Hirdetés
- Luck Dragon: Asszociációs játék. :)
- Graphics: Telefonvásárlási kálváriám....avagy clickbait cím: Horror a hardveraprón
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Lalikiraly: Kinek milyen setupja van?
- Lalikiraly: Mercis kalandok - Huszonnyolcadik rész - Az újrakezdés
- Luck Dragon: Alza kuponok – aktuális kedvezmények, tippek és tapasztalatok (külön igényre)
- sziku69: Fűzzük össze a szavakat :)
- Parci: Milyen mosógépet vegyek?
- sziku69: Szólánc.
- bambano: Bambanő háza tája
-

LOGOUT
A Microsoft Excel topic célja segítséget kérni és nyújtani Excellel kapcsolatos problémákra.
Kérdés felvetése előtt olvasd el, ha még nem tetted.

Új hozzászólás Aktív témák
-

ny.janos
tag
válasz
 macilaci78
#54274
üzenetére
macilaci78
#54274
üzenetére
Szia!
Nézd meg ezt a leírást. -
ny.janos
tag
válasz
 Kovbob
#53711
üzenetére
Kovbob
#53711
üzenetére
Szia!
A raktárkészletet tartalmazó táblázatodat mindig ugyanazon a helyen tárold (ahogy írod, csak a dátum változik benne).
PQ-vel olvasd be a mappából a raktárkészleteket tartalmazó legfrissebb fájlt (a legegyszerűbb az, ha a mappában nem szerepel csak a legfrissebb fájlod) a másik fájlodba.
Betöltés után a függvényben ebben a táblázatban és nem a másik fájlodban keresel.
Beállíthatod, hogy a lekérdezés megnyitásra frissüljön, sőt azt is, hogy milyen időközönként frissüljön újra automatikusan. -
ny.janos
tag
Szia!
Egy másik lehetséges megoldás (mivel az indirekt függvény VOLATILE tulajdonsággal rendelkezik, ezért lassíthatja a működést):
=INDEX($A$2:$A$21;SOROK($A$2:A2)*3-2)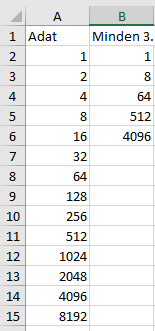
Az utolsó előtti paraméter (3) azt adja meg, hogy minden hányadik sor elemét kéred, a -2 pedig attól függően szükséges, hogy a 3. elem egyben az-e amit első eredményként kapni szeretnél, vagy azt megelőző sorban szereplő adatra van-e szükséged. A képletben az első sor eredményével kezdődik a felsorolás (3-2 = 1).
-
ny.janos
tag
Szia Mutt!
Egy hónapokkal ezelőtti esetre térnék vissza, amibe most újra belefutottam, ezért végeztem egy kis kutakodást, hogy mikor és hogyan jön elő a hiba, illetve milyen esetekben nem.
Az itt linkelt fájlban leírtam az információkat. Nem tudom, hogy neked mennyire hasznos, esetleg ha van időd hibabejelentéssel foglalkozni (nekem úgysem menne az angoltudás hiányában), akkor esetleg segíthet.
Üdv.
-
ny.janos
tag
válasz
 bozsozso
#53676
üzenetére
bozsozso
#53676
üzenetére
Az a kérdés fogalmazódott még meg bennem, hogy vajon a már helyes formátumra alakított adataidat mire használod, illetve a csv fájlod mindig az összes releváns adatot tartalmazza-e, vagy azok esetleg mindig új (pl. napi, heti vagy havi) adatokat tartalmaznak? Ezekkel önállóan dolgozol, vagy ezek mind ugyanannak az adathalmaznak a részei lesznek-e, amivel utána valamilyen műveletet végzel / statisztikát gyártasz belőle?
Ha nem csak egyetlen fájlból nyert adatokkal dolgozol a későbbiekben, akkor a PQ nyújtotta lehetőségeket nem csak az adatok átalakításában kellene kihasználnod! -
ny.janos
tag
válasz
bozsozso
#53674
üzenetére
...Mindegy akkor megcsinálom mindig az átalakítást...
Ezt most nem egészen értem. A PQ-nek pont az az előnye, hogy ha a forrásadataid struktúrája azonos, akkor csak egyszer kell az átalakítást elvégezned, utána ha a csv fájlod megváltozik, elegendő frissítened a lekérdezést, az átalakítás automatikusan megtörténik.
Alapesetben annyit kell tenned, hogy a csv fájlt felülírod az újjal, hiszen ugyanabban a mappában fogja keresni ugynazon vevű fájlt a lekérdezésed.
Ha akadálya lenne annak, hogy ugyanabba a mappába / ugyanazzal a fájlnévvel mentsd el a csv fájlodat, akkor paraméterként javasolt felvenned az elérési utat és a fájlnevet és azt hivatkozni meg a lekérdezésben (ez azonban már alaposabb PQ ismeretet feltételez, menüszalagról ezt nem fogod tudni megoldani). -
ny.janos
tag
válasz
bozsozso
#53662
üzenetére
Szia!
Én nem bántanám az excel speciális rendszerbeállításait, ehelyett ha nem magyar formátumban vannak a számok, akkor a PQ átalakítás során az érintett oszlop fejlécében a formátum ikonra kattintasz, majd a legutolsó pontban (nyelvterület használata) kiválasztod a tizedes törtet illetve a megfelelő nyelvterületet (leggyakrabban GB vagy USA).
Én munkahelyi környezetben azzal szoktam még találkozni, hogy a vállaltirányítási rendszerben a felhasználó nem állítja át a személyes beállításokban a szám és dátumformátumot, ezért merül fel utána az igény az átalakításra. Azonban ha már a vállalatirányítási rendszerben megfelelő formátumot állít be a dolgozó, akkor nincs szükség a PQ-vel történő átalakításra.

-
ny.janos
tag
Power Query ismét.
A minap olvastam arról az exceloffthegrid.com oldalon (néha az alapokat sem árt átvenni, főleg ha innen-onnan szedtem össze a PQ tudásomat, nem szervezett oktatás keretében, így sok a hiányosságom), hogy az adatok betöltésekor – főként ha sok adat betöltéséről van szó – érdemes bejelölni az Adat felvétele az adatmodellbe jelölőnégyzetet. Eddig annyit tudtam erről, hogy PowerPivot esetén ven szükség rá (erről Mutt már többször is írt a fórumban - de én magam még sosem használtam). Viszont akkor is jelölhető, ha nem használunk Power Pivotot és értelme is lehet a használatnak.
Aztán pár nappal később láttam egy videót (BCTI), mely a PQ sorbarendezésének néha érthetetlen voltáról értekezett.
2016-os excelben nem tudom egyértelműen előidézni azt ami a videóban látható, ugyanakkor korábban már nem egyszer találkoztam azzal, hogy az adatok sorrendje megváltozott.
@Mutt: neked vannak információid a fentiekről? Van egyáltalán összefüggés az adatmodellbe töltés és a sorbarendezés között? Vagy az adatmodellbe töltéstől független a sorbarendezési kérdés és csak én kombináltam össze fejben, hogy azért csökken a fájl mérete az adatmodellbe töltés használatával (ahogy Mark írta), mert az adattárolás kevesebb adattal történik, ahogy az a BCTI videójában látható? Köszi.
-
ny.janos
tag
válasz
 andreas49
#53601
üzenetére
andreas49
#53601
üzenetére
Szia!
Az MNB oldaláról történő árfolyamkereséseket én meguntam egyszer, ezért PQ-t akalmazok a lekérdezéshez.
Az excel-bazison van egy ingyenes anyag erről.Én az alábbi kódot alkalmazom (értelemszerűen ha más időszaki árfolyamokra vagy kíváncsi, vagy más devizanemek is kellenek, akkor módosítható).
let
Forrás = Web.Page(Web.Contents("https://www.mnb.hu/arfolyam-tablazat?deviza=rbCustom&devizaSelected=HUF&datefrom=2020.01.01.&datetill=2029.12.31.&order=1&customdeviza%5B%5D=CHF&customdeviza%5B%5D=EUR&customdeviza%5B%5D=USD&customdeviza%5B%5D=GBP&customdeviza%5B%5D=RUB")),
Data0 = Forrás{0}[Data],
#"Oszlopok átnevezve" = Table.RenameColumns(Data0,{{"CHF svájci frank 1", "CHF"}, {"EUR euro 1", "EUR"}, {"GBP angol font 1", "GBP"}, {"RUB orosz rubel 1", "RUB"}, {"USD USA dollár 1", "USD"}}),
#"Típus módosítva" = Table.TransformColumnTypes(#"Oszlopok átnevezve",{{"", type date}, {"CHF", type number}, {"EUR", type number}, {"GBP", type number}, {"RUB", type number}, {"USD", type number}}),
#"Oszlopok átnevezve1" = Table.RenameColumns(#"Típus módosítva",{{"", "Dátum"}})
in
#"Oszlopok átnevezve1"Üdv.
-
ny.janos
tag
Szia Mutt!
Nekem ma bela85 kérésére írt kódot pl. át kellett írnom, és alkalmaznom kellett benne az általad javasolt List.Accumulate függvényt a számlaszámok kiszedésére mert a 2016-os verzió még nem ismeri a Splitter.SplitTextByCharacterTransition függvényt (2019 igen).
De ugyancsak hibát írt a 2016-os verzió a Table.AddIndexColumn fügvényre , mert míg a 2019-es verzióban 5 paramétert lehetséges megani, a 2016-os verzió hibát dobott rá, hogy 2-4 paraméter adható meg.
, mert míg a 2019-es verzióban 5 paramétert lehetséges megani, a 2016-os verzió hibát dobott rá, hogy 2-4 paraméter adható meg. -
ny.janos
tag
Nem tudom mire gondoltál a megoldás menetének ismertetése kapcsán, de olyan részletességgel, ahogy Mutt szokott itt publikálni sajnos nem lesz időm közzétenni a lépéseket, de úgy hiszem, hogy nem is erre van szükséged.
A fájlt itt letöltheted és tanulmányozhatod a lépéseket.A felosztás alapja az oszlopfelosztás számjegyről nem számjegyre és fordítva lépés, és ehhez egy elő és utótag beszúrása, hogy biztosan ne kezdődjön a szöveg számmal és ne is végződjön arra.
A sorok csoportosítása után pedig egyéni lépést követően a két megelőző lépés adatai vannak összesítve úgy, hogy az M kódban végeztem módosítást a megfelelő lépés meghivatkozásával. A csoportosításban pedig a már említett trükköt használtam, mait Mark-tól tanultam. Ha valamely lépésben további segítség kell, írj nyugodtan, akár PM-ben is.Köszönöm a javaslatot, elmentem magamnak a megoldást. Megtisztelő, hogy ilyen megoldásokat osztasz meg velem, de be kell valljam, hogy túlbecsülöd a képességeimet az általad javasolt megoldások / kódok általam történő felfogását illetően.

A 2016-os excel verzióhoz javasolt megoldásodból lemaradt, hogy tömbképlet, azaz régi excel verziókban CSE-el kell lezárni.
(A képletet még meg kell fejtenem, mert még nem jutott rá időm.) -
ny.janos
tag
válasz
 Fire/SOUL/CD
#53562
üzenetére
Fire/SOUL/CD
#53562
üzenetére
Pedig érdemes lehet és ezt nem én mondom
"How difficult is Power Query to learn?
So, how difficult is it to learn Power Query? If you are thinking that you need to be a programmer, or at least an Excel expert, you would be wrong. Power Query has an easy-to-use interface which is designed for everyday users.
There is a bit of a learning curve, but most of that is learning what each button does.
It takes years to become competent in VBA macros, it takes months to become competent in Power Query. Since 80% of what we did with VBA can be achieved with Power Query, then that is the place to focus.
If you want to go deep into Power Query, there is a programming language called “M” which you could learn. But you can harness 99% of the power without needing it at all."A megoldás egyébként (ha még jól emlékszem) egyetlen lépés kivételével a menüszalagról elérhető parancsokkal történt. Az utolsó 3 oszlopba az egyes azonosítók összevonásához kell az M kódba kézzel belenyúlni, melynek megoldását én magam Mark How to use Power Query Group By to summarize data bejegyzéséből tanultam.
-
ny.janos
tag
válasz
 bela85
#53559
üzenetére
bela85
#53559
üzenetére
Még mielőtt elfelejteném: a számlaszámokon kívül más szám nem lehet a cellában, mert akkor a kód nem fog megfelelően működni!
Az előző bejegyzésemben írt eredményhez az alábbit kellene tenned (a megoldást 2019-es excelben készítettem ,csak remélni tudom, hogy a PQ függvényei működnek a 2016-os verzióban is).
1. A fájlod adott munkalapjának egyetlen oszlopát (melyben az adataid vannak) alakítsd táblázattá, az oszlop fejlécét írd át Adat-ra, a táblázat neve pedig Táblázat1 legyen.
2. A táblázat bármely részén állva az Adatok menü Táblázatból vagy tartományból pontját válaszd.
3. A PQ felugró menüjének kezdőlapján balra fent rákattints a Speciális szerkesztő-re, majd kijelölve az ott található kódot, az alábbira cseréld:let
Forrás = Excel.CurrentWorkbook(){[Name="Táblázat1"]}[Content],
#"Indexoszlop hozzáadva" = Table.AddIndexColumn(Forrás, "Index", 1, 1, Int64.Type),
#"Érték felülírva" = Table.ReplaceValue(#"Indexoszlop hozzáadva","-","",Replacer.ReplaceText,{"Adat"}),
#"Érték felülírva1" = Table.ReplaceValue(#"Érték felülírva"," ","a",Replacer.ReplaceText,{"Adat"}),
#"Hozzáadott előtag" = Table.TransformColumns(#"Érték felülírva1", {{"Adat", each "a" & _, type text}}),
#"Hozzáadott utótag" = Table.TransformColumns(#"Hozzáadott előtag", {{"Adat", each _ & "a", type text}}),
#"Oszlop felosztása karakterátalakítás alapján2" = Table.SplitColumn(#"Hozzáadott utótag", "Adat", Splitter.SplitTextByCharacterTransition((c) => not List.Contains({"0".."9"}, c), {"0".."9"}), {"Adat.1", "Adat.2", "Adat.3", "Adat.4"}),
#"Oszlopok eltávolítva2" = Table.RemoveColumns(#"Oszlop felosztása karakterátalakítás alapján2",{"Adat.1"}),
#"Oszlop felosztása karakterátalakítás alapján3" = Table.SplitColumn(#"Oszlopok eltávolítva2", "Adat.2", Splitter.SplitTextByCharacterTransition({"0".."9"}, (c) => not List.Contains({"0".."9"}, c)), {"Adat.2.1", "Adat.2.2"}),
#"Oszlop felosztása karakterátalakítás alapján4" = Table.SplitColumn(#"Oszlop felosztása karakterátalakítás alapján3", "Adat.3", Splitter.SplitTextByCharacterTransition({"0".."9"}, (c) => not List.Contains({"0".."9"}, c)), {"Adat.3.1", "Adat.3.2"}),
#"Oszlop felosztása karakterátalakítás alapján5" = Table.SplitColumn(#"Oszlop felosztása karakterátalakítás alapján4", "Adat.4", Splitter.SplitTextByCharacterTransition({"0".."9"}, (c) => not List.Contains({"0".."9"}, c)), {"Adat.4.1", "Adat.4.2"}),
#"Oszlopok eltávolítva3" = Table.RemoveColumns(#"Oszlop felosztása karakterátalakítás alapján5",{"Adat.2.2", "Adat.3.2", "Adat.4.2"}),
#"Hozzáadott utótag2" = Table.TransformColumns(#"Oszlopok eltávolítva3", {{"Adat.2.1", each _ & "00000000", type text}}),
#"Hozzáadott utótag3" = Table.TransformColumns(#"Hozzáadott utótag2", {{"Adat.3.1", each _ & "00000000", type text}}),
#"Hozzáadott utótag4" = Table.TransformColumns(#"Hozzáadott utótag3", {{"Adat.4.1", each _ & "00000000", type text}}),
#"Többi oszlop elemi értékekre bontva" = Table.UnpivotOtherColumns(#"Hozzáadott utótag4", {"Index"}, "Attribútum", "Érték"),
#"Oszlopok eltávolítva4" = Table.RemoveColumns(#"Többi oszlop elemi értékekre bontva",{"Attribútum"}),
#"Kinyert első karakterek1" = Table.TransformColumns(#"Oszlopok eltávolítva4", {{"Érték", each Text.Start(_, 24), type text}}),
#"Típus módosítva" = Table.TransformColumnTypes(#"Kinyert első karakterek1",{{"Index", type text}}),
#"Oszlop felosztása pozíció alapján" = Table.SplitColumn(#"Típus módosítva", "Érték", Splitter.SplitTextByRepeatedLengths(8), {"Érték.1", "Érték.2", "Érték.3"}),
#"Oszlopok egyesítve" = Table.CombineColumns(#"Oszlop felosztása pozíció alapján",{"Érték.1", "Érték.2", "Érték.3"},Combiner.CombineTextByDelimiter("-", QuoteStyle.None),"Érték"),
#"Sorok csoportosítva1" = Table.Group(#"Oszlopok egyesítve", {"Érték"}, {{"Előfordulás száma", each Table.RowCount(_), Int64.Type}, {"Indexsorok száma", each Text.Combine([Index],","), type nullable text}}),
Egyéni1 = #"Oszlopok egyesítve",
#"Egyesített lekérdezések" = Table.NestedJoin(Egyéni1, {"Érték"}, #"Sorok csoportosítva1", {"Érték"}, "Egyéni1", JoinKind.LeftOuter),
#"Kibontott Egyéni1" = Table.ExpandTableColumn(#"Egyesített lekérdezések", "Egyéni1", {"Előfordulás száma", "Indexsorok száma"}, {"Előfordulás száma", "Indexsorok száma"}),
#"Oszlopok átnevezve" = Table.RenameColumns(#"Kibontott Egyéni1",{{"Index", "Sorszám"}}),
#"Típus módosítva1" = Table.TransformColumnTypes(#"Oszlopok átnevezve",{{"Sorszám", Int64.Type}, {"Előfordulás száma", type text}}),
#"Sorok rendezve" = Table.Sort(#"Típus módosítva1",{{"Sorszám", Order.Ascending}}),
#"Típus módosítva2" = Table.TransformColumnTypes(#"Sorok rendezve",{{"Előfordulás száma", type text}}),
#"Sorok csoportosítva" = Table.Group(#"Típus módosítva2", {"Sorszám"}, {{"Számlaszámok", each Text.Combine([Érték]," ; "), type text}, {"Előfordulások száma számlaszámonként", each Text.Combine([Előfordulás száma]," ; "), type nullable number}, {"Indexsorok száma számlaszámonként", each Text.Combine([Indexsorok száma]," ; "), type nullable text}}),
#"Típus módosítva3" = Table.TransformColumnTypes(#"Sorok csoportosítva",{{"Előfordulások száma számlaszámonként", type text}})
in
#"Típus módosítva3"4. A menüben a Bezárás és betöltés - Bezárás és betöltés adott elyre parancsot válaszd, majd a táblázatot kijelölve adj meg egy olyan cellát a munkalapodon, ahol már nincs adat, amit felülírnál. Ugyanabba a sorba tedd, ahol a táblázatod fejadatai vannak.
-
ny.janos
tag
válasz
bela85
#53557
üzenetére
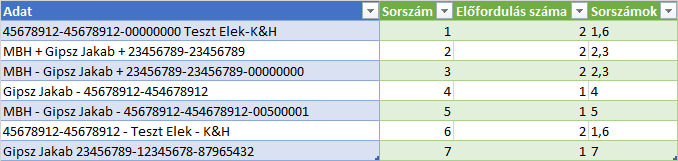
Nos, ha vannak olyan cellák, amelyben több számlaszám is szerepel, akkor már halmozódnak a problémák, azt nem tudom, hogy PQ-vel meg lehetne-e oldani (illetve feltehetően igen, de ahhoz lehet, hogy már Mutt tudása kell).
Abban az esetben, ha csak egyetlen számlaszám szerepel egy cellában és biztosan nincs benne más szám a számlaszám 16 vagy 24 karakterén túl, úgy működik az általam javasolt megoldás a 8 db nullával történő kiegészítéssel, ahogy azt Fire/SOUL/CD is írta.
-
ny.janos
tag
válasz
Fire/SOUL/CD
#53552
üzenetére
Bocs, de ezt most te nem értelmezted megfelelően.
A korábbi kérdésem tartalmazta, hogy csak az első 16 karakter alapján kell az összehasonlítás? Ezt feltételezve készült a megoldás is. Ha egy 16 számjegyként megadott bankszámlaszámot hasonlítunk össze egy 24 számjegyből álló bankszámlaszámmal, és az első 16 karakter azonos, akkor az ugyanazt a számlaszámot jelenti (attól, hogy kiírjuk a nyolc darab nullát, vagy nem, attól az nem lesz másik bankszámlaszám). -
-
ny.janos
tag
válasz
bela85
#53542
üzenetére
Szia!
Fire/SOUL/CD kérdésein túl pár további:
5. Jól értem, hogy valójában ismétlődéseket szeretnél keresni számlaszám alapján, azaz tényleg az oszlopon belüli azonosságokat szeretnéd megjelölni (pl. színnel) a számlaszám alapján (oszlopon belül mindkettő vagy több cellát)?
6. A cellában a számlaszám 16 vagy 24 karakterén kívül előfordulhat, hogy más szám is szerepel?
7. Az azonosságot a számlaszám hány karaktere alapján szeretnéd vizsgálni? Elegendő az első 16 karakter? Vagy ha szerepel 2x8 és 3x8 formátumban is, azt ne mutassa azonosnak?A legjobb lenne, ha fiktív adatokkal tudnál egy több sort tartalmazó mintát mutatni.
-
ny.janos
tag
Sziasztok!
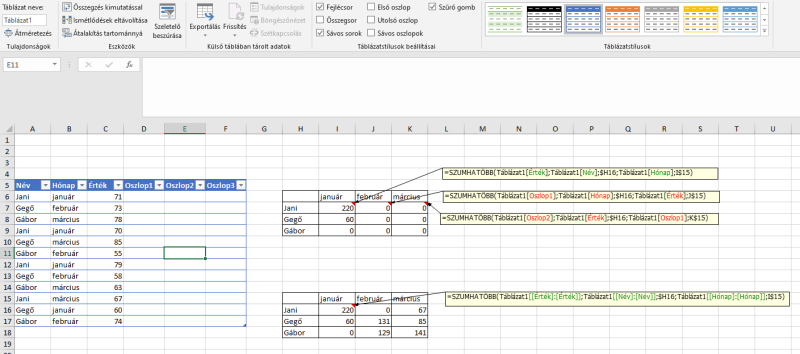
Nem tartom kizártnak, hogy csak én nem ismertem, miközben egy köztudott dologról van szó, azonban én már többször szenvedtem azzal, hogy amennyiben egy képletben nem tartományra, hanem táblázatra hivatkoztam, akkor azt a képletet jobbra vagy balra másolva a táblázat oszlopai ugyanúgy megváltoztak, mint ha relatív hivatkozás történt volna egy tartományra. Emiatt táblázatra hivatkozva is módosítottam ilyenkor a képleteket, és a táblázat ellenére tartományként hivatkoztam meg az oszlopokat (mert ugye a táblázat hivatkozásában a $ jel nem használható).

Ma azonban Mark (Excel Off The Grid) egyik videójából sikerült megvilágosodnom
, hogy a táblázatoszlopokra vonatkozó hivatkozások hogyan tehetők abszolút hivatkozássá. Gondoltam megosztom, hátha mégsem csak én voltam tudatlan eddig. (Balra a táblázat, amire hivatkozok, jobbra fent a normál hivatkozás, amelyet jobbra másolva az oszlopok nem várt módon megváltoznak, jobbra lent pedig a megoldás a problémára.)
Üdv.
-
ny.janos
tag
Szia!
Köszönöm, hogy ismét foglalkoztál a kérdésemmel.
1. Nekem a 2.134.7447.1 verziójú Power BI Desktop is ugyanazt a hibás eredményt hozza.
2. Erre a lehetőségre én is gondoltam, de mivel én egyenként cseréltem volna a betűket és nem is lesz garantáltan jó az eredmény így sem, valamint esetemben nem is nagy a jelentősége annak, hogy nem lesz jó a sorrend, így hagytam a fenébe. Köszönöm szépen a kódot, ínségesebb időkre esetleg még jó lehet.
Külön köszönet, hogy bejelentetted a hibát. Hátha javítják egyszer.Üdv.
-
ny.janos
tag
válasz
 Fferi50
#53240
üzenetére
Fferi50
#53240
üzenetére
A linken látható képen szereplő mindhárom mérkőzés ugyanannak a PQ betöltésnek az eredménye és egyetlen táblázat. A táblázat pedig excelben csak teljes egészében rendezhető, annak egy részét hiába jelölöd ki, amint a rendezésre kattintasz, kijelöli a teljes táblázatot.
-
ny.janos
tag
válasz
Fferi50
#53226
üzenetére
Szia!
No igen, mikor csak egy része ismert a kérdésnek, akkor jogosnak tűnik a felvetésed. Nem akarok hosszas okfejtésbe kezdeni, de csak annyiban függ össze az 1-4 és az 5-8 oszlop, hogy azok az adott fordulóban egymással játszó két csapat eredményeit tartalmazzák. De tényleges összefüggés csak külön-külön van 4 oszloponként. Ráadásul az adott fordulóban lejátszott valamennyi mérkőzés megjelenik egymás alatt, így az excel sorba rendezés csak az adott résztartomány kijelölését követő sorba-rendezéssel oldható meg esetemben, amit szerettem volna elkerülni.
Itt látni fogod miről van szó, és így talán nem lesz annyira furcsa a kérdésem (az eredmények – és a versenyzők – a versenyző-csapat hozzárendelésből, fordulóbeli párosításból és a versenyzők egyéni eredményeiből számolódnak és kerülnek a helyükre).
Mindenesetre furcsa, hogy bár van magyar nyelvterületi beállítás a PQ-ben, az ezek szerint az ABC szerinti rendezéssel nem bír megbirkózni. A hab a tortán a példámban, hogy a Szakáts úgy is megelőzi a PQ szerint névsorban a Séllei-t, hogy az S és az Sz esetében tudja a PQ, hogy az S van a betűrendben előrébb. De amint az első karakter után egy ékezetes karakter kerül, akkor már az Sz-el kezdődő nevet teszi előrébb. Miért? Abszolút felfoghatatlan számomra…
-
ny.janos
tag
válasz
Fferi50
#53224
üzenetére
Az az igazság, hogy a táblában, ami excelbe áterül PQ-ból, 8 oszlop van, de olyan formában, hogy ez első 4 oszlop az első oszlop alapján, míg az 5-8 oszlop az 5. oszlop alapján van rendezve. Ahhoz, hogy excelben rendezzem, külön kellene szednem az eredményt két táblára, amit nem szeretnék, lévén, hogy elég sok meló van ebben a formátumban. Mivel 4 sor van csak, legfeljebb az lesz, hogy kézzel átrendezem, mielőtt véglegesítem.
Ps. Inkább vegyes, de az a valószínű, hogy elfelejtettem rendezni, mielőtt a képet elmentettem. -
ny.janos
tag
válasz
ny.janos
#53053
üzenetére
Bár a kérdésem korábban már megválaszolásra került itt a fórumban, ma pont ezen problémát taglaló videóba futottam bele, ezért gondoltam érdekességképpen megosztom (bár nem tudom hányan foglalkoznak a jelenlévők közül behatóbban a PQ-vel, Muttnak pedig úgysem fogok újat mondani).
-
ny.janos
tag
Sziasztok!
Az elmúlt időszakban nem volt időm foglalkozni a válaszokkal, csak most tudtam rá időt fordítani.
Köszönöm a megoldási javaslatokat mind Fferi50-nek (#53054), mind Mutt-nak (#53061). Mivel olyan megoldást kerestem, amely a PQ M kódban „egyszerűen” alkalmazható, ezért Mutt megoldását jegyzem fel magamnak. (Makróban nem vagyok otthon és nem is szeretnék azt alkalmazni, mert később nem tudok hozzászagolni, ha valami változtatásra lenne szükség. Ettől függetlenül a javaslatot köszönöm.)
Valahogy éreztem én, hogy Mutt lesz az, aki tuti fog megoldással szolgálni és nem is tévedtem. Ha egyszer a tizedét tudni fogom PQ-ben, mint ő, akkor nyulat lehet velem fogatni örömömben.
-
ny.janos
tag
Sziasztok!
Power Q-vel kapcsolatban kérdeznék ismét (M kód).
Van egy teke bajnoksághoz készült táblázatom, amelyben az induló csapatok számától függően PQ-vel készül egy táblázat, melyben vezetve vannak a versenyzők adott fordulóban elért eredményei. Minden versenyző esetében valamennyi fordulóban elért eredmény külön sorban szerepel az alábbiak szerint.
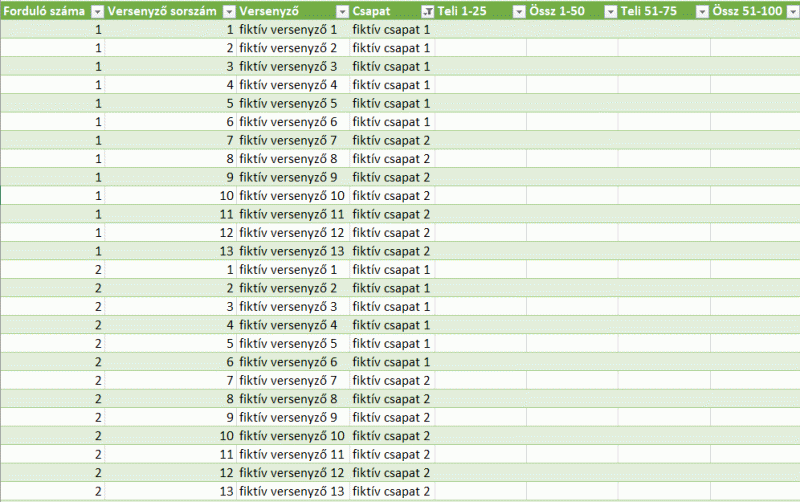
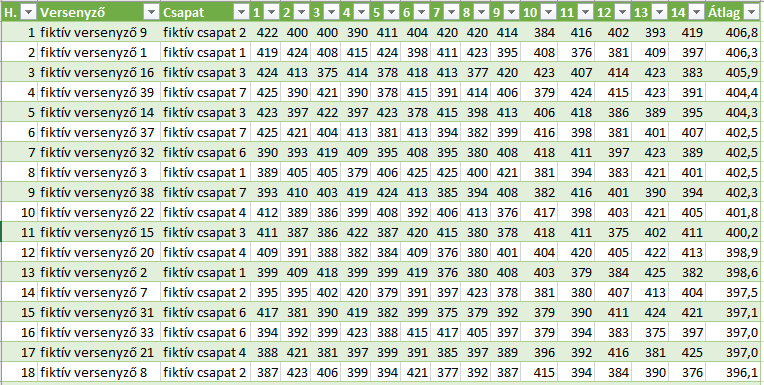
Az versenyzők egyéni eredményeiből készül egy egyéni tabella az előbbi táblázat oszlopainak elforgatásával. Az összes (már lejátszott) fordulóban elért eredményből számítok ezt követően egy átlagot az utolsó oszlopban, majd erre az oszlopra történik a sorok csökkenő értékű rendezése (ld. az alábbi képernyőképet).
A megoldandó probléma az, hogy a csapatok és amiatt a fordulók száma változhat, és én azt szeretném, hogy az M kódban ne kelljen emiatt módosítani. Viszont az átlag számításához az M kódba az oszlopok neve keményen kódolva kerül (a példában 7 csapat és így 14 forduló van).= Table.AddColumn(#"Oszlop elforgatva", "Átlag", each List.Average({[1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14]}), type number)Van mód arra, hogy a fenti M kódban az oszlopok nevei dinamikusan változzanak attól függően, hogy hány forduló és így hány oszlop van, amiből átlagot kell számolni? (Csökkenhet, vagy nőhet is az oszlopok száma.)
A kérdésem a konkrét fenti kód dinamikussá tételére vonatkozik (mert nem hagy nyugodni, hogy meg lehet-e valósítani).
Alternatív megoldást már találtam: az átlagszámítás az oszlopok elforgatását megelőző, a sorok csoportosításával történő elvégzésével megelőzhető a probléma, és az oszlopok elforgatását követően egyesíteni tudom azzal a számított átlagot. -
ny.janos
tag
Szia Mutt!
Nos mivel annyira közel sem vagyok otthon a PQ-ben, mint te magad, ezért végül kerülő megoldásként azt csináltam, hogy mind a jobban, mind a gyengébben teljesítő játékosok eredményét betöltöttem munkalapra, majd onnan újra beolvastam. Így sikerült elérnem azt, amit te sokkal egyszerűbb és nagyszerűbb módon oldottál meg. Le is fogom cserélni a bonyolult és időigényesebb megoldást az általad javasoltra.Nagyon köszönöm, hogy foglalkoztál a felvetésemmel, érdemes lesz megjegyeznem a módszert. Az M kódot külön köszönöm, anélkül nem fogtam fel, hogy miről írtál, de azzal igen.
Sokáig azt hittem, hogy tuti én rontottam el valamit, de ezúttal megerősítést kaptam tőled, hogy nem én szerencsétlenkedtem, hanem tényleg nem várt működés lépett fel.
A legbosszantóbb az egészben, hogy van egy olyan megoldandó feladatrészem is, ahol az egymás mellett figyelembeveendő eredmény nem fix kettő versenyzőtől, hanem többtől jön össze úgy, hogy csak a kettő legjobb eredmény veendő figyelembe. Az eredeti módszerem szerint hiába távolítottam el a 2-nél nagyobb értékeket a sorba rendezés után, a kibontást követően azt a harmadik legjobb eredményt is sikerül kibontani, amit elvileg korábbi lépésben már kizártam. Szóval valami nagyon nem működik jól.
-
ny.janos
tag
Sziasztok!
Power Query kérdés (MS Office Professional Plus 2019):
A feladat egy teke versenyen egy oszlopban azonos számkóddal egymáshoz rendelt párosok eredményeinek egymás mellé rendelése oly módon, hogy előbb az eredményesebb játékos eredményét, majd a kevésbé eredményes játékos gurított értékét szeretném látni. Nem tartom magam kezdőnek a PQ-ben, de fogalmam nincs, hogy miért csinálja azt, amit.A párosok összerendelése megtörtént, megvan, hogy ki az eredményesebb a másiknál. A táblaegyesítéskor még jó adatok látszanak az egyes táblákban, de kibontás után már nem mindenhol.
Nem érzem úgy, hogy én csesztem el, a PQ hibájának gondolom a dolgot, de azért gondoltam felteszem a kérdést, hátha.
Próbáltam úgy is, hogy nem egy lekérdezésben csináltam, hanem három különállóban, majd azokat egy negyedikben összesítettem, úgy sem jó az eredmény (ezért be sem fejeztem az egyesítést).


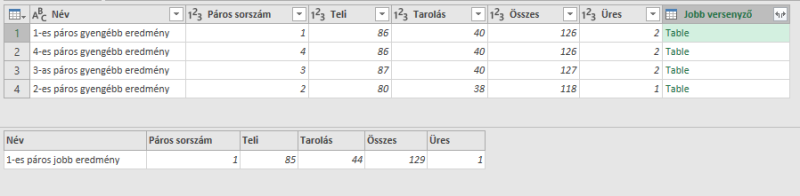

Köszi, ha tud valaki segíteni.
-
ny.janos
tag
válasz
Fferi50
#51837
üzenetére
Zseniális ötlet, köszönöm szépen! (Bár sokszor használom a feltételes formázást, itt és most valamiért nem jutott eszembe ezt használni.)

Mindenesetre elég gáz, hogy úgy tűnik ezek szerint, hogy nincs egyszerűen használható beépített formátumkód, ami ezt egy lépésben megcsinálná. -
ny.janos
tag
válasz
 dellfanboy
#51835
üzenetére
dellfanboy
#51835
üzenetére
Nincsenek egynél kisebb értékeim, így csak az első felére lenne szükségem kettő tizedessel, de a
#,#0formátummal mindenképpen van legalább 1 tizedes ott is, ahol egész az érték, sőt az egy tizedes helyett pedig megjelenik még egy 0 a végén eképpen:227,20
Ha csak#,##-t használok, akkor pedig ez lesz az eredmény pl.240,. Ugyanakkor a vessző már nem kellene. -
ny.janos
tag
Sziasztok!
Milyen formátumkódot kell megadnom ahhoz, hogy ha egy szám esetében azt szeretném, hogy legfeljebb 2 tizedes jelenjen meg, de ha nincs tizedes, akkor az egész számot lássam csak? Gondolom megoldható, csak én nem jövök rá.
Ha a 0,## formátumot használom, akkor a tizedesvessző megjelenik akkor is, ha egész a szám, aminek értelemszerűen nem kellene. Hogy tudom opcionálissá tenni a tizedesvesszőt is?Köszi.
-
ny.janos
tag
Sziasztok!
2019-es excelben adott egy PowerQuery-vel beolvasott táblázat, amelynek a formátumát egyéni táblázatstílussal formáztam, az oszlopok szélességét az általam kívántak szerint beállítottam.
Azonban amint frissítésre kerülnek az adatok, a táblázatstípus megváltozik, az öszlopszélességek módosulnak.
Zárolt cellákon a lapvédelmet próbáltam, de akkor a frissítés sem futtatható.A kérdésem: ismertek módszert arra, hogy a PQ frissítés a beállított formátumot ne változtassa meg?
-
ny.janos
tag
Szia!
Makróval sok minden lehetséges, így értelemszerűen erre is tudnak biztosan megoldást írni azok, akik értenek a mekróhoz.
Ugyanakkor sokszor elhangzott már itt a fórumban, hogy a színnel történő kódolás nem egy excel logikára felépített megoldás, ezért célszerű az ilyen megoldásokat kerülni. Ugyanis ha a színezés alapján lenne szükséged valamilyen műveletre, akkor az csak autoszűrővel és részösszeg/összesít függvényekkel illetve makróval oldható csak meg. Több kategóriából adatokat nyerni pedig értelemszerűen csak makróval lehet, vagy sokszor kell az autoszűrőn módosítani.Fentiek miatt célszerű megoldás lehet, hogy az eddigi táblázataidat átalakítod oly módon, hogy hozzáadsz egy új oszlopot a tábládhoz és a valamilyen kódokat (számok, betűk, konkrét szövegek stb.) rendelsz mind egyes színhez. Ha a színezést továbbra is szeretnéd látni, akkor feltételes formázásban rendeld a színezést az új oszlopként hozzáadott kódokhoz. Ezt követően a manuális színezés eltávolítható.
A fájlaid adatainak összefűzésére pedig az Adatok - adatok beolvasása - fájlból - mappából menüpontot (korábbi excel verziókban Power Query kiegészítőként volt telepíthető) javaslom. Ezzel az összes fájlod adataiból egy összesített adattáblát fogsz kapni (a feltételes formázást ebben is megadhatod).
-
ny.janos
tag
Kicsit nyakatekert, de működő megoldás lehet, hogy a HAHIBA függvényedben hiba esetére nem üres eredményt ("") kérsz, hanem 0 értéket (feltételezem, hogy mivel szöveges eredményt kapsz egyébként a leírásod alapján, így 0 eredményed csak hiba esetén lesz).
Ezt követően kettő részösszeg (vagy összesít függvény) eredményét kombinálod. Előbb darab2-vel (103) összeszámolod az összes sorodat és ebből kivonod darab-al (102) a 0-k mennyiségét. Ha az oszlopban nem szeretnéd látni a nullákat, akkor egyéni cellaformátummal eltünteted a 0 értékek megjelenítését. -
ny.janos
tag
Persze a makrós megoldás is tetszés szerint bővíthető, de azért is tettem ki végül a megoldásomat, mert azzal akár az összes dolgozó, összes munkafázisban történő részvétele összeszámolható egyetlen függvénnyel megfelelő előkészítés mellett.
Ha megengeded, hogy őszinte legyek, elsőre úgy gondoltam közzé sem teszem a megoldást, mert a - nem szándékosan, hanem rosszul megfogalmazott - struktúra miatt úgy éreztem, hogy feleslegesen akarok segíteni és nem hiányzik nekem, hogy tovább gondolkodjak a megoldáson, mert majd újra kiderül valami, ami nem úgy van, ahogy elsőre tűnt. Aztán meggondoltam magam, mert bármelyikünk hibázhat és a megoldások sokszínűsége segíthet egy későbbi probléma megoldásában másnak is, illetve én azokból tanultam sok mindent, amit itt a fórumon olvastam.A PQ-t mindig azért tartom nagyszerű megoldásnak, mert olyan dolgokat lehet vele viszonylag könnyedén megoldani sok esetben, melyhez vagy nagyon bonyolult, sokszorosan egybeágyazott függvények kellenének, vagy makrót kellene segítségül hívni. Mivel én utóbbihoz még annyi ismerettel sem rendelkezem, hogy egy kapott kódot hova kellene másolni (azt tudom, hogy az összefoglalóban meg tudnám nézni, de magamtól tényleg nem tudom), ezért mindig örülök, ha létezik programozási ismeret nélküli megoldás a PQ segítségével.
A te esetedre visszatérve: ha az általam javasolt megoldást úgy módosítod, hogy PQ-ben a beolvasás után felveszel egy indexoszlopot, majd a darabolást követően szűrsz azokra a sorokra, amelyek tartalmazzák az ellenőrzés kódot, akkor betöltés után ebből a táblából az index sorszám alapján az eredeti adataid mellé egy külön oszlopba ugyanúgy hozzá tudod olvasni a kinyert részletét az adatodnak (a módszert - PQ, index-hol.van, fkeres-sor függvények pedig tetszőlegesen megválaszthatod)
-
ny.janos
tag
Szerintem nem egyedi esetről van szó. Soha nem próbáltam még így kijelölni, de most megnéztem és Win 10, 2019 Office esetén sem működik. Szerintem máshol sem fog.
Javaslom, hogy tanulj meg billentyűkombinációkat (Ctrl, Shift, A, Space, "kurzormozgató nyilak", End, Home,Page Up, Page Down) használni a kijelöléshez az egér helyett, hidd el sokban meg fogod könnyíteni a saját munkádat.
Itt találsz egy csomó billentyűkobinációt összeszedve egy csokorba, köztük a kijelölésre vonatkozóakat is. -
ny.janos
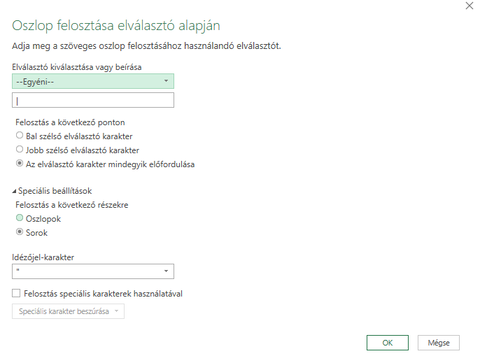
tag
Kijelölöd az adataidat, majd az adatok menü adatok beolvasását táblázatból vagy tartományból pontot választod (PQ). PQ-ben a kezdőlapon az oszlop felosztását választod
A betöltés után a nevekből és a munkafázisból csinálsz egy táblázatot, majd aSZORZATÖSSZEG((SZÁM(SZÖVEG.KERES([NÉV];[PQ által létrehozott tartomány]))*(SZÁM(SZÖVEG.KERES([munkafázis];[PQ által létrehozott tartomány])))))
függvénnyel megkeresed mi mennyiszer fordul elő (ha egy sorban ugyanaz a név ugyanahhoz a munkafázishoz többször szerepelne, akkor azt duplán fogja számolni az összesítésben).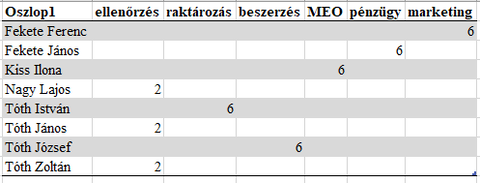
A PQ betöltés munkalapját elrejted, ha neked szeretnéd látni.
-
ny.janos
tag
válasz
TillaT
#50532
üzenetére
Ha a feltételes formázásban írod meg a képletet és kijelöléssel hivatkozol a cellára, akkor a DÁTUM függvény 3. paramétere abszolút hivatkozás ($A$5) lesz. Azt kézzel át kell írni vegyes hivatkozásra, hogy mindig az adott sort vizsgálja, de minden esetben az A oszlopot.
-
ny.janos
tag
Még egy kérdés: az
[időbélyeg] - [munkafázis] - [név] - [pozició]struktúra minden eleme mindig megjelenik a cellában, vagy előfordulhat olyan, hogy valamelyik adat hiányzik?
Azaz lehet olyan, hogy a következő időbélyeg előtt ennyi áll?[időbélyeg] - [név] - [pozició]
Ha utóbbi előfordulhat, akkor munkafázis pozíció teljesen hiányzik, vagy a szögletes zárójel megvan, de nem tartalmaz adatot? -
ny.janos
tag
Szia!
Az ellenőrzés munkafázis egy sorban egyszer fordulhat elő, vagy többször? Függvénnyel arra lehet megoldást találni, ha csak egyszer szerepel, mert ez esetben ismert, hogy meddig (következő | jel) kell a nevet keresni. Ha viszont többször is lehet ellenőrzés munkafázis cellán belül, akkor úgy gondolom, hogy mindenképpen darabolni kellene a cellákat (kivéve persze a makrós megoldást - amihez én nem értek).
Jól értem, hogy adott személyhez az összes sort szeretnéd vizsgálni egyszerre, hogy melyekben szerepel az ellenőrzés munkafázisnál az ő neve és ezek darabszámára vagy kíváncsi az összes sorból? Ha igen, akkor Power Query irányába is el lehet indulni szerintem. -
ny.janos
tag
Legfeljebb még nem, mert eddig nem használtad.
Ha több problémát is sikerül megoldani vele (SZORZATÖSSZEG), akkor a megoldások keresése során elkezd vele egyre gyakrabban szemezgetni az ember (én legalábbis így vagyok vele).
Ha van kedved hozzá, akkor rákereshetsz a fórumban a függvény nevére, érdekes megoldásokra lehet bukkanni a használatával. -
ny.janos
tag
válasz
 pero19910606
#50485
üzenetére
pero19910606
#50485
üzenetére
A korábbi megoldási javaslatomon túl egy másik (segédoszlop nélküli tömbképletes) megoldást is sikerült kitalálnom.
A képlet (CSE):=INDEX($B$2:$B$369;HOL.VAN(1;SZÁM(SZÖVEG.KERES($B$2:$B$369;I2))*1;0))

-
ny.janos
tag
Szia!
Tömbképlettel pl. szorzatösszeg függvénnyel, de nem bonyolítanám ezzel. Inkább szumha függvényt használnék, vagy kimutatást. De PowerQuery-vel is megoldható.
#Szerk: közben rájöttem, hogy félreértelmeztem, hogy mit szeretnél. De PQ az általad kértekre is megfelelő lehet.
-
ny.janos
tag
válasz
pero19910606
#50485
üzenetére
Szia!
Wikipediáról az automárkák letölthetőek PQ-vel, vagy akár másolhatóak is (bár PQ esetén a megfelelő stuktúra biztosabb.
Ha megvannak az autómárkáid (az én példámban B2:B369 tartomány), és H oszlopban vannak az általad írt adatok, akkor
I2 cella képlete:=BAL(Munka1!$H2;SZÖVEG.KERES(" ";Munka1!$H2)-1)
J2 cella képlete:=INDEX($B$2:$B$369;HOL.VAN("*"&Munka1!$I2&"*";$B$2:$B$369;0))
I oszlop egy segédoszlop, a várt eredmény a J oszlopban található. (Ha lenne olyan automárka, melynek az első tagja megegyezik egy másik márka első tagjával, akkor lesznek benne hibák.) -
ny.janos
tag
válasz
Fferi50
#50410
üzenetére
A DARABHATÖBB függvény alkalmazása remek megoldás (nekem magamtól nem jutott volna eszembe, a DARABTELI-vel próbálkoztam volna, de mint rájöttem az nem alkalmas arra, hogy
DARABTELI($A$2:$A$7&$B$2:$B$7;A2&B2)formában használjam).
Ha megengeded kiegészíteném egy ötlettel, mely esetén nem kell a második segédoszlop:=1/DARABHATÖBB($A$2:$A$7;A2;$B$2:$B$7;B2)
Ez esetben értelemszerűen az összeget kell használni a kimutatásban a maximum helyett. -
ny.janos
tag
válasz
 Krant.ia
#50316
üzenetére
Krant.ia
#50316
üzenetére
Szia!
Használhatod az adatok beolvasása és átalakítása menüpontot (korábbi verziókban Power Query kiegészítő) is.
Oszlop hozzáadása példákból menüpontot válaszd. Az első kettő értéket gépeld be zárójel és szóköz nélkül, amilyen eredményt kapni szeretnél. Ebből automatikusan felismerésre kerül, hogy a szóközöket és a zárójeleket kell eltávolítani és a képletet megírja helyetted a program. Betöltés után meg is vannak a kívánt adataid. -
ny.janos
tag
Sziasztok!
Igazából nem konkrét feladathoz kapcsolódik, csak a kíváncsiságom nem hagy nyugodni: ismer valaki egyszerű módot arra, hogy Power Query-vel egy adott dátumhoz tartozó hét számát az ISO 8601 szabvány szerint határozzuk meg?
Excelben a HÉT.SZÁMA függvény második paraméterének megfelelő megválasztásával (21) simán működik, ugyanakkor Power Query-ben a Date.WeekOfYear függvény csak a január 1-t tartalmazó hét első hétként történő értelmezését ismeri.
-
ny.janos
tag
Szia!
Akkor kezdem előröl az előbbi elveszett hozzászólás után.
A dátum átalakításához (a kérdésed alapján végzett) kísérletezgetésem alapján megfelelő megoldás lehet a szövegből oszlopok átalakítás, ha az utolsó lépésben megadod a dátum formátumát. Ha a dátumaid több formátumban vannak (ahogy írtad), akkor többször egymás után kell az átalakítást elvégezned. Az átalakítás a dátum formátumú cellákat nem fogja elrontani, a nem dátum formátumúakat ellenben megfelelő formátumra fogja alakítani. Az egyetlen (általam azonosított) probléma, ha a dátumok között NHÉ és HNÉ formátum egyaránt szerepel. Ez esetben összetettebb megoldást kellene keresni. Az átalakítás mikéntjéről Horváth Imre ebben a bejegyzésben írt részletesen.
Alkalmas lehet az átalakításra a Power Query is, de míg a szövegből oszlopok átalakítás a 202212.10 hibás formátummal is megbirkózik, addig előbbivel ezt nekem nem sikerült kezelnem (biztos lehet, csak az általam nem ismert megoldást igényelne).A megelőző hozzászólásod kapcsán (főként az alapján, hogy a bemeneti adataid több fájl több munkalapján találhatóak, de a struktúra azonos) szintén a Power Query alkalmazását javasom. A betöltés történhet akár az általad készített fájlba (ez esetben nem kell a bemeneti adatokat tartalmazó fájlokat megnyitnod) és azt is be tudod állatíni, hogy az adatfrissítés megtörténjen automatikusan, mikor a fájlodat megnyitod. A megoldásról itt találsz egy részletes, könnyen érthető, képernyőképekkel illusztrált leírást.
Sok sikert!
-
ny.janos
tag
válasz
 szricsi_0917
#49518
üzenetére
szricsi_0917
#49518
üzenetére
Szia!
Ha az oszlopaidból igen sok van és nem csak 2-szer ismétlődik, hanem esetleg több 10-szer is, akkor érdemes lehet elgondolkodni egy segédmunkalapban szerintem. Itt megnézheted, mire gondolok.
-
ny.janos
tag
válasz
 MasterDeeJay
#49512
üzenetére
MasterDeeJay
#49512
üzenetére
Ha minden rendszám csak 1 sorban szerepel, ahogy írod, akkor a rendszámok A oszlopban történő felsorolásával és hozzá minden lehetséges dátum kombináció megadásával kezdenék a helyedben. Mutt pár hozzászólással feljebb részletezte, hogy miként lehet PQ-vel egyszerűen valamennyi rendszámhoz egy intervallumban szereplő valamennyi dátumot hozzárendelni külön-külön sorban.
Ha ezzel megvagy, akkor az oszlopazonosítókat kell felvinned ebbe a táblázatba a, majd az index és hol.van fügvényekkel kombinálnod.Töltöttem fel egy mintafájlt, ezen egyszerűbb megérteni, mint ha képernyőfotót tennék fel.
Arra figyelj mindenképpen, hogy ha a táblázat második sorában lenne olyan szám, mely megegyezik valamelyik dátummal, akkor ez a javasolt megoldás hibát fog okozni!
-
ny.janos
tag
válasz
MasterDeeJay
#49507
üzenetére
Szia!
Konkrét megoldást nem fogok tudni javasolni, mert ilyen szinten nem értek a PowerQuery-hez, de biztos vagyok benne, hogy mivel az ismétlődés 15 oszloponként van, azzal meg lehet oldani, hogy összesen 16 oszlopba kerüljön az összes adatod, ahol az első oszlopban ismétlődnek a rendszámok.
Talán Mutt tud neked ebben segíteni, ő kimondottan profi a PQ-ben. -
ny.janos
tag
válasz
 Melorin
#48882
üzenetére
Melorin
#48882
üzenetére
Ahogy a táblázatodat nézem, a központi adatbázisból nyert árakhoz tartozó érvényeségi dátum kezdete és vége könnyedén kinyerhető PowerQuery-vel. Ha ez megvan, akkor az alapján meg tudod keresni az adott termék adott napon érvényes árát nem kell hozzá semmilyen átalakítás. Ezeket a videókat nézd meg és válassz olyan megoldást, ami neked megfelelő.
[link] [link] [link] [link] [link] -
ny.janos
tag
válasz
 BigBadPlaYeR
#48759
üzenetére
BigBadPlaYeR
#48759
üzenetére
Akkor lehet, hogy valamiért az én excel verzióm nem szereti, mert nálam ez nem működött, de örülök, hogy nálad igen.
Ha több cella kitöltését szeretnéd, akkor használd az előbbi függvényt egy ÉS függvénybe ágyazva, pl:=ÉS(NEM(ÜRES(A1));NEM(ÜRES(B1));NEM(ÜRES(C1));NEM(ÜRES(D1))) -
ny.janos
tag
válasz
BigBadPlaYeR
#48748
üzenetére
Szia!
Feltételezéssel élek, ha ez nem igaz, akkor a javasolt megoldás feltételezhetően nem használható a számodra:
Ha a kérdésed oka az, hogy aki a táblázatba adatokat rögzít, az rendszeresen elfelejti valamely hozzá tartozó további adatok töltését, akkor adatérvényesítésben próbálkozhatsz képlettel lekorlátozni az adatbevitelt. Ha arra a cellára teszed az adatérvényesítést, melyet mindenképpen tölteni kell annak, aki az adatot rögzíti, akkor csak azt követően fogja tudni azt kitölteni, ha a többit már kitöltötte.
A képletben az ÉS és a DARAB2 függvények kombinációját próbálnám a helyedben (az ÜRES függvény a NEM függvénnyel kombinálva érdekes módon nem működik az adatérvényesítésben). -
ny.janos
tag
válasz
 jerry311
#48728
üzenetére
jerry311
#48728
üzenetére
Egy gondolatébresztő a korábban felvetett Power Query megoldáshoz: Ha az összes csv fájlt beolvasod mintából és a fájloknak a nevében szerepel a dátum, akkor a fájlnév részének kinyerésével és dátummá alakításával lesz egy adathalmazod, melyben szerepel a Name, ID, Status adatok mellett a dátum is. Az ID és a dátum oszlop összevonásával készíthetsz egy új oszlopot. Ezután a státuszt meg tudod keresni a VLOOKUP-al a PQ által előállított adathalmazban, ha az ID cella és fejlécként szereplő dátum cella összevont adatára keresel.
Ha az egyes csv fájlok nem tartalmaznak több 10e sort így a több, mint egymillió soros korlátot várhatóan nem léped túl, akkor nem is foglalkoznék havonta külön munkalappal, hanem az évet és a hónapot kiemelném egy-egy cellába a munkalap tetején, és annak felhasználásával képezném a fejlécben a dátumot. Így ha változtatod az évet és a hónapot, akkor mindig az aktuális értéket fogja dátumnak megfelelően kiolvasni a VLOOKUP a PQ által beolvasott csv fájlok összességéből. -
ny.janos
tag
válasz
 Brandynew
#48715
üzenetére
Brandynew
#48715
üzenetére
Van itt egy kis tévedés a részedről, de a függvény súgó egyértelmű:
"A függvény a kezdő_periódus és a vég_periódus között egy kölcsönre visszafizetett összes kamat halmozott értékét adja meg."
Ha te ezzel szemben a havonta fizetett kamat mértékét szeretnéd megtudni, akkor a halmozott kamatból ki kell vonnod az eggyel korábbi hónap halmozott kamat értékét.
Ahelyett, hogy részletekbe mennék, megosztom egy korábbi táblázatomat, amit tetszőlegesen átalakítasz majd a saját szád íze szerint. A működést viszont meg fogod érteni.
[link] -
ny.janos
tag
válasz
ny.janos
#47741
üzenetére
Ha az oszlopaidra nem igazak az általam feltételezettek, akkor az én megoldási javaslatom az alábbi:
1. A táblázatod munkalapját (neve az én példámban eredeti) másold le egy új munkalapra (neve az én példámban masolat).
2. Minden adat kijelölése utánCtrl+G, irányított, állandók-at pipálod csak be, majd delete gomb.
3.Alt+.
4. Teljes tartományt kijelölöd, Ctrl+H, az egyenlőségjeleket cseréled valami olyan karaktersorozatra (az én példámban ###, ami garantáltan nem fordul elő egyik képletedben sem.
5. Új munkalapon A1 cella képletének megadod a következőt (szintén kell a végére egy speciális karakersorozat, ami nem szerepel a képleteidben - én másikat használtam - &&&& -, mint előbb, de akár azonos is lehet):=HA(ÜRES(masolat!A1);eredeti!A1;"=HAHIBA("&HELYETTE(masolat!A1;"###";"=")&";&&&&)")
6. A teljes tartományt kijelölöd ezen a munkalapon és csere funkcióval cseréled az utóbbi karaktersorozatot - &&&& - két darab idézőjelre (így lesz a hiba esetén üres a cellád).
7. Kijelölöd a teljes tartományt, másolást követően beilleszted egy jegyzettömbbe, majd onnan kimásolva visszailleszted az eredeti munkalapodra.
8. A segéd munkalapokat törlöd. -
ny.janos
tag
válasz
 Dilikutya
#47740
üzenetére
Dilikutya
#47740
üzenetére
Ha egybefüggő területet alkotnak a képletezett cellák (azaz nincs közöttük olyan, hogy 10 oszlop képleteket tartalmaz, majd 3 nem stb.), akkor a következőket tenném:
1.
Alt + .-al átváltanám excelben a cellékat értékről képletre,
2. átmásolnám a képleteket wordbe,
3. csere funkcióval cserélném az alábbiakat,
a)^t=csere;"")^t=-re
b)^pcsere;"")^p-re
c)=csere=HAHIBA(-re
4. wordből visszamásolnám az adatokat excelbe,
5. (a word idézőjel sajátossága miatt) bármely cellából kijelölve már excelben cserélném valamennyi cellában a”„-t""-re,
6.Alt+.Remélem működik, és nem írtam el / hagytam ki semmit.
-
ny.janos
tag
válasz
 botond187
#47587
üzenetére
botond187
#47587
üzenetére
Szia!
Ha jól értem a problémádat, akkor arra Mutt 3,5 évvel ezelőtt javasolta nekem ExcelisFun videóit erre a témára. Itt a megoldás. A kérdést pedig itt találod hozzá.
-
-
ny.janos
tag
válasz
rvn_10
#47493
üzenetére
Remélhetőleg az új tábla struktúrában átgondoltabb lesz.
Ezt a képletet próbáld meg a korábbi helyébe írni:=HAHIBA(HAHIBA(HAHIBA(HAHIBA(INDEX('[Produktionsplan-Chiron 2021.xlsx]1._munkalap'!E:E;HOL.VAN($B158;'[Produktionsplan-Chiron 2021.xlsx]1._munkalap'!$B:$B;0)+1); INDEX('[Produktionsplan-Chiron 2021.xlsx]2._munkalap'!E:E;HOL.VAN($B158;'[Produktionsplan-Chiron 2021.xlsx]2._munkalap'!$B:$B;0)+1)); INDEX('[Produktionsplan-Chiron 2021.xlsx]3._munkalap'!E:E;HOL.VAN($B158;'[Produktionsplan-Chiron 2021.xlsx]3._munkalap'!$B:$B;0)+1)); INDEX('[Produktionsplan-Chiron 2021.xlsx]4._munkalap'!E:E;HOL.VAN($B158;'[Produktionsplan-Chiron 2021.xlsx]4._munkalap'!$B:$B;0)+1));$A$1) -
ny.janos
tag
válasz
rvn_10
#47490
üzenetére
Ha erre keresel megoldást, akkor valójában soha nem a keresett értékhez tartozó adatokat fogod a másik táblázatból eredményül megkapni, hanem az egyel alatta levő sorban található értékeket. Bár az okot nem értem, ha erre van szükséged, akkor én az FKERES függvényt az INDEX - HOL.VAN függvénypárosra cserélném. Ekkor az INDEX függvényen belül a sorszám értéknél a HOL.VAN függvényhez hozzá kell adj 1-et.
Csak este leszek gép előtt, így pontos képletet most nem tudok írni.
-
ny.janos
tag
válasz
rvn_10
#47482
üzenetére
Tehát van egy fileom, amiben a B oszlopban cikkszámok vannak PL "323B" D től X ig pedig a hét napjai 3 műszakra osztva.
Ez az egyik fájl:
A másik fileban pedig A B oszlopban szintén cikkszámok vannak E től Y ig pedig szintén a hét bontva napi 3 műszakra.
Ez pedig a másik:

-
ny.janos
tag
válasz
rvn_10
#47478
üzenetére
Szia!
Egy lehetséges megoldás, hogy a HAHIBA függvény második részébe teszed a második keresési tartományt és így tovább a többit, további HAHIBA függvényeket alkalmazva.
Az alábbi képletben a munkalapoknak a nevét cseréld ki a megfelelőre. (Ha 5 munkalapod lesz és nem négy, akkor értelemszerűen bővítened kell a függvényt).
A te példádból kiindulva a D158 cella képlete, melyet másolhatsz jobbra és lefelé is:
=HAHIBA(HAHIBA(HAHIBA(HAHIBA(FKERES($B158;'[Produktionsplan-Chiron 2021.xlsx]1._munkalap'!$B:$Y;HOL.VAN(D$1;'[Produktionsplan-Chiron 2021.xlsx]1._munkalap'!$B$1:$Y$1;0);0);FKERES($B158;'[Produktionsplan-Chiron 2021.xlsx]2._munkalap'!$B:$Y;HOL.VAN(D$1;'[Produktionsplan-Chiron 2021.xlsx]2._munkalap'!$B$1:$Y$1;0);0));FKERES($B158;'[Produktionsplan-Chiron 2021.xlsx]3._munkalap'!$B:$Y;HOL.VAN(D$1;'[Produktionsplan-Chiron 2021.xlsx]3._munkalap'!$B$1:$Y$1;0);0));FKERES($B158;'[Produktionsplan-Chiron 2021.xlsx]4._munkalap'!$B:$Y;HOL.VAN(D$1;'[Produktionsplan-Chiron 2021.xlsx]4._munkalap'!$B$1:$Y$1;0);0));$A$1) -
ny.janos
tag
Szia!
Először az A és B oszlop értékeit határozd meg (másolás után ismétlődések eltávolításával, vagy ha O365-öt használsz, akkor az EGYEDI függvénnyel). Ezek kerüljenek a D oszlopba illetve az első sorba (utóbbit nyilván transzponálnod kell).
Ezt követően E2 cella képlete:
=HA(SZORZATÖSSZEG(($D2=$A$1:$A$12)*(E$1=$B$1:$B$12))=1;E$1;"")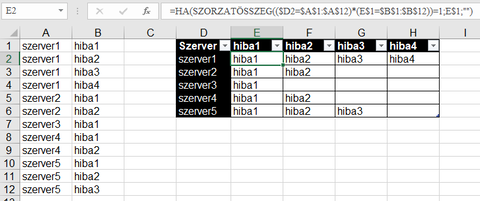
-
ny.janos
tag
válasz
 Chrisluke
#47311
üzenetére
Chrisluke
#47311
üzenetére
Szia!
A HAELSŐIGAZ függvény a HA függvényhez hasonlóan egy logikai vizsgálatban csak egyetlen feltételt tartalmazhat. Ha egy adott érték felvételéhez több logikai vizsgálatnak is igaznak kell lennie, akkor az ilyen feladatot a HA (esetedben a HAELSŐIGAZ) függvénybe ágyazott ÉS függvénnyel oldhatod meg.
Ha az értéktartományaid között valóban vannak lyukak, azaz vannak olyan értékek, ahol semmilyen eredményt nem kell kapj, akkor egy HAHIBA függvénybe érdemes ágyaznod a HAELSŐIGAZ függvényedet.
=HAHIBA(HAELSŐIGAZ(ÉS(D1>=0;D1<=9);"0.";ÉS(D1>=12;D1<=18);"I.";ÉS(D1>=25;D1<=27);"II.";ÉS(D1>=32;D1<=50);"III.";ÉS(D1>=72;D1<=147);"IV.");"") -
ny.janos
tag
válasz
MostaPista
#46694
üzenetére
Beillesztés után használd az adatok menüben a szövegből oszlopok parancsot, válaszd a tagolt adattípust, majd az egyéb mezőbe írd a visszaperjelet.
Ha visszatérően lenne szükséged ilyen megoldásra, akkor a PowerQuery-t is használhatod. -
ny.janos
tag
válasz
 morgusz
#45992
üzenetére
morgusz
#45992
üzenetére
Előfordulhat (főként külső adatforrásból exportált adatok esetén), hogy olyan nem nyomtatható karaktereket tartalmaznak egyes cellák, amely karakterek nem láthatóak és úgy tűnik, mintha a cella üres lenne, holott valójában nem az. Segítség lehet a KIMETSZ, TISZTÍT és a HELYETTE függvény is.
Kerülő megoldás lehet, hogy szűröd a tartományodat az üresnek tűnő cellákra, majd manuálisan törlöd azokat, hogy valóban üressé váljanak (ez viszont sok adat esetén körülményes lehet).
-
ny.janos
tag
válasz
 BagyiAti
#45948
üzenetére
BagyiAti
#45948
üzenetére
Szia!
Bár a leírásodból az tűnik ki számomra, hogy az adatbázisod egy külön táblázat, amihez a termékkategóriát szeretnéd eredményül kapni, és ehhez a már írt megoldások elegendőek is, megosztom az én gondolatomat is, hátha hasznos lesz neked vagy másnak.
Én abból a gondolatból indultam ki, hogy az első sorban felsorolt termékkategóriák alá vannak felsorolva a hozzá tartozó cikkszámok (ahogy az általad megosztott képen is látható) és ebből szeretnénk egy olyan adatbázist előállítani, melyben a cikkszámok egymás alatt vannak és ehhez van a mellette szereplő oszlopban megadva a termékkategória.
Én ehhez a power query-t használtam.
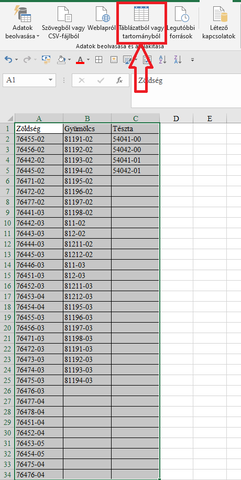
1. Kijelöltem a teljes adattartományt.
2. Az adatok menüpontban a jelölt parancsot választottam.
3. A power query szerkesztőben címsorrá tettem az első sort.
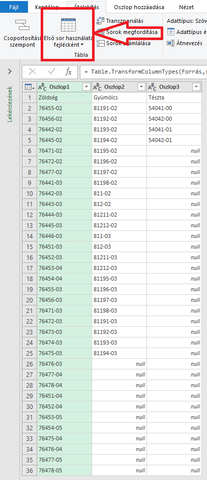
4. Mindhárom oszlopot kijelölve az alábbi parancsot használtam.
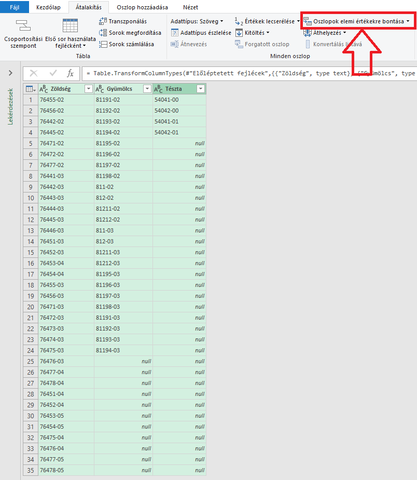
5. Az oszlopok sorrendje fogd meg és húz módszerrel felcserélhető, az adatok az alábbi menüponttal sorba rendezhetőek.
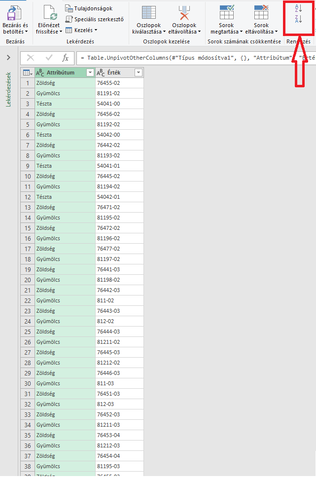
6. Ha mindezzel megvagy, akkor betöltheted az excelbe.
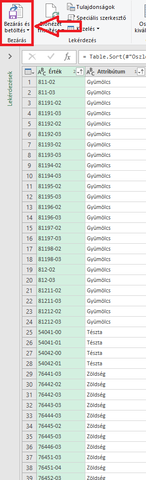
Ezzel van egy teljes adatbázisod, és egy FKERES függvény is elegendő, hogy ebből kikeresd a saját adatbázisodban szereplő cikkekhez a megfelelő kategóriát.
-
ny.janos
tag
válasz
 tozo86
#45884
üzenetére
tozo86
#45884
üzenetére
Szia!
A Power Query biztosan megoldást ad a problémádra, de nem vagyok annyira gyakorlott benne, hogy perfekt megoldást mondjak annak használatával. Ha a táblázatot Power Query beolvasást követően az alábbi pontot választod
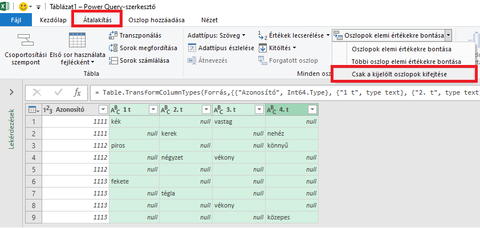
Akkor ezt az eredményt kapod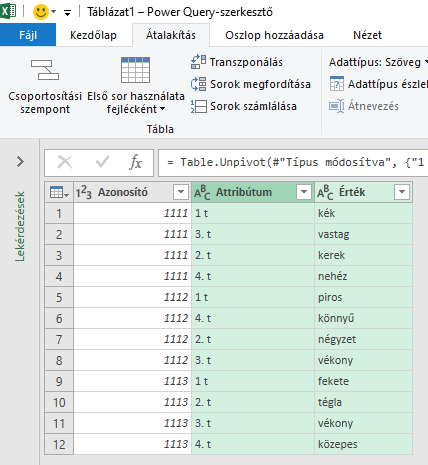
Ezt betöltve az excelbe, majd ez első két oszlopot összefűzve, és az összefűzött azonosító+tulajdonságra az FKERES függvény már megoldás lesz neked.
Attól tartok, hogy a P.Q. a teljes megoldásra is alkalmas és az én megoldásom kissé fapados, de még én is csak most tanulgatom, hogy mi mindenre is jó.
Ha Mutt felbukkan, biztos ír neked egy sokkal kifinomultabb megoldást az enyémnél. Én is kíváncsian várom. -
ny.janos
tag
válasz
kokokka
#45873
üzenetére
Szia!
Volt egy hasonló kérdés sok-sok hónappal ezelőtt melynek a gondolatmenete szerintem itt is hasznosítható. A cellákat én a helyedben nem színnel jelölném, hanem beleírnám a szakok rövidítését (De, Du, Éj) kiegészítve a hétvégével (pl. "Hv"). Ekkor a színezést megoldhatod feltételes formázással, a beírt értékekre pedig tudod használni a DARABTELI függvényt. A táblázat végére beszúrt 3 oszlop fejlécében ehhez megadnám a szakokat és egy pontosan megírt függvény másolható minden irányban.
Azokra a hétvégékre, ahol valaki dolgozott, értelemszerűen a szak jelét írd a Hv helyett. Én nem erőltetném ez esetben a makrót, mert könnyen kiváltható.
-
ny.janos
tag
válasz
andreas49
#45857
üzenetére
Lappy javaslatát (eredmény típusa: 21) próbáltad? (Office 365-öm nincs, de 2019-ben hiba nélkül működik, míg az 1-es vagy 2-es típus a 2019-es excelben is azt az eredményt adja, amit te írtál).
Egyébként létezik az ISO.HÉT.SZÁMA függvény is, ott nem kell eredmény típusát megadnod.
-
ny.janos
tag
válasz
porjes
#45826
üzenetére
Szia!
Bár a már javasolt INDEX és HOL.VAN függvény páros megoldást adhat, de ehhez minimum a cellaegyesítéseket megszüntetném, ha valóban arról van szó pl. az A5-A6, B5-D5 stb. tartományokban.
Alternatívaként megfontolásra javasolnám, hogy egymás mellett oszlopokban kerüljön felvitelre a mozgás dátuma, mellette a kiadva és bevétel valamint a kiadható oszlop, mely utóbbi egy görgetett összeget tartalmazzon. Ebből pedig kimutatással lehet bármely napra utólag statisztikát készíteni. Persze lehet, hogy más a cél, mint amit én gondolok a táblázatot látva, kérlek ne vedd kukacoskodásnak, hogy én strukturálisan máshogy állnék neki a probléma megoldásának.
-
ny.janos
tag
válasz
bela85
#45818
üzenetére
Sziasztok!
bela85: Ma sem értem ide mostanáig, meg el is felejtettem, de örülök, hogy megoldódott.
Fferi50: köszönöm a kisegítést.
Delila_1: Nem jobb, nem rosszabb, más. Ha valamennyi oszlopban előfordulhat több figyelembe veendő érték (igen, talán, lehet stb.) valamint a nem érték helyett is lehetnek más nem számítandó értékek (pl. soha, semmikor stb.), a tömbképlet akkor is működik érdemi átalakítás nélkül. (Én úgy értelmeztem, hogy bela85-nek ilyen megoldásra van szüksége, ezért lett ez az általam javasolt megoldás.)
Én mindenesetre mindig örülök, ha több megoldást is látok, mert sokszor én is tanulok ezekből. Például hogy adott esetben másként, egyszerűbben is gondolkodhatok.
-
ny.janos
tag
válasz
bela85
#45808
üzenetére
Szia!
Bocs, nem voltam nap közben. Próbálkoztam, ez lett belőle (elképzelhető, hogy van egyszerűbb, elegánsabb megoldás is, most így estefelé ennyi tellett tőlem). Segédoszlop nélküli megoldás nem tudom, hogy létezhet-e (nekem nem sikerült ilyet alkotnom).
Bármelyik oszlopban számolja az IGEN, LEHET, TALÁN értékeket, a lista értelemszerűen bővíthető. A tömbképlet első fele a Krit.fő.állapot oszlopot vizsgálja, míg a második fele annyi DARABTELI függvénnyel, ahány krit. állapot oszlopod van azt, hogy ezek közül szerepel-e valamelyikben az elfogadható válaszok valamelyike.
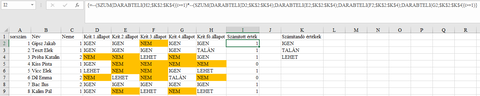
A képletet természetesen Ctrl + Shift + Enter -el zárd le (tömbképlet továbbra is).
Utóbb jöttem rá, hogy a képen még használt két mínusz jelre nincs is szükség.
=(SZUM(DARABTELI(H2;$K$2:$K$4))>=1)*(SZUM(DARABTELI(D2;$K$2:$K$4);DARABTELI(E2;$K$2:$K$4);DARABTELI(F2;$K$2:$K$4);DARABTELI(G2;$K$2:$K$4))>=1)











 , mert míg a 2019-es verzióban 5 paramétert lehetséges megani, a 2016-os verzió hibát dobott rá, hogy 2-4 paraméter adható meg.
, mert míg a 2019-es verzióban 5 paramétert lehetséges megani, a 2016-os verzió hibát dobott rá, hogy 2-4 paraméter adható meg.































































Új hozzászólás Aktív témák
- PC Szervizeket, Gépépítőket keresek B2B szoftver partnerségre (E-számlával)
- Windows 10/11 Home/Pro , Office 2024 kulcsok
- Vírusirtó, Antivirus, VPN kulcsok GARANCIÁVAL!
- MEGA AKCIÓ! - Jogtiszta Windows - Office & Autodesk & CorelDRAW - Azonnal - Számlával - Garanciával
- The Elder Scrolls Online Imperial Collector s Edition
- Prémium PC házak akár 20-40% kedvezménnyel eladók garanciával, számlával! Upd. 04.20
- BESZÁMÍTÁS! Gigabyte Z390 i7 9700KF 16GB DDR4 512GB SSD GTX 1070 Ti 8GB Cooler MasterCM 690 III 550W
- Apple iPhone 11 Pro Max 64GB,Újszerű,Adatkabel,12 hónap garanciával
- ÚJ Magic Keyboard billentyűzetek/ USB-C - Lighning/ 27% Áfás/ Ingyenes szállítás!
- iPhone 11 Pro 64GB 100% (3 hónap garancia)
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest