- sziku69: Szólánc.
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- f(x)=exp(x): A laposföld elmebaj: Vissza a jövőbe!
- eBay-es kütyük kis pénzért
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Luck Dragon: Óraátállítás
- gban: Ingyen kellene, de tegnapra
- PSti: Total Commander - Memória duplázás!
- Luck Dragon: MárkaLánc
Új hozzászólás Aktív témák
-
#1600
 pittbaba
aktív tag
Sk8erPeter
#1599
pittbaba
aktív tag
Sk8erPeter
#1599
pittbaba
aktív tag
válasz
 Sk8erPeter
#1599
üzenetére
Sk8erPeter
#1599
üzenetére
Látatlanban? Ott van minden már, épphogy az adatbázist nem csatoltam

Indexelni melyik táblákat érdemes? Egyelőre csak a stop_times.stop_id-t, és a stops.stop_name -t indexeltem. Explain-t nem vágom, guglizom, nézem, de jöhet tipp! -
#1599
 Sk8erPeter
nagyúr
pittbaba
#1596
Sk8erPeter
nagyúr
pittbaba
#1596
Sk8erPeter
nagyúr
válasz
 pittbaba
#1596
üzenetére
pittbaba
#1596
üzenetére
látatlanban: indexelés, EXPLAIN?
Szerk.: ja, most látom, hogy írtad is (csak átfutottam a kérdéseden):
"Olvastam, hogy létre lehet hozni index-et a tábla oszlopaihoz, milyen oszlopokhoz érdemes?"
legalább próbálkozz egy EXPLAIN-nel. Na de konkrétabbat majd ha esetleg kipróbáltam (és elolvastam normálisan a kérdésedet![;]](//cdn.rios.hu/dl/s/v1.gif) ), meg ha addig nem érkezik másik válasz.
), meg ha addig nem érkezik másik válasz. -
pittbaba
aktív tag
Itt a BKK GTFS db, csak hogy ne kelljen keresgélni:
[link]Példák:
stops:
stop_id,stop_name,stop_lat,stop_lon,location_type,parent_station,wheelchair_boarding
F00001,"Mihály utca",47.486079,19.034561,,,2stop_times:
trip_id,arrival_time,departure_time,stop_id,stop_sequence,shape_dist_traveled
A651191,03:46:00,03:46:00,F04679,010,0trips:
_id,service_id,trip_id,trip_headsign,direction_id,block_id,shape_id,wheelchair_accessible,trips_bkk_ref
6100,A65119ASZGPP-021,A651191,"Örs vezér tere M+H",1,A65119ASZGPP-021_10A,1226,2,61001A gps koordináta kerekítés elve megvan, de mivel az szerintem még lassabb lesz, egyelőre megálló névre keresek rá:
SELECT stop_name,stops._id,stop_times._id,trips._id FROM "+MYDATABASE_TABLE+" JOIN stop_times ON stops.stop_id= stop_times.stop_id JOIN trips ON stop_times.trip_id = trips.trip_id WHERE stops.stop_name LIKE '%"+searchstr[0]+"%' GROUP BY stop_times.stop_id"
Ha azt kérem: Deák tér, meg is kapom vissza, szóval megleli, de kb 10 perc alatt, mert a stop_times tábla nagyon nagy és végig kell nyálazza. Olvastam, hogy létre lehet hozni index-et a tábla oszlopaihoz, milyen oszlopokhoz érdemes? Ez után az eredeti lekérdezést kell használni továbbra is, csak az adatbázison gyorsít valamennyit?
Nem tudtam jól megfogalmazni a módosítással mit akartam mondani. A lényeg, hogy lenne olyan megoldás is, hogy a három táblából csinálok egy leegyszerűsítettet, melyik GPS koordinátákhoz mely járatok tartoznak, viszont mivel az alapformátum CSV és a célformátum mysqlite db fájl, nehéz olyan scriptet írni ilyen sok sorú fájlnál, ami nekem ezeket összemergeli egy táblába logikusan. A kész db táblákból csinálni egy újat is lassú, mert ugyanúgy soronként kell haladni.
UI: A GPS koordináták kerekített lekérdezését így oldom meg, hogy legyen hibahatár:
SELECT * FROM "+MYDATABASE_TABLE+" WHERE ( stop_lat > '"+latstart+"' AND stop_lat < '"+latend+"' ) AND (stop_lon > '"+lonstart+"' AND stop_lon < '"+lonend+"')Egyszerű, működik, de gondolom bazi lassú lesz :S
-

modder
aktív tag
válasz
pittbaba
#1594
üzenetére
érdekes probléma, és ebből nem tudjuk meg, hogy miért lassú.
Azt mondod gps koordináták alapján akarod kiszedni, hogy melyik megállóban áll. Be tudnád írni a pontos lekérdezést, és egy-egy sor példát a három táblából? Feltételezemm, hogy a telefon nem pont ugyanazt a gps koordinátát fogja visszaadni, amit a táblában tárolsz, tehát ilyen kisebb-nagyobb összehasonlításokat végzel, ami elég költséges lehet.
Plusz nem értem, hogy miért nehéz bármit is változtatni az eredeti formátumon. Gondolom úgy működik, hogy az ember wifi közelben updateli az adatbázist, ekkor akármilyen transzformációt csinálhatsz rajta, majd úgy mented el az SQLite adatbázsiban, ahogy akarod. Keresésénél kell gyorsan működnie, nem updatenél
-
pittbaba
aktív tag
Sziasztok!
Androidra fejlesztek BKV programot, ennek az adatbázisához kellene finomításhoz segítség, tipp nekem.
A BKV kiadja a teljes menetrendet a Google GTFS adatbázis formátumban.
Ebből készítek egy programmal egy SQLite adatbázisfájlt, amit az alkalmazás felhasznál az adatok kivételére.
Ez egy 159Mb-os adatbázis file, egy telefonnak elég leterhelő, sajnos egy lekérdezés több perc jelenleg.Gps koordináták alapján próbálom kiszedni a user melyik megállóban áll, és milyen járatok haladnak át azon a megállón.
Három táblát kell ehhez felhasználnom:
stops táblában vannak a megálló nevei és a GPS koordináták
stop_times táblában az időpontok vannak megadva, melyik percben melyik megállóban melyik járat megy(id)
trips táblában vannak a trip id-hoz tartozó nevek.Egyértelmű, hogy a stop_times tábla nagyon nagy, úgy emlékszem, hogy 200 000 sor körül van, e miatt nagyon lassú lesz a lekérdezésem. JOIN-al összekapcsoltam a három táblát, az eredmény több perc után, de megérkezik helyesen egyébként.
Hogy lehetne gyorsítani a lekérdezést?
Az adatbázis feldarabolása nem jó, mert megállókra lehetne szétbontani, de az is 4000 fájlt jelentene, ami megint nem megoldás.Mivel létre kell hozni egy külön SQLite adatbázis fájlt, nehéz bármit is változtatni az eredeti formátumon, mivel a GTFS fájlok sima CSV formátumú fájlok, nem könnyű dolgozni velük.
Milyen tippekkel tudtok segíteni?
-
#1589
 rum-cajsz
őstag
Apollo17hu
#1588
rum-cajsz
őstag
Apollo17hu
#1588
rum-cajsz
őstag
válasz
 Apollo17hu
#1588
üzenetére
Apollo17hu
#1588
üzenetére
Ez az SQL szabvány szerinti, de csak az Oracle esetén új, más adatbáziskezelőkben ez volt a megszokott
from egytabla t1
join kettotabla t2 on t1.id = t2.id
join haromtabla t3 on t1.id = t3.idEz a leegyszerűsített, az Oracle optimalizáló állítólag ezt jobban szereti:
from haromtabla t3, kettotabla t2, egytabla t1
where t3.id = t1.id
and t2.id = t1.idMellesleg az új Oracle esetén azt jelenti, hogy kb. 10-12 éve került bele....

-
#1588
 Apollo17hu
őstag
Apollo17hu
őstag
Apollo17hu
őstag
Sziasztok!
Erre a régi meg új szintaktikára tudnátok egy-egy nagyon rövid példát írni? Miben jobb az új és miért? Van előnye a régi használatának? Köszi!
-

martonx
veterán
válasz
 rum-cajsz
#1586
üzenetére
rum-cajsz
#1586
üzenetére
Ezért is hangsúlyoztam mindenhol, hogy az Oracle-el felületesek (mondjuk azok nem túl pozitívak) az ismereteim, és egy szinte ismeretlen rendszerről nem volna etikus véleményt mondanom. Pláne, hogy történelmi okok miatt máig a legelterjedtebb db, annyira nem lehet rossz.
Őszintén én is bármit el tudok képzelni az Oracle db motor működéséről, de mivel az Oracle-höz bevallottan nem igazán értek, és db motor flame-be se akarok belemenni, maradjunk abban, hogy Oracle esetén akár igaz is lehet, hogy biztos ami biztos alapon érdemes a régi join szintaktikát használni. -
rum-cajsz
őstag
válasz
 martonx
#1585
üzenetére
martonx
#1585
üzenetére
Ó, én az Oracle optimalizáló fejlesztőiből bármit ki tudok nézni, annyi minden
"faszsággal"érthetetlen dologgal találkoztam már. Ebbe belefér az is, hogy a joint rosszul (értsd: nagyobb költséggel) értelmezi egyik illetve másik esetben.
De lehet, hogy csak a rosszindulat beszél belőlem, és mostanra már tényleg szép és jó az Oracle join szintaxisokkal. -
martonx
veterán
válasz
rum-cajsz
#1584
üzenetére
MS SQL optimalizációit ismerve nagyon nem mindegy, hogy az sql motornak néhány soros (hangsúlyozom néhány), vagy ennél több, mondjuk pár százezer adattal kell dolgoznia. De hogy 100.000 vagy 100.000.000 az már édesmindegy. Klasszikus optimalizálási hiba tud lenni, hogy pár sornyi teszt adatokkal az sql-t beoptimalizálja a motor, majd amikor mindezt ráengeded 100.000-re akkor csodálkozol, hogy miért lassú.
De hogy jön ez a join-olás régi vagy új szintaktikájához? Nehogy már a használt join szintaktika határozza meg az sql motor optimalizálását. -
martonx
veterán
válasz
rum-cajsz
#1582
üzenetére
hehe, ezen tényleg csak nevetni lehet.
Mondjuk ezt többször is hangoztattam, hogy leginkább MS SQL, PostgreSQL vonalon mozgok, néha egy kis MySQL-el, Oracle-el fűszerezve. Azért megkérdezném azt az oktatót, hogy mire alapozza amit mond (évtizedes berögzülés nem számít, illetve az Oracle 9i-re hivatkozást sem fogadom el érvként), és ugyan mutasson már egy példát. -
-
martonx
veterán
bocsánat, nem fogalmaztam pontosan, természetesen a join-ban használt alselectre gondoltam, azt hittem ez a szövegből egyértelműen kiderül. De ezek szerint nem. Senkit nem szeretnék félrevezetni!
Szóval az egyértelműség kedvéért: A select-be ágyazott alselect a legrosszabb megoldás (még ha gyarkan az engine ki is tudja optimalizálni, de erre ne építsünk!). A join-ba ágyazott alselect viszont nagyon hasznos tud lenni. -
martonx
veterán
2013-ban nem illik ilyen old school join-okat csinálni. Írd át modern sql szintaktikára:
from egytabla t1
join kettotabla t2 on t1.id = t2.id
join haromtabla t3 on t1.id = t3.idA hiba pedig elég egyértelmű. A három tábla descartes szorzata túl sok sort adna vissza, és (shared hosting környezetben jellemzően direkt) le van korlátozva a mysql memória használata, join-ok mérete.
Ezt elkerülni úgy tudod, hogy vagy megpróbálod átkonfigurálni a mysql-t, ha nem vagy hosting környezetben akkor ez menni fog.
Vagy alselecteket használsz, és megpróbálod csökkenteni a join-olt táblák visszaadott sorainak számát. Erre jó lehet akár egy szigorúbb feltételes join is. Az is lehet, hogy az id kapcsolat nem jó, és ez miatt többszörőződik meg indokolatlanul a join.
Vagy átmész egy rendes hosting-hoz, ahol nincs ilyen korlátozás. -

Jim-Y
veterán
sziasztok
3 táblából szeretnék lekérdezni, mysql-ben, az elején csak két táblából kérdeztem le, az futott rendesen, így:
SELECT table_1.id as ROW_1, SUM(table_1.VALAMI) as ROW_2, SUM(table_1.VALAMI) as ROW_3, SUM(table_1.VALAMI) as ROW_4, [B]table_2[/B].akarmi as isAKARMI
[B]FROM EGYTABLA as table_1, MASIKTABLA as table_2
WHERE table_2.id = table_1.id[/B]
GROUP BY 1
ORDER BY 3A kiemelt részek a fontosak, mert így működött, ellenben ha a
FROM EGYTABLA, MASIKTABLA, HARMADIKTABLA -sorra kicserélem a fentit, akkor egy ilyen hibát dob:
#42000The SELECT would examine more than MAX_JOIN_SIZE rows; check your WHERE and use SET SQL_BIG_SELECTS=1 or SET SQL_MAX_JOIN_SIZE=# if the SELECT is okay
A kérdés tehát: hogy lehet három táblát összekapcsolni egy selectben? van egy oszlop, amivel a három táblát össze tudom kapcsolni, ez az "id".
Próbáltam így is:
SELECT ...
FROM [B]EGYTABLA_CI [/B]as tabla_1
INNER JOIN [B]MASIKTABLA [/B]as tabla_2 ON tabla_1.id = tabla_2.id
INNER JOIN [B]HARMADIKTABLA [/B]as tabla_3 ON tabla_1.id = tabla_3.id
...üdv
megj: rákerestem a hibára, de nem lettem okosabb
 amit ír az error, azt pedig nem tudom hova kéne beilleszteni a queryben.
amit ír az error, azt pedig nem tudom hova kéne beilleszteni a queryben. -

Dave-11
tag
Úgy gondoltam, hozzátok fordulok a kérdésemmel:
Nem konkrétan SQL a téma, hanem MS Acces. Az lenne a lényeg, hogy van egy táblám, benne személyekkel, és van egy Neme mező, ahol 0 vagy 1 található (0 ha nő, és 1 ha férfi). Ehhez készítek egy jelentést, és hogy tudnám megcsinálni azt, hogyha a Neme értéke 0, akkor Nőt írjon ki, ha pedig 1, akkor Férfit, mert egyébként ugye a számokat írja ki, de úgy meg elég csúnya. -

cucka
addikt
válasz
martonx
#1563
üzenetére
Ez miért előnye a php-nak? Miért más nyelveken mit tárolnak a verziókövetőben? Szerelmes verseket?
Annyi előny, hogy nem kell lefordítani, megszabadulsz a Make/Ant szkriptektől, vagy az xml-ek turkálásától Mavenben, stb. . (Meg persze bizonyos szempontból ez hátrány is, tudom jól, ne akadj fenn ezen)A relációs SQL az egy rohadt nagy halmaz, rengeteg alhalmazzal, amik között halmaz műveleteket tudsz elvégezni rohadtul gyorsan. Hol akarsz ebben fejlődést? Legyenek örökölhetőek, interfészelhetőek a tárolt eljárások?
Ha alkalmazáslogikára szeretnéd használni, akkor szélesebb körű beépített libeket, és igen, több nyelvi eszközt.Ráadásul vicces pont PHP oldalról fanyalogni az SQL nyelv egyszerűsége miatt...
Az egy dolog, hogy a php egy nem túl jól kitalált nyelv, csomó furcsasággal, viszont a beépített eszközkészlete (magyarul a standard lib) igencsak jól használható és jól dokumentált.De hidd el, amikor komoly adatlogikákat kell kivitelezni, és komoly algoritmusokat kell kivitelezni, akkor azt próbáld már meg webszerver oldalon kivitelezni.
Emlékeztetlek, az eredeti hozzászólás a php topikban keletkezett, arra a felvetésre, hogy a php kódba nem kéne egyáltalán sql-t beágyazni/összerakni, hanem minden hasonló feladatot tárolt eljárással kéne megoldani. A php topikban pedig jellemzően nem a szakma krémje szokott kérdéseket feltenni, hanem kezdők.
Szóval igyekezz ennek tükrében értelmezni, amiket írtam. Én is pontosan jól tudom, hogy komplex projekteknél és nagy adatmennyiségnél az adatbázis szerver és kliens közötti kapcsolat overhead-je elszaladhat. Ennek ellenére nem fogom egyik kezdő php fejlesztőnek sem tanácsolni, hogy dobja ki a php-vel legyártott dinamikus sql-t és kezdjen inkább tárolt eljárásokat írni ezek kiváltására. -
martonx
veterán
"A php előnye, hogy a verziókövetőben található fileok halmaza és a futtatható kód egy és ugyanaz."
Ez miért előnye a php-nak? Miért más nyelveken mit tárolnak a verziókövetőben? Szerelmes verseket?"Félreérthető voltam, amire utalni szerettem volna, az a programozási nyelv (mondjuk PL/SQL) és annak a szolgáltatáskínálata, na ez az, aminek 60-as évekbeli hangulata van."
A relációs SQL az egy rohadt nagy halmaz, rengeteg alhalmazzal, amik között halmaz műveleteket tudsz elvégezni rohadtul gyorsan. Hol akarsz ebben fejlődést? Legyenek örökölhetőek, interfészelhetőek a tárolt eljárások? Legyen bennük lambda, meg generikus függvények??? Ráadásul vicces pont PHP oldalról fanyalogni az SQL nyelv egyszerűsége miatt...
"A többire kb. válaszoltam feljebb. A lényeg, hogy nem azt állítom, hogy tárolt eljárást írni rossz ötlet lenne, hanem hogy az esetek többségében nem ad semmilyen előnyt, cserébe növeli a komplexitást."
Ne általánosítsunk már ennyire. Lehet, hogy a te eseteid kimerülnek abban, hogy egy darab adattábla van a weboldalad alatt. De hidd el, amikor komoly adatlogikákat kell kivitelezni, és komoly algoritmusokat kell kivitelezni, akkor azt próbáld már meg webszerver oldalon kivitelezni. És ha készen vagy vesd össze a futásidőket. Tudnék mutatni olyan tárolt eljárásokat, amik több ezer sorosak, és percek alatt lefutnak. Az egyikkel konkértan egy 4 óra futásidejű webszerver oldali tákolmányt váltottunk ki.
Csak gondolj bele. Minden egyes db-hez fordulás idő. Ha van egy komplexebb feladat, amihez több db hívás kell, hívásonként visszad az sql szerver pár millió adatot. Utána for-al megforgatod az adatokat, megcsócsálod, majd visszaírod db-be, akkor az nagyságrendekkel könyebben, gyorsabban, optimalizáltabban elvégezhető db oldalon.
Az én eseteim pl. szinte minden esetben ilyenek. Mégse mondom azt, hogy az esetek többségében tárolt eljárást kell írni. Ehelyett maradjunk abban, hogy a helyzet dönti el, melyik megoldás a hatékonyabb a rendszer futása, terhelhetősége szempontjából. -
cucka
addikt
válasz
 sztanozs
#1551
üzenetére
sztanozs
#1551
üzenetére
Egyszerűen csak a szöveg alapú reprezentációt kell frissíteni és verziónként új adatbázist készíteni - nem pedig az aktuálist hozzáhegeszteni a fejlesztői verzióhoz. Ilyen módon az adatbázis felépítés (és a tárolt eljárásoik is) is egyszerűen verziókövethetővé válik.
Igen, ez így van. Lehet adatbázis deploy scripteket írni, nincs ezzel semmi gond. Az eredeti kérdésfelvetés viszont a php topikban volt, méghozzá azzal kapcsolatban, hogy a php kódban implementált alkalmazáslogikát megérné tárolt eljárásként megírni. Na ezzel így már problémák vannak:
- A php előnye, hogy a verziókövetőben található fileok halmaza és a futtatható kód egy és ugyanaz. Tárolt eljárásokkal elvesződik az előny.
- A legtöbb php-s projekt olyan kis léptékű, amin már egy adatbázis deploy script elkészítése és karbantartása is túlmutat.Nem azt mondom, hogy a tárolt eljárások ne lennének alkalmanként hasznosak, de abban a kontextusban, ahol felmerült a kérdés, egyáltalán nem tartom jó ötletnek.
A második szerintem csak sírás. Adatbázis oldalon bőven elég szerintem az a WSWG megoldás, ami a piacon elérhető - ha az nem felelne meg, amit a motorhoz adnak.
Mi az a WSWG?(#1555) martonx
Szvsz SQL fejlesztői környezetek közül a legjobb az SSMS, de Oracle vonalon a Toad for Oracle is jó (csak ronda, mint a bűn)...
Félreérthető voltam, amire utalni szerettem volna, az a programozási nyelv (mondjuk PL/SQL) és annak a szolgáltatáskínálata, na ez az, aminek 60-as évekbeli hangulata van.A többire kb. válaszoltam feljebb. A lényeg, hogy nem azt állítom, hogy tárolt eljárást írni rossz ötlet lenne, hanem hogy az esetek többségében nem ad semmilyen előnyt, cserébe növeli a komplexitást.
-

iff
senior tag
Sziasztok!
Hátha tud segíteni valaki. Adott egy ubuntu 12.10 szerver, amin fut a PostgreSQL 9.1. Ennek a mentését szeretném, hogy automatikusan lefusson. Erre a script megvan ill. a cron is működne, de amikor eléri a pg_dump ... leáll. Ha WinScp-vel belépek és a scriptet kézzel próbálom futtatni akkor sem fut le. Terminálban root-ként a pg-hez jelszó beírása után indul is a backup és lefut. Amit eddig találtam, ott valami olyat írtak, hogy csatolni kellene az pg_backup.sh-t. Na ezt, hogy tudnám megcsinálni? (gondolom jelszó a probléma, nem tud hozzáférni az adatbázishoz)

Előre is köszönöm a segítséget. -
#1559
Sk8erPeter
nagyúr
Sk8erPeter
#1556
Sk8erPeter
nagyúr
válasz
Sk8erPeter
#1556
üzenetére
Hát ez is igaz, hogy ott nagyon OFF lenne.
Rájöttem, hogy a legtisztább az lenne, ha az illető jönne inkább ide témázni a dologról, talán végre konstruktív vita is kialakulhatna, "nem arról szólna végre a topic, hogy nááám múúúkodik az, hogy lekérjem a termékek táblából a 123-as id-jú termék nevét, mééé' neeem?" -
#1558
 lakisoft
veterán
Sk8erPeter
#1556
lakisoft
veterán
Sk8erPeter
#1556
lakisoft
veterán
válasz
Sk8erPeter
#1556
üzenetére
Ez nem kibeszélés, csak megvitatás. Egy rossz szót nem szóltam.

 .
. -
#1557
martonx
veterán
Sk8erPeter
#1556
martonx
veterán
válasz
Sk8erPeter
#1556
üzenetére
mert az egy php-s topik, minek offolni benne SQL fejlesztő eszközökről. Annak meg nem látom értelmét, hogy egy szemmel láthatóan nem képben lévő, ám annál arrogánsabb embert, megpróbáljunk picit is képbe hozni.
-
#1556
Sk8erPeter
nagyúr
rum-cajsz
#1552
-
martonx
veterán
válasz
 lakisoft
#1550
üzenetére
lakisoft
#1550
üzenetére
"- A tárolt eljárásként írt kódot nehézkes verziókövetővel használni"
Butaság, miért ne lehetne, bár valóban nem annyira triviális. Én pl. TFS-ben egy külön mappát tartok fenn a DB scripteknek, amik ugyanúgy verziókezelődnek."- Az adatbázisok által biztosított fejlesztői eszközök a 60-as évek színvonalát idézik"
Ez mondjuk nagyon függ attól, hogy milyen DB-t használunk. Szvsz SQL fejlesztői környezetek közül a legjobb az SSMS, de Oracle vonalon a Toad for Oracle is jó (csak ronda, mint a bűn), MySql vonalon szeretem a Toad for MySql-t (mysql-hez van kismillió jó SQL IDE), PostgreSQL-hez meg egészen használható a PgAdmin.Klasszikus hibás programozói attitűd, amikor valaki nem akar megtanulni SQL-ezni (pedig gyakran nagyon hasznos), hanem mindent java-ban, c#-ban, php-ben akar programozni. Én használok ORM-et (sőt mostanra csak ezt), de az ORM-el ha a feladat azt kívánja meg akkor tárolt eljárást hívok meg. Sokan az ORM-et is félreértik.
Attól, hogy ORM-et használ valaki, miért ne lehetne összerakni DB oldalon egy view-t, vagy egy tárolt eljárást, és azt használni ORM-mel? -

Lortech
addikt
válasz
lakisoft
#1550
üzenetére
Örökös vita a tárolt eljárás használata vagy nem használata.
Én egyik mellett sem kardoskodnék, mert ezer + 1 körülménytől függ, hogy adott fejlesztésben / ellenjavalt, érdemes / kell használni tárolt eljárásokat.
Csak egy a számtalan, neten fellelhető cikkből, threadből, ahol ez a téma: [link]
Szinte minden érvre lehet ellenérvet találni ebben a témakörben. Szerintem az a fontos, hogy jól ismerjük a lehetőséges megoldásokat, ezek előnyeit, hátrányait, így lehet jó döntéseket hozni a tervezés, implementáció során. -
válasz
rum-cajsz
#1552
üzenetére
Más kérdés persze, hogy a keretrendszerek gyakran (?) nem készítenek tárolt eljárásokat, csak összehegesztik az adatstruktúrát és legenerálják a műveleteket közvetlen SQL utasításokként.
De végül is nem mindegy, hogy az ember keretrendszert haszál, vagy speciális környezetet fejleszt. Természetesen egy kis fejlesztésnél keretrendszer használatával az ember nem fog minden adat-reprezentációt kézzel megvalósítáani, mivel pont azért használ keretrendszert, hogy ezzel ne kelljen foglalkozni.
-
rum-cajsz
őstag
válasz
lakisoft
#1550
üzenetére
A verziókezelés használata önfegyelem kérdése. Nem is értem miért ne lehetne a tárolt eljárásokat verziókezelni, hiszen végül is azok is csak sima szöveges "fájlok".
A második résszel meg egyszerűen nem értek egyet. Vagy mit nevez ő a XXI. század fejlesztői eszközének?
-
válasz
lakisoft
#1550
üzenetére
Az elsővel inkább az a gond, hogy a feljesztés előtt ha nincs rendes specifikáció, akkor az adattartalom és adat-reprezentáció komolyan változhat a fejlesztés során. Ilyen helyzetben tényleg hátrány lehet az adatbázis oldal verziókezelése. Azonban az adatbázis felépíthető tisztán text alapú utasításokon keresztül, amit már kezel a verziókezelő. Egyszerűen csak a szöveg alapú reprezentációt kell frissíteni és verziónként új adatbázist készíteni - nem pedig az aktuálist hozzáhegeszteni a fejlesztői verzióhoz. Ilyen módon az adatbázis felépítés (és a tárolt eljárásoik is) is egyszerűen verziókövethetővé válik.
A második szerintem csak sírás. Adatbázis oldalon bőven elég szerintem az a WSWG megoldás, ami a piacon elérhető - ha az nem felelne meg, amit a motorhoz adnak.
Ráadásul amint adatbázis szintű jogosultságkezelésre kerül sor nagyon nehéz bekorlátozni egy felhasználó tevékenységét, ha bármilyen tevékenységre kell jogának legyen bármelyik táblán, mert közvetlen adatbázis műveletekkel megy a lekérdezés, frissítés.
-
#1549
lakisoft
veterán
TheCompany
#1544
lakisoft
veterán
válasz
 TheCompany
#1544
üzenetére
TheCompany
#1544
üzenetére
Miért akarod leállítani a szolgáltatást?
-
#1548
Sk8erPeter
nagyúr
DonThomasino
#1547
Sk8erPeter
nagyúr
válasz
 DonThomasino
#1547
üzenetére
DonThomasino
#1547
üzenetére
Konkrétabban?
-
#1546
martonx
veterán
DonThomasino
#1545
martonx
veterán
válasz
DonThomasino
#1545
üzenetére
De hiszen ez kezdőknek szóló könyv. Onnan indul, hogy hogyan hozzunk létre táblát, meg hogy kérdezzük le select * from tabla-val. Mit akarsz ennél kezdőbbet? Hogyan installáljunk SQL szervert? Letöltöd netről, majd next-next-finish.
-
#1544
 TheCompany
csendes tag
TheCompany
csendes tag
TheCompany
csendes tag
Sziasztok!
Olyan kérdésem lenne, hogy MSSQL 08 Server R2-be lehet-e olyat csinálni, hogy SQL Server Agent Job-ba leállítani egy szolgáltatást, magyarán meg tudom-e oldani, valahogy, hogy pl. net stop dnscache?
Steppeket szeretnék feltölteni, hogy állítsa le a szolgáltatást, aztán második stepbe, hogy backupoljon egyet, aztán meg indítsa újra el az adott szolgáltatást.
Remélem valaki tud segíteni! -
válasz
martonx
#1542
üzenetére
Igen, már tegnap kiderült, hogy a szerver haldoklott, ezért volt lassú (most villámgyors). Ettől függetlenül még érdekelt a téma, és gondoltam megkérdezem a nálam tapasztaltabbakat, hogy van-e mód tovább gyorsítani az SQL-t. Mint írtam, egy más jellegű problémánál jól fog jönni a file-cache, de az kisebb jelentőségű, mint az első.
Kösz a válaszokat!
-
martonx
veterán
Rossz hírem van, mert ez tipikusan nem cache-elendő, nem cache-elhető eset. Illetve lehet próbálkozni a Zeratul által leírtakkal (bár mysql-nél pont ezt sem tudod megtenni). Pont erre való lenne az SQL, hogy szabadszavas kereséskor villámgyorsan kiszolgálja az alkalmazást.
Gondolom azért akarod cache-elni, mert lassúak a válaszok?
Pedig ez még nagyon nem is sok adat. Én a helyedben inkább annak néznék utána, hogy miért lassúak a válaszok, mert ennyi adat nem sok. Vagy eleve rossz a DB felépítése, vagy hiányoznak index-ek. -
válasz
martonx
#1540
üzenetére
Ok, leírom:
Van 3 táblám: ugyvitel_marka, ugyvitel_termek, ugyvitel_termek_altipus, ugyvitel_termek_tulajdonsag_kapcsolat
ugyvitel_marka: id, markanev; értelemszerűen márkanevek vannak benne, ~250 db.
ugyvitel_termek: id, ugyvitel_marka_id, termeknev: a termékek listája. Egyelőre ~17000 rekorddal.
ugyvitel_termek_altipus: id, ugyvitel_termek_id, ugyvitel_statusz_id, stb.. : termék alkategóriák listája. Szintén ~17000 rek.
ugyvitel_termek_tulajdonsag_kapcsolat: id, ugyvitel_tulajdonsag_id, ugyvitel_termek_altipus_id, tulajdonsag: ez tartalmazza a termékekhez tartozó tulajdonságokat (cikkszám1, cikkszám2, ismertető, stb...). Az ugyvitel_tulajdonsag_id a tulajdonság típusát azonosítja (csz, ismertető, stb.). Jelenleg ~110000 rekorddal.Ezekből kéne leválogatni márkanév, terméknév, csz1, csz2, és ismertető alapján (szabad szavas keresővel).
Az adatbázis tovább fog nőni, akár a többszörösére. MySQL-ről van szó.
-
martonx
veterán
Fordítsunk a dolgon. Azt mond meg mit szeretnél. Milyen program alá, milyen platformon, mindenféle részlet jöhet, amu publikus. Aztán megpróbálunk segíteni. Mert ennyi részletből "Kereséshez van szükségem erre, szóval egy 7*20000 soros táblát kéne a cache-ben tartani." nem sok minden derül ki.
-
válasz
martonx
#1533
üzenetére
Tisztában vagyok a memcache-sel, de úgy vélem, hogy ennél gyorsabb lenne SQL szerveren belül maradni, hiszen a VIEW már úgy lenne összeállítva, hogy a legoptimálisabb legyen lekérdezés-szempontból. Csak azt tartom "pazarlásnak", hogy minden lekérdezésnél frissíti a tartalmát. Kereséshez van szükségem erre, szóval egy 7*20000 soros táblát kéne a cache-ben tartani. Ez sok...
-
martonx
veterán
Azért a materialized view, illetve indexed view-k korántsem olyan hatékonyak, mint egy sima webszerver cache, mert ezek ha nem is olyan mértékben mintha elölről indulna mindegy egyes lekérdezés, de azért mozgatják az SQL-t. Az adatok felesleges mozgásáról, felesleges SQL-hez fordulásokról nem is beszélve. Szvsz nem is arra lettek kitalálva, hogy kvázi cache-t alkossanak bizonyos táblák felett, inkább az indexelt lekérdezéseket könnyítik meg nagyon komplex lekérdezéseknél (legalábbis MSSQL vonalon, ott használtam már indexed view-t).
-
-
martonx
veterán
Nem a táblát cache-eled, hanem a választ. Mondjuk ASP.NET-tel egy programsor beállítani az adott válasz cache stratégiáját. De gondolom PHP-ban se kivitelezhetetlen feladat normális cache stratégiát felépíteni.
Hogy jobban megértsd:
Kliens oldalon lekérsz adatokat. Ezt úgy teszed meg, hogy elküldöd a kérést a webszervernek, és az odafordul az SQL-hez, lekéri az adatokat, ezekből mondjuk json-t, xml-t, html-t csinál, és azt visszaküldi a böngészőnek (ami persze lehet vastag kliens, bármilyen program, csak manapság a böngésző a legelterjedtebb).
Nos ezt a webszerver választ tudod cache-eltetni, függetlenül attól, hogy mennyi sor van az sql tábládban. Adott kérdére mindig adott választ fog adni X ideig. Sőt továbbmegyek, a választ a kliensben is el tudod tárolni, így legközelebb még a webszerverig se fog eljutni a kérdés, mert a válasz már ott van a kliens memóriájában. -

bpx
őstag
válasz
martonx
#1529
üzenetére
egyáltalán nincs eltévedve, én nem feltétlenül cache-elnék alkalmazásoldalon (de persze én nem fejlesztő vagyok)
ezt úgy hívják, hogy materialized view [link]
Oracle-ben van, a többi RDBMS-ről nincs tapasztalatom
wiki szerint MS SQL-ben van hasonló, MySQL-ben csak workaround -
#1530
martonx
veterán
DonThomasino
#1527
martonx
veterán
válasz
DonThomasino
#1527
üzenetére
Tényleg csak pár hsz-t kellett volna visszaolvasnod...

-
Sziasztok!
Tudtok egy olyan parancsot/függvényt/módszert, amely ugyanúgy működne, mint egy VIEW, de nem frissülne a lekérdezéskor a tartalma, hanem mondjuk csak óránként?
Illetve mennyivel gyorsabb a lekérdezés egy VIEW-ból (hiszen frissítenie kell a szervernek a tartalmát), mintha én szedném össze az adatokat az összekapcsolt táblákból?
-
#1527
 DonThomasino
veterán
DonThomasino
veterán
DonThomasino
veterán
Tud valaki ajánlani egy jó könyvet ? az alapoktól és ha lehet magyart.
2008 és 2012 főleg üzemeltetéshez... -
#1526
bpx
őstag
csabyka666
#1525
bpx
őstag
válasz
 csabyka666
#1525
üzenetére
csabyka666
#1525
üzenetére
itt egy példa táblákkal, egy olyan alkatrésszel, ami 3 autóba is beépíthető
alkatrész
---------
cikkszám | alk_név | ...
---------------------------------
1 | féktárcsa | ...
2 | ablaktörlő | ...
autó
----
típusnév | gyártott_db | ...
---------------------------------
Audi | 10000 | ...
Suzuki | 50000000 | ...
Trabant | 10000000 | ...
kapcsolótábla
-------------
cikkszám | típusnév |
-----------------------------
1 | Audi |
1 | Suzuki |
1 | Trabant |
2 | Audi |szerk: javítottam mert a PH! máshogy értelmezi a tabokat
-
#1525
 csabyka666
veterán
bpx
#1524
csabyka666
veterán
bpx
#1524
-
#1524
bpx
őstag
csabyka666
#1523
bpx
őstag
válasz
csabyka666
#1523
üzenetére
igen, de a kapcsolótáblában
-
#1523
csabyka666
veterán
bpx
#1522
Hm, ez igaz. A lényeg, hogy én úgy akarok felvenni minden alkatrészt, hogy megadom a felvételnél, hogy melyik autótípusokba lehet beépíteni. Itt jön a következő gond, hogy például ugyanazt a féktárcsát beépíthetem 8 féle autótípusba is, akkor azt a rekordot 8x kell felvennem, csak más autókkal?
-
#1522
bpx
őstag
csabyka666
#1521
bpx
őstag
válasz
csabyka666
#1521
üzenetére
1. konkrétan Access-ben fogalmam sincs, nem használok Access-t
nyilván lesz az autó és alkatrész tábla az ábrán látható oszlopokkal és elsődleges kulcsokkal
lesz a kapcsolótábla, amiben idegen kulcs a másik 2 tábla elsődleges kulcsa2. kelleni semmit se kell
autót és alkatrészt is lehet felvenni a kapcsolótábla piszkálása nélkül
az autó és alkatrész tábla között nincs közvetlen kapcsolat
és a diagram szerint nem kötelező, hogy minden alkatrészhez tartozzon autó és fordítva sem (hiszen a * az lehet 0 is) -
#1521
csabyka666
veterán
bpx
#1520
-
#1520
bpx
őstag
csabyka666
#1519
bpx
őstag
válasz
csabyka666
#1519
üzenetére
"ha fel akarok venni egy alkatrészt, akkor meg kell adnom a kapcsolótábla "típus_név" mezőjét is, és így jelölöm, hogy milyen autóba passzol"
erre van a kapcsolótáblád, amit az alkatrész felvétele után tudsz beállítani
-
#1519
csabyka666
veterán
Üdv!
Lenne egy alap kérdésem. Access-es beadandót csinálok, és egy alap dologgal nem vagyok tisztában.
Itt egy kép, amivel kapcsolatban kérdezni szeretnék:
Ez egy részlet egy ER modellből. Mivel ez egy több-a-többhöz kapcsolat, a relációs modellben megvalósítom az egyedeket külön külön, plusz csinálok egy kapcsolótáblát, amibe belerakom az elsődleges kulcsokat. Eddig ok. Amit viszont nem tudok, hogy az adatokat hova, melyik táblába kell felvinni?
Én úgy érzésre azt mondom, hogy ha fel akarok venni egy alkatrészt, akkor meg kell adnom a kapcsolótábla "típus_név" mezőjét is, és így jelölöm, hogy milyen autóba passzol? Jól látom, vagy teljesen butaság, amit beszélek?Köszi!
-
#1518
lakisoft
veterán
Sk8erPeter
#1517
lakisoft
veterán
válasz
Sk8erPeter
#1517
üzenetére
Ez így van
 .
. -

Jeti1
tag
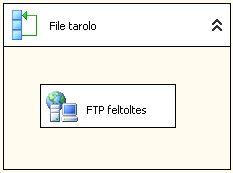
Utána néztem a dolognak, el is kezdtem megvalósítani a tervem, de problémám akadt. Az SSIS FTP Task Itemjét használva szépen fel és le tudok tölteni egy-egy fájlt az FTP tárhelyemről, de egyszerre többel már nem boldogulok. Érdekes módon letöltésnél (receive) a RemotePath résznél tudok joker karaktereket (?,*) használni, fetöltés (send) esetén a LocalPath résznél már nem, emiatt letölteni tudok egyszerre több fájlt, de feltölteni nem. Gondoltam használok egy For each Containert, összekapcsolva azt az FTP Taskkal, de ez sem hozta meg a várt sikert. Nem így kellene csinálnom vagy csak valahol valamit elírtam? Kellene kis segítség!
-
#1508
Inv1sus
addikt
Sk8erPeter
#1505
Inv1sus
addikt
válasz
Sk8erPeter
#1505
üzenetére
Sikerült, köszi. Tényleg sokkal egyszerűbb így.
-
#1506
 sztanozs
veterán
fordfairlane
#1504
sztanozs
veterán
fordfairlane
#1504
válasz
 fordfairlane
#1504
üzenetére
fordfairlane
#1504
üzenetére
megfelelő helyzetekben
-
#1505
Sk8erPeter
nagyúr
fordfairlane
#1504
Sk8erPeter
nagyúr
válasz
fordfairlane
#1504
üzenetére
De ilyen tagelés-kategorizálás esetében miért lenne már jó a pipe-karakterrel elválasztott módszer?
Indokot még nem írtál, szerintem jogos volt, hogy elég csúfnak találták a megoldást a többiek, meg én is.
Nehézkes és lassú lehet a keresése, nehezebb szűrni, eleve ez a LIKE-os megoldás elég hányadék. Nem is lehet normálisan végigiterálni a kapcsolt elemeken. Módosítás/törlés is problémás, és még elég sok más érvet is fel lehetne sorolni ellene.





![;]](http://cdn.rios.hu/dl/s/v1.gif) ), meg ha addig nem érkezik másik válasz.
), meg ha addig nem érkezik másik válasz.


















 amit ír az error, azt pedig nem tudom hova kéne beilleszteni a queryben.
amit ír az error, azt pedig nem tudom hova kéne beilleszteni a queryben.





















 .
.




Új hozzászólás Aktív témák
- Okos otthon - Home Assistant, openHAB és más nyílt rendszerek
- LEGO klub
- Kormányok / autós szimulátorok topikja
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Folyószámla, bankszámla, bankváltás, külföldi kártyahasználat
- Április 30-án rajtol korai hozzáférésben a Heroes of Might and Magic: Olden Era
- Robotporszívók
- Autós topik
- Óra topik
- Építő/felújító topik
- További aktív témák...
- Kingston 2TB KC3000 NVMe SSD - Garanciális
- Kingston FURY 32GB (2x16GB KF560C36BBEK2-32) DDR5-6000 CL36 - Garanciális
- S. Mario PC! Hogy fusson a Super Mario! I5 14400F / RX 6900XT 16GB / 32GB DDR5 / 1TB SSD
- XFX Radeon 7900GRE 16GB - garanciális
- Truecam M5 GPS WiFi autós menetrögzítő kamera + CPL Polarizációs szűrő + 64Gb Endurance kártya
- Licencek + laptopok + dokkolók
- 27% - MSI MAG 275QF IPS Monitor! 2560x1440 / 180Hz / 0.5ms / FreeSync
- 5G Lenovo ThinkPad P14s Gen 3 Intel Core i7-1280P Nvidia T550 32GB 1000GB 1 év teljeskörű garancia
- Bontatlan Oriflame Love Potion parfüm eladó
- 27% PNY GeForce RTX 5070 EPIC-X RGB OC 12GB GDDR7 192bit (VCG507012TFXXPB1-O) Videokártya
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest