Hirdetés
Új hozzászólás Aktív témák
-

S_x96x_S
addikt
válasz
 solfilo
#4550
üzenetére
solfilo
#4550
üzenetére
> A kérdés már csak az, hogy az AMD termelése (kb mindent eladnak gondolom)
már a Microsoft is az AMD-hez könyörög .. "Microsoft to AMD: Please help us!"
https://edition.cnn.com/2021/01/04/tech/xbox-amd-console-shortages/index.html"Microsoft Executive Vice President of Gaming Phil Spencer acknowledged the Xbox shortage in a podcast interview last week with Xbox Live programming director Larry Hryb, and said he has sought help from chipmaker AMD (AMD) in making more units available. AMD makes the processor and graphics chips for the Xbox consoles.
"I was on the phone last week with (CEO) Lisa Su at AMD (asking), 'How do we get more? How do we get more?,' So it's something that we're constantly working on," Spencer said. He did not go into detail about how AMD might help make more units available more quickly, and AMD did not immediately respond to CNN Business' request for comment.
"We got the consoles launched — wish we had more of them, we're selling out too quickly," Spencer added.
"Mottó: "A verseny jó!"
-

Cathulhu
addikt
válasz
 S_x96x_S
#4545
üzenetére
S_x96x_S
#4545
üzenetére
Ebben a megoldasban szerintem csak a szuperszamitogepek piacan lehet igazan impactja. Amig ez nem automatikusan tortenik, hanem a szoftverhez kell mellekelni egy masikat amit aztan indulaskor beleir az FPGA-ba, addig ezt csak a nagyon egyedi, celszoftverek fogjak kihasznalni, altalanos celuak nem igazan. Ne erts felre, van benne jovo, de nem jelen leirt formaban. Ha mondjuk a proci a programkod betoltesenel eszreveszi, hogy van abban olyan insturkcio amit o nem tamogat ezert egy ROMbol automatikusan betolti az mukodhet.
RDNA melle nagyobb ertelmet latnam, hogy mondjuk inferencere barmilyen random deeplearning halot be tudna FPGA-ba tolteni.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
S_x96x_S
addikt
válasz
 Cathulhu
#4552
üzenetére
Cathulhu
#4552
üzenetére
> FPGA ... szerintem csak a szuperszamitogepek piacan lehet igazan impactja.
Én azért bízom benne, hogy a "jövőben" a szűk keresztmetszeteket
"nagyrészt" át lehet tolni az FPGA-s részre ...A xilinx ilyen példákat emleget:
- LZ4 Compression ( 2X sebesség a CPU -hoz képest )
- Haversine Distance (10x sebesség )
- Regex Overlay ( 18x sebesség )
- ...
De már egy egyszerű adatbázis gyorsítás ( PostgreSQL, REdis, Appache Arrow,... )
is sokat fantáziáját beindithatja,
https://www.xilinx.com/applications/data-center/database-data-analytics.htmlpersze a jövő a CPU + GPU + FPGA fúziója ...

szerintem

Mottó: "A verseny jó!"
-

hokuszpk
nagyúr
válasz
S_x96x_S
#4551
üzenetére
konyorogni a TSMC -hez kell, javitsanak a kihozatalon vagy noveljek a 7nm kapacitast, ilyesmi.
Az AMD megvett minden szabad kapacitast, -- meg az NV is besegitett azzal, hogy elment a Samuhoz gyartatni -- sajnos csak ennyire eleg.Első AMD-m - a 65-ös - a seregben volt...
-
Cathulhu
addikt
válasz
S_x96x_S
#4555
üzenetére
Az a jo a kovetkezo konzolgeneracioig ez szepen ki fogja forrni magat es ez eleg lehet meg egy teljes generaciot behuzni. Megha az nV + ARM utol is erne oket addig, ez lehet a merlegben donto. Az intelnek lehetne hasonlo ajanlata, ha rakenyszerul addig custom gyartani, de nem hiszem hogy a GPU reszleguk versenykepes lesz akar meg ilyen tavlatban sem.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#4560
 Petykemano
veterán
S_x96x_S
#4555
Petykemano
veterán
S_x96x_S
#4555
Petykemano
veterán
válasz
S_x96x_S
#4555
üzenetére
Annak látod realitását, hogy az AMD az AVX512-t (az összes féle változatával együtt, ami ugye elég szerteágazó és ezért sokan kifejezték a csomaggal kapcsolatos ellenszenvüket) legalábbis kezdetben integrált FPGA-val oldja meg?
Nyilván szólnak érvek ellene.
Ha már ott vannak a 256bites FP végrehajtó egységek (4db), akkor arra "ugyanúgy" rá lehet építeni az AVX512-t, mint ahogy volt a 4db 128 bites és működött rajta a 256bites AVX2
Ugyanakkor nyilván már ennek is van tranzisztorköltsége. Nem is beszélve arról, ha bővítik a végrehajtóegységek szélességét 4db 512bitesre.
Ezt a megoldást - hacsak nem jön elő az AMD egy a SVE-hez hasonlatos rugalmasabb megoldással - persze nem vetném el, de az AVX512 penetrációja elég vékony és jelenleg azért rezeg a léc, ugye gyakran felmerül, hogy hát igazából ezeket a dolgokat hatékonyabb volna GPU-val végrehajtani.
Többféleképpen tudnám elképzelni a csomagolást:
- CCX-enként 1 FPGA
- magonként 1 FPGA
És azt is, hogy az AMD a megrendelőnek előre felkonfigurálva szállítja, vagy egy program futása előtt kell felkonfigurálni. Számomra kérdés (úgy értem, kétlem, hogy) utasításonként való felkonfigurálás elég gyors tudna lenni, tehát azt látom realitásnak, hogy ezzel az AMD különböző igényű cégeket tudna rugalmasan kiszolgálni anélkül, hogy egyedi terméket kellene gyártania. Egyik cégnek AVX512 kell, akkor ő olyan FPGA-t kap, a másiknak meg más.Feltehetnénk a kérdést, hogy de miért venne valaki ilyet, amikor már most is telepakolhatja a szervereit FPGA gyorsítókkal. A trükknek nyilván abban kell állnia, hogy a megrendelőnek egyáltalán ne kelljen a gyorsítóra progrmozni, hogy az FPGA-val megvalósított AVX512, vagy bármilyen új egyedi és virtuális x86 utasítás (?) úgy viselkedjen, mintha a cpu mag natívan tudná.
Találgatunk, aztán majd úgyis kiderül..
-
#4561
S_x96x_S
addikt
Petykemano
#4560
S_x96x_S
addikt
válasz
 Petykemano
#4560
üzenetére
Petykemano
#4560
üzenetére
> Annak látod realitását, hogy az AMD az AVX512-t ...
> legalábbis kezdetben integrált FPGA-val oldja meg?jó kérdés ...
nem tudom ...
Valószínüleg a ZEN4 már nagyrészt le van tervezve ...
és talán már benne van az "alap" AVX-512 -is
( akár cpu chipsetbe integrált vagy egy custom gpu integrált megvalósítás )Ráadásul ez az FPGA-s irány még nagyrészt nagyon új lehet ..
vagyis ha a fő kérdés a "kezdetben" körül forog
akkor én inkább
- a ZEN4-es félig-kész tervekre tenném a tétet ..a másik probléma meg az AVX2 ( 256bit ) vs. AVX-512 (512bit) tranzisztoros terület közös halmaza ... szerintem van átfedés ...
és ott az FPGA-s implementáció nagysága ...
az AVX-512 már igy is elég nagy területet foglal el ... szerintem akár >= 2x akkora FPGA-s terület ( tranzisztorszám ) is kellhet ugyanazon AVX-512 funkcionalitás megvalósítására ...
ami megnövekedett fogyasztást is jelenthet - erősen izzadva ugyanazon a teljesítményért.ezt az FPGA-s irányt inkább a ZEN5, ZEN6 környékére tenném.
persze lehet - hogy régebben még másképp gondoltam .. de most újragondolva én a ZEN4-es AVX-512 -nek látom a legnagyobb valószínűségét ...
( szerencsére sokszor tévedek ... )
Mottó: "A verseny jó!"
-
S_x96x_S
addikt
- AMD Ryzen 9 5980HX
- Ryzen 7 5700G
https://videocardz.com/newz/amd-ryzen-9-5980hx-and-ryzen-7-5700g-apus-appear-on-usb-if-websiteMottó: "A verseny jó!"
-
#4564
Petykemano
veterán
S_x96x_S
#4562
Petykemano
veterán
válasz
S_x96x_S
#4562
üzenetére
Cezanne
"In Cinebench R20, the Ryzen 9 5900H scored 584 and 5264 points in single-core and multi-core tests respectively. A quick comparison to i7-10875H reveals that the AMD CPU is 17% in the single-core test and 22% faster in the multi-core according to Notebookcheck."
[link]Találgatunk, aztán majd úgyis kiderül..
-
#4566
Petykemano
veterán
Petykemano
veterán
Konkurencia - M1 - miért is olyan jó?
"The premise here is wrong. arm64 is the Apple ISA, it was designed to enable Apple’s microarchitecture plans. There’s a reason Apple’s first 64 bit core (Cyclone) was years ahead of everyone else, and it isn’t just caches."
"Arm64 didn’t appear out of nowhere, Apple contracted ARM to design a new ISA for its purposes. When Apple began selling iPhones containing arm64 chips, ARM hadn’t even finished their own core design to license to others."
"ARM designed a standard that serves its clients and gets feedback from them on ISA evolution. In 2010 few cared about a 64-bit ARM core. Samsung & Qualcomm, the biggest mobile vendors, were certainly caught unaware by it when Apple shipped in 2013."
"Apple planned to go super-wide with low clocks, highly OoO, highly speculative. They needed an ISA to enable that, which ARM provided. M1 performance is not so because of the ARM ISA, the ARM ISA is so because of Apple core performance plans a decade ago."
[link] [link]Lényegében azt mondjam, hogy amit az Apple használ az nem a gyári ARM ISA, hanem egy ARM ISA fork. Sokéves tervezés eredménye.
Nem teljesen értem, hogy viszont ez így hogy hozná el a vágyott Arm áttörést? mármint itt eddig arról volt szó, hogy legyenek arm alapú eszközök, ami pont ugyanúgy futtatja a szoftvereket, mint a szerver és akkor majd jó lesz.
De ha jól értem, akkor egy apple készülékre készített bináris nem futna egy arm szerveren, vagy egy másik arm eszközön.
Nem tudom, hogy ez így van-e, vagy hogy ez egyáltalán számít-e, mármint hogy pont ugyanakkora gapról beszélünk-e, mint ami általánosságban az arm és x86 inter-futtathatóságáról.még egy kérdés:
Azt olvastam, hogy a gyári linux disztribúciók (ubuntu, stb) úgy vannak forgatva, hogy a legáltalánosabb utasításkészleteket használják. És például ha te szeretnéd használni mondjuk az AES hardveres gyorsítót, vagy az AVX2-t, akkor sok esetben újra kell forgatnod a kérdéses szoftvert. Én ehhez nem különösebben értek, ezért kérdezem: ez igaz? Én azt hittem, a szoftverek képesek kezelni az ilyen hardveres lehetőségeket, mármint dinamikusan, hogy ha van AVX, akkor azt a kódutat választja, ha meg nincs, akkor SSE3. Egyik-másik tesztelésre használt szoftvernél még volt is szó arról, hogy ha behazudod, hogy mi a cpu, akkor használja a megfelelő - gyors - utasításkészleteket.
Ez persze nyilván növeli a bináris méretét, de én azt gondoltam, hogy ezek az opcionálisan elérhető utasításkészletek a fordítókban tök általánosan kezeltek ma már.[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
-
#4568
 Ueda
senior tag
Petykemano
#4566
Ueda
senior tag
Petykemano
#4566
Ueda
senior tag
válasz
Petykemano
#4566
üzenetére
Annyit pontosítanék, hogy a fordítók csak a programkódot fordítják le (tehát helyetted nem fognak semmit megcsinálni). Az eltérő utasításkészlet kezelését programban kell megoldani, tehát mindenképpen plusz (emberi) munkaráfordítás kell.
Tulajdonképpen ez hasonlít a driverekhez. Eltérő hardverekhez más driver kell.Mondjuk épp azon filóztam, hogy a C64 a konzolok őse is volt egyben, mert fix hardvere volt, ezáltal minden rá készített (jellemzően játék)program (és milyen furcsa kimondani) vajsimán futott.
A fragmentáció meg bonyolítja a dolgokat.
OS : EndeavourOS KDE . . . . . . Parancs menü : https://pastebin.com/u/txt444
-
#4569
S_x96x_S
addikt
Petykemano
#4566
S_x96x_S
addikt
válasz
Petykemano
#4566
üzenetére
> a gyári ARM ISA, hanem egy ARM ISA fork.
szerintem keveri az ISA -t és a Microarchitektúrát ..
M1 ISA =ARMv8.4 (ARM) + ( néhány nem dokumentált kiegészítés )
M1 Microarchitecture = Firestorm, Icestorm
M1 isa family = ARM +az ISA - csak az utasításkészlet
az Architektúra a konkrét implementáció - a megvalósításSzerintem az "AArch64 - es (ARM64) Linux Docker" image-ket
natívan tudja futtatni az M1-es Docker - az X86-os -t pedig emulációval
https://docs.docker.com/docker-for-mac/apple-m1/
"Not all images are available for ARM64. You can add--platform linux/amd64to run an Intel image under emulation."
ez már X86 téma:
> Azt olvastam, hogy a gyári linux disztribúciók (ubuntu, stb) úgy vannak forgatva,
> hogy a legáltalánosabb utasításkészleteket használják."általában" az X86-os kompatibilitás miatt ... minimálisat használnak ...
de újabban már apró lépéseket tesznek a jobb optimalizáció miatt ...amúgy minden kombinációra már szinte lehetetlen előre kódot generálni ..
nem véletlen, hogy most nyomják a "feature level"-t , így tudás alapján 4 általános csoportba osztják az x86-64 -es procikatx86-64: CMOV, CMPXCHG8B, FPU, FXSR, MMX, FXSR, SCE, SSE, SSE2x86-64-v2: (close to Nehalem) CMPXCHG16B, LAHF-SAHF, POPCNT, SSE3, SSE4.1, SSE4.2, SSSE3x86-64-v3: (close to Haswell) AVX, AVX2, BMI1, BMI2, F16C, FMA, LZCNT, MOVBE, XSAVEx86-64-v4: AVX512F, AVX512BW, AVX512CD, AVX512DQ, AVX512VL
https://gcc.gnu.org/onlinedocs/gcc/x86-Options.html
https://www.phoronix.com/scan.php?page=news_item&px=GCC-11-x86-64-Feature-Levelspersze a ZEN1, ZEN2, ZEN3 valószínűleg a "
x86-64-v3"-ba lesz besorolva.
az új ZEN3-as kiterjesztésről meg ne is álmodjunk
amúgy a nativ optimalizáció "nálam" az esetek 50%-ban nem működött; mert a teszt elhasalt rajta ... vagy a fordítóprogramban van valami hiba, vagy a programkódot nem tesztelik arra a kombinációra .. és pár napot eredmény nélkül úgy el lehet tölteni, hogy még mindig nem tudod, hogy fog-e ez futni native módban.
Mottó: "A verseny jó!"
-
Ueda
senior tag
válasz
S_x96x_S
#4569
üzenetére
"és pár napot eredmény nélkül úgy el lehet tölteni, hogy még mindig nem tudod, hogy fog-e ez futni native módban."
Lehet nem ártana, ha maga a proci képes lenne programozási nyelvet futtatni. Hiszen az assembly használata úgyis hanyagolva van, csupán a fordításra korlátozódik.
OS : EndeavourOS KDE . . . . . . Parancs menü : https://pastebin.com/u/txt444
-

HSM
félisten
"tehát mindenképpen plusz (emberi) munkaráfordítás kell."
Nem vagyok különösebben jártas a fordítók lelkivilágában, de nem úgy van, hogy ha lehetőséget biztosítasz bizonyos utasítások használatára, akkor azokat akár automatikusan is képes bizonyos szituációkban felhasználni? Nyilván, az ideális eredményhez kell emberi ráfordítás is (optimalizáció), de tudtommal nem minden esetben elengedhetetlen.#4569 S_x96x_S : Valami kavarás dereng régebbről, AVX1-2, FMA3-4, ez sem ment egyszerűen...
 [link]
[link] -
S_x96x_S
addikt
> Lehet nem ártana, ha maga a proci képes lenne programozási nyelvet futtatni.
de Melyik programozási nyelvet? És mi lesz a többivel?
amúgy az már nem X86 lenne
Jelenleg a legtöbb programozási nyelvet - le lehet fordítani gépi kódra ..
amit a hardver tovább fordít mikrokódra> Hiszen az assembly használata úgyis hanyagolva van,
> csupán a fordításra korlátozódik.Miért lenne hanyagolva?
szinte mindennek az az alapja ..A C / C++ is ugyanolyan forráskód - mint az assembler ..
nagyrészt fordításra van használva ... csak magasabb absztrakciós szint ...Mottó: "A verseny jó!"
-
S_x96x_S
addikt
az a gond az új CPU utasításokkal ( architektúrákkal), hogy kezdetben kicsi rájuk a támogatás, de az idő lassan megoldja ..
pl. a-march=znver3
( ZEN3-as optimalizáció még lassan kerül be a fordítóprogramokba , jelenleg jobb esetben csak a ZEN2 -es optimalizációt használja )
"AMD Ryzen 9 5950X + GCC 11 Compiler Benchmarks At Varying Optimization Levels"
https://www.phoronix.com/scan.php?page=article&item=amd-5950x-gcc11&num=1Mottó: "A verseny jó!"
-
S_x96x_S
addikt
"AMD Ryzen 7 5800U Cezanne “Zen3” CPU tested – higher single-threaded score, problems with multi-threading"

https://videocardz.com/newz/amd-ryzen-7-5800u-cezanne-zen3-cpu-tested-higher-single-threaded-score-problems-with-multi-threading"When it comes to multi-threaded score, there clearly appears to be a problem with SMT. Even the Ryzen 7 4800U scores at 5K points, so it is safe to assume that either SMT does not work, or this particular notebook has a BIOS which is not yet fully supported."
...
The Ryzen 7 5800U scores 509 points in Cinebench R20 ST and 3614 points in MT. In Cinebench R23 the CPU scores 1311 and 9326 points respectively. A quick comparison reveals that the CPU is 6% faster in the single-threaded benchmark while also being slower than 4800U
"Mottó: "A verseny jó!"
-

TRitON
aktív tag
AMD 32-Core EPYC "Milan" Zen 3 CPU Fights Dual Xeon 28-Core Processors
32 vs. 56 mag. Nem rossz.Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
HSM
félisten
válasz
S_x96x_S
#4575
üzenetére
A C-Ray-nél az AVX optimalizációk is erősen számíthatnak. Látszik is, az -O3 kapcsoló ad sokat, nem az architektúra specifikus optimalizáció. A másik teszt viszont azért szépen hoz a konyhára zen2 vs zen3 finomhangolással az általános X86-hoz képest.

#4576 S_x96x_S : Ezekben a fogyasztási osztályokban nagyon nem mindegy a hűtés, és a konfigurált limitek, amik főleg a többszálú eredményekben látszanak. Amúgy szerintem jók az eredmények ennek ellenére, elfogadnám így is.

-
#4582
Petykemano
veterán
Petykemano
veterán
-
#4583
 solfilo
veterán
Petykemano
#4582
solfilo
veterán
Petykemano
#4582
válasz
Petykemano
#4582
üzenetére
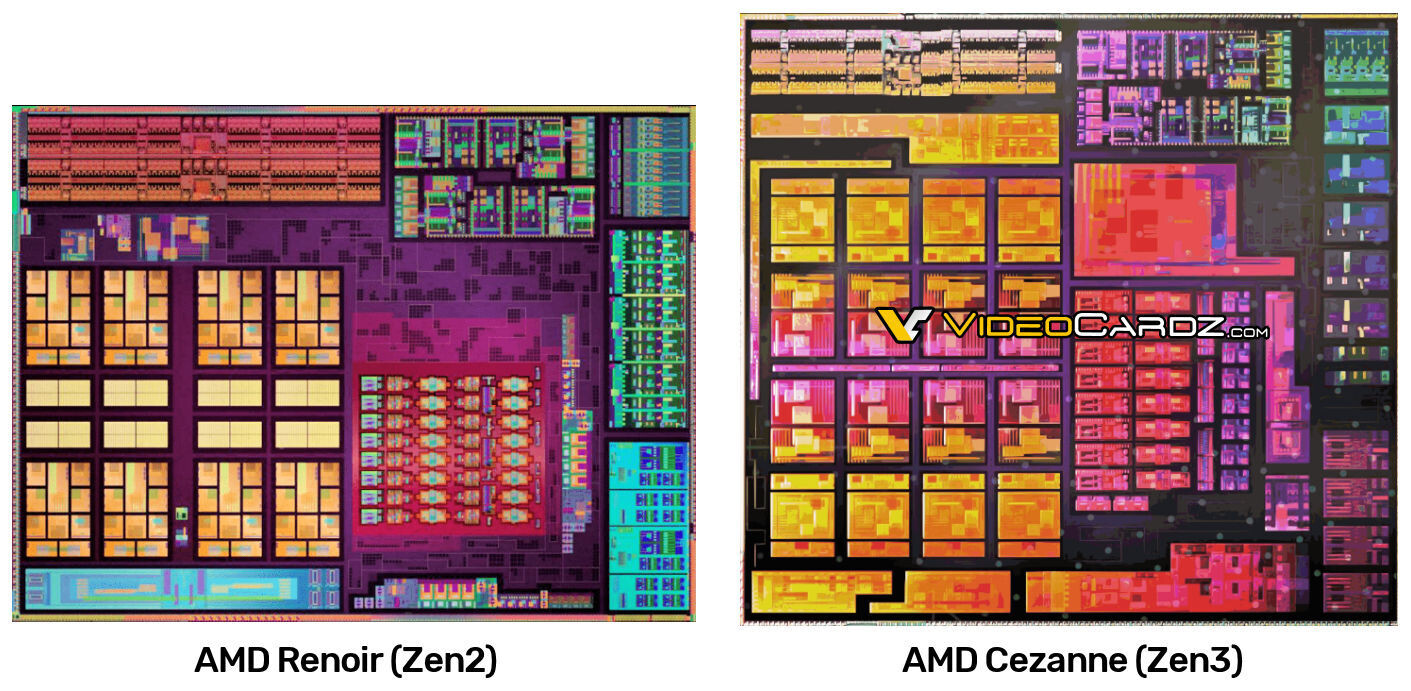
Volt már leak a Cézanne IGP-jéről? Nekem nem rémlik, csak annyi, hogy még Vega. A multimédiás motor érdekelne, hátha megörökölte az RDNA2-ben lévőt, mint a Renoir a sima RDNA motorját. Jó lenne, ha nem csak Intel kínálna AV1 gyorsításra képes APU-t a piacon.
[ Szerkesztve ]
solfilo
-
#4585
 Devid_81
félisten
Petykemano
#4584
Devid_81
félisten
Petykemano
#4584
Devid_81
félisten
-
#4587
solfilo
veterán
Petykemano
#4584
válasz
Petykemano
#4584
üzenetére
Az jöhet vajon desktopra? El tudom képzelni, hogy csak notiban lesz. De nem bánom, ha a Cézanne megkapja a frissített multimédiás motort.
mod: Ha ez azóta nem változott, nem lesz desktopra.
"A Van Gogh csak mobil fókuszú fejlesztés, nem jön belőle asztali verzió, ugyanis pont arra reflektál, hogy a vékony ultramobil gépekbe specializált részegységekkel érdemes beépíteni az egyes feladatokhoz való feldolgozókat, így érhető el a legjobb hatékonyság."#4586 pcsullog
Reméljük nem úgy járunk, mint a VP9-cel, hogy AMD sokáig bénázik a témában. Az bíztató, hogy az RDNA2-ben már viszi a motor AV1-et, innen már tényleg csak egy kis lépés betenni a Cézanne-ba a képességet.[ Szerkesztve ]
solfilo
-
#4588
Petykemano
veterán
solfilo
#4587
Petykemano
veterán
válasz
solfilo
#4587
üzenetére
Lehet, hogy nem
[link]De én nem zárnám ki azért teljesen. Az U és H valójában egy lapka, csak binnelve van.
Nyilván az nem mindegy, hogy mi van benne a lapkában, de a 9W-ra tervezett változatból még akár lehet ilyen max 25W-os BGA tokozású minipc.
De ez nyilván nem jelenti azt, hogy 9W-től 100+W-ig mindent le fog fedni RDNA2 igpvelTalálgatunk, aztán majd úgyis kiderül..
-
S_x96x_S
addikt
STH: AMD Ryzen Threadripper PRO 3995WX Review A Bold WEPYC (january 10, 2021)
https://www.servethehome.com/amd-ryzen-threadripper-pro-3995wx-review-a-bold-wepyc/
( kb féléves technológia, még ZEN2-es magokkal ,
exclusive Lenovo ThinkStation P620 ;
egy kicsit megkésett teszt ...
)Mottó: "A verseny jó!"
-
Cathulhu
addikt
válasz
S_x96x_S
#4574
üzenetére
Szerintem szimplan hulyeseg amit mond, eleve nem is megoldhato. Viszont ami megoldhato lenne, mint a GPUknal vagy az Androidnal, hogy egy koztes nyelvre fordulna csak a kod es onnan pedig JIT oldana meg az optimalizaciot a futtato architekturata. Egy csapasra optimalizaltabb kodot kapnank es platform fuggetlenseget is. Tudna mukodni SIMD-vel is.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
TRitON
aktív tag
válasz
solfilo
#4587
üzenetére
Kezdenek teljesen összezavarni.
Eredetileg Lucienne jött volna desktopra (forrás: [link] ), aztán egyszercsak felbukkan egy Cézanne 5700G (ami egyébként gyorsabbnak tűnik, mint a 3700X és csak ~5%-kal lassabb az 5800X-nél; riszpekt), amiről szintén a következőt írja a Techspot:
"...there's a good chance that the 5700G will be exclusive to OEMs. Given how unconventional it is, that would be a disappointing outcome though. If any of the above are coming to shelves, they'll probably be announced on Tuesday during the AMD CES 2021 keynote." (forrás: [link] )
Remélem, hogy nem így lesz. Azt is el tudom képzelni, hogy 5700(X) nem is lesz, hanem annak a helyére ugrik be az 5700G.
Miért nincsenek publikus roadmap-ek? Kockázatossá vált előre megosztani a terveket a potenciális vásárlókkal?
Annyira keveset tudnak gyártani belőle, hogy a DIY piacra nem jut? Vagy annyira kicsi a DIY piac, hogy nem éri meg dobozosként kiadni? Miért nem árulják tálcán?[ Szerkesztve ]
Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
#4592
Petykemano
veterán
TRitON
#4591
Petykemano
veterán
"Eredetileg Lucienne jött volna desktopra "
Én nem véltem felfedezni ezt az állítást a linkelt forrásban. Lehet, hogy elkerülte a figyelmem.
A LCN és a CZN vegyírése után el tudok képzelni egy 5700GE-t, ami LCN alapú
Viszont furcsa lenne, ha nem próbálnák bevenni a 6 magosok terét is.
5600G: CZN, 5600GE: LCNVagy az is lehet, hogy GE nem lesz, csak simán az 5600G az LCN
Én azt hiszem, már bármi elképzelhető.Ez a termékvonal szerintem gamekeret kevésbé érinti. Irodába, vagy melós gépbe viszont tök jó. De igencsak kétlem, hogy olcsón számolnák meg. 150 és ~170 mm2 7nm lapka - az azért már elég sok és drága ahhoz, hogy ez valami mainstream opció legyen (mint amilyennek az 1600-1600X indult)
Az eddigi gyakorlat az volt, hogy a 4 magos apu változatot a 6 magossal adták egy árban. és kb másfélszer volt drágább, mint a 4 magos IGP nélküli
Az 5700G - főleg ha csak 5%-ban marad el az 5800X-től - ára minden bizonnyal $500 körül lesz. Ami másfélszerese annak, aminek az IGP nélkül 8 magosnak lennie kéne. Ha lesz 6 magos és Cezanne, akkor az is legalább $400 (ami közel másfélszeres ár az 5600X-hez képest) Ha csak Lucienne, akkor mehet az IGP nélküli Vermeerrel egy árban.
Tehát én erre számítanék:
5700G(CZN): $500
5700GE(LCN): $400
5600G(CZN): $400
5600GE(LCN): $300Találgatunk, aztán majd úgyis kiderül..
-
#4594
TRitON
aktív tag
Petykemano
#4592
TRitON
aktív tag
válasz
Petykemano
#4592
üzenetére
Második bekezdés: "Code-named Lucienne (pronounced lucy-en), a feminine French name meaning 'light,' when the processors release, they'll join AMD's desktop parts in going by the Ryzen 5000 series nomenclature."
Mi az? 3 lába van mégsem tranzisztor? - ??? - Traffipax...
-
#4596
Petykemano
veterán
TRitON
#4594
Petykemano
veterán
De ez a mondat nem mondja, azt, hogy a Lucienne csak a desktopra jön - az ellentmondás is lenne a cikk táblázatával. És azt sem, hogy a desktopra csak a lucienne jön. Csak azt, hogy
a Lucienne jön desktopra. De az CZN alapú 5700G létezése még nem zárja ki, hogy legyen egy LCN alapú sku desktopra. (Legalábbis névleg.)A nagy bizonytalanságot leginkább az okozhatja, hogy ki tudja mire lesz elég kapacitás?
De talán nemsokára kiderül.
Találgatunk, aztán majd úgyis kiderül..
-
#4598
Petykemano
veterán
Petykemano
veterán
/Konkurencia/
SnapDragon 888 teszt
vs SD 865
vs Kirin 9000A teljesítményt hozza, de rémes (=az elődöknél rosszabb) fogyasztással, melegedéssel és energiahatékonysággal.
Elvileg ez 5nm-es Samsung gyártástechnológián készül.
Nehéz megmondani, hogy önmagában gyártástechnológia felelős-e az eredményért - lévén a SD865 TSMC 7nm-en készül. Vagy a Cortex X1.Mindenesetre ez alapján azt a következtetést lehetne levonni, nagyobb teljesítmény mellett az Arm fogyasztási előnye is elolvad. De ott az M1. Igazából az a fura, hogy a Qualcomm részvényei nem esnek.
Találgatunk, aztán majd úgyis kiderül..
-
#4599
Cathulhu
addikt
Petykemano
#4598
Cathulhu
addikt
válasz
Petykemano
#4598
üzenetére
Miert esnenek? az M1 nem konkurenciaja a Qualcommnak semmilyen teren.
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell
-
#4600
S_x96x_S
addikt
Petykemano
#4598
S_x96x_S
addikt
válasz
Petykemano
#4598
üzenetére
> Mindenesetre ez alapján azt a következtetést lehetne levonni,
> nagyobb teljesítmény mellett az Arm fogyasztási előnye is elolvad.azért én nem vonnék le messzemenő következtetéseket ..
A "SnapDragon 888" új gyártás technikán készült, valószínűleg a következő generációban jobban optimalizálják a samsung5m -re.
Dual5G (???) ; Ai,GPU,CPU -t ; vagyis rengeteg segéd chipet is tartalmaz ..
Az AI az A14-hez képest ... több mint dupla teljesítmény ( 26TOPS vs. A14(11TOPS ))
persze a 888 "always-on AI functions" is belejátszat a fogyasztási keretbe.
26 TOPS AI = (Total CPU+GPU+HVX+Tensor)
( forrás )A CPU-s része
1x Cortex-X1 @ 2.84GHz 1x1024KB pL2
3x Cortex-A78 @ 2.42GHz 3x512KB pL2
4x Cortex-A55 @ 1.80GHz 4x128KB pL2valószínüleg a Cortex-X1 - már túl lehet húzva a @2.84 -en .. és nem annyira hatékony
( nem bir ennyit a samsung 5nm )Mottó: "A verseny jó!"

































Új hozzászólás Aktív témák
Hirdetés

Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest