Hirdetés
- bb0t: Ikea PAX gardrób és a pokol logisztikája
- GoodSpeed: A RAM-válság és annak lehetséges hatásai
- Luck Dragon: Asszociációs játék. :)
- GoodSpeed: Márkaváltás sok-sok év után
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- sziku69: Fűzzük össze a szavakat :)
- ldave: New Game Blitz - 2025
- Real Racing 3 - Freemium csoda
- Gurulunk, WAZE?!
- Brogyi: CTEK akkumulátor töltő és másolatai
Új hozzászólás Aktív témák
-

lanszelot
addikt
válasz
 sztanozs
#6035
üzenetére
sztanozs
#6035
üzenetére
Először is nagyon szépen köszönöm a segítséget mindenkinek

Látod, te is php-val oldottad meg.
 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed bambano: ha csak azt írod le, hogy rossz séma, rossz séma, abból nem fogom tudni hol rontottam és hogyan kellene.

pch: sajnos abból egy szót se értek. Nekem az még túl bonyolult

-
-
válasz
sztanozs
#6033
üzenetére
Sehogy nem oldja meg, mert rossz az adatbázis sémája és nem akarja elhinni. De ez nem probléma, most a matematika ellen fogad, és megvárjuk, amíg megoldja.

A te megoldásod is rossz, mert ha az insert into suppliers utasításban egy oszlopot adsz meg, akkor a valuesben nem lehet két kérdőjel.
-
lanszelot
addikt
válasz
sztanozs
#6026
üzenetére
Köszönöm szépen a választ.
Nekem nem működik. Lehet én csinalok valamit rosszul ezért belinkelem a kódodt, és a hibát.
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT)";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}Hiba: "Error: SQLSTATE[23000]: Integrity constraint violation: 19 NOT NULL constraint failed: suppliers.group_id"
-
-

Louro
őstag
válasz
sztanozs
#5790
üzenetére
Sajna van egy olyan társosztály, akik adattáblából dolgoznak. Kb. a jobbklikk->select top 100 rows funkciót ismerik. Próbáltam, hogy kiexportálom nekik és dolgozzanak Excelből, így nem kellene felesleges telepíteni ssms-t nekik. De fafejű a főnökük és a "régen is így csináltuk és működött" elvet követi :/
Mivel van egy igényük van és én hülye mondtam, hogy sokat kell görgetni és a képernyő nagy része kihasználatlan, akkor dobjuk be 10 oszlopba és már talán görgetés nélkül ott lesznek nekik, amik kellenek.
Sajnos a hülye vezetőkkel ellen én kevés vagyok.
-
-
Louro
őstag
válasz
sztanozs
#5617
üzenetére
Én a T-SQL megoldást jobban csíptem. Nem voltak túlbonyolított jobok. Kisebb ellenőrző riportok, töltések. Csak most kitalálták az anyacégnél, hogy mindent át kell ültetni.
Az okot nem tudom. De mivel akad néha valami módosítás, ami igényli, hogy hozzányúljuk meglévő folyamatokhoz. Eleve nem túl gyors és viszonylag sűrűn omlik össze a Visual Studio. Félek, hogy ez durván lassítani fog. Ezért gondoltam ,hogy a tárolt eljárás kiskapu lehetne, hogy gyorsan szűrhessek. Anno Excelbe elkezdtük adminisztrálni, hogy melyik job mit tartalmaz, de hamar hamvába halt, hogy nem cska ketten csináltuk. Vagy mindenkinek kellene vagy senkinek. -

Hintalow
senior tag
válasz
sztanozs
#5506
üzenetére
Lehet bevettem némi fogalmazásgátlót

1 sor xxy
2 sor xxy
3 sor xyx
stb.Azt szeretném, hogy számolja a az értéket, és mondjuk az xxy-t tartalmazó soroknál egy 2-es menjen minden sor végére, mert 2x szerepel, az xyx sor végére 1-es, ami 10x ugyanaz az érték, ott minden azt az értéket tartalmazó sor végére 10-es stb.
Mintha csak lehúznék egy countif-et végig rajtuk.
-

Taci
addikt
válasz
sztanozs
#5441
üzenetére
Köszönöm, hogy rászántad az időt és ezt ilyen részletesen leírtad, de valószínűleg akkor rosszul (túlbonyolítva) tettem fel a kérdést, mert (bár pár új részletet megtudtam, köszönet érte, de) nem erre irányult a kérdésem, ez a része tiszta.
Ezt írta bambano: az a megoldás, ha a link a saját webjére mutat és redirectel a célra.
Én pedig azt szeretném megérteni, hogy miért jobb egy ilyen módszert kifejleszteni (ennél a példánál maradva: rd aldomain, átirányítás saját aldomain-ről a külső linkre) ahelyett, ahogy pl. tegnap a tesztszerveren megcsináltam, hogy simán csak megnyitja a külső linket (href), mellé meg fut egy szkript (onclick), ami szerver oldalon realizálódik és tárolja az összes adatot ami szükséges. Miért kell hogy saját szerverre mutasson a link, és onnan legyen az átirányítás a külső linkre?
@martonx: Köszönöm.
-
Taci
addikt
válasz
sztanozs
#5438
üzenetére
Én elhiszem, hogy a segítő szándék vezérelt (ahogy korábban is), de semmivel sem jutottabb előrébb egyik kérdéssel kapcsolatban sem azzal, hogy átolvastam pl. a Wikipédia cikket róla.
Nem is értem, mire írtad, max a 301 status code-nál lenne értelme, de ott pont nem volt semmi ilyen kérdésem, csak az eredeti fájlt nem tudtam elkapni, hogy amiről átirányít, az hogy néz ki - csak később curl-el.
Ebből egyik témára sem kapok választ, de még csak iránymutatást sem:
- "az a megoldás, ha a link a saját webjére mutat és redirectel a célra."
- "Google Analytics erre a megoldás, saját kókányolás helyett."
De így már ez tényleg teljesen offtopic ide. -

nyugis21
kezdő
válasz
sztanozs
#5371
üzenetére
Tudnál segíteni, hogyan lehet az ms weboldalán értelmesen keresni?
Az általad linkelt weboldalról kizárólag az "egyszerű keresés" weboldalra van link, és ha az alsó keresőbe írok be témát, vegyesen ad excel, share point és mindenféle mást.
Most két témára keresem a választ:
Az egyik a projektes példára vonatkozik, ez alapján látszik, hogy csak nagyon bonyolult, több táblás lekérdezéssel lehet adatot felvinni, ezt akarom megérteni, de a példában nem engedi, hogy megnézzem az sql kódot, és a weboldalon nem tudok továbblépni, illetve nincsen link másik weboldalra, ami az adatbevitelt elmagyarázná.A másik egy általános kérdés, a táblák közötti kapcsolatnál van három sor, az elsőt értelemszerűen be kell pipálni, ha két táblát összekapcsolok, de a másik kettő használata nem teljesen világos számomra. Úgy sejtem, akkor lehet belőlük probléma, ha adattörlésre kerül sor, és akkor rekurzívan törölnek másik táblákból is, de nem értem, hogyan és miért, és mi a különbség közöttük.
-
válasz
sztanozs
#5386
üzenetére
a keresendő adatom egy adatpár. van egy A és egy B oszlopom. Csak azokat az egyezőségeket keresem ami A oszlopban pl az egyes sorba van. Tehát A1-et B1-el. A elvileg nem ismétlődhet, de B igen.
nyunyu: rendben, köszi
kb 10k sorom volt, és 7 darabbal lett több. Distinctet direkt nem írtam az ID-ra, mert állítólag az ID-ban nincs ismétlődés, de majd leellenőrzöm. -
válasz
sztanozs
#5384
üzenetére
igen, bár az elsőben ismétlődés nem lehet, mert egyedi azonosító. Egy azonosítóhoz tartozhat sok dátum, de én csak azt keresném ami mellette van. És persze előfordulhat olyan, hogy egy másik azonosítóhoz ugyan az a dátum van rendelve. Ezt szeretném kiszűrni, és csak úgy lekérdezni az adatokat, hogy csak a mellette lévő dátummal keressen
ez így baromság?and (azonositok.ids = temp.column1 and azonositok.dates = temp.column2)
-
nyugis21
kezdő
válasz
sztanozs
#5377
üzenetére
Mondanál egy Móricka-példát arra, hogy mi lehet egy Projekt < több esemény < több feladat?
5374 első mondatában leírtam, a projekt az eseményekből áll, amik megtörténtek, a feladatok az elintézendőek, amik jövőbeli dolgok.
Először azokat is be akartam venni, hogy lehessen látni az összes történést, de rájöttem, hogy az túl sok lenne, így azt majd csak ki kell pipálni, hogy még élő dolog, vagy már befejezett.
A Móricka példa a kedvedért:
projekt (ügy):
az osztályban lévő lányokat virágesővel köszönteni 1 hét múlva.
1. esemény:
gyűlés, résztvevő Móricka, Ottó, a tizedes, meg a többiek
leírás: Megalakult a "LáViKö" csoport, a lányokat virágesővel köszöntők csoportja.Feladatok:
1. feladat felelős: Móricka, teendő: megtudni, hol a legolcsóbb a cserepes virág - kipipálva
2. feladat felelős: Ottó, teendő: létrát szerezni - kipipálva2. esemény:
gyűlés, résztvevő Móricka és Ottó
leírás:
Móricka közli, hogy 13 virágkereskedést hívott fel, a legtávolabbinál van a legolcsóbb cserepes virág, így autó kell a beszerzéshez
Ottó közli, hogy megszerezte a szomszéd villanyszerelő létráját, de sietni kell a visszaadással, mert az illető a csavarhúzójába kapaszkodva maradt.Feladat:
1. feladat: pénzt összeszedni a tagoktól - kipipálva
2. feladat: cserepes virágokat gyorsan elhozni - kipipálva
3. feladat: virágesőt lebonyolítani- kipipálva
4. feladat: létrát visszavinni- kipipálva3. esemény
résztvevők: Móricka, Ottó, a tizedes, meg a többiek
leírás: 600 ft-ért megvették a virágokat, 200 ft-ért elhozták taxival, virágeső létra tetejéről megvolt, annyira sikeres lett, hogy a lányok a földön fekve sikongattak4. esemény
Ottó a létrát visszavitte, a villanyszerelő a földön feküdt aléltan, így a létrát ratette, hogy balesetnek látszódjonEz egész érthetőnek és jól felépítettnek tűnik a leírás alapján.
Nekem nem úgy tűnik, pl. hova írom be az eseményekhez a résztvevőket? Az ESET táblába nem tudom betenni, mert onnan az ID-vel kell kapcsolódnom a M táblához, akkor az M táblába kell felvennem egy résztvevők rubrikát?
Valamint a Feledat-okat is jelezni kell, hogy élő, vagy megoldva, ezt talán logikai Y/N mezővel meg lehet oldani, de akkor valahogy kezelni kell, hogyha megoldva, akkor ne legyen megjelenítve a lekérdezésben később, de jelentésekben szerepeljen, ha a feladatok is érdekesek lesznek.Adatbevitellel próbálkoztam, de úgy tűnik, az access nem szereti, ha egy id-hez egynél több tábla kapcsolódik, erre még megoldást kell találnom.
-
nyugis21
kezdő
válasz
sztanozs
#5371
üzenetére
Furcsa ez a fórum, elvileg segítőkészséget ígértek, de ahogy visszaolvastam, a nekem írt "tanácsok" nagy része nem a témához tartozik, vagy félrevezető.
![;]](//cdn.rios.hu/dl/s/v1.gif)
Utána néztem, az acces is sql alapú, ami 1992-es megegyzés (szabvány?) alapján jött létre, majd 1999-ben volt egy újabb verzió, de azt már nem mindenki fogadta el. Akkor most nem mindegy, hogy a program 2007-es vagy frissebb, ha évtizeddel korábbi kódot használ?
Legyen lényeges téma is:
Agyalok egy ideje a megoldáson, szerintem táblák közötti kapcsolat mindennek a kulcsa, azt kellene valahogy összehozni, ebben lenne szükségem segítségre, az pedig még a programtól független megoldásnak tűnik.Amin elakadtam:
A project minta adatbázisban van egy jónak látszó megoldás, hogy a projekt-hez lehet feladatokat csatolni, amihez felelőst lehet kinevezni, de ha jól értem, ez csak úgy működik, hogy a projektnek is van felelőse (tulajdonosa?).Az én megoldásomban a projekt az eseményekből áll, amihez sok résztvevő tartozik - azaz ellentétes a példával, ahol csak egy felelős van - és az eseményekhez kellene feladatokat csatolni, amiknek lenne felelőse.
DE: a feladat megvalósításával az is eseménnyé válik.(Példa:
esemény: telefonhívásos megbeszélés 2 személy között, megegyeznek, hogy az egyik megvesz valamit, majd elviszi a másiknak, aki azt majd később visszaadja neki.Erre két megoldást látok:
1.séma
Az egyik megoldásnál van egy esemény 2 fővel, telefonos megbeszélés, majd lesz egy újabb esemény 2 fővel a találkozóról, ahol a lényeg az, hogy az egyik átad valamit a másiknak.Az első eseményhez kapcsolódik két feladat, az első feladatnak az egyik személy a felelőse, és a téma a bevásárlás.
A másik feladatnak mindkét személy a felelőse és a téma adott helyen és időben találkozni.A második esemény már a megvalósult találkozó lesz, ahol adott helyen és időben a két személy találkozik és megtörténik az átadás.
Ehhez rögtön kapcsolódik egy újabb feladat, a második személy a felelőse, és adott határidőre vissza kell adnia a dolgot az első személynek.Ekkor kell két külön tábla, az egyik az esemény, amikhez feladatok kapcsolódhatnak, a másik a feladat, ahol csak az a lényeg, hogy megvalósult, vagy sem.
A hátránya, hogy néha ugyan az a dolog feladat és esemény is lesz, lekérdezésnél esemény és feladat sorrendet kell választani.2.séma
A fenti folyamat azzal a különbséggel, hogy a feladatok a sikeres teljesüléskor eseménnyé válnak.
Ekkor a lekérdezés (megjelenítés) egyszerűbb lesz és nem lesz párhuzamos adat, de fogalmam sincs, hogyan lehet ezt megvalósítani - talán kell egy "kód" mező, hogy ez feladat vagy esemény?A másik problémám az, hogy a feladathoz egy felelős kell, ami a ms projekt mintában látszik, hogy csak egy személy kapcsolódik hozzá, DE! amint eseménnyé válik, akkor már ellenkező irányú kapcsolat kell, mert akkor már több résztvevője lehet az eseménynek.
Tehát, ha az ms projekt sémáját követem, akkor a második feladatot, amikor két személynek kell találkoznia, mindkét személynek ki kell osztani, személyenként lehet egy feladat, és mindkettőnek teljesülnie kell, hogy létrejöjjön a két feladatból az egy esemény.Ez önellentmondásnak tűnik számomra, ti ezt hogyan oldanátok meg? (vagy fel, ha az ellentmondást fel kell oldani.)
-
nyugis21
kezdő
válasz
sztanozs
#5369
üzenetére
Most látom, hogy már lelkes újonc vagyok, a moderátorok adnak kategóriákat?
------
1. Nem, az oldalon nem tudok semmit megtalálni, bármit keresek, az első tiz találatot megjeleníti - ami többnyire aktiváld-töltsd le, stb. - és nem enged továbblépni a többire.2. amennyit értek a videóból, az már 2016-os access példafájl, képpel, és csak a task-employee két táblából áll.
ennél jobb a projects adatbázis - lásd lentebb a képet - ha megtalálnád az azt bemutató videot, megköszönném, ott nem értem, miért van külön task és common task tábla is, eltérő kapcsolatokkal.3. Ez volt az első kérdésem, hogy hogyan lehet access példa adatbázisokat összehozni, de nem volt rá válasz. Végignéztem mindet, ami 2007-ben volt, a project adatbázis volt a legjobb, de nagy része felesleges nekem, más részét nem értem, mire jó és miért így vannak a kapcsolatok, és van, ami nekem hiányzik belőle, ezért kellett nekem több tábla.
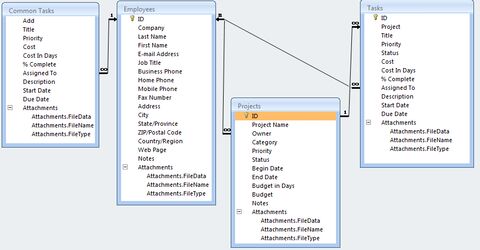
Itt van
project - ami nálam ügy,
tasks - ami nálam feladat
employees - ami nálam emberek
common tasks - fogalmam sincs, hogy mire jó, és csak az emberekkel van kapcsolatahiányzik az
eset - vagyis a project/ugy egyes lepesei
hely - esetek valahol történnek (vagy virtuálisak, pl. telefonhívás)Valamint itt úgy látszik, hogy mind a project, mind a task csak egy emberhez tartozhat, míg ténylegesen többen vesznek benne részt, és gyakran mindig mások.
-
nyugis21
kezdő
válasz
sztanozs
#5343
üzenetére
Óh, köszönöm, én az eset táblával próbálkoztam, mert annak van minden táblával kapcsolata, de az "a kapcsolat másik végén" van.
Egyenlőre csak azt akarom valahogy tesztelni, hogy ez az elrendezés működik-e, és igen, akkor miért nem, ezért akarok pár adatot bevinni.
Ha működik, akkor akarok nekiállni a beviteli űrlapot megcsinálni, ahhoz már most segítséget kérek, eddigi tudásom alapján azt sejtem, hogy a feladat-okat csak lekérdezéssel lehet majd bevinni, amire eddig semmilyen példát se találtam. Igazából nem is nagyon értem, mert úgy látom, hogy a táblába beviszek egy rekordot, majd a feladat "virtuális tábla" révén ugyan abba a táblába viszek fel újabb rekordokat, amik egyenlőre üres sorok lesznek, hoszen csak később realizálódnak.
Ennek emésztéséhez kérnék segítséget, mit olvassak el, hogy ezt a megoldást megértsem. -
nyugis21
kezdő
válasz
sztanozs
#5297
üzenetére
Igen, igazatok volt, csak megjelenítése ilyen furcsa.
Azóta viszont elakadtam, sehogyan se tudok adatokat bevinni a táblákba.
Egy hete bújom a könyveket és oktatóanyagokat, de semmit se találtam rá.

Hogyan tudok legalább két sornyi adatot bevinni minden táblába, hogy kipróbálhassam a lekérdezéseket?
-
nyugis21
kezdő
válasz
sztanozs
#5272
üzenetére
Helyes,akkor ez nekem való, a bíróságot meg nem akarom többet látni.
Sejtettem, amint a Northwin-det megnyitottam, hogy amit akarok, az jóval egyszerűbb, majd átnéztem a többit is, azt hiszem, a task és projekt ami részben kell nekem, de sok velük a gond.
Az első kérdésem:
Azt látom, hogy kis különbséggel azonos táblák vannak különböző fájlokban.Hogyan lehet a táblákat átmásolni másik access fájlba, vagy több access fájlból egyet csinálni, és a fölösleges táblákat törölni?
-
nyugis21
kezdő
válasz
sztanozs
#5269
üzenetére
Nem, angollal hadilábon vagyok, csak az írott szöveget értem valamennyire. Igaz, németet még annyira se, a francia és spanyol és más nyelvek pedig hottentotta kategóriák nekem.
Nem akarom megtanulni a programozást, meg akarok csinálni azokat, amikre szükségem van.
Elegem van abból, hogy azt mondják, hogy ahhoz fizetnem kell milliókat, amikor látom, hogy access-ben csak kattintgatnak és máris működik.Nemrég egy szélhámos megalázott a bíróságon, hogy összekevertem dátumokat és nem emlékeztem pontosan az adatokra, így még nekem kellett fizetnem azért, hogy átvert.
Két programra van szükségem, amiket meg akarok csinálni, ha már senki se akar segíteni nekem, akkor "magad uram" elv alapján, és amikor elakadok, akkor kérek majd továbblépéshez segítséget.
Az egyik program az legyen, ahova minden este beírom, hogy aznap mi történt, dátum és óra szerint, hogy mi volt az ügy, mi történt, levél vagy telefon, vagy cselekedet, és ki hívott vagy írt levelet. Esetleg legyen megjegyzés, vagy figyelmeztetés, hogy ott valamire várni kell, vagy határidő van, így ne legyen az, hogy valamiért nem kapom meg a levelet, vagy nem hívnak, és utána azt mondják, hogy de, hívtak és volt megállapodás.
Ha kell, akkor ott legyen, akár a bíróság számára is bizonyíthatóan, hogy pontosan mikor mi történt, és akkor már az adott ügy összes történését lehessen csak látni.
Bár már nem akarok többször bíróságra menni az életemben, csak meg akarom mutatni, hogy van egy lista a történésekről, így a szélhámosok már ne is próbálkozzanak többet.A másik program az idézeteknek legyen, nagyon pontosan emlékszem mondatokra, de nem tudom, hogy melyik filmből, vagy könyvből valók.
Ezek szerintem egyszerűen megvalósíthatóak, vagy legalábbis annyira, hogy segítséggel még én is össze tudom ezeket kattintgatni.
-
Taci
addikt
válasz
sztanozs
#5140
üzenetére
Ha az általad írt lekérdezés által visszaadott össz-elemszámot szeretném megtudni (a belső limit nélkül - hogy később tudjak vele számolni, a belső limit meddig nyújtózkodhat - szóval a belső Select-et ezért veszem ki, plusz ugye nem kell rendezni sem (Order By), és a végén lévő Limit sem kell)), akkor jelen tudásom szerint azt így kérdezném:
SELECT COUNT(*) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id) AS tVan esetleg ennek hatékonyabb, gyorsabb, jobb módja?
Ezt találtam még:
SELECT COUNT(DISTINCT item_id) AS result_count FROM(SELECT i.item_id FROM items AS iINNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)) AS tItt elvileg a Distinct kiváltja a Group By-t.
Viszont sajnos Count-hoz a phpMyAdmin nem ír lekérdezési időt, így nem tudom, melyik a gyorsabb. Vagy jobb.
Ebben kérnék tanácsot.
Köszönöm. -
Taci
addikt
válasz
sztanozs
#5140
üzenetére
 Na azért ez így hasít...
Na azért ez így hasít...
0.0096 secondsEzek szerint akkor nem kell "archiválni"? Akármekkorára is dagad a tábla, jobb egyben tartani? Vagy van egy határ valahol, ahol már szeletelni kell?
GROUP BY i.item_id, i.item_date
Itt miért kell az _id után a _date is, ha csak azért van a Group By, hogy egy-egy _id csak egyszer szerepeljen? (Csak szeretném megérteni.)Illetve még egy dolog jár ezzel a lekérdezéssel kapcsolatban a fejemben:
Ez egy nagyon jó és gyors lekérdezés. Azt hogyan lehetne legoptimálisabban megoldani, hogy ha a visszaadott rekordok száma kisebb, mint 4, akkor megnézze LIMIT 1000 helyett 2000-re is? Mert ha 2000-ben a talált rekordok száma nagyobb egyenlő mint 4, akkor onnan kell az eredmény, és akkor a következő görgetős lekérdezéshez is már a 2000-et kell használni, mert az 1000 nem volt elég.
Ehhez elég gyors ez a lekérdezés már, úgy gondolom, hogy kettő egymás után is beleférjen, ha kell.Hogy a gyorsabb/jobb?
1) Futtatom a query-t, aztán számoltatom php-ben a rekordok számát, és ha kisebb, mint 4, akkor jöhet az újabb query 2000-re?
2) Vagy előbb "üresen" csak egy Count, és az eredmény függvényében a valós (rekordokat visszaadó) lekérdezés?
3) Vagy van valamilyen COUNT-os utasítás (esetleg feltételes is) hozzá, amivel ezt még SQL-oldalon meg lehetne oldani? Ami akár egy lekérdezésen belül visszaadja, hogy az 1000-es limittel mennyi rekordot adna vissza, és ha 4-nél kevesebbet, akkor egyből futtatja 2000-re?Egy Count biztosan sokkal gyorsabb, mint az összes érintett mezőt visszaadni, és azt számoltatni, csak ezért jutott eszembe a kérdés.
-
Taci
addikt
válasz
sztanozs
#5137
üzenetére
Köszönöm szépen a részletes magyarázatot és okfejtést! (És mindenki másnak is, aki segített!)
Mindezt figyelembe véve még az az elméleti kérdés jutott eszembe, hogy:
Csakis és kizárólag a legfrissebb dátumú elemek vannak elől. Egyszerre mindig csak 4 elemet kap a felhasználó, mindig a (kiválasztott kategóriának stb. megfelelő) 4 legfrissebb dátumút. Mindig.
Ezek a rekordok pedig 5 percenként kerülnek az adatbázisba, kb. 5-10-esével / forrás, 20-30 helyről egyszerre.
Aztán ha görget a lap aljáig (mínusz X pixel), akkor következő 4 és így tovább. 25 görgetés 100 rekord. 250 görgetés 1000 rekord. 750 görgetés 3000 rekord. Ennyit nem fog senki soha egy huzamban végig pörgetni a szűrési feltételek módosítása, vagy ráfrissítés nélkül (ahol 0-ról kezdődik az egész).
Plusz a következő "4-esbe" az időközben bekerült új rekordok is benne kerülnek, szóval egyre kevésbé valószínű, hogy "túl mélyre ér" (a rekordok időbélyegzőit figyelembe véve).Így a tábláknak (items) nem kellene csak max 3 ezer (az items_categories-nak pedig átlag 3 kategória/item-mel számolva max 9 ezer) rekordot tartalmaznia. Tehát a mostani példa adatbázisomnak (300e / 900e) a század részét.
Most levittem erre a számra a rekordok számát, és így az eddigi 0,5 mp-es lekérdezés 0,01 mp-re (sőt inkább alá) szelídült. Azért ez már élhető. Még ha a duplájával számolnék (rekordszám) a biztonság kedvéért, akkor is.
A legfrissebb 3000 utáni rekordra pedig csak és kizárólag a szöveges keresésnél lehet szükség, ott pedig belefér egy lassabb (Union miatt) lekérdezés is.
Illetve még akkor is, ha mondjuk csak 1 kategóriát néz, és abban a legfrissebb 3ezerből csak kb. 100 rekord van (30+ kategória van), és 25-től többet scrollozik - ami azért nem olyan sok. Inkább megnéztem most gyorsan 6e/18e rekordra, 0,03 mp alatti a lekérdezés, és így "biztonságban is lennék" minden téren.A kérdésem az lenne, hogy:
1) ezt jó ötletnek tartjátok-e,
2) ha igen, akkor hogyan lenne jobb az "archív" rekordokat tárolni? Minden, ami nem a 3000 (vagy 6000) legfrissebben van benne, az legyen egyetlen egy darab (mondjuk items_archive) táblába áthelyezve? Mert ha jól emlékszem, azt mondtátok, hogy ahol ugyanazok a mezők vannak, nem jó ötlet szétszedni.
Viszont azt is mondták, hogy mindenképp kell "archiválni" is.
Tehát egy nagy archiv tábla legyen (items_archive), vagy legyen mondjuk évenkénti? (items_archive_2021, items_archive_2022 stb.)
Úgy gondolom, csak kereséseknél kellene használni az archívokat, normál használattal görgetve oda már "nem jut le senki" (de biztos ami biztos, felkészíteném arra is).@nyunyu: Az SQL Server Express-t most raktam fel, már a táblákat töltöm. Kíváncsi leszek az ottani eredményekre.
-
Taci
addikt
válasz
sztanozs
#5126
üzenetére
SELECT item_id, item_dateFROM itemsWHEREitem_id IN (select item_id from items_categories wherecategory_id not in (1,3,13,7,20) anditem_id not in (117,132,145,209,211))ORDER BY item_date DESC LIMIT 4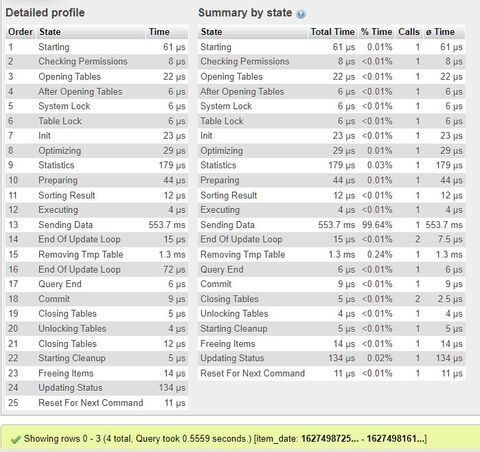

(valami régi kódból maradt benne a neve, a feed_id az az item_id az index nevében)
Mivel itt azt mondja, hogy az items_categories táblán nem használ indexet (key = NULL), ezért arra gondoltam, akkor létre hozok egy covering indexet ide:
CREATE INDEX idx_category_id_item_id ON items_categories (category_id,item_id)A sebességen nem javított, de most már így néz ki az explain:

----------
SELECT i.item_id, i.item_dateFROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_idWHEREc.category_id NOT IN (1,3,13,7,20) ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_id, i.item_dateORDER BY i.item_date DESC LIMIT 4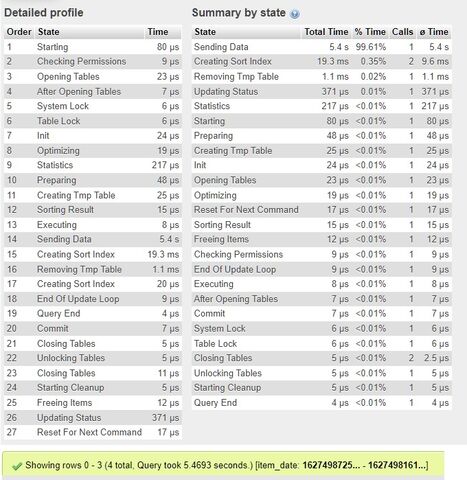

Itt ha a
GROUP BY i.item_id, i.item_date
helyettGROUP BY i.item_id
van, akkor ennyi a változás:
De időben semmit nem jelent.
-
-
Taci
addikt
válasz
sztanozs
#5126
üzenetére
Mondjuk egy-egy execution plan-t jó volna látni mindegyikre...
Ezekre a fajta információkra gondolsz (a lekérdezés egyes részei mennyi ideig futottak, használt-e indexeket stb.), amit az Explain és a Profiling ad? (Google-ön rákeresve az execution plan-re phpMyAdminban ezeket dobta fel.)
Mert akkor megcsinálom.
-
válasz
sztanozs
#5126
üzenetére
"az indexet növekvő sorrendben hozza létre így az index végén levő (legnagyobb értékek) rögtön rendelkezésre kell álljanak": szemben azzal, ha csökkenő sorrendben hozza létre, mert akkor az index elején áll rendelkezésre a legnagyobb érték.
normálisan az indexet egyféleképpen kell létrehozni, és ha csökkenő a lekérdezés, akkor egyszerűen reverse scan-t csinál. legalábbis a postgres ilyen, hogy más adatbáziskezelők mit csinálnak, nem tudom.
-
Taci
addikt
válasz
sztanozs
#5124
üzenetére
Köszönöm szépen a sok energiát amit bele fektettél.
Az indexeléssel kapcsolatos módosítás nem hozott érezhető eredményt. (Amúgy ha Order By DESC van a lekérdezésben, akkor az indexet is DESC alapján kellene létrehozni, nem? Csak mert ASC-t írtál. De amúgy próbáltam mindkettővel, nincs változás sajnos.)
A Join-os lekérdezés sajnos minden formájában szörnyen lassú, ha van benne Group By is.
- Copy-past amit #5124-ben írtál: 7.6651 seconds.
- Group By nélkül: 0.0278 seconds. (Csak így egy-egy rekord (az amúgy jó eredményekből) többször is benne van, ami nem jó.)Közben hogy kiszűrjem, hogy nem-e az én lokál gépeimen (kettőn építettem fel és futtattam a lekérdezéseket) van-e a gond, kipróbáltam egy ingyenes szolgáltatónál is (000webhost.com, a célnak megfelelt tökéletesen).
Sajnos ugyanaz az eredmény.Elképzelhető, hogy ennél a 300e rekord az egyik táblában, és 900e rekord a másikban (és ezek összekötve), itt ez a max lekérdezési sebesség? A leggyorsabb helyes eredményt az #5112-ben leírt lekérdezés hozta, 0,5 mp. Ami lassú így is.
Szóval lehet, hogy ha majd elérek 100e bejegyzés környékére (az első táblában), akkor el kell gondolkodnom a régi rekordok "archiválásán"? Hogy a fő táblában ne legyen 100e rekord fölött, és akkor "megúszom" a lekérdezéseket (amik persze csak a fő táblából kérdeznek le, nem az "archivakból") kb. 0,2 mp alatt?Több ötletem nincs. És köszönöm szépen nektek ezt a sok segítséget és próbálkozást, nem akarok visszaélni a jóindulatotokkal.
-
válasz
sztanozs
#5123
üzenetére
és ha minden Itemhez csak egy dátum tartozik, akkor használható az index:
SELECT i.item_id, i.item_date
FROM items as i INNER JOIN items_categories AS c ON i.item_id=c.item_id
WHERE
c.category_id NOT IN (1,3,13,7,20) AND
i.item_id NOT IN (117,132,145,209,211)
GROUP BY i.item_id, i.item_date
ORDER BY i.item_date DESC LIMIT 4 -

nyunyu
félisten
válasz
sztanozs
#5116
üzenetére
Nincs rá garancia, az igaz.
Gyakorlatban meg pont emiatt szívtam a mostani GDPR projektemen.
3 insert szedte össze a daráló érett szerződéseket, első leválogatta az egyik típusú szerződéseket, második az első szerződésekhez kapcsolódó másik típusúakat, harmadik meg a második típusúakból az önállókat.Aztán amikor beröffentettük az állami hivatallal való szinkronizációt, az első 20000db-os adatcsomagba kb. 19000 olyan rekord került, aminek az IDja 20000 alatti volt.
Végül a második típusú szerződések szinkronizációjára már csak akkor került sor, amikor az első típusúak teljesen elfogytak a táblából.Ez azért volt kellemetlen, mert mint kiderült, a második típusú szerződések nagy része nem kellett, hogy meglegyen az állami nyilvántartásban, azok sokkal gyorsabban darálhatóak lennének.
Első típusúak darálása meg nem ment olyan gyorsan a túloldalon, mint vártuk. -
Taci
addikt
válasz
sztanozs
#5107
üzenetére
Értem a logikát mögötte, és amúgy tök jó ötlet, köszönöm a tippet - de sajnos kb. 0,2 mp-cel lassabb, mint az előző.
Csak kíváncsiságként:
Itt az ORDER BY 2 ugye a második mezőt jelenti, ami jelen példában a MAX(item_date)? Ha sok mezőm lenne a SELECT-ben, és nem akarnám számolgatni, ide írhatnám azt is az ORDER BY 2 helyére, hogy ORDER BY MAX(item_date)? (Most így lefut a lekérdezés, az eredmény ugyanaz, csak nem tudom, az ORDER BY-os résznél is műveletnek veszi-e a MAX-ot, vagy már a fenti SELECT-ben elvégzettre hivatkozik?) -
-
Taci
addikt
válasz
sztanozs
#4939
üzenetére
Ha jó keresési találatokat nézek, akkor ez az, ugye? (Soha nem hallottam még róla, és amikro azt kerestem anno, hogy tudok keresni szavakra, a LIKE-ot dobta a legtöbb oldal, ezért kezdtem el ezt használni.)
WHERE CONTAINS ((title, description),'"szoveg1" AND "szoveg2" AND "szoveg3"')Ha ez így helyes, akkor ugye mindkét helyről (title, description) ad vissza találatokat, akár egyikben, akár másikban, akár mindkettőben van találat az összes keresett szóra?
@bambano:
Ez azt jelenti, hogy inkább egy táblám legyen csak?
De amúgy tényleg érdekelne, hogy miben/mennyivel "rosszabb", ha több táblában vannak az adatok. Nyilván a sebesség az egyik válasz, ez biztos. De érdekelne, miben még.Úgy szeretném megcsinálni, hogy utána szerkezeti változás miatt ne kelljen már "soha" belenyúlni, ezért veszem a fáradságot és időt és átírom, ezzel nincs baj. Csak érteni is szeretném a miértjét.
Köszi.
-
nyunyu
félisten
válasz
sztanozs
#4932
üzenetére
'NOT IN' elég pazarló (legalább is az én ismereteim szerint), persze lehet, hogy a modern motorok már átalakítják kevésbé lassabbakra.
Tizenéve már azt tanították az egyetemen, hogy mindegy, úgyis átalakítja left joinra az optimalizáló.
Gyors futáshoz LEGYEN index a vizsgált mezőn.A LIKE-ok meg szerintem mindegy milyen scope-ban futnak.
Na, az az igazán pazarló, pláne, ha %-gal kezdődik a lájkolnivaló, mert akkor semmilyen indexet nem tud használni hozzá, hanem mindig full table scan lesz a vége.
Ha csak 'valami%'-ra alkalmazod a facebook filtert (vagyis ismert a string eleje), akkor legalább a keresendő oszlopra rakott indexből tud dolgozni. -
nyunyu
félisten
válasz
sztanozs
#4919
üzenetére
Csak hogy az Oracle szintaxis is meglegyen:
select szttorzsszam, sztnev, listagg(klnevhu, ',') within group(order by klnevhu) from szemelytorzs
left join bfkepzettsegimatrix on szemelytorzs.szttorzsszam = bfkepzettsegimatrix.kmtorzsszam
left join kepzettseglista on bfkepzettsegimatrix.kmkepzettsegid = kepzettseglista.klid where szttorzsszam = '1234'
group by szttorzsszam, sztnev; -
nyunyu
félisten
válasz
sztanozs
#4573
üzenetére
Group by után minden olyan mezőt fel kell sorolni, ami nem szerepel az oszlopfüggvények paraméterében.
Ha van egy fixen 'kiscica' oszlopod, akkor azt is.
Értelmes interpreterrel bíró DBken valahogy így nézne ki:
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id, ad, nev, ertek2, ertek3, ertek4, ertek5;Kevésbé értelmeseken valahogy így:
group by id, 1, 3, 5, 6, 7, 8;(Ha már a hülye Oracle nem tud alias alapján rendezni, csoportosítani, csak oszlopszámmal...)
-
válasz
sztanozs
#4570
üzenetére
Ja, ahogy nézem nem is kell subselect, simán mehet a végére is...
select 'adat' ad, ID, nev, ertek1, ertek2, ertek3, ertek4, ertek5
from tabla
union
select "osszesen" ad, ID, null nev, sum(ertek) ertek1, null ertek2, null ertek3, null ertek4,
null ertek5
from tabla
group by id
order by ID, ad -
válasz
sztanozs
#4349
üzenetére
Mire gondolsz dátumaritmetikán pontosan?
Azért kérdezem, mert kipróbáltam, hogy varchar típusú oszlopokban tároltam dátumokat és hiba nélkül működött rajta a DATEDIFF.
Erre gondoltam:
create table #tmp (dátum1 varchar(50), dátum2 varchar(50))insert into #tmp (dátum1 , dátum2)values ('2019.11.01', '2019.11.02'),('2019.11.01', '2019.11.03'),('2019.11.01', '2019.11.04')select dátum1, dátum2, datediff(day,dátum1,dátum2) from #tmpHa butaságot kérdeztem, akkor elnézést kérek
-

Male
nagyúr
válasz
sztanozs
#4331
üzenetére
Az kb kizárt... egyrészt le van védve rendesen (nem mondom, hogy nem hibázhatok, de odafigyeltem az ilyesmire, és át is néztem), másrészt ez nem egy weboldal, csak a kezelőknek van hozzáférésük, ami 7 embert jelent, és ezzel dolgoznak, nem nyírják ki a saját bevételüket (ha nem őrültek meg
). -

haxiboy
veterán
válasz
sztanozs
#4319
üzenetére
Ha nem kéne másik rangere tenni a fieldeket/táblákat. Vagy nem kéne megtartani a sok adatot nem lenne gond 😅
A fieldek számozása egyébként a különböző partnerek fejlesztéseinek van fenntartva, de természetesen két azonos nevű Field egy táblában nem lehetséges. Szokott is probléma lenni ebből ha másik partnertől érkezik az ügyfél. -
haxiboy
veterán
válasz
sztanozs
#4317
üzenetére
Field No. az SQL-től független, csak a Dynamics NAV licencelés szempontjából mérvadó, a tábláknak is van számuk, SQL-ben attól még a saját nevével jelenik meg.
Sajnos ezeket a számokat a NAV nem engedi módosítani ha van benne adat, viszont lokalizáció ranget kellett váltanunk az ügyfélnél. Ez annyit tesz hogy vannak fieldek pl
1000-es számtól 1015-ig, mindegyiknek van valamilyen Neve (ami SQL-ben is a neve a fieldnek).
A számot meg kéne változtatni 2000-től 2015-ig. Csak akkor lehetséges, holott az SQL schema nem változik semmit, a NAV szempontjából ez azt jelenti hogy Törölted az 1000-es fieldeket és felvettél 2000-es fieldeket ugyanolyan névvel.Így amit csináltam (végül ugyebár működött).
SQL -> Delete from Táblanév
Navision -> Átszámozás
SQL SSIS -> Export Data az eredeti adatbázisból az átszámozott adatbázisbaSSIS-ben ennél az export datás funkciónál meg lehet neki mondani hogy mekkora batchekben commitoljon? Ha esetleg nagyobb mennyiségű adatot szeretnék mozgatni? Jelen esetben egy átlagos ~85GB-os adatbázisról beszélünk.
-
haxiboy
veterán
válasz
sztanozs
#4315
üzenetére
A változtatások dynamics nav tábla oldalon történnek (field no.) ami SQL oldalról irreveláns, attól még a field neve ugyanaz marad. De lekopogom most elvileg sikerült betöltenem az adatot az egyik kissebb vállalatnál problémamentesen. Minden a helyén maradt.
A következő 3 vállalatot amiben jelentősen több az adat a holnapi nap próbálom meg átemelni.
Nem kompatibilis adat előfordulhat, találkoztam már olyannal hogy nem lehet null érték az adott fieldben, mégis az volt ott, de hogy hogyan...fogalmam sincs, a lényeg hogy a kiexportált adatot már nem lehetett újra visszatölteni a táblába.
De a memória elfogyásra nincs ötletem, remélem most hogy csak a NAV oldalról módosult (SQL schema szerint nem) táblákat rakom át így működik majd a dolog.
-

bandi0000
nagyúr
-

zek47
csendes tag
válasz
sztanozs
#4154
üzenetére
Köszönöm!
Egyébként nem akarok beavatkozni a gazdaprogram és az adatbázis kapcsolatába, csak elszedni az adatokat (könyvjelzők, logok stb.), majd a gazdaprogrammal törölni a listát. Journal fájl van, akkor is, ha a program nem fut. Lehet azért, mert az Android automatikusan indítja a programot, és sosem állítja le teljesen.
-
válasz
sztanozs
#4146
üzenetére
megnéztem rendesebben a kérdést, és nem látom értelmét bemásolni az eredményt.
az explain és az explain analyze egymáshoz képest fordított eredményt hoz. az explain szerint a not in 4x gyorsabb, az explain analyze szerint meg az exists gyorsabb.ez elég fura, mert elvileg az exists-hez le kellene futtatni a subselectet minden sorhoz, ami a fő selectben van. egyébként pedig a postgresql-nél ez a probléma régebben felmerült, úgy látom, hogy a query plannere fel van rá készítve és jó eredményt hoz.
-
válasz
sztanozs
#4141
üzenetére
explain select * from customer where id not in (select customer_id from <anonimizálva>);
QUERY PLAN
---------------------------------------------------------------------------------
Seq Scan on customer (cost=1174.57..1372.72 rows=3366 width=243)
Filter: (NOT (hashed SubPlan 1))
SubPlan 1
-> Hash Join (cost=395.85..1134.83 rows=15895 width=4) -
kezdosql
tag
válasz
sztanozs
#4057
üzenetére
Date-vel vagy evet, vagy pontos napot kell megadni.
Az esemeny ev/ho szovegben szerepel idoszak cimen, karakteresen tol-ig savonkent, numerikus hivatkozassal a sorbaallitashoz.
Utobbival az esemeny megadhato.
Na de hogyan oldod meg, hogy a vizsgalt idoszak az par honap, es az esemeny kozben jelentkezik?
Aranyositod az idoszakot napra?
Akkor a savos idoszakokat at kell irni from-to datum mezokre, es ahhoz tartozhat a numerikus mezzo? -
-

mckay
aktív tag
válasz
sztanozs
#3509
üzenetére
Sziasztok!
A legnagyobb tisztelettel szeretnék kérni pár linket, ha egyáltalán tudtok ilyesmit.
Meg kéne értenem, hogy mit és hogy csinálhatunk alap szinten egy SQL adatbázissal!Tudom, ez most nagyon mókásan hangzik, hiszen ez egy külön szakma. És én semmit nem tudok belőle, soha nem is használtam, soha egy lekérdezést nem csináltam. Mert hardveres vagyok.

De most kitalálták a munkahelyemen, hogy apróbb (kinek apró?...) SQL-megoldást majd a "kisebbik rendszergazda" is meg tud csinálni. Pontosabban azt találták ki, hogy az eddig ilyeneket mókoló senior rendszergazda majd jól bevezeti a kisebbiket, azaz, és már a jövő héttől kezdheti az okosításomat.
Ez mind jó és szép, de nem vagyunk igazán olyan viszonyban, hogy megkérjem, hogy úgy mutasson alapinfókat, mintha csak Juliska lennék az X osztályról. Fel kéne készülnöm, hogy legalább az alapfogalmakkal, alapfogásokkal tisztában legyek az első találkozásunkra. Például hogy milyen prograra kéne kattintani a start menüben...
És végülis szívesen segíteném az ő munkáját, miért is ne, de hát hol kezdjek hozzá?Tudnátok ilyen láma-beavató oldalakat/pdf-eket/könyveket javasolni?
Üdv és köszi.
-

GreenIT
tag
válasz
sztanozs
#3483
üzenetére
Erdekes, hogy folyamatosan az ellenkezojet irod annak, amit en irtam, de mindig ram hivatkozva.

Probald meg az alabbit szo-ta-gol-va olvasni, hatha segit:
Kiprobaltam a Sugarcrm CE verziojat, es nem mukodik.
Pontosabban szepen mukodik, amig nem akarsz bele adatokat irni.
Attol kezdve az adatok egy reszet lathatod, csak nem tudod elerni.
Erdekes megoldas. -
GreenIT
tag
válasz
sztanozs
#3464
üzenetére
Aha, magyar SI szabvany.
Az elsonel szerintem egyertelmu, hogy a tanulasnal a helyes gondolkodasmod elsajatitasa a legfontosabb, de ti valamiert azonnal ugy ertelmezitek, hogy jon valaki, aki el akarja happolni a ti ugyfeleiteket.
Erdekes.A masik eseteben ugy latom, ingyenes CRM-ek nem mukodnek, csak csalinak szolgalnak, hogy "vedd meg a fizetoset, az is csak azert fog mukodni, mert mi folyamatosan azon dolgozunk, hogy valahogy mukodokepes maradjon."
Amugy fogalmam sincs, hogy ti hogyan csinaltok penzt ingyenes CRM-bol, ugyhogy ez is magyar SI szabvanykategoria. -

1eske
tag
válasz
sztanozs
#3191
üzenetére
Ez is mindent visszaad.

Így rakom bele a DB-be a rekordokat:
PreparedStatement pstmt = conn.prepareStatement("INSERT INTO t1 (dt,val1,val2) VALUES (?,?,?)");
pstmt.setTimestamp(1, java.sql.Timestamp.valueOf(java.time.LocalDateTime.now()) );
pstmt.setString(2, v1);
pstmt.setString(3, v2 );
pstmt.executeUpdate();Lehet, hogy nem timestamp-pel kéne berakni?



 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed 



![;]](http://cdn.rios.hu/dl/s/v1.gif)

















 Na azért ez így hasít...
Na azért ez így hasít...






























Új hozzászólás Aktív témák
- TCL LCD és LED TV-k
- Elektromos autók - motorok
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- Outlaws + Handful of Missions: Remaster teszt
- Kicsomagoljuk és bemutatjuk a Poco F8 Ultrát
- Bemutatkozott a Poco X7 és X7 Pro
- Samsung Galaxy A52s 5G - jó S-tehetség
- LEGO klub
- One otthoni szolgáltatások (TV, internet, telefon)
- Autós topik
- További aktív témák...
- Szép! Lenovo Thinkpad T14s G2 Üzleti "Golyóálló" Laptop 14" -50% i7-1185G7 4Mag 16GB/1TB FHD IPS
- Szép! Lenovo Thinkpad T14s G2 Üzleti "Golyóálló" Laptop 14" -50% i7-1185G7 4Mag 16GB/512GB FHD IPS
- Dell PowerEdge T110 II PC, Xeon E3-1220 v2 CPU, 32 GB DDR3 RAM, 2 x 1 TB SAS HDD
- Lenovo Tab M10 HD 64GB, Kártyafüggetlen, 1 Év Garanciával
- HyperX Fury DDR4 - 3200 - CL16 - 16GB RAM (8GB x 2) RGB
- ÁRGARANCIA!Épített KomPhone Ryzen 5 4500 16/32/64GB RAM RTX 3050 6GB GAMER PC termékbeszámítással
- Microsoft Surface Pro 7+ - Újszerű, billentyűzettel és ceruzával
- GeForce RTX 2060 (OEM HP) Garanciával
- Ultimate előfizetés akár 4166 Ft/hó áron! Azonnali, automatizált aktiválással, csak Nálam!
- Készpénzes / Utalásos Videokártya és Hardver felvásárlás! Személyesen vagy Postával!
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi