen eltér, de sztem ez nem probléma összehasonlításnál. Out of box össze kell nézni és ennyi. Kapott fps/ 300 w a 6900-nál, ugyanez a 7900-nal is fsp/355. Szerintem így fair perf/w-ot nézni. Ha manual belenyúlsz akkor a nagyobb alap kerettel rendelkező kártyának kedvezel akarmerre húzod is. 355-nél a 6900 az ellaposodó görbe miatt nem profitál annyit mint amennyivel magasabb a keret, 300-nál a 7900 megy a jellemzően jobb p/w-al kecsegtető irányba.
-
#60311
 Cyberboy42
senior tag
Pakmara
#60310
Cyberboy42
senior tag
Pakmara
#60310
Cyberboy42
senior tag
válasz
Pakmara
#60310
üzenetére
hát de ezaz, nem a relatív tekjesítményt akarjyk összehasonlítani. hanem a csipnek perf/watt mutatóját, azt meg bizony csak ugyanazon a teljesítményel lehhet. ez mindig így volt. az más kérdés hogy a játékosokat ez kevésbé érdekli.
...A teknős ezután pszichoanalitikusként kezeli az identitászavaros krokodilt...
-
#60312
Pakmara
őstag
Cyberboy42
#60311
Pakmara
őstag
válasz
 Cyberboy42
#60311
üzenetére
Cyberboy42
#60311
üzenetére
Csak ha kiveszed a dobozból akkor nem úgy működik, ez fals nekem. Persz, értem az okokat: így lehet szép nagy számot írni a reklam anyagokra. Az hogy hogyan jött ki meg keveseket mozgat. De oké elengedtem, nekem nem szimpi, másnak elmegy. Nem rugózok rajta
Ha már tesztkörnyezet tekergetése: egy olyan összehasonlítást tökre megnéznék, hogy mondjuk 250 W-tól 400 W-ig hogy alakulnak az fps-ek a két karinál. Ott jól látszana melyiknél hol a sweet point, ahhoz képest hol a gyári beállítás és a különböző szintekhez milyen fps társul.
-
#60313
 Alogonomus
őstag
Alogonomus
őstag
Alogonomus
őstag
A helyzet ugyanaz, mint a GDDR6 vs. GDDR6X esetén volt. A Micron azzal reklámozta a termékét, hogy 14 Gbps esetén 15 %-kal takarékosabb. Ez valószínűleg igaz is volt, viszont sem a GDDR6, sem a GDDR6X nem 14 Gbps szinten került felhasználásra a termékekben. A valós felhasználás esetén pedig a GDDR6X többet fogyasztott, viszont gyorsabb is volt a GDDR6-hoz képest.
-
#60314
 Raggie
őstag
Cyberboy42
#60311
Raggie
őstag
Cyberboy42
#60311
Raggie
őstag
válasz
Cyberboy42
#60311
üzenetére
Nem teljesen értem amit írsz...
A relatív teljesítmény, az gyakorlatilag ugyan az, mint a performance/watt, amit meg bármilyen fogyasztás mellett lehet mérni nem csak azonos fogyasztás mellett. Pontosan ezért van benne az osztó részen a watt...
Szerintem is az lett volna a korrekt, hogy ha a kiadott kártyák out of the box performance értékeit és fogyasztási értékeit véve hasonlítják össze.
Még így is bőven lett volna elég módjuk a trükközésre, pl. RTX-es címeket venni bele, ahol a 6900-nak a teljesítménye jobban megsínyli mint az új gen, stb...Clint Eastwood FTW
-
[AMD Radeon RX 7900 XTX & 7900 XT GPUs See Up To 19% Price Cuts In China, Now Below MSRP]
A XTX nem sokat esett sajnos, de a 7900XT átszámolva 790 dollár. Ugyan ez az Nvidia kártyáinál is. a 4080 és a 4070 Ti is MSRP alatt kever ,a 4070 Ti is olcsóbb lett.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

bjasq99
kezdő
Abu egy kérdés:
Idézet tőled: "És GPU-król lévén szó az L2 cache hit eléggé fos. Jellemzően 5% alatti, és ha mondjuk sokszorosára növeled az L2-t, akkor is 10-15% alatt marad"
Ezzel szemben Chips and Cheese mérési eredményei RDNA 2 esetében, valós játékokat tesztelve:
Cyberpunk 2077, RT On:
DispatchRays call: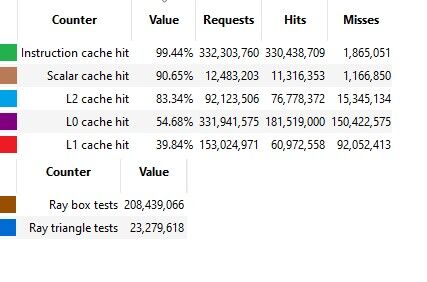
Vagy pl:
The longest duration compute call (number 4473):
És egy csomó más esetben is a mérési eredmény az, hogy sokkal sokkal magasabb a shared cache hit rate az általad felvázalthoz képest.
Akit érdekel a cikk: https://chipsandcheese.com/2023/02/19/amds-rdna-2-shooting-for-the-top/
Szóval, hogy is van ez?
Szerintem egyik gyártó sem olyan amatőr, hogy olyan rossz cache policyt tervez aminek csupán 5% alatti lenne a hit rate -je.
[ Szerkesztve ]
-
válasz
 bjasq99
#60317
üzenetére
bjasq99
#60317
üzenetére
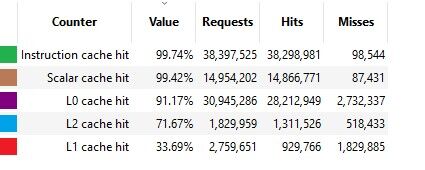
ah ez egy remek cikk ,nagyon köszi!
Igazi kincs ez az oldal, végre!
Nagyon érdekes hogy a CPU nál a a találati arány az L0+ L1 esetén kifejezetten magas, ,GPU nál extra alacsony 25 % körüli és az L2 ben pedig több mint 90 % ra emelkedik, ... tehát pont a nagy L2 az ami a hitrate javarészét lehozza.
ami még nagyon érdekes hogy nehezményezi a cikkiről hogy a magasztalt AMD a profilozó nem enged betekintést az Infinity cache működésébe, nem tudnak kiolvasni belőle adatokat.[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-
PuMbA
titán
válasz
bjasq99
#60317
üzenetére
Ez az oldal nagyon baró, mert sok NVIDIA infó is van az AMD mellett és így van architektúra összehasonítás
"AMD and Nvidia thus make different tradeoffs to reach the same performance level. A chiplet setup helps AMD use less die area in a leading process node than Nvidia, by putting their cache and memory controllers on separate 6 nm dies. In exchange, AMD has to pay for a more expensive packaging solution, because plain on-package traces would do poorly at handling the high bandwidth requirements of a GPU.
Nvidia puts everything on a single larger die on a cutting edge 4 nm node. That leaves the 4080 with less VRAM bandwidth and less cache than the 7900 XTX. Their transistor density is technically lower than AMD’s, but that’s because Nvidia’s higher SM count means they have more control logic compared to register files and FMA units. Fewer execution units per SM means Ada Lovelace will have an easier time keeping those execution units fed. Nvidia also has an advantage with their simpler cache hierarchy, which still provides a decent amount of caching capacity."
[ Szerkesztve ]
-
És igen!! itt [link]a magyarázat arra amit írtam már régebben hogy az Ada javított az alacsony felbontáson a CPU limiten.
Mindegy ezt nem ide kellene hanem az Nvidiásba, bocs.
"AD102’s L2 cache implementation is dramatically improved over GA102’s. Obviously, it tackles the memory bandwidth problem by increasing L2 cache capacity, almost to AMD Infinity Cache levels. The amazing part is that Nvidia has done this while also improving L2 cache performance compared to GA102. AD102’s L2 has more bandwidth, allowing it to feed the additional compute capacity. It has reduced latency, making it easier to utilize the available bandwidth. Better L2 latency indirectly reduces VRAM latency as well, because a significant portion of VRAM access latency is just moving data across the GPU die. Ada Lovelace does that faster. And of course, AD102 should have to hit VRAM less often than GA102.Beyond global memory subsystem changes, Ada Lovelace also improves local memory latency. Compute throughput at low occupancy takes a step forward compared to Ampere too, thanks to much higher clock speeds. Clock speed increases may be boring, but higher clock speeds are a very good way of scaling performance, and mean that just about everything you can do on Ampere can be done a bit faster on Ada Lovelace.
All of changes come together to make Ada Lovelace a formidable architecture, even if we put aside the headline grabbing raytracing related features. Nvidia’s new architecture improves performance at low occupancy, eroding one of RDNA 2’s key advantages over GA102. At high occupancy, Ampere was already very strong. Ada Lovelace extends that strength, and towers over RDNA 2. AMD has their work cut out for them if they want RDNA 3 to be competitive, even in pure rasterization workloads. We look forward to seeing what AMD’s next architecture will bring.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
-

Abu85
HÁZIGAZDA
válasz
bjasq99
#60317
üzenetére
Mert csak kiemel hívásokat, de nem csak ennyi a grafikai feldolgozás. Az L2 legnagyobb terhelői a ROP-ok, mert azok az L2 kliensei a modern GPU-dizájnokban (a Maxwell és a Vega óta). A legnagyobb L2 terhelés is innen érkezik, hiszen messze ezek mennek a legnagyobb adamennyiségért a memóriába. Az persze tök jó, hogy a kb. 8 kB-os memóriaigényű shaderek jó hitet érnek el az L2-ben, de a ROP-ok már nagyon nem, és ezek felelnek az L2 adatmásolások legalább 98%-áért. Ezért épített az AMD Infinity Cache-t a lapkákba akár 100 MB-ot, mert az egyszámjegyű megabájtos L2-t teljesen kiheréli a ROP. Alig van cache hit benne a lapok cseréjével. De ez így normális, egyszerűen túl sok adat mozog túl aprócska gyorsítótárban.
#60318 b. : Az Infinity Cache csak egy védőháló, ami felfogja a kidobott L2 lapokat, amelyek kellhetnek még a ROP-nak. Ezt nem lehet program oldaláról befolyásolni, így értelmetlen lenne láthatóvá tenni. De van egy kulcs hozzá, ami megmutatja, csak ahhoz nem elég developer módba kapcsolni a drivert. Szükséges a support mód is, azt meg csak a kiemelt fejlesztők kapják meg.
#60320 b. : A CPU-limiten az tudna javítani, ha nem emulálná a bindlesst az NV driver. Ez egy szoftveres probléma, nem hardveres. Amikor kidobják az összes hardver támogatását az Ampere-ig, akkor át tudják írni a drivert bindlessre, de ehhez előbb meg kell szüntetni a Maxwell, a Pascal és a Turing terméktámogatását.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-

Raymond
félisten
Csak roviden hogy megerts:
5% vagy 15% kozotti cache hit rate mellet a gyartok nem raknanak cache-t a termekekbe. Irtal egy ordatlan nagy marhasagot megint es ezzel az elso bekezdessel amivel probalod elmagyarazni csak rontasz a helyzeten mert ez igy teljesen ertelmetlen.
Hagy a fenebe inkabb az egeszet aztan par honap mulv csak elfelejtik az emberek.
Privat velemeny - keretik nem megkovezni...
-
-

GeryFlash
veterán
Csak ismetelni tudom azt, amit az elottem levo 2 kollega kerdezet, szoval ha mindez igaz amit irsz akkor,
1.) Miert latunk jobb/javulo teljesitmenyt NV-nel kis felbontason, es mi ez ha nem csokkeno CPU limit
2.) Minek raknanak bele cache-t ha utana ennyire szar lenne a hit arany.Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
bjasq99
kezdő
válasz
 GeryFlash
#60324
üzenetére
GeryFlash
#60324
üzenetére
Bocsi csak lehetséges magyarázatok miért gyorsul Nv kisebb felbontáson:
1. ami le volt írva chips and cheeseben is, hogy javították kis terheltség esetén a hardver kihasználtságát.
2. szerintem nem lehet semmit sem úgy elképzelni, hogy valami homogén cpu limites. Egy Cpu limites folyamatról azt tudjuk, hogy nagyobb részben a Cpu határozza meg a teljesítményt, de nem tudjuk, hogy milyen arányban. Lehet pl 60% ban vagy 90% ban, mindegy is csak azt akarom mondani, hogy ettől a fentmaradó rész egy gyorsabb gpu -tól fog gyorsulni, s így a "pure cpu limites" résznek is több ideje marad.
Nyilván az nagyon nem mindegy milyen arányban vannak ezek. -
bjasq99
kezdő
Azt akarom leszögezni, hogy az Abu által felvázolt driveres Nv működésből fakadó hátrány igaz (lsd HUB). És mindenki figyelmébe ajánlom aki elolvasta chips and cheesen a Nv hardver elönyeit, hogy olvassa el a scalar datapath -ról való értekezést amiben egyértelműen Jensen bácsiék használnak sokkal primitívebb megoldást.
És nyilván tudnak Cpu limites feladatokban is gyorsulni, (amint előző hozzászólásomban leírtam, de ennek meg van a felső korlátja, az igazi a driveres "nem issue" kigyomlálása lenne. -
bjasq99
kezdő
Bocs úgy emlékszem, hogy abban a cikkben amit linkeltél nincsenek játék tesztek, csak egyéb mérések, amik nem feltétlen reprezentatívak játékok során mért hitrate -re. Ami reprezentatív az a cikk amit legutóbb hoztam és valós játékokban mért hitrate. És, Abu szerintem nem jó az érvelésed,, hogy pár kb os shaderek hitratejeként emlegeted, de ez nem számit, az számít, hogy az adott shader milyen arányban fordul elő a feldolgozásban. Mint vizsgálták azok a shaderek a feldolgozás döntő részét képviselték, hiába, hogy kicsikék. Igen és vannak olyan feladatok amelyek sokkal nagyobb memória téren garázdálkodnak, de még sem ők a döntő többségük. Pl a raytracinges CP mérés: 21 ms frametime ból 7 ms vett el a vizsgált shader 82 % -os L2 hitrate -el. A 7 harmada a 21 nek tehát ha feltételezük, hogy a fame generálás többi folyamatában 0% os a cache hitrate (ami örületesen nagy túlzás csak a szemléltetés miatt) akkor is marad 82/3 = 27.3 % hitrate a teljes frame esetében, remélem lehet követni.
-
#60332
Petykemano
veterán
b.
#60315
Petykemano
veterán
csorog lefelé
nemrég még csak $40-ral volt msrp alatt.
Persze kérdés, hogy ez mennyire lesz tartós.Én azt látom pl az RDNA2 árakon, hogy annak ellenére, hogy a forint árfolyama javulgatott, az elmúlt hetekben az RDNA2 árak emelkedtek.
Találgatunk, aztán majd úgyis kiderül..
-
#60333
 DudeHUN
senior tag
Petykemano
#60332
DudeHUN
senior tag
Petykemano
#60332
DudeHUN
senior tag
válasz
Petykemano
#60332
üzenetére
Mindig lassabban követi le a kiskereskedelmi rész a változásokat. Tehát ha hullámzik az árfolyam, akkor azt később érzékeljük.
Gamer for Life
-
#60334
PuMbA
titán
Petykemano
#60332
PuMbA
titán
válasz
Petykemano
#60332
üzenetére
A használt árak viszont kiválóak. 90k körül 6600XT. 130k körül 6700XT. Amennyiért vettem a 3060-at, azért most már 6700XT-t lehet kapni. A 3060 ára viszont nem változott a 120k körüliről, most is ugyanannyiért el tudnám adni
Eladásnál mindig jobb egy NVIDIA kártya, de vételnél az AMD nagyon jó, mert ők a kisebb hal.[ Szerkesztve ]
-
#60335
GeryFlash
veterán
Petykemano
#60332
GeryFlash
veterán
válasz
Petykemano
#60332
üzenetére
Nekem nagyon furcsa hogy a current genek ara megy le mikozben az AMD-nel halomban allnak az eladhatalan felsokozep-felso kategorias RDNA2-k, es azert RTX3000-bol is van meg boven, es egyik ceg sem tori magat hogy arat csokkentsen, inkabb a current gen lesz meginkabb megerosebb. Jo pelda erre a 4070 vs 3090/3090Ti arai. Erthetetlen.
Hi, i'm new to APHEX TWIN, so i was wondering how much the IQ requirements was to enjoy his stuff. and understand all the underlying themes, because its really complex stuff. I have IQ of 119 but i heard that you need atleast 120 is it true?
-
Abu85
HÁZIGAZDA
válasz
 Raymond
#60322
üzenetére
Raymond
#60322
üzenetére
Én meg hosszabban, hogy érthető legyen. A GPU egy heterogén multiprocesszor. Van egy rakás különböző féle-fajta részegység benne, amelyek írják/olvassák a megosztott L2-t. Compute shader esetén viszonylat sok értelme van az L2 cache-nek, mert elég jó hit rate érhető el. Akár sugárkövetésnél is van értelme az elsődleges sugaraknál, mert azok koherensek. Másodlagos sugaraknál már ez megszűnik, így ott már az L2 cache nem igazán ér semmit. A BVH esetében is van némi értelme. Ezek mind olyan feladatok, amelyekben elég nagy hit rate érhető el. De vannak emellett olyan feladatok is, amelyekben nem olyan jó. Persze a tile-alapú leképezés segít, de valójában a ROP blokkok egy rakás gyorsítótársorral dolgoznak. Ezek egy része az L2-be kerül, de ugye ennek kapacitása véges, így idővel a VRAM-ig kell menni. Ebből a szempontból az L2 sosem volt jó, mert nagyon alacsony a hit rate. Ezért van a GPU-kon olyan brutál széles busz, meg gyors memória, mert ezt az alacsony hit rate-et kompenzáljuk vele. A másik opciója ennek ugye az Infinity Cache, ami védőhálóként felfogja az L2-ből helyhiány miatt kidobált gyorsítótársorokat, és esélyes, hogy a ROP blokk megtalálja őket az Infinity Cache-ben, nem kell elmenni a VRAM-ig. De ehhez elég nagy gyorsítótár kell még, és teszem azt 128 MB-nyi gyorsítótárral is csak 50% körül van a hit rate a Navi 21 esetében 4K-s felbontáson. Képzeld el azt a szegényke 4 MB-os L2-t. Ilyenre szintén volt az AMD-nek anno mérése, és 8 MB-os cache esetében van 10% környékén a hit rate. Persze a cache felépítése is fontos, például az RDNA 3 jobban használja az Infinity Cache-t, de itt nem drámai a különbség. Az AMD szerint nagyjából olyan hit rate van 96 MB-os IC-vel a Navi 31-en, amilyen 128 MB-os IC-vel a Navi 21-en. Tehát a strukturális háttér fontos, de annak javítása nem okoz drámai előnyt, azt az extra kapacitás hozza.
#60324 GeryFlash :
1) Az NV-nek ez a CPU-limites dolga egy nagyon specifikus tényező. Nem minden játékot érint, mert bizonyos dolgok szükségesek ahhoz, hogy előjöjjön. Például az, hogy a Microsoft és ne az NV ajánlásait kövesse egy fejlesztő a D3D12 leképező írásakor. Mert ugyan a D3D12-ben mindkét cég utazik, de több helyen homlokegyenest ellenkező dolgot ajánlanak.
2) Azért raknak bele több cache-t, mert heterogén multiprocesszorok a GPU-k. Attól, hogy a ROP-ok hit rate-je nem túl jó, még a compute feladatoké jellemzően az. Csak ugye egy játékban döntő tényező a ROP, tehát ez rontja a működést.[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
#60337
Petykemano
veterán
GeryFlash
#60335
Petykemano
veterán
válasz
GeryFlash
#60335
üzenetére
Pontosítanék:
Az (engem leginkább érdeklő) RX 6600 ára nem nagyon akar csökkenni, hovatovább visszaemelkedett. Nemrég lehetett kapni 105-110 között, ma már inkább 115-120.
Az RX 6650XT ára csúszogat lefelé. Ma már lehet kapni 130 táján is. Tulajdonképpen azt lehet mondani, hogy csúszik egybe az RX 6600 és a 6650 ára, ami valami olyasmire enged következtetni, hogy vagy nincs már RX 6600-nak való chip ("túl jó" kihozatal), vagy egyre kevsébé meghatorozó a végtermék árában a chip ára.
Hovatovább 135-140-ért lehet már kapni RX 6700-at is.Tehát úgy tűnik, hogy a az árak azért csorognak lefelé, de a alacsonyabb árú termékek nem mennek egy bizonyos összeg alá.
Találgatunk, aztán majd úgyis kiderül..
-
#60339
 bitblueduck
senior tag
Abu85
#60336
bitblueduck
senior tag
Abu85
#60336
bitblueduck
senior tag
-
#60340
Abu85
HÁZIGAZDA
bitblueduck
#60339
Abu85
HÁZIGAZDA
válasz
 bitblueduck
#60339
üzenetére
bitblueduck
#60339
üzenetére
Drága. Bonyolult NYÁK kell hozzá, és az árnyékolása sem egyszerű ezekkel a gyors memóriákkal. Amúgy nyilván mérnökileg kivitelezhető, de ha van hova menekülni előle, akkor inkább menekülnek a gyártók egy másik megoldás irányába.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
HSM
félisten
válasz
bjasq99
#60317
üzenetére
Érdekes cikk volt, köszi a hivatkozást.
#60322 Raymond : Pedig az AMD által közzétett adatok is őt támasztják alá: 10MB nagyságrendű cache-nél alig van hit-rate [link] . Persze, jó lenne látni, pontosan milyen helyzetekről is van szó, de a footnote kb. csak annyit mond, hogy a modelljeik alapján.
#60332 Petykemano : Alakul, ahogy várható volt. Kezdenek szimpatikus ársávba kerülni az AIB kártyák.
-
#60342
 S_x96x_S
addikt
Petykemano
#60338
S_x96x_S
addikt
Petykemano
#60338
S_x96x_S
addikt
válasz
Petykemano
#60338
üzenetére
> Azért sajnálatos, hogy a V-cache (infinity cache bővítés)
> nem járt hasonló kellemes (mellék)hatással, mint a CPU esetén.Itt ( GPU ) nem lehet olyan könnyen megállapítani
Mert van-e V-cache nélküli - minden másban megegyező GPU? - amivel korrekten benchmarkolni lehetne?
Vagy van-e olyan lehetőség, amivel le lehet tiltani a 3D-Vcache-t a GPU-ból?
( lehet, hogy van, akkor remélem, hogy valaki jelzi ..)[ Szerkesztve ]
Mottó: "A verseny jó!"
-
bjasq99
kezdő
Na akkor kifejtem mert úgy látom elég nagy még a zavar, szóval olvassátok el következő írásaim, s talán akkor világosabb lesz.
1. #60341 HSM, és mindenki aki nem érti, hogy hogyan lehet összhangban a Chips and Cheese mérése az Amd slide -jával ami az Infinity Cache hitrate -t elemzi. Látszólag nagy az ellentmondás mert a néhány 10 Mb -os cachre az Amd prezije kis hitrate -t mutat, míg chips and cheese mérései arról tanúskodnak, hogy a kisebb L2 cache -nek is milyen jó a hitrateje. Ebben azonban NINCS!!! semmilyen ellentmondás, mert a hitrate a hit/request aránya. Nos az infinity cache -be csak olyan requestek érkeznek amelyek nem voltak benne az L2 cache be. Magyarán ezek azok a requestek amelyek már rosszabb hatásfokkal cachelhetők. Tehát nem szabad az L2 Cache -be és az Infinitiy Cache be érkező requesteket összekeverni, nyilván ha nem lenne L2 akkor a 10 Mb -os Infinity cache is baromi jó hitrate -el rendelkezne.
De ha nekem nem is hisztek akkor chips and cheese mérés:
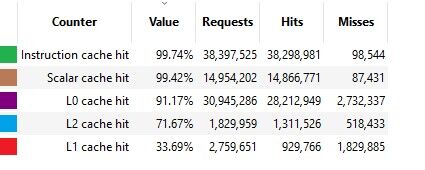
Azt kell figyelni, hogy a kisebb (igaz nem osztott) L0 cache mennyivel jobb hitrate -t generál mint a nagyobb L1, de ez nincs ellentmondásban, hisz nyilván L1 ből már csak az jön ami L0 nincs benne. Nézzétek a request számot is. -
Abu85
HÁZIGAZDA
válasz
bjasq99
#60343
üzenetére
Ennél egy kicsit bonyolultabb. Például az AMD specifikusan ment bizonyos adatokat. Az L0 elsődleges feladata a textúrázók és az RT egységek kiszolgálása, és emiatt elég jó lesz a hit rate, mert jellemzően jól cache-selhető koherens adatelérésekről van szó. Az L1 cache már jóval univerzálisabb, az már számos olyan munkafolyamatra is vonatkozik, ami nem jól cache-selhető. Ezen túlmenően sok adat közvetlenül az L2-be lesz kiírva a multiprocesszorból. Tehát az L1 cache rossz hit rate-je attól van, hogy olyan adatok kerülnek bele a mögötte lévő memóriákból beolvasva, amivel nem mindig lehet jó hit rate-et elérni.
Az L2-nél sok múlik azon, hogy az AMD mennyire épít az IC-re. Mert amíg régebben muszáj volt ebből kiszolgálni a ROP-ot, addig manapság már építhetnek arra, hogy van egy védőhálójuk, ami ugyis felfogja a szükséges gyorsítótársorok egy részét, tehát nem muszáj az L2 cache nagy részét rosszul cache-elhető ROP műveletekre használni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
-
HSM
félisten
válasz
bjasq99
#60343
üzenetére
GPU cache-ről beszél a dia, nem IC-ről, vagy legalábbis nem egyértelmű.
Egyébként tisztában vagyok a cache rendszerek működésével, de szerintem az is nyilvánvaló, hogy ha ennyire jól cache-elhő lenne egy GPU, akkor nem kellene alá TB/s nagyságrendű memória sávszélesség... Sajnos nem vagyok kellően naprakész GPU-architektúrákból, pontosan milyen adatokért nyúlkál a különböző cache-ekbe, melyik részegység mekkora méretű adatokon dolgozik, azok mennyire cache-elhetőek, de biztos vagyok benne, hogy ez egy komplex és messzire vezető témakör.
Azért mindenesetre felraktam ezt a profilert, ha lesz kis időm belekukkantok majd mivel szorgoskodik a 6800XT-m.
Szerintem van még itten felfedezni-való. 
-
#60348
Petykemano
veterán
Petykemano
#60332
Petykemano
veterán
válasz
Petykemano
#60332
üzenetére
7900XT: $799
[link]Ez a lefelé csorgó ár nem csak azért örvendetes, mert maga a 7900XT ára a 7900XTX-hez.viszonyítva rendeződik. (Szerintem mindkettő mehetne még lejjebb.)
Hanem azért is, mert egyúttal az alatta helyet foglaló navi32 és navi33 várható árazását is tolja maga alatt lefelé. Remélhetőleg.
Találgatunk, aztán majd úgyis kiderül..
-
#60350
Alogonomus
őstag
Alogonomus
őstag
Elkezdődött végre az árháború.
Sőt még csak nem is egy sima referencia kártya ára csökkent $800-ra. Hamarosan kiderül, hogy a 4070 Ti és 4080 árában eredetileg mennyi tartalékot hagytak, mert alighanem válaszolnia kell erre a konkurenciának is árengedménnyel.




![;]](http://cdn.rios.hu/dl/s/v1.gif)




 )
)


 Aki ért hozzá és akarja, az tuningol és kisajtol, aki meg nem ért hozzá annak meg pont ez lenne a legjobb, mert a kártya halkabb lenne, elég lenne egy kisebb tápegység stb.
Aki ért hozzá és akarja, az tuningol és kisajtol, aki meg nem ért hozzá annak meg pont ez lenne a legjobb, mert a kártya halkabb lenne, elég lenne egy kisebb tápegység stb.




























Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

Állásajánlatok

Cég: HC Pointer Kft.
Város: Pécs

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest