- mefistofeles: Az elhízás nem akaratgyengeség!
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Elektromos rásegítésű kerékpárok
- MasterDeeJay: i7 4980HQ asztali gépben (vs i7 4770)
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- GoodSpeed: Te hány éves vagy?
- Toomy: FOXPOST: régen jó volt, de már jobban jársz, ha elfelejted
- sziku69: Szólánc.
- hcl: Eszelős szívatás : kijelzőtükrözés 2026
Új hozzászólás Aktív témák
-

Taci
addikt
válasz
 bambano
#5077
üzenetére
bambano
#5077
üzenetére
Alapból a my.ini-ben ez volt:
innodb_buffer_pool_size = 16MEzt most kicseréltem ennek a tartalmára:
my-innodb-heavy-4G.ini
innodb_buffer_pool_size = 2GÍgy a lekérdezés első futtatása ugyanúgy ~20mp-ig tartott, viszont amikor újra futtattam, már csak 0.01-ig.
Szóval ennél a lekérdezésnél a memória bővítése valóban segített, viszont, csak addig, amíg pont ugyanezt a lekérdezést futtatom, mert így memóriából tudja újra felhasználni. Amint akár egy feltételt is módosítok, újra 20mp várakozás, memóriába töltés. Aztán megint változtatok, megint várakozás. És ez csak 1 felhasználó, nem 10e-100e.Szóval sajnos nem ez a jó megoldás, de azért köszönöm a tippet.
------
@martonx: Az a legelső ajánlásaitok egyike volt, azóta indexelve van. Írtam is 3 hozzászólással korábban, hogy indexelt a feed_date.
Az EXPLAIN-eknél látszik, hogy hiába indexelt, mégis, ha van DISTINCT és ORDER BY is, akkor átnéz és rendez 410e rekordot lekérdezésenként, ezért tart 20 mp-ig...

Ha csak az ORDER BY-t használom, akkor 0,01 mp:

Ha csak a DISTINCT-et használom, akkor is 0,01 mp:

------
És ha van mindkettő, DISTINCT és ORDER BY is, akkor nem a jó logika mentén alkalmazza a DISTINCT-et, mert ez a találat (a LIMIT 4-gyel):
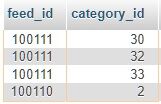
Tehát így a rekordok valóban különbözőek, viszont ezt ugye a JOIN-os nagy egészre nézi. És ebben benne van az általatok javasolt plusz tábla, amibe ki lettek szedve a kategóriák, hogy ha egy bejegyzéshez több kategória is tartozik, akkor az mind külön rekord legyen. És ezzel így összefűzve a DISTINCT valóban jó eredményt ad - csak rossz logika szerint:
nekem az kellene, hogy a feed_id-kra legyen vonatkoztatva, tehát a képernyőfotós példában a 100111 csak egyszer szerepeljen.






Új hozzászólás Aktív témák
- Használt Lenovo ThinkPad T14 G1 laptop i5, 16GB RAM, 256GB m.2 SSD, 1 év garancia
- Dell Alienware AW3225QF (31,6", OLED, 3840x2160, 240Hz, 1700R, FreeSync, G-SYNC)
- HP Laptop 15s-fq2996nz + monitor + egér és billenzyűzet + fejhallgató (INGYEN FOXPOST!)
- ASUS TUF VG279QM1A Gaming Monitor 280Hz GARANCIÁLIS!
- Canon EF 28-300mm f/3.5-5.6L IS USM - Újszerű -
- Jura Impressa S90 Automata kávégép 6 hónap Garancia Beszámítás Házhozszállítás
- Tp-Link Archer C64 Dual Band Full Gigabit Wi-Fi router
- BESZÁMÍTÁS! 8GB Crucial Ballistix Sport 1600Mhz DDR3 memória garanciával hibátlan működéssel
- Bomba ár! Lenovo ThinkPad X270 - i7-7G I 16GB I 512SSD I 12,5" HD I HDMI I Cam I W11 I Garancia!
- Keresünk iPhone 13/13 Mini/13 Pro/13 Pro Max
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Central PC számítógép és laptop szerviz - Pécs
Város: Pécs