Hirdetés
- Luck Dragon: Asszociációs játék. :)
- gban: Ingyen kellene, de tegnapra
- eBay-es kütyük kis pénzért
- sziku69: Fűzzük össze a szavakat :)
- Brogyi: CTEK akkumulátor töltő és másolatai
- Geri Bátyó: Agglegénykonyha 9 – Az impulzusvásárlás is lehet tudatos
- sidi: 386-os Chicony gázplazma laptop memóriabővítése
- tordaitibi: Windows rendszerek indítása EFI partíció nélkül
- GoodSpeed: Pillangóhatás: F billentyű meghibásodása -új gamer számítógépasztal
- potyautas: Idővándor
Új hozzászólás Aktív témák
-
-

dobragab
addikt
válasz
 pvt.peter
#3696
üzenetére
pvt.peter
#3696
üzenetére
Jól értem hogy az a
void*valami userdata, amit a callback regisztrálásánál megadhatsz, és amikor visszahívódik, akkor a callback megkapja? Mert akkor különböző callback-eket érdemes regisztrálni a különböző típusú user data-hoz.void A_callback(void * data)
{
A& a = *static_cast<A*>(data);
// ...
}
void B_callback(void * data)
{
B& b = *static_cast<B*>(data);
// ...
}
register_callback(A_callback, &a);
register_callback(B_callback, &b);Ha ez a helyzet, akkor még lehet rajta ezen túl is szépíteni, elsősorban annak függvényében, hogy a
// ...részeknek egymáshoz van-e bármi köze. Ha mégsem, légyszí mutass valami példakódot, akár mockolt osztálynevekkel. -

pvt.peter
őstag
válasz
 EQMontoya
#3693
üzenetére
EQMontoya
#3693
üzenetére

Mentségemre legyen, hogy ez egy 3rd party *.dll egyik callback függvényének a paramétere.Én is érzem, hogy eléggé fos megoldás...
Persze szebben is megcsinálhatták volna, pl. a paraméter legyen egy interfész amit a saját típusaimmal megvalósíthatok, utána kedvem szerint castolhatok. Vagy az interfészt megvalósító típusba becsomagolni a saját cuccomat.Az egyetlen egy talán még szép megoldás erre az, hogy két ugyanolyan callback szignatúra lesz csak más névvel, és adott feladat elvégzésére mindig beállítgatom, hogy melyik callback hívódjon meg.
Mindenesetre köszönöm szépen mindenkinek a válaszát

-
válasz
pvt.peter
#3692
üzenetére
"Tehát adott egy void* típusú pointer ami reprezentálhat több egymással semmilyen kapcsolatban nem álló típust ami szintén egymással semmilyen kapcsolatban nem álló interfész megvalósítása."
Hát, ez így első nekifutásra az "elbaszott design" c. kategóriába való, ezt szépen nem lehet megoldani.
-

EQMontoya
veterán
válasz
pvt.peter
#3692
üzenetére
Erre nincs szép megoldás.
Minden egyes alkalommal, amikor void*-ot castolsz valamire, egy éhező kisgyerek élve felfal egy kiscicát.
Ha egy függvény argumentuma void*, és az nem egy memóriakezelésért felelő függvény, akkor ott komoly tervezési hibák történtek. Minden egyes alkalommal, amikor egy ilyet lefordítasz, az univerzumban felsír egy feketelyuk és szegény Bjarne-nek kicsit szúrni kezd az oldala.
C++-ban void*-ot csak a gonosz azon teremtményei használnak, akik az ősi feketemágia (C) hívei továbbra is. Ha nem küzdünk ellenük, egyszercsak azt vesszük észre, hogy már nem tudjuk megállítani a világuralomra törésüket, és mindannyiunkat birkává fognak static_castolni. Ezt Te sem akarod, ugye? -
pvt.peter
őstag
Sziasztok,
Én is bedobnék egy témát
Egy void* típusú pointert hogyan lehet valid típusra castolni?
Tehát adott egy void* típusú pointer ami reprezentálhat több egymással semmilyen kapcsolatban nem álló típust ami szintén egymással semmilyen kapcsolatban nem álló interfész megvalósítása.
Hogyan tudom a valódi típusára castolni ezt a szerzeményt?
Jöhet bármilyen ötlet, amikre én gondoltam azok eléggé csúnyácskák voltak.Jelenleg nem tudok erre valid es relatív "szép" megoldást.
A kérdés az, hogy ti esetleg tudtok-e erre vmit?
-

ToMmY_hun
senior tag
Bedobok egy témát, ami szerintem megér egy kisebb beszélgetést. Nektek mi a véleményetek az osztályok unit teszteléséről? Az alap feltevés az, hogy mi a helyzet akkor, ha szükségünk van más osztályokra, amit például init list-en példányosít a tesztelni kívánt osztályunk? Ilyen esetben valahogy setelni kell a tagváltozókat a mockolt objektumokkal. Tudom, hogy ez egy jól ismert probléma és számos megoldás létezik rá, viszont a kérdés az, hogy szerintetek melyik megoldás az, amelyik a leginkább elfogadható - nagy általánosságban?
-

bandi0000
nagyúr
Nem tom emlékeztek e ráde ajánlottátok a cin>>ws;-t a white space lenyelésre, viszont ez csak akkor működik ha kevesebb karakter ütök be mint a tömb méret, vagyis char tmb[5]= abc
De ha már abcd-t irok, akkor megint csak átugorja a számbekérést, mondjuk string-el nem próbáltam -
dobragab
addikt
válasz
EQMontoya
#3686
üzenetére
Klasszikus értelemben vett hibát egyet sem. Olyat viszont, ami a költő hozzá nem értéséről tanúskodik, többet is.
- Az osztály elnevezése. Ha kommentben kell jelezni, hogy ez bizony
XMLParsingException, tessék már úgy is nevezni az osztályt. Bár ahogy nézem, itt az osztálynevek módosítva vannak, nem hiszem, hogy az XML-t kiszedted volna belőle.-
std::string-et érték szerint átvenni a konstruktorban. Elvileg nem baj, sok esetben érdemes így csinálni C++11 óta, ha ugyanis aBaseException-nek vanstd::string&&-es konstruktora, egy füst alatt csinálhatsz string-et másoló és mozgató konstruktort, ha az inicializáló listán ezt írod:BaseException{std::move(error_)}.Mivel pl. az
std::runtime_error-nak nincs ilyen konstruktora, és az egész kódból sugárzik, hogy C++98-ban írták, így erős a gyanúm, hogy itt csak egy felesleges másolást látunk. Plusz sose szerencsés, ha exception dobása közben dobódik egy másik a másolásnál, mert pl. elfogyott a memória. Ezt viszont nem lehet teljesen kikerülni.- Kézzel forward-olni a konstruktort, mint az állatok. Ráadásul rosszul, lásd előző pont. C++11 óta illik így írni:
using BaseException::BaseException;- Copy ctor kézzel, mint az állatok. Ha valami magic-et csinál ott, még elfogadható, de akkor az op=-nél is illene, meg amúgy is minek. Ez egy sima kivétel-osztály, az ilyen szarság csak hibalehetőség.
- Virtuális destruktor a leszármazottban. Feltételezem, csak azért csinálta, hogy a destruktort virtuálisnak deklarálja, annak meg így semmi értelme, azt az ősben kellett. Ha a destruktora nem üres, komoly indok kell az egészhez, de attól még lehet jó.
-
throw(). Már a C++98 szabványosítás körül kiderült, hogy athrow(...)deklaráció szar, elavult, nincs értelme, csak ront a helyzeten. 2016-ban még "karban tartják" ezt a kódot, és ilyen van benne. Athrow()ráadásul inkompatibilis anoexcept-tel, tehát ha tényleg rögzíteni és vizsgálni kell, hogy egy függvény dobhat-e, ez a kifejezés false lesz.if(noexcept(e::~ParsingException())) // ...- Kivételdobásról nyilatkozni destruktorban. Egyrészt ha konstruktorban bármi dobódik, az
std::terminate. Másrészt, hathrowdeklaráció sérül, az isstd::terminate, tehát a destruktornál pontosan ugyanaz történik, akármit nyilatkozik ott. Még hanoexcept-et ír, az is ugyanazt jelenti, mintha semmit nem ír oda.- Az egysoros tagfüggvények definícióját kiviszi másik forrásfájlba. Ugyan már, kinek fáj, ha inline? Feltételezem, egyikben történik semmi eget rengető, tehát egyrészt a nagy semmiért egy egész függvényhívás lesz (pl. a destruktornál). Másrészt az olvasót baszogatja a tudat, hogy meg kéne nézni, mi van a cpp fájlban, pedig sejti, hogy valószínűleg semmi különös, amiért érdemes lenne megmozdítani az ujját.
Szóval röviden ennyi. Nálam így nézne ki ez az osztály:
struct XMLParsingException : public BaseException
{
using BaseException::BaseException;
}; -
bandi0000
nagyúr
bocs hogy megint itt vagyok a hülye kevert kódommal, de nem nagyon tudok máshonnan segítséget kérni
megoldható hogy függvényként rakjak ki egy random szám generálást?
lehet én írtam meg rosszul/és vagy rosszul gondoltam hogy meg lehet oldani
meg ugye nem tudom hogy kéne átadni a később meghívott tömbömnek azt az értéket amit most a tmb[2
-be rak
ezt írtam, de természetesen nem jó, sejtem hogy mi a baj, de nem tudom megoldani, jól gondolom azt is, hogy mivel az int main-en belül van a srand ((unsigned)time(NULL)); ezért is nem működhetne?void sorsolas(int tmb2[6])
{
int szam, i, j;
do
{
szam = rand() % 45 + 1;
j = 0;
while (tmb2[j] != szam && j < 6)
{
j++;
}
if (j == 6) { tmb2 = szam; i++; }
else i--;
} while (i != 6);
} -
EQMontoya
veterán
#include <Base/BaseException.H>
namespace A { namespace B { namespace C
{
/** Exception represents a problem during parsing of the XML fragment */
class ParsingException : public BaseException
{
public:
ParsingException(std::string error_);
ParsingException(const ParsingException& aCopy_);
virtual ~ParsingException() throw ();
};
}}}
Ki hány hibát vél felfedezni a fenti kódban? -
Akkor még egyszer: a C++ oktatásban a C tömb olyasmi, aminek semmi keresnivalója a kezdőanyagban. Az olyan dolog, ami már valami advanced classben jöhet elő, mint különleges nyelvi feature, kb. úgy, mint mondjuk a placement new.
A kezdőknél, amikor tömbökről van szó, akkor STL konténerek. -
bandi0000
nagyúr
így van, fősulin(egyetemen) tanulok, középsuliba C# ment, most meg gyakorlatilag ahogy írom az úgy van ahogy tanítják
érdekes amúgy, mert cout,cin-t tanítják és mellé a tömböket, szóval én sem értem teljesenés igen, az if-nél volt a hiba, szóval köszönöm, azt hittem simán rosszul írtam meg de akkor nem
-

cattus
addikt
válasz
 dabadab
#3680
üzenetére
dabadab
#3680
üzenetére
Gondolom felsőoktatásban tanul a kolléga, ott meg úgy kezelik az első félévben az embereket, mintha 0 előismeretük lenne (legalábbis nálunk ez a bevett forma). Persze ha valaki már előrébb tart, akkor eléggé zavaró lehet ilyen primitív eszközökkel dolgozni, de ha normális a képzés, akkor túllépnek ezeken.
Nem hiszem, hogy ne tanítanák az STL-t, csak nem az elején. Nyilván az ilyen egyszerűbb adatszerkezeteket egy kezdőnek könnyebb megérteni. -
-
bandi0000
nagyúr
kellene még 1 ici pici segítség
függvényt szeretnék írni, egy sorba rendezéshez, sorsoltattam számokat egy 6 elemű tömbbe
és a függvény így nézne ki :void rendez(int tmb[6])
{
int i, j, csere;
for(i=5;i>0;i--)
for (j = 0; j < i; j++)
{
if (tmb[j] > tmb[j + 1])
csere = tmb[j];
tmb[j] = tmb[j + 1];
tmb[j + 1] = csere;
}
}de nem csinálja meg, vagyis meghal a program, nem vagyok biztos benne hogy jól adtam meg az első sort
-

sko
csendes tag
válasz
 bandi0000
#3673
üzenetére
bandi0000
#3673
üzenetére
A problémára két egyszerű megoldás létezik.
1. tegyél egy
cin >> ws;-t acin.getline()elé.2. használj a második, azaz a szám beolvasásához is
getline()-t.A lényeg, hogy a getline egy adott delimiterig olvas és azt el kell tüntetni az input buffer-ből, mielőtt a második ciklus eljut a getline()-ig. Azaz egy további "retro" megoldás lehet
3. tegyél egy
getchar()-t acin.getline()elé.A getline delimiterét egyébként megadhatod neki harmadik paraméterként. A default értéke '\n'.
-
bandi0000
nagyúr
válasz
 dobragab
#3672
üzenetére
dobragab
#3672
üzenetére
köszi, de még mindig ugyan azt csinálja, vagyis szinte ugyan azt, így gondoltad nem?
cout << "Kerem az " << i + 1 << " karatkerlancot\t:";
cin.getline(valami[i], 9);
cout << "Kerem az " << i + 1 << " szamot\t:";
cin >> tmb[i];
cin >> ws;
cout << valami[i] << "\t" << tmb[i]<<endl; -
dobragab
addikt
válasz
bandi0000
#3668
üzenetére
A szám beolvasása után dobj bele egy ilyet:
cin >> ws;Ilyenkor az történik, hogy a szám beolvasásánál te ezt írod be:
"5\n"
A beolvasás megeszi az 5 karaktert, az utána lévő pufferben benne marad az enter. Majd jön a getline, ami enterig olvas. Azonnal megtalálja a pufferben az entert, tehát visszatér üres sztring beolvasása után, mindezt user interaction nélkül.A
cin >> wsannyit csinál, hogy cin-ről beolvassa és lenyeli az összes whitespace-t, de a többi, értékes karaktert nem. Azért jobb ez, mint a simacin.ignore(), mert ez azt is le tudja kezelni, ha a user ezt írta be:"5 \n"(#3669) PumpkinSeed
A clear nem a puffert üríti, hanem a hibajelző flageket
-
#3670
bandi0000
nagyúr
PumpkinSeed
#3669
bandi0000
nagyúr
válasz
 PumpkinSeed
#3669
üzenetére
PumpkinSeed
#3669
üzenetére
igen, ezt beírtam, de ugyan úgy csinálja, a 2015-ös verzió legalább is
-
bandi0000
nagyúr
csak hogy ne hagyjak pihenni senkit...
a kövi problémával szembesültünk, hogy ha egymás után kértünk be számot illetve karaktert, akkor valamiért a 2. ciklus után már csak a számot akarja bekérni...
a tanár magyarázott valamit, hogy valami fügvény nem működik a 2015 visual studioban, ezért írt egy függvényt amibe ha jól emlékszek a cin.sinc,és cin. volt benne, de aztán kiderült hogy nem működik
na már most felajánlott + pontot annak aki tud írni normális függvényt, ami ezt megoldja, na már most nekem nehéz lenne mivel azt se tudom mi nem működik
c# alatt sose volt ilyen gondom, de ott igaz a gets()-et használtam
-
cattus
addikt
válasz
bandi0000
#3665
üzenetére
így ahogy kiírattam cout-tal, kerekített, de viszont ha az atlagba beletöltöttem, az összeget, és azt a couton belül leosztottam i+1-el, akkor viszont jó lett és nem egészet írt ki, én bénáztam?
Gondolom az
atlagváltozódinttípusú, így amikor azatlag=osszeg/i+1;műveletet elvégzed, a gép egész osztást csinál. Hogy ezt a bugot kijavítsd, az osztás egyik oldalán lévő változót kasztolni kell double típusra:atlag=(double)osszeg/(i+1);Érdemes továbbá rendesen bezárójelezni a műveleteket.
-
#3665
bandi0000
nagyúr
PumpkinSeed
#3663
bandi0000
nagyúr
válasz
PumpkinSeed
#3663
üzenetére
értelek, egyrészt még nagyon az elején vagyok, vagyunk és ilyen kis szar kódokhoz én azt nézem, hogy nekem adott esetbe legyen értelmes, persze ha már több feladatot csinálnék akkor nyilván nem így nevezném el őket
másrészt, meg ezt a tanár csinálta
én sem értem mi az az i2, én mindig i-j-k-t használok, pláne ha meg nem is egymásba ágyazott ciklusról van szó mint a fenti kódnál, akkor simán használhatta volna tovább az i-t, bár lehet azt akarta hogy ne zavarja meg a többieketmindenesetre ma megírtuk az első ZH-t, ha nem köt bele mindenbe akkor hibátlan, hozzáteszem azt mondta első órán, hogy őt nem érdekli ha ékezettel vagy anélkül íratunk ki, erre ma mondta hogy pontlevonás lesz érte
szerencsére eszembe jutott a setlocalos vacak, és tudtam használniviszont felmerült egy kis probléma
átlagot kellett számolnom, és mint ahogy a nagykönyve meg van írva így csináltam:
double atlag=0.0;
összegbe benne vannak 0-7 ig összeadva a számok, és 8-al osztottam
atlag=osszeg/i+1;így ahogy kiírattam cout-tal, kerekített, de viszont ha az atlagba beletöltöttem, az összeget, és azt a couton belül leosztottam i+1-el, akkor viszont jó lett és nem egészet írt ki, én bénáztam?
c#-be egyszerűbbnek tűnt nekem, mert %.2f-el vagy hogy irtattam ki 2 tizedesjegyet, meg eleve jobbnak találtam azt is, hogy a %d-t pl bárhova pakoltam, míg cout-nál "körbe" pakolom a változót a szöveggel, hogy oda írja ki a számot vagy bármit ahova akarom
-
#3664
dobragab
addikt
PumpkinSeed
#3663
dobragab
addikt
válasz
PumpkinSeed
#3663
üzenetére
Törekedni kell az angol elnevezésre is, de ez opcionális.
Igen, de amíg tanul, és kezdő, a kutyát nem zavarja szerintem. Aztán ha már párszáz sornál hosszabb programnak áll neki, akkor "kötelező" az angol változónév.
Illetve a camelCase használata változók, függvények és metódusok közben.
Naaaa, ne jávázzunk pls.
Egyrészt ez is camelCase, másrészt ez is CamelCase. A jávás konvenció a lowerInitialCamelCase. C++-ban ez projetkfüggő, hogyan nevezi el a változókat, de csak egyféleképpen.
Az STL konvenciója egyébként a lower_case_with_underscore...
-
#3663
 PumpkinSeed
addikt
bandi0000
#3662
PumpkinSeed
addikt
bandi0000
#3662
PumpkinSeed
addikt
válasz
bandi0000
#3662
üzenetére
Egy jó tanács a kezdetekre. Vannak a változóid:
int i2, db, ossz2=0, jegy[20], jelesdb=0;Ha a jövőben programot írsz akkor törekedned kell arra, hogy a változónevek egyértelműen a funkciójuk alapján legyenek elnevezve. Ez az egyik legnehezebb része a programozásnak. Én például van, hogy 10 percet ülök egy változónév felett.Miért kell ez a baszakodás? - Teszed fel magadban a kérdést. A programozásnak nem az a lényege, hogy egy kódot megírsz, elkészítesz, vagy álmatlan éjszakádon kiokomulálsz és az a végtelenségig tökéletesen fog működni. Olykor-olykor megesik az, hogy fél évvel később vissza kell térned, hogy változtass valamit, és nézed a kódot, ami majd 5000 sor, ahol olyan változók vannak mint a
jegy[20]vagy a barátai mellette. Na ebben az ilyen esetekre kell normális változó és később függvény, metódus neveket adni.Általában a for ciklus index változóit ami ebben az esetben "i2" (el nem tudom képzelni miért), i-vel szoktuk jelölni, ha véletlen egymásba ágyazott ciklusaid vannak, ami amúgy kerülendő a komplexitás növekedésének elkerülése végett, akkor használhatsz j-t vagy a következő betűket az angol abc-ből.
Törekedni kell az angol elnevezésre is, de ez opcionális. Illetve a camelCase használata változók, függvények és metódusok közben. A camelCase azt jelenti, hogy az első szó kis kezdőbetűs míg a többi nagy, pl.: mintEzItt. Ezt a metodikát követve, illetve értelmesebb neveket adva a változóidnak:
db -> pieceOfSomething // El nem tudom képzelni minek a darabja
ossz -> countOfSomething // Szintén nem tudom minek az összege
jegy -> marks[20] // Mivel tömb ezért többesszámba kell tenni
jelesdb -> countOfALevel // Ez godolom a meglévő ötös érdemjegyek darabszámát jelzi.Ha valaki jobb neveket tud a kód mivoltának tudatában, akkor javítson ki.
-
-
dobragab
addikt
válasz
bandi0000
#3659
üzenetére
Naakkor sorolom.
- A bemenet ellenőrzésével erősen ellenjavallott ennyit tökölni. Ha valami nem stimmel, kiírni, hogy szar a bemenet és rage quit. Konzolos program úgyse lesz sose user-friendly, de így elveszik a lényeg a sok marhaság között.
- Ha a
cin.clear()és acin.sync()nélkül nem működik egy algoritmus, akkor szar. Ráadásul nem feltétlenül végtelen ciklus, ha kihagyod, csak bizonyos esetekben. Megint csak az van, hogy ne próbálj user-friendly lenni.-
for (i2=db; i2<db; i2++)
Ez így ebben a formában nem csinál semmit. És nem is tudok rájönni, hogy hány darabot kéne randomgenerálni.-
int i2, db, ossz2=0, jegy[20], jelesdb=0;
Ezért dupla nyers hal jár. Egyrészt egy sor, egy deklaráció! Másrészt minden változót akkor deklarálj, amikor szükséged van rá, sose előbb! Ez C++, és kb. minden C89-től különböző nyelv és Linus-tól különböző programozó megengedi.- Tessék mán
for(int i-t írni, akkor nem kell számozni a ciklusváltozókat (i2). Lásd előző pont.- A végén az átlagszámítós - ötösszámolós ciklus a lényege az egésznek, azt kellett volna faszán elmagyaráznia a tanárnak. És nem a C++-specifikus beolvasós trükközgetésekkel terhelni az agyatokat, az égvilágon semmi értelme. Feltételezem, hogy nem magyarázta el a lehető legérthetőbben, mert akkor külön for ciklust kaptak volna, ahogy illik.
Így röviden ennyi, ami a kódot érinti.
Na és akkor a kérdésed.
A cin belső flagekben tárolja, hogy volt-e valami hiba a beolvasás során, például ha te számot akartál beolvasni, de a júzer azt írta be, hogy
hesstegfoskód, akkor a cin nem dob hibát, hanem megjegyzi, hogy valami büdös volt, és te akkor ellenőrzöd, amikor akarod. Ezt acin.fail()-lel, meg még két hasonló függvénnyel tudod megtenni, mindegyik máskor jelez. Ha a következő beolvasás sikerül, akkor is megmarad a flag, tehát nem írja felül a hibás állapotot. Vagy csak annyit írsz acin.fail()helyett, hogycin.if(cin) // nem kell ide semmi, ilyenkor igaz-hamissá konvertálódik
cout << "Minden rendben volt.";
else
cout << "Szar van a palacsintában.";Ezeket a flageket a
clear()-rel tudod kipucolni, hogy ha az előző beolvasás elfailelt, akkor is lásd, hogy a következő jó-e. -
bandi0000
nagyúr
válasz
dobragab
#3658
üzenetére
jah... igen végül is nagy nehezen át lehet látni, csak azokat az ismeretlen vackokat nem tudom mit csinálnak a kódba
na meg ezt is most vettem észre: cin.fail(), ez ha jól tévedek valami bekérési hiba lenne ? pl ha nem olyat akarok tölteni a változóba mint amilyennek lefoglaltam? pl int a-ba beletöltenék egy karaktert?
-
bandi0000
nagyúr
válasz
dobragab
#3654
üzenetére
elég sok, mert több fajta feladatot csinált egyszerre, de konkrétan ebbe a feladatba volt ez:
/*
###########################################################################################################
# Feladat: #
# Maximum 10 érdemjegy bekérése ellenörzötten/véletlenszámmal feltöltve, #
# - az átlagok kiíratása #
# - a jelesek számának kiíratása #
###########################################################################################################
*/
int i2, db, ossz2=0, jegy[20], jelesdb=0;
do
{
cin.clear(); //a hibejelzők törlése, enélkül hiba esetén végtelen ciklusba fut
cin.sync(); //a beviteli puffer szinkronizálása, és a fel nem használt elemek ürítése, enélkül végtelen ciklus
cout<<"Hány jegyet ad meg?(max.10)"<<endl;
cin>>db;
if (cin.fail() || db<1 || db>10)
{
cout<<"Nem jó érték!\n";
}
}
while (cin.fail() || db<1 || db>10);
//jegyek bevitele billentyűzetről
for (i2=0; i2<db; i2++)//tömbindexálás mindig a 0. elemtől!
{
do
{
cin.clear(); //a hibejelzők törlése, enélkül hiba esetén végtelen ciklusba fut
cin.sync(); //a beviteli puffer szinkronizálása, és a fel nem használt elemek ürítése, enélkül végtelen ciklus
cout<<"Adja meg a(z) "<<i2+1<<". jegyet!"<<endl;
cin>>jegy[i2];
if(cin.fail() || jegy[i2]<1 || jegy[i2]>5)
{
cout<<"Nem jó érték!\n";
}
}
while (cin.fail() || jegy[i2]<1 || jegy[i2]>5);
}
//jegyek bevitele véletlen számokkal
for (i2=db; i2<db; i2++)
{
jegy[i2]=rand()%5+1;
}
cout<<"A beirt jegyek\t\tA generált jegyek"<<endl<<endl;
for (i2=0; i2<db; i2++) //végig kell néznie az öszes jegyet
{
if (jegy[i2]==5)
{
jelesdb++;
}
ossz2+=jegy[i2];
}
cout<<"\nÖssesen "<<jelesdb<<" db jeles van benne.\n";
cout<<"A jegyek átlaga= "<<setprecision(2)<<(double)ossz2/db<<endl; -
bandi0000
nagyúr
valaki el tudná magyarázni ezt a 2 dolgot?
a tanár do-while-on belül használta, persze leírta hogy mit csinál, de én sose használtam ezt, és nem éreztem hiányát
cin.clear(); //a hibejelzők törlése, enélkül hiba esetén végtelen ciklusba fut
cin.sync(); //a beviteli puffer szinkronizálása, és a fel nem használt elemek ürítése, enélkül végtelen ciklus -
dobragab
addikt
válasz
bandi0000
#3647
üzenetére
Másik jó megoldás, hogy generálsz egy 90 elemű tömböt. Aztán ötször:
- generálsz egy n-t 0-89-ig,
-tomb[n]-t kiválasztod
- majdtomb[n]-t kiveszed tomb-ből. Ez legegyszerűbbentomb[n]és az utolsó elem cseréjével oldható meg, és ezután már 0-88-ig generálsz n-tKódban még egyszerűbb is.
int megoldasok[5];
int tomb[90];
for(int i = 0; i < 90; ++i)
tomb[i] = i;
for(int i = 0; i < 5; ++i)
{
int n = rand() % (90-i); // jó, éles kódban ne rand-ot használj
megoldasok[i] = tomb[n];
std::swap(tomb[90-1-i], tomb[n]); // vagy sima segédváltozós csere
}Nem próbáltam ki, lehet benne elírás...
-
cattus
addikt
-
bandi0000
nagyúr
válasz
EQMontoya
#3644
üzenetére
biztos jók amit mondotok meg stb, de az a baj hogy nem tudom mit írtál most le
természetesen nem várom hogy elmagyarázd, majd apránként megtanulom ezeket, de annak sincs értelme ha csak lemásolgatom amit írtoktetszik ez a shuffle, sztem ezt majd használom
de a vektor alatt ti mit értetek? sima tömböt nem?
-
EQMontoya
veterán
válasz
bandi0000
#3643
üzenetére
Arra miért nem jó egy másik shuffle?
De ha nem akarsz shuffle-t használni:
std_vector<int> nums;
std_vector<int> results;
for(int i=1;i<=90; ++i)
{
nums.push_back(i);
}
for(int i=0;i<5;++i)
{
int rand_index = //generálsz egy randomot 0 és nums.size()-1 között.
result.push_back(nums[rand_index]); //berakod a generált számot a végeredmény containerbe
std::vector<int>::iterator it = ( nums.begin() + rand_index ); //szerzel egy iterátort az indexelt elemre
nums.erase(it); //ezt az elemet törlöd a containerből
}A fenti megoldásnak az az előnye, hogy amit egyszer kisorsoltál, azt ki is veszed, így legközelebb egyel kisebb méretű vektorban sorsolsz, ami így nem is fog tudni ütközni.
-
bandi0000
nagyúr
-
bandi0000
nagyúr
ja értem már, akkor ez csak összekeveri az elemeket, és 0-4-ig kiíratom a tömb elemeit, amik elvileg nem 1,2,3,4,5 lesz, hanem kevert valami
(#3639) sztanozs : azzal próbáltam, vagyis megírom úgy hogy legyen egy tuti jó, aztán ráérek kísérletezni vele, mert így is úgy is meg kellene tanulnom ezeket, ha akarok is kezdeni vele valamit, mert ezt már régen megírtam, de most valami miatt nem akar menni, vagyis, nem is értem, mert már akkor meg hal a program, mikor a jó és nem ismétlődő számot, bele akarom tölteni a tömbbe...
do
{
szam = rand() % 90 + 1;
j = 0;
while (sors[j] != szam && j < 6)
{
j++;
}
if (j == 6) { sors[i] = szam; i++; }
else i--;
} while (i != 6);persze feltöltöttem a sors tömböt
-

Karma
félisten
válasz
bandi0000
#3635
üzenetére
Ennél csak jobb megoldás van. Egy dolog, hogy nehezen olvasható és követhető a ciklusváltozók belső manipulációja miatt, de még le is fagyhat az algoritmusod (még ha ez egy ötöslottónál nem is valószínű).
Szerintem itt nem baj, ha a valóságra támaszkodsz: vegyél egy vectort, benne a számokkal 1-90 között, használd az std::shuffle függvényt hogy megkeverd őket, és vedd ki az első öt számot.
-
bandi0000
nagyúr
válasz
bandi0000
#3634
üzenetére
ezt végül is megoldottam, csak le kellett tölteni
viszont van egy kis prog feladatom, beadandót kéne csinálni, sima lottó sorsoltás, ugyebár nem ismétlődhet 0-90 ig ezzel nincs is gond, csak van e ennél egyszerűbb vagy szebb megoldás?
dupla for, mindkettő elmegy <6-ig, első for alatt random számot generálok, a 2. for is <6-ig megy, de ott meg megvizsgálom, hogy az eddig kisorsolt számok között van e olyan mint amit most sorsoltam, ha nincs akkor beletöltöm a tömbbe, ha van akkor meg az első for változóját, (i-t) minuszolom egyel, tehát hogy sorolja ki még1-szer azt
-

kispx
addikt
Be kell állítani a fordítót, amit a kiírt helyen megteheted.
Windows platformon van egy olyan szokása, hogy két fajta telepítő is van az oldalukon.
codeblocks-16.01-setup.exe
Ebben csak az IDE van.codeblocks-16.01mingw-setup.exe
Ebben az IDE és (mingw) fordító program is van. Ha az elsőt töltötted le, akkor fordítód nincs. Így érdemes a codeblocks-16.01mingw-setup.exe letölteni. (vagy külön egy mingw fordítót felrakni.) -

lorcsi
veterán
válasz
dobragab
#3624
üzenetére
ok, kezdetihez ezt-azt csináltatni vele jó lesz
tx
felpakoltam..és egy suliban írt progit nyitottam vona, de dobott egy iylen hibát:
"elso100 - Debug": The compiler's setup (GNU GCC Compiler) is invalid, so Code: locks cannot find/run the compiler.
locks cannot find/run the compiler.
Probably the toolchain path within the compiler options is not setup correctly?! (Do you have a compiler installed?)
Goto "Settings->Compiler...->Global compiler settings->GNU GCC Compiler->Toolchain executables" and fix the compiler's setup.mi a fene ez?
minden alapon van..semmit sehova nem állítottam -
-
lorcsi
veterán
elkezdtem szept.-től programozást tanulni-...
c++ és C# is van-lesz (később meg majd java is)a C++ Code bocks-al írjuk..
mennyire használják még ezt a felületet?
vagy mennyire elavult?C#-ot pedig microsoft visual C# express 2010 verzióval..
szintén ez lenne a kérdésem...-nem vág túlzottan témába, de hátha... -

jattila48
aktív tag
válasz
dobragab
#3621
üzenetére
Nincs túl nagy különbség a két megoldás közt. Végül is nálad is van type switch, csak egy kicsit másképp. Scope alatt azt értem, ami pl. a Pascal-ban a scope. Egy adott sope-ban nem lehetnek azonos nevű szimbólumok, de egymásba ágyazott scope-okban vagy különállóakban már igen. A belső scope-ban lévő név elfedi a bentfoglaló scope-ban lévő ugyanilyen nevet. Ha kilépünk a scope-ból, akkor megszűnnek e nevei. Tehát a szokásos. Egységes szimbólum táblát (és vektort benne) a scope egyszerűbb kezelése miatt vezettem be. Nálad a különböző szimbólum táblák mindegyikében kezelni kell a scope-ot, ki kell jelölni a scope határokat. Nálam csak az egyetlen táblázatban. Nálad viszont valóban nincs típus attribútum, és static_cast. A set szerintem nem alkalmas, vagy csak akkor, ha scope-onként is külön táblázatokat tartasz fent, és ezeket stack-be szervezed. Azt hiszem maradok a static_cast-nál.
Köszönöm mindenkinek a hozzászólást! -
dobragab
addikt
válasz
 jattila48
#3618
üzenetére
jattila48
#3618
üzenetére
A keresést úgy értettem, hogy a
bool symbol_exists(Symbol)van szétosztva, és nem a find_symbol. Szarul fogalmaztam.Szóval valami ilyen type switch van neked:
Symbol * s = find_symbol("int");
switch(s.type)
{
case KEYWORD:
Keyword * k = static_cast<Keyword*>(s);
// blablabla
break;
case TYPE:
Type * t = static_cast<Type*>(s);
// blablabla
break;
}Ennél mennyivel rosszabb ez?
std::string symbol = "int";
auto it_keyword = keywords.find(symbol);
if(it_keyword != keywords.end())
{
// use *it_keyword
return;
}
auto it_type = types.find(symbol);
if(it_type != types.end())
{
// use *it_type
return;
}A scope kezelést még mindig nem tudom, hogy kéne működnie.
-
jattila48
aktív tag
válasz
dobragab
#3617
üzenetére
Kicsit visszatérve a type switch vs. virtuális fv. problémához:
Szerintem a zavart az okozza, hogy a szimbólumot reprezentáló osztály type mezője nem az osztály típusát jelöli, hanem a szimbólumét. Egy objektum típusa meghatározza, hogy rajta milyen műveletek végezhetők. Itt azonban a típusmező a név forráskódbeli szerepére utal, nem pedig a szimbólum osztályon végezhető műveletekre. Ez két külön dolog. A virtuális fv. az objektum típusához kapcsolódik, nem pedig a szimbólum név típusához. A szimbólum név típusa ugyanolyan attribútum, mint a többi, amik a program szerkezetére lesznek hatással (hogy generálja a kódot a fordító, a név típusától függően), ezért a type switch elkerülhetetlen. Mellesleg éppen ezért helytelen type switch-nek nevezni a dolgot. -
jattila48
aktív tag
válasz
dobragab
#3617
üzenetére
A set-ben (vagy nem vektorban) való tárolásról még annyit, hogy a scope kezelést nem lehet megoldani benne (hogy tartod nyilván a scope határokat?). A sope-ok stack szerűen rakódnak egymásra, ezt pedig vektorban a legegyszerűbb kezelni. Ha set-et használsz, akkor scope-onként külön-külön (sőt szerinted ezen belül még típusonként is) szimbólum táblákra lenne szükség (annál is inkább, mivel különböző scope-okban lehetnek azonos nevű szimbólumok,a set már csak ezért sem alkalmas), amiket aztán a scope-oknak megfelelően stack-be szervezel. Biztos, hogy ez jó elgondolás?
-
jattila48
aktív tag
válasz
dobragab
#3617
üzenetére
"Futásidejű költsége nem a static_cast-nak van, hanem a type switch-nek"
Én is ezt írtam. A type switch-et meg nem tudom elkerülni, mert mikor megtalálok egy szimbólumot, akkor a tíőusától függően kell folytatni a fordítást. Pl. egész mást kell csinálni ha a szimbólum változó, mint ha függvény. És azt előre nem tudom, hogy a keresett szimbólum milyen típusú lesz.
Nem értem mi előnye lenne a különböző típusok külön tárolásának, azonban azt látom, hogy rengeteg a hátránya.Minden, típusonként külön szimbólum táblában kezelni kell a scope-ot, holott a scope a típustól függetlenül ugyanúgy vonatkozik az összes szimbólumra. A find_symbol fv.-nek végig kell keresni az összes szimbólum táblát, és attól függően, hogy melyikben találta meg a szimbólumot, vissza kell hogy adja a típusát (ezután pedig mindenképpen type-switch jön). Sőt nem csak a típusát, hanem valami módon magát a szimbólumot is, pl. iterátorral. A visszaadott iterátor minden esetben más típusú lesz, ha csak az összes szimbólum nem egy közös őstől származik, és a táblázatok az ős pointert tárolják, amiket aztán ugyanúgy típustól függően static_cast-olni kell (mint ahogy most is csinálom). De akkor miért kéne külön táblázatokba tenni? Ha valamiért új típusú szimbólumot kell bevezetni, akkor a find_symbol fv.-t bővíteni kell az új típusnak megfelelő táblázat keresésével. Ezek mind hátrányok, és bonyolítják a programot. A Te megoldásod egyetlen "előnye", hogy a szimbólumokban nem kell a típusukat tárolni.
Az, hogy a táblázat vektor-e, vagy más, teljesen lényegtelen. Max. pár száz szimbólumról lehet szó, ennyire pedig talán a vektor overhead-je a legkisebb, úgyhogy a keresés sem lesz túl lassú (egyébként is csak fordításkor van szimbólum tábla, futáskor már nincs).
Egy szó mint száz, nem tudsz meggyőzni a külön-külön tároláskor, de nem is ez volt a kérdés. A static_cast nekem sem tetszik, de nem tudok jobbat. -
dobragab
addikt
válasz
jattila48
#3599
üzenetére
Futásidejű költsége nem a static_cast-nak van, hanem a type switch-nek. De ha az enum értékei 0-n-ig folytonosak, a fordító O(1) jump table-t tud belőle generálni. Pont pár hete néztem meg.
Szerintem az a legtisztább megoldás, ha külön tárolod. Egyedül a keresést kell az összes tárolóra kiterjeszteni, és a scope keresésben azt hívni. A scope kezelése nem tudom, hogy megy, főleg, hogy nem tudom, milyen nyelvről van szó
A hozzáadás tuti nem macerásabb, hiszen hozzáadáskor tudod, milyen típust adsz hozzá, csak a megfelelő kollekcióba kell belerakni.Aztán ja, nem hiszem, hogy ezeket
std::vector-ban kéne tárolni, ha a tárolási sorrend nem életbe vágó, és csak egy lehet mindenből. Errestd::setvagystd::unordered_setjobb, szerintem az utóbbi. -

mgoogyi
senior tag
válasz
EQMontoya
#3613
üzenetére
Értem mire gondolsz, de ez csak a pointerekre vonatkozó cache miss.
Az objektumok kapcsán annyi cache miss lesz, ahányat feleslegesen megnézünk, azaz set esetén O(log(N)), vektor esetén meg O(N).Ha csak a pointert elég használni a komparálásra, akkor teljesen igazad van, de nem látom, hogy ez milyen esetben van.
A fordító csak a szimbolúm nevét látja, nem?A kis elemszámra hol van algoritmikus overheadje a set-nek pointeren keresztüli elemkeresésnél?
(Mondjuk ez tök mellékes, mert úgyis elhanyagolható.) -
jattila48
aktív tag
válasz
 mgoogyi
#3611
üzenetére
mgoogyi
#3611
üzenetére
De, erről van szó. Azonban a kód generálás, már nem a szimbólum tfv.-einek hívásával történik, hanem a szimbólum attribútumai alapján. A megtalált szimbólum állapotán már nem változtatunk. Ahogy írtad, pl. függvények, változók neveiből keletkeznek szimbólumok, teljesen különböző attribútumokkal. Ezért nem lehet egységes interfészen kezelni őket, viszont mégis egy táblázatban kell tárolni ezeket.
Nyugodtan dumálj bele, nem leugatni akartalak. Bocs, ha így érezted. -
mgoogyi
senior tag
válasz
jattila48
#3610
üzenetére
Lehetséges, hogy nem tudom..
Nem az, amit leírtál? Egy tábla, ami tárolja a lefordítandó kód szimbólumait, mint változó, függvény, stb. és arra használod pl., hogy ellenőrizd, hogy az adott objektumra az adott scopeban lehet e egyáltalán hivatkozni.
A process kapcsán arra gondoltam, hogy valami gépi vagy köztes kódot generálsz, mikor mész a következő sorra a kódban és találkozol pl. egy szimbólumon végzett művelettel.
És elnézést, hogy beledumáltam (inkább ne tettem volna), nem vágom, hogy működnek a fordítóprogramok. -
jattila48
aktív tag
válasz
mgoogyi
#3606
üzenetére
Nekem úgy tűnik, mégsem egészen tudod, mi a szimbólum tábla (bocs). Ha egyszer bekerült a szimbólum a táblázatba, akkor azt már nem kell "feldolgozni" (legfeljebb törölni), hanem szükség szerint megtalálni kell, és az attribútumai alapján generálni a megfelelő kódot. A tárolt szimbólumnak ha lenne virtuális fv.-e, akkor az csak getter lenne, de semmiképpen nem "processz". Tulajdonképpen a find const pointereket ad vissza, mivel egyáltalán nincs szükség a megtalált szimbólum megváltoztatására. Azonban a szimbólumok, ahogy írtam teljesen különbözők, így nincsenek hasonló attribútumaik sem (a nevet és típust kivéve). Ezért nem lehet (és nem is kell) őket egységes interfészen keresztül kezelni.
-
-
mgoogyi
senior tag
válasz
jattila48
#3602
üzenetére
Tudom mi a szimbólumtábla, viszont nem tudom, hogy mi történik pontosan a "tárolt attribútumai szerint folytatni a fordítást" során. Különböző külső függőségei vannak a különböző objektumoknak a további feldolgozás szempontjából? Még mindig az van a fejemben, hogy minden objektumra lehetne egy Process-t hívni, ami kezelné az adott objektumot a típusának megfelelően, ami kaphat egy olyan külső függőséget, amin keresztül mindent megkaphat, amire esetleg szüksége van, vagy esetleg vmi callback-et. Ha viszont teljesen heterogén és abszolút összegyezhetetlen dolgok vannak, akkor nincs ötletem.
-
jattila48
aktív tag
válasz
mgoogyi
#3603
üzenetére
Ne haragudj, de szerintem nem érted miről van szó. Persze, hogy csak a pointerek vannak sorfolytonosan a vektorban (hiszen írtam, hogy csak ezeket tárolom vektorban). EQMontoya arra gondolt, hogy vektorban (a sorfolytonos elrendezés miatt), kis elemszám esetén gyorsabb az ismétlődés keresés, mint pl. set-ben. Ez akkor is így van ha, csak az objektumok pointereit tároljuk, mert az algoritmus ezen fog föl-alá futkosni, miközben a pointerek által hivatkozott objektumokat hasonlítja össze. Ha jól van megírva az ismétlődés kereső algoritmus, akkor mindössze egy összehasonlító operátort kell neki átadni, és pont ugyanúgy működik, mint egyéb esetben.
Na de ennek semmi köze az eredeti problémához, mert szimbólum táblában NEM keresünk ismétlődést. -
jattila48
aktív tag
válasz
mgoogyi
#3600
üzenetére
Leírtam, hogy miről van szó. Ha nem tudod mi az a szimbólum tábla, akkor azt most nem tudom teljes részletességgel elmagyarázni. Nem ismétléseket kell keresni benne, hanem hanem amikor a programszövegből új nevet olvas a szintaktikus elemző, meg kell állapítani, hogy előfordult-e már ilyen nevű szimbólum. Ezt vagy azért teszi, mert új nevet definiálunk (ekkor ellenőrizni kell, hogy a scope-ban szerepel-e már), vagy azért, mert hivatkozunk rá (ekkor ki kell keresni (nem csak a scope-ból), és a tárolt attribútumai szerint folytatni a fordítást). Leírtam, hogy miért kell az összes különböző típusú szimbólumnak egy táblázatban szerepelni. Mivel különböző típusúak, ezért nem lehet őket egységesen (polimorf módon sem) kezelni. Az, hogy a szimbólum tábla most vektor-e, map, vagy hash tábla, teljesen mindegy. Nekem bőven elég a vektor. A hangsúly a heterogén tároló használatán van.
-



























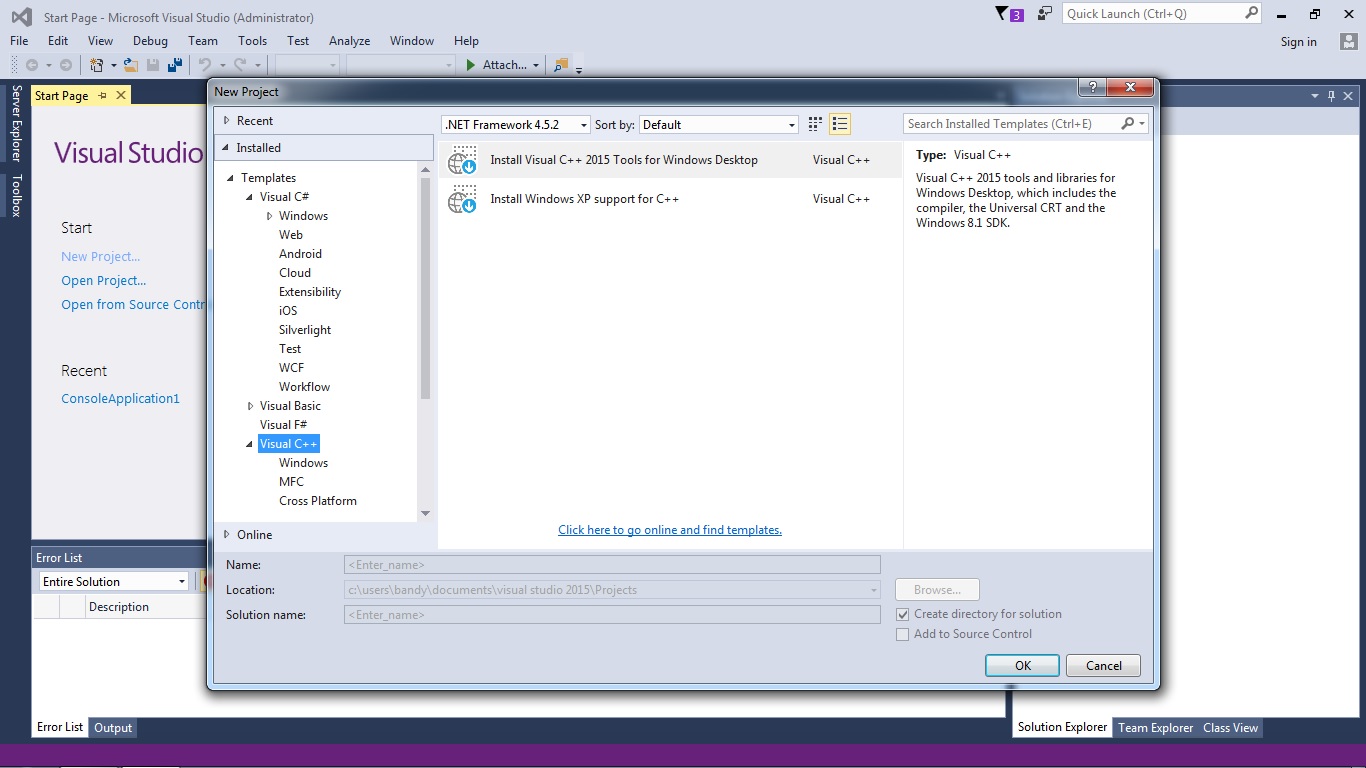




 locks cannot find/run the compiler.
locks cannot find/run the compiler.




Új hozzászólás Aktív témák
● ha kódot szúrsz be, használd a PROGRAMKÓD formázási funkciót!
- Újjászületés: szombattól új szerverkörnyezetben a PROHARDVER! lapcsalád
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- Építő/felújító topik
- Battlefield 6
- Milyen billentyűzetet vegyek?
- iPhone topik
- Androidos tablet topic
- Videós, mozgóképes topik
- Simbin topic (GTR, Race07, GTR Evolution, RaceRoom Racing Experience, stb.)
- Rendkívül ütőképesnek tűnik az újragondolt Apple tv
- További aktív témák...
- Samsung Galaxy Z Fold6 ,Navy ,120 Hz AMOLED dupla kijelző, Snapdragon 8 Gen 3,12/512 GB,2027. 07. 11
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7500F 16/32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- 2db UK billes (146 / 147) - Lenovo Legion Pro 7 (16IRX9H) - Intel Core i9-14900HX, RTX 4090
- Xiaomi Redmi Note 14 5G 256GB, Kártyafüggetlen, 1 Év Garanciával
- Samsung Galaxy s25 256GB,Uj, Dobozával 12 hónap garanciával
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest