Hirdetés
- MaxxDamage: (TongFang) Medion Erazer Beast 16 X1 benchmark
- GoodSpeed: A megfelelő matrac kiválasztása egy hosszú folyamat végén!
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- ubyegon2: Airfryer XL XXL forrólevegős sütő gyakorlati tanácsok, ötletek, receptek
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- btz: Internet fejlesztés országosan!
- Sapphi: StremHU | Source – Self-hostolható Stremio addon magyar trackerekhez
- Meggyi001: A végtelenbe...
- Invázió egy novellában 3-4. (Update) +5. fejezet! (18+ nyelvezet)
Új hozzászólás Aktív témák
-
#38156
 Petykemano
veterán
#45185024
#38155
Petykemano
veterán
#45185024
#38155
Petykemano
veterán
válasz
 #45185024
#38155
üzenetére
#45185024
#38155
üzenetére
Én inkább valahogy úgy illusztrálnám a problémát, mint a procikban a pipeline-ok.
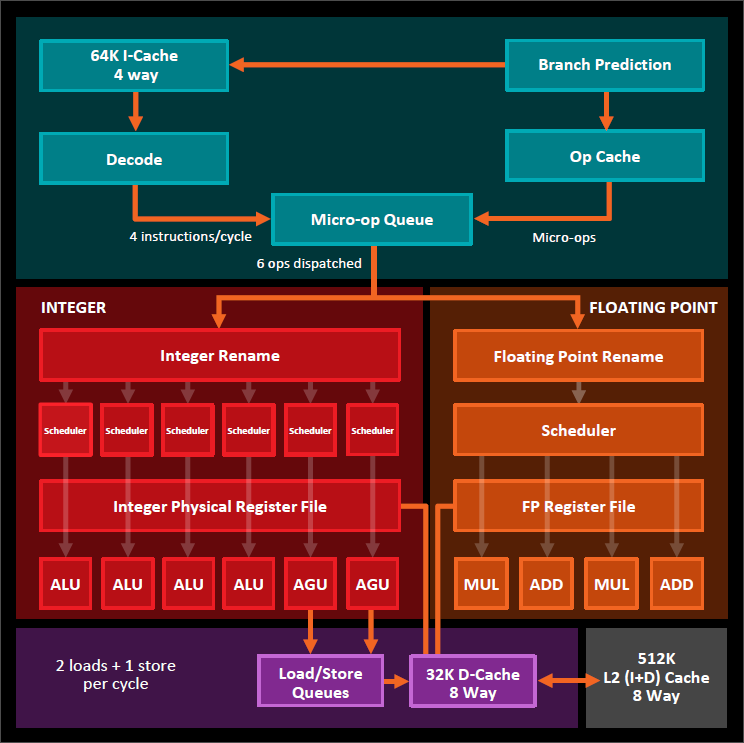
A zenben van 4 ALU egy magban. outoforder, tehát ügyesen sorrendezi a parancsokat, hogy minden órajelciklusban lehetőleg minden ALU-nak legyen - időzített - dolga. (ILP)
És még ez is úgy van, hogy a 4 ALU-t (meg az fpu-t) valójában akár 2 szál is tudja kezelni, kihasználni1 lapka -> 2 CCX (L3$/CCX) -> 2x4 mag (L1$ & L2$ / core) -> 2x4x4 ALU
Tehát 4 ALU / L1$+L2$
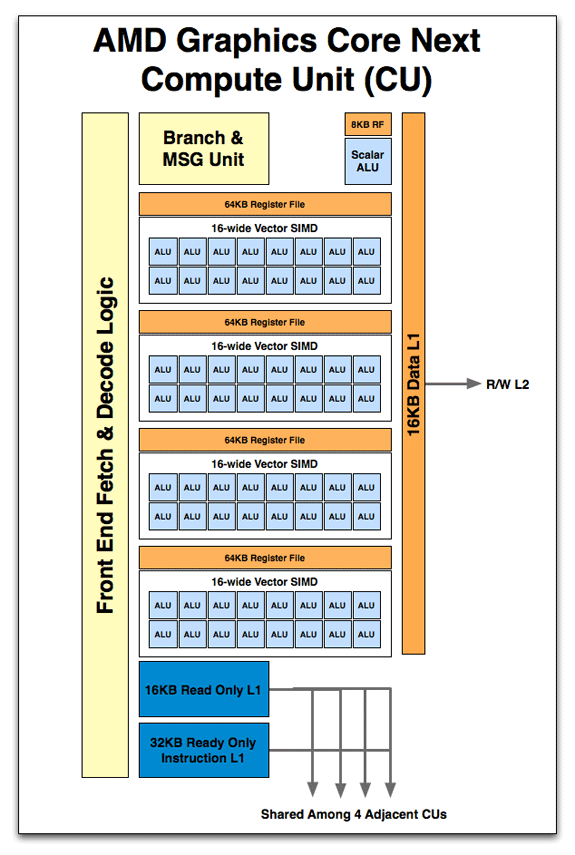
Ehhez képest a GCN:
1 lapka -> 4 SE -> 4x(9 - 16) CU -> 4x(9-16)x4 SIMD -> 4x(9-16)x4x16 ALU
Itt a L1$ a CU-ban van => 64ALU/L1$
az L2$ pedig az SE-ben => 1024ALU / L2$A problémát a hatékonytalanságra szerintem úgy lehetne illusztrálni, mintha a zen magban sokkal több, mondjuk 4 helyett 8 ALU lenne. Nyilván nehéz lenneo olyan szintű ILP-t elérni, amivel kihasználható 8 aLU egyszerre.
Tehát most annyi történik, hogy vezérlést, ütemezést és valószínűleg cache-t is visznek a SIMD szintre ezzel növelve a granularitást. Tehát nem a 64 ALU-t vezérlő CU lesz a legkisebb önálló egység, hanem egy 16 ALU-s SIMD.
"The main thing is that AMD has applied for a patent for a new design that apparently moves much more of the scheduling and control logic down the chain. This makes it look a little bit more like nVidia, which has the same scheduling logic on the streaming multiprocessor (SM) level. A card like the 1080 has 20 SMs active, to be compared with the 4 shader engines AMD uses. The metaphor isn't exact, but NVidia's SMs each control the equivalent of 2 CUs, while AMD's shader engines are asked to control as many as 16."
"But here's the thing, almost everything in that design is scalable. You can make a sSIMD with 2 ALUs or 4 ALUs, a CU with 4 superSIMDs or 6 superSIMDs, you can make a product with 2 CUs or 10 CUs. What is the implication of this? By mixing and matching components you can make a fit for purpose gpu, for gaming for compute or for AI. But there is more! You can take one of the subcomponents and mix it with an entirely different processor, a DSP, an FPGA and, yes, a cpu to make something entirely new."
(innen)


Új hozzászólás Aktív témák
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- Samsung Galaxy A56 - megbízható középszerűség
- Mindenkinél több és erősebb AI gyorsítót ígér Elon Musk
- Xbox Series X|S
- WoW avagy World of Warcraft -=MMORPG=-
- Videós, mozgóképes topik
- Anime filmek és sorozatok
- Fejhallgatós találkozó
- Milyen billentyűzetet vegyek?
- Google Pixel topik
- Mazda topik
- További aktív témák...
- LG 65B3 -65" OLED - 4K 120Hz 1ms - NVIDIA G-Sync - FreeSync Premium - HDMI 2.1 - PS5 és Xbox Ready
- Újszerű HP 14s-dq5001nh - 14"FHD IPS - i5-1235U - 16GB - 512GB - Win11 - Magyar - Garancia
- Apple iPhone 16 Pro Max Desert Titanium 256 GB Használt, megkímélt 93% akku 2026. 02. 27-ig
- BESZÁMÍTÁS! Apple iPhone 12 Mini 64GB mobiltelefon garanciával hibátlan működéssel
- HP ZBook Firefly 14 i7-1165G7 16GB 1000GB Nvidia Quadro T500 4GB 14" FHD 1 év garancia
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest