- Gurulunk, WAZE?!
- Android másképp: Lineage OS és társai
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Luck Dragon: Asszociációs játék. :)
- Magga: PLEX: multimédia az egész lakásban
- bambano: Bambanő háza tája
- VoidXs: Tényleg minden játék optimalizálatlan?
- erkxt: A Roidmi becsődölt – és senki nem szól egy szót sem?
- Viber: ingyen telefonálás a mobilodon
Új hozzászólás Aktív témák
-
#550
 Petykemano
veterán
Petykemano
#549
Petykemano
veterán
Petykemano
#549
Petykemano
veterán
válasz
 Petykemano
#549
üzenetére
Petykemano
#549
üzenetére
Ugyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
(A gput folytassuk a radeon találgatósban) -
#549
Petykemano
veterán
Cathulhu
#548
Petykemano
veterán
válasz
 Cathulhu
#548
üzenetére
Cathulhu
#548
üzenetére
De és ez a csomó késleltetés ez biztos?
Mert ha igen, akkor az meg is adja a választ arra, hogy a következőkben miért is lenne indokolt imterposer használata. Lezso azt mondta, az IF nem széles, nem szükséges az IP, de az IP miközben rövidít, aközben szélesebb buszt is lehetővé tesz. Ha az irány az IF javításán vezet, akkor az IP a későbbiekben elkerülhetetlen.Mindenesetre az jó hasonlat, hogy mintha csak közvetlen memóriaelérés nélküli TR lapkák lennének. Az biztos kolönbség, hogy az IF órajele magasabb kell legyen, ez máris csökkenthet a késleltetesen.
Viszont ha ebben igazad van, az megint csak indkolja, hogy az IO lapkán egy bazi nagy cache legyen, hogy egy útvonal minél inkább megúszható legyen. (Eddig: cpu<->ram, most: cpu<->io), amibe a prefetchelést maga az IO lapka végezze. Pont úgy, ahogy a Vega HBCC-nél láttuk. (Lehet, hogy a technológiát ott csak kipróbálták)
Az, hogy ezt a struktúrát fel lehetne használni gpuknál, nem egyedi gondolat. Sőt, kicsit a 4 Shader engine már eleve ez. De mennyivel jobb lenne minden shader enginet külön gyártani és IF-fel össszekapcsonil? Akár külön célra. Akár válogatva.
(Via) -

Cathulhu
addikt
Egy erdekes gondolat utotte fel bennem a fejet. A kozponti IO miatt felaldozott az AMD egy csomo kesleltetest, gyakorlatilag olyan az uj proci, mintha a threadripperekben csak azok a magok uzemelnenek, amelyikeknek nincs sajat memoria vezerlojuk, es csak egy kulsol vezerlon keresztul tudjak ezt elerni. De igy viszont egy IO chip tud akar 8 csatornat is kezelni marha nagy sebesseggel. Emellett maradtak a kis chipletek a sajat "kis" cacheikkel, de eleg sokan (8an most, ki tudja mennyien meg). Ez nem CPU emberek, ez egy GPU!
Egy marha eros es modularis CPUGPU hibrid. Kovetkezo lepesben latok magam elott nehany GCN chipleteket a tokozason belul a marha gyors ion keresztul RAM-ot kezelni, utana viszont mar kulonbseg se lesz koztukEs ez egybe vagna azzal is amt Lisa mondott, hogy meresz dolgokkal kiserleteznek, amelyik evek mulva robbannak.
Mark my words! Jo ejt

-
Cathulhu
addikt
AVX-re programot irni marha egyszeru, es a latency is kicsi, mig GPU-ra nem olyan trivialis. Amugy mindketto SIMD, szoval attol meg lehet, hogy a backend az a GCN-lesz, de a kod az AVX. Ha van egy kodod, ahol erzed hogy van ertelme a SIMD-nek, azt par perc alatt megirod es lemered, mig GPU-nal szorakozni kell a hosttal, bufferekkel, kernelekkel, stb. Raadasul mig az egyik folyamatosan etetni kell adattal, hogy a latencyt elfedd, addig a masiknal eleg 128/256 vagy 512 bites reszeket kiragadni, azon azonnal lefut, visszairod es mar vissza is kapod a vezerlest.
-
válasz
 S_x96x_S
#543
üzenetére
S_x96x_S
#543
üzenetére
"Getting back to the Rome package again there are a few details left to talk about. The CCXs connect to the IOX via an Infinity Fabric (IF) link. This is point to point and the CCXs do not talk to each other directly, all communication is through the IOX die."
Szóval nincs crossbar. Kelleni fog az L4. Valószínűleg túl sok helyet foglalt volna egy crossbar vagy nem lett volna semmi értelme.
Zen 3-nál az az SMT4 gondolom az akar lenni, hogy egy magon 4 szál fut. Ebből az következik, hogy baromi széles lesz az új mag. A Zen 4 AVX-512 támogatása viszont fura. Minek, ha ott a GCN? Bár addigra a jelenlegi ütem szerint 2023 lesz, szóval lehet az új GPU architektúra valami GPU-CPU fúziós megoldás lesz.
-

S_x96x_S
addikt
Semiaccurate.com -os értékelés:
AMD’s Rome is indeed a monster
Some details, some performance claims, and more
Nov 9, 2018 by Charlie Demerjian
https://semiaccurate.com/2018/11/09/amds-rome-is-indeed-a-monster/A cikkiró 2019.Q2 -re mondja a Rome -ot ; A Rome után röviddel jöhet a Ryzen 3000-es sorozat.
más ..
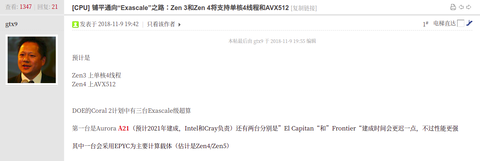
A ChipHell -es legújabb infó -
az AMD komolyan veszi a HPC-t !Zen 3: SMT4
Zen 4: AVX512
At least one of the planned Exascale HPCs (2021-2022, "Frontier", "El Capitan") will use AMD Epyc processors (might be Zen 4/Zen 5).
via -
#542
 lezso6
HÁZIGAZDA
Petykemano
#541
lezso6
HÁZIGAZDA
Petykemano
#541
válasz
Petykemano
#541
üzenetére
Szerintem semmilyen strukturális kompaTIBILÁTÁS nem kell, a lényeg a socket. Oprendszer felé úgyis egy processzorként látszik az egész, aztán úgyis kap másik drivert.
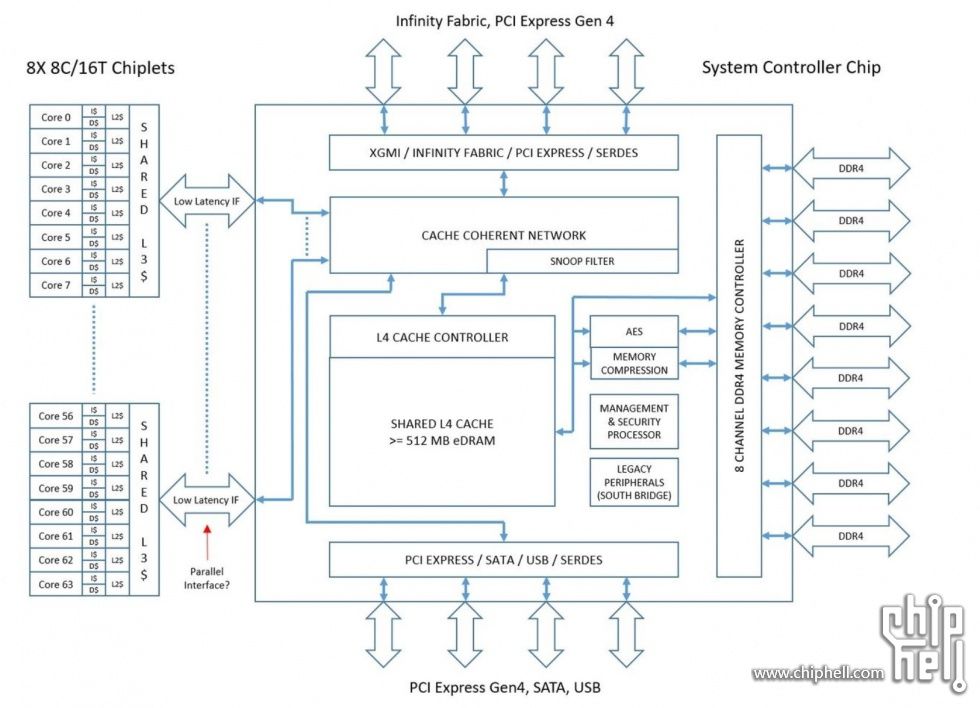
Érdekes a rajz, nagyon megy a spekuláció. Ha azt a 128 MB SRAM-ot rá tudta zsúfolni, akkor 512 eDRAM simán elfér, wikichip alapján egy eDRAM cella negyede sincs egy SRAM-énak a Glofo 14 nm-én.
-
#541
Petykemano
veterán
lezso6
#540
Petykemano
veterán
Annak esetleg látnám létjogosultságát, hogy az egymás melletti chipletek közvetlen módon kommunikáljanak egymással ezzel megtartva valamiféle strukturális visszafelé kompatibilitást az EPYC1-gyel, ahol szintén volt olyan, hogy lapkán belüli magok a lapkán kívüli magokhoz viszonyítva gyorsabb eléréssel rendelkeztek. Így minden optimalizálást, amit az EPYC 1 megkap, áthozható a ROME-hoz is és vica versa, minden ROME optimalizálás értelmet nyer az EPYC1-nél is.
Amúgy looncraz is rajzolt egyet:
![[link]](http://files.looncraz.net/Zen_2_AMD_Rome_IOLayoutTheory.jpg "[link]")
"Decided to throw together a roughly scaled (probably should have been wider and slightly shorter) version of the IO chip using the Zepplin die shot.
This includes everything we know (ahem.. or believe) to exist on the IO die (8 IFOPs, 128 PCI-e lanes, 8 DDR4 channels, etc...) and all of the strange unknown blocks from the Zepplin die. And there was enough room to add 128MiB of L4.. using the L3 from the CCXes directly.
I estimated ~26ns nominal latency to any IFOP from the L4, which is half the latency as to main memory - and with potentially more than double the bandwidth reaching a chiplet (400GB/s). Latency to the L4 from a core would be hard to estimate, but it would be 20~30ns faster than going to main memory, so it's a big win."
-

Simid
senior tag
"...meg lehet spórolni egy IF utat a másik processzorlapkához, feleződik a késleltetés... Ugye az eddigivel ellentétben az I/O lapkás megoldás annyiból fájó, hogy 2x kell átmenni az IF-en a másik oldalra."
Na erre írtam azt korábban, hogy nem tudom honnan jön a feltételezés, hogy így működik. Kiindulva a korábban linkelt NVSwitch működéséből (ahol 16(!) GPU tud kommunikálni egymással, úgy hogy bármely kettő esetében elérhető a max sávszél és a min a késleltetés) itt sem tűnik lehetetlennek egy olyan összeköttetés kialakítása amiben két CCX (most feltételezem, hogy egy 8 magos die az egy CCX) ugyan olyan gyorsan éri el egymást mint bármi mást az I/O dieon belül, még úgyis, hogy egymással nincsenek közvetlenül összekötve. Fizikailag persze ez az ember benyomása, hogy ez két lépcsős folyamat, de az adat a vezetékben fénysebességgel megy szóval az a pár centi nem fog számítani, hogy die-on belül vagy kívül.

Innentől meg csak topológia kérdése, hogy hogyan működik.
(Mondjuk tényleg borítja az egész okoskodást, ha a lapkák még egymással is direkt összeköttetésben vannak.)"Mivel elvileg 64 MB L3 lenne egyenként mind a 8 lapkában, ezért legalább 512 MB-os L4 kell, hogy ez működhessen."
Nekem az utolsó infóm (pletykák) az, hogy 256MB L3 van összesen tehát 32MB van egy lapkában.
De még ez is brutál nagy lenne és kell hozzá ugye egy nem kicsi vezérlő. Ez a legfőbb kételyem a nagyméretű L4 cache-sel kapcsolatban. 8 DDR4 vezérlő, 128 PCI4.0 lane, fullos SB és egy felhizlalt IF van abba az I/O dieban, ha emellé még beraktak több száz MB L4 cachet akkor minden elismerésem nekik. -
Az eDRAM L4 arra jó lenne, hogy inkluzív, azaz az összes L3 benne van. Így meg lehet spórolni egy IF utat a másik processzorlapkához, feleződik a késleltetés. Mivel elvileg 64 MB L3 lenne egyenként mind a 8 lapkában, ezért legalább 512 MB-os L4 kell, hogy ez működhessen.
Ugye az eddigivel ellentétben az I/O lapkás megoldás annyiból fájó, hogy 2x kell átmenni az IF-en a másik oldalra. Miközben a Naples-nél közvetlenül össze volt kötve az összes lapka.
Azonban lehetséges, hogy azért nem csak az I/O-val lesz összekötve minden Zen2 lapka.

Párosával vannak, szóval eléggé gyanús, hogy ezek az egymás melletti chipek össze lesznek kötve IF-fel. Sőt, lehet még több IF kapcsolat lesz. Így viszont az L4-nek nem igazán van értelme.
-
#537
Simid
senior tag
Petykemano
#535
Simid
senior tag
válasz
Petykemano
#535
üzenetére
"zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés"Igen, ismerem ezt a grafikont. Pont ez az a rész amit nem értek. Ugye van egy 8MB-os rész ami gyorsan elérhető az adott CCX számára. Aztán van egy kevésbé gyorsan elérhető 8MB L3 (kvázi L4). És TR vagy EPYC esetében további 16/48MB L3 (kvázi L5) ami még ennél is lassabban elérhető.
Az Intel esetében az eDRAM a die-on volt, így gyorsan elérhető volt. Ilyen a Rome esetében úgy néz ki nem lesz.Továbbra sem kétlem, hogy egy L4 cache nagyon hasznos lehet szerver környezetben, főleg így, hogy a RAM elérés már minden esetben IF-el összekötött I/O die-on történik. De ez semmit nem fog javítani azon a problémán amit ez a lépcsős grafikon mutat nekünk. Egyszerűen megnövelik annak a cachenek a méretét ami lassan (de a rendszer memóriánál még mindig sokkal gyorsabban) elérhető.
Hogy röviden összefoglaljam, a közeli és gyorsan elérhető L3 hiányát nem lehet pótolni egy távoli és lassan elérhető L4-gyel. Gondolom ezért döntöttek a megnövelt L3 mellett.
"Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency."
Ez is megvan, de én úgy értelmeztem az előadásból, hogy ez nem fog változni a IF 2.0 esetében sem, csak szélesebb a link. Laikusként nézegetve az IF működését pl ezen leírás alapján nekem az jött le, hogy az SDF bár a mem órajelen üzemel a szinkronizáció miatt, de máskülönben független tőle. Ha ez nem így van és ténylegesen a rendszer memórián keresztül történik a kommunikáció, akkor máris értelmet nyer egy esetleges L4 cache.
-
S_x96x_S
addikt
( AMD Next Horizon )
újságirói kérdések - EPYC ROME
AMD Epyc Data Centre ROME Session 3 Nov 6 2018 (25perc )
https://www.youtube.com/watch?v=DaUy880vtRMvannak még más felvételek a Radeon Instict ; ROCm ; .. kistermes bemutatókról.
Lehet bogarászni Alex csatornáján
------
+ egyéb apróságok :
"A Look At The AMD EPYC Performance On The Amazon EC2 Cloud"
https://www.phoronix.com/scan.php?page=article&item=amazon-ec2-m5a&num=1"AMD EPYC for ATX Workstations: GIGABYTE MZ01-CE0 & MZ01-CE1 Motherboards"
https://www.anandtech.com/show/13566/amd-epyc-for-atx-workstations-gigabyte-mz01ce0-mz01ce1-motherboards -
#535
Petykemano
veterán
Simid
#534
Petykemano
veterán
zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés
Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency.,
Itt tökre jól látszik, hogy 8MB felett emelkedik a késleltetés

Egy L4$-sel pedig ezt lehetne kb elérni, amit az 5775C-nál látsz:
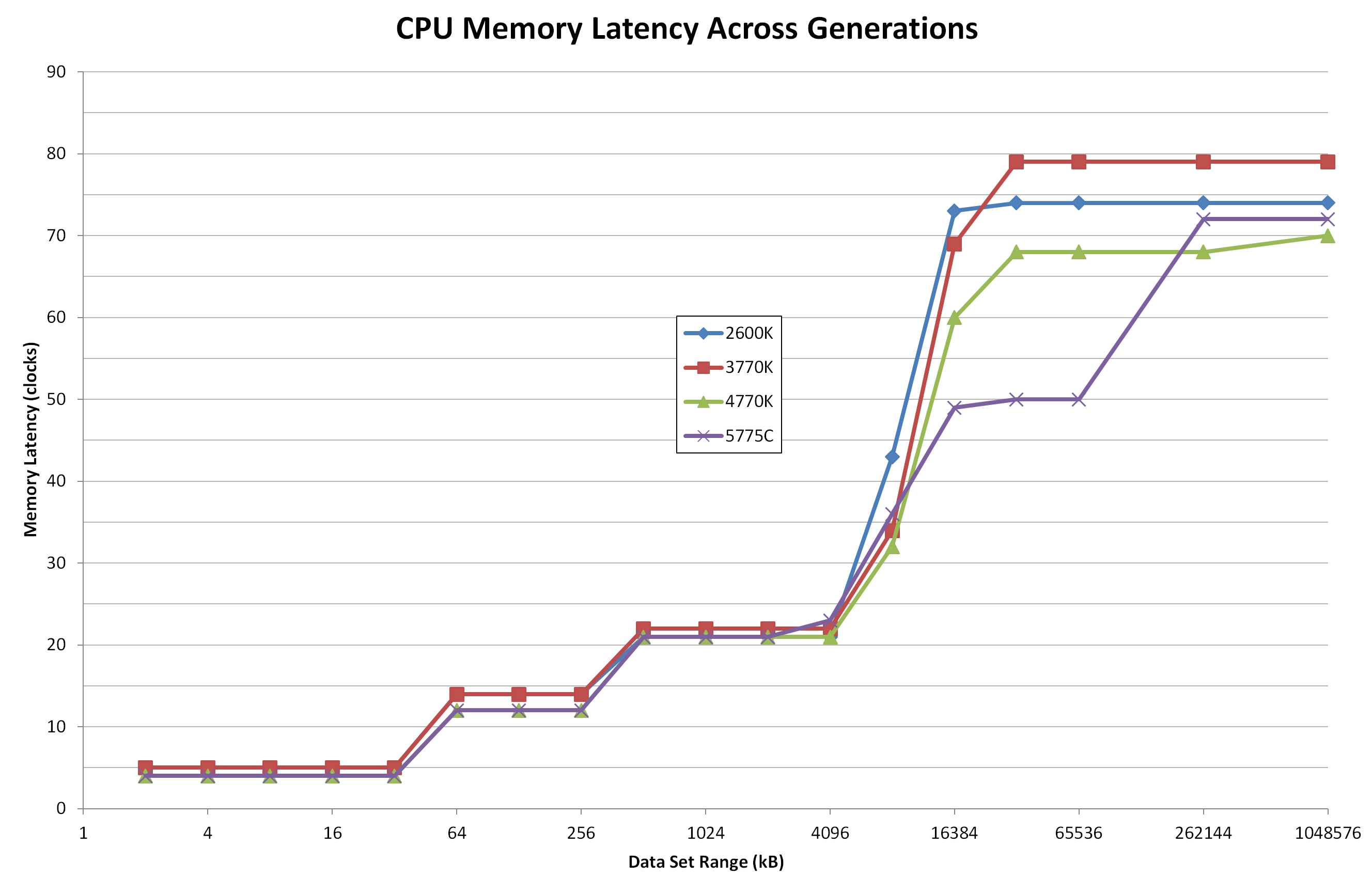
-
Simid
senior tag
válasz
Cathulhu
#533
üzenetére
"egyrészt a nagy L4-be prefetcher sokkal nagyobb szeleteket tud betölteni mint L3ba"
Erről fogalmam sincs, szóval elhiszem.
"másrészt így mind a 64 mag között lesz egy nagy közös cache, nem csak CCX páronként."
Úgy tudom az első gennél is megosztott az L3. Fizikailag persze szét van szórva, de legalább az adott CCX gyorsan hozzáfér a saját szeletéhez.Hogy kicsit magam ellen is beszéljek. A több cache nyilván mindig jó, csak nem mindenhol éri meg. Az I/O die cachenek meg van az az előnye, hogy szabadon variálható a különböző termékkategóriákra. Desktopra/HEDT-re úgyis más I/O kell majd valószínűleg. Ha a CCX-ek mellé rakják nincs meg ez a rugalmasság.
-
-
Simid
senior tag
válasz
Cathulhu
#530
üzenetére
Oké, értem én, hogy úgy általában mi a gyorstárazás előnye. Akkor pontosítok kicsit: Mi értelme egy IF-en keresztül elérhető L4 cachenek ebben az esetben?
Itt most lehet én értem félre az IF működését (illetve erről az új fajtáról nem sokat tudunk), de a probléma eddig az volt, hogy vagy a CCX saját cache-ben volt az adat vagy az IF-en keresztül kellett azt bekérnie, ahol viszont a többi CCX L3$ adataihoz is hozzáfér. Most ez annyit változott, hogy már a RAM hozzáférés is minden esetben IF-en keresztül történik, cserébe nagyobb a cache és szélesebb lett egy-egy IF link.
Ebből nekem az jön le, hogy bármit is csinál az I/O die, azt IF-en érkező utasítások alapján csinálja. Egy itt elhelyezett nagyméretű cache is csak az IF-en keresztül lesz hozzáférhető és semmivel nem lesz gyorsabb mint egy másik CCX L3$-éhez való hozzáférés. Akkor viszont felmerül a kérdés, hogy ha már több cachet szeretnének, akkor miért nem a CCX mellé rakják azt? Így legalább az adott CCX gyorsan érné el, de a többinek is gyorsabb lenne mint a RAM. Persze, értem én, hogy 7nm vs 14nm és SRAM vs eDRAM, szóval rohadt drága lenne. De az sem mellékes, hogy így legalább több die-on lenne elosztva egy hatalmas tömb helyett és ez viszont költség csökkentő tényező.
Lehet pont ezért duplázták meg a magonkénti L3 mennyiségét, mert hasonló módon gondolkodtak.Ha jól értem, ti azt feltételezitek, hogy az I/O die-on keresztül elérni egy másik lapkát nem olyan közvetlen elérés mint most a zeppelin esetében, hanem valami két lépcsős folyamat (CCX-I/O majd I/O-CCX). Így valóban lenne értelme a két lépcső közé cachet rakni. Én viszont úgy képzeltem ezt (megintcsak laikusként, lehet teljesen hibásan), hogy az I/O die egy IF switch, hasonlóan mint az NVSwitch. Ebben az esetben az IF-en keresztül bármi elérhető közvetlenül és így késleltetés szempontjából az hogy I/O die-on lévő L4 vagy egy másik CCX L3-a, az tök mindegy.
-
#531
lezso6
HÁZIGAZDA
Petykemano
#527
válasz
Petykemano
#527
üzenetére
Kiegyenesítettem a perspektívából a legjobban sikerült Rome fotót simára. A nyáklap 58.5 mm × 75.4 mm, szóval pixel-arányból kiszámolható melyik lapka mekkora. Zeppelinre így 220 mm2 jön ki, szóval egész pontos.
Eredmény: egy Zen2 lapka ~75 mm2, az I/O lapka meg ~430 mm2.
Hely szintjén meg lehet spórolni gyakorlatilag elég sok mindent. Csak az Infinity Fabric, PCIE, DDR4 vezérlő szentháromságra van szükség. Előbbi kettő új, így nem tudni mekkora, utóbbi ismert csak, kb 60 mm2 + körítés lenne legalább.
-
Cathulhu
addikt
CPUknal fontos az alacsony latency, ellentetben a GPUkkal, ahol a legfontossab a throughput. Ezert GPUn nem kell akkora cachet alkalmazni, a legtobb adat a nagy latencyvel elerheto global memoryban van, a local memoryk relative kicsik. CPUnal, ami rengeteg kulonbozo taskon dolgozik egyszerre ezzel ellentetben nem jarhato ut, hogy minden egyes adateleres a RAMon keresztul tortenjen, ezert kulonbozo prefetcherek dolgoznak azon, hogy azt az adat szeletet, amt valoszinusithetoen igenyelni fog a CPU, azt mar azelott lekerje a RAMbol, hogy valoban szukseg lenne ra. Ezt elhelyezi fontossagi sorrendben valamelyik cache-ben (L1, L2, L3). A nagyobb cache altalaban mindig extra teljesitmenyt hoz, mivel nem kell minden adatot RAMba irni es RAMbol olvasni, valamint a magok is tudnak egymassal adatot megosztani a kozos L2 vagy L3 cache-en keresztul, szinten megkerulve a RAM szinkronizaciot.
Azzal, hogy bevezetsz egy kulso vezerlot valamilyen szinten noveled a kesleltetest a RAM fele, hiszen a CCX mar nem tudja az adatot a sajat belso memoria vezerlojen keresztul szinkronizalni az o csatornajan levo RAM-mal, hanem mindenkepp egy kulso vezerlot kell erre megkernie. Viszont ha ennek a vezerlonek van egy hatalmas buffere, amibe rengeteg adatot tud prefetchelni (a tobb szaz megabajt hatalmas ebben az esetben), akkor viszont rengeteg esetben nem is kell a RAMhoz fordulnia, hanem azonnal ki tudja szolgalni a CPU-t L4 cachen keresztul, ami joval gyorsabb mint a masik eset.Szvsz pont CPUnal fontos az eDRAM vagy hasonlo megoldas, hiszen a legtobb program nem foglal sok helyet onmagaban, pl jatekoknal is a rengeteg hely a texturaknak kell, amik meg ugyis a GPU iranyaba fognak vandorolni pci-expressen keresztul. Pont GPU melle nem latom ertelmet a kis (pl 32MB-os) eDRAMnak, abbol azonnal kiszalad. Ez volt a kezdeti problema a kozos cache-es APUknal (azt hiszem az intel elso par generaciojanal), hogy a GPU azonnal teleszemetelte a kozos cachet, gyakorlatilag megfojtva ezzel a CPUt.
-
#529
Petykemano
veterán
Simid
#528
Petykemano
veterán
két lehetőség:
- 2 CCX közötti adatkommukáció meggyorsítása úgy, hogy az adatot ne a memórán keresztül kelljen cserélni (ez a feltétezés jelenleg az alapján, hogy a 2 CCX közötti késleltetés magasabb, mint a memóriahozzáférésé)
- memóriahozzáférés gyorsítása hagyományos cache funckióként.De a L4$ létezése még nem bizonyos.
-
#528
Simid
senior tag
Petykemano
#527
Simid
senior tag
válasz
Petykemano
#527
üzenetére
Ennek az eDRAM-nak mi lenne a funkciója amúgy? Értem én, hogy L4 cache, de miért érné meg ez egy CPU-nál? (Laikusként kérdezem, tényleg nem tudom)
A zeppelinhez képest nem csak a redundanciát kell szerintem figyelembe venni, hanem azt is, hogy ez egy jóval bonyolultabb IF, ami már 8 chipet képes összekötni. Gondolom ez nem kis különbség a korábbihoz képest.
-
#527
Petykemano
veterán
lezso6
#526
Petykemano
veterán
1000 az egész
65-80 között becsülgetik a chiplet méretét, ahhoz képest szemre ~5x nagyobb az IO chip.
75x8=600
75x5=375Ezek nem az én méréseim, becsléseim, csak amik szembejöttek.
Volt egy számítás, ami szerint a zen1ben a CCX 44mm2, kettő együtt mondjuk 90mm2 a maradék ~100 az uncore. Ebből 4 volt a naplesben. A kérdés az, hogy mennyi lehetett a redundancia az önállóan is működőképes zeppelin chipek miatt, amit ki lehetett vágni (usb, northbridge, huzalozás), aminek a helyére esetleg elfér eDRAM.
Ennek persze csak akkor van létjogosultsága, ha a zen2 chiplet mérete inkább nagy. Ha kisebb, az uncore is kicsi -
#526
lezso6
HÁZIGAZDA
Petykemano
#523
válasz
Petykemano
#523
üzenetére
1000 mm2? Wat, mi annyi?

Ha csak cellát számolok, akkor ~75 mm2 512 MB eDRAM GloFo 14 nm-en, ami eléggé apró, a HD SRAM ugyanígy számolva ~350 mm2-re jön ki. De ezt persze valamivel vezérelni is kell meg kérdéses a buszszélesség is.
-
#525
S_x96x_S
addikt
Petykemano
#524
S_x96x_S
addikt
válasz
Petykemano
#524
üzenetére
> Arra gondolsz ..
akár,
de fontos megjegyezni, hoy a memória probémákkat fókuszban tartja az AMD.
és tényleg nem mindegy, hogy egy szállra mekkora memória sávszélesség esik."Over the last decade, we have actually lost major grounds. In other words, the GPU and CPU are increasing in performance at a much faster rate than the memory bandwidth. The inability to feed the processors with data fast enough continues to increase and as the gap widens, memory bandwidth will exceed in severity the other barriers in the future."
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/3/"Full 3D Stacking" - van hosszú távon megcélozva, de rövid távon akár lehet tényleg egy 12/16 csatornás megoldás.
"Su’s ambitious vision didn’t stop with 3D stacking. She proceeded to explain a concept she called “full 3D stacking” whereby AMD would be able to stack the GPU on top of the CPU along with the HBM and NVRAM all together to form a “superchip” of a sort with incredibly high bandwidth and I/O communication between the data, the CPU, and the GPU."
...
"AMD believes that in the future workloads will become increasingly diverse and no one type of design would be able to attack every problem. “In the legacy world, the CPU was the center of everything.” Su said. But in the future heterogeneous architectures will take on a much more prominent role.
Su believes that there is a lot of opportunity in not only maintaining the rate of performance and efficiency but also accelerating the performance curve over the next ten years. “What I would like to say is that there is an opportunity to really bring in all of the conversation around 2.5D integration, 3D integration, multi-chip architectures, memory integration, and different types of memory so that we re-architect the system in a way that each of the components are able to get as efficient as possible.”"
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/4/
persze ettől nem lettünk okosabbak, de majd megátjuk milyen lesz a végleges Epyc ROME és az utódja.
szóval nem tudok semmit se ..
-
#524
Petykemano
veterán
S_x96x_S
#522
Petykemano
veterán
válasz
S_x96x_S
#522
üzenetére
Arra gondolsz, hogy a kifelé 8 csatornás DDR4 (később DDR5) megtartása mellett lepakolnak a feltételezett eDRAM helyére és/vagy üres helyre 4 stack HBM2-t (lásd Vega20) és HBCC-vel vidáman cachelgetnek 32GB-ban 1-1.2TB/s sávszélesség mellett?
Végülis könnyen lehet, hogy egy ilyen megoldással is könnyen tudnának.etetni 8-nél több chipletet.
-
#522
S_x96x_S
addikt
Petykemano
#519
S_x96x_S
addikt
válasz
Petykemano
#519
üzenetére
>Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot,
> ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat
>és a lapkán 12 chiplet kapna helyet?jó kérdés - spekulálásra tökéletes.
biztos elemzik az AMD-nél, de óvatosak - kicsi az erőforrásuk és egy ilyennek a bevezetése nem olyan rövid idő. Ha valamelyik partnernek lesz egy ilyen igénye - akkor lesz.
imho: A 12ch DDR4 akkor lesz fontos, hogyha memória sávszél limites lesz az EPYC(2;3;4) - és a DDR5 extrém drága lesz.
Vagyis ez lesz a szűk keresztmetszet.De talán a memória compresszálás valamit segíthet a sávszélességnél is
- és nem véletlenül van ott a Chiphell-es ábrán, ha már titkosítják a memóriát(AES), akor lehet előtte tömöríteni is. ha GPU-knál bejött miért ne lehetne a CPU-knál is ?
https://arxiv.org/pdf/1807.07685.pdfDe az EPYC CPU-nál a HBM bevetése is (elméleti) alternativa.
- "HBM is a new type of CPU/GPU memory (“RAM”) that vertically stacks memory chips, like floors in a skyscraper." https://www.amd.com/en/technologies/hbmnem tudom igazából,
de nem is zárom ki mint elméleti lehetőséget.Én a Deep learning miatt a hibrid HBM+DDR4/5 irányt forsziroznám inkább mnt a 12ch -t:
de 1 év múlva okosabbak leszünk. -
S_x96x_S
addikt
servethehome.com elemzés:
https://www.servethehome.com/amd-epyc-2-rome-what-we-know-will-change-the-game/
- Az új INTEL-s "Cascade Lake-AP" -t nem igen tartják "mainstream product"-nak.
- Talán csak az egyes licenszelt szoftverek esetén marad az INTEL versenyképes.
" Intel may retain the per-core performance lead which is important for many licensed software packages. In terms of total performance, Intel is going to be behind."de várjuk meg a tényleges végső termékeket és a teszteket.
Az AMD-nek nem érdeke a késlekedés. Ahogy kész a termék piacra fogja dobni.
De szerintem kell még félév mig piacra kerül.
Alaplapok és a szerverek már készen állnak - és akár komoly előrendelése is lehet. -
#520
lezso6
HÁZIGAZDA
Petykemano
#515
válasz
Petykemano
#515
üzenetére
Igen, most már világos. Én úgy értettem, hogy külön chip, stb. IF-fel így logikus meg az is, hogy miért ekkora az I/O (~300 mm2).

Számolgattam...
Az Intel 22 nm-en készülő 128 MB eDRAM-ja 84 mm2. Wikichip alapján csak cellákkal számolva 31 mm2 jön ki, ami ugye kevés.
De ha csak az Intel 22 nm és a GloFo 14 nm eDRAM cella méretéből arányosan szorzok, akkor az jön ki, hogy 202 mm2 512 MB eDRAM. Tehát az I/O chip kétharmadát vinné.Azonban nem hiszem, hogy 100 mm2-re ráfér minden I/O. TriTon számai alapján legalább 40 mm2 lenne egy alap uncore kiszerelés a Zeppelinből. Így 160 mm2-re jön ki a tiszta I/O. Emellé 256 MB eDRAM fér a fenti számolás szerint. Hacsaknem a tömbösítések miatt valahogy "megtrükközhető" kisebbre.
SRAM biztos nincs az I/O-ban. Az sokat fogyaszt és 3x akkora.
-
#519
Petykemano
veterán
S_x96x_S
#517
Petykemano
veterán
válasz
S_x96x_S
#517
üzenetére
Ez az egész nagyon flexibilis.
A Rome socket kompatibilis lesz a naples-szel. SP3. 8ch DDR4De most, hogy a cpu chipletek készek, bármi máshoz csak az IO chippel kell játszani. Lefelé quarter IO - ian cutress szerint.
Ha már ennyire nagy szám az intel 12ch ddr4 cascade lakeje...
Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot, ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat és a lapkán 12 chiplet kapna helyet?
-
S_x96x_S
addikt
Az AnandTech-es Ian Cutress - szerint
a Ryzen 3000-esek 2 chiplet + negyedakkora méretű IO -ból készülnek
( várhatóan, az ő tippje szerint )
"My money on two chiplets and a quarter IO die"+az új EPYC szerver támogatja az új 16Gb DRAM IC-ket is.
"Confirmed that @AMD @AMDServer Rome will support 4TB per socket with new 16Gb DRAM ICs after validation" @IanCutress -
#516
Petykemano
veterán
HSM
#514
Petykemano
veterán
Szerintem belefér AM4-be 2 chipletes 12 v 16 magos változat is. Méret, fogyasztás szempontjából mindenképp.
Ha az összekötő IO chipbe még EDramot is tesznek, azzal mindenképp megoldják a CCX-ek közötti kommunikációt és a 32MB/CcX és az edram együtt biztos jelentős mértékben tompíthatja a 2ch DDR terhelését.
Az ár még fontos. Frekvenciát még nem tudunk.. de ha a IF2, és az esetleges L4 kiküszöböli az eddigi CCx felépítésből adódó hátrányokat (latency) akkor már a 1x8 magos változattal is verhető a 9900K és a 2x6 és 2x8 változat is mehet a $400-700, ahol az ilyen magszámú TR1 jelenleg is vannak.Ha van L4, threadripperben biztos kisebb lesz az IO...
-

HSM
félisten
Mint írtam, akkor látom ennek értelmét, ha marad a több CCX-es felépítés, és azt is írtam, hogy akkor ez jó lenne gyorsabb adatcserés opciónak az új IF-on a CCX-ek között.
Illetve ezzel már a Threadripper is sokkal életképesebb lehetne, mint HEDT platform, lényegesen javulhatna a NUMA felépítés miatti egyenetlen (és sokszor magas) késleltetés, akár a magok, akár a memóriaterületek között. -
Hát, most azért, hogy néhol jó legyen, szerintem nem éri meg egy komplett lapkát odatenni a CPU mellé. E-pénisznek jó, de kb ennyi.
Az eDRAM elsődleges alkalmazása az SRAM cache kiváltása. Azaz ha valahol bazi nagy SRAM-ra lenne a szükség, akkor harmadakkora területen megoldható ugyanez eDRAM-mal.
-
S_x96x_S
addikt
Úgy néz ki, nagyjából bejött a 2018-09-25 -ös Chiphell-es leak.
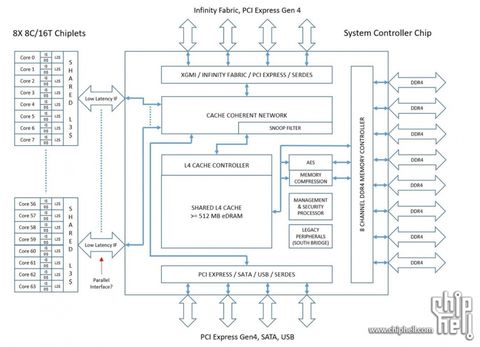
Talán az 512MB eDRAM is igaz.
De a memória tömörítés hardveres támogatása is érdekes. -
#510
HSM
félisten
Petykemano
#507
HSM
félisten
válasz
Petykemano
#507
üzenetére
"de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors"
Vélhetőleg az nem a másik L3-ból olvasott, viszont ha ott volt a szükséges adat aktuális állapota, akkor azt előbb vissza kellett menteni a rendszermemóriába, hogy utána onnan a másik CCX kiolvashassa.Ez nem nem volt gyors, és lassulást okozhatott, hanem keményen okozott is az erre fel nem készített alkalmazásoknak, lásd pl. az Nv drivert mikor megjelent a Ryzen.
Így viszont egy L4-el lehet csinálni egy viszonylag gyors köztes lépcsőt, amin keresztül a memória kihagyása nélkül, lényegesen gyorsabban lehet adatot cserélgetni a CPU csoportok között.
Amúgy vannak alkalmazások, amik nagyon szerették az L4-et, lásd pl. a PH tesztet: [link], egy esetben még az 5960X-et is odakente!
 [link]
[link](#509) lezso6: Bruteforce avagy sem, én AM4-en is szívesen látnék egy 32-64MB-ot belőle L4-ként, ha marad a több CCX-es felépítés.

-
#509
lezso6
HÁZIGAZDA
Petykemano
#507
válasz
Petykemano
#507
üzenetére
Egyelőre az Infinity Fabric 2-t kéne látni akcióban. Az eDRAM meglehetősen bruteforce megoldás.
-
#507
Petykemano
veterán
lezso6
#506
Petykemano
veterán
L4$ két okból lenne hasznos.
Egyrészt úgy tűnik, hogy a zeppelin esetén a 2 egy lapkán levő CCX között is nagy késleltetés volt. Az IF ugyan kezelte, hogy 2db L3 tömb van, de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors.UGyanez igaz most az epyc2-re is. Lehet, hogy egy CPU-nak egy másik CCX-ből kellő adat pont ott van a másik CCX L$-ban és a lokalizációt az IF lekezeli, de mégiscsak gyorsabb lehet, ha a IO lapka vissza adja, mintha át kell nyúlni a másik CCX L3-ába, és onnan vissza az IO-hoz és onnan az eredeti adatkérő cpu maghoz.
Másrészt segíthet önmagában a memóriaelérés gyorsítótárazásában is.
Ha jól emlékszem a broadwell használta L4.-ként a eDRAM-ot és némileg hasznára vált
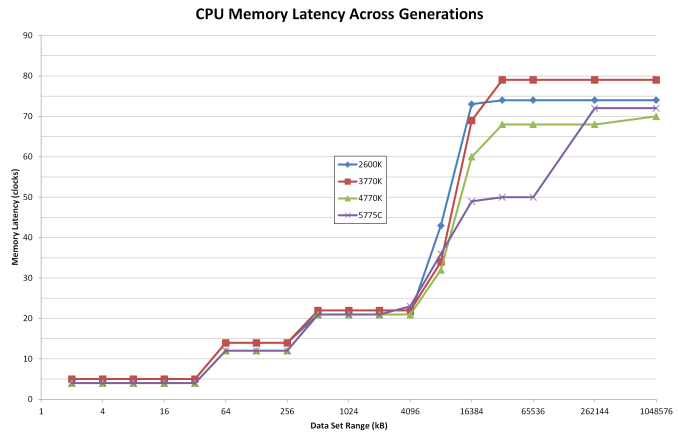
AT -
válasz
Cathulhu
#505
üzenetére
"Ha mindez igaz lenne (nekem tetszik az otlet) akkor Lisa hatalmas dobasa, gyakorlatilag ket legyet egy csapasra, olcso IO vezerlo a GloFotol, WSA teljesitve, mehet a fontosabb chiplet gyartas a fejlettebb TSMC-hez."
Az eDRAM-ot viszont nagyon nem értem. Miért lenne az jó? Esetleg azt tudom elképzelni, hogy IGP mellé pakolnak ilyet HBC-vel, de nem tudom képes lenne-e megfelelő sávszélre.
Ugye az Intelnél az eDRAM-ra azért van szükség, mert a GPU architektúrájuk nem skálázódik jól, ezért bruteforce módon eDRAM-mal támogatják.
-
Cathulhu
addikt
WSA a titok nyitja szerintem ahogy irtak feljebb is. Illetve adok azokra a feltetelezesekre is, hogy azon belul azert 14 es nem 12, mert igy tudnak eDRAMot is beletenni. Ami amugy az AMD szamara egy remek differencialo eszkoz lehet olcsobb es dragabb termekek kozott (kicsit mint pentium 2-nel a cache). Az meg nem akkroa gond, hogy az eDRAM nagy selejtarannyal gyarthato csak, hiszen a 14 nano mar tobb mint kiforrott, illetve lehet letiltogatni abbol is es a legangyobb opciokat aranyaron adni.
Ha mindez igaz lenne (nekem tetszik az otlet) akkor Lisa hatalmas dobasa, gyakorlatilag ket legyet egy csapasra, olcso IO vezerlo a GloFotol, WSA teljesitve, mehet a fontosabb chiplet gyartas a fejlettebb TSMC-hez.
-
#503
lezso6
HÁZIGAZDA
Petykemano
#501
válasz
Petykemano
#501
üzenetére
Jó, ez jogos, ott az OEM. De azért ha nem gyárt a procikhoz ott semmit, az jelentős kiesés a GloFo-nak szerintem.
-
#501
Petykemano
veterán
lezso6
#500
Petykemano
veterán
Ott készül a Subor+ chipje, és a vega12 is (az apple-nek) 14nm-en. És a raven ridge is.
12-n a polaris30, a pinnacle ridge még fél-háromnegyed évig (bár szerintem ez ugyanaz a gyártósor, csak újabb maszk vagy ilyesmi)
Ezzel együtt a GF 14 még mindig olcsóbb lehet egy ilyen amúgylóbaszónagy méretű chipnél, mint a TSMC 16. Ez az IO lapka nagyobb, mint a vega10!



















 Ezzel azért alaposan feladnák a leckét a konkurenciának.
Ezzel azért alaposan feladnák a leckét a konkurenciának.

Új hozzászólás Aktív témák
- INGYEN POSTA - ÚJ GAMER PC - Ryzen 5 5600 - RTX 4060Ti - 16GB RAM - 1TB SSD - www.olcsogamerpc.hu
- 830 G11 13.3" FHD+ IPS Ultra 5 125U 32GB 512GB ujjlolv IR kam gar
- Precision 5550 15.6" 4K+ IGZO érintő i7-10850H T1000 16GB 512GB NVMe ujjlolv IR kam gar
- INGYEN POSTA - ÚJ GAMER PC - i5-10400F - RTX 3060 12GB - 16GB RAM - 1TB SSD - www.olcsogamerpc.hu
- Pc kompletten
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest