








A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!
Gyorskeresés
Legfrissebb anyagok
- Bemutató Spyra: akkus, nagynyomású, automata vízipuska
- Bemutató Route 66 Chicagotól Los Angelesig 2. rész
- Helyszíni riport Alfa Giulia Q-val a Balaton Park Circiut-en
- Bemutató A használt VGA piac kincsei - Július I
- Bemutató Bakancslista: Route 66 Chicagotól Los Angelesig
Általános témák
LOGOUT.hu témák
- [Re:] [D1Rect:] Nagy "hülyétkapokazapróktól" topik
- [Re:] [bitpork:] 2024 phautós tali ?
- [Re:] [bb0t:] Gyilkos szénhidrátok, avagy hogyan fogytam önsanyargatás nélkül 16 kg-ot
- [Re:] [Luck Dragon:] Asszociációs játék. :)
- [Re:] [attilasd:] A laposföld elmebaj: Vissza a jövőbe!
- [Re:] [sziku69:] Fűzzük össze a szavakat :)
- [Re:] [Mr Dini:] Hálózati problémából kiber-versenyfeladat!
- [Re:] [Parci:] Milyen mosógépet vegyek?
- [Re:] [sziku69:] Szólánc.
- [Re:] [antikomcsi:] Való Világ: A piszkos 12 - VV12 - Való Világ 12
Szakmai témák
PROHARDVER! témák
Mobilarena témák
IT café témák
Téma összefoglaló
Hozzászólások

Abu85
HÁZIGAZDA
Igazából a chiplet mindenképpen kell mindenkinek. Aki top GPU-ban gondolkodik, muszáj chiplettel összeraknia. Már nincs választási lehetőség 3 nm-en és alatta. Az 4/5 nm volt az utolsó node, ahol tervezhető volt relatíve nagy kiterjedésű lapka. Ma még ez választás kérdése volt, holnap már kötelező a chiplet.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

S_x96x_S
őstag
> Az a baj, hogy az AMD az alsó és közép kategóriában akar versenyezni,
inkább az AI-ban akar versenyezni az AMD.
az MI300 versenytárs az nVidia H100 ~ $35.000 - $45.000 -ért kapható.
és nem csak egy kell belőle ..
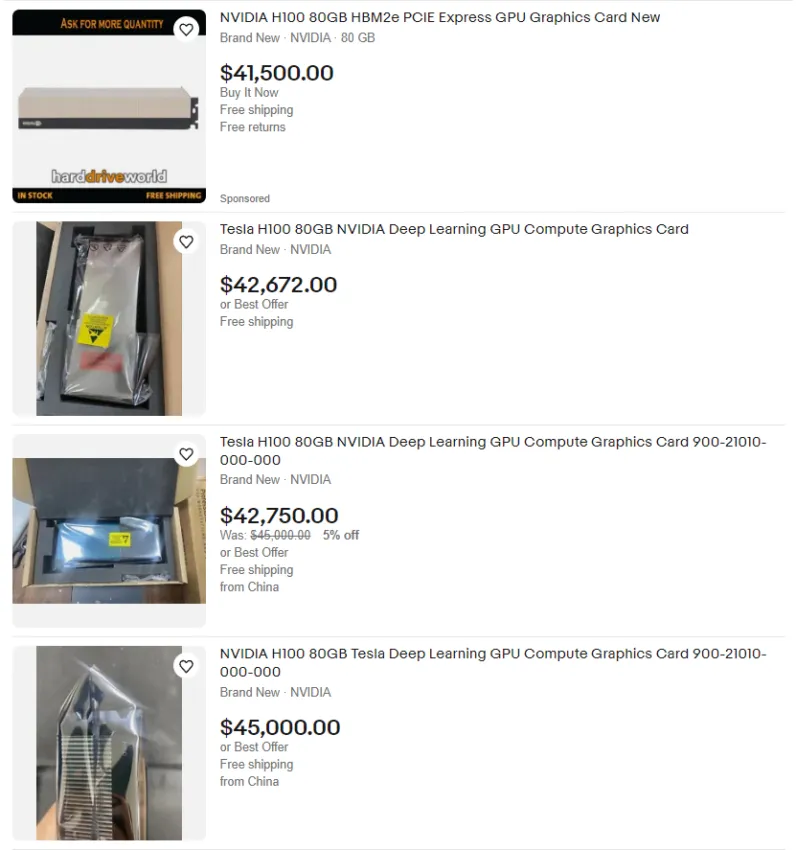
és ha jól értem,
MI300 -ból már több pénz vár az AMD mint EPYC-ből. 

Mottó: "A verseny jó!"
Abu85
HÁZIGAZDA
Igen, de az AMD azért vár ettől többet, mert az MI300 az nem csak gyorsító, hanem APU. És egy csomó cég számára sokkal egyszerűbb lesz EPYC+gyorsító helyett MI300-at rendelni, tehát nem is kell majd gyorsítóban gondolkodniuk. Így könnyű több pénzt várni az EPYC-hez viszonyítva, mert a MI300 nem csak gyorsító.
A MI300X pedig azért kapós, mert van rajta 192 GB memória. Egyszerűen baromira megéri ugrani rá bármiről, mert ennyi memóriával sokkal olcsóbb lehet az üzemeltetés. De ez ugyanúgy áll majd mindenre, ha az NV hoz valamit mondjuk 384 GB memóriával, akkor arra is ugrik majd mindenki, és ha az AMD hoz valamit 512 GB-tal, akkor arra is. Minden ilyen lépés csökkenti az üzemeltetési költségeket. Tehát egy hardverváltást záros határidőn belül ki lehet termelni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

Busterftw
veterán
Rick bacsi mondta, AMD EVP egy adott interju soran:
Es ugyan van 500-600W 4090 BIOS, de a legtobb 450W, jatek alatt pedig ennel is kevesebbet fogyaszt (TPU atlaga 420W), az UV potencial pedig remek. (itteni topikbol egy pelda)
"87% powerlimit, +120mhz, igy 3030, 3045 mhz ingame, 360w korul megall god of war kozben 4k 117 fps mellett."
Szoval cseppet sem ertem Rick bacsi hebegeset a 600W-rol.
Busterftw
veterán
Ezzel viszont az AMD azt kockaztatja, hogy csokken(het) az EPYC+gyorsito iranti kereslet, ha ezek a cegek kivaltjak ezt a kombot.
Arban igy mennyiben kulonbozik a dolog?


Csak ez ugye kapható, nvidia meg bejelenti most a H2000 at holnap a SIGGRAPH -on és egyéb dolgokat.[link]
Ha jól tudom a hardveres költség mellett a szoftveres háttér jobban számít a megrendelőknek.
Annyira nagyok a megrendelések, hogy egy növekvő piacon kell is a több versenyképes gyártó és termék szerintem.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
Abu85
HÁZIGAZDA
Árban drágább csak Instinct MI300A-t venni, mint EPYC+gyorsítót, viszont nem a hardver ára a lényeges a cégeknek, mert az valójában a teljes beruházási költség nem túl nagy része. Amiben erős az MI300A, az a jobb fogyasztás és AI-hoz sokkal jobban illő felépítés. Tehát a TCO-ban már gyorsan visszahozza a hardver az árát, és egy éves távon már az MI300A az olcsóbb. Tehát ha legalább egy évig megtartja a vásárló a hardvert, akkor jobban megéri MI300A-t venni, mint EPYC+gyorsítót.
Alapvetően ez az a két dolog, ami miatt most rácuppant a piac az MI300-ra. Az MI300X-nél a memóriakapacitás a kulcs, míg az MI300A-nál a TCO, meg az a tény, hogy APU-ról van szó.
#62256 b. : Nyilván az MI300A nagy előnye, hogy nem kell átírni a szoftvereket ARM-ra. De ez csak ideiglenes előny, idővel, teszem azt úgy 3-4 éves távon elvész. Az NV-nél a Grace+Hopper ennek az iránynak a nulladik generációja. Ez a bevezető, hogy elkezdődjenek a szoftveres munkálatok.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
ismerve Nvidiát komplett megoldást kínálnak és specifikus szoftvereket a rajtra.
Holnap kiderül.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
S_x96x_S
őstag
> Ha jól tudom a hardveres költség mellett a szoftveres háttér jobban számít a
> megrendelőknek.
azért pár dolog már most is működik. pl. PyTorch
és remélhetőleg az AMD még nagyobb fókuszt tesz a szoftverre ...
"""
With PyTorch 2.0 and ROCm 5.4+, LLM training works out of the box on AMD MI250 accelerators with zero code changes when running our LLM Foundry training stack.
Some highlights:
- LLM training was stable. With our highly deterministic LLM Foundry training stack, training an MPT-1B LLM model on AMD MI250 vs. NVIDIA A100 produced nearly identical loss curves when starting from the same checkpoint. We were even able to switch back and forth between AMD and NVIDIA in a single training run!
- Performance was competitive with our existing A100 systems. We profiled training throughput of MPT models from 1B to 13B parameters and found that the per-GPU throughput of MI250 was within 80% of the A100-40GB and within 73% of the A100-80GB. We expect this gap will close as AMD software improves.
- It all just works. No code changes were needed.

.png)
"""
https://www.mosaicml.com/blog/amd-mi250
[ Szerkesztve ]
Mottó: "A verseny jó!"
20-30% % azért elég jelentős lemaradás A váltáshoz ennél több kell, konkrétan jobbnak kellene lenni. A memórakapacitás viszont előny de a koherens megoldások erre tudnak nyújtani megoldást mindkét oldalon.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)

hahakocka
senior tag
7600 as nem igazi RDNA 3 kártya nem chipletes egy csomó dolog kiherélt benne kb egy 6670xt.
7900xt-7900xtx meg most majd az új karik (7700-7800) azok amik igazán számítanak szerintem RDNA3 kapcsán. Ott pedig 30W difi van meg, sokkal több ram (+8gb), olcsóbb ár, jó sokféle jó hűtés, jobb raszter, és 20% al rosszabb RT. 4090 től vannak igazán lemaradva de az akkora fizikailag túlzással mint Paks és fogyasztás sokszor 500W, dupla ár s így hoz 30-40% ot + nem egy kateg.
Ha bukó lesz a 7700-7800 azt viszont megfogják érezni Lisáék.
[ Szerkesztve ]
Busterftw
veterán
Az architektura RDNA3, az AMD RDNA3-kent hivatkozik ra, mirol beszelsz, hogy nem igazi RDN3 kartya? 


PuMbA
titán
RDNA3 kártya  Az, hogy a cache mérete kisebb, nem változtatja meg az architektúrát, sem a chiplet, hiszen ugyanazok az egységek vannak benne, csak fizikailag más helyen. A chiplet minimálisan még csökkenti is a teljesítményt, ezt kimérte a Chips and cheese, mert van egy felesleges interfészed, ami növeli a késleltetést.
Az, hogy a cache mérete kisebb, nem változtatja meg az architektúrát, sem a chiplet, hiszen ugyanazok az egységek vannak benne, csak fizikailag más helyen. A chiplet minimálisan még csökkenti is a teljesítményt, ezt kimérte a Chips and cheese, mert van egy felesleges interfészed, ami növeli a késleltetést.
[ Szerkesztve ]

HSM
félisten
3-3.5Ghz-el, és kicsit ügyesebb driverrel bőven ~40%-al erősebb lenne, ami a mostani CU-számmal is igencsak versenyképes lehetne.  Nem is elrugaszkodott szám ez, hiszen a jobb Navi21-ek már 7nm-en súrolták a 3Ghz-et.
Nem is elrugaszkodott szám ez, hiszen a jobb Navi21-ek már 7nm-en súrolták a 3Ghz-et.
Az is érdekes adalék, hogy a CU órajel tartománya el lett választva a GPU többi részéről. Ez utalhat arra is, hogy arra számítottak, hogy a CU-kat sikerült ezáltal magasabb órajelen járatni, de a gyakorlatban ez fordítva sült el, a 7900XTX gyári front-end órajele 2.5Ghz lett, míg a shader órajel csak 2.3Ghz.
Nagyon érdekes még amit itt írnak: [link] ("Frontend Clock Behavior" rész) . Jól látszik a grafikonon, hogy alacsony órajelen egyforma órajelen járatja a 7900 is a frontend/shader tömböt (itt hirtelen nem a frontend a limit?! ![;]](http://cdn.rios.hu/dl/s/v1.gif) ), de nagyobb órajelen "lemaradnak" a shaderek... A "hivatalos" magyarázat számomra kevéssé meggyőző, főleg shaderből implementált RT-vel.
), de nagyobb órajelen "lemaradnak" a shaderek... A "hivatalos" magyarázat számomra kevéssé meggyőző, főleg shaderből implementált RT-vel. 
#62233 b.: "Jensen több éve már azt mondta hogy 3 nm gyártás felett és megfelelő tokozás hiányában nem érdemes Chipletes GPU -ban gondolkodni. Igaza volt."
Persze, ő mindenki előtt látta, hogyan fog alakulni a kereslet/kínálat (=árazás) a modern gyártástechnológiákon. Ez is kevéssé hihető.  Sokkal inkább szerecséje volt, hogy igen hamar olcsó lett az 5nm, így az AMD nem tudta kihasználni a chipletezésből származó előnyöket a Navi31-32-nél, és így az Nv büntetlenül gyárthat ormótlan nagy 5nm GPU-kat, mint pl. a 4090-esé, 609 mm²-el. Volt, amikor nem jött be ez a taktika, abból lettek pl. a Fermi-s mémek, mint pl. ez a gyöngyszem: [link] .
Sokkal inkább szerecséje volt, hogy igen hamar olcsó lett az 5nm, így az AMD nem tudta kihasználni a chipletezésből származó előnyöket a Navi31-32-nél, és így az Nv büntetlenül gyárthat ormótlan nagy 5nm GPU-kat, mint pl. a 4090-esé, 609 mm²-el. Volt, amikor nem jött be ez a taktika, abból lettek pl. a Fermi-s mémek, mint pl. ez a gyöngyszem: [link] .
"Azt gondlom az Nvidia első chipletes GPu -i már rég tervező asztalon megszülettek"
Azért ide némi adalék, hogy míg a Navi31 esetén már a memória-alrendszer jelentős részét sikeresen leválasztották az L3-al együtt, addig Nv-nél az L2 növelésével éppen a GPU "növekedett" méginkább. Ez nem tűnik a chiplet felé való lépkedésnek... 
#62262 Busterftw : Jelentős butítást kapott, hiába RDNA3, nem kapta meg a nagyobb modellek másfélszer akkora regiszterét a CU, hanem maradt az RDNA2-es méretnél....
[ Szerkesztve ]

Yutani
nagyúr
A 7600 egy RDNA3 kártya, a Navi33 egy RDNA3 GPU. Pont.
#tarcsad
a világ legsikeresebb GPu gyártójaként nem láthatta gondolod?[link]
Szerencséjük volt? Az a óriás GPU energiahatékonyabb és olcsóbban gyártható minta 7900XTX :
Amúgy már a Volta a GV 100 ban is évekkel ezelött már speciális fabric interfészt használtak.
Abu cikke 2017 ből : [link]
Nvidia MCM : [link]
nekem kissér fura, alulról nézve felfele állítjátok be vesztesnek Nvidiát, elmaradottnak, és lúzernek a fejlesztések szintjén. Ilyenkor kicsit értetlenül állok, hogy ugyan abban a moziban ülünk e, mert szerintem nem.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
HSM
félisten
Nem állítottam be őket vesztesként. Csupán azt próbáltam kiemelni, hogy az érvelésed gyenge lábakon áll, hiszen nem tudhatta senki előre, hogyan fog alakulni az 5nm árazása. Így "vakon" bevállalni egy 600mm²-es csipet a megjelenésekor brutálisan drága 5nm-en minimum bátor húzás volt.
Illetve, amire utaltam még, hogy játékos felhasználású GPU-ból az AMD már lerakott az asztalra egy alapvetően igen jól működő, konkrét megvalósítást, míg az Nv Ada architektúrájában semmi nyoma, hogy akár csak elmozdultak volna MCM irányba.
Én nem írtam olyat hogy tudták az 5nm árazását sehol előre,de abban biztos lehetsz hogy mielött egy architektúrát el kezdenek fejleszteni egy gyártásra akkor már lekötik bizonyos feltételekkel az árazást. ( előrendelt mennyiség, kötbér, előleg befizetés stb) Én teljesen más területen ,de ebben dolgozom és ez nálunk is így megy.
Amúgy szó volt arról hoyg Nvidiának van egy B terve arra hogy a MCM dizájnt hoz az RDNA ellen a csúcsra, de aztán Jensen eltörölte. Itt volt róla szó:[link]
Miért kellene hogy nyoma legyen? az RDNA1 architektúrájában volt nyom arra hogy az RDNA3 chiplet lesz ?
Az Ada2 is monolitikus lesz még.2027 kb amikor jön geforce szintre.
Az Nvidia ütemterve szerint előszőr a professzionális szintre hozzák be az MCM vonalat, meg kisebb autó gyártás, 5 G Mediatek, stb.
Szerintem tökéletesen tisztában voltak azzal mindkét cégnél, hogy TSMC kb mekkora árazást ad a wafferre hisz ez nem napi árfolyam előre megegyeznek, nem ma kezdték. Egy termék ára tól-ig van meghatározva valószínűleg.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)

Petykemano
veterán
Én hajlamos lennék elhinni azt, hogy az ilyen - sikeres - cégek vezetőinek valóban magasfokú az előrelátása. Persze azért ugye tudjuk, hogy az évtizeteken keresztül sikeres politikusok nem csak annak köszönhetik sikereiket, hogy csupán remekül tapogatják le a néplelket, hanem megfogják és agyagként formálják is azt.
Azt nem bírom (akkor lóg ki a lóláb), amikor meg valamilyen PR szempontból "kellemetlen" dolog történik, akkor elkezdenek takarózni váratlan és/vagy kiszámíthatatlan piaci folyamatokkal.
Máskülönban azzal - sajnos - egyet kell értsek, hogy valószínű, hogy az Nvidia nem azért nem hozott még piacra chipletes terméket, mert nagyon le vannak maradva ennek a területnek a kutatás-fejlesztésével. Több alkalommal előfordult már (pl tesszeláció, HBM, gyártástechnológia), hogy az Nvidia valamivel látszólag később rukkolt elő, de amikor az megtörtént, az nagyon profin történt és megsemmisítőleg hatott az azt megelőző évek arra irányuló érvelésére nézve, hogy az AMD azért volna valamilyen vonatkozásban előnyben, mert már X generáció óta termék formájában ki is adják.
Ha esetleg tudsz olyat mondani, ahol az látszott, hogy az Nvidia kapkodott, vagy tapasztalatlanság miatt bukdácsolt és az AMD képes volt néhány éves előnyét megtartani, akkor kiváncsi vagyok rá.
Én nem gondolom, hogy az Nvidia ne folytatna kutatás-fejlesztést ebben a témában. Csak nem jelentetnek meg belőle terméket. Nem feltétlenül azért, mert még sehogy se állnak, hanem talán azért, mert nem szorulnak rá arra, hogy egy megoldást a nagyközönséggel béta-teszteljenek, vagy épp azért, mert van erőforrásuk párhuzamosan futtatni többféle fejlesztést. Másként fogalmazva, lehet, hogy az Nvidiának volt - chipletes - B terve arra nézve, ha nem így alakulnak a wafer árak. Másként fogalmazva: Jensen nem látnok, csak rendelkezésére állnak az ahhoz szükséges erőforrások, hogy többféle szcenárióra is felkészüljön.
Tartok tőle, hogy benne van az a lehetőség, hogy ugyanez fog történni a chiplettel is: hogy amikor az nvidia megjelenteti a saját megoldását, akkor az addig többéves előnynek tűnő AMD erőfeszítés hirtelen más megvilágításba kerülve többéves értelmetlen és kézzelfogható hasznot nem hajtó szerencsétlenkedésnek (pionírkodásnak) fog tűnni.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
Abu85
HÁZIGAZDA
Az RDNA 2-ben volt nyoma annak, hogy chiplet lesz, mert ugye a problémát az jelenti a chipletnél, hogy nem tudod hol jól megvágni a GPU-t. Ehhez kellett egy victim cache, hogy szeletelhető legyen a dizájn.
Nem az árral van baj, hanem azzal, hogy a 3 nm-es node esetében a reticle limit nagyon picike. Mindössze 429 mm^2. Tehát ennél nagyobb lapkát nem lehet tervezni. Mondjuk ettől még lehet monolitikus az NV-féle next-gen, csak nem tudják, hogy az AMD mit fog csinálni. Valószínű, hogy az NV is chipletben gondolkodik, mert egyszerűen túl szűkös a friss limit. Az MCM chipletet egyébként meg lehet oldani egyben is. Nem muszáj ám három részletben bevezetni, mint ahogy az AMD teszi. Utóbbi csak biztonságos, mert annyi helyen félremehet, hogy aztán a jó ég tudja, hogy hol a bug, de amúgy technikailag kivitelezhető egyben megcsinálni mindent.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Igen azért írtam ,hogy az Ada next ami majd jönni fog 2025 ben lesz a Chiplet elötti utolsó gen, mint az RDNA 2 volt AMD nél.
Az ár a 4090 vs 7900XTX miatt jött szóba , legalább is HSM szerintem erre gondolt.
A chipletnél Nvidánál a hűthetőség és az összeköttetés/ tokozás miatt írták anno, hogy halasztanak, meg ha jól tudom azon variálnak hogy bontsák/ kössék össze a szegmenseket, melyik okoz kevesebb késleltetést és kerül kevesebb energiába.
Komplikato: Igen ,ők formálják a piacot a szoftverezettséggel a hardveriekhez így is lehet fogalmazni és ez fordítva is igaz.
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)

Komplikato
veterán
Azért Linus videója a témában eléggé odavert pár hete, pedig hát ő ugye nem annyira hardcore HW szakértő, főleg NEM PC ügyileg, mint szeretné elhitetni magáról. Az AI vitában nem látom visszaköszönni, hogy NVidia AI kutatásokra mennyit költ és ennek mennyi rengeteg eredménye van. Ilyen hülyeségeket kell olvasni szakmai fórumokban is, hogy az Nvidia "felült" az AI hype-ra, mert most az a menő. Mint ha közük se lenne hozzá. A 2 minutes papper csatornán bemutatott AI technológiák nagyobbik fele mind NV kutatási téma és vagy szoftver fejlesztés. Na és én ezt a felét hiányolom AMD oldaláról, nyilván ott is folynak kutatások, de úgy látszik kivűlről nincsenek ennyire mélyen benne.
"Figyelj arra, aki keresi az igazságot és őrizkedj attól, aki hirdeti: megtalálta." - (André Gide)
Busterftw
veterán
En ezt ertem, ettol meg az RTX 4060 nem lesz Ampere, mert hasrautve szerinte csak.
[ Szerkesztve ]
HSM
félisten
Az architektúra alapjainak sokszor előbb kell készen lennie, mint ahogy elérhető lenne a gyártástechnológia, hát még annak árazása... Szóval kötve hiszem, hogy amikor elkezdték tervezni az Ada-t, akkor már tudták volna, mennyibe fog kerülni az 5nm-es gyártás.
Érdekesség egyébként, hogy párszor előfordult a történelemben, hogy az Nv-nél megbosszulta magát, hogy ki akarták maxolni a gyártástechnológiát. Gondolok itt a GTX280-ra és a GTX480-ra, mindkettőnél túllőtek a célon, amivel igen kellemes piaci helyzetbe hozták a konkurens HD4870 és HD5870 kártyákat.
"az RDNA1 architektúrájában"
Abban nem. De az RDNA2-ben igen. (L3 beépítése az L2 növelése helyett.)
"hogy TSMC kb mekkora árazást ad a wafferre hisz ez nem napi árfolyam"
Nem hinném, hogy bármelyikünk ebbe belelátna, de a pletykált, rendkívül alacsony Wafer-árak szinte biztosan nem jöhettek volna létre az előre nehezen jósolható meredek kereslet (és ebből fakadóan gyártósor kihasználtság) csökkenés nélkül.
hahakocka
senior tag
Gondolom emlèkeztek a Rx 480 vs Rx 580 esetre is. De lehetne mèg sok más âtnevezèses esetet mondani. A marketingben lehet az lesz oda is van írva se valójàban kb egy àtnevezès a az addig kiadott Rdna3 újdonsàgok jó rèsze se jellemzi ki van spóroltatva. Le van butítva ahogy HSM is írta.
[ Szerkesztve ]

Raymond
félisten
"az addig kiadott Rdna3 újdonsàgok jó rèsze se jellemzi ki van spóroltatva"
OK, jatszunk akkor. Melyik RDNA3 tulajdonsagok vannak belole kisporolva?
Privat velemeny - keretik nem megkovezni...
A architektúra tervezését igen, biztos évekkel előre elvégzik, de a gyártásra tervezésnél az árazassál már tisztában kell lenniük.
Azért olyan nagy eltérés nincs a megjósolható árazásban hisz például a 3 nm már most is elérhető árajánlattal, az Apple használja ezerrel, már 2020 ban lefoglalta , 2 év múlva is elérhető lesz mire az Ada next piacra kerül ez így volt az 5 nm gyártással is.
Ez egy nem rossz kis videó matekról., igaz nagyon leegyszerűsítve. [link]
Minkét architektúra 5 nm gyártáson készült és AMD nek kiegészítve 6 nm gyártással azaz egy olcsóbb gyártással és még így is állítólag közel annyi a Navi 31( 140-160$ + interposer és csomagolási költség hozzáadódik ehhez, kb 200$) az egészhez a monolitikus dizájnnal szemben.
És ne elejtsük el hogy a csúcs navi 31 a 4080 nal versenyez ami AD103@ 309 mm2 teljes értékű AD102( 4090TI) közel 45 % kal gyorsabb lehetne , mint a Navi 31...
Kepler és nerdtech szerint a 7900XTX teljes előállítási költsége 4-500$ [link] az RTX 4080 költsége 300-350$[link]
ha egy csúcs AD102 ( nem a 4090) 5-600 dollár és közben ennyivel gyorsabb akkor a matek jó volt még akkor is ha a Navi 31 4090 sebességű lett volna ,mert cserébe nem tartalmaz kockázatot, kísérleti státuszt.
Ha jól néztem a Navi 31 533 mm2 az AD102( 4090) 609mm2 és le van tiltva egy csomó részegység és az L2 egy része a 4090-ben
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
HSM
félisten
Nagyjából ezt számolgattam ki én is [link] . (Nem láttam még a videót, amikor ezeket számolgattam.)
Egyébként, a mostani wafer-árakon az AD103 szerintem eléggé eltalált lett.
A 4090 óriás csip méretét kicsit meredeknek látom még a sok tiltás mellett is, de ettől függetlenül az is nyilván igen jó lett, bár megnéztem volna a bolti árát az eredetileg belengetett közel 20 000$-os 5nm wafer árakon. 
[ Szerkesztve ]
S_x96x_S
őstag
> a világ legsikeresebb GPu gyártójaként nem láthatta gondolod?[link]
> Szerencséjük volt?
ez nem érv ..
a múltbéli siker "sose" garancia a jövőbeli sikerre .. 
és létezik szervezeti vakság is .. ( ~ corporate strategic blindness )
a KODAK
és a NOKIA is látta a trendet , csak nem hitte azt, hogy veszélyes és utána kapkodtak és rossz döntéseket hoztak.

> nekem kissér fura, alulról nézve felfele állítjátok be vesztesnek Nvidiát, elmaradottnak,
> és lúzernek a fejlesztések szintjén.
Nyugi, még nem vesztes és nem lúzer.
de ha az AMD-nek a chiplet bejön AI és GPU - fronton is ... akkor már az AMD nem a visszapillantó tükörben lesz.
Az AMD 100%-ban odatette magát a chipletre .. már-már vallásosan ..
Vagyis az nVidiáért (is) aggódunk páran, mert a verseny jó
Mottó: "A verseny jó!"
Busterftw
veterán
Csak ugye b. gpu-król beszél, gpu találgatósban.
Ha az AI bejön az AMD-nek még nem jelent semmit.
Az Epyc és a Ryzen is bejött nekik, mégsincs az Nvidia gpu piacon a visszapillantó tükörben, ahogy az Intel sem a CPU piacon.
Az AMD ezzel szemben az Epyc és Ryzen sikerei után egyre jobban lecsúszott a GPU piacon.
Szóval értem en a lelkesedést , de fordítottan is igaz a corporate strategic blindness.

FLATRONW
őstag
Emlékszünk, itt szó sincs ilyesmiről.
A 7600 egy agyonvágott RDNA3, ahogy a 4060 is egy agyonvágott Ada.
Valóban, erre nem emlékeztem. te is hasonlóan számoltál.
S_x96x_S:
várj , szerintem félreértesz. Nvidia is a chipletre rá fog térni.
,minden gyártó rá fog térni. Mi most az RDNA 3 ( 4) és az Ada ( next) ről beszélünk.
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
S_x96x_S
őstag
> Csak ugye b. gpu-król beszél, gpu találgatósban.
> Ha az AI bejön az AMD-nek még nem jelent semmit.
Nem pontosan értelek .. miért ne jelentene ?
A GPU már nem csak a gaming -ről szól ..
még az "NVIDIA H100 Tensor Core GPU" is GPU,
ugyanazok az építőelemek .. az AI-nál és a GPU-nál
az MI300 lényegében egy big APU .. És a Grace is az.
persze kezd ketté válni .. ahogy az AMD- is szétszedte CDNA - RDNA -ra.
de még mindig GPU : "AMD Instinct is AMD's brand of professional GPUs"
> Szóval értem en a lelkesedést , de fordítottan is igaz a corporate strategic blindness.
persze ez fordítva is igaz.
Az AMD a szoftvert és az ökoszisztémát nézte be .
Az nVidiának a CUDA bejött .. 100% - ban odatették a fókuszt és az erőforrást ..
és bár az AMD-nek volt pár kisérletezése és prototípusa, de nem annyira tette oda magát ..
és most meg kell küzdenie ezzel - be kell hozni a hátrányt - ami nem olyan könnyű ..
És nem csak az AMD-nek,
hanem a piacnak is, mert a verseny jó - de a monopólium verseny ellenes ..
--> NVIDIA's CUDA Monopoly
és a mai Hacker news - ahol ezt a témát járják körbe - érdemes beleolvasni !
--> https://news.ycombinator.com/item?id=37031451
[ Szerkesztve ]
Mottó: "A verseny jó!"
S_x96x_S
őstag
(piac)
azért mások is gondolkodnak chiplet cloud-ban
és az AMD-nek igencsak szüksége lesz a Xilinx -es gyorsítók beintegrálására
hogyha versenyben akar maradni ...
mert csak a GPU nem mindenre optimális ( főleg ha a TCO-t is nézzük. )
---------------
CHIPLET CLOUD CAN BRING THE COST OF LLMS WAY DOWN
(July 12, 2023)
https://www.nextplatform.com/2023/07/12/microsofts-chiplet-cloud-to-bring-the-cost-of-llms-way-down/
"If Nvidia and AMD are licking their lips thinking about all of the GPUs they can sell to the hyperscalers and cloud builders to support their huge aspirations in generative AI – particularly when it comes to the OpenAI GPT large language model that is the centerpiece of all of the company’s future software and services – they had better think again.
..... "
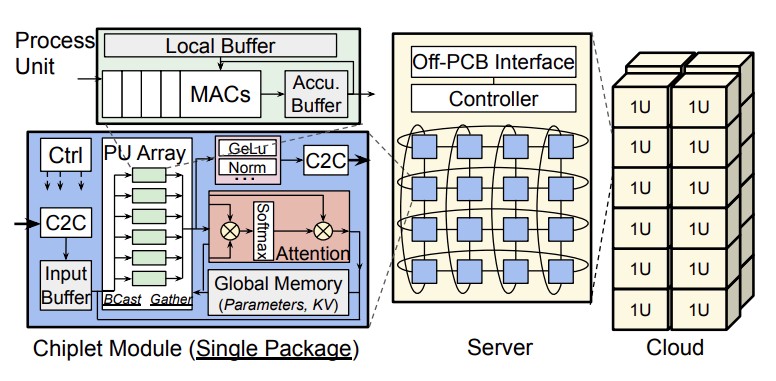
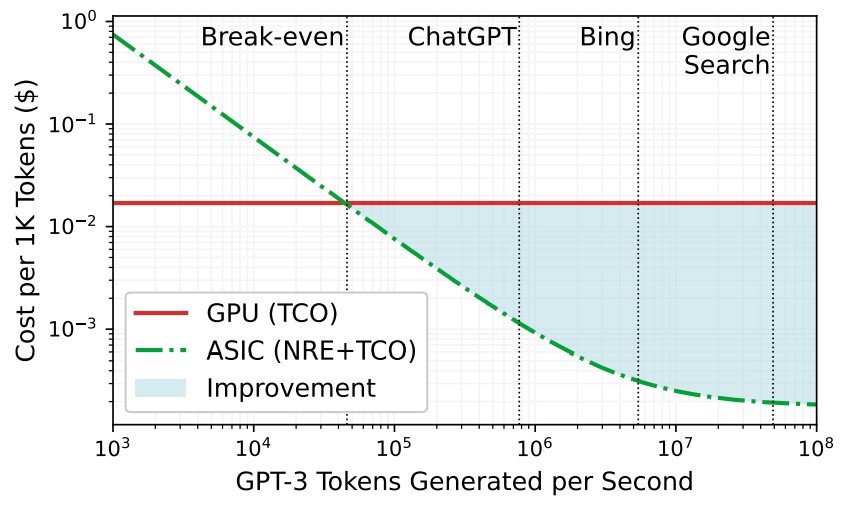
Mottó: "A verseny jó!"
Busterftw
veterán
"Nem pontosan értelek .. miért ne jelentene ?"
Ugy ertem, hogy az AI gyorsitok sikere nem jelenti automatikusan azt, hogy consumer gpu piacon is sikert ernek el. Ugyan GPU, de ez egy teljesen mas szegmens. (lasd Epyc/Ryzen siker/pelda)
Jo lora tettek az Epyc-kel, mostanra sikeres a szerver uzletag, viszont ettol az AMD nem lett jobb pozicioban GPU vonalon (consumer).
"de a monopólium verseny ellenes .."
Ha jol tudom ez jogilag nem igy van, a monopolium onmagaban nem versenyellenes, csak ha visszaelnek vele.

Ribi
nagyúr
Neem a monopólium akkor verseny ellenes, ha az nem egy "nagy kutya" kezében van
Petykemano
veterán
Yanis Varoufakis egy időben úgy kritizálta az Európai Uniót érő "demokrácia-deficit" kritikát, hogy az olyan, mintha azt mondanánk, hogy a Holdon oxigén-deficites a légkör. A Holdon valójában nincs oxigén.
Valahogy így van a kapcsolat monopólium és a verseny (versenyellenesség) tekintetében is. A monopóliumra azért nem lehet azt mondani, hogy az versenyellenes, mert a monopólium valójában a verseny hiányát jelenti.
Találgatunk, aztán majd úgyis kiderül..
Petykemano
veterán
Itt egy értekezés pont az iménti "chiplet / nem chiplet / meddig nem chiplet" témában: [link]
(Ez azt mondja, hogy Mi300-at szállítják a vásáróknak.)
Találgatunk, aztán majd úgyis kiderül..
Raymond
félisten
"Ez azt mondja, hogy Mi300-at szállítják a vásáróknak."
Ez ujdonsag lenne a vasarloknak mert egyelore ugy nez ki az iden max az El Capitan-ba n lesz csak MI300 az ev vegeig.
Privat velemeny - keretik nem megkovezni...
Petykemano
veterán
Azt mondja, hogy a N43 és N44 monolitikusak. Ez még az RDNA3 chipletezéshez képest is visszalépést jelent. (Ez persze nem biztos, hogy rossz ezekre a lapkákra nézve)
Azt gondolnám, hogy ha az RDNA3 folytatásához hasonló a GCD feldarabolásán alapuló multi-GCD chipletezéssel próbálkoztak volna, akkor legrosszabb esetben is az RDNA3 esetén is látott megoldáshoz fallbackelnének.
Ha a megmaradt lapkák valóban monolitikusak lesznek, akkor gyanítható, hogy valami egész más nem sikerült.
RDNA5 2025Q4!!!! Ez döbbenet.
Ami miatt írom az mégsem ez, hanem egy állítólagos 400mm2-es RDNA3 (Navi36) lapka megemlítése - persze sajnos azzal a megjegyzéssel, hogy ennek kiadása valószínűtlen. Lehet, hogy az AMD-s urak erről beszéltek, mint 600W-os GPU. De lehet, hogy ez is csupán egy olyan dolog, hogy megemlítek valamit, azzal, hogy az nem fog megjelenni és aztán amikor tényleg nem jelenik meg, akkor jutott is - maradt is alapon nem lehet engem felelősségre vonni.
Találgatunk, aztán majd úgyis kiderül..
Raymond
félisten
"RDNA5 2025Q4!!!! Ez döbbenet."
RGT, a MLiD unokatestvere/bajtarsa 
Eloszor az RDNA3 maradekat kene kiadni utanna megnezni mikorra sikerul az RDNA4 es aztan lehet arrol spekulalni hogy az akkori allas szerint mi a realisztikus egy RDNA5-nel.
Privat velemeny - keretik nem megkovezni...
S_x96x_S
őstag
> Ez ujdonsag lenne a vasarloknak mert egyelore
> ugy nez ki az iden max az El Capitan-ba n lesz csak MI300 az ev vegeig.
valószínüleg a vásárlók típusától is függ ..
mert a magyar nagykerekbe még tényleg nem várnám ..
de az AWS/Azure/Google Cloud -ban már mintaképpen "feltünhet" ..
Azért Lisa Su óvatosan optimista volt a befektetők felé,
és bár a tervezett MI300 -as idei bevételek nagy része tényleg El Capitan ( ~ supercomputing ) ; de nem az egész ...
( Persze ha ezek minde előre fizetős ügyfelek az már más tészta )
Mindenesetre Q4 Mi300 ramp -ot nagyon nyomja a menedzsment,
de jelentős felfutás csak 2024-ben várható.
Aztán majd meglátjuk mit hoz a valóság,
nem lehetetlen, hogy neked lesz igazad és a szkepticizmus indokolt ..
de akkor az AMD befektetők morcosak lesznek ..
--------------
Lisa Su - 1 hetes véleménye - A "Q2 2023 Earnings Call Transcript" -ből szemezgetve:
"
Yes, sure. So, it is a large ramp, Stacy, into the fourth quarter. I think the largest piece of that is the MI300 ramp. But there is also a significant component that's just the EPYC processor ramp with, as I said, the Zen 4 portfolio. In terms of the lumpiness of the revenue and where it goes into 2024. Let me give you kind of a few pieces.
So, I think there was a question earlier about how much of the MI300 revenue was AI centric versus let's call it supercomputing centric. The larger piece is supercomputing, but it's meaningful revenue contribution from AI. As we go into 2024, our expectation is again, let me go back to the customer interest on MI300X is very high. There are a number of customers that are looking to deploy as quickly as possible.
So, we would expect early deployments as we go into the first-half of 2024, and then we would expect more volume in the second-half of '24 as those things fully qualify. So, it is going to be a little bit lumpy as we get through the next few quarters. But our visibility is such that there are multiple customers that are looking to deploy as soon as possible. And we're working very closely with them to do the co-engineering necessary to get them ramped.
--------------
And then we will have contribution from both MI300X going to large AI customers as they start their initial ramps, as well as MI250s with a number of customers who have now -- view that as a very good option for some of the workloads that are not necessarily the largest language models or the largest parameters, but let's call it more sort of the other AI workload. So, those are the components of the fourth quarter implied growth. Lots of pieces to it, but clearly a big piece of it is the MI300 ramp.
--------------
And in particular, where we've seen a lot of interest is in the sort of large language model inference. So, MI300X has the highest memory bandwidth, has the highest memory capacity. And if you look at that inference workload, it's actually a very, it's very dependent on those things. That being said, we also believe that we have a very strong value proposition and training as well. When you look across those workloads and the investments that we're making, not just today, but going forward with our next generation MI400 series and so on and so forth, we definitely believe that we have a very competitive and capable hardware roadmap. I think the discussion about AMD, frankly, has always been about the software roadmap, and we do see a bit of a change here on the software side. Number one, we've put a tremendous amount of resource on it. So, bringing together our former Xilinx software team, together with the AMD sort of based software team, we've dramatically increased the resources. And also the focus has now been on sort of optimizing at these higher level models.
So, if you think about the frameworks around PyTorch and Triton and Onyx, I think many of the new AI centric companies are actually optimizing at a different level, and they're working very closely with us. So, in this place where AI is tremendously exciting, I think there will be multiple winners. And we will be first to say that there are multiple winners. But we think our portfolio is actually fairly unique in the sense that we do have CPUs, GPUs, we have the accelerator technology with Ryzen AI on the PC side as well as in the embedded side with our Xilinx portfolio. So, I think it's a pretty broad and capable portfolio.
----------------- ( supply chain )
Yes, absolutely. So, I'm not going to comment on the exact units, but what I will say is that we've been focused on the supply chain for MI300 for quite some time. It is tight. There's no question that it's tight in the industry. However, we have sort of commitments for significant capacity across the entire supply chain. So, co-host is one piece of it, high bandwidth memory is another piece of it and then just the general capacity requirements and look, our goal is to make this a significant growth driver for AMD, I think it's a great market opportunity. We love the engagements with customers, it's our responsibility to provide the supply for the demand and so that's what we've been working on.
-----------------
Sure. So, there were a lot of aspects to that question, Chris. So, let me try to give you some framework here. I don't think we're ready to talk about timing yet of revenue numbers. What we will say is we do believe it's a multibillion dollar opportunity. I think 2024 is a very important year for us.
Ramping MI300 in multiple customers over the next several quarters is very important. I think I mentioned earlier in the Q&A that the customer interest is actually diverse, which is great. It includes sort of what you would expect in terms of the large Tier-1 hyperscalers. But I think these new class of sort of AI focused companies have been working very closely with us, and then some of the large enterprises are also looking at ramping up their efforts. The performance that we see is strong. I think the large language model work that we've done, we've done a lot of it on MI250, and we've seen very good results that's on both training as well as inference. I think as we go through MI300 again, the early results are strong.
For AI applications, what we're seeing now is MI300X. So, let's call it the GPU only version is the one that is sort of most prevalent in the AI customer engagement. But the MI300A, actually, which is sort of where we have the CPU and the GPU more closely coupled together is also of interest. So, I think the key is I think we've built a platform that does allow people to kind of choose what is best for the models and for the workloads that they're trying to enable. And that's what we're working on.
---------------
Yes, thanks Chris. Let me just make sure I get the statement clear. So, both MI300A and MI300X will be part of the ramp, particularly in the fourth quarter. And as we go into next year for the AI specific applications, we are more heavily weighted towards MI300X, just given sort of where the software is written. And to your question about gross margins at the corporate level, so we would expect that our AI business will be accretive to gross margins at the corporate level. And obviously, as you start the ramp, there's a little bit of learning, but overall we expect it to be accretive to our corporate gross margins.
"
( via "Advanced Micro Devices (AMD) Q2 2023 Earnings Call Transcript" )
------------------------
Mottó: "A verseny jó!"
Elmentettem a múltkor ezt a videót, hogy majd egyszer bedobom ide [link] Hihetetlen :
azóta is jót röhögök rajta :ahogy elmondja és felvezeti majd tálalja mi jön itt , vérengzés, paks, stb...
Az első 4-5 percben szekunder szégyenérzetem van ez miatt az ember miatt, de nem tudom miért nekem.
Sajnos ezután születnek ezek a kommentek: [link]
[link]
57800 tól érdemes s elolvasni egy olyan 50-60 kommentet
Mlid és társai itt meg alá teszik a lovat sajnos.
Ez miatt van mindig hypevonat mert Nvidia gyalázást és Nvidia gyilkolást várnak, AI szinten is, gamingban is,mindenben is. nem pedig egy jó GPU-t.
Ugye poor Volta, meg Nvidia killer stb.... Erre épül MLiD és RGT pályafutása. Már kezdődik a Chiplet hype...
[ Szerkesztve ]
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
Raymond
félisten
"az AWS/Azure/Google Cloud -ban már mintaképpen "feltünhet" .."
Nem tunhet fel, pont errol van szo. Az osszes az El Capitan-ba megy es jo eselyel nem lesz eleg oda se az iden.
Privat velemeny - keretik nem megkovezni...
Abu85
HÁZIGAZDA
A kiemelt partnereknek, nem az átlag vásárlóknak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Petykemano
veterán
Találgatunk, aztán majd úgyis kiderül..
[Special driver for Ratchet and Clank from AMD]
Ratchet & Clank Rift Apart update enables ray tracing on Radeon RX GPUs
"A számítógépek hasznavehetetlenek. Csak válaszokat tudnak adni." (Pablo Picasso) "Never underrate your Jensen." (kopite7kimi)
S_x96x_S
őstag
"Making AMD GPUs competitive for LLM inference" ( Aug 9, 2023 )
https://blog.mlc.ai/2023/08/09/Making-AMD-GPUs-competitive-for-LLM-inference
( HN: https://news.ycombinator.com/item?id=37066522 )
TL;DR
MLC-LLM makes it possible to compile LLMs and deploy them on AMD GPUs using ROCm with competitive performance. More specifically, AMD Radeon™ RX 7900 XTX gives 80% of the speed of NVIDIA® GeForce RTX™ 4090 and 94% of the speed of NVIDIA® GeForce RTX™ 3090Ti for Llama2-7B/13B. Besides ROCm, our Vulkan support allows us to generalize LLM deployment to other AMD devices, for example, a SteamDeck with an AMD APU.

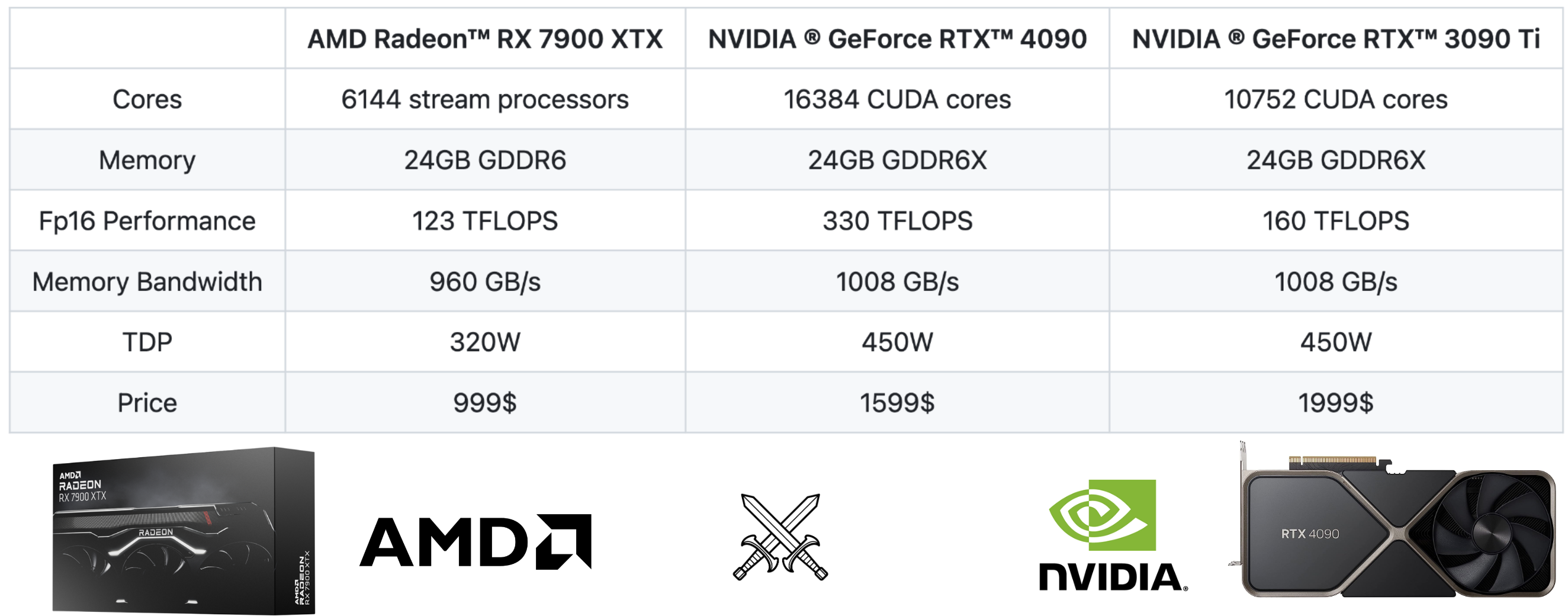

Mottó: "A verseny jó!"
Yutani
nagyúr
Nem értek hozzá, de jól hangzik.
#tarcsad
Petykemano
veterán
Egész versenyképes lehetne 400mm2-es GCD-vel és 450W-os TDP-vel.
Az jutott eszembe a Mi300-ról, hogy vajon az most mennyire a határon pörög? És hogy mennyire hamar lehet iterálni.
Mire is gondolok?
Vajon a 300-350mm2-es N6-on gyártott lapkák kimaxoltnak számítanak? Összességében a 1700mm2-es alapterületnél nem is lehet tovább terjeszkedni
2020-ban még azt mondták, hogy a Cowos a reticle size (858mm2) 2x-esében tud lapkák összerakásában rendelkezésre állni. [link] a Mi300 ezt ki is használja.
Itt már 6x reticle size-ról írnak, ami valami 5100mm2. [link]
Tartok tőle, hogy a szorzó ugyan helyes, de a reticle size értéknek itt már nem a 858mm2-t, hanem az Abu által emlegetett N3 alatt feles értéket kell érteni. Vagyis összességében kb 2500mm2 lehet majd a csomag.
Számomra különös, hogy a 370mm2-esnek mondott alapra csupán 2db 115mm2-es CDNA3 lapkákat vagy 3x71mm2-es CPU lapkákat helyeznek el. Vajon miért csak 210mm2 méretben fedi le? [link] Miért ilyen nagy a differencia? Nem lehet-e a base die méretét jobban kihasználva lefedni?
Az iteráció is egy érdekes kérdés. A CDNA3 esetén az XCD-ről tulajdonképpen minden sallangot leválasztottak, a last level cache és az IO - vagyis azok a részek, amelyeknél gyártástechnológiai skálázódás jelentősen lelassult vagy megállt - is a base die-on kapott helyett. A Logic rész mérete viszont az N3 esetén is még remekül csökkenthető. Logikus volna, hogy mihamarabb N3-on készüljön az XCD, mert úgy még több számolóegységet tudnak rárakni.
Találgatunk, aztán majd úgyis kiderül..

Téma tudnivalók
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

Mai Hardverapró hirdetések
prémium kategóriában
- DELL 7070 SFF Core i7 8700 vagy i7 9700 8/16GB DDR4 250GB M.2 SSD számla + gari - több db
- Wacom Intuos Pen&Touch medium eladó
- Feiyutech AK4500 Gimbal + follow focus + hyperlink eladó (standard kit)
- Apple Ipad Pro M1 2021 128GB Wifi + Apple Pencil 2.gen + tok + extra fólia
- XFX RX 6800 SWFT - 3 év ALZA garancia - eladó!
