- Magga: PLEX: multimédia az egész lakásban
- Luck Dragon: Asszociációs játék. :)
- Lalikiraly: Commodore The C64, Ultimate
- aquark: Flipper PC-n!
- Luck Dragon: Óraátállítás
- sziku69: Fűzzük össze a szavakat :)
- eBay-es kütyük kis pénzért
- sziku69: Szólánc.
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Parci: Milyen mosógépet vegyek?
Új hozzászólás Aktív témák
-

Taci
addikt
Szerintem ne privátban kérj segítséget. Ez a fórum egyik előnye, hogy a te problémád másnál is előjöhet, és akkor egy kereséssel a választ is megtalálja. Szóval szerintem írd be ide a kérdésedet.
A második kérdésedre pedig a válasz az SQL Fiddle vagy a DB Fiddle. (De lehet, ajánlanak majd mást is.)
-
Taci
addikt
válasz
 sztanozs
#5441
üzenetére
sztanozs
#5441
üzenetére
Köszönöm, hogy rászántad az időt és ezt ilyen részletesen leírtad, de valószínűleg akkor rosszul (túlbonyolítva) tettem fel a kérdést, mert (bár pár új részletet megtudtam, köszönet érte, de) nem erre irányult a kérdésem, ez a része tiszta.
Ezt írta bambano: az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Én pedig azt szeretném megérteni, hogy miért jobb egy ilyen módszert kifejleszteni (ennél a példánál maradva: rd aldomain, átirányítás saját aldomain-ről a külső linkre) ahelyett, ahogy pl. tegnap a tesztszerveren megcsináltam, hogy simán csak megnyitja a külső linket (href), mellé meg fut egy szkript (onclick), ami szerver oldalon realizálódik és tárolja az összes adatot ami szükséges. Miért kell hogy saját szerverre mutasson a link, és onnan legyen az átirányítás a külső linkre?
@martonx: Köszönöm.
-
Taci
addikt
válasz
sztanozs
#5438
üzenetére
Én elhiszem, hogy a segítő szándék vezérelt (ahogy korábban is), de semmivel sem jutottabb előrébb egyik kérdéssel kapcsolatban sem azzal, hogy átolvastam pl. a Wikipédia cikket róla.
Nem is értem, mire írtad, max a 301 status code-nál lenne értelme, de ott pont nem volt semmi ilyen kérdésem, csak az eredeti fájlt nem tudtam elkapni, hogy amiről átirányít, az hogy néz ki - csak később curl-el.
Ebből egyik témára sem kapok választ, de még csak iránymutatást sem:
- "az a megoldás, ha a link a saját webjére mutat és redirectel a célra."
- "Google Analytics erre a megoldás, saját kókányolás helyett."
De így már ez tényleg teljesen offtopic ide. -
Taci
addikt
válasz
 bambano
#5436
üzenetére
bambano
#5436
üzenetére
Annyira szeretném érteni, amit írtok, de csak
 fejek jönnek elő belőlem (meg rengeteg kérdés).
fejek jönnek elő belőlem (meg rengeteg kérdés).Google Analytics erre a megoldás, saját kókányolás helyett.
Szeretnék egy menüpontot, hogy pl. "Legolvasottabb cikkek". De az nem világos, hogy hogyan lehet jobb az Analytics-es adat, mint a saját szerveren tárolt. Vagy van rá mód, hogy direktben elérjem ezt az adatot (Google), és be tudja építeni egy query részeként? Tehát hogy pl. rendezze sorba a cikkeket aszerint, hányszor voltak megnyitva (aka. Legolvasottabb cikkek). Mert csak erre kellene.az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Ezt elmagyaráznád, kérlek, hogy miért jó? Szeretném megérteni, hogy aztán implementálni tudjam. (Ez offtopic ide, ezért rakom off-ba, de nagyon szeretném érteni.)
Így hirtelen ami eszembe jutott, hogy külső linkekkel operál az a hírkereső. Meg is néztem gyorsan, ott ez hogyan van megoldva.Egy példa (direkt nem alakítom linkké):
https://rd.hirkereso.hu/rd/39891270?place=6544&partner=hirkereso&url=https%3A%2F%2Fprohardver.hu%2Fhir%2Fjon_lg_elso_hibrid_projektora.htmlEz ide dob tovább:
https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlMegköszönném, ha lenne annyi türelmed, hogy pár szóban elmagyarázod, hogy ez a link miért így épül fel. Pl. itt miért kell az "rd" aldomain? redirect, gondolom, de ez miért kell?
https://rd.hirkereso.hu/rd/39891270
Ez is ugyanoda továbbít, már a többi rész nélkül is. (és minden más cikkhez is van egy ilyen "redirect-id") Akkor miért kell a többi rész? Nem is igazán értem, bár ez gondolom a saját kódjához kell valamiért.És ennek a headerjében van a
Status Code: 301 (from disk cache)
location: https://prohardver.hu/hir/jon_lg_elso_hibrid_projektora.htmlViszont semmilyen forrásadatot nem látok, nem tudom, hogy továbbít.
Szóval talán az aldomain azért kellhet, mert ezekhez a külsős linkekhez csinált 1-1 saját linket a redirect aldomain-ban, és ezek a linkek 301-el továbbítják a valós cikkhez?
Ez plusz forgalmat generál neki? Vagy miért jó?Milyen rendszert kell építeni mögé? Mit kell hogy tudjon?
És miért jobb, ha így nyílik meg a link, mintsem a direkt link? Mi a célja, szerepe?
A startlap pl. a külsős linkeket simán csak belinkeli, nincs redirect. Akkor ők rosszul csinálják?Vagy ha nincs türelmed, kedved, természetesen azt is megértem, csak kérlek, ez esetben legalább a megfelelő keresőszavakkal segíts, hogy a megfelelő cikkeket találjam meg.
Egy általános "url redirect" sajnos nem mondja meg, hogy hogyan (és miért) kell saját weblapról saját weblapra átirányítva átirányítani. (Se másik jó pár keresés az utóbbi majd' 1 órában.)
Köszönöm.
-
Taci
addikt
válasz
 martonx
#5432
üzenetére
martonx
#5432
üzenetére
Nem saját link egyik sem, mind kifelé mutat, és 5 percenként jön pár 20-50-100 új.
Pl.:<a href="https://mobilarena.hu/tema/sql-kerdes/friss.html"target="_blank" rel="noopener noreferrer">SQL kérdések</a>Azt, hogy melyikre hányszor kattintanak, csak saját kódon belül tudom mérni. (Vagy nem tudom jól használni a Google toolját.
 )
)De akárhogy is, ott is ugyanaz lenne a helyzet a végén (Google adatbázisa), ott is van egy számláló egy rekordhoz, amit emelni kell.
Simán csak egy update?UPDATE clicks SET clicks_counter = clicks_counter + 1 WHERE link_id = 123Vagy van ennek jobb módja is? Mert nem tudom, mennyire "jó" ha folyamatosan update van a táblán (még ha erre is van kitalálva).
-
Taci
addikt
Sziasztok!
Szeretném mérni, hogy egy-egy linkre az oldalamon mennyien kattintanak (és erre építve új menüpontokat létrehozni, tehát ezek a számok új query-khez kellenek majd).
Elsőre azt gondoltam ki, hogy minden linkhez
<a hrefteszek egyonclickeseményt, ami minden rákattintásnál (ellenőrzés után) beír majd egy ehhez létrehozott táblába: a link id-jához tartozó számlálót megemeli eggyel.
Tehát lenne egy clicks tábla, abban egy id, egy link_id és egy clicks_counter mező.
Kattintás, link_id = xyz, megnézi, ez benne van-e a clicks táblában, ha igen, akkorclicks_counter = clicks_counter + 1.Van ennél egyszerűbb, szebb, jobb megoldás?
Csak azért kérdezem, mert az is eszembe jutott, mi van akkor, ha mondjuk 2 user pont ugyanakkor kattint ugyanarra a linkre. Mondjuk eddig 0 volt az értéke a counterének, megy egyszerre a 2 query, mindkettőnek azt mondja, hogy clicks_counter = 0, így mind a kettő 1-re fogja állítani. Vagy ezt okosan lekezeli az SQL?
Vagy máshogy kell ezt lekezelnem?Köszi a tippeket előre is.
-
Taci
addikt
Végig követtem egy mysql-bin tartalmát, és azt találtam, hogy valamiért az összes cron job-om összes tartalma, rekordonként megismételve szerepel benne...
Tehát ha a full backup és az inkrementális backup között 2000 rekord került be, akkor a mysql-bin-ben 2000-szer szerepel az összes cron job összes tartalma...
A teljes sztorihoz tartozik, hogy anno, amikor elkezdtem ezt az oldalt csinálni, még WordPress-szel kezdtem, és ahhoz raktam fel egy beépülőt (WP Crontrol). A WP már rég nincs használatban, azonban a mai napig ezzel készítettem a cron jobokat, mondván, erre a tesztkörnyezetre ez tökéletesen megfelel, és majd a szolgáltatónál kitapasztalom a normál cron jobok (CPanelből) létrehozását.
Lehetséges, hogy ez a plugin kavar be? Ilyen bejegyzések vannak tonnaszámra a mysql-bin fájlokban:
UPDATE `wp_options`SET `option_value` = 'a:35:{i:1640350382;a:1:{s:17:\"crontrol_cron_job\ ...i:1640350473;a:1:{s:17:\"crontrol_cron_job\ ...i:1640350552;a:1:{s:17:\"crontrol_cron_job\ ...
stb. az összes cron job tartalma.
Aztán ez az egész rekordonként megismételve.Mivel ilyen tábla nem lesz (wp_options, hisz' ez WordPress-hez tartozik), gondolom, éles rendszerben (ahol WP a közelben sem lesz) ez a probléma már nem fog előjönni.
-
Taci
addikt
Azt hiszem, kezdem érteni.
FLUSH LOGS just closes and reopens log filesTehát nem rajta múlik, mi kerül a logokba. Ez csak lezárja az aktuális log fájlt, és nyit egy újat.
Valahol be kell állítanom, hogy ezekbe a logokba csak az adatbázist érintő bejegyzések legyenek elmentve (rekordok, táblák stb. módosításai, létrehozása stb.)
De ha már ezt így eddig összeraktam, hátha meglesz az is.
Persze ha valaki tudja a választ, kérem, írja meg.Bocsánat az előbbi regényért, de nagyon nem akart összeállni, és nem akartam fontos részletet kihagyni a "nyomozásból".
-
Taci
addikt
Az a nagyon-nagyon fura, hogy a mysql-bin fájlok tartalmazzák jó pár .php fájlok tartalmát.
Semmi közül az adatbázishoz, erre ott virít a tartalmuk a binary log fájlokban...Most fogtam egy 2,8 MB-os mysql-bin fájlt, megnyitottam Notepad++-szal, és csak felületesen, de kitöröltem belőle a php szkriptjeim tartalmát.
A végeredmény fájl mérete 13 kB. (Ezt gondolnám reális méretnek egy inkrementális mentésnél ennyi új adatra.)Én ezt nem értem. Mi történik itt?
-
Taci
addikt
válasz
martonx
#5416
üzenetére
Utánanéztem, lehet-e natív eszközökkel inkrementális backupokat készíteni, és ezt a linket találtam: incremental-backup-using-mysqldump
MySQL, InnoDB, incremental backupAkinek van tapasztalata ebben a témakörben, kérem, segítsen megérteni, mi és hogyan működik, mert egyszerűen nem áll össze.
Hosszú lesz, szóval csak ha van egy fölös 5 percetek így karácsony előtt, csak akkor álljatok neki.A fenti linken azt írják, kell előbb egy teljes backup, aztán ahhoz képest készül majd a "különbözet" (inkrementális backup).
Követtem a leírást, a példát, el is készülnek a fájlok, de nagyon sok kérdőjel van bennem. Próbáltam végig követni, mi és miért történik, de nem értem. Összeírtam magamnak időpontokkal, hogy mikor-mi történt a rendszerben:16:59
- összes létező log fájl (mysql-bin.0000xx) törlése (teszt szerver, csak hogy tiszta lappal induljak)
17:00
- full backup"mysqldump" . " --skip-extended-insert --complete-insert--single-transaction --skip-lock-tables --flush-logs --master-data=2--user=" . $username . " --password=" . $password . " " . $dbname ." > " . $backup_folder . $backup_filename_sql;
- létrejött: backup-20211222-1700.sql (65 MB, benne minden adat)
- létrejött: mysql-bin.000001 (1 kB)
17:02
- szerver leállítása
17:03
- szerver indítása (csak hogy lássam, mi történik ilyenkor a mysql-bin fájlokkal)
- létrejött: mysql-bin.000002 (1 kB)
- módosult: mysql-bin.000001 (nagyobb lett - 769 kB)
- kérdés: Mi íródott bele, és miért ekkor?
17:04
- módosult: mysql-bin.000002 (nagyobb lett - 770 kB)
- kérdés: Mi íródott bele, és miért ekkor?
17:10
- Adatok folyamatosan kerülnek az adatbázisba, de a 01 és 02 fájlok nem változnak.
17:20
- A 01 és 02 fájlok továbbra sem módosultak.
- kérdés: A 01, 02 stb. fájlokban a saját szkriptjeim tartalmát látom. Miért?
- kérdés: ib_logfile0, ib_logfile1 stb. Ezek milyen fájlok? 262.144 kB méretűek...
17:21
- módosult: mysql-bin.000002 (nagyobb lett - 7.212 kB)
- kérdés: Miért? Mi került bele, és miért pont most?
- kérdés: 7 MB-os fájl 20 perc után? Az előző 3 hónap teljes adatbázisa 65 MB körül van... Akkor ez mi?
22:25
- semmi változás, pedig folyamatosan kerültek be új rekordok az elmúlt 4 órában
22:27
- incremental backup"mysqladmin" . " --user=" . $username ." --password=" . $password . " flush-logs";
- létrejött: mysql-bin.000003 (1 kB)
- módosult: mysql-bin.000002 (nagyobb lett - 106.819 kB)
- kérdés: 107 MB? 4 órányi adat után? 65 MB a full backup 3 hónap után...
22.39
- módosult: ib_logfile0 és ib_logfile1, de a méretük az előzőekhez képest nem változott (262.144 kB), csak a fájl időbélyegzője.
- kérdés: Ezek milyen fájlok? Mi változott bennük, ha a méretük változatlan maradt?
- módosult: az ibdata1 fájl is friss időbélyegzős lett
22.41
- módosult: ib_logfile0, ib_logfile1 és ibdata1 időbélyegzője
Úgy látszik, ez a 3 fájl szinkronban frissül (legalábbis az időbélyegzők).A full backup-hoz találtam még egy "--delete-master-logs" kapcsolót is, de az csak talán egy 1 kB körüli fájlt csinált, amiben nem volt érdemi adat, szóval azt nem is használtam.
Szóval amiket nem értek:
- 20 perc után csinált egy 7 MB-os differenciál fájlt. De az előző 3 hónap összes rekordja elfér 65 MB-ban. Akkor mi kerül 7 MB-ba 20 perc után?
- Akármelyik fájlba nézek bele (mysql-bin.0000xx), a saját szkriptjeim "tartalmát" látom. Nagyon fura. Semmilyen adat a rekordokból, csak a szkriptjeim sorai...
- A link alatt ezt írja: And we only need to save mysql-bin.000002, because it contains all changes we done after our full backup. Ebből én azt értettem (amit írt is), hogy a mysql-bin.0000xx fájlok tartalmazzák a full backup óta történt változásokat, így a fő backup mellé ezeket kell majd lementeni. De akkor a rekordokat kellene tartalmaznia, nem a szkriptjeim "kivonatát"...Valami nálam csúszik nagyon félre? Nem értem ezt az egészet.
Úgy indultam neki, hogy full backup - töltés felhőbeli tárhelyre. Aztán inkrementális backup, kis fájlok, mennek szintén felhőbe. Aztán majd valamikor (csak példa, mondjuk hetente) újra 1 full backup, és a hét hátralévő részében inkrementális, kis fájlok.
De egyrészt ezek az inkrementális fájlok hatalmas fájlok (ahhoz képest, hogy max pár 100 rekordot tartalmaznak elvileg), másrészt, a tartalmukat sem értem.Rosszul hívom meg a full- és inkrementális backupolást? Rossz fájlokat vizsgálok?
Mit rontok el?Hátha valakinek van tapasztalata a témában. Már csak az utolsó lépés (backup) hiányzik ahhoz, hogy költözhessek (szolgáltatóhoz), de ez egyelőre nagyon nem áll össze.
Köszönöm előre is, ha két bejgli közt (vagy akár csak pezső után majd) van időtök ránézni.
-
Taci
addikt
válasz
martonx
#5414
üzenetére
Ez a 2 példa jó, köszönöm.
Viszont ugye ha esetleg programhiba rontotta el az adatokat, az nem jelenti, hogy csökkenni fog az adatbázis mérete. Tehát a vizsgálatom nem helyes (a régi fájlok törlésére vonatkozólag), legalábbis nem elég. Bár ezt az esetet (programhiba) úgyis csak utólag lehet észrevenni.Nem felhőben vagyok, és 5 percenként pár 100 rekord van mentve, így muszáj vagyok sűrűn backupolni. Legalább egy 2-3 órás periódusban gondolkodom. Aztán azért lenne fontos a megfelelő vizsgálat (arról, hogy nem-e egy sérült adatbázis-állaptot mentek le), mert arra gondoltam (és úgy csináltam meg), hogy másnap a legelső backupnál törli az előző napi backupokat, kivéve a legutolsót. Így a végén minden napról lesz egy valid mentésem.
De ez még sok kérdőjeles koncepció, bár minden eleme készen van már és működik, csak ahogy írtam is, arra alapoztam, hogy ha nagyobb a lementett adatbázis az előzőnél, akkor valid is. És ez így nem biztos.
-
Taci
addikt
Kérlek, segítsetek irányba állni a témában:
Úgy csináltam meg az adatbázis biztonsági mentését, hogy mivel nem tarthatok meg minden backupot, ezért a már feleseges(nek vélt) fájlokat egy idő (fájl darabszám) után nem tárolom tovább.
Mivel alapból abból indultam ki, hogy ha baj van az adatbázissal, akkor az elsősorban adatvesztést jelent, így akkor az előző mentéshez képest kisebb lesz a mentett (.sql) fájl. Ezért ha kisebb, nem menti, ha pedig nagyobb, akkor mentheti, tárolhatja, hisz' került bele új adat, ergo rendben az adatbázis. Ehhez mindig az előző mentés (tömörítés nélküli) fájlméretét veszi alapul.De most az ötlött belém, mi van, ha az adatbázis mérete nem csökken? Nem tudom, milyen eset lehet ez, de tegyük fel (extrém példa), az én oldalamat akarják a legtöbben feltörni, sikerül is, és teledobálják saját reklámokkal. Az adatbázis mérete így nőni fog. A szkriptem viszont jelenleg csak a méretnövekedésből veszi, hogy rendben van minden az új mentéssel, ami ebben az esetben hibás következtetés lenne, így a régi (még nem "meghekkelt") mentések potenciális automatikus törlés célpontjai lesznek, és a végén használható backup nélkül maradok.
Pontosan milyen esetekre kellene felkészítenem a biztonsái mentés mechanizmusát?
Mert úgy érzem, ha csak a fájlméretet nézem, már a fenti (oké, nem túl reális) példa alapján sem jó a vizsgálatom.Ott van ugye, ha a szolgáltatót támadják, vagy esetleg hardverhiba miatt ugrik minden adat. Erre ugye megoldás, ha felhőbe is mentek folyamatosan.
Milyen (akár reális, akár 1:1M-hoz esélyű) esetek vannak még, ahol a biztonsági mentés megléte "életet menthet"? Mert akkor úgy módosítom, mit vizsgáljon.
Köszi!
-
Taci
addikt
válasz
 nyugis21
#5358
üzenetére
nyugis21
#5358
üzenetére
Én ahogy láttam, elég sok segítséget, tanácsot és iránymutatást kaptál a fórumtársaktól.
Részemről továbbra is az alapok tanulmányozását javaslom, mert előbb-utóbb szükséged lesz rá, nem hiszem, hogy "kattintgatással" végig lehet vinni egy projektet.
Kezdetnek én mindig ezt ajánlom, mert egyből gyakorolni és kipróbálni is lehet:
https://www.w3schools.com/sql/Talán próbálj meg kisebb területeket lefedni a kérdéseiddel, mert ezek talán túl általánosak, megfoghatatlanok, vagy nehezen megválaszolhatóak. (Számomra, sőt igazából nekem az egész témád az. Ezért sem igazán tudtam eddig érdemben segíteni.)
És azt kérlek, ne feledd, itt mindenki saját idejéből, önszántából segít, válaszol, senki sem kötelez senkit, hogy segítsen neked vagy másnak. És te sok választ és segítséget kaptál eddig is. Úgyhogy talán nem a legjobb "taktika" egy ilyen hozzászólás ezek után. De ez csak az én véleményem.
-
Taci
addikt
Köszönöm a gyors választ mindkettőtöknek.
Még egy kezdő kérdés:
Jelen tudásommal az index újraépítése az az index törlése és újrakreálása. Van ennek esetleg jobb/más/hatékonyabb módja? (MySQL, MariaDB)A REINDEX INDEX, REINDEX TABLE és OPTIMIZE TABLE opciókat találtam.
Ebből csak az utóbbi működik, viszont ezzel az üzenettel:
Table does not support optimize, doing recreate + analyze instead -
Taci
addikt
Sziasztok!
Van egy "kategóriás" táblám, amibe cikkehez tartozó kategóriák kerülnek be. Ha egy cikkhez 3 kategória tartozik, akkor az 3 rekord ebben a táblában.
Ez a szám (kategória egy cikkhez) azonban módosulhat, bekerülhet új kategória, és ki is kierülhet olyan, amihez mégsem tartozik.
Így elkerülhetetlen, hogy "lyukak" legyenek a táblában (ha mondjuk 3 kategória volt egy cikkhez, és csak 2 maradt, akkor ott lesz egy "lyuk", mert az a rekord ki lesz törölve).
A kérdésem az lenne, hogy megéri ezeket a lyukakat feltöltenem? Van bármilyen hátránya ilyen "kis lyukaknak" a táblában?
Mert ha úgy oldom meg, hogy az új elemeket előbb a lyukas részekre töltöm fel, akkor bár "szét lesznek szórva", de hát arra van az indexelés.
De ha az új elemek mindig csak "felülre" kerülnek, akkor idővel nagyon foghíjas lehet - bár ezek max 1-2 rekordnyi "lyukak".
Mit ajánlotok? Kezeljem, és a lyukas részeket töltsem fel előbb az új elemekkel, vagy ekkora lyuk az nem számít, hagyhatom?
(Mindkét módszert meg kell még írnom, ezért kérdezem, mert mindegy, melyiket csinálom, az egyikkel foglalkoznom kell így is - úgy is. Csak akkor már jó lenne a megfelelővel.)Köszönöm.
-
Taci
addikt
válasz
martonx
#5335
üzenetére
Na nagy nehezen csak tudtam lockolni a táblát (phpMyAdminból nem volt olyan egyszerű), adtam hozzá egy 30 másodperces sleep-et.
Abban a 30 mp-ben valóban nem volt hozzáférés a táblához, ez viszont a weboldal felőli oldalon abban mutatkozott meg, hogy új adatot nem tudott behúzni. De ami cache-elve volt, azt szépen hozta újra, mintha semmi se történt volna.Viszont így bár lehet, hogy maga az UPDATE processz hamar lefutna (sőt, igazából folyamatosan azt nézem, hogy futtatom, és közben privát böngészésben nézem, hogy ne cache-ből szedjen adatokat, de így is gond nélkül betölt mindent) inkább napi 1x futtatom csak (az UPDATE-et használó karbantartó szkriptet), azt is valami hajnali órában, így biztosan nem fog "bad user experience"-t okozni.
Köszönöm ismételten a segítséget!
Amúgy jó lenne, ha valahogy ezt a rengeteg segítséget meg tudnám hálálni. Nem szeretek csak kérni, úgy vagyok rendben magammal, ha viszonozni is tudom.
-
Taci
addikt
válasz
martonx
#5333
üzenetére
Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem.
Próbáltam direktben lockolni is a táblát (LOCK TABLE cikkek WRITE), de egyrészt ez alatt is ment minden, másrészt a SHOW OPEN TABLES által visszaadott adatokban azt láttam, hogy nincs is lockolva. (Szóval lehet, ez nem is volt jó teszt ehhez.)
Úgy csináltam anno meg amúgy (a kategóriás karbantartó szkriptet), hogy 100 rekordonként tol egy commit-ot. Nem tudom, ebben a kontextusban ennek köze van-e bármihez.
Annyit találtam még (SQL oldalon), hogy talán lehet csak az érintett mezőket lockolni:
SELECT ... FROM your_table WHERE domainname = ... FOR UPDATE
Ezzel van tapasztalatotok? Jó lehet ide?Az indexeket létrehoztam az érintett mezőkre. Viszont ott észre vettem egy "érdekességet":
Azt mondta az egyik mezőnél (utf8mb4), hogy Warning: #1071 Specified key was too long; max key length is 767 bytes. Ennek utána olvastam, és értem is az okát.A kérdésem az lenne ezzel kapcsolatban, hogy amikor ránézek az indexre, ezt látom:
varchar(255)-ből varchar(191) lett. (ugye 767 / 4).
Ez azt jelenti, ha az eredeti sztring 255 karakter hosszú, indexelve ebből csak az első 191 lesz? Vagy ez pontosan hogyan "manifesztálódik"?"bár szemlátomást, ő magával is ezt teszi
 "
"
Ott a pont. Bár hidd el, nem szánt szándékkal teszem.
Bár hidd el, nem szánt szándékkal teszem. 
-
Taci
addikt
válasz
martonx
#5329
üzenetére
Persze, amint gép elé kerülök, lock-olom a táblát, és megnézem, mi történik web oldalon. Ezt még sosem néztem meg.
Az milyen megoldás lenne amúgy, hogy amíg fut az update, addig a select egy erre beállított view-t használna? Vagy így a lock-olt táblára támaszkodó view sem "érhető el"?
(Az indexet mindenképp megcsinálom - ha esetleg nem lenne. Csak ez most eszembe jutott.)
-
Taci
addikt
Ez nagyon hasznos információ, köszönöm!
Tehát ilyenkor sorbanállás van? Tehát egy sima Select is sorban áll, és a (honlapot használó) user nem kap vissza addig adatot, amíg az update nem végez?
Akkor csak lenne még kérdésem:
Melyik a jobb megoldás ezt a helyzetet kezelni?
- Egy index a cikk_id-ra (ezt kapja vissza a kategóriakarbantartó szkript),
- vagy mégiscsak egy külön tábla ennek a mezőnek?Nem fér bele semennyi várakozás, sorbanállás, hogy a user megkapja a tartalmat (a honlap a kért adatokkal betöltődjön). Most oké, még pár 10ezer rekordnál a karbantartó szrkipt hamar végez, de később ez csak lassulni fog.
Tényleg nagyon köszönöm ezt az információt!
-
Taci
addikt
De most kiderült, hogy ezekről szó sincs, hanem a kategoria_verzio az ellenőrző szkriptednek egy flag, hogy az adott cikket már ne kelljen vizsgálnia?
Igen, pontosan.
Akkor marad úgy, ahogy eredetileg volt felépítve. Csak pár héttel/hónappal ezelőttről emlékszem, hogy valaki írta itt, hogy az úgy nem jó, ha ez a két mező, amit folyamatosan frissítve lesz így vagy úgy (kategória verziója, illetve cikkhez tartozó kategóriák írott nevei, vesszővel elválasztva - amikre "rá tudok nézni"), a többi adat mellett van, ugyanabban a táblában.
Sajnos már nem találok rá arra a válaszra. De ezért tettem fel a nyitó kérdést, hogy maradhat-e így, ahogy most van (amit most Te is megerősítettél), vagy esetleg rakjam külön táblába.Köszönöm szépen még egyszer a sok segítséget!
-
Taci
addikt
Átnéztem, köszönöm a belefektetett időt és energiát.
Ami kérdésem még lenne, az csak elméleti, szeretném érteni a dolgokat.
A cikkek és kategóriák kapcsolata egy külön táblában van (az előbbi példákban
cikk_kategoria ck). Itt egy-egy cikkhez több kategória is tartozhat, ekkor ennyi rekord van létrehozva hozzá. (csak az id-k).
Logikailag ide tartozna a korábban tárgyalt verzió (amivel a kategóriák vannak ellenőrizve,kategoria_verzio). Viszont mivel egy cikkhez több rekord is tartozhat, így ha itt lenne a verzió is, akkor ez az adat redundáns lehetne.Megéri ezért ezt egy külön táblába kivinni, ahol csak a
cikk_idés akategoria_verziolenne?
Adatbázis szempontjából melyik a jobb?Illetve még egy kérdésem lenne, amit az eleje óta nem értek:
Ha ez akategoria_verzioacikkek(a fő) táblában maradt volna, az miért lett volna baj? Az miben okozott volna gondot (adatbázis szempontjából), hogy abban a táblában kellett volna azt a mezőt frissítgetni?Csak szeretném érteni.
Köszönöm. -
Taci
addikt
Az első fele meg is van, a GROUP_CONCAT volt a megoldás rá. (Hamarabb is meglettem volna a teszttel, csak GROUP_CONTACT-ot írtam...
)Ez lett végül kb. belőle:
create view cikkek_vw asselect c.id cikk_id,c.cim cim,c.create_date datum,c.creator cikk_iro,GROUP_CONCAT(k.nev) AS kategoriakfrom cikkek cjoin cikk_kategoria ckon c.id = ck.cikk_idJOIN kategoriak AS kON ck.kategoria_id = k.idGROUP BY c.id cikk_id;Köszönöm!
A másik kérdéskörhöz (és a válaszaid feldolgozásához) picit több időre lesz szükségem.
De ott talán nem voltam teljesen egyértelmű azzal, mit szeretnék, miért is volt a verziózás használva.
Ha csak pár cikkről lenne szó, nyilván meg tudnám kézzel is csinálni a módosításokat. De 2 nap alatt kb. 1000 rekordnyi cikk jön, és ezt csak egy karbantartó szkripttel tudom kezelni.
Kategóriát nem nagyon tervezek hozzá adni, de ha úgy alakulna, hogy kell, az nem gond.
Viszont azt, hogy egy-egy cikk milyen kategóriába tartozik, már nem ilyen egyszerű. Ha észreveszek (vagy bejelentenek) egy anomáliát, hogy egy nem megfelelő / többértelmű kategória-szó miatt egy cikk rossz kategóriába is belekerült, azt az összes cikknél ellenőriznem kell. (Mint pl. az előbb láttam: alapból az Ünnepek kategóriába kerül egy cikk, ha a karácsony szó a cikkel kapott kategóriák közt van - viszont most jó pár cikk, ami politikai irányzatú, a szó miatt szintén az Ünnepek kategóriába került, pedig ott nincs helye). Ilyenkor azt a kategória-szót vagy ki kell vennem, vagy egy exclude-tömbbe rakni (HA karácsony ÉS politika, akkor NEM ünnepek). Ezeket nyilván nem lehet egyesével kezelni, visszamenőleg is át kell nézni az összes cikket. Erre van egy szkriptem, szépen működik.Erre írtam, hogy ez a verziót figyeli, mert ami a legfrissebb kategóriatömb-verzióval került az adatbázisba, azt nem kell nézni, mert az már jól van mentve. A többit viszont át kell nézni.
Ez az ellenőrző szkript óránként lefut. Mivel ettől sokkal ritkábban frissítem csak a kategória-tömb tartalmát, ezért a legtöbbször csinál egy gyors ellenőrzést, látja, hogy minden rekord a legfrissebb verziójú kategória-tömbbel van kezelve, úgyhogy nincs dolga.De ha ezt a verziózást kiveszem belőle, akkor óránként végig kell mennie az összes rekordon, ott mindehol legenerálni, hogy az aktuálisan legfrissebb verziójú kategória-tömb szerint milyen kategóriákba kell tartoznia a cikknek, ellenőrizni, hogy úgy van-e elmentve az adatbázisban, és ha nem, cserélni.
Napi kb. 500 új cikk kerül be (és ez csak több lesz), valahogy muszáj vagyok skippelni azokat a rekordokat az ellenőrzésből, amiket nincs értelme ellenőrizni, mert az aktuálisan legfrissebb változat szerint kerültek be. Másképp sosem lenne vége, és a szolgáltató is kidobna, plusz annyi ideig tartana, hogy a max execution time-ot is túllépném bőven.Lehet, már megírtad a jó választ erre a kérdésre is az előbbiekben, még át kell néznem alaposan.
De ha esetleg mégsem, akkor talán mégis az lesz a legegyszerűbb, ahogy most van megcsinálva:
A cikkek táblában egy mező a verziónak, amivel a rekord kategóriái fel lettek töltve, egy másik mező pedig a rekord kategóriáinak, szövegesen.
Ha változik a verzió, mert javítani kellett kategória-szavakat (lásd az előbbi példa), akkor frissítés az összes nem-legfrissebb rekordon ezen a két mezőn.Amúgy az én hibám, visszaolvastam, ezt a verziós dolgot nem írtam az elején, pedig fontosabb, mint az, hogy a kategóriák nevét lássam.
Gondolom, túl nagy gondot nem okoz a rendszernek, hogy két mezőt frissítgetni (UPDATE) kell.
-
Taci
addikt
És lenne még egy kérdésem, de ezt külön írom, nem is igazán SQL-es. (Átraktam off-ba, de alig bírom kiolvasni..)
Eddig úgy csináltam, hogy a rekordok amikor az adatbázisba kerültek, be lett jegyezve, hogy melyik verziójú kategória tömbből lettek feltöltve a kategóriái.
Ezeket a verziókat mindig növeltem, ha változtatni kellett benne. Az új bejegyzések mindig a legújabbal kerültek be.A cikkek kategóriáit ellenőrző és módosító szkript pedig azzal kezdte a futását, hogy megnézte, melyik az aktuális kategória-verzió, indított egy egyszerű lekérdezést, ami visszaadta a nem ezzel a kategóriaverzióval "kezelt" cikkek id-jait, és így csak ezeken kellett az ellenőrzéseket és az esetleges módosításokat megcsinálni. A végén átírta a kategória-verziót az aktuálisra, az új rekordok pedig már az újjal kerültek be. És így tovább.
Most viszont így ez a plusz adatom (kategória-verzió) már nincs többé. Így nem látok más módot, csak azt, hogy minden egyes elemnél legeneráltatni, hogy az aktuális kategória-verzió szerint milyen kategóriákba tartozik egy-egy cikk, és ellenőrzöm egyenként, és ahol nem egyezik, átírom az újra.
Viszont ez rengeteg idő és energia, és azt hiszem tipikus példája az erőforráspazarlásnak.
Ha benne hagynám a kategória-verziót, akkor azt folyamatosan frissíteni kellene, szóval visszajutnék az eredeti kérdésemhez:
A kérdésem az lenne, hogy hol tartsam ezeket a "kiírt" kategórianeveket?
1) Legyen az "A" táblában a többi adattal együtt,
vagy
2) legyen egy külön "C" tábla, amiben csak ez a pár adat van, ami ahhoz kell, hogy rossz kategóriakiosztás esetén gyorsan át tudjam nézni, mi ment félre?És ugye itt a redundancia miatt inkább az 1)-es opció lenne a jobb.
Van esetleg más ötletetek, hogy ne legyen feleslegesen erőforráspazarló a dolog?
@nyunyu: Most látom, hogy írtál közben. Köszönöm, ránézek majd nemsokára.
-
Taci
addikt
Köszönöm szépen, ezzel így már szépen alakul.
Viszont még lenne benne csavar:
3 tábla van (példád alapján írom):
- 1.: cikkek (c.cim, c.create_date stb.)
- 2.: kategoria (k.id, k.nev)
- 3.: cikkek_kategoriak (ck.cikk_id, ck.kategoria_id): Mivel egy cikk több kategóriában is lehet, ezért javaslatotokra ezt külön szedtem ebbe a táblába, így minden rekord 1-1 kapcsolat a cikk és a kategória között. Ha egy cikkhez 3 kategória tartozik, akkor 3 rekord van hozzá.Amit írtál, az szépen visszaadja a kért adatokat, de csak a kategóriák id-ját, és ha egy cikkhez több kategória van, akkor annyi rekordot ad vissza.
Pl.: ha a cikk_id = 5 -höz van kategória 3, 15 és 22, akkor így adja most vissza:cikk_id ... kategoria_id5 35 155 22Viszont úgy szeretném, hogy cikkenként csak egy rekordot adjon vissza, és a kategoria_id-khoz tartozó szringeket (neveket) sorolja fel, vesszővel elválasztva.
Tehát ha a 3-as kategória a "belfold", a 15-ös a "kulfold", a 22-es pedig a "sport", akkor ezt adja vissza:cikk_id ... kategoria_nevek5 belfold,kulfold,sportEddig arra jutottam, hogy:
create view cikkek_vw asselect c.id cikk_id,c.cim cim,c.create_date datum,c.creator cikk_iro,ck.kategoria_id cikk_kategoria_id,k.nev kategoria_nevfrom cikkek cjoin cikk_kategoria ckon c.id = ck.cikk_idJOIN kategoriak AS kON ck.kategoria_id = k.id;(Lehet, ide most nem a legpontosabban írtam át, de a lényege ez, és nálam a valós kód szépen hozza.)
Tehát ez kiírja több rekordban, ha egy cikkhez több kategória is van, viszont így már odaírja a kategória nevét is, nem csak az id-ját.
cikk_id ... kategoria_id kategoria_nev5 3 belfold5 15 kulfold5 22 sportValahogy meg lehet csinálni, hogy 1 cikk csak egyszer szerepeljen (ezt a distinct vagy a group by megoldja), és hogy a különböző kategóriák vesszővel elválasztva egy új mezőben legyenek az adott egy darab cikk rekordjában?
Mert ez így valóban egy az egyben az lenne, mint a mostani külön tábla tartalma.@Ispy: Már megvolt, a sokadik is, már a ló túloldalon vagyok lassan...
-
Taci
addikt
Van egy kategória tábla (a cikkek és kategóriák kapcsolatairól), amiben a cikkek id-ja, és a kategóriák id-ja van, semmi más. Azt nem is szeretném bántani, mert 1-1 cikk id-hoz több kategória id is tartozhat, és ha mind után még odaírom szövegesen a kategóriák neveit, az egyrészt túl sok felesleges adat oda, plusz a "másik oldalról" is hiányozna ehhez a taskhoz adat, mert csak a cikk id-ját látom, a címét, szövegét nem.
Amit írtok (Ispy és DeFranco), ahhoz az kellene, hogy szerepeljen ez az adat (a "kiírt" kategórianév) valamelyik mezőben. De pont ez a kérdésem alapja, nem tudom, hol lenne jó helyen.
Viszont mivel kell lennie valahol, és a redundancia nem jó dolog, akkor talán az 1)-es megoldás a jobb.
-
Taci
addikt
Tanácsot kérnék a következő témában:
Adott az "A" tábla, benne a megjelenítéshez (HTML) szükséges adatokkal (cím, szöveg, kép linkje stb.
Adott a "B" tábla, amiben az ajánlásotokra csak az előző táblában szereplő rekordok ID-ja, és a hozzájuk kapcsolódó kategóriák ID-jai szerepelnek.
Ezzel nincs is gond, hála nektek tökéletesen működik.Viszont továbbra is szükségem van rá, hogy ne csak az ID-ját lássam a kategóriáknak, hanem a "kiírt" változatát is (pl. "politika"). Néha (gyakran) egy-egy cikkhez rossz kategória kerül, ilyenkor meg kell néznem a címet, a linket, a leírást, és a hozzá rendelt kategóriákat, hogy aztán tudjam módosítani a kategóriák keresőszavainak tömbjét (ami alapján a kategóriák meghatározásra kerülnek), hogy utána a karbantartó szkript updatelni tudja a frissített tömb alapján (cron job - ellenőrzi, milyen verziójú kategória tömbbel lettek a rekord kategóriái létrehozva, és ha van frissebb, ellenőrzi, kell-e változtatnia).
A kérdésem az lenne, hogy hol tartsam ezeket a "kiírt" kategórianeveket?
1) Legyen az "A" táblában a többi adattal együtt,
vagy
2) legyen egy külön "C" tábla, amiben csak ez a pár adat van, ami ahhoz kell, hogy rossz kategóriakiosztás esetén gyorsan át tudjam nézni, mi ment félre?Mindenképp szükségem van ezekre az adatokra, mert amúgy csak a kategóriák id-jait látnám, aztán azt mire visszakeresem mindet, hogy most az 4542. rekordhoz tartozó 3, 12, 25 és 42-es kategória mi, és melyik került "hibásan" oda, az túl sok idő lenne.
Sokkal egyszerűbb az, hogy látom a cikk címét, szövegét és linkjét, látom kiírva, hogy milyen kategóriákba kerültek, és látom, hogy a karácsonyi vásárról szóló tudósító cikk egy nem megfelelő kategóriatömb-bejegyzés miatt került az auto-motor kategóriába, és egyből tudom, mit kell módosítanom.Azért nem jutok ezzel dűlőre, mert, folyamatosan frissítenem kell a rekordokat, hogy a jó "kiírt" kategórianevek szerepeljenek benne.
Ha az 1)-est választom, akkor emiatt az amúgy sehol sem használt adat ("kiírt" kategórianév) miatt kell folyamatosan update-elgetnem a fő táblát - bár annak csak ezt a sehol nem használt mezőjét. (És úgy rémlik, erre azt mondta itt valaki anno, hogy nem jó ötlet.)
Viszont ha a 2)-est választom, akkor redundancia lesz, mert az "A" táblában már szerepel pár mező, amire az ellenőrzéshez szükségem van mindenképp (cím, szöveg, link). És a redundancia nem jó adatbázisban, ha jól sejtem. Ezek az adatok mondjuk sosem lesznek többet frissítve, szóval abból nem lehet gond, hogy csak az egyik helyen frissülnének.Egyik megoldás sem ideális, de nem tudom, melyik a jobb (vagy kevésbé rosszabb).
Tudnátok ebben tanácsot adni? Készen van már mindkét változat, kipróbálva, működik, csak nem tudom eldönteni, melyikkel menjek tovább.
Köszönöm. -
Taci
addikt
Lehet, ez buta kérdés, de ma valahogy eszembe jutott, hogy van a MySQL-felhasználó, amit az adatbázishoz "kapok" a szolgáltatótól.
Van értelme annak, hogy a weblappal kapcsolatos műveletekhez (rekordok felvétele, lekérdezése és frissítése) létrehozzak egy másik felhasználót, aminek csak a valóban elengedhetetlen jogokat adom meg?
Mert most a tesztkörnyezetben a "fő felhasználót" állítottam be, de szerintem az úgy nem lesz az igazi (főleg biztonsági szempontból talán).Pl. nem kell, hogy tudjon rekordot/táblát/mezőt/bármit törölni, így nem kap Delete-jogosultságot. Csak mondjuk Select, Insert, Update. (Data)
A Structure-nál kell gondolom a táblákkal kapcsolatos funkciókat beállítani, szóval ott pl. nem kellene semmi.
Az Administration rész még nem tiszta, annak utána olvasok.
Ti használtok külön felhasználót ezekre a feladatokra?
Ha igen, milyen jogosultságokkal bír, milyen feladatokhoz?Köszi.
-
Taci
addikt
válasz
nyugis21
#5267
üzenetére
Nekem személy szerint Access-szel semmilyen tapasztalatom nincs, de persze általános SQL-kérdésekben szívesen segítek, ha tudok.
És eltanácsolást semmiképp nem fogsz kapni, szerintem nagyon jó, ha valaki belevág valami új dolog megtanulásába. És ez a fórum tele van segítőkész tagokkal, szóval szerintem jó helyen vagy. -
Taci
addikt
válasz
 crmtanulo
#5263
üzenetére
crmtanulo
#5263
üzenetére
Én ezeket mondanám:
- HTML: Ez a weblap tartalma, amit látsz, a szövegek, a képek.
- CSS: Ez formázza a HTML által visszaadott szöveget, képeket. Ez mondja meg, hol legyen, mekkora legyen, hogyan nézzen ki, animál stb.
- SQL: Ezzel kéred le az adatbázis tartalmát, ezzel írsz bele, frissíted, törölsz stb.
- PHP: Szerver oldalon ezzel kommunikálsz az adatbázissal (SQL-lekérdezésekkel), és dolgozod fel a tartalmát, készíted elő a lekérdezéseket, küldöd a klienseknek a visszakapott, feldolgozott adatokat stb.
- JavaScript: Kliens oldalon ezzel kommunikálsz a szerverrel, ezzel küldesz és kérsz adatot a szerver irányába, ezzel fogadod a szerver oldalról a PHP-n keresztül érkező adatokat, illetve a "kliensen történő kattintgatások" is ezen keresztül realizálódnak (pl. gombra kattintás mit csináljon). Továbbá módosíthatod vele a HTML tartalmát, manipulálhatod a megjelenést is, feldolgozhatod a PHP által visszaadott adatokat, illetve a másik irányba, a szerver (PHP) felé is adatokat küldhetsz.Nagyon nagy vonalakban.
Biztosan vannak egyszerűbb megoldások is, de én csak ezt ismerem, ahol én kontrollálhatok mindent, mert minden úgy működik, ahogy én írom meg. (Ennek összes előnyével és hátrányával.)
Ezeknek mindnek van külön topikja is (HTML, CSS, JavaScript, PHP és SQL (a jelenlegi topik)), illetve van egy általánosabb, a Weblap készítés topikja.
Illetve én a W3Schools oldalát ajánlom, példákon keresztül lehet megtanulni az alapokat, az összes említett nyelven/technológiával.
-
Taci
addikt
Izgalmasan hangzik.
Bár élvezetes valószínűleg akkor lehetett (volna), ha nem tegnapelőttre kérik a megoldást. De azért ez az eredmény biztosan nagyon jó érzéssel tölthetett el. SQL-ben már nem volt több nyitott kérdés a listámban, csak ez a kettő, ezért tettem fel így a végén. Közben még JS- és PHP-oldalon van teendőm (a tesztek során ami hibát találtam, összeírtam, azokat javítom, és tesztelem újra).
Nagyon szeretném már elindítani az oldalt. Eredetileg nyár elején akartam, viszont ott vettem észre, hogy az SQL-oldalt nagyon rosszul raktam össze. Most már (a Ti segítségeteknek hála ) az a rész úgy néz ki, rendben lesz.
) az a rész úgy néz ki, rendben lesz.
De ha már ennyit "késtem", nem kapkodom, próbálok átgondolni mindent, előre is tervezni. Inkább induljak később, de minél kevesebb probléma legyen a későbbiekben - főleg ha azokat még most "elkaphatom". (De azért kategorizáltam a To-do lista elemeit is, van, ami azonnal megoldandó (mert rosszul működik, rossz eredményt ad stb.), de van amit v1.1-ként jelöltem csak, hogy majd indulás után ráér bőven.) -
Taci
addikt
Köszönöm a magyarázatot, így már világos.
@martonx: Neked is.
Amúgy csinálom, folyamatosan. Azért jött fel ez a legutóbbi két kérdés, mert anno amikor nagyon-nagyon elakadtam, akkor találtam egy srácot, aki órabérben ránézett az egészre, ő tett jó pár javaslatot és kommentet, és ezeket én feljegyeztem (a to-do listámba). Vele azóta sajnos nem tudtam beszélni, a kérdések pedig ott voltak nyitott pontként, és most, hogy végre a keresés részét is rendbe raktam (és a hozzá kapcsolódó pontok kikerültek így a listából), utamba került ez a két kérdés is, ezért kértem tanácsot velük kapcsolatban. Mert ha olyan dolgok lettek volna, amikkel előre számolnom kell (és a kódokat hozzájuk igazítanom), akkor még indulás előtt történjen.
Köszönöm a türelmeteket és a segítségeteket. -
Taci
addikt
Az indexekkel kapcsolatban annyit hadd kérdezzek már még, hogy kell-e őket valahogy "kezelni, karbantartani"? Van nekem bármi dolgom velük a létrehozásukon kívül? Mert elsőre azt gondolnám, hogy minden más már a rendszer dolga lenne, de azért inkább rákérdezek, hátha figyelnem kell (majd idővel) valamire, bármire.
Első körben ezt találtam: [link]
Ezt úgy tudom elképzelni, hogy (maintenance módban) az indexeket újraépítem majd, ha szükség lesz rá (törlés, és újra létrehozás), ahogy írja is.
-
Taci
addikt
Lenne egy egyelőre csak elméleti kérdésem.
Ha jól tudom, valahogy összefüggésben van az indexelt mezők száma, illetve az adatbázisba való írás sebessége: minél több mező van indexelve, talán annál több idő a rekordok adatbázisba való írása. Ezt jól tudom?
Azt szeretném kideríteni, van-e olyan "váltópont", ahonnan már annyira belassulna az adatbázisba való írás, hogy nem érné meg az indexelés használata.
A kérdés háttere:
5 percenkénti kb. 100-400 új rekorddal számolva (még ezt nem tudom, mennyi lehet valósan, de itt körül, szóval legyen ennyi a példa kedvéért) megéri-e full text search-re átállnom a gyorsabb keresés kedvéért?
Ehhez ugye be kell állítanom full text indexet azokra a mezőkre, amiben keresni akarok. Pl.:
ALTER TABLE feed ADD FULLTEXT(title)
ALTER TABLE feed ADD FULLTEXT(description)Viszont mivel elég sok rekord kerül a táblába folyamatosan, azt szeretném kideríteni, hogy emiatt (és a többi) indexelés miatt lehet-e gond később (bármikor, akármikor) a teljesítménnyel, esetleg belassulhat-e annyira az adatbázisba való írás, hogy az 5 percenkénti cron job "túl sűrű" lesz, mert ennyi idő alatt nem végez az új rekordok tárolásával?
Lehet, hogy teljesen alaptalan a "félelmem", de ez a kérdés bennem van már egy ideje, de még csak most jutottam a keresés rendbe tételéhez.
Jelenleg jobb híján a LIKE %%-os keresést használom, kb. 1 mp a lekérdezési ideje egy 300e-res táblánál, szóval nem vészes, úgyhogy az sem tragédia, ha ez marad egy ideig. Plusz a full text search-keresés amúgy sem olyan egyszerű, mint jó lenne.
-
Taci
addikt
Ezért is fontos a QA.
Meg a lomtár. Én most egy kicsit értetlenül is álltam a dolog előtt, mert egy ilyen hibát észrevettem volna ennyi idő alatt (már kerestem egy ideje, nem egyből ide jöttem segítséget kérni).
Aztán rájöttem, hogy egy régi lekérdezést mutattam példának, azt átalakítva a problémához - viszont a problémás lekérdezés nem ez volt...
Szóval most átírtam a példához újra: DB Fiddle
De hátha ez is egy teljesen egyértelmű hiba részemről csak, hogy itt nem úgy működik, ahogy szeretném.
Ránéznél, kérlek?
-
Taci
addikt
Saját kútfőből erre jutottam: DB Fiddle
Van esetleg valakinek jobb/másabb ötlete? Valós adatbázison még csak most fogom kipróbálni, nem tudom, mennyire lehet gyors/lassú.
@nyunyu: Most látom csak, hogy írtál, máris nézem, köszönöm.
Oh, valóban, pont ellenkezőleg gondolkodtam... Köszönöm az irányba állítást! -
Taci
addikt
Adott ugyanaz a témakör, ami korábban is.
A kérdésem a következő lenne:Adott példának okáért ez a lekérdezés: DB Fiddle
Itt ami fontos lenne nekem, hogy ha egy kategóriára azt mondom, hogy nem érdekel (
category_id not in (27)), akkor azokat az elemeket ne jelenítse meg, amikhez ez a kategória hozzá van rendelve. (Pl. ha azt mondom, allergiás vagyok a mogyoróra, akkor ne mutasson olyan recepteket, amiben mogyoró van)Ezzel az adott lekérdezéssel viszont nem így működik.
Direkt úgy módosítottam a példát, hogy könnyen látni lehessen:INSERT INTO `items_categories` (`id`, `item_id`, `category_id`) VALUES(349, 117, 27),(350, 117, 26),(351, 117, 29)Tehát 117-es elem benne van a 27-es, 26-os és a 29-es kategóriában.
Ha én azt kérem, hogy azokat az elemeket ne jelenítse meg, amik a 27-es kategóriába tartoznak (
category_id not in (27)), azt várnám, hogy a 117-es elemet nem jeleníti meg egyáltalán.Viszont ebben a formájában ez nem így működik, mert ezzel csak azt érem el, hogy eredménybe visszaadja a 117-est is, mert a 3 rekordból kizárja azt az egyet, ami a 27-es kategóriás, viszont a maradék kettő miatt a találati listában marad.
Hogyan lehet megoldani ezt?
Köszönöm.
-
Taci
addikt
Lehet, triviális a válasz, de:
Egy Count-lekérdezés végrehajtása ugyanannyiba kerül, mint pont ugyanannak a query-nek a Count nélküli változata?
Azért merült fel a kérdés, mert ha a Count nélkülivel eleve megkapom magukat az elemeket is, akkor ha csak a Count-ban tér el a két query, abban az esetben nincs értelme a Count-ot használni, hisz' az csak az elemek számát adja vissza, míg a másikkal megkapom az elemeket is, amiket aztán meg összeszámoltatok egyszerűen.
(Nyilván lehet millióféleképpen használni, én sem csak így használom, de amikor pont ilyen eset lenne, hogy a Count-on kívül minden más ugyanaz, akkor vajon ugyanannyi időt vesz igénybe mindkét lekérdezés? Tippem szerint igen, hisz' ugyanúgy kell elvégezni minden műveletet benne, így a Count csak összeszámolja az eredménytáblát "és kész".
De most már inkább rákérdezek.)
-
Taci
addikt
Sosem találkoztam még vele, úgyhogy ránéztem. És itt azt taglalják, hogy az SQL_CALC_FOUND_ROWS általában véve lassabb, mint a két külön query (az eredeti + a count).
Plusz ahogy olvasom, a jövőbeli verziókból már ki is szedik a támogatottságát:
The SQL_CALC_FOUND_ROWS query modifier and accompanying FOUND_ROWS() function are deprecated as of MySQL 8.0.17 and will be removed in a future MySQL version.
És hogy a COUNT(*)-ot ajánlják helyette.Köszönöm azért a tippet, legalább láttam, hogy ilyen is van (lassan: volt).
-
Taci
addikt
Illetve még azt kérdezném külön témaként, elméleti kérdésként:
Eddig úgy csináltam, hogy kértem 4 elemet (query, Limit 4), a kliens felhasználta, kért újabb 4 elemet, felhasználta és így tovább.
Tehát 4 elemenként volt egy query az adatbázisból. Per kliens.
Ez azért volt jó (inkább kényelmes), mert abban a pillanatban, hogy nem 4 elemet kapott a kliens vissza, megvolt, hogy nincs több elem, jöhet a no_more_items elem.Most azt nézem, hogy a Limit 64-gyel egyből betöltök 64 elemet. Ez nyilván 16-szor több (szöveges) adatot jelent egyben, viszont így is csak kb. 30 kB a Limit 4-nek a kb. 2 kB-jával szemben. 30 kB-nyi adat pedig semmi, és ezzel a query-k számát is drasztikusan leredukálhatom. (4 elemenkéti lekérdezés helyett csak 64 elemenkénti).
Viszont ezzel egy teljes szerkezeti változást meg kell csinálnom a PHP és a JS fájljaimban is. Amit persze szó nélkül megteszek, csak szeretnék előbb tanácsot kérni, hogy melyik a jobb út. Vagy van-e egy harmadik út, ami még jobb lenne.
Ha a szervernek "nem fáj" az ilyen sűrű lekérdezés (és nem is lassítja - több ezer felhasználó egyidejű lekérdezéseit figyelembe véve sem), akkor maradok a Limit 4-nél.
De ha ez a sűrű lekérdezgetés rossz hatással van a válaszidőre, és ezzel a felhasználói élményre is, akkor nézegetem a másik utat, hogy egyszerre több adatot kérek le, és az utolsó pár elemig azzal eldolgozgat a kliens lokálban, aztán a vége felé kéri az újabb adagot.
Vagy van valami más, jobb út?
Köszönöm.
-
Taci
addikt
válasz
sztanozs
#5140
üzenetére
Ha az általad írt lekérdezés által visszaadott össz-elemszámot szeretném megtudni (a belső limit nélkül - hogy később tudjak vele számolni, a belső limit meddig nyújtózkodhat - szóval a belső Select-et ezért veszem ki, plusz ugye nem kell rendezni sem (Order By), és a végén lévő Limit sem kell)), akkor jelen tudásom szerint azt így kérdezném:
SELECT COUNT(*) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id) AS tVan esetleg ennek hatékonyabb, gyorsabb, jobb módja?
Ezt találtam még:
SELECT COUNT(DISTINCT item_id) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)) AS tItt elvileg a Distinct kiváltja a Group By-t.
Viszont sajnos Count-hoz a phpMyAdmin nem ír lekérdezési időt, így nem tudom, melyik a gyorsabb. Vagy jobb.
Ebben kérnék tanácsot.
Köszönöm. -
Taci
addikt
válasz
sztanozs
#5140
üzenetére
 Na azért ez így hasít...
Na azért ez így hasít...
0.0096 secondsEzek szerint akkor nem kell "archiválni"? Akármekkorára is dagad a tábla, jobb egyben tartani? Vagy van egy határ valahol, ahol már szeletelni kell?
GROUP BY i.item_id, i.item_date
Itt miért kell az _id után a _date is, ha csak azért van a Group By, hogy egy-egy _id csak egyszer szerepeljen? (Csak szeretném megérteni.)Illetve még egy dolog jár ezzel a lekérdezéssel kapcsolatban a fejemben:
Ez egy nagyon jó és gyors lekérdezés. Azt hogyan lehetne legoptimálisabban megoldani, hogy ha a visszaadott rekordok száma kisebb, mint 4, akkor megnézze LIMIT 1000 helyett 2000-re is? Mert ha 2000-ben a talált rekordok száma nagyobb egyenlő mint 4, akkor onnan kell az eredmény, és akkor a következő görgetős lekérdezéshez is már a 2000-et kell használni, mert az 1000 nem volt elég.
Ehhez elég gyors ez a lekérdezés már, úgy gondolom, hogy kettő egymás után is beleférjen, ha kell.Hogy a gyorsabb/jobb?
1) Futtatom a query-t, aztán számoltatom php-ben a rekordok számát, és ha kisebb, mint 4, akkor jöhet az újabb query 2000-re?
2) Vagy előbb "üresen" csak egy Count, és az eredmény függvényében a valós (rekordokat visszaadó) lekérdezés?
3) Vagy van valamilyen COUNT-os utasítás (esetleg feltételes is) hozzá, amivel ezt még SQL-oldalon meg lehetne oldani? Ami akár egy lekérdezésen belül visszaadja, hogy az 1000-es limittel mennyi rekordot adna vissza, és ha 4-nél kevesebbet, akkor egyből futtatja 2000-re?Egy Count biztosan sokkal gyorsabb, mint az összes érintett mezőt visszaadni, és azt számoltatni, csak ezért jutott eszembe a kérdés.
-
Taci
addikt
válasz
sztanozs
#5137
üzenetére
Köszönöm szépen a részletes magyarázatot és okfejtést! (És mindenki másnak is, aki segített!)
Mindezt figyelembe véve még az az elméleti kérdés jutott eszembe, hogy:
Csakis és kizárólag a legfrissebb dátumú elemek vannak elől. Egyszerre mindig csak 4 elemet kap a felhasználó, mindig a (kiválasztott kategóriának stb. megfelelő) 4 legfrissebb dátumút. Mindig.
Ezek a rekordok pedig 5 percenként kerülnek az adatbázisba, kb. 5-10-esével / forrás, 20-30 helyről egyszerre.
Aztán ha görget a lap aljáig (mínusz X pixel), akkor következő 4 és így tovább. 25 görgetés 100 rekord. 250 görgetés 1000 rekord. 750 görgetés 3000 rekord. Ennyit nem fog senki soha egy huzamban végig pörgetni a szűrési feltételek módosítása, vagy ráfrissítés nélkül (ahol 0-ról kezdődik az egész).
Plusz a következő "4-esbe" az időközben bekerült új rekordok is benne kerülnek, szóval egyre kevésbé valószínű, hogy "túl mélyre ér" (a rekordok időbélyegzőit figyelembe véve).Így a tábláknak (items) nem kellene csak max 3 ezer (az items_categories-nak pedig átlag 3 kategória/item-mel számolva max 9 ezer) rekordot tartalmaznia. Tehát a mostani példa adatbázisomnak (300e / 900e) a század részét.
Most levittem erre a számra a rekordok számát, és így az eddigi 0,5 mp-es lekérdezés 0,01 mp-re (sőt inkább alá) szelídült. Azért ez már élhető. Még ha a duplájával számolnék (rekordszám) a biztonság kedvéért, akkor is.
A legfrissebb 3000 utáni rekordra pedig csak és kizárólag a szöveges keresésnél lehet szükség, ott pedig belefér egy lassabb (Union miatt) lekérdezés is.
Illetve még akkor is, ha mondjuk csak 1 kategóriát néz, és abban a legfrissebb 3ezerből csak kb. 100 rekord van (30+ kategória van), és 25-től többet scrollozik - ami azért nem olyan sok. Inkább megnéztem most gyorsan 6e/18e rekordra, 0,03 mp alatti a lekérdezés, és így "biztonságban is lennék" minden téren.A kérdésem az lenne, hogy:
1) ezt jó ötletnek tartjátok-e,
2) ha igen, akkor hogyan lenne jobb az "archív" rekordokat tárolni? Minden, ami nem a 3000 (vagy 6000) legfrissebben van benne, az legyen egyetlen egy darab (mondjuk items_archive) táblába áthelyezve? Mert ha jól emlékszem, azt mondtátok, hogy ahol ugyanazok a mezők vannak, nem jó ötlet szétszedni.
Viszont azt is mondták, hogy mindenképp kell "archiválni" is.
Tehát egy nagy archiv tábla legyen (items_archive), vagy legyen mondjuk évenkénti? (items_archive_2021, items_archive_2022 stb.)
Úgy gondolom, csak kereséseknél kellene használni az archívokat, normál használattal görgetve oda már "nem jut le senki" (de biztos ami biztos, felkészíteném arra is).@nyunyu: Az SQL Server Express-t most raktam fel, már a táblákat töltöm. Kíváncsi leszek az ottani eredményekre.
-
Taci
addikt
válasz
sztanozs
#5126
üzenetére
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4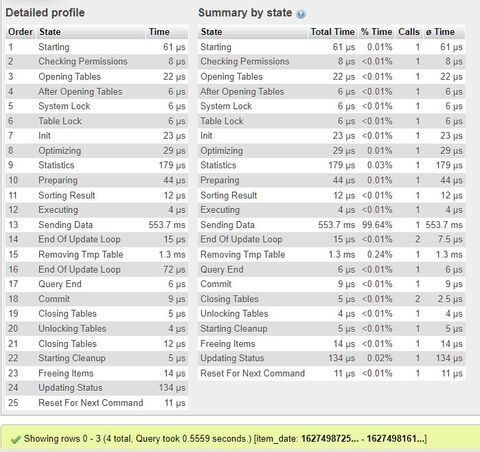

(valami régi kódból maradt benne a neve, a feed_id az az item_id az index nevében)
Mivel itt azt mondja, hogy az items_categories táblán nem használ indexet (key = NULL), ezért arra gondoltam, akkor létre hozok egy covering indexet ide:
CREATE INDEX idx_category_id_item_id ON items_categories (category_id,item_id)A sebességen nem javított, de most már így néz ki az explain:

----------
SELECT i.item_id, i.item_dateFROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id, i.item_dateORDER BY i.item_date DESC LIMIT 4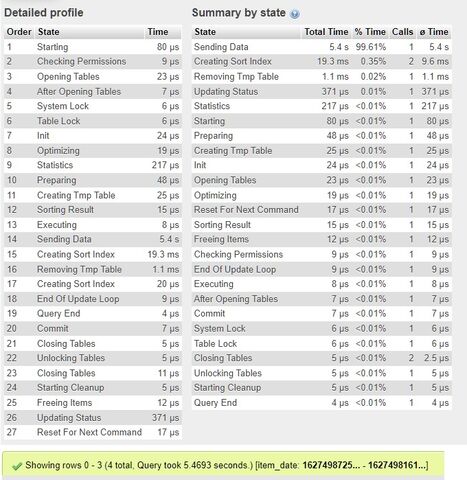

Itt ha a
GROUP BY i.item_id, i.item_date
helyettGROUP BY i.item_id
van, akkor ennyi a változás:
De időben semmit nem jelent.
-
Taci
addikt
válasz
martonx
#5131
üzenetére
Már fontolóra vettem, ha másért nem is, hogy lássam, ott is ugyanez-e a sebesség. Plusz ugye a Weblap készítés topikban szolgáltatóválasztásnál az Azure-t ajánlottad.
Egyelőre nem köt semmi a MySQL-hez, csupán pár lekérdezésem van, aminek jól (gyorsan) kellene működnie (az itt tárgyalt a legfontosabb), ezekben meg annyira nem lehet semmi specifikus, vagy ha igen, akkor van alternatívája.
Teszek egy próbát vele. -
-
Taci
addikt
válasz
sztanozs
#5126
üzenetére
Mondjuk egy-egy execution plan-t jó volna látni mindegyikre...
Ezekre a fajta információkra gondolsz (a lekérdezés egyes részei mennyi ideig futottak, használt-e indexeket stb.), amit az Explain és a Profiling ad? (Google-ön rákeresve az execution plan-re phpMyAdminban ezeket dobta fel.)
Mert akkor megcsinálom.
-
Taci
addikt
válasz
sztanozs
#5124
üzenetére
Köszönöm szépen a sok energiát amit bele fektettél.
Az indexeléssel kapcsolatos módosítás nem hozott érezhető eredményt. (Amúgy ha Order By DESC van a lekérdezésben, akkor az indexet is DESC alapján kellene létrehozni, nem? Csak mert ASC-t írtál. De amúgy próbáltam mindkettővel, nincs változás sajnos.)
A Join-os lekérdezés sajnos minden formájában szörnyen lassú, ha van benne Group By is.
- Copy-past amit #5124-ben írtál: 7.6651 seconds.
- Group By nélkül: 0.0278 seconds. (Csak így egy-egy rekord (az amúgy jó eredményekből) többször is benne van, ami nem jó.)Közben hogy kiszűrjem, hogy nem-e az én lokál gépeimen (kettőn építettem fel és futtattam a lekérdezéseket) van-e a gond, kipróbáltam egy ingyenes szolgáltatónál is (000webhost.com, a célnak megfelelt tökéletesen).
Sajnos ugyanaz az eredmény.Elképzelhető, hogy ennél a 300e rekord az egyik táblában, és 900e rekord a másikban (és ezek összekötve), itt ez a max lekérdezési sebesség? A leggyorsabb helyes eredményt az #5112-ben leírt lekérdezés hozta, 0,5 mp. Ami lassú így is.
Szóval lehet, hogy ha majd elérek 100e bejegyzés környékére (az első táblában), akkor el kell gondolkodnom a régi rekordok "archiválásán"? Hogy a fő táblában ne legyen 100e rekord fölött, és akkor "megúszom" a lekérdezéseket (amik persze csak a fő táblából kérdeznek le, nem az "archivakból") kb. 0,2 mp alatt?Több ötletem nincs. És köszönöm szépen nektek ezt a sok segítséget és próbálkozást, nem akarok visszaélni a jóindulatotokkal.
-
Taci
addikt
Meg lehet azt valahogy csinálni, hogy ne a subquery-ben lévő Select-re (select item_id) alkalmazott fő Select-re (select item_id, item_date) alkalmazza az Order By-t, hanem csak a fő Select-re?
Ahogy írtam is a bejegyzésben, amire itt válaszolok most, külön-külön gyorsak a lekérdezés részei:
select item_idfrom items_categorieswherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)
Showing rows 0 - 24 (768981 total, Query took 0.0232 seconds.)SELECT item_id, item_dateFROM itemsORDER BY item_date DESC LIMIT 4
Showing rows 0 - 3 (4 total, Query took 0.0057 seconds.)És ha egyben van, akkor pedig az egészre nézve az Order By lassítja le:
Order By benne:
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.5749 seconds.)
Order By nékül:
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.0295 seconds.)
Ezért gondoltam arra, ha a Group By-t "le lehetne tudni hamarabb", akkor már kellően gyors lehetne az egész lekérdezés. Mert így a join-olt (ez így subquery-vel amúgy Join-nak számít?) táblán sokat időzik az Order By miatt - amire amúgy már az elején, az első Select-nél is meg lehetne csinálni, mert úgyis csak abban van a mező, ami alapján rendez, így kár a kibővített találati táblán rendezgetni.
Így lehetne optimális:
SELECT item_id, item_dateFROM itemsORDER BY item_date DESC -- <----WHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))LIMIT 4Persze ez itt a szintaktika nem helyes. Ahogy nézegettem, kb. ilyesmi módon lehetne helyesen lekérdezni:
SELECT item_id, item_dateFROM(SELECT item_id, item_dateFROM itemsORDER BY item_date DESC) AS iWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)) LIMIT 4És ez már elég gyors is:
Showing rows 0 - 3 (4 total, Query took 0.0156 seconds.)Viszont itt van egy furcsaság:
Nálam a saját gépemen futtatva más eredményt ad a 2 változat. Az első (ahol a Group By a végén van) adja a helyes eredményeket, ez a legutóbbi pedig teljesen más rekordokat mutat, és nincsenek item_date alapján rendezve sem.VISZONT
DB Fiddle-ben ugyanazok az eredmények, tehát ott meg elvileg jó az új lekérdezés:
- Eredeti: [link] (item_id: 213, 212, 210,208)
- Új: [link] (item_id: 213, 212, 210,208)Erre az új fajta lekérdezésre, és a különböző eredményekre tudtok mondani valamit?
Esetleg finomítani ezen a változaton? (Ha pl. nem raktam bele az "AS i"'-t, akkor szólt, hogy "Every derived table must have its own alias". Így viszont a Where után lehet, hogy i.item_id kellene? Bár nem változtat az eredményen. Csak hátha ti láttok még benne valamit, azért írtam ezt a példát, hogy ez nekem csak Google-keresés eredménye. Hátha lehet csiszolni.) -
Taci
addikt
válasz
sztanozs
#5107
üzenetére
Értem a logikát mögötte, és amúgy tök jó ötlet, köszönöm a tippet - de sajnos kb. 0,2 mp-cel lassabb, mint az előző.
Csak kíváncsiságként:
Itt az ORDER BY 2 ugye a második mezőt jelenti, ami jelen példában a MAX(item_date)? Ha sok mezőm lenne a SELECT-ben, és nem akarnám számolgatni, ide írhatnám azt is az ORDER BY 2 helyére, hogy ORDER BY MAX(item_date)? (Most így lefut a lekérdezés, az eredmény ugyanaz, csak nem tudom, az ORDER BY-os résznél is műveletnek veszi-e a MAX-ot, vagy már a fenti SELECT-ben elvégzettre hivatkozik?) -
Taci
addikt
Még annyi, hogy külön-külön a rész-lekérdezések gyorsak:
select item_idfrom items_categorieswherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211)
Showing rows 0 - 24 (768981 total, Query took 0.0232 seconds.)SELECT item_id, item_dateFROM itemsORDER BY item_date DESC LIMIT 4
Showing rows 0 - 3 (4 total, Query took 0.0057 seconds.)Szóval nem tudom/értem, összekapcsolva hogyan lesz ebből 0.8 mp.
-
Taci
addikt
válasz
bambano
#5104
üzenetére
Talán ez lehet a jó irány...
Most így néznek ki a lekérdezések:
Az "eredeti" (a javasolt változtatásod előtti):
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 10.8688 seconds.)
A categories tábla kivétele a Join-ból:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idWHEREic.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 5.0478 seconds.)
A subquery-s megoldás (WITH-et nem engedett használni, így most ezt a megoldást találtam a "helyettesítésére"):
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.7163 seconds.)
(És ide már nem is kell a Group By.)
Frissítettem a db-fiddle-t vele.
Mind a 3 változat ugyanazt a 4 rekordot adja vissza, helyesen.
Ez utóbbi, az általad javasolt valóban sokkal gyorsabb - bár (lehet, az én implementálásom miatt) még így is lassú (0,8 mp környéki lekérdezés).
(Furcsa mód ha kiveszem az Order By-t belőle (ami eddig csak lassította), a 0,8 mp-ből 6,6 mp lesz...)De ezzel talán már el lehet indulni ebbe (subquery) irányba.
Még valami ötlet esetleg ehhez az irányhoz?Köszönöm a tippeket és hogy ránéztél!
-
Taci
addikt
válasz
martonx
#5100
üzenetére
Próbáltam azt is, kicseréltem a *-ot 2 mezőre, de csak minimálisat gyorsult, annyit, amennyivel kevesebb adatot kellett visszaadnia. (Jelen lekérdezésnél 18mp helyett 17mp.)
Próbáltam azt is, hogy a most fent lévő xampp lite mellé felraktam a legfrissebb xampp-ot is, feltöltöttem adatokkal - és ugyanez a helyzet. Szóval nem a rendszer valamilyen hibája.
Annyit vettem észre "változást", hogy a "Copying To Tmp Table On Disk" helyett most a "Sending Data" veszi el a sok időt. De a végeredmény ugyanolyan lassú.
@bambano: Distinct-et nem használok, mert a join-olás miatt 1-1 bejegyzéshez az eredeti táblában (itt item) több kategória is tartozik, azok így több külön rekordba kerültek, és mivel így van több unique rekord ugyanahhoz az item_id-hoz, így sajnos nekem nem jó. (Mivel pont hogy az item_id-ra akartam volna használni a distinct-et.)
-----
Gondoltam, megnézem már, hogy a lekérdezés melyik része lassítja le az egészet amúgy.
Így néznek ki:Where, Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idShowing rows 0 - 24 (901830 total, Query took 0.0165 seconds.)
Egy kérdés itt:
Amúgy az miért van, hogy habár azt írja ki, hogy 0.01 mp-ig tartott a lekérdezés, mégis, a lekérdezés indítása után kb. 5-7 mp-cel jelenítette csak meg ezt az eredményt?
A lekérdezés gyors, de mégis csiga lassan adja vissza az eredményt?
Most akkor a szememnek higgyek vagy az adatoknak?------
Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)Showing rows 0 - 24 (768981 total, Query took 0.0351 seconds.)
------Group By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)ORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.0420 seconds.)
------Minden benne:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 2.5095 seconds.)
------Szóval Group By (vagy Distinct) nélkül gyors a lekérdezés (bár mintha erre is lett volna cáfolat korábban, már nem tudom, annyi tesztet csináltam, már kavarodnak az eredmények).
Közben átmentem a másik (lokál) szerverre, és ott meg ugyanez a lekérdezés már az Order By-jal is belassul... Tök jó, hogy mindig változó eredményt kap, segít megtalálni a hibát...Még annyi ötletem van, hogy választok egy szolgáltatót, és reménykedem benne, hogy csak az én lokál telepítéseimen szerencsétlenkedik a kód (és én), és éles szerveren rendben lesz.
Egy kérdés:
Ha egyszer tényleg jó lenne a lekérdezés (mármint Group By vagy Distinct nélkül), hogyan tudnám "pótolni" azok funkcióját?Mert tegyük fel, ezeket a rekordokat adta vissza most eredményül:
item_id | category_id | item_date11 | 32 | 21111 | 27 | 21111 | 13 | 21135 | 7 | 165De így a 11-es item_id 3-szor szerepel, nekem pedig az kell, csak 1-szer legyen, akármi is van.
A Distinct nem jó, mert a különböző category_id-k miatt egyedi minden rekord, tehát szerepelni fog mind ugyanúgy külön.
A Group By nem jó, mert szörnyen lelassítja.Milyen megoldás jöhet még szóba?
-
Taci
addikt
válasz
martonx
#5094
üzenetére
Sajnos semmin nem változtatott, ~300e rekordnál a lekérdezésed ~13 mp alatt dob csak eredményt.
Viszont a Profiling szerint a legtöbb időt a "Copying To Tmp Table On Disk" viszi el.
És amit korábban linkeltem magyarázat szerint rendesen indexelt tábláknál ez a lépés nem is kellene, hogy ott legyen:
"But generally speaking, the indexed sort would probably be chosen, if for no other reason, because it does not need to accumulate the entire result set in temporary storage before sorting and thus uses much less temporary storage."Szóval ebből gondolom, hogy talán az indexeléssel lehet baja. Csak azt nem találom, mi. Egy (a lekérdezésnél használatlan) mezőn kívül mind indexelve van. A rajzolást már elkezdtem, hátha a végére jutok valahol.
-
Taci
addikt
válasz
martonx
#5092
üzenetére
Köszönöm, hogy ránéztél.
Nem Select *-ot fogok használni, viszont itt nincs annyi mező, hogy a query-t bonyolítsam vele, így az olvashatóság kedvéért ehhez a példához elégnek találtam.
A Group By-nak tényleg nem jártam alaposabban utána még - főleg azért nem, mert ahogy írtad is az okát, működött, így nem gondoltam, hogy baj van vele. Mindenképp alaposan utána járok most már, már amikor tegnap a hibát láttam, akkor felírtam a teendők közé.
Megfogadom a tábla- és mezőneves tanácsodat.
Nem item a tábla neve ("rendes" neve van), de a fenti (egyszerűsítő) törekvés miatt ebbe a példába elégnek találtam.
Sajnos igen, ez a db fiddle-teszt nem elég arra, hogy itt és ennyi adattal kiütközzön a hiba úgy, mint sok adattal nálam.
De köszönöm szépen az ötletet is, és hogy ránéztél.
-
Taci
addikt
válasz
martonx
#5083
üzenetére
Sikerült feltöltenem, bár nem túl sok adattal: db-fiddle
(Fel akartam tölteni ~300e rekorddal, de nem hagyta, így nem akartam az időt húzni, hogy megtaláljam, hol a határ.)Eredetileg ezt a lekérdezést írtam bele (Group By-jal és Distinct nélkül):
SELECT *FROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Viszont erre ezt a hibát dobta:
Query Error: Error: ER_WRONG_FIELD_WITH_GROUP: Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.ic.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by -
Taci
addikt
Ezt a "gyorstalpalót" értelmeztem most, hogy mégis mi-miért történik a lekérdezésben, hogyan kapcsolódnak ide az indexek, és hogy min csúszhatott el a dolog.
Azt hiszem, nekiülök "rajzolni", hogy lássam, hogyan működik a lekérdezésem, és hogy hogyan lehetne "optimálisan kérdezni". Lehet, máshogy kell indexelnem.
Rajzolok, aztán remélem, rájövök. -
Taci
addikt
A category_id-ra szükségem van, nem szedhetem ki. (De amúgy a teszt kedvéért kivettem, és semmi sem változott, se a sebesség, se a distinct nem hozta a kívánt eredményt.)
Annyit találtam, hogy ha használom a GROUP BY-t is, akkor a megfelelő eredményeket kapom, és valamelyest gyorsul a lekérdezés is. (És DISTINCT-tel vagy anélkül is ugyanazt a (jó) eredményt adja, szóval így a DISTINCT talán nem is kell.)
select p.*from product pjoin product_category pc1on pc1.product_id = p.idjoin category c1on c1.id = pc1.category_idwhere c1.name in ('sárga', 'piros', 'kék')group by p.idorder by p.date desc;Így a korábbi ~20 mp helyett már megvan ~9 mp alatt.
És az explain-je is sokkal jobban néz ki:

De a 9 mp még mindig szörnyű.
Merre tovább?
Vagy ez nem is a jó út?
Az adatbázis szerkezete a hibás?
Vagy a lekérdezés?Jelenleg nyitott vagyok a teljes adatbázisszerkezet átalakítására is. Egyszer már megcsináltam a javaslatotokra, megcsinálom megint, ha kell. Csak működjön végre.
Mindenesetre keresgélek még, hátha találok ilyen hasznos dolgot, mint a group by. Bár néztem már annyi mindent, millió stackoverflow-bejegyzést...
-
Taci
addikt
válasz
bambano
#5077
üzenetére
Alapból a my.ini-ben ez volt:
innodb_buffer_pool_size = 16MEzt most kicseréltem ennek a tartalmára:
my-innodb-heavy-4G.ini
innodb_buffer_pool_size = 2GÍgy a lekérdezés első futtatása ugyanúgy ~20mp-ig tartott, viszont amikor újra futtattam, már csak 0.01-ig.
Szóval ennél a lekérdezésnél a memória bővítése valóban segített, viszont, csak addig, amíg pont ugyanezt a lekérdezést futtatom, mert így memóriából tudja újra felhasználni. Amint akár egy feltételt is módosítok, újra 20mp várakozás, memóriába töltés. Aztán megint változtatok, megint várakozás. És ez csak 1 felhasználó, nem 10e-100e.Szóval sajnos nem ez a jó megoldás, de azért köszönöm a tippet.
------
@martonx: Az a legelső ajánlásaitok egyike volt, azóta indexelve van. Írtam is 3 hozzászólással korábban, hogy indexelt a feed_date.
Az EXPLAIN-eknél látszik, hogy hiába indexelt, mégis, ha van DISTINCT és ORDER BY is, akkor átnéz és rendez 410e rekordot lekérdezésenként, ezért tart 20 mp-ig...

Ha csak az ORDER BY-t használom, akkor 0,01 mp:

Ha csak a DISTINCT-et használom, akkor is 0,01 mp:

------
És ha van mindkettő, DISTINCT és ORDER BY is, akkor nem a jó logika mentén alkalmazza a DISTINCT-et, mert ez a találat (a LIMIT 4-gyel):
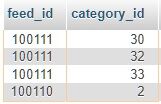
Tehát így a rekordok valóban különbözőek, viszont ezt ugye a JOIN-os nagy egészre nézi. És ebben benne van az általatok javasolt plusz tábla, amibe ki lettek szedve a kategóriák, hogy ha egy bejegyzéshez több kategória is tartozik, akkor az mind külön rekord legyen. És ezzel így összefűzve a DISTINCT valóban jó eredményt ad - csak rossz logika szerint:
nekem az kellene, hogy a feed_id-kra legyen vonatkoztatva, tehát a képernyőfotós példában a 100111 csak egyszer szerepeljen. -
Taci
addikt
Sajnos kb. pont ugyanez a kód (illetve a saját kiegészítéseddel ugyanez), amit írtál (és ami sztanozs tanácsára ki lett egészítve DISTINCT-tel), ez fut le eszméletlen lassan.
Bemásolom, hogy ne kelljen visszakeresni, és kiegészítem a DISTINCT-tel:
select distinct p.*from product pjoin product_category pc1on pc1.product_id = p.idjoin category c1on c1.id = pc1.category_idwhere c1.name in ('sárga', 'piros', 'kék')order by p.date desc;Ha benne van együtt a DISTINCT és az ORDER BY is, akkor ~20 mp, ha csak az egyik, akkor 0,05 mp a futási idő.
Plusz a DISTINCT nem is működik (úgy, ahogy elvárnánk), mert ha a product_category táblában egy id-hoz több category_id is van (és van, mert ezért lett ez a tábla létrehozva), akkor annyiszor listázza a product-ból az id-t. (Pedig pont ezért lenne használva, hogy egy id-t csak egyszer listázzon.)
A profiling opciót bekapcsolva ezt látom, ami "fura":
- Copying To Tmp Table On Disk: 18.9 s
- Sorting Result: 1 s
Tehát csak ez a 2 lépés 19.9 másodpercbe kerül, ha van DISTINCT és ORDER BY is.Ha csak az ORDER BY van, akkor:
- nincs Copying To Tmp Table On Disk lépés
- Sorting Result: 6 µsHa csak a DISTINCT van, akkor:
- Copying To Tmp Table: 2.8 ms
- nincs Sorting Result lépésAhogy utána olvastam, azt írják, hogy a DISTINCT és az ORDER BY is sorba rendez, és nem szeretik egymást. Azt is írják, hogy ha az egyiket használom, akkor a másikat valószínűleg nem kell. De hát ez itt nem igaz, mert a DISTINCT azért kell, hogy 1 id csak egyszer jelenjen meg (ami amúgy most sajnos nem igaz, ahogy feljebb írtam is), az ORDER BY meg azért, mert időrendi sorrendben van szükségem a találatokra.
Nagyon nem tudom, merre tovább. Követtem a tanácsaitokat, megcsináltam és átírtam mindent, ahogy javasoltátok, (amit köszönök ez úton is), de sajnos valami még nem kerek, és magamtól nem találok megoldást rá.
Higgyétek el, ég az arcom, hogy ennyiszer kell írnom, és segítségért kuncsorognom - nem jókedvemből teszem. Felajánlottam, hogy fizetek is a szaktanácsadásért és a segítségért, csak végre haladhassak, mert már 1 hónapja egy helyben veszteglek - de sehonnan nem kapok segítséget, sehol egy szakember.
-
Taci
addikt
Nagyon bénának és kapkodósnak érzem magam, pedig nem vagyok (kapkodós).
De ahogy most újra lefuttattam a lekérdezést (JOIN, amiben ott van az ORDER BY) is, láttam, hogy hiába van benne az elején a DISTINCT, a 4 találatból 3-nak ugyanaz a feed_id-ja.
Aztán fogtam, kiszedtem a DISTINCT-et (az ORDER BY ugyanúgy benne maradt), és a korábbi 19 mp-es lekérdezésből hirtelen 0.0615 mp-es lett... ugyanazzal az eredménnyel...
-
Taci
addikt
válasz
martonx
#5067
üzenetére
Megvan a "bűnös": az ORDER BY.
SELECT DISTINCT *FROM feeds AS fJOIN feed_item_categories AS ficON f.feed_id = fic.feed_idJOIN categories AS cON c.category_id = fic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDf.feed_id NOT IN (101,456,3566,32345,56432,223444,344456)ORDER BY f.feed_date DESC LIMIT 4Ha benne van: Showing rows 0 - 3 (4 total, Query took 19.2113 seconds.)
Ha nincs benne: Showing rows 0 - 3 (4 total, Query took 0.0541 seconds.)Pedig indexelt a feed_date.
Amikor explain-nel megkérdezem, mi történik, ezt mondja:
table: f
type: index
possible_keys: PRIMARY
key: feed_date
rows: 298917
Extra: Using where; Using index; Using temporary; Using f...A "régi" lekérdezést miért nem lassítja be az ORDER BY?
SELECT * FROM feedsWHERE(feed_category NOT LIKE '%cat1%'OR feed_category NOT LIKE '%cat2%'OR feed_category NOT LIKE '%cat3%'OR feed_category NOT LIKE '%cat4%')ORDER BY feed_date DESC LIMIT 4(Nem pont ugyanazt csinálja, mint a felső, csak azért másoltam be, hogy meglegyen, melyik a "régi".)
0.3591 seconds
Egyértelműen látszik, mennyivel gyorsabb a JOIN-os megoldás, de az a baj, hogy, hogy kell az ORDER BY - vagy legalábbis az lenne a fontos, hogy a leszűkített (WHERE) rekordlista teljes tartalmát időrendileg csökkenő sorrendben kell visszaadnom, négyesével.
Ezért csináltam úgy már eredetileg is, hogy megvan a feltételek alkalmazása (WHERE), aztán a találati lista rendezése (ORDER BY), aztán az első 4 listázása.
Aztán következő lekérdezésnél ugyanígy, csak a már korábban kilistázott elemek kizárása (id NOT IN...).Tudnátok tanácsot adni, kérlek?
-
Taci
addikt
Megcsináltam mindent, amit javasoltatok, pont úgy, ahogy javasoltátok. Készen és beállítva az új táblák, rendben a kapcsolatok az indexek, és a rekordszám is feltornázva 500e fölé (a kategória-elem kapcsolatok száma 800e körül).
És így a javasolt a JOIN-os lekérdezés ideje: 25 másodperc...
A régi, pazarló LIKE-os lekérdezés ideje: 0.3 másodperc (egy picit javítva a LIKE-os módon már csak 0.01 másodperc)...Nem értem.
Csak "érdekességként" írtam ide (bár nekem bosszúság), már találtam valakit, aki remote-ban tud segíteni - bár ő is pont ugyanezt a JOIN-os módszert mondta, miután átnézne a tábláimat.
-
Taci
addikt
Megcsináltam így, működik is szépen, aktívak az indexelések is.
Viszont így már nem tudom ugye duplikálni a rekordokat, mert a másik táblában (ahol a rekordokhoz tartozó kategóriák vannak tárolva) már nem lehet olyan könnyen.
Szóval most egyelőre 159 rekord van.És amiért most írok:
Összehasonlításként futtatom a régi lekérdezést (LIKE '%category%'stb.) és az új lekérdezést (JOIN).És az a régi:
- egyrészt dupla olyan gyors (sőt, 0.0112 vs 0.0266 seconds),
- másrészt az Explain szerint csak a szükséges 4 rekordot ellenőrzi/használja (rows: 4) az indexelés miatt (a 159 helyett).Hogy van ez akkor?
A sebesség talán most még az alacsony rekord szám miatt lehet, később, sokkal több elemnél ez talán majd fordul?
Viszont Ti is azt írtátok, és én is azt találtam, hogy ha a LIKE operátor %sztring formában van használva, akkor a teljes táblát használja.
Itt akkor rows: 4 helyett nem rows: 159-nek kellene lennie?Bocsánat a sok kérdésért, de ha már így alakult, hogy saját kezüleg kell csinálnom, szeretném érteni a miérteket. És köszönöm, ha válaszoltok, tanácsot adtok.
(És továbbra is szívesen fizetnék a segítségért, a mostani struktúra átnézéséért, módosítására javaslatért, tanácsokért stb., csak hogy biztos lehessek az erős és stabil alapban.)Köszönöm.
-
Taci
addikt
Sikerült egy úgy-ahogy rendszert összeraknom, megcsináltam a táblát, feltöltöttem ugyanúgy, ahogy otthon is tenném, minden ugyanaz, kivéve, hogy most csak 20 elemet raktam bele, hogy tudjam kézzel szerkeszteni az ajánlott új táblákat is, és ne menjen rá túl sok időm.
Kész mind a három tábla, mondom akkor indexelem a dátum mezőjét (ahogy otthon is tettem), és lekérdezem EXPLAIN-nel, hogy jól dolgozik-e, elsőre csak az alap lekérdezéssel, hogy legyen összehasonlítási alapom:
EXPLAIN SELECT * FROM table ORDER BY date DESC LIMIT 4Az otthoni rendszerben ez visszaadta, hogy
rows: 4, type: index.
Most azonban hiába ott van az indexelés (phpMyAdmin-ban egyértelműen látszik több formában is), ez a visszatérési érték:rows: 20, type: all.Tehát nem indexelt semmit.
Próbáltam kézzel is (CREATE INDEX table_date_ix ON table(date)), illetve grafikus felületen a megfelelő kapcsolóval. De ugyanaz az eredmény.Mi lehet ennek az oka? Túl kevés a 20 elem az indexeléshez? (Otthon 500e rekord volt a táblában, itt most csak 20.)
1. update:
Kíváncsiságból "felduplikáltam" kb. 100e rekordig, és most márrows: 4, type: index.
Ezek szerint a 20 kevés volt? Mennyi a "minimum limit"? Kézzel kell egyelőre dolgoznom, szóval nem mennék nagyon túl a minimumon, ha nem muszáj (és ha van ilyen, persze).2. update:
Visszatöröltem 20 rekordig, és most még mindig van indexelés...rows: 1, type: index.Ezt nem értem.
Itt azon kívül, hogy hogyan és miért lett hirtelen indexelés ugyanannyi elemre, azon kívül még azt nem értem, a rows értéke miért csak 1, amikor a lekérdezés (explain nélkül) 4 rekordot ad vissza. A rows: 1 pedig ugye azt jelenti, hogy 1 rekordot vizsgált át.
Hogyan ad vissza 4 rekordot, ha csak 1-et vizsgált át?El tudnátok magyarázni, kérlek?
Köszi.
-
Taci
addikt
(Mivel egyelőre még nem tudom kipróbálni a megoldást, így csak agyban tudok a témán "dolgozni", és az jutott eszembe, hogy) mi lenne, ha a ~30 kategóriának csinálnék egyszerűen mezőket a jelenlegi táblában? Lenne category1, category2 stb. nevű mező, értékként 0, ha a rekordhoz nem tartozik, 1, ha igen.
Így nem kellene LIKE-ot sem használni már, az eredeti lekérdezésSELECT * FROM tableWHERE channel_idIN ('id1','id2','id3','id4')AND(category LIKE '%category1%'OR category LIKE '%category2%'OR category LIKE '%category3%'OR category LIKE '%category4%'OR category LIKE '%category5%'OR category LIKE '%category6%')AND(category NOT LIKE '%category7%'AND category NOT LIKE '%category8%'AND category NOT LIKE '%category9%')ORDER BY date DESC LIMIT 4nézhetne ki így is:
SELECT * FROM tableWHERE channel_idIN ('id1','id2','id3','id4')AND(category7 = 0AND category8 = 0AND category9 = 0)ORDER BY date DESC LIMIT 4(Mert most látom csak, hogy feleslegesen szűrtem arra is, hogy milyen kategóriákat listázzon, ha egyszer már ott van az is, hogy miket NE, és csak 2 állása van (vagy benne van, vagy nincs)).
Ez lenne olyan hatékony, mint a 3 táblás JOIN-olás? Vagy még hatékonyabb, esetleg kevésbé?
(Most kíváncsi lennék, az EXPLAIN erre mit mondana.) -
Taci
addikt
Nagyon szépen köszönöm a tanácsokat, segítséget, a részletes példákat! Lesz mit átnéznem, értelmeznem és kipróbálnom.
Eljöttem pihenni/nyaralni 3 hétre, szóval lassabban tudok csak reagálni, és egyelőre "vasam" sincs még ezeket a tippeket kipróbálni sem, de szerzek valamit, és ha nem bánjátok, utána kérdezek még.
Nem webshop-motort fejlesztek, azt csak a Te példád miatt vittem tovább (product). RSS feed-ekből szedem ki az adatokat (cím, rövid tartalom, kép, link, illetve kategória), majd ezek az adatok mennek adatbázisba. Itt kerül képbe a kategória, mert van, hogy 1-1 feed elemhez több kategória is tartozik (előre definiáltak), és a jelenlegi megoldásomat ("category1,category2,category3" stb.) kell átírnom az általatok javasoltra, külön táblákba kiszervezve.
Illetve majd később szeretném a (valódi) lájkolást és kommentelést implementálni, lehet, azt is akkor legalább elő kellene majd készítenem
Köszönöm a sok segítséget, és az időt, amit erre fordítottál! És persze mindenki másnak is a tanácsokat, segítséget.
-
Taci
addikt
Most (utazás után, de még pár hétig nem otthon) volt egy kis időm jobban átolvasni és értelmezni, amit a 3 tábláról írtál. Teljesen jól érthető, köszönöm. Pár részlet még nem világos benne, de azoknak utánajárok.
Illetve 1 dolgot mégis kérdeznék a kódoddal kapcsolatban:
where c.name like '%akármi%'
Ha úgy csinálom, ahogy mondod, és ha 1 terméknek 3 kategória, és így 3 külön rekord a product_category-ban, akkor itt nem kellene már LIKE-ot használnom sem, hiszen rekordonként csak 1 kategória lenne. Szóval ez akkor lehetne inkább:where c.name = 'akármi', nem?
(Több kategóriára szűrésnél meg valami ilyemi:where c.name = 'akármi'or c.name = 'akármi1'or c.name = 'akármi2'
Javítsatok ki, ha tévedek, kérlek.)És ha jól értem, ugye azt írod, hogy csináljak egy product_category táblát, amibe úgy kerülnének bele a rekordok, hogy ha a fő táblámban (product) mondjuk van 2 millió rekord, és mindegyikhez tartozik 2-4 (átlagban 3) kategória (category). Akkor e szerint a product_category táblában jelen állás szerint 6 millió rekord lenne.
Ez tényleg gyorsabb, mint a 2 milliós? Bár gondolom, erre is írta tm5 a redundanciát (ha nem, kérlek írd meg, mire).
Meg hát ugye azt is írtátok, hogy LIKE-nál az egész adatbázist átnézi, nem számít az indexelés és semmi, szóval az mindenképp lassú.Na ezt nem kis idő lesz így átírnom. Mielőtt nekikezdek: ezt az utat javasoljátok akkor?
- Külön tábla a kategóriáknak.
- Külön tábla a termékek és kategóriák kapcsolatának.
- Lekérdezés előtt (már ahol aktív a kategóriára való szűrés) JOIN.Köszönöm.
-
Taci
addikt
Azt használom, amit a DesktopServer feltelepített nekem: MariaDB. Az alap beállításon van, nem néztem még rá a konfigurációjára. (De utánanézek, hol és hogyan lehet.)
Amit ajánlottatok, külön táblát létrehozni a kategóriáknak, azt egyelőre nem tudom, hogyan kell megcsinálnom, ennek is utánanézek. Illetve akkor lehet, hogy más mezőket is "ki kell majd szerveznem".
Szóval örülnék egy szaki-ajánlásnak.
-
Taci
addikt
Köszönöm a tanácsot.
Igazából már azt gondoltam, készen vagyok, mehet élesben a weblap (és vele az adatbázis), csak eszembe jutott, megnézem, hogyan viselkedik majd x év adatfelhalmozódása után. És mint kiderült, nem jól...
Szóval tényleg át kell alakítanom, mert így nem lesz jó hosszú távon, és most még bármit csinálhatok vele, bárhogy alakíthatom, mert még csak tesztfázisban van (bár már 1-2 hét múlva küldtem volna bevetésre). Viszont igazad van, ennek tényleg újra neki kell ülni. De sajnos úgy látszik, egyedül én ehhez kevés vagyok. (Így is csodálom, hogy saját erőből (plusz a Ti segítségetek itt, plusz Stackoverflow, plusz W3Schools stb.) fel tudtam ezt építeni, elég sok ez (HTML, CSS, JS, PHP, SQL) egy embernek (nekem legalábbis), úgy, hogy még működjön is).
Szóval talán segítséget kellene kérnem (fizetőst, egy hozzáértőt pár óra szaktanácsadásra), hogy az alapok stabilak legyenek.
Mert hát ahogy írtad is, ilyen csepegtetett infókból nem fog összeállni a kép, és amúgy sem veletek akarnám megoldatni a felmerült problémákat.Ha esetleg tudtok ilyen szolgáltatást, akár itt, akár privátban jelezzétek, kérlek. (Elképzelésem szerint) óradíjban, megmutatom, hogy működik az oldal, ezt hogyan szolgálja ki jelenleg az adatbázis, ő pedig elmondja, mi és miért nem jó, javítjuk, teszteljük, és örülünk.
Mert logikázhatok én itt egyedül (a Ti segítégetekkel, amit ezúton is köszönök), de ha rossz a logikám, amiből indul az egész, akkor csak az időt húzom a semmire.
Viszont azt amúgy továbbra sem értem, hogy az alap lekérdezéssel miért ilyen piszok lassú, ha egyszer már indexelve is van, és LIKE és kategóriák a közelben sincsenek.
-
Taci
addikt
Köszönöm a sok és részletes választ, illetve a tippeket!
Nem csak a
LIKE-os lekérdezésekre ad vissza nagyon lassan választ, de az "alapra" is:SELECT * FROM table ORDER BY date DESC LIMIT 4
Ezért "nem látom, hogy működne" az indexelés, mert se "alap" lekérdezésnél, se kibővítettnél nem gyorsult semmit. Mit tudok még átnézni, változtatni, ellenőrizni? Lehet, csak a lokál szerver "miatt" ilyen lassú? Mert ha más nem, az alap lekérdezésre már jól kellene (gyors válasszal) működnie.----------
(A jelenlegi felépítés szerint) muszáj vagyok LIKE-ot használni:
A kategóriákra szűrök így. Mert jelenleg ha category1, category3 és category4-be tartozik egy elem, az most úgy van letárolva, hogy a category mező tartalma a rekordhoz:"category1,category3,category4"De a user category1 és category4-re szűr rá, akkor (jelenleg) nem tudom máshogy, mint
AND
(category LIKE '%category1%'
OR category LIKE '%category4%')Rengeteg féle kategória van (30+), így ez lehet egy elég hosszú sztring is, ezért nem is nagyon tudom, hogyan tudnám máshogy megcsinálni.
De ha van tipped, szívesen veszem.Vagy esetleg ezt is lehetne
IN-nel? Csak nekem úgy kell az eredmény, ha cat1 és cat4-re szűr, akkor mutassa, ha vagy az egyikben, vagy a másikban van (vagy mindkettőben, nyilván). De az IN-nél meg inkább AND az operátor, nem OR.
Tehát aWHERE category IN ('category1', 'category2')
nem jó eredményt adna vissza, nem?Köszönöm.
-
Taci
addikt
Bocsánat a sok posztért, de ebben a témában minden dolog új nekem, és szükségem van segítségre vagy megerősítésre.
Most pl. ebben:
Rátaláltam azEXPLAIN-re. Így most látom, hogy arowsértéke 4 (type: index), tehát működik az indexelés, mert nem olvassa be mind a ~500e rekordot, hogy dátum szerint sorba állítsa.
Még akkor is 4 arowsértékeEXPLAINmellett, ha a korábban írt hosszú-hosszú lekérdezést indítom (OR, AND, LIKE, NOT, %%). Szóval ez "papíron" nagyon jól néz ki most.Viszont ha ez már így elvileg működik, miért olyan dög lassú még mindig magán az oldalon? 10x gyorsabb, ha az eredeti 7500 rekordot rakja sorba indexelés nélkül, mintha ezt az 500e-t indexelve.
Hol és mit kellene még megnéznem?
-
Taci
addikt
Közben pár dolgot még megtaláltam:
A konzolban (phpMyAdmin) a táblát kibontva az indexek alatt ott van a létrehozott index.
Aztán ha rákattintok ("Indexek"), akkor a megfelelő mező mellett látok egy szürke kulcsot, szóval létre lett hozva.
Illetve alul látom a tulajdonságait is:
Egyedi: Nem
Csomagolt: Nem
Számosság: 7597 (a PRIMARY-nak ezzel szemben ~500e. Esetleg ez a szám mutatja majd, hol jár az indexelés?) (De most töröltem az indexet, és újra létrehoztam. És most 7341-et ír... Nem értem.)
Nulla: Igen (?) -
Taci
addikt
Illetve még egy kérdésem lenne:
Indexeltem elvileg, aztán a duplikálással felvittem 500e körülre a rekordok számát.
Viszont ugyanolyan lassú még mindig.- Most akkor nem vártam eleget, idő kell az indexeléshez, és csak később lesz gyorsabb?
- Vagy az indexelés csak az aktuálisan létező elemekre vonatkozik, a jövőbeniekre nem, ezért mondjuk minden új rekord felvétele után újra indexelni kellene?
Ezt mondjuk most meg is válaszolom magamnak, mert újra futtattam az indexelős parancsot, és azt írja, nem lehet, duplikált kulcsazonosító.
- Nyomon tudom követni valahol vagy valahogy az indexelés állapotát? Azt írják, hogy a user nem látja, de valahol biztos jegyezve van.(Kérlek, ha lehet, az előző kérdéseket is próbáljátok már megválaszolni.)
Köszönöm.
-
Taci
addikt
Köszönöm a tippet.
Ezt a leírást találtam róla: [link]
Note: Updating a table with indexes takes more time than updating a table without (because the indexes also need an update). So, only create indexes on columns that will be frequently searched against.
Van ilyen lekérdezésem is:
SELECT * FROM tableWHERE channel_idIN ('id1','id2','id3','id4')AND(category LIKE '%category1%'OR category LIKE '%category2%'OR category LIKE '%category3%'OR category LIKE '%category4%'OR category LIKE '%category5%'OR category LIKE '%category6%')AND(category NOT LIKE '%category7%'AND category NOT LIKE '%category8%'AND category NOT LIKE '%category9%')ORDER BY date DESC LIMIT 4Ez alapján akkor ezeket a mezőket (channel_id, category) is indexelni kellene, mert végülis ugyanolyan gyakran vannak használva?
Látok a link alatt olyat is, hogy lehet indexet mezők kombinációjára is beállítani. A fenti példám alapján hogy lenne jobb? Index külön a mezőkre? Index ezek kombinációjára? Vagy is-is?És ezt a CREATE INDEX-et csak egyszer kell mezőnként futtatni, és onnan "rendben van"? Azért kérdezem, mert próbálok mindent automatizálni, hogy ne kelljen figyelni rá, ha nem muszáj, és ha ez is olyan, amit többször kell meghívni, akkor erre is figyelnem kell.
Bocsánat a sok kérdésért és értetlenkedésért, csak erről most hallok először, és fontosnak tűnik, nem szeretnék hibázni vele.
Köszönöm.
-
Taci
addikt
És meg is van az eredmény... 2 millióig tudtam felvinni a duplikálást. Most pedig az apache logban ezeket találom:
Nincs elegendő memória-erőforrás a parancs feldolgozásához.
Érvénytelen cím hozzáférésére tett kísérlet.
Fatal error: Out of memory (allocated 467664896) (tried to allocate 16384 bytes)És nem is tölt be semmit az adatbázisból.
Jelenleg ez csak egy desktop server, csak tesztelni.
De előfordulhat ilyen hiba a szolgáltatónál is?
Az én kódomban van a hiba?Amúgy nem egy nagy lekérdezés volt, csupán ennyi:
SELECT * FROM table ORDER BY date DESC LIMIT 4És erre dobta a fenti hibákat.
Nekem kell javítani/változtatni valamit, vagy ez a DesktopServer korlátjai miatt van, és a normál szerveren (szolgáltató) ezzel nem lesz gond?
Köszi.
Upd.: 1 milliónál is ugyanez a baja. De 500ezernél már lassan, de végzi a dolgát.
-
Taci
addikt
Sziasztok!
Van rá mód esetleg, hogy valahogy (egyszerűen) sokszorosítsam az adatbázisom (az egyik tábla) tartalmát?
Jelenleg kb. 4e elem van benne, és szeretném megnézni, hogyan viselkedne mondjuk 400e vagy 4 millió elemnél. Mennyire lassulna be stb.
Meg lehet ezt oldani egyszerűen? (Nem kell a tábla semmire, teszt fázisban van csak, törlöm, és újra feltöltöm, ha az kell majd.)
Köszi.
-
Taci
addikt
válasz
martonx
#4980
üzenetére
Amúgy azért őket választottam, mert habár saját HTML (és CSS, JS, PHP, SQL) kódot írtam, nem tudom, hogyan "védhetném" meg az oldalamat a különböző féle (általános) támadások ellen. Ezért eleve abból indultam ki, hogy WordPress-re van millió kiegészítő, van pár (elvileg) nagyon jó, ami a biztonságért felel (pl. Wordfence), így némi kompromisszummal, de tudom a 2 világot (saját kódok szabadsága + WordPress biztonsága) kombinálni.
Régebben amikor WP-t tanultam, akkor ajánlották és használtam a Wordfence plugint, azokból a reportokból láttam, hogy mennyi mindent megfogott. Fogalmam sincs, hogyan kell/lehet egy weblapot/tárhelyet másképp megvédeni, és védeni pedig sajnos van mitől, nem a backup-ok visszaállításával szeretném az időmet majd tölteni.
Na de ez teljesen más téma (security), amihez még annyira sem értek, mint az SQL-hez (és az sem sok... ), szóval muszáj vagyok már kész megoldásokat és rendszereket használni, mert erre tényleg nincs már időm/energiám 0-ról megtanulni (mert elég nagy témakör, ha jól sejtem.) -
-
Taci
addikt
Úgy látom, a PHP-oldali résszel készen vagyok (nagy meglepetésemre).
Viszont a kereséshez (és szűréshez) kapcsolódó lekérdezések még mindig a "régi csúnyák":
Így néz ki jelenleg, ha keresést indítok 3 különböző szóra:
SELECT * FROM the_only_one_tableWHERE((title LIKE '%kereso_szo_1%'ANDtitle LIKE '%kereso_szo_2%'ANDtitle LIKE '%kereso_szo_3%')OR(description LIKE '%kereso_szo_1%'ANDdescription LIKE '%kereso_szo_2%'ANDdescription LIKE '%kereso_szo_3%'))ANDid NOT IN (672,467,439,395,325,143,10,156)ORDER BY date DESCLIMIT 4(az id NOT IN részt csak azért hagytam benne, hogy megmutassam, hogy megfogadtam a tanácsaitokat, és így valóban kulturáltabb az egész
)A kereséshez (és ugyanilyen elven (LIKE %%-kal) működik a szűrés is):
Az ajánlás alapján rákerestem a full text search-re. Ott elsőnek a CONTAINS-t találtam. De kézzel (phpMyAdmin-ban a konzolban) sem adott vissza találatot:WHERE CONTAINS ((title, description),'"kereso_szo_1" AND "kereso_szo_2" AND "kereso_szo_3"')Láttam keresési találatokat
MATCH-re,MATCH AGAINST-re, de a leírásuk sem győzött meg, hogy ezeket kellene használnom.Szóval martonx tanácsát megfogadva inkább rákérdezek, hogy hogyan lehetne megoldani a keresést/szűrést a a
LIKE %%használata nélkül?
Engem -tapasztalatlant- persze nem zavar, csak ugye írtátok, hogy rém pazarló. A LIKE-nál keresés miatt pedig muszáj vagyok a %%-ot használni, mert a szöveg bármelyik pontján lehetnek a keresett szavak.Köszi!





 fejek jönnek elő belőlem (meg rengeteg kérdés).
fejek jönnek elő belőlem (meg rengeteg kérdés).
 )
)



 "
" Bár hidd el, nem szánt szándékkal teszem.
Bár hidd el, nem szánt szándékkal teszem. 





 Na azért ez így hasít...
Na azért ez így hasít...











Új hozzászólás Aktív témák
- 27% Számlával! ASUS ROG Loki 1000W 80 PLUS Platinum SFX Tápegység!
- Samsung PM9E1 "9100 PRO" 2TB M.2 NVME Gen5 x4 SSD! 14.000-12.500MB/s
- Független IPhone 14 pro 256 gb
- NZXT KRAKEN Elite V2 240 RGB AIO Display White vízhűtő!
- Bomba ár! Dell Latitude 7330 - i5-1235U I 16GB I 256SSD I HDMI I 13,3" FHD I Cam I W11 I Garancia!
- Honor X6 /4/64GB / Kártyafüggetlen / 12Hó Garancia
- Samsung Galaxy A16 / 4/128GB / Kártyafüggetlen / 12HÓ Garancia
- BESZÁMÍTÁS! Akár részletfizetés 0% THM ÚJ Intel LGA 1700 processzorok 3 év garanciával 27% áfaval
- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max
- 27% Számlával! ASUS ROG Loki 1000W 80 PLUS Platinum SFX Tápegység!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest