Hirdetés
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- sziku69: Szólánc.
- Meggyi001: A kérdés...
- oriic: A TOP 10 legtöbb hozzászólással rendelkező PH! felhasználó
- Trewerr: Analóg-digitális jelátalakítás (zenefájlok leegyszerűsítésével magyarázva)
- Lalikiraly: Astra kalandok @ Negyedik rész
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Brogyi: CTEK akkumulátor töltő és másolatai
- Lalikiraly: Kaáli Autó-Motor Múzeum
Új hozzászólás Aktív témák
-
#9024
 S_x96x_S
addikt
Petykemano
#9023
S_x96x_S
addikt
Petykemano
#9023
S_x96x_S
addikt
válasz
 Petykemano
#9023
üzenetére
Petykemano
#9023
üzenetére
> Azt már korábban is tapasztaltuk, hogy az AMD különböző IPC értéket
> adott meg a Zen4 esetén a desktop (8%) és a szerver (14%) termékhez.
> A különbség nagyobbrészt adódhat a tesztelt programcsomag összetételéből,szerveren az AVX-512 alkalmazása sokkal gyakoribb és az felfelé tudja húzni az átlagot.
Desktopon az AVX-512 (még) nem elég elterjedt, hogy legyen elég kihatása.Amire én kíváncsi leszek, hogy a ZEN6 tudni fogja-e már
az Inteles új AVX10 -es utasításokat.
Vagy még inkább kivár ezzel az AMD.#9022paprobert :
> A "low power core option" az mégis mi?én az embedded fókuszra tippelek.
- Embedded Automotive Solutions
- Embedded Infrastructure Solutions
- ...de az is lehet, hogy az ARM little core - hoz hasonló .. extrém alacsony idle power.
-
#9023
 Petykemano
veterán
Petykemano
#9021
Petykemano
veterán
Petykemano
#9021
Petykemano
veterán
válasz
Petykemano
#9021
üzenetére
Fontos adalék lehet az információk értelmezéséhez - és ezt MLiD is elmondja - hogy az általa megszerzett és publikált ábra szerver/EPYC roadmap. El is mondja, hogy az ábrán látható dátumok és határok miért azok, amik és jelölgeti, hogy ahhoz képest mikor voltak a desktop rajtok.
Azt is elmondja az elején, hogy az IPC nem egy egzakt érték, hanem 15-25 alkalmazásban/játékban azonos frekvencia mellett tapasztalt gyorsulások (esetleg lassulások) átlaga. Ez az érték a definícióból fakadóan jelentős mértékben függvénye a beválogatott alkalmazások/játékok listájának.
Azt már korábban is tapasztaltuk, hogy az AMD különböző IPC értéket adott meg a Zen4 esetén a desktop (8%) és a szerver (14%) termékhez. A különbség nagyobbrészt adódhat a tesztelt programcsomag összetételéből, kisebb részben talán abból is, hogy különböző frekvenciamagasságban esetleg eltérő lehet a tapasztalt IPC.
-
#9018
 Komplikato
veterán
Petykemano
#9017
Komplikato
veterán
Petykemano
#9017
Komplikato
veterán
válasz
Petykemano
#9017
üzenetére
A Videocardz hírekben szereplő használtan árult kínai Zen4 Threadripper-t bő éve gyártották le. Szóval ki tudja?
-
#9013
 HSM
félisten
Petykemano
#9010
HSM
félisten
Petykemano
#9010
HSM
félisten
válasz
Petykemano
#9010
üzenetére
Szerintem desktopon nem akkora prioritás, hogy energiatakarékosan legyen gyors az AI, így nem annyira kritikus a gyorsító hozzá. Ráadásul már elég standard lett Ryzen oldalon is egy belépő IGP, desktopon simán lehet azt is használni AI-ra, főleg ha RDNA3-as.
Szerk: most olvasom, a korábban linkelt cikk is ezt említi: "If applications take advantage of it, XDNA should let Phoenix handle AI workloads with better power efficiency than the GPU. Technically, the RDNA 3 iGPU can achieve higher BF16 throughput with WMMA instructions. However, doing so would likely require a lot more power than the more tightly targeted XDNA architecture. Saving every bit of power is vital in a mobile device running off battery, so XDNA should let programs use AI with minimal power cost." [link]
-
#9011
 kleinguru
addikt
Petykemano
#9010
kleinguru
addikt
Petykemano
#9010
válasz
Petykemano
#9010
üzenetére
Alap dolgokra már mac miniket használok (M1,M2). Lehet, hogy réteg igény, de nagyon hálás tudok lenni, amikor a szkennelt képről kijelölöm a szöveget és hibátlanul a vágólapra másolja. Ezt ha jól tudom a neual engine blokkal csinálják almáék. Nem akarom lekicsinyíteni, de ilyen "alap" dolgot, azért implementálhatnának legalább nem

Vagy a saját OS hiányában ehhez már kellene a Microsoft is, így meg már macera?
-
#9006
S_x96x_S
addikt
Petykemano
#9005
S_x96x_S
addikt
válasz
Petykemano
#9005
üzenetére
> Az elmúlt napokban az Intel elég sok fejlesztést bemutatott.
az Inteles 3D V-Cache -ra kiváncsi leszek ..
Intel Adopting 3D-Stacked Cache for CPUs, Challenging AMD's 3D V-Cache
https://www.tomshardware.com/news/intel-will-adopt-3d-stacked-cache-for-cpus-says-ceo-pat-gelsinger""
"We feel very good that we have advanced capabilities for next-generation memory architectures, advantages for 3D stacking, for both little die, as well as for very big packages for AI and high-performance servers as well. So we have a full breadth of those technologies. We'll be using those for our products, as well as presenting it to the Foundry (IFS) customers as well," Gelsinger concluded.
It's logical that Intel could adopt this sort of technology; the hybrid bonding technology behind 3D V-Cache isn't proprietary to AMD -- it's enabled by TSMC's SoIC packaging technology. Additionally, this sort of chip architecture has been on the long-term horizon for chip makers for several years.
Stacked cache has proven to be a strategic advantage for AMD, as it powers the company's Ryzen X3D CPUs, which are the fastest gaming processors in the world. It's also a strong value add for its X-series EPYC processors, like Genoa-X. Now it appears that Intel will also throw its hat into the ring with this tech, too.
""" -
#9000
 hokuszpk
nagyúr
Petykemano
#8998
hokuszpk
nagyúr
Petykemano
#8998
hokuszpk
nagyúr
válasz
Petykemano
#8998
üzenetére
ilyen limited edition lehetne, mittomen "AMD 54" csak hogy a bencheckben legyen par piros csik is legelol.
-
#8999
 paprobert
őstag
Petykemano
#8998
paprobert
őstag
Petykemano
#8998
paprobert
őstag
válasz
Petykemano
#8998
üzenetére
"Ha egy sokmagos asztali gépet MT teljesítményre húzol fel, az papíron jól hangzik, de egyrészt a 300W elég nevetséges. (1-2 generáció múlva ugyanezt fogja hozni egy 15W notebook)"
"Nagy" rendszert venni ezzel jár. Az elején jó, de idővel túl nagy, túl sokat fogyaszt, és nem öregszik méltóságteljesen. Azok veszik, akiknek kell az erő, és az is most kell.
A Threadripper vagy az Epyc is, egy mezei PC-hez képest egy traktor hatékonyságát tudja... 150W üresjárat, stb."Hasonló helyzetként lehetne emlegetni a Zen1 betörését, hogy hát ott is feleslegesen jöttek a plusz magok."
Egyetértek. A Zen1/Zen1+ egyetlen dologra viszont megoldást adott, a megjelenés után nem sokkal. Ár/értékben szétverte a 4c/8t konkurenciát többszálú feladatokban. Minden másban hamar öregedett a további fejlődés miatt, de ez az érdem elvitathatatlan."Intelnek ott van a fiókban a titkos új architektúra, amivel majd újra megszégyenítő vereséget mér az MT teljesítménnyel bohóckodó AMD-ra"
Az Alder Lake lett ez az architektúra, 4.5 évvel később, ami nagyon valószínűsíti, hogy a Zen-től megijedve kezdődött el a fejlesztése.És igen, otthoni felhasználásra a MT teljesítmény egy szinten túl már alig számít, számomra ezért nem imponál a Zen-dense vagy az E-core megléte. Értem hogy mi a célja, és mire szolgál, de egyszerűen a nyers number crunching nem mindennapos otthon.
Persze ha sok-sok évig használja valaki a CPU-t, akkor megtörténik, hogy a vásárlás elején parlagon heverő MT teljesítmény egyre több workload-nál használatba kerül, de addigra a ST teljesítmény már rég elavultatta a rendszert, és egy sokat fogyasztó irodai PC lett a gép.
Én sokkal jobban örülnék egy olyan rendszernek, ami a teljes rendszer fogyasztását ~5W-ra tudná redukálni üresjáratban, minden komponenst beleértve.
Ma csak a laptopok tudják ezt. -
#8995
S_x96x_S
addikt
Petykemano
#8993
S_x96x_S
addikt
válasz
Petykemano
#8993
üzenetére
> Az M2-höz N4-en gyártott és és most
> az A17-ben debütált N3B-n gyártott lapkák egyszálas CPU teljesítménye
> szinte alig növekedett.lehet, hogy kezdenek átállni tik-tok -ra ..
( a GPU-ba jobban belenyultak )"Apple's A17 Pro SoC maintained the company's renowned six-core configuration and packs two high-performance cores functioning at up to 3.77 GHz and four energy-efficient cores operating at a lower frequency. When compared to the A16 Bionic (made on TSMC's N4), the A17 Pro boosts the maximum clock-speed of performance cores by 8.95% (from 3.46 GHz), which is in line with what TSMC's N3 (3nm-class) process technology offers compared to its 5nm-class counterparts (+10% ~ +15% compared to N5, about 10% compared to N4)."
--------------------
Single-Core
2914 A17 Pro ( up to 3.77 GHz )
2641 A16 Bionic
3223 Core i9-13900K
3172 AMD Ryzen 9 7950X ( up to 5.70 GHz )
2050 Snapdragon 8 Gen 2"When Apple formally introduced its A17 Pro system-on-chip (SoC) earlier this week, it said that its high-performance cores deliver a 10% increase in single-thread workloads compared to its predecessor. Apparently, this was an accurate estimate and the new processor delivers single-thread performance that is competitive with some PC processors while working at a considerably lower frequency. Meanwhile, it looks like Apple has made little to no architectural changes to its A17 Pro CPU cores and only boosted clocks."
via:
Apple's A17 Pro Within 10% of Intel's i9-13900K, AMD's 7950X in Single-Core Performance
https://www.tomshardware.com/news/apples-a17-pro-challenges-core-i9-13900k-ryzen-7950x-in-single-core-performance -
#8991
S_x96x_S
addikt
Petykemano
#8989
S_x96x_S
addikt
válasz
Petykemano
#8989
üzenetére
> Arról szól a hír, hogy most találtak valami szoftveres megoldást,
> hogy az adatlokalitás optimalizálásával csökkentsék a késleltetést?csak egy még finomabb a hardveret jobban figyelembe vevő
szoftveres optimalizáció. -
#8987
HSM
félisten
Petykemano
#8982
HSM
félisten
válasz
Petykemano
#8982
üzenetére
Sajnos nem vagyok jártas ilyen területen, de általánosságban minél gyorsabb egy interfész, annál kényesebb a jelvezetésre, hacsak nem változnak a technológia alapjai.
#8986 S_x96x_S: "This means that the impact of L3 cache locality is noticeable in these experiments"
Használva Ryzen 3600 majd Ryzen 5600-at illetve mobil Ryzen 4650U-t és 5850U-t (mindkét eset elsősorban az osztott/egyesített L3-ban különbözik) azt kell mondjam, bőven akad olyan feladat/felhasználás, ahol komoly jelentősége lehet ennek.
Bár sajnos az app szálkezelését ez önmagában nem fogja tudni megoldani, de az OS legalább segít majd, ahol tud.
-
#8984
hokuszpk
nagyúr
Petykemano
#8983
hokuszpk
nagyúr
válasz
Petykemano
#8983
üzenetére
én amatőr meg a Zen5-re várok.
de váltok Zen6 -ra várásra, nemkerül semmibe![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#8970
S_x96x_S
addikt
Petykemano
#8969
S_x96x_S
addikt
válasz
Petykemano
#8969
üzenetére
> Azért az nem hangzik rosszul,
> hogy egy Veyron V1 mag még a Bergamonál is 30%-kal kisebb.Szerintem van 2 kulcs mondat, hogy miért is kisebb:
- "V1 has no vector capability, " és az AVX2/AVX-512 elég sok helyet foglal.
- "Ventana (B1) hasn’t included die to die interfaces in their images"https://chipsandcheese.com/2023/09/01/hot-chips-2023-ventanas-unconventional-veyron-v1/
SPECInt -ben viszont nem rossz .. , persze a zen4/zen5 -höz képest kell mérni majd, mert azok lesznek a versenytársai.
 https://www.servethehome.com/ventana-veyron-v1-risc-v-data-center-processor-hot-chips-2023/
https://www.servethehome.com/ventana-veyron-v1-risc-v-data-center-processor-hot-chips-2023/Az mindenesetre jó hír, hogy egyre nagyobb a verseny :-)
-
#8967
HSM
félisten
Petykemano
#8966
HSM
félisten
válasz
Petykemano
#8966
üzenetére
Igen, az IF sávszélessége visszafogja az AM5 cpu-kat gyors ramokkal elég jól láthatóan. A gyorsabb kapcsolat ott lehet kérdéses, hogy a fogyasztás kulcskérdés, ha sok CCD-t kell összekapcsolni. A nagy CCD lokális L3 ilyen téren is nagy segítség, csökken(het) a terhelés a memória felé, szinkronizálni is több sávszélesség marad(hat).
-
#8965
S_x96x_S
addikt
Petykemano
#8964
S_x96x_S
addikt
válasz
Petykemano
#8964
üzenetére
> sávszélesség
talán az egyik ok .. a sok közül ..
a másik az általad is említett energia kérdése .. ( "hogy mennyi energia megy " )
és a link is jó, amit linkeltél ..
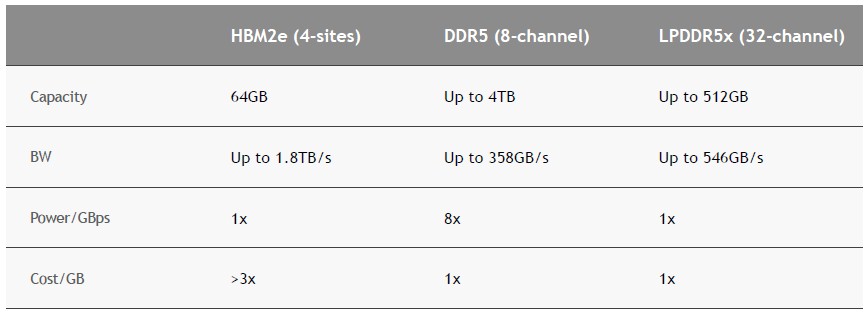
"Compared to an eight-channel DDR5 design, the NVIDIA Grace CPU LPDDR5X memory subsystem provides up to 53% more bandwidth at one-eighth the power per gigabyte per second while being similar in cost. An HBM2e memory subsystem would have provided substantial memory bandwidth and good energy efficiency but at more than 3x the cost-per-gigabyte and only one-eighth the maximum capacity available with LPDDR5X. "Tehát a DDR5 EPYC - kb 8x akkora energiát igényelhet ( Power / GBps )
mint a HBM és az LPDDR5x - GraceVagyis a [ sávszél * költség * energia ] alapján az Nvidiás mérnökök a DDR5-öt elvetették.
https://www.nextplatform.com/2022/08/29/details-emerge-on-nvidias-grace-arm-cpu/
----------------Amúgy az OpenFOAM -nak használ az AVX-512 ; vagyis a ZEN5 előrelépés lesz
https://www.phoronix.com/review/amd-epyc-avx512/9-------------------
Vagyis összefoglalva, ami számíthat az OpenFOAM szempontjából:
- Magok száma ( grace next : 144 )
- FPU hatákonyság ( itt gyengébb a grace , a zen5 meg ütős lesz .. )
- Memória sávszél , cache ( NVMe, 3Dvcache; 12 csatornás DDR5 )
- CPU Energia igény ( TSMC 4N ?? )
- Memória energia igény ( a DDR5 itt nem ideális )Amúgy nem tünik rossznak a Grace ..
-
#8963
S_x96x_S
addikt
Petykemano
#8962
S_x96x_S
addikt
válasz
Petykemano
#8962
üzenetére
közben már megválaszoltam ott ( is )
De az Intel XEON MAX -os teszt alapján
a HBMe eléggé rásegíthet a feladatra
és az új grace HBME3e -s.vagyis a 3D-Cache segít, de a HBMe még jobban ..
az új MI300 -al kell majd összehasonlítani a Next Gen Grace-t. -
#8956
 fatal`
titán
Petykemano
#8955
fatal`
titán
Petykemano
#8955
fatal`
titán
válasz
Petykemano
#8955
üzenetére
Nem hinném, hogy közeledne a Zen 5, pláne a 3D caches. Fél éves sincs a Zen 4 X3D.
-
#8955
Petykemano
veterán
Petykemano
#8949
Petykemano
veterán
válasz
Petykemano
#8949
üzenetére
7800X3D közel $100-ral akcióban [link]
Vajon ez eseti akció lehet, vagy futnak ki a szerveres megrendelések és halmozódik a készlet és/vagy közeledik a Zen5?
-
#8940
S_x96x_S
addikt
Petykemano
#8939
S_x96x_S
addikt
válasz
Petykemano
#8939
üzenetére
> Nem tudom, hogy ezt hiányoltad-e.
érdekesnek érdekes ..
de ettől még nem leszek optimistább -
#8930
S_x96x_S
addikt
Petykemano
#8929
S_x96x_S
addikt
válasz
Petykemano
#8929
üzenetére
> A chiplet kommunikáció késleltetésén
érdekesség:
Az UCIe - 2ns alatti késleltetést céloz be .."Meanwhile, it’s interesting to note just what the promoters are expecting in terms of latency and energy efficiency. For all package types, latency is expected to be under 2ns, which is especially critical in chiplet designs that are splitting up what would previously have been a monolithic chip design. "
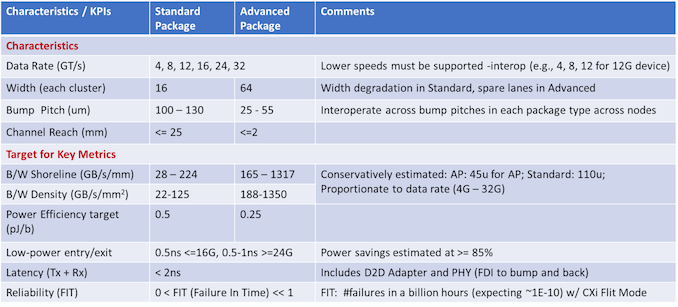 https://www.anandtech.com/show/17288/universal-chiplet-interconnect-express-ucie-announced-setting-standards-for-the-chiplet-ecosystem ( March 2, 2022 )
https://www.anandtech.com/show/17288/universal-chiplet-interconnect-express-ucie-announced-setting-standards-for-the-chiplet-ecosystem ( March 2, 2022 )------------------------------------
És a héten jelent meg az UCIe 1.1 - legalább valamit dolgoznak a háttérben ..
https://www.phoronix.com/news/UCIe-1.1-Specification
https://www.uciexpress.org/press-releasesA 3 nagy CPU gyártó ott van azok között - akik névvel is vállalták, hogy kiállnak mellette ..
Statements of Support for UCIe 1.1 Specification
AMD - Statement:
“The UCIe 1.1 specification, which adds new features to optimize silicon and packaging costs, additional protocol flexibility and automotive use cases, takes the first step towards establishing a chiplet ecosystem. We are proud of the UCIe Consortium’s progress so far and look forward to establishing a truly pervasive universal chiplet ecosystem.”
Nathan Kalyanasundharam, Corporate Fellow and AMD Infinity Fabric Lead Architect, AMDIntel - Statement:
“Intel is proud to be a founding member of the UCIe consortium. Chiplets are continuing to become a critical technology for the semiconductor industry. Intel Foundry Services (IFS) is focusing on UCIe to enable our foundry customers to build interoperable silicon solutions, based upon industry standards.”
Bob Brennan, Vice President of Customer Enablement, Intel Foundry ServicesArm - Statement:
“As compute requirements continue to grow and evolve across all industries, we must deliver scalable, cost-effective solutions and new approaches. Arm partners are already delivering chiplet-based solutions in infrastructure applications; in automotive, chiplets can reduce time to market, allow for new performance points and enable unique SoC designs in applications such as ADAS and infotainment, while still delivering the dedicated features tailored to the safety and real-time needs of the market. Arm will continue to work with industry leaders in the UCIe Consortium on standards and specifications like the UCIe 1.1 Specification as the Consortium expand to increase interoperability and address industry needs.”
Andy Rose, VP Technology Strategy and Fellow, Arm---------------------
és apró siker - az egyik cég már a 3nm-eren sikeresen tesztelte ..
"We are delighted to announce successful tapeouts on TSMC’s most advanced 3nm process including UCIe PHY IPs."
https://www.uciexpress.org/post/meet-ucie-consortium-member-alphawave-semi
-----------
(Board) UCIe Director -ok - van nVidiás és TSMC-s is.
https://www.uciexpress.org/board-representatives -
#8925
HSM
félisten
Petykemano
#8923
HSM
félisten
válasz
Petykemano
#8923
üzenetére
Különös adalék, hogy úgy nem látjuk a piacon, hogy elvileg készült belőle egy fizikailag kisebb kiadás is az olcsóbb modellekhez...
-
#8922
S_x96x_S
addikt
Petykemano
#8921
S_x96x_S
addikt
válasz
Petykemano
#8921
üzenetére
> Bennem ez azt erősíti, hogy a 2024Q1-es Zen5 rajt sínen van.
az is lehet, hogy a Zen5 -ös APU a gyorsító sávba került.
( valamiért nagy prioritást kapott Lisa Su-tól )És ha arra gondolok, hogy most az AI az AMD Number 1 prioritása
akkor tényleg az APU-nak több értelme van,
A STRIX Point lényegében egy ideális MI300/MI400-as dev kit ROCm kompatibilitással.
És ha lesz belőle mini PC/notebook/... akkor veszik mint a cukrot ..Az én spekulációm:
Vagyis ami az MI300/MI400 - szoftveres ellátottságát segíti - az magas prioritást kap.
a sima ZEN5 CPU - pedig alacsonyabbat.
Legalábbis ez az én spekulációm - az én szubjektív nézőpontomból
Az is lehet, hogy a PhoenixAPU -val valami gond van
 .. nagyon lassan megy a launch.
.. nagyon lassan megy a launch.
és az AM5 -ös desktop-os Phoenix verzióról kevesebb a pletyka mint a Strix Point -ról.
Nyugtassatok meg, hogy minden rendben vele -
#8920
HSM
félisten
Petykemano
#8918
HSM
félisten
válasz
Petykemano
#8918
üzenetére
Pusztán spekuláció, de azt gondolom, arányos lehet a felfedezés "piaci értéke" azzal, mekkora felhasználói bázist érint... Így minél több a Zen-es rendszer, annál inkább foglalkoznak vele. Már csak azért is, mert egyre több Zen-es gép lesz, amit a kutató kipróbálhatja tesztelni a potenciális sebezhetőségét....

#8919 Busterftw : Mivel eddig nem jelent meg javíthatatlannak tűnő súlyos sebezhetőség, így nincs ok "lyukas sajtozni"...

De tény, most átmenetileg jár a jelző a Zen2-nek, amíg nem jönnek rá széleskörűen a Zenbleed patch-ek. -
#8917
HSM
félisten
Petykemano
#8915
HSM
félisten
válasz
Petykemano
#8915
üzenetére
Szerintem most jobban figyelnek a kutatók a Zen architektúrára, ahogy egyre nagyobb méretekben terjed, akár szerver oldalról is.
A másik oldalon is miket találtak az elmúlt néhány évben, most úgy tűnik valamennyire felzárkózik a Zen ebben is...
Persze, ez Zen2 és Zen3 tulajként annyira nem villanyoz fel, de várható volt. -
#8916
S_x96x_S
addikt
Petykemano
#8915
S_x96x_S
addikt
válasz
Petykemano
#8915
üzenetére
Valami olyasmi .. öngerjesztő spirál.
- szerintem most a kormányok és a cégek is több pénzt áldoznak erre, és az egyetemek + kutatók jobban kapnak erre forrásokat. ( ~ több benne a pénz )
- és egyre gyakorlottabbak a kutatók is. Ugyanazt a trükköt sokszor csak egy picit elég módosítani - és néha szerencséjük van, mert működik.
- És minél inkább felkapja a sajtó .. annál több pénzt adnak rá a politikusok és a cégek ..
amelyek újabb sebezhetőségeket generálnak A hosszú távú hatása, hogy a CPU-k egyre biztonságosabbak lesznek.
-
#8912
hokuszpk
nagyúr
Petykemano
#8907
hokuszpk
nagyúr
válasz
Petykemano
#8907
üzenetére
hm.
Zen1 = AVX2 128 bit. stimt.
Zen2 = AVX2 256 bit de ez ha jolemlexem vegrehajtasnal 2x128 bitre bomlott.
Zen3 = AVX2 256 bit, full.
Zen4 = AVX512 bit de vegrehajtasnal megint kette van bontva 2x256 bitre
szoval logikailag ZEN5 = AVX512 full -
#8911
S_x96x_S
addikt
Petykemano
#8910
S_x96x_S
addikt
válasz
Petykemano
#8910
üzenetére
> Két dolog miatt hiszek a 2024Q1-es rajtban:
legyen igazad !
-
#8909
S_x96x_S
addikt
Petykemano
#8908
S_x96x_S
addikt
válasz
Petykemano
#8908
üzenetére
> A 2024Q1-es rajt elég valószínű.
ki tudja ..
de a (May 15th 2023 -MLID-Videocardz alapján csak 2023Q1-ben kezdődik el a gyártása )
"More importantly, the slide shows when the product might enter production, which is between Q1 2024 and Q1 2025,"Az ábra alapján a "Turin Dense" és a "Turin Classic" kap nagyobb prioritást.
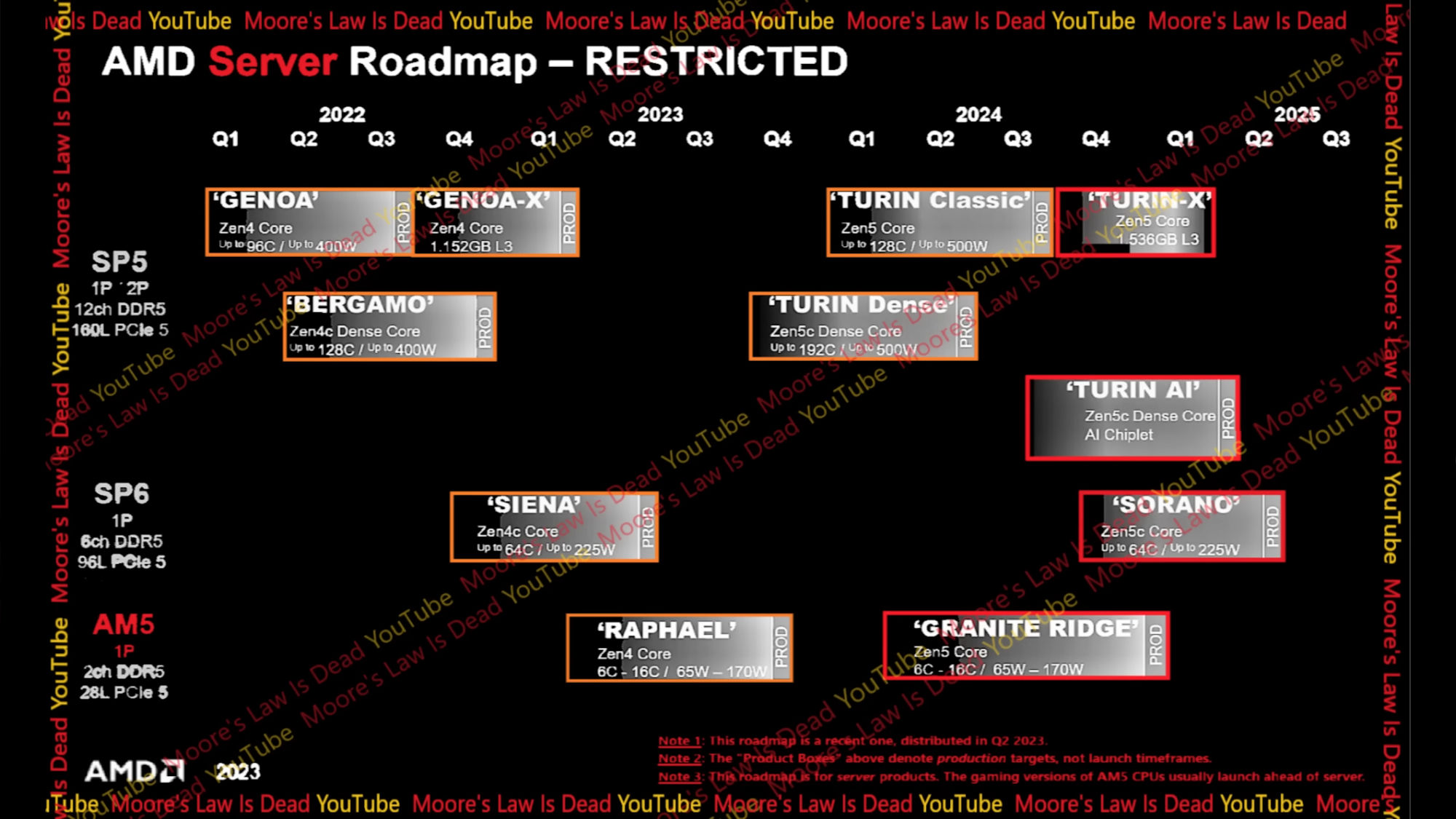
de amúgy én is örülnék, hogyha már januárban meg lehetne venni ..
-
#8908
Petykemano
veterán
Petykemano
#8907
Petykemano
veterán
válasz
Petykemano
#8907
üzenetére
Nagyon erősnek tűnik a hype és az elégedettség a zen5 tesztpéldányokkal.
Azt nézegettem, hogy Vajon mikor jelentek meg az első olyan leak-ek, amiket nem Mlid, RGT jelentettek meg, hanem a twitter sejtelmes közönsége is somolyogva lebólogatott. Szerintem nyáron ilyen már biztos történt.
A 2024Q1-es rajt elég valószínű.
Igazából persze a nép annak örülne, ha karácsonyra vihetne haza egyet.A 25% körüli ST teljesítménynövekedés valószínű. Bármi ennél jobb, legyen inkább meglepetés. A raptor lake refresh nem tűnik túl erősnek. Mivel az Intel árat akart volna emelni, ezért az árcsökkentés valószínűtlen, tehát minimum a zen3 borsos árazásához való visszatérés várható. Főleg a kisebb magszámú skuknál.
-
#8885
S_x96x_S
addikt
Petykemano
#8882
S_x96x_S
addikt
válasz
Petykemano
#8882
üzenetére
2.
> APX/AVX10 ...amúgy nem látok még tisztán ..
és minnél többet olvasok a témáról .. annál több kérdés merül fel bennem ..
-
#8884
S_x96x_S
addikt
Petykemano
#8882
S_x96x_S
addikt
válasz
Petykemano
#8882
üzenetére
> Szerinted az APX/AVX10 [link] már magábafoglalja/megvalósítja azt,
> amit az SVE-nél láttunk? Vagyis hogy az utasítás/vektorhossz
> és a végrehajtó szélessége nincs szorosan összekötve?(ahogy felületesen én látom)
bár messziről úgy tünk .. és egyes cikkek meg is emlitik [1]
csak "érzésre" van meg a hasonlóság ..
persze lehet, hogy egy következő AVX10.3/AVX10.4 már arrafelé vezet a kiegészítésekkel
de ezt még nem látjuk.[1] "However, the e-cores will be limited to the converged AVX10's maximum 256-bit vector length, while P-cores can use 512-bit vectors. This feels akin to Arm's support for variable vector widths with SVE. " ( tomshw )
Ami még érdekes olvasva a kommenteket (spekulációkat) ..
hogy egyesek szerint ez az Intel részleges válasza az AMD AVX-512 -es megvalósításra .."No, the E-cores will implement only a 256-bit subset of AVX-512, which halves the size of the vector registers to 256-bit and the size of the mask registers to 32-bit. The same subset will be implemented on the P-cores combined with E-cores.
This subset AVX10/256, is the reason for this new specification. It is the Intel response to AMD Zen 4.
When their competitor supports AVX-512 on all products, Intel had to do something to remain competitive. Because they believe that supporting the full AVX-512 on their E-cores is too expensive, they have created a subset of AVX-512, including only the instructions with an operand size up to 256 bits."
( via https://news.ycombinator.com/item?id=36854341 ) -
#8883
Petykemano
veterán
Petykemano
#8878
Petykemano
veterán
válasz
Petykemano
#8878
üzenetére
Ez max 24GB, 1.2TB/s
24GB szerintem egy gépnek ma már nem számít kifejezetten soknak. Minimumnak talán inkább a 16GB-ot mondanám. Figyelembe véve, hogy a ebből kellene kiszoglálni az IGP-t is, a 24GB indokolt.
Azon gondolkodtam el, hogy vajon minek kellene teljesülnie, vagy milyen akadályok vannak még ma is az előtt, hogy egy HBM-es készülék készüljön.
Az előny ott van:
- 1.2TB/s, ami egy 150W TDP-be beférő közepes GPU-t taralmazó APU-t
- kompakt módon ki tudna szolgálni.Mit jelent a kompakt (a gép méretén kívül)? Azt, hogy az IOD-ból elhagyható lenne
- a RAM vezérlő, az alaplapról a RAM huzalozás
- a PCIe sávok nagyobb része.Hátránya persze ezzel az volna, hogy sem RAM, sem bővítókártyás GPU fogadására nem volna alkalmas. Nem mintha ezt meg tudnád tenni a manapság egyre népszerűbb kézikonzolok esetén.
A RAM bővítés esetleg lehet szempont. Erre a jövőben viszont talán elegendő lehet PCIe sávokat meghagyni és hagyatkozni a CXL-re, amely esetben egy m.2 csatlakozós bővítőkártya (akár DRAM-okkal) csak overflow kezelését célozná.Ma már nem szükségszerű a nagy interposer, meg tudják oldani "hidakkal". Persze annak is nyilván van valamekkora többletköltsége. Az IOD-on lehet picit spórolni.
Vajon még ennél is olcsóbban megvalósítható LPDDR5X és/vagy 3D stacked v-cache?
-
#8877
S_x96x_S
addikt
Petykemano
#8876
S_x96x_S
addikt
válasz
Petykemano
#8876
üzenetére
logikus:
"TSMC have the best nodes, but they are very expensive. Samsung can produce the mid range AMD products (like next console SoCs)."
https://twitter.com/BitsAndChipsEng/status/1684134578263404544 -
#8872
 Busterftw
nagyúr
Petykemano
#8871
Busterftw
nagyúr
Petykemano
#8871
Busterftw
nagyúr
válasz
Petykemano
#8871
üzenetére
Amúgy Linus elsőként kapott a Framework laptopjába Phoenixet, de ott sem mutatták a rendszert élőben mert a Framework CEO nem nagyon engedte, az se volt biztos, hogy bebootol a dolog.
Valószínűleg még hiányzott már akkor a szoftveres háttér AMD-től. Miközben úgy márciusra ígérték az egészet.
-
#8867
 Z_A_P
addikt
Petykemano
#8865
Z_A_P
addikt
Petykemano
#8865
Z_A_P
addikt
válasz
Petykemano
#8865
üzenetére
Now that the first AMD Phoenix APU-powered laptops are rolling out, AMD failed to deliver the processor's official graphics drivers.
Anno sokat volt ez az indok hogy miert a "szarabb" intel architekturat preferaljak a gyartok - hat ime, emiatt.
Es hihetetlen, hogy most mar nagyobb cegertekkel, stabil haterrel ugyanott tartanak mint 10 eve. Ekkora baklovest.
De akkor most mi van, nem mukodik a kepernyo, vagy alap 1024x768 SVGA driverrel megy? -
#8857
S_x96x_S
addikt
Petykemano
#8856
S_x96x_S
addikt
válasz
Petykemano
#8856
üzenetére
> Különös, hogy ezúttal az APU változat (mérnöki példánya)
> látott előbb napvilágot és nem pedig az asztali.én ezt már nem tartom furcsának.
a 7840HS - is már elérhető .. de az asztali csak talán szeptember után várható> mindazonáltal számomra a 40CU-s változat sokkal izgalmasabban hangzik.
> Ugyanakkor én korlátozásként (kitolásként) élném meg,
> ha azt csupán valamilyen előregyártott kompakt egybegépként lehetne megvásárolni.a 40Cu-s -nak már 256 bites memória csatornája van .. és nem 128
És az is lehet, hogy csak konzol csip lesz
.. és nem is kerül kisker forgalomba még egy jó ideig. -
#8856
Petykemano
veterán
Petykemano
#8849
Petykemano
veterán
válasz
Petykemano
#8849
üzenetére
Azt hiszem, ez nem mót vég.
A 12-core AMD Ryzen 8050 Zen5 “Strix Point” APU has been spotted
- benchleaks, milkyway, boinc
- AMD Eng Sample: 100-000000994-03_N [Family 26 Model 32 Stepping 0]Korábbi mérnöki példányok felbukkanási ideje alapján tényleg azt lehet jósolni, hogy 7-8 hónap múlva megjelenhet.
Különös, hogy ezúttal az APU változat (mérnöki példánya) látott előbb napvilágot és nem pedig az asztali.Szerintem 4P+8d lehet a hatékony felállás. Azt gondolom, hogy ha már 4 magnál többet kell használni mobil környezetben, akkor ott már nem nagyon lehet korlátozó tényező az, hogy egy d mag esetleg nem megy feljebb 3.5-4Ghz-nél.
mindazonáltal számomra a 40CU-s változat sokkal izgalmasabban hangzik.
Ugyanakkor én korlátozásként (kitolásként) élném meg, ha azt csupán valamilyen előregyártott kompakt egybegépként lehetne megvásárolni. Fájna a szívem, ha a már meglevő kiegészítőimtől (pl CPU hűtő) ezért kéne megválni. -
#8850
 Valdez
őstag
Petykemano
#8849
Valdez
őstag
Petykemano
#8849
Valdez
őstag
válasz
Petykemano
#8849
üzenetére
A 40 CU-s megoldáshoz milyen ramot tesznek?
-
#8842
 Alogonomus
őstag
Petykemano
#8841
Alogonomus
őstag
Petykemano
#8841
Alogonomus
őstag
válasz
Petykemano
#8841
üzenetére
Ahhoz képest örömteli hír, hogy MLiD Tom korábban azt is belengette, hogy DIY piacra talán nem is érkezik majd, mert csak az utóbbi évben lecsökkent piaci kereslet miatt beragadt Zen3-as prebuilt rendszerek megsegítésének szánják, hiszen a V-Cache miatt a legtöbb szituációban bőven felveheti a versenyt egy 7700x alapú új Zen4-es konfigurációval, csak a 400-as lap, a DDR4 és a 7 nm-es node következtében jelentősen olcsóbb árcédulával is érkezhet.
-
#8839
HSM
félisten
Petykemano
#8838
HSM
félisten
válasz
Petykemano
#8838
üzenetére
Arra leszek kíváncsi, ezek külön CCX-ben lesznek-e. Ha igen, azaz közös az L3, akkor nagyon tetszik, ha külön, akkor annyira nem.
-
#8836
Alogonomus
őstag
Petykemano
#8835
Alogonomus
őstag
válasz
Petykemano
#8835
üzenetére
Valószínűleg elért a piac terjeszkedés egy olyan állapotba, ahol már a "trey féle" - megfelelő pozícióban is elhelyezkedő - radikálisan márkahű ügyfeleket kellene meggyőzni, amihez már messze nem elég a komoly teljesítményelőny és fogyasztáselőny, de a pénzügyi részleg támogatását is meg kell szerezni az olyanok ellenállásának a letöréséhez.
Mostantól kezdődik a lassú előrehaladás, mert sorban fel kell számolni az elmúlt kb 20 évben a helyzeti előnyben levő oldal által létesített "bunkereket" és "lövészárok-rendszereket" a további komolyabb térnyerés érdekében. -
#8834
hokuszpk
nagyúr
Petykemano
#8833
hokuszpk
nagyúr
válasz
Petykemano
#8833
üzenetére
azt a 14nm -et az AMD ismeri is, igaz a Glofo féle verziót, de nagy eltérés nemlehet.
szóval 14nm-en baromi olcson lehetne gyartani szép nagy cachet, ami eleg gyors, es ha jolertem amit ideztel, magas hőfokon is üzemképes.
szóval elég sok szempontból ideális a Zen tetejére ( aljara ? ) való felszigszalagozásra. -
#8820
Alogonomus
őstag
Petykemano
#8817
Alogonomus
őstag
válasz
Petykemano
#8817
üzenetére
Úgy talán lehet is értelme, hogy a változatlan 64 MB extra kapacitáson kevesebb mag osztozik, ami így még simább futás eredményezhet. Persze az új játékokhoz már inkább 8 mag a javasolt minimum, de egy pár éves játékhoz még valószínűleg bőven elég a 6 mag.
-
#8819
HSM
félisten
Petykemano
#8817
HSM
félisten
válasz
Petykemano
#8817
üzenetére
Vajon készlet is lesz, vagy csak kiszórják a selejtet, mint korábban a 3300X-el?
-
#8818
hokuszpk
nagyúr
Petykemano
#8817
hokuszpk
nagyúr
válasz
Petykemano
#8817
üzenetére
Zen 4 magos !
-
#8813
S_x96x_S
addikt
Petykemano
#8811
S_x96x_S
addikt
válasz
Petykemano
#8811
üzenetére
> lelkesítő, de sajnos szerintem valószínűbb,
azt már nem tudom, hogy mennyire igaz ..
de ha tényleg idén jön,
akkor augusztus végéig kell lennie valami ennél konkrétabb leak-nek is.
egyenlőre én még nem élem bele magamat ..A Threadripper Zen5c lehetőség - pedig túl jó lenne
..
annyira jó, hogy pont emiatt nagyon pici a valószínűsége. -
#8810
S_x96x_S
addikt
Petykemano
#8809
S_x96x_S
addikt
válasz
Petykemano
#8809
üzenetére
> Mindenesetre ez akkor is előrevetíthet akár egy idén év végi Zen5 rajtot.
MLID ábráján - 2023 Q4 -re van téve a "TURIN Dense Zen5c" ( SP5 )
odatekerve -> https://youtu.be/3FsUTYnQNOA?t=632 -
#8809
Petykemano
veterán
Petykemano
#8806
Petykemano
veterán
válasz
Petykemano
#8806
üzenetére
Zen5 első bench leak ES engineering sample
Szokásom visszanézni, hogy mikor volt az előző esetben az első leak és ahhoz képest mennyi idő telt el a megjelenésig.
Úgy láttam, hogy a Zen4-ről 2022 májusban érkeztek az első kiszivárgó mérések.
Ehhez képest szeptember végén jelent meg. Az mindössze 4 hónap.Persze azt tudjuk, hogy a Zen4 szándékosan késleltetett design volt, tehát elképzelhető, hogy több felkészülési idő volt és így gyorsabban tudták intézni.
Mindenesetre ez akkor is előrevetíthet akár egy idén év végi Zen5 rajtot.
Persze elképzelhető, hogy tévedek és már május előtt lehetett látni Zen4 ES-t.
A 2024Q1 akkor is reális. -
#8808
 b.
félisten
Petykemano
#8806
b.
félisten
Petykemano
#8806
válasz
Petykemano
#8806
üzenetére
Ez elméletileg AM5 foglalat lesz?
-
#8807
 awexco
őstag
Petykemano
#8803
awexco
őstag
Petykemano
#8803
awexco
őstag
válasz
Petykemano
#8803
üzenetére
Kérdés mit hoz a matek , fogyasztás , , teljesítmény …
-
#8790
S_x96x_S
addikt
Petykemano
#8784
S_x96x_S
addikt
válasz
Petykemano
#8784
üzenetére
> 2024Q4-re simán megjelenhet desktopon egy 8P + 16E magos Zen5+Zen5c változat.
Ezzel egyetértek,
de azon spekulálok, hogy szerintem ez nem biztos, hogy elég lesz.
bár a Zen5c valószínűleg nem lesz lebutitva 1 szálra,.
de a sok lúd disznót győz .. ( mivel a másik oldalon: 8+32 )a korai tesztek alapján durván +15% Cinebench R23 MT várhatunk a zen5-től ( a zen4-hez képest ) és itt még az esetleges extra 3D-Vcache hozzáadása se segít, mert érzéketlen rá.
vagyis Cinebench R23 MT -ben
a papírforma alapján az Intelnek - van esélye +25% teljesítménnyel nyerni.viszont megvan az a remény,
hogy a Cinebench új verziója már támogatni fogja az AVX-512 -őt.Még lehet reménykedni a 3 chipletes AM5 -ben is (1x8 Zen5 + 2x 16 zen5c -vel) ami már 40 mag. De ehhez annyira át kellene tervezni az I/O die-t, hogy extrém kicsi esélyt adok rá, hogyha eddig nem kezdték el.
A pozitiv olvasata az egésznek: Lesz egy kis verseny és a verseny jó!
Mindenesetre kíváncsi leszek az AMD válaszára. -
#8787
Busterftw
nagyúr
Petykemano
#8784
Busterftw
nagyúr
válasz
Petykemano
#8784
üzenetére
Másik kérdés, hogy az IPC/MT növekedés mennyi lesz a Raptor Lake refresh-hez (ha lesz) képest.
Bár ugye a sima RP-hez képest a refresh valószínűleg nem lesz egy eget rengető ugrás. -
#8780
Busterftw
nagyúr
Petykemano
#8779
Busterftw
nagyúr
válasz
Petykemano
#8779
üzenetére
Szerintem marketing szempontból is erősebb a 16 "nagy mag", kérdés ennek a valóságban mekkora jelentősége lesz.
Ha jól emlékszem az AMD is említett hybrid designt a jövőben, lehet az Intel jó lóra tett. -
#8774
S_x96x_S
addikt
Petykemano
#8773
S_x96x_S
addikt
válasz
Petykemano
#8773
üzenetére
> Mi300
izgi ...
abban reménykedek, hogy lesz Threadripperes verziója is az MI300A -nak. :-)friss tippelés mi várható:
https://www.theregister.com/2023/06/01/amd_june_event_preview/"Curiously, it appears AMD may not be using the same chiplet architecture found in last year's Epyc 4 Genoa series. The MI300A renderings appear to show two core-complex dies (CCDs) – what AMD calls its CPU chiplets. Judging from the picture, which could be obfuscated or just wrong, AMD may actually use two 16-core CCDs, like the ones we expect to find on Bergamo – more on that later – rather than two 12-core CCDs. Dual 16-core CCDs would be too many cores, but it's not uncommon for AMD to disable cores on its CCDs, bringing the working number down from 32 to 24."
"The MI300A is shaping up to be a proper APU with direct die-to-die communications and a shared pool of memory. Grace-Hopper differs in that it glues together a 72-core Arm-compatible CPU processor with a 96GB H100 GPU using Nvidia's NVLink-C2C interconnect."
-
#8771
Petykemano
veterán
Petykemano
#8761
Petykemano
veterán
válasz
Petykemano
#8761
üzenetére
Érdekes elemzés az AmpereOne A192-ről [link]
Kritizálja a teljesítmény mutatókat
Pl hogy a core/rack, amiben 3x értéket mutatnak fel, semmit nem mond a tejesítményről.
És a stable diffusiom teszt konfigurációja is sajátos. -
#8762
Alogonomus
őstag
Petykemano
#8761
Alogonomus
őstag
válasz
Petykemano
#8761
üzenetére
Azt azért fontos hozzátenni, hogy az Ampere One ARM magokkal és így ARM utasításkészlettel érkezik, míg az AMD és Intel érintett termékei x86 utasításkészttel rendelkeznek.
Az AMD is nagyjából 4 generáción keresztül ostromolta a szerverpiacot egyértelműen jobb termékekkel, mire végül komoly tényezővé vált, pedig az AMD terméke ugyanúgy x86 alapú volt, mint az Intel terméke, és legfeljebb csak kis változtatásokat kellett eszközölni a szoftverek területén, hogy azok optimálisan működjenek az AMD termékein. Az ARM utasításkészlethez igazodás érdekében alighanem határozottan mélyebb rétegektől kiindulva kellene újraírni a szoftvereket, így az ARM alapú termékek nem jelenthetnek komoly konkurenciát az évtizedek óta kialakult x86-os "nagygépes" területen, mert túl sokba kerülne újraalkotni a szoftvereket az ARM utasításkészlet lehetőségei mentén. -
#8753
b.
félisten
Petykemano
#8752
válasz
Petykemano
#8752
üzenetére
Többen megcáfoltak már, hogy valami félreértés van a dolog mögött.( Állítólag arra utaltak, hogy saját fejlesztésű.) [link]
meglátjuk mi az igazság. -
#8751
awexco
őstag
Petykemano
#8747
awexco
őstag
válasz
Petykemano
#8747
üzenetére
ha a xilinxet kivonjuk az eredményekböl akkor azért amd is beleált a földbe ...
-
#8738
paprobert
őstag
Petykemano
#8730
paprobert
őstag
válasz
Petykemano
#8730
üzenetére
Ha a Samsung még mindig le van maradva, akkor ott van értelme, ahol
dizájn-win van eleve, (GPU biztosan nem, CPU talán beleférhet)
vagy nem teljesítménykritikus alkatrészekre, pl. IO
vagy "nem számít, csak olcsó legyen" termékekre, mint a Mendocino vagy a low-end GPU-k.A TSMC finom zsarolásához sem utolsó szempont a partnerség fenntartása.
-
#8732
S_x96x_S
addikt
Petykemano
#8730
S_x96x_S
addikt
válasz
Petykemano
#8730
üzenetére
> Wow Vajon mi készül majd ott?
Szerintem ez valamilyen deal része ... valamilyen viszonosság ...
de majd meglátjuk ...
2023-04-11: "Tovább licenceli az AMD Radeon IP-ket a Samsung"
https://prohardver.hu/hir/samsung_tovabb_licencel_amd_radeon_ip.html -
#8696
HSM
félisten
Petykemano
#8692
HSM
félisten
válasz
Petykemano
#8692
üzenetére
Ezt hogyan fogják memória sávszélességgel kiszolgálni? Kicsit soknak tűnik ez két DDR5 csatorna mellé. Lesz HBM csiplet is rajta a GPU-nak?
-
#8694
 Devid_81
félisten
Petykemano
#8692
Devid_81
félisten
Petykemano
#8692
Devid_81
félisten
válasz
Petykemano
#8692
üzenetére
40CU az rengeteg, nem konzol lesz abbol?
-
#8693
Alogonomus
őstag
Petykemano
#8692
Alogonomus
őstag
válasz
Petykemano
#8692
üzenetére
Valóban soknak tűnik a 16 mag, de Tom is megjegyezte, hogy az a 16 mag esetleg ugyanúgy Zen5 és Zen5c magok keveréke lesz, ahogy állítólag a 12 magos "sima" Strix is 4+8 formátumú lesz. Úgy azért már nem olyan sok a 12 és 16 mag, hiszen még vagy 1,5 év múlva érkeznek 2024 második fele magasságában.
-
#8689
Petykemano
veterán
Petykemano
#8688
Petykemano
veterán
válasz
Petykemano
#8688
üzenetére
VCZ: [link]
-
#8686
S_x96x_S
addikt
Petykemano
#8684
S_x96x_S
addikt
válasz
Petykemano
#8684
üzenetére
a ZEN5 -ös teljesítmény ex-has becsült ..
vagyis nem vagyunk előrébb ..
sőt .. ha megint túl magasra teszi mindenki a lécet ..
akkor sokan fognak csalódni, hogyha csak ~90%-át tudja ... "There is a major catch with Tenstorrent's performance expectations: they are all projections and not real or even simulated benchmarks, Tenstorrent told Tom's Hardware. So while we can expect engineers from Tenstorrent to accurately model the performance of their own CPU design and try to predict what AMD could offer next, these are still projections, not actual benchmark results.
For obvious reasons, AMD's Zen 5 performance number has attracted the most attention, even though it is highly unlikely that this projection is completely accurate. But what is perhaps more important is that Tenstorrent expects AMD's Zen 5 to run north of 4.0 GHz and have a TDP south of 250W, as opposed to Ascalon running at around 3.80 GHz at a TDP of approximately 200W.
"
https://www.tomshardware.com/news/jim-keller-shares-zen5-performance-projections-kind-of -
#8685
S_x96x_S
addikt
Petykemano
#8684
S_x96x_S
addikt
válasz
Petykemano
#8684
üzenetére
érdekes ..
a jobb felső sarokban egy "Frequency(Ghz)" táblázat is van.
és míg a Milan - 3.5 Ghz .. a ZEN5 már 4.0 Ghz, vagyis a SPECINT-et korrigálni kell ezzel.De ha így van,
akkor az Integer végrehajtást jelentősen kiszélesítették ..
míg ZEN4 -ben csak 4 párhuzamos integer végrehajtó van
a ZEN5-ben valószínüleg ennél több, vagy valami más okosítást raktak bele.
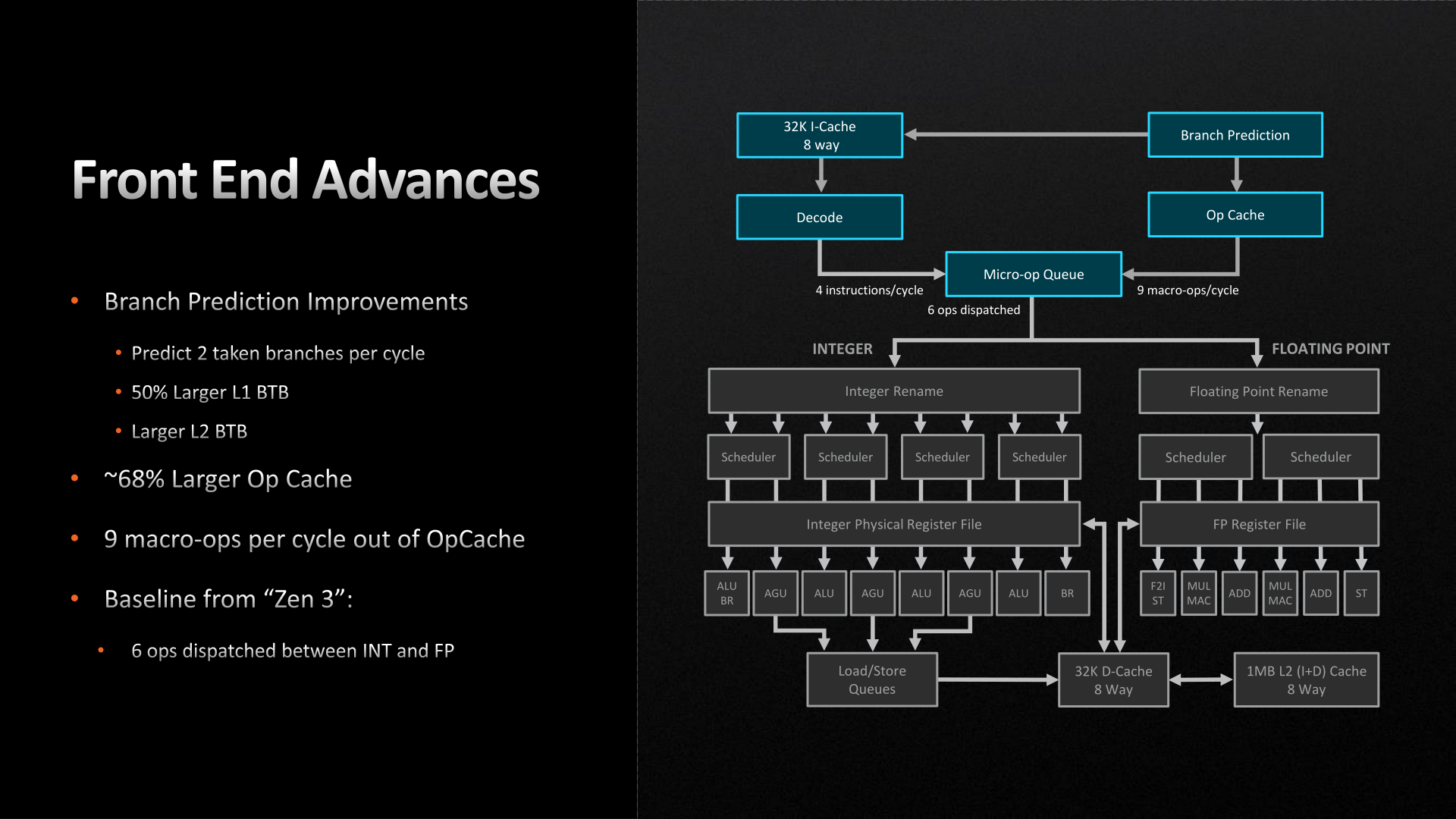
-
#8682
b.
félisten
Petykemano
#8680
válasz
Petykemano
#8680
üzenetére
Az nem lehetséges hogy ostyánkként 10 % kal több SOC jön ki ?
-
#8672
 Yutani
nagyúr
Petykemano
#8671
Yutani
nagyúr
Petykemano
#8671
Yutani
nagyúr
válasz
Petykemano
#8671
üzenetére
"Undershipping"
-
#8670
Busterftw
nagyúr
Petykemano
#8669
Busterftw
nagyúr
válasz
Petykemano
#8669
üzenetére
Valoszinuleg itt koszon vissza az elerhetoseg, legyartott mennyiseg.
Az Intel el tudja onteni a piacot client CPU-val, AMD pedig kevesbe, mert mason van a fokusz.
Illetve nagyon sokaig az Alder Lake tenyleg bestbuy volt. (az) -
#8664
S_x96x_S
addikt
Petykemano
#8662
S_x96x_S
addikt
válasz
Petykemano
#8662
üzenetére
>> az i/o die-t nehezebb skálázni ..
>> ( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )
> Túlterhelve milyen értelemben?16 mag esetén nagyobb az esélye, hogy a kommunikációt chipleten belül is el lehet intézni és kevesebb kérés megy ki az i/o die -ra.
a Genoa-ban
- 12 memoria csatorna van
- 12 cpu chiplettel ( CCD- )ha skálázni szeretnénk a magok számát,
akkor a chipletek számának növelése nehezebb út lehet, mint hogy
12 vagy 16 magos chipleteket raknak be és marad a 12 cpu chipletes felépítés.a "túlterhelést" úgy értem,
hogy 192 magos socket-et kétféleképp lehet összerakni:
a.) 24 cpu chiplet * 8 cpu-s CCD
b.) 12 cpu chiplet * 16 cpu-s CCD.és szerintem az "a.)" kevésbé optimálisabb, jobban terheli az i/o die-t
-
#8663
HSM
félisten
Petykemano
#8660
HSM
félisten
válasz
Petykemano
#8660
üzenetére
A 12-16 magos CCX ellen szól az is, hogy minél több magot fűznek rá a közös L3-ra, annál komplexebb lesz az összekötés, nő a késleltetés. A konkurencia is megütötte ezzel magát, hiszen náluk is 8 mag felett kezdett el betegeskedni a gyűrűs topológiájuk, az Alder Lake-nél is egy igen egzotikus megoldás született erre az E-magok tekintetében, lásd: [link] .
Ráadásul szerverekben azért sem lenne ennek sok értelme, mert egy 128 magos szerveren jó eséllyel nem olyan feladatok fognak futni, amik 8-nál több mag szoros együttműködését igénylik, vagy ha mégis, ott lesz arra pénz, hogy úgy optimalizálják a szoftvert, hogy ne legyen gond ebből a felépítésből.
-
#8661
S_x96x_S
addikt
Petykemano
#8660
S_x96x_S
addikt
válasz
Petykemano
#8660
üzenetére
> Vajon mi értelme/célja lenne a CCX-en belüli magszám emelkedésnek?
szerintem praktikussági és egyszerűségi okok lehetnek mögötte ...
pl.
1. ) az i/o die-t nehezebb skálázni ..
( vagyis az az egyik cél, hogy az Infinity fabric ne legyen túlterhelve. )2.) packagelési / gyártási / ökoszisztéma egyszerűsítés
ha több CCD (chiplet) -> több macera, akkor okosan vállaljuk be .
mert jelentősen át kell tervezni szinte mindent
.. a desktop hűtőket, és az i/o die-t, ..
és az elég nagy változtatás .. ami növeli a kockázatokat.Amúgy a CCX magszám növelésének - szervereknél a a cloud-nál
lehet egy olyan hatása is,
hogy eddig egy 8 magos Virtuális gép volt az optimális ( a késleltetés miatt )
és ez a limit most felmegy 16 magosra.
De akár a chipleteket biztonsági védőhálóval is fel lehet vértezni.
és a 16 mag jövőállóbb.Amúgy az is lehet, hogy már a következő konzol APU-t is próbálják összerakni/demózni.
és az két chipletes felépítésű lesz.
- 16 magos CCX
- RDNA4de ez csak találgatás . igazából nem tudom ..
-
#8654
S_x96x_S
addikt
Petykemano
#8653
S_x96x_S
addikt
válasz
Petykemano
#8653
üzenetére
> A 7600X3D szerintem akkor kerülne piacra, ha a meteor lake megérkezik.
spekulálva az én ex-has véleményem:
bármi lehetséges, és akár ősszel is ..
- "Raptor Lake Refresh" lesz az ellenfél.
- 7800X3D árát is csökkentik, mivel jönnek a 8000 -es ryzenek.
- ha az X3D-sek nagyon jól mennek a piacon, akár már a nyáron is megjelenhet a 7600X3D.kiegészítő:
- a 7600X3D - alatt én desktop-ot értek,
- és "az Intel törölte a Meteor Lake-S kódnevű fejlesztést, azaz papíron az asztali Meteor Lake sorozatot," ( via Prohardver-abu-2023-02-23 ) -
#8652
b.
félisten
Petykemano
#8650
válasz
Petykemano
#8650
üzenetére
7700X ben várható 3 D ?
-
#8648
HSM
félisten
Petykemano
#8647
HSM
félisten
válasz
Petykemano
#8647
üzenetére
Az L2 növelésének szvsz nem lett volna értelme, hiszen az rendkívül késleltetés-kritikus, ott nem nagyon fér bele az a néhány órajeles büntetés, mint az L3-nál.
-
#8641
S_x96x_S
addikt
Petykemano
#8639
S_x96x_S
addikt
válasz
Petykemano
#8639
üzenetére
> az AMD talán próbálgatja,
> de komolyan nem tervezi olyan nagyobb gpu erővel rendelkező apu piacra vitelét,szerintem valami a (technológiailag | gazdaságos gyártáshoz ) még hiányzik.
Ha minden rendelkezésre áll, akkor már nyomnák a piacra.
( Legalább a Prémiumos-ra .. )
És azt is remélem, hogy erre is gondoltak az AM5 socket tervezésénél )Technológiailag az egyik probléma az extrém hőtermelés lehet ,
ami minden sűrű design ( avx-512 ; gpu ; 3D-Vstack ) velejárója.
A jövő évi következő generációnál én viszont már várnék valami piaci próbálkozást is.
( remélhetőleg a GPU chiplet is kiforrja magát )A jövőben mindenképpen elkerülhetetlen lesz .. és ezt az AMD is látja ..
"AMD Envisions Stacked DRAM on top of Compute Chiplets in the Near Future"
https://www.techpowerup.com/305060/amd-envisions-stacked-dram-on-top-of-compute-chiplets-in-the-near-future
( a lenti ábránál )
viszont ami érdekes, hogy nincs megemlítve az Infinity Fabric.
csak a UCIe ..
ha az AMD hosszú távra gondolkodik és a UCIe-re fókuszál a GPU chiplet esetén, akkor az a piaci értékesíthetőség miatt is lehet, hogy más chipek ( ARM/RISC-V ? ) mellé lehessen tokozni.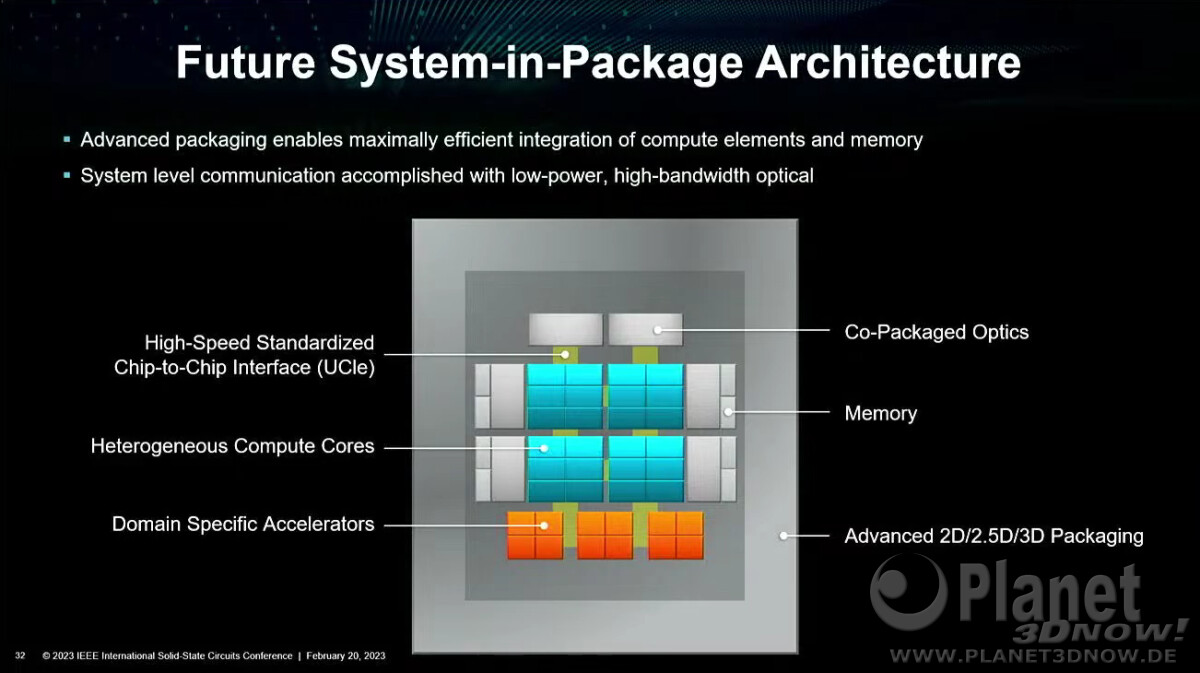
-
#8634
HSM
félisten
Petykemano
#8633
HSM
félisten
válasz
Petykemano
#8633
üzenetére
Jelenleg játékokban kevés esetben jut szerep 8 erős magnál többnek. Remek és kellően extrém példa, a TPU 720P+Ultra tesztje RTX4090-el, a 7950X ugyanazt tudja, mint a 7700X, míg a "házi készítésű" 7800X3D vagy a cache-preferált 7950X3D szépen ellép mindentől [link] . Ez alapján én azt gondolom, racionális vásárló nem játékra vesz ilyesmit elsősorban, tehát nem feltétlen lesz mellette egy extra torkos VGA. Illetve vannak még hozzám hasonló emberek, akik azt sem szeretik, ha feleslegesen sokat fogyaszt a rendszerük, és inkább rászánnak kis időt a gyárinál kedvezőbb perf/watt működésre hangolni a rendszert. És nem is feltétlenül a gazdasági oldala miatt, az is manapság már hangsúlyosabb, de anélkül sem szeretem a pazarlást, az indokolatlan fogyasztást.
-
#8632
HSM
félisten
Petykemano
#8631
HSM
félisten
válasz
Petykemano
#8631
üzenetére
"Persze az is világos, hogy nem ez az 50-60W lesz a meghatározó a 400-500W-os videokártyák mellett."
Azért 4-500W-os videókártyák szerencsére elég ritkák. Talán a 3090TI és RTX4090 megy fel eddig, a többi inkább 350W és alatta. Nekem csak egy "szerény" 6800XT-m van, papíron 300W TBP, de kicsit finomhangolva már vidáman elvan kevesebből gyorsabban, az egész gép szokott fogyasztani egy PBO-zott Ryzen 5600-al Witcher 3 RT alatt ~350W-ot konnektorból, monitor nélkül...RTX4090 ugyanúgy kb. teljesítményvesztés nélkül 300W-ra lehúzható.
Szóval szerintem van jelentősége, hogy a CPU 80 vagy 150W-ból látja el a feladatát, főleg egy józanul konfigurált VGA mellett. Nekem nagyon tetszik egyébként, hogy a 7950X3D némileg csökkentett TDP keretet kapott, így sokkal jobb perf/watt mellett üzemel.
TPU-nál nagyon érdekes, hogy megnézték a fogyasztásokat és perf/watt-ot, hogyan alakulnak a különböző CCD-ket preferálva: [link] . Elég szembeötlő az alacsonyabb órajelre korlátozott, így szükségszerűen hatékonyabb CCD előnye.
-
#8627
S_x96x_S
addikt
Petykemano
#8620
S_x96x_S
addikt
válasz
Petykemano
#8620
üzenetére
> "Ha az AMD core design-ja egyszerűbb és kisebb is, viszont
> az AMD több packaging trükköt kellett felhasználnia.
> Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache
> lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta."azért az AMD-nek megvan a technológiai tapasztalata és előnye
és ez az előny nagyrészt a TSMC-vel történő szoros együttműködésből is következik.Az hogy az Intel előtt ott van a lehetőség nem jeleni azt is hogy sima út. A Sapphire Rapids az első komplexebb chipje az Intelnek és igencsak izzadságos volt.
És az AMD is volt egy kis melója a 3D-Vcache-el és nem hiszem, hogy ne lehetne még tovább
fejleszteni.- Ha az AMD kiheréli az AVX-512 -öt a ZEN4c/4d -ből, akkor az egy öntökönszúrás ..
- az AMX utasításkészlet hiányzik még ahhoz, hogy teljesen utolérje az AMD az Intelt.
- A ZEN5 -re +20-40% IPC célt ( a ZEN4-hez ) - pletykált MLID ( 2021 November)
vagyis én itt jelentős szélesítést várok.
- amit én érzékelek, hogy az InfinityFabric a fő fókusz és az MI300 szerű konstrukció jöhet AM5-re is. ( Threadripper meg eleve adott lesz )
- És a ZEN5-ös is már kaphat NeuralEngine- gyorsítót.
- És talán elkezdődik az FPGA mélyebb integráció a GPU és CPU-ba.
-
#8625
HSM
félisten
Petykemano
#8620
HSM
félisten
válasz
Petykemano
#8620
üzenetére
"Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta."
Itt azért hozzátenném, hogy a packaging trükk nem feltétlen egy egyszerű gyártástechnológiai dolog. Valószínűleg szinte mindent hozzá kell igazítani, optimalizálni, hogy jól működjön. Az AMD-nél erre sokéves gyakorlat van. Ezt nem feltétlen lesz egyszerű behozni. -
#8624
paprobert
őstag
Petykemano
#8620
paprobert
őstag
válasz
Petykemano
#8620
üzenetére
Egyetértek a meglátásaiddal.
Az Intel gyártástechnológiai hátránya leginkább abban mutatkozik meg, hogy maximum terhelésen irdatlan magas a fogyasztás.
Meg tudták építeni azt a magot, amit szerettek volna, nem kellett visszavágni az architektúrát, el tudták érni a megcélzott órajeleket, de a működési tartományt vizsgálva a vállalhatatlan kategóriába csúszott padlógázon a termék.Én a találgatások idején a Zen4-re a mag szélesítését vártam volna, de egyértelműen nem ez történt. A Zen4 igazából egy ultra-low latency mag. Ennél sokkal jobbat chipletezéssel már nagyon nehéz elérni.
A kérdés, hogy hogyan fog tudni szélesíteni az AMD a jövőben, hogy ne essen visssza a latency Zen1 szintre?
Illetve mikor hoz olyan hibrid dizájnt, ahol egy low-latency és/vagy throughput-optimalizált és/vagy egy szélesített "nagy mag" CCD fog együtt dolgozni?Ideális esetben a jelenlegi Zen4 fölé és alá is kellene egy új mag család, hogy az egy szálas teljesítmény, és a throughput is javulhasson, 3 szintes hibrid dizájnként.
-
#8622
S_x96x_S
addikt
Petykemano
#8620
S_x96x_S
addikt
válasz
Petykemano
#8620
üzenetére
> Az jár a fejemben, hogy azért az Intel akkor valamit mégiscsak jól csinál...
Kíváncsi leszek a Raptor Lake frissítésre, vajon mivel lesz több ?
( mert a Meteor Lake-S -t a fejlettebb magokkal elkaszálták )mindenesetre teljesen kiszámíthatatlan a jövő .. gyors és hirtelen változások vannak ...
-
#8621
S_x96x_S
addikt
Petykemano
#8618
S_x96x_S
addikt
válasz
Petykemano
#8618
üzenetére
> Azt írják, átlagban 5-6%-kal gyorsabb,. mint az 13900K
talán van még remény ..
"These benchmarks might have been done with the older chipset drivers. The new chipset and optimized drivers deliver at least 20% better performance than the previous ones so wait for the real benchmarks next week. :)"
https://twitter.com/hms1193/status/1629116333991272449valószínüleg erre gondolhattak
"AMD Preps New 1.0.0.7 Chipset Driver Optimized For Ryzen 7000 3D V-Cache CPUs"
https://wccftech.com/amd-preps-new-1-0-0-7-chipset-driver-optimized-for-ryzen-7000-3d-v-cache-cpus/ -
#8620
Petykemano
veterán
Petykemano
#8618
Petykemano
veterán
válasz
Petykemano
#8618
üzenetére
Az jár a fejemben, hogy azért az Intel akkor valamit mégiscsak jól csinál...
az N5 azért valamivel mégiscsak fejlettebb gyártástechnológia, mint az Intel 7. Tranzisztorsűrűségben mindenképp és talán fogyasztásban is.
70-80mm2-es N5 lapka + ~120mm2-es N6 lapka. Utóbbiban döntően olyan részegységek vannak, amelyek N5-ön sem lennének sokkal kisebbek. Tehát az egész nyugodtan tekinthető egy kb 200mm2-es lapkának. Persze az AMD gyártási költség vonatkozásában talán sokat nyer azon, hogy a lapka nagyobb része mégse a drágább gyártástechnológán készül, de valamit meg veszít (latency) azáltal, hogy a chipleteket össze kell kötni.Ha pontos akarok lenni, akkora 2CCD-s változathoz két ~80mm-es lapka kell, ami már nem is 200 akkor, hanem 280. És ahhoz, hogy ez elérje azt a játék teljesítményt, amit az Intel lapkája tud, rá kellett még pakolni legalább egy kb ~40mm-es cache lapkát. Ez alsó hangon 240, felső hangon 320mm2 lapkát jelent. Nem is beszélve a 3D packaging költségéről, hibalehetőségeiről.
(Persze az is világos, hogy az AMD nem a legjobb asztali CPU teljesítmény elérése érdekében csinálja így, hanem pont a skálázhatóságért.)
Tulajdonképpen az AMD használ most több szilíciumot, komplexebb a gyártástechnológiája. Persze cserébe lényegesen jobban skálázható, szűkös waferkapacitások esetén talán előnyösebb allokációs lehetőséggel.
az Intel core design-ja szerintem valamivel jobb, de valószínűleg lényegesen nagyobb, ami sokat ront a skálázhatóságon. A MT teljesítményt kismagokkal érik el, ami az asztali környezetben jól mutat, de az elvileg jobb core design szerverkönyezetben való költséghatékony újrahasznosítását nem segíti. (feltéve, hogy az Intel nem akar ott is hybrid designnal megjelenni) Ha az AMD core design-ja egyszerűbb és kisebb is, viszont az AMD több packaging trükköt kellett felhasználnia. Tehát míg az Intel előtt még mindig nyitva van az a 3D packaging / v-cache lehetősége a teljesítmény további növelésére, addig ezt a lapot az AMD már lehívta. Az AMD chipletezik, lehívta az ebből fakadó költség és volumen előnyöket, addig az Intel előtt ez az út még mindig nyitott.Én azt látom, hogy az AMD lehívta az előtte álló core design-on kívüli low-hanging fruits-ok lehetőségeit és következő lépés mindenképpen a core design komoly átalakítása. Erre egyébként elő is készítették a terepet a Zen4c bevezetésével. Megengedhetik maguknak azt, hogy hízlalják a magot, ha annak lesz karcsúsított változata is párhuzamosan.
És lassan az Intel is talán megérkezik a saját packaging technológiáival, chipleteivel.
-
#8613
hokuszpk
nagyúr
Petykemano
#8612
hokuszpk
nagyúr
válasz
Petykemano
#8612
üzenetére
ilyen egál vagy lassabb esetekben az 5800X3D védhető volt azzal, hogy alacsonyabb a boostja ; a 7800X3D -t majd meglátjuk ; de talán a marketingnek jóttenne, ha ezekről a 16 magos motyókról olyan eredmenyek szivarognának ki, ahol látszik, hogy erősen besegit a cache, mert maxfrekiben papiron megegyezik a normál verzióval.
-
#8606
hokuszpk
nagyúr
Petykemano
#8604
hokuszpk
nagyúr
válasz
Petykemano
#8604
üzenetére
nagyon egyszerű logikával közelítem a dolgot : az L3 ha jóltévedek victim cache.
azaz az előtte lévő szintekből kicsorgó adatokat tárolja. Szvsz dupla méretú L1 -ből kevesebb adat csorog le. Zen5 -re volt valami hír, hogy összevonják az L2 -t ; ha igaz a hír megkockáztatom, hogy bazi nagy közös L2 mellett akár el is tűnhet az L3. -
#8605
S_x96x_S
addikt
Petykemano
#8604
S_x96x_S
addikt
válasz
Petykemano
#8604
üzenetére
A GeekBench -es dolgot a videocardz és a wccftech is lehozta ..
Azzal egyetértek, hogy kis mintából nem sokat tudunk következtetni
- csak azt, hogy elkezdödött a tesztelés és kezdem magamat felkészíteni a MultiCore csökkenésre, habár nekem a Phoronix-os teszt lesz a mérvadó ..
- A geekbench-es teszt amúgy se volt sose a kedvencem .."AMD Ryzen 9 7950X3D in Geekbench: slower multi-core, similar single-core to 7950X"
https://videocardz.com/newz/amd-ryzen-9-7950x3d-spotted-on-geekbench-with-similar-single-core-performance-to-7950x"AMD Ryzen 9 7950X3D 3D V-Cache CPU Benchmarks Leak: 10% Slower In Multi-Thread & Similar Single-Core As 7950X"
https://wccftech.com/amd-ryzen-9-7950x3d-3d-v-cache-cpu-benchmarks-leak-10-percent-slower-versus-7950x/ -
#8603
hokuszpk
nagyúr
Petykemano
#8602
hokuszpk
nagyúr
válasz
Petykemano
#8602
üzenetére
nemtalálom hol, de valahol azt tippeltem, hogy olyan nagyot, mint az 5800X3D nem fog ütni, mert azoknak a szűk keresztmetszeteknek egy reszet, amit a 3d cache athidal, kiutoltak az L1, TLB es tarsai mértének növelésével. Azert valamire biztos jó lesz ; olyan indokkal, hogy "mindenki erre vár", csak nem dobja piacra az AMD.
-
#8601
hokuszpk
nagyúr
Petykemano
#8598
hokuszpk
nagyúr
válasz
Petykemano
#8598
üzenetére
ipc = Zen4 * 1.22 ? na arra már talán érdemes lesz a Zen3 -ról váltani.
kerül amibe. kezdem félretenni a lét. -
#8592
HSM
félisten
Petykemano
#8591
HSM
félisten
válasz
Petykemano
#8591
üzenetére
A Vermeer PCIE4-es. Az APU verziók, Renoir, Cezanne voltak 3.0-k. A Rembrandt-ban újították fel az IO-t, az már PCIE4.0-val és USB4-el jött.
De amúgy engem sem lepett meg emiatt, amire gondoltál. -
#8583
S_x96x_S
addikt
Petykemano
#8582
S_x96x_S
addikt
válasz
Petykemano
#8582
üzenetére
> a pletykák - MLID - amelyek nagyon hamar, 2023Q4-re tették a Zen5 rajtját.
> ... hogy akár lehetséges lehet.szerintem ez valamilyen belső határidő lehet, amit erőltetett menetben próbálnak tartani ..
És reménykedem, hogy sikerül is .. és minimálisan legalább egy paper launch lesz belőle ..
De a teljes zen5-ös termékskálát nem hiszem, hogy ki fogják hozni idén ..

https://www.anandtech.com/show/17439/amd-zen-architecture-roadmap-zen-5-in-2024-with-allnew-microarchitecture
+
- AMD’s Data Center Roadmap: EPYC Genoa-X, Siena, and Turin
- AMD Laptop, Desktop Roadmap: Zen 5 Strix Point, Granite Ridge in 2024megj: azért más a CPU CORE ROADMAP .. és a termék ROADMAP ..
> Persze nyilván vannak más szempontok is.
> Többek között hogy lesz-e akkor már elérhető gyártósor, amin a Zen5 készülne,ha jól látom, a végleges gyártósor még lebegtetve van ..
feltételezem, hogy minden eshetőségre felkészült az AMD .. ( 4nm vs. 3nm )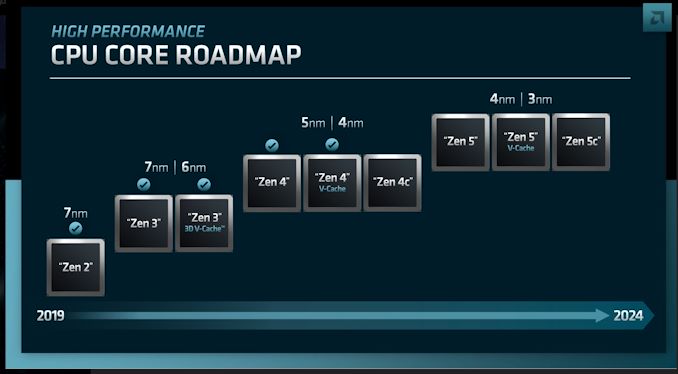
II.
> Többek között hogy lesz-e akkor már elérhető gyártósor,nézegetve a https://www.semianalysis.com/p/iedm2022p1 ( friss mai : 4 hr ago )
A TSMC N3B szerverre és mobilra talán jó, de nem várható még 5 GHz ..
Az N3E - jobb lesz, de az csak 2023 végén várható ..
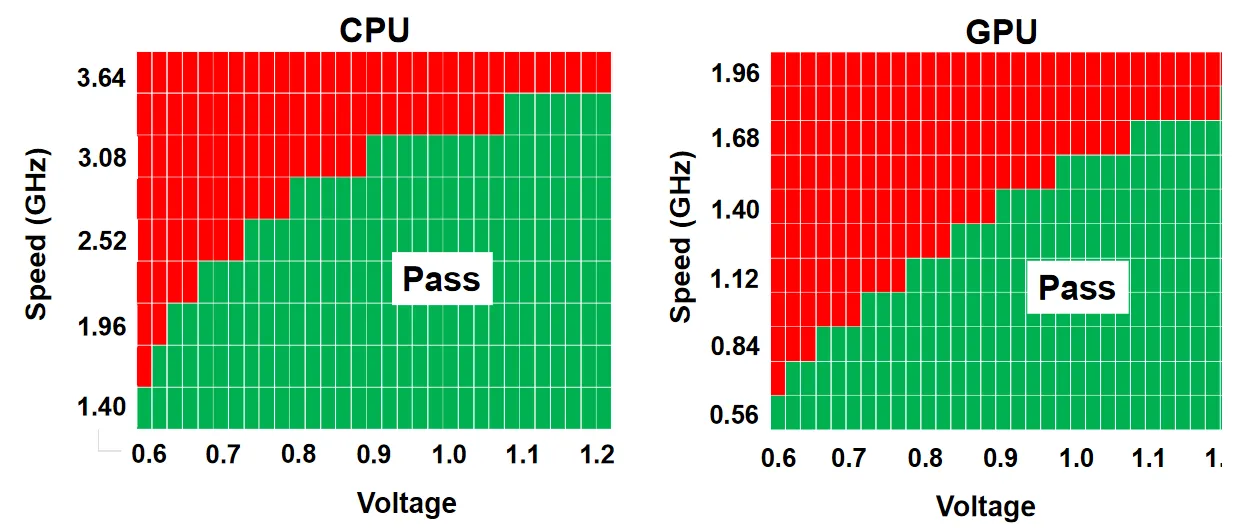
( "N3E enters production in mid to late 2023. " ) És mivel az Apple lesz az első körös .. én nem számolok azzal, hogy az AMD beleférne."TSMC also showed shmoo plots of a test chip on their N3B node, which showed a CPU core reaching 3.5 GHz at 1.2V and a GPU core reaching 1.7 GHz at 1.2V. They also showed a shmoo plot of the SRAM in the chip, which was fully functional down to 0.5V."
-
#8581
S_x96x_S
addikt
Petykemano
#8580
S_x96x_S
addikt
válasz
Petykemano
#8580
üzenetére
> Ez persze nem hivatalos, de két érdekes információmorzsa:
> - a Zen4 2 negyedéved csúszott a CXL integráció céljából.ha jól tudom, a 2 negyedéves csúszás Forrest Norrod publikusan felvállalt döntése volt,
valószínüleg a Cloud-os ügyfelek nyomására .. ( Type 3 memory devices támogatása )
"
Forrest Norrod: First of all, we really like CXL. I delayed Genoa to get CXL in it.
We really like UCI, but I think that it is going to be a couple of generations before it gets to the point you can have high bandwidth and relatively low latency connections between discrete functions.
If you can put a clean boundary around a function, I think that you can connect them with UCI fairly easily. And that is not first generation, but second generation – that’s sort of the way these standards go. But if you need to use chiplets to break up a function and then scale that function with multiple dies, the interconnect for that sort is so different. It is difficult to tunnel stuff like that through a standard interface of any type. If you are breaking up a function, you really want 20,000 wires, and you don’t want to impose a protocol and you don’t want to impose any sort of latency cost on top of that."
https://www.nextplatform.com/2022/10/03/the-steady-hand-guiding-amds-prudently-expanding-datacenter-business/-------------------
As Norrod explained to us several weeks ago, Genoa was delayed by two quarters to intersect the CXL disaggregated memory standard, but AMD never dreamed that it would be beating Intel’s “Sapphire Rapids” Xeon SPs to market. Genoa was timed to come to market around the same time as Intel was expected to have its “Granite Rapids” Xeon SPs to market, which are now coming in 2024.
https://www.nextplatform.com/2022/11/10/amd-genoa-epyc-server-cpus-take-the-heavyweight-title/
--------------------------AMD generally supports CXL 1.1 but supports CXL 2.0 for Type 3 memory devices. We exclusively detailed this feature support level here.
"Type 3 is what the ecosystem wanted." ( Kevin Lepak, Genoa Server SOC Chief Architect )
Genoa was delayed 2 quarters to add this feature, and we believe that was the correct decision.
https://www.semianalysis.com/p/amd-genoa-detailed-architecture-makes -
#8579
 IzI
senior tag
Petykemano
#8578
IzI
senior tag
Petykemano
#8578
IzI
senior tag
válasz
Petykemano
#8578
üzenetére
Sajna nem
 ,pont ami szóba jöhetett volna.Ráadásul drága is lesz
,pont ami szóba jöhetett volna.Ráadásul drága is lesz -
#8561
S_x96x_S
addikt
Petykemano
#8560
S_x96x_S
addikt
válasz
Petykemano
#8560
üzenetére
> Not sure if this is widely known, Zen 5 is family 26/1Ah.
> Nem tudom, hol kellene nézni. ...a számozás egyszerű ...
"AMD calls its Zen 4 CPU core design an “incremental update“ over Zen 3. This shows with the same CPUID Family 19h for products using either core generation. The next major revision arrives in 2024 with Zen 5 (Family 1Ah)."
https://www.angstronomics.com/p/ryzen-7000-desktop-previewhexában van a számozás
19h(hex) --> 1*16 + 9 = 25 decimális
1Ah(hex) -> 1*16 + A( = 10) = 26 decimalis.itt is van egy lista:
https://en.wikipedia.org/wiki/List_of_AMD_CPU_microarchitecturesAz AMD CPU azonosító alapján tudja a kernel, hogy melyik mikrokód kell neki ..
pl. "AMD Publishes New Family 19h CPU Microcode"
https://www.phoronix.com/news/AMD-EO-September-Microcode -
#8553
S_x96x_S
addikt
Petykemano
#8552
S_x96x_S
addikt
válasz
Petykemano
#8552
üzenetére
> A nagyobb Delta gondolom Annak köszönhető,
nagyrészt igen ..
spekuláció:
de ahogy egyre jobban tuningolják az AVX-512 -es támogatást a ZEN4-re is,
szerintem egy picit változni fog a kép a zen4 javára.
( a korai sw-es támogatás nem annyira erőssége az AMD-nek )-------------------------
kapcsolódva:A ZEN4-ben van "Automatic IBRS mitigation for Spectre V2 mitigation"
ami még csak most kerül majd be a Linux-ba.
És ez is segít a teljesítményben .."This AMD Ryzen 9 7950X, AMD Radeon RX 6800 XT, ASUS ROG CROSSHAIR X670E HERO, 2 x 16GB DDR5-6000 memory, and WD_BLACK SN850X 2TB NVMe SSD desktop indeed was showing better performance for Automatic IBRS enabled kernel for workloads with high kernel interactions / sensitive to Spectre V2 mitigations."
https://www.phoronix.com/review/amd-auto-ibrs/2
"Automatic IBRS is able to help slightly improve the performance for workloads with high kernel interactivity and impacted by Spectre V2 mitigations / Retpolines. This lower-overhead handling than Retpolines mitigation can be particularly beneficial for server workloads that tend to be more involved than conventional desktop applications, so Automatic IBRS is especially good news for AMD 4th Gen EPYC "Genoa" servers." -
#8542
S_x96x_S
addikt
Petykemano
#8541
S_x96x_S
addikt
válasz
Petykemano
#8541
üzenetére
> Ez a CDX milyen viszonylatban áll CXL-lel, meg az infinity cumókkal?
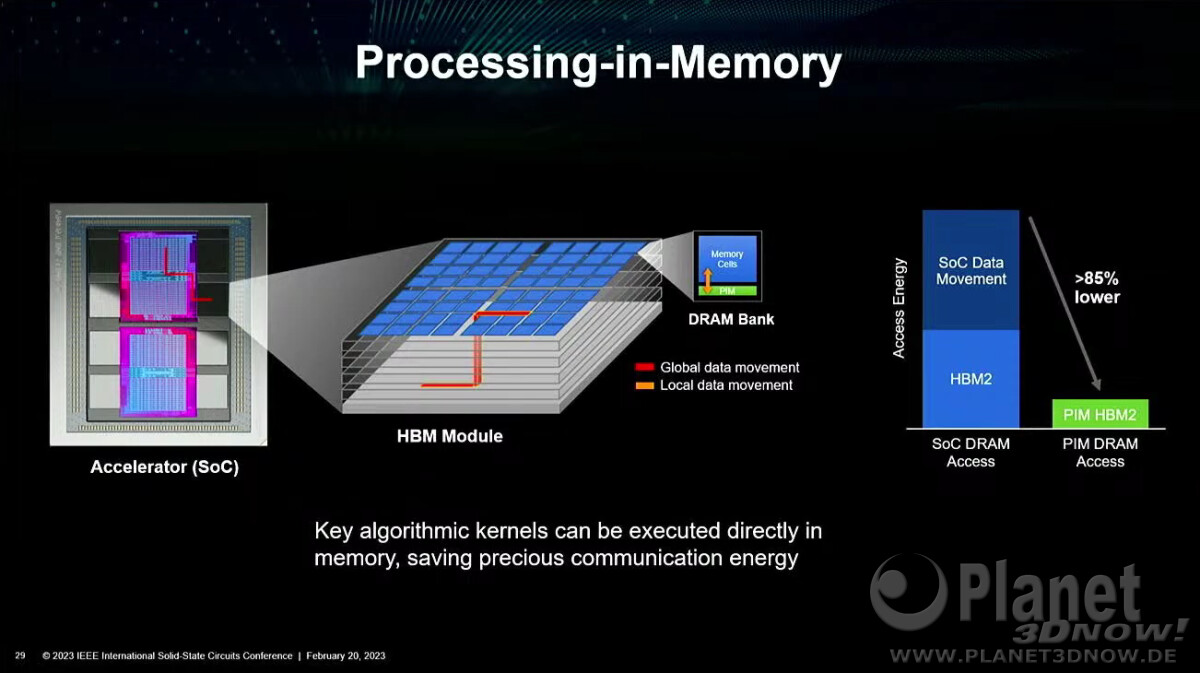
igazából nem nagyon tudom .. de valamilyen kapcsolat lehet ...
még ezt találtam egy agusztusi hírben ami segíthet elhelyezni a fogalmi térképünkön:
"So right now this CDX bus is intended for the dynamic addition/removal of FPGA devices exposed to the embedded Arm CPU cores. Though CDX may also play an important role with future AMD processors expected to introduce onboard Xilinx accelerators, so we could see the CDX bus potentially used there too. There is talk that as soon as next year AMD could be potentially integrating Xilinx "AI engines" onto AMD CPUs and other accelerators also likely to be introduced in the future, thanks to AMD's acquisition of Xilinx that closed earlier in the year."és talán ezt érthetik CDX alatt ?? = Chiplet Design Exchange
https://semiengineering.com/standardizing-chiplet-interconnects/"“UCIe advocates have clearly defined their areas of focus, which include die-to-die I/O with industry leading KPIs, CXL/PCIe for near-term volume attach, and a well-defined specification that ensures interoperability and evolution,” said Keith Felton, product manager for the Embedded Board Systems division of Siemens EDA. “Looking ahead, UCIe should look to partner closely with other industry alliances focused on enabling commercialization and usage of chiplets such as the Chiplet Design Exchange (CDX) project that is part of the Open Compute Project’s ODSA/CDX Business working group.”"
-
#8538
Busterftw
nagyúr
Petykemano
#8537
Busterftw
nagyúr
válasz
Petykemano
#8537
üzenetére
N3-mal AMD mar 2024 vegen szerintem szamol, next gen Radeon time.
Persze az is benne van a pakliban, hogy maradnak 5nm-en.(Nvidia szerintem atmegy N3-ra, ugye elvileg mondtak, hogy az MCM designhoz nekik az feltetel.)
-
#8533
S_x96x_S
addikt
Petykemano
#8532
S_x96x_S
addikt
válasz
Petykemano
#8532
üzenetére
mindenképpen ..
de megvárom a Phoronix -os tesztet .. és valószínűleg az alapján döntök.
7950X vs 7950X3D
ez itt a kérdés ..
Persze én a sakkot leszámítva már nem nagyon játszom ..
úgyhogy főleg munkára kell..
vagyis az én esetem nem nagyon általánosítható.Nekem még egy 2x X3D-s max 5.0 Ghz -es cpu is ideális lenne,
de ezt a fele-ilyen fele-olyant .. még nagyon emésztenem kell ..Amúgy ennél nagyobb problémám ne legyen az életben ..
jó - és mégjobb között kell választanom .. -
#8529
S_x96x_S
addikt
Petykemano
#8524
S_x96x_S
addikt
válasz
Petykemano
#8524
üzenetére
> milyen következtetést lehet levonni
> az AMD wafer ellátottságára és annak jövőbeli árazására vonatkozólag.a TSMC-nek is alkalmazkodni kell a piaci körülményekhez.
Lehetséges, hogy valamilyen árcsökkentéssel vonzóvá teszi az N3-as platformot.TSMC Might Cut 3nm Prices to Lure AMD, Nvidia
By Anton Shilov published 5 days ago
Industry sources say TSMC is considering lowering 3nm prices to stimulate interest from chip designers
https://www.tomshardware.com/news/tsmc-might-cut-3nm-prices-to-lure-amd-nvidia
"...
We believe the meaningful [N3] ramp-up will be in 2H 2023 when the optimized version, N3E, will be ready," wrote Szeho Ng, an analyst with China Renaissance. "Its major customers in HPC (i.e., AMD, Intel), smartphone (i.e., QCOM, MTK) and ASIC (i.e., MRVL, AVGO, GUC) will likely stay in N4/5 and choose N3E as their maiden N3 class foray, in our view. Meanwhile, we believe the baseline N3 (aka N3B) adoption will be largely limited to Apple products."To stimulate its partners into using its N3-class process technologies, TSMC is reportedly considering lowering its quotes for these nodes. In particular, TSMC's N3E process uses EUV only for up to 19 layers and features somewhat lower complexity in terms of manufacturing, and is thus cheaper to use. TSMC could lower quotes of N3E production without harming profitability. N3E provides zero advantages over N5 when it comes to SRAM cell scaling, which means larger die sizes when compared to those made on N3/N3B.
AMD publicly announced that it planned to use an N3 node for some of its Zen 5-based designs due in 2024, and Nvidia is expected to adopt N3 for its next-generation Blackwell architecture-based GPUs set to arrive around the same timeframe. Due to high costs, adoption of N3-class nodes is expected to be limited to certain products — so lowering quotes will probably make chip designers reconsider their adoption strategy.
There's also another issue with TSMC's N3: low yields. Some estimate yields are between 60% and 80%, and sources at DigiTimes (via Dan Nystedt) indicate that they're below 50%. That said, since only Apple reportedly uses this manufacturing technology and the company is known for being very secretive, any details about yields of initial N3 chips should be taken with a large grain of salt."
-
#8527
 ShiTmano
aktív tag
Petykemano
#8526
ShiTmano
aktív tag
Petykemano
#8526
ShiTmano
aktív tag
válasz
Petykemano
#8526
üzenetére
Applenak minden belefér. Fanok megveszik a legújabbat is. [Iphone 14]










![;]](http://cdn.rios.hu/dl/s/v1.gif)



 .. nagyon lassan megy a launch.
.. nagyon lassan megy a launch.













 ,pont ami szóba jöhetett volna.Ráadásul drága is lesz
,pont ami szóba jöhetett volna.Ráadásul drága is lesz
Új hozzászólás Aktív témák
- Lenovo ThinkPad P1 Gen 4 i7 32GB RAM 512GB SSD NVIDIA T1200 16 2560 1600 Garancia
- Dell Precision 7550 i7 32GB RAM 512GB SSD NVIDIA Quadro T1000 FHD
- Dell Precision 5560 i7 32GB RAM 512GB SSD NVIDIA RTX A2000 FHD+
- BOMBA áron eladó új Microsoft Surface Laptop 4 garanciával! AMD Ryzen 5 /16GB /256 SSD/TOUCH/13.5"/
- Dell Latitude 7420 i7 / 32GB /1TB SSD / FHD IPS
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7800X3D 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
- LG 65QNED86T3A / QNED / 65" - 164 cm / 4K UHD / 120Hz / HDR Dolby Vision / FreeSync Premium / VRR
- Új és újszerű 15-16 Gamer, irodai, üzleti, készülékek nagyon kedvező alkalmi áron Garanciával!
- LG 27GS60QC-B - 27" Ívelt - 2560x1440 - 180Hz 1ms - AMD FreeSync - Bontatlan - 2 Év Gyári Garancia
- Acer Nitro 16 - 16" WQXGA 165Hz - Ryzen 7 8845HS - 16GB - 1TB - Win11 - RTX 4070 - Garancia
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: NetGo.hu Kft.
Város: Gödöllő