







Na ez milyen időszakot jelent pontosan?
- "From the end of Q2 to the beginning of Q3"
Ez valami spéci english (slang?)
vagy csak a [ jun-01 - jul-31 ] -et definiálja ?

Mottó: "A verseny jó!"

Na ez milyen időszakot jelent pontosan?
- "From the end of Q2 to the beginning of Q3"
Ez valami spéci english (slang?)
vagy csak a [ jun-01 - jul-31 ] -et definiálja ?
Mottó: "A verseny jó!"

Szerintem az inkább június 30-a és szeptember 1-e lesz (06.30-09.01). Magyarul két hónap.
Play nice!

Legfeljebb amolyan szimbolikus.
Találgatunk, aztán majd úgyis kiderül..
A Linux 5.17 -ben hegesztik a ZEN procik NUMA-s teljesítményét.
( javulás várható egyes estekben )
Persze ez főleg a Szervereknél ( EPYC ) lesz hasznos.
----------------------
"New Linux Scheduler Patches Can Improve AMD Zen Performance For Some Workloads"
https://www.phoronix.com/scan.php?page=news_item&px=Linux-Sched-NUMA-Imbalance-Zen
"A set of two patches under review on the kernel mailing list for tweaking some kernel scheduler behavior can provide noticeable performance benefits to those using AMD EPYC and Ryzen processors on various workloads.
Last year the Linux kernel scheduler code was adapted to allow a floating imbalance between NUMA nodes until 25% of the CPU cores are occupied while higher than that the balancing behaves as normal. Prior to that an imbalance between NUMA nodes was only allowed when the destination node was effectively idle."
". With benchmarks carried out by Gorman, on an AMD Zen 3 system when running the Stream OpenMP-based memory benchmark he saw improvements between 180% and 268%. For the Coremark CPU synthetic benchmark he saw the harmonic mean and maximum performance go up by 15% while the minimum score improved by nearly 10% too. With SPECjbb Java workloads he also generally saw better performance too."
[ Szerkesztve ]
Mottó: "A verseny jó!"
Talán nem is annyira a proci érdekes. Arm V1.
A cikk is két dolgot hangsúlyoz:
- vertikális integráció. Várhatóan az összes tech gigacég a saját vertikális megoldását fogja megvalósítani kilőve ezzel legalábbis a hyperscaler/cloud szerver piacról a CPU és más hardvergyártókat.
Lehet, hogy ez technológiailag szenzációs. De így a kapitalizmus egészét tekintve mennyire lehet jó, hogy mindent egy, najó,.néhány gigászi cég birtokol és irányít?
- chipletek használata. Elég érdekes, hogy a CPU magok egy monolitikus lapkán vannak és kívülről vannak hozzápasszintva a külön gyártott részegységek.
Mindenzt DDR5-tel és pcie5-tel fél évvel a nagy chipgyártók előtt.
Persze ezen se csodálkozzunk. Az amazon egy olyan gigászi cég, mint az Apple. 5x akkora bevétellel, mint az Intel. Miért volna meglepő, ha gyorsabban is fejlesztenek? Az Auchan valószínűleg lényegesen hamarább vezetne be egy új péküzemi techmológiát, mint a csak pékséggel foglalkozó sarki pék.
Találgatunk, aztán majd úgyis kiderül..
(#6006) Petykemano válasza Petykemano (#6005) üzenetére
Van egy ilyen is:
-->
"Beating Intel+AMD to DDR5 by ~6 months"
"We TESTED Graviton 3..."
Graviton 3 is not shipping in large volume yet and is not being used to power those instances.
Zen 4 and SPR are probably in the same "testing phase" right now.
I wouldn't call this "beating by ~6 months"
<-- [link]
Találgatunk, aztán majd úgyis kiderül..
A fogyasztás és a TCO egyre fontosabb ..
és itt az X86 -os irány - hátrányban van.
https://semianalysis.substack.com/p/amazon-graviton-3-uses-chiplets-and
"""
"Graviton3 is of course the star of the show. Amazon jumped forward as the first to many technologies on the server CPU side. They are using a chiplet design with 7 different dies. What stands out is that they are packaged using advanced packaging. The size of the ubumps connecting each die are <55um whereas every CPU from Intel and AMD is still at >100um. Intel and AMD only catch up with their next generation CPUs. This enables a design where IO is disaggregated from the CPU without ballooning in power budget. AMD IO dies on Rome and Milan server CPUs take as much as 100W. This 100W eats into the power budget for the cores, and cannot be geared towards computations. Graviton achieves 50% higher memory bandwidth than AMD Milan and PCIe 5.0 connectivity while keeping the entire CPU power consumption in that same ~100W range."
""
"""
While x86 CPU vendors will maintain their peak performance per CPU lead, Intel and AMD are ignoring the more important battle. That battle is over total cost of ownership (TCO) per unit of compute on a server and rack level for generalized CPUs. Commoditization is here for the CPU market, and even if Intel's and AMD's individual core design is markedly better, it won't change the equation. Intel and AMD are hyper focusing on certain aspects, which make them miss crucial factors in system level design such as peak power being too high, density being too low, and clock speeds being pushed too far.
Graviton3 should be making Intel and AMD executive’s quiver. In fact, all merchant silicon vendors should be terrified because Microsoft, Facebook, Google, and the major Chinese players want to replicate this vertical integration across networking, CPU, SSD, AI inference, and AI training. This basket of hyperscale firms are growing much faster than rest of the market, and they are swallowing up computing dollars spent like veracious beasts. Tech monopolies are going vertical, and there doesn't seem to be much being done to stop this long term tsunami.
"""
Mottó: "A verseny jó!"
Bocs, rosszat linkeltem.
Mindenesetre ha már kiemelted, segítségre lenne szükségem az értelmezésben.
TCO tekintetében miért van hátrányban az x86?
- Túl drágán adja az AMD meg az Intel?
- vagy bonyolult és túl drága fejleszteni az x86 processzorokat Arm procikkal szemben?
- Vagy úgy kell ezt érteni, hogy az AMD-hez és az intelhez hasonlóan legalább ugyanilyen bajban van/lenne az Ampére is - vagyis arról van szó, hogy az ilyen fejlesztő munka akkor éri meg, ha megfelelő volumenű produktumra tudod skálázni - itt most a legyártott és üzembe helyezett CPU-kra gondolok és ha Te, mint cég önmagadban elég nagy vagy, akkor neked már megérheti azt a fejlesztőgárdát házon belül tartani, akiknek a munkájára vastag profitot és adminisztrációs költséget is ráfizetnél, ha third party cégben lennének.
- Vagy az előző plusz itt is valami olyasmiről van szó, mint az apple-nél, hogy az Intel, AMD, Ampére általános célú processzorokat gyárt szabványok alapján csereszavatos szerverkomponensekbe - mert nagyjából ez volt a komponensek szintjén nyílt piacú PC/x86 piac óriási előnye akkor, amikor vertikálisan integrált mainframe-eket gyártó cégek versengtek egymással. De a versengést lenyomja a monopólium, mivel a redundancia többletköltség, a szabványokat pedig lenyomja a kusztomizáció, mert a minden piaci szereplő számára megfelelő szabványokhoz igazodás költséges? és ha minden saját ,akkor szarhatsz a világra, miközben beleviheted az egyedi elgondolásaidat, egyedi megoldásaidat, amit nyilván a szabványos / általános célű valami nem kínál.
?
Találgatunk, aztán majd úgyis kiderül..
> TCO tekintetében miért van hátrányban az x86?
csak feltételezem - mint cloud használó:
az AWS -nél az on-demand gépek kihasználtsága hullámzik.
mert nem lehet szűkre venni a kapacitást.
És tegyük fel, hogy a nemfizetős gépek aránya ~ 5 - 40% között mozog.
(pl. hétvégén több a szabad kapacitás.
hétközben - helyi munkaidő alatt viszont sokkal jobb a kihasználás)
Ekkor a nemfizetős gépek áramigényét is fizetni kell ..
És most eléggé elszáltak az áramárak az EU-ban.
És ha kevesebbet fogyaszt
- olcsóbbak a rezsi költségek
- kisebb hőt kell elvezetni - és sűrűbb lehet a gépterem.
nem véletlen, hogyha 1/3 a fogyasztás, akkor akár 3 CPU-t is be tudnak rakni .. "stuffing 3 CPUs into an air-cooled server unit. "
Mottó: "A verseny jó!"

Ezt írja az előző idézeted: "which make them miss crucial factors in system level design such as peak power being too high, density being too low, and clock speeds being pushed too far"
Ez egyébként erősen paraméterezés kérdése is. Hülye példa, de talán szemléletes, hogy notebookokban ugyanaz a Cezanne APU konfigurálható 10-től akár 60W-ig is.
Szerverekben is pl. kompromisszum, hogy az AMD a jelenlegi "pici" chipletes megoldással kedvezően tartja az előállítás költségét, de pl. a fogyasztás tekintetében számottevő hátrány lehet a sok IF link szükségessége.
Ugyanakkor nagyon kíváncsi leszek a már beharangozott Zen4c magokra, lehet éppen ide hoznak vele előrelépést?
Ez jogos. Mindig meglep az a 100W, és aztán elfelejtek rákérdezni:
Vajon hogy csinálják?
A cikk foglalkozik azzal is, hogy az AMD esetén csak az IOD fogyaszt ennyit.
Kiváncsi vagyok, hogy vajon ebből a fogyasztásból mennyiért tehető felelőssé az infinity fabric. Az adattovábbítás szempontjából nem olcsó - az alacsony késleltetésért magas fogyasztással kell fizetni. A zen esetén a lapkák elég távol vannak egymástól.
Erről volt szó, ez egy választás volt és arról, hogy lényegesen alacsonyabb pJ/bit értéket lehetne elérni alternatív (de eddig nyilván drágább) megoldásokkal. Csak azért hozom fel mindig, merthogy most már az AMD-nek van EFB. Kiváncsi vagyok bevetik-e az Zen4-gyel,
hogy csökkentsék az adatmozgatás energiaszükségletét, vagy a kérdést letudják a V-cache-sel?
Találgatunk, aztán majd úgyis kiderül..
"Kiváncsi vagyok, hogy vajon ebből a fogyasztásból mennyiért tehető felelőssé az infinity fabric."
Szvsz nem kevésért.  Szerintem régi, de nagyon jó mérés a témában: [link] . Persze, azóta sokat javítottak az egyes IF linkek fogyasztásán, de több lett a linkek száma is.
Szerintem régi, de nagyon jó mérés a témában: [link] . Persze, azóta sokat javítottak az egyes IF linkek fogyasztásán, de több lett a linkek száma is.
>> and clock speeds being pushed too far"
> Ez egyébként erősen paraméterezés kérdése is.
> Hülye példa, de talán szemléletes, hogy notebookokban
> ugyanaz a Cezanne APU konfigurálható 10-től akár 60W-ig is.
ez igaz,
de nem olyan egyszerű a lefelé skálázás
és több év kell neki.
Kérdés, hogy mennyire várnak a nagy ügyfelek.
Amúgy eddig chipletes mobil proci se nagyon volt;
és ez csak majd a ZEN4-től várható.
Valószínüleg az i/o die-t karcsúsították fogyasztás szempontjából is.
Az ARM-nak nagy előnye; hogy alulról felfelé skálázódik
és a fogyasztás kiemelten fontos volt ( telefonok )
És ebben van már több mint 10 éves fókusza, gyakorlata, tapasztalata.
És a gyártási technológiára való optimalizálás is fontos
pl.
az Apple (A*)(M1) procik már-már sok-sok éve
főleg a TSMC -re vannak optimalizálva.
és az új TMSC gyártósorok kezdetben nem is birják a ~4ghz feletti freq-kat, de a 3Ghz -et általában tudják.
Emiatt az Apple egyre inkább szélesíti a magjait, hogy egy szálon - alacsony freq-n is jó teljesítményt adjon.
( Az Apple M1 notebook- on hűtés sincs )
az X86 hozzá van kötve a magasabb FREQ-hoz.
és az Inteles 14+++++++++++++ -ra való beragadás
is részben ezzel magyarázható.
Mert ha a gyártástechnológia csak 2Ghz-et enged, akkor ennek megfelelő magok kellenek.
Mottó: "A verseny jó!"

"Az ARM-nak nagy előnye; hogy alulról felfelé skálázódik"
az "alulrol felfele" szokapcsolatrol juteszembe.
Most ugye az az allaspont, hogy a Zen 3D -n majd a cpu lapka tetejere helyezik a cache lapkat. Namost lehet tevedek, de ugyemlexem, az volt a kozmegallapodas, hogy az alig fogyaszt, ezert lehet odatenni. a ket cpu magcsoport fole meg valami igenjo hovezeto anyag fog kerulni, mert az ott keletkezo hot meg valahogy el kell vinni.
ezesetben mi akadalyozza meg, hogy a proci lapkajanak kozeperol ugy unblokk eltavolitsak az L3 cachet, es egy ( vagy tobb ) a cpueval azonos meretu cache lapkat a cpumagok _ala_ helyezzenek el ? Vagy akar a bazinagy cache lapka tetejere tegyek a cpu-t ?
igy a hotermelo magok maradnak kozvetlenul az ihs alatt, az alig hotermelo cache meg ugysetermel hot 
[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...

Akkor csökkenne a proci felszíne azaz a hőátadó felülete, tehát jobban melegedne.
viszont mégjobblehetne a szent kihozatal.
[ Szerkesztve ]
Első AMD-m - a 65-ös - a seregben volt...

"ezesetben mi akadalyozza meg, hogy a proci lapkajanak kozeperol ugy unblokk eltavolitsak az L3 cachet, es egy ( vagy tobb ) a cpueval azonos meretu cache lapkat a cpumagok _ala_ helyezzenek el ?"
Valószínűleg power.
4W vs. 60W átküldése a TSV-n.
[ Szerkesztve ]
640 KB mindenre elég. - Steve Jobs
> Állítólag ez az első nagyobb zen4 patch
ideje.
A Linux 5.17 - a következő éve elején várható.
A szoftveres tuning elkezdéséshez nem árt minnél hamarabb.
Feltételezem, hogy egyes "VIP" ügyfelek már a következő év elején elkezdik a tesztelést.
amúgy már novemberben elkezdték a támogatást.
- Family19 - Zen4
https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.17-k10temp-New-AMD-Zen
- Family 19 - 12 CCD
https://www.phoronix.com/scan.php?page=news_item&px=AMD-Zen-12-CCDs-hwmon
Mottó: "A verseny jó!"
"de nem olyan egyszerű a lefelé skálázás"
Ugyanúgy, ahogyan a felfelé skálázás sem. Minden rendszernek megvan az optimális mérete, ahol jól működik.
"Amúgy eddig chipletes mobil proci se nagyon volt;"
Egyébként várható?  A mobilban, főleg az alacsony fogyasztású régióban kritikus a fogyasztás, ahhoz pedig hogy az minél alacsonyabb lehessen fontos a komponenseket minél közelebb és szorosabban integrálni egymáshoz. Chipletet én igazából csak a magasabb TDP osztályokban tudok elképzelni, 45W és felette.
A mobilban, főleg az alacsony fogyasztású régióban kritikus a fogyasztás, ahhoz pedig hogy az minél alacsonyabb lehessen fontos a komponenseket minél közelebb és szorosabban integrálni egymáshoz. Chipletet én igazából csak a magasabb TDP osztályokban tudok elképzelni, 45W és felette.
"az X86 hozzá van kötve a magasabb FREQ-hoz."
 Ez az asztali piac sajátja.
Ez az asztali piac sajátja.
A Ryzenek igencsak jól skálázódnak 4Ghz alatt is, nem véletlen tudnak igencsak harapós 8-magos CPU-t kínálni 15W-os keretből (Renoir, Cezanne), és a szerverek esetén is igencsak fontos összetevője ez, hogy olyan sikeresek és egyáltalán tudtak hozni annyi magot, amennyit. Sajnos szerverekben a sok mag összekötése relatív energiaigényes, ez a kritikus kérdés. Szerintem sokkal inkább ezen fog múlni, melyik megoldás lesz sikeres, nem a magokon vagy frekvenciákon.
"A mobilban, főleg az alacsony fogyasztású régióban kritikus a fogyasztás, ahhoz pedig hogy az minél alacsonyabb lehessen fontos a komponenseket minél közelebb és szorosabban integrálni egymáshoz."
Nem akarnám azt sugallni, hogy szerintem lesz chipletes mobil az AMD-től. Csak kérdezem.
Ennél:
Ez:

Lényegesen közelebb és szorosabb
Ilyen "mozaikszerű" módszerrel el tudnád képzelni, hogy mobil célra már közel annyira megfelelhet, mintha monolitikus lenne?
Találgatunk, aztán majd úgyis kiderül..
>> "de nem olyan egyszerű a lefelé skálázás"
>Ugyanúgy, ahogyan a felfelé skálázás sem.
>Minden rendszernek megvan az optimális mérete, ahol jól működik.
A lefelé skálázás alatt
~ "az egyre kevesebb watt-ból - egyre több teljesítményt kihozni"
értem.
A Nuvia például azzal az igérettel adta el magát
( persze ezt még bizonyítani kell ... ),
hogy kombinálni tudja a mobilchipek energihatékonyságát a szerverek teljesítményével..
Vagyis jobb és energiahatékonyabb szerver csipet csinál mint a többiek mobil procijai! ( AMD, Intel, Apple )
deepl fordítva:
"Az ARM eredményei minden ponton energiatakarékosabbak/nagyobb teljesítményűek, mint bármi, ami x86-on elérhető, még akkor is, ha a felső határon az Apple és az Intel majdnem azonos teljesítményt nyújt ..."
és a Cloud -ban az energihatékonyság zsebre megy.
100.000 CPU -nál már ~0.5% -os energihatékonyság több millió $-os éves költségmegtakaritás, amiért érdemes lehajolni.
De egy kis cég, akinek 10 szervere van - ez elenyésző költség.
Veszi a konfekciós szervereket - átalakítás nélkül.
Vagyis a Cloud és a HPC piac egész más optimalizációs problémát igényel az AMD és az Intel részéről.
-------------
According to NUVIA’s numbers, this is where the current market stands with respect to Geekbench 5. At every point, ARM’s results are more power efficient/higher performant than anything available on x86, even though at the high end Apple and Intel are almost equal on performance (for 4x the power on Intel).
NUVIA notes that power of the x86 cores can vary, from 3W to 20W per core depending on the workload, however in the sub 5W bracket, nothing from x86 can come close to the power efficiency of high-performance Arm designs. This is where Phoenix comes in.
...
"NUVIA’s claim is that the Phoenix core is set to offer from +50% to +100% peak performance of the other cores, either for the same power as other Arm cores or for a third of the power of x86 cores. NUVIA’s wording for this graph includes the phrase ‘we have left the upper part of the curve out to fully disclose at a later date’, indicating that they likely intend for Phoenix cores to go beyond 5W per core."
https://www.anandtech.com/show/15967/nuvia-phoenix-targets-50-st-performance-over-zen-2-for-only-33-power
"Compared to AMD's Ryzen 4700U, the company says it can achieve a 40 to 50 percent higher IPC with only 33 percent of the power consumption." [1]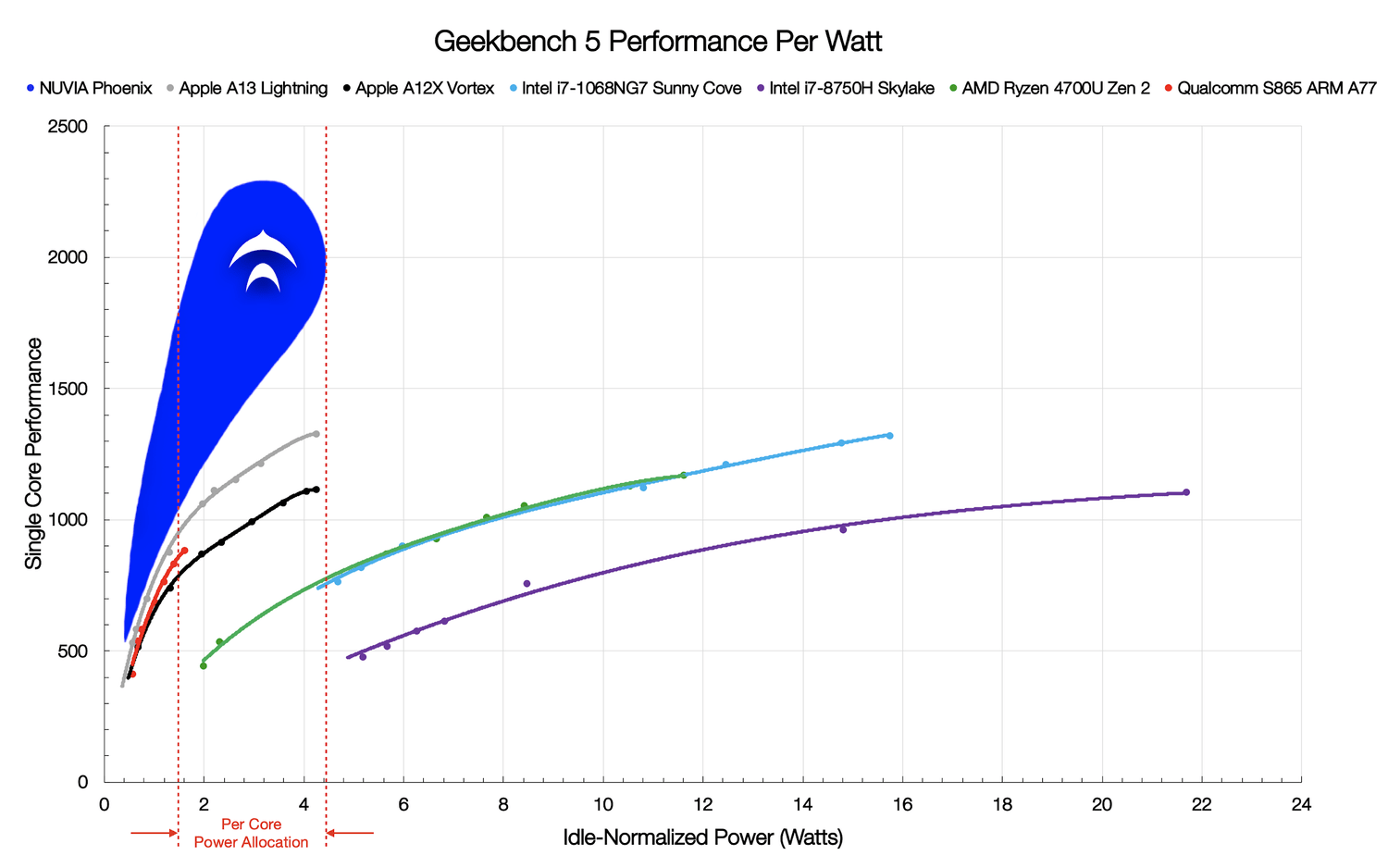
Mottó: "A verseny jó!"
> Az összehasonlítás szvsz több sebből is vérzik.
Ha lehagyjuk az NUVIA-s állítását
(ami mögött amúgy az Apple ex tervezője van)
attól még igaz:
"Az ARM eredményei minden ponton energiatakarékosabbak/nagyobb teljesítményűek, mint bármi, ami x86-on elérhető, ...."
és mert a Graviton3-as történet mögött is ez van - energihatékonyság.
> valós, megvehető termékekkel...
ez cloud .. bérelhető és tesztelhető termékekről van szó.
Az alkalmazások fele ~ ARM-es szerverprocin is elfut.
[ Szerkesztve ]
Mottó: "A verseny jó!"
(konkurencia, iparági trend)
ez az M1 skálázás kezd érdekes lenni.
és az M1 Max Quadra - már a Threadripper területe lenne.
amúgy ez elég szép példa a felfelé skálázásra.
bár sok eltérés van ..
pl. az Apple - elég "böhöm" chipleteket használ ( az AMD-hez képest )
-----------
Pics of Apple M1 Max Die Hint at Future Chiplet Designs
'M1 Max Duo' or 'M1 Max Quadra' chips incoming?
"M1 Max Quadra" solution with 40 CPU cores and 128 GPU cores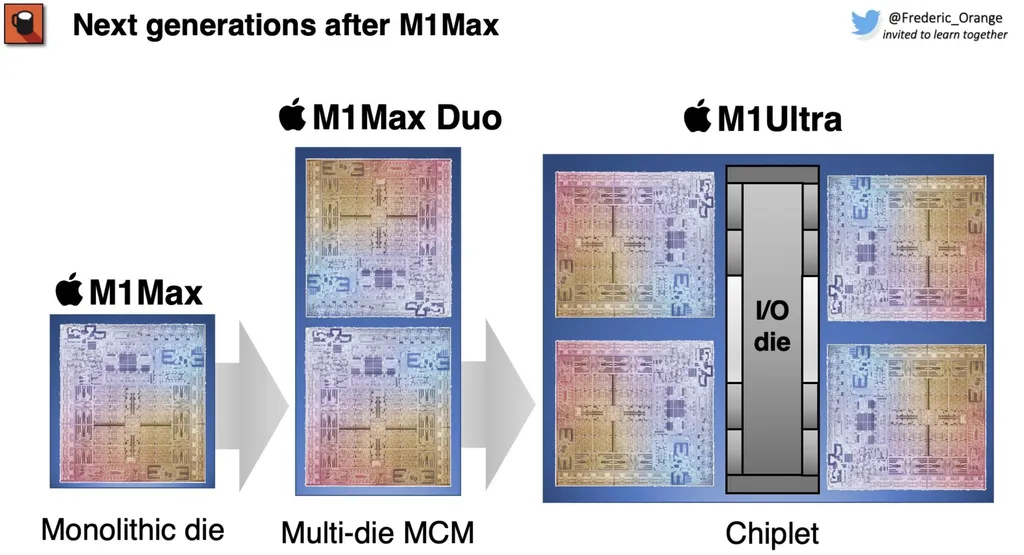 https://twitter.com/VadimYuryev/status/1466526403331952644
https://twitter.com/VadimYuryev/status/1466526403331952644
https://www.tomshardware.com/uk/news/pics-of-apple-m1-max-hint-at-incoming-chiplet-designs
Mottó: "A verseny jó!"
Szerintem - az igp miatt - ez túlmutat a threadripperen. Ez egy új termékvonal lenne az amdnél.
Szerintem csodálatos lenne, ha az AMD gyártana mondjuk 20CU-s monolitikus lapkákat, amelyet így össze lehetne fűzni.
Minden lapká rendelkezne egy 64MB-os a gpu és a CPU által is hasz.altató v-cache-sel (L3/IC) és az összetokozott chipleteket egy nagyobb Cache bridge kötné össze.
Egy ilyen megoldásnál a brutálsok cache segítene, hogy 4 csatornás DDR5 mellett is elketyegjen 16-24 mag.
De vajon az Apple esetén mi a terv? Ott 1 M1 Max lapka kap 512b LPDDR5-öt. Hogy lenne 2 v 4 lapka esetén?
Az AMD persze szerintem nem így fogja megoldani, hanem külön CPU és GPU compute chipletekkel.
[ Szerkesztve ]
Találgatunk, aztán majd úgyis kiderül..
"Egy ilyen megoldásnál a brutálsok cache segítene, hogy 4 csatornás DDR5 mellett is elketyegjen 16-24 mag."
Egy ilyen megoldásnál a brutálsok cache segítene, hogy ne kelljen semmilyen memoriat rakni a gepbe ! ( mint a Sapphire Rapids egyik uzemmodjaban. )
Első AMD-m - a 65-ös - a seregben volt...
ez aranyos ...
INTEL CEO: ""Nem vesztettem részesedést az AMD-vel szemben, hanem részesedést adtam neki, mert nem volt kapacitásom. ..."
Intel CEO: I Haven't Lost Share To AMD, I've Given Share To AMD
https://hothardware.com/news/intel-ceo-i-havent-lost-share-amd
""I haven't lost share to AMD, I've given share to AMD, because I didn't have capacity. So a lot of this is just catch up to our growing market and years of under investment," Gelsinger said at the 25th Credit Suisse Technology Conference.
-----------
de azért van egy mélyebb értelme is.
Az AMD bár versenytárs ..
de azért segít az X86-64 -es ökoszisztéma fentartásában.
Mert EPYC-ről vissza lehet csábítani az ügyfeleket az Intel-hez
- később egy jobb ajánlattal,
de ha átmennek ARM-re ..
akkor az az ügyfél nagyrészt kiesett a potenciális ügyfelek halmazából ..
És igazából emiatt fájhat az Intel-nek az Apple elvesztése.
Mottó: "A verseny jó!"
> Szerintem - az igp miatt - ez túlmutat a threadripperen.
> Ez egy új termékvonal lenne az amdnél.
Az én egyedi felhasználó nézőpontomból ( adatfeldolgozás )
főleg az nVidia CUDA dominál,
vagyis a piaci sikert eléggé elő kellene készíteni.
(dömping ár, jobb szoftveres támogatás, olcsó fejlesztői gépek... )
viszont ha a ZEN4 (desktop & notebook) procikban lesz már
"AMD CDNA" támogatás, akkor már a Threadripperes CDNA -nak
is nagyobb sikere lenne.
Viszont a TR - már workstation-ös gép,
vagyis a külön opcionális CDNA/GPU optimálisabb ( ~ gazdaságosabb ) lenne.
Szerintem ez az 3gen-es Infinity jön le elsőként TR-re. 
> Az AMD persze szerintem nem így fogja megoldani,
> hanem külön CPU és GPU compute chipletekkel.
kíváncsi leszek a 4gen-es Infinity Architektúrára ..
de szerintem is valami hasonló lesz ..
Amúgy remélem, hogy ott már az FPGA-s (Xilinx) chipletek támogatása is meg lesz oldva.
És akkor remélhetőleg van remény a CPU+GPU+FPGA-s fejlesztői laptopra is - AMD alapokon.
Mottó: "A verseny jó!"
A sok v-cache azért a RAM kiváltására szerintem kevés. A SPR esetén 4 HBM2e csatlakoztatható, ami azért már 32GB. A V-cache / infinity cache pedig még a fél gigát se éri el.
Amit el tudok képzelni:
- régi álmunk, a hbm. Viszont a modern technológiákkal már nem kell nagy interposert. Viszont HBM mellé nagy cache se kell.
- brutálsok cache esetén esetleg a RAM kiváltható valami olcsóbb, lassabb megoldással, pl optane, znand, stb (HBCC)
Ezekre az AMDnek mind van megoldása, de én kétlem, hogy ebbe az irányba menne.
Találgatunk, aztán majd úgyis kiderül..
"a Graviton3-as történet mögött is ez van - energihatékonyság."
Ez rendben van. Én ahogy írtam a #6020-ben, egyáltalán nem mindegy, mi a tervezési cél és prioritás, amikor létrehozták az adott rendszert. Az AMD a chipletes megoldással egyértelműen a gyártási és tervezési költségek hatékony hasznosítását priorizálta, amit szvsz nagyon jól tettek az adott piaci környezetben. Még a mobil APU-k is ugyanígy IF linken kapcsolódnak, csak egy monolitikus lapkán belül. Ezzel nincs semmi baj, három piaci szegmenst (mobil, asztali, szerver/WS) is sikeresen letaroltak ezzel a megoldással 6-tól 64 magig biztosan. Ez a rendszer nagyon jól teljesít ezekben a szegmensekben, ugyanakkor nem feltétlen ez fogja tudni a legextrémebb energiahatékonyságot. Már a tervezésnél is figyelembe kellett venni pl. az asztali és laptop piacot is, ahova kellett pl. a magas egyszálú teljesítmény. Egyébként könnyen lehet erre a piaci igényre lesz válasz a Zen4c mag, amit kifejezetten a magas magszámú környezetbe szánnak [link] .
Én egyébként az M1-ek kapcsán sem látom azt, hogy "letarolnák" hatékonyságban a jelenlegi, pl. Cezanne APU-t, ha figyelembe vesszük pl. a tranzisztor számot, vagy egyéb, költségekkel, konfigurálhatósággal összefüggő dolgokat.
vegulis tenyleg nemvolt 10nm kapacitasuk. Most 7nm nincs ![;]](http://cdn.rios.hu/dl/s/v1.gif)
Első AMD-m - a 65-ös - a seregben volt...
"A V-cache / infinity cache pedig még a fél gigát se éri el. "
_most_még_nem. viszont ez is tobb, mint amennyi ram ~20-25 eve a gepemben osszesen volt. El se tudtuk kepzelni, hogy a vilagon letezik ennyi.
bizom a gyorsulo fejlodesben.
vajon grafenbol csinaltak mar ramot vagy memristort ?
Első AMD-m - a 65-ös - a seregben volt...
érdekes .. hybrid cpu szerüség támogatása ...
habár ez alapján még nem tudom elképzelni, hogy milyen lesz ..
az én tippem - hogy pl. az eltérő 3D cache kiépítéseket is ezzel lehet lekezelni ...
Jobb magyarázat ?
-----
"AMD Makes Some Interesting SMCA Driver Changes For Future CPUs"
https://www.phoronix.com/scan.php?page=news_item&px=AMD-SMCA-Different-Layouts
"A set of three patches sent out by AMD last week add new SMCA bank types in preparation for new CPUs and also bank layout changes for future AMD systems. What makes these patches interesting is, "Future AMD systems will have different bank type layouts between logical CPUs. So having a single system-wide cache of the layout won't be correct....Future AMD systems will lay out MCA bank types such that the type of bank number may be different across CPUs."
The patches though don't elaborate though on why future AMD CPUs may begin seeing different bank layouts between the logical cores of the system. It is a real possibility though that it's in relation to a hybrid processor design with a combination of different cores, similar to Alder Lake / Arm big.LITTLE. AMD patents over the past two years along with rumors have alleged AMD is developing such a hybrid processor and that could be one explanation for why future AMD CPUs may be seeing the different bank layouts between cores.
When it comes to the new SMCA bank types added for future processors as part of this same patch series. the additions include: MPDMA unit, NBIF unit, system hub unit, SATA unit, USB unit, GMI PCS unit, and GMI PHY unit."
Mottó: "A verseny jó!"
Rembrandt | FP7 is a BGA-1140
package Die Size: 12,82 mm × 16,25 mm ≈ 208,33 mm²
Package: 25 mm × 35 mm
[link]
Találgatunk, aztán majd úgyis kiderül..
Ez igaz, de arról volt szó, hogy bármilyen nagy mennyiségű cache teljesen kiválthatja-e azt a layert, amit ma memóriának nevezünk. Az összes layer arról szól, hogy az alatta levő layernél kisebb késleltetést és/vagy nagyobb sávszélességet biztosít, de a tradeoff a tárhely mérete.
Én a közeljövőben nem látom annak megvalósulását, hogy a v-cache kiváltsa a DRAM szükségességét. (DRAM - ide értve a HBM-et is)
Jelenleg 64MB egy v-cache lapka. Elvileg ebből fognak tudni a közeljövőben egymásra pakolni 4-et. Az még mindig csak 256MB. Szerintem ez még kevés ahhoz, hogy emögött már csak egy NVMe SSD legyen.
Találgatunk, aztán majd úgyis kiderül..
Én eddig úgy tudtam, hogy nem N2, hanem V1
Mindenesetre érdekes, hogy a megjelentetett főbb számokban (L1$, L2$) alig van változás.
Az L3$ duplájára nőtt és DDR5 támogatást kapott.
Így nem is annyira meglepő, hogy "csak" 25%-kal jobb a graviton3. (Gondolom ez valami ST mérés lehet)
Találgatunk, aztán majd úgyis kiderül..
újabb pletyka: Samsung 4LPP --- Chromebook APU
--------------
AMD Might Use Samsung's 4nm Node for Chromebook CPUs: J.P. Morgan
AMD reportedly preps a 4LPP processor for Chromebooks.
https://www.tomshardware.com/news/amd-may-adopt-samsung-4lpp-for-chromebooks
Adopting Samsung Foundry's 4LPP (second-generation 4nm-class process) for a Chromebook-bound APU would require AMD to redesign its CPU and GPU IP for the new manufacturer, something that is rather costly at 4nm. Also, keeping in mind that the Chromebook market isn't growing, it's unclear how financially viable the project would be. The analysts believe that AMD could also use Samsung Foundry for some of its GPUs going forward, but didn't elaborate.
"In addition, we believe that AMD is likely to evaluate some projects (probably for GPU) at Samsung 3nm in 2023/2024, but vast majority of its core platforms (CPUs for server, mobile, and desktops) are likely to stay with TSMC N3." said the report.
Mottó: "A verseny jó!"
Xilinx
"
Network accelerators, sometimes called smartNICs, are a different story. They offload packet processing from the CPU, and in addition to Intel, Nvidia and Marvell also have network-accelerator offerings. Newman says there is a strong need for their ability to maximize the utility of general-purpose CPUs to run optimized workloads, and AMD can’t ignore it. “We’re at a point now where we’re trying to optimize every bit of our computing architectural resources. So yeah, I think that’s a gap that they’re either gonna need to fill in on their own or through partnership,” he said.
But rather than make a network processor, Norrod believes the Xilinx FPGA technology will allow for a different level of processing. “It’s really more about adaptive computing for data-flow oriented workloads,” he said. “There’s a lot of cryptographic applications, networking applications, security applications, and storage that benefit from [FPGA] as well. And so there’s a lot of interesting areas that we think the Xilinx technology brings to the table.”
"
[link]
Találgatunk, aztán majd úgyis kiderül..
megerősítve: Az új epyc támogatja a 12 memória csatornát.
https://lore.kernel.org/lkml/20211208174356.1997855-1-yazen.ghannam@amd.com/
+ [F19_M10H_CPUS] = {+ .ctl_name = "F19h_M10h",+ .f0_id = PCI_DEVICE_ID_AMD_19H_M10H_DF_F0,+ .f6_id = PCI_DEVICE_ID_AMD_19H_M10H_DF_F6,+ .max_mcs = 12,+ .ops = {+ .early_channel_count= f17_early_channel_count,+ .dbam_to_cs = f17_addr_mask_to_cs_size,+ }+ },
https://www.phoronix.com/scan.php?page=news_item&px=AMD-EDAC-RDDR5-LRDDR5
lassan minden 12 lesz ..
- 12 CCD / socket
- 12 memory controllers / socket
Mottó: "A verseny jó!"
Nézegetve a MILAN-X árakat és speckót ..
https://wccftech.com/dual-amd-epyc-7773x-flagship-milan-x-cpus-benchmarked-over-1-5-gb-of-total-cpu-cache-on-a-single-server-platform/
- A "3D V-Cache" ( Milan-X ) - verzió nem tud akkora "Base"/"Boost"
órajelent mint a sima verzió.
De az árazásnál ( ha igaz ) elég durva a 3DVcache felár.
- 16c -nál meg +200% ( vagyis 3x ár ! )
- 24c -nál csak +100% ( 2x ár )
- 32c-nál +50% (1,5x ár )
- 64c -nál +10% a felár .. (1,1x ár )
Jajj ... 
Persze gondolom a 16c-s Milan-X -nek főleg akkor van értelme, hogyha
elég drága szoftver licenszet működtet - és még így is megéri a legjobb 16 magosért kifizetni egy vagyont (AMD EPYC 7373X 16c $5595.99!)
( a sima - mezei AMD EPYC 7343 - 16 magos csak $1784.99! )
Mottó: "A verseny jó!"
Az általad linkelt táblázat alapján:
16C
az L3$ alapján a hagyonányos verzió (7343) csak 4 CCD-t tartalmazott (4c/CCD), míg az V-cache-sel szerelt verzió (7373X) 8-at (2c/CCD) Tehát összességében 6x annyi L3$-sel rendelkezik, nem pusztán annyival több, hogy a meglevő CCD-ket v-cache-sel is szerelik! Ha lenne ilyen változat is (128MB+256MB), az kerülhetne éppenséggel ennek fele-kétharmadába is.
24C
Ugyanaz igaz itt is.
A hagyományos változatban 6c/CCD aktív (Najó, esetleg az is lehet, hogy olyan hibás chipeket alkalmaztak, aminél az L3$ fele le volt tiltva)
Az új változatban viszont biztosan 8 CCD van egyenként 3 aktív maggal.
Itt is 6x annyi az L3$.
Meg nem is biztos, hogy ennyi lesz az msrp. Ha jól látom, akkor valami bolt által megszabott árazás. Bár a hagyományos Epyc lapkák is drágábbak, mint az msrp, de nem kizárt, hogy egy csak egy ilyen scalper árazás, ami mindig megjelenik egy-egy új, nagy keresletre számot tartó termék esetén.
Ha az AMD csak a 12-16 magos konzumer változatokra teszi rá, akkor sem adhatja azokat 2x-3x drágábban. Ki venné meg? (Márminthogy azon kívül, akinek épp szüksége lenne ilyen cuccra, de nem akar $5000-t kiperkálni az epyc változatért.) Az AMD elvileg ezt "ígérte" 2021-es konzumer product update gyanánt a "gamereknek"
Persze tudom, hogy ha eladnak úgyis mindent, akkor nem érdekes, hogy mit szól a low-end közönség.
Egyébként volt asszem szintén a wccf-en egy cikk arról, hogy megjelent pár teszt a Milan-X-ről, ahol épphogy semmi haszna nincs a v-cache-nek és hogy - az alacsonyabb órajelek miatt - épphogy némiképp gyengébbek voltak az eredmények.
Találgatunk, aztán majd úgyis kiderül..
hát igen ... sok minden még bizonytalan ..
> Ha az AMD csak a 12-16 magos konzumer változatokra teszi rá,
> akkor sem adhatja azokat 2x-3x drágábban.
én kb 10-20% ár prémiumot saccolok a consumer vonalon.
ha az 5950x - ~ 300eFt , akkor ~345e várható majd a 3D vcache.
> ahol épphogy semmi haszna nincs a v-cache-nek
> és hogy - az alacsonyabb órajelek miatt ...
az biztos, hogy nem minden alkalmazás tudja kihasználni.
És még kérdéses, hogy játékokban tudja-e hozni a fél éve ígért teljesítmény többletet .. ( persze itt is játékoktól - és játék engine -től függ ..) De szerintem az AMD általában óvatosan igérget ... szóval itt kevésbé érzek gondot ..
Viszont a TSMC az N7-n is csiszolt ..
vagyis ~+150 Mhz órajelnövekedés várható az alaptermékeknél is.
és a vásárlók ehhez képest nézik a felárat.
És persze a 3D-Vcache változatot kevésbé lehet overlockolni.
Az üzleti felhasználóknak - akik nem overlockolnak és spéci science-es alkalmazásokat használnak, szerintem biztos megéri a Vcache.
Mottó: "A verseny jó!"

Itt írják, hogy a GAAFETtel(MBCFET) újra lehet növelni a SRAM sűrűséget. Cikk közepe táján van. [link]
[ Szerkesztve ]
"Ilyen dolog ez, folyamatos növekedés, egy állandó méretű bolygón :D Rip rendszer..." by Crim
AMD Ryzen 7 PRO 5850U Linux Performance
( Lenovo ThinkPad T14s Gen2. )
https://www.phoronix.com/scan.php?page=article&item=amd-ryzen7pro-5850u&num=1
Mottó: "A verseny jó!"
Az 5850U Pro valójában az 5800U, csak másféle támogatással, nem?
Találgatunk, aztán majd úgyis kiderül..
SK Hynix 24-48GB DDR5 [link]
Elnézést, kicsit off, de érdekes.
Ezért mondom, hogy én nem biztos, hogy mernék már AM4-be beruházni ha az nem csak egy procicsere, mert jön DDR5. Aminek nem is a sávszélesség a lehet a nagy dobása, hanem a kapcitás ugrás.
Persze minden ár függvénye, de remélhetőleg 2 év múlva már mainstream lesz a DDR5.
Jelenleg talán az asztali piacon a 2x16GB a mainstream. Itt már arról beszélnek, hogy a 2 modullal 64-96 is elérhető. De ha csak a fele 32-48GB-ot nézzük, akkor is látható, hogy a néhány.éve még mainstreamben utazó 16GB-os gépek nagyon hamar korosodnak majd.
Persze majd meglátjuk,
Miylem árban lesznek
És esetleg jön-e ugyanez a sűrűség DDR4-re is?
Találgatunk, aztán majd úgyis kiderül..
"akkor is látható, hogy a néhány.éve még mainstreamben utazó 16GB-os gépek nagyon hamar korosodnak majd."
Ezt mi támasztja alá?  Most is alig van mainstream "végfelhasználói" program, ami 16GB-nál többet kér, pedig akár 128GB is beletömhető egy mainstream rendszerbe évek óta DDR4-en is.
Most is alig van mainstream "végfelhasználói" program, ami 16GB-nál többet kér, pedig akár 128GB is beletömhető egy mainstream rendszerbe évek óta DDR4-en is.
> Az 5850U Pro valójában az 5800U, csak másféle támogatással, nem?
én is így tudom ..
a "Pro" -s ban valószínüleg aktiválva van pár extra (hw-es) security-s és enterprise-os ficsőr ,
amit vagy kihasznál az os/szoftver - vagy nem ...
- AMD PRO security
- AMD PRO manageability
- AMD PRO business ready
https://www.amd.com/en/processors/laptop-processors-for-business
pl. "Secure Memory Encryption (SME) is an x86 instruction set extension introduced by AMD for page-granular memory encryption support using a single ephemeral key. ...
On its Ryzen Pro processor families, AMD brands TSME as Memory Guard. ..."
https://en.wikichip.org/wiki/x86/sme
persze a valóságban - azért itt is vannak bug-ok ..
"Linux To No Longer Enable AMD SME Usage By Default Due To Problems With Some Hardware" https://www.phoronix.com/scan.php?page=news_item&px=Linux-SME-No-Default-Use
Elméletileg - ha valaki felhőben dolgozik,
akkor le tudja ellenörizni - hogy "amiben" dolgozik - az titkosítva van-e ..
https://github.com/AMDESE/mem-encryption-tests
Mottó: "A verseny jó!"
+1.
"persze a valóságban - azért itt is vannak bug-ok .."
Azt írja, a régi Raven Ridge-el voltak bajok. Amúgy úgy tudom az SME és TSME nem ugyanaz (ők is úgy tudják: [link] ), nekem van itthon egy Ryzen 5 Pro 4650U, annál BIOS-ból tudom kapcsolni a TSME-t, és az elvileg az OS számára (is) láthatatlanul titkosítja a teljes memória tartalmát, minimális teljesítményveszteség árán. Szvsz bizalmas, vállalati környezetben igen hasznos lehet.




