Hirdetés
- sziku69: Fűzzük össze a szavakat :)
- Meggyi001: Áram nélkül....méltóság nélkül.....
- Luck Dragon: Asszociációs játék. :)
- sziku69: Szólánc.
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- f(x)=exp(x): A laposföld elmebaj: Vissza a jövőbe!
- Luck Dragon: Óraátállítás
- ubyegon2: Airfryer XL XXL forrólevegős sütő gyakorlati tanácsok, ötletek, receptek
- MasterDeeJay: Intel Optane M10: mire lehet használni?
- Navaren: Resident Evil Requiem szösszenet
Aktív témák
-

Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
VC1 Traffic
Isochronous Flow Control Mode
UnitID Clumping 2/3 & B/C
2x LCLK
HT Link Tristate (disable should increase performance)VC1:
This BIOS feature allows you to manually map a specific traffic class to the second (VC1) virtual channel of the PCI Express graphics port. This is the higher-priority virtual channel, so mapping a specific traffic class to it will increase bandwidth allocation priority for that traffic class. However, this is not a requirement
Isochronous Flow-Control Mode:
This has to do with how information is passed between the CPU, the GPU and the RAM along the NorthBridge. It has been a part of the BIOS for HT since AGP 8X, but the option to enable or disable it is a fairly recent addition. When this option is enabled, it assigns the information a number, in the order it was received. Each bit of information is then processed in that order along the route. In toher words, there is no loss of information, but the processing in this orderly manner has drawbacks. If you choose to enable this feature, you will also need to enable UnitID Clumping and then under PCI-E COnfiguraiton and the NB-SB section of the BIOS, VC1 needs to be enabled as well.
UnitID Clumping:
Simply put, it accounts for not all devices being equally quick at processing information. This allows each device to support a longer waiting line. VC1 accounts for a major drawback of Isochronous Flow-Control mode in that the flow control mode does not allow any information to break line. Everything must wait it's turn. Therefore, if one piece of info is intended for the CPU and in front of it is info the for GPU, the info for the GPU needs to be processed before the CPU info is processed; plus, if there is a waiting line of info to be processed onthe GPU, the CPU info is held up all that much longer. VC1 comes to the rescue by letting the CPU info break line, bypassing the GPU info jam to join the CPU info queue.
2xLCLK:
This setting only affects HT 3.0, so Phenom's may benefit from it while with Athlon's, it just does not apply. LCLK stands for Latency Clock. The 2x means that instead of one full bandwidth HT Link you are requesting two half bandwidth HT Links. For performance, at times it is better to have a two lane highway; traffic flowing in both directions at the same time along the same strip of asphalt at 50mph, than it is to have a single lane highway along the same strip of asphalt with traffic lights controlling the directional flow at 100mph.
HT Link Tristate:
A power saving feature in addition to ASPM linking. Whatever sections you want to enable Tristate in, you reduce the energy needed to run that area, but the downside is that you also reduce that area's performance
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
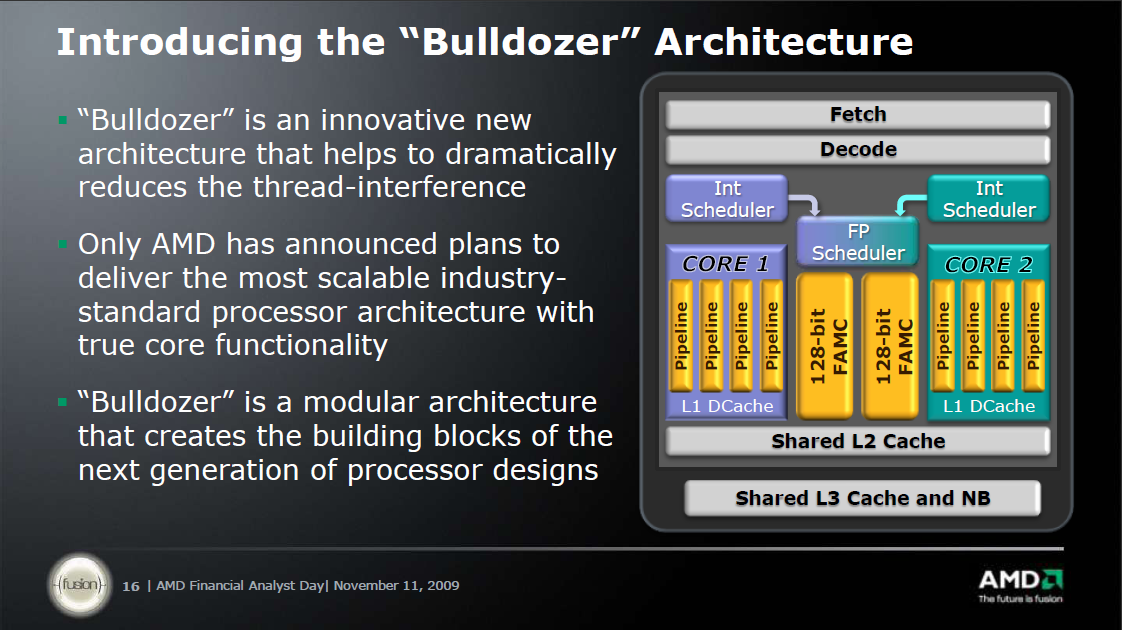
JF:
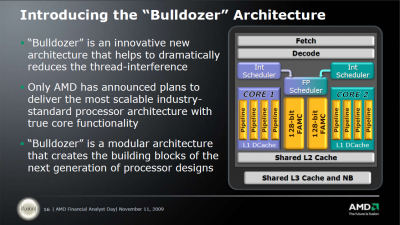
"There have been some questions about the Bulldozer architecture so this should help clear up any confusion.
First, Bulldozer is based on a modular architecture where two integer cores are teamed up with an extra-large FPU to create what we call a Bulldozer module. Bulldozer modules are the basis of all of the designs that will be coming from this architecture, and it’s modular nature not only allows us to build processors with different sized core counts but also provides flexibility for future designs that could allow other modular components like GPUs to be added into the designs. The Bulldozer module is a concept and part of an architectural design, it is not something that the user will come in contact with. For instance, when an Interlagos system boots up, the hardware will see 16 integer cores, not 8 modules. When the OS loads, it will see 16 integer cores, not 8 modules, and the applications will see 16 cores as well. Because of this extremely consistent manner by which the whole system sees the integer core (and not modules), it is only natural that Interlagos will be marketed as a 16-core processor. It would actually be more confusing to call it an 8-core processor, because there is no point where a customer would see 8-cores.
Secondly, there was a question about the amount of die space that is consumed by having 2 integer cores in a module versus just one. Bulldozer was designed to be a modular architecture where 2 integer cores are able to share certain resources where it makes sense (in order to reduce power consumption) yet still retain discrete components in order to ensure great performance and no bottlenecks. It was never designed as a single integer core in each module, so dissecting the module components becomes a bit more tricky. Some have compared this to SMT and made statements that SMT customers could see a modest increase in performance for only a fraction of die space. We believe that our Bulldozer architecture will provide far greater performance gains than SMT with up to 80% greater expected throughput when running 2 threads simultaneously compared to a single thread running on a single integer core. Our engineers estimate that the amount of discrete circuitry that is added to each Bulldozer module in order to allow for a second integer thread to run is ~12% at the core level, but because the integer cores are only a portion of the overall die space , the addition of the second integer core in each module only adds ~5% of circuitry to the total die. We believe this is an excellent balance of greater performance with a very small silicon cost.
Finally, there are those that have suggested that the two integer cores in the Bulldozer module could potentially be merged together into a single core. This is not true. Perhaps they are confusing the functionality of the FPU, which is flexible enough to be split between the two cores in the module, giving each a 128-bit FMAC simultaneously, OR can be combined into a 256-bit FMAC for one integer core to use exclusively if the second integer core does not need any FPU commands in that cycle.
We hope this clarifies the questions that seem to be most prevalent."
-
Oliverda
Topikgazda
-
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
MX Revolution (+3K) -> Performance Mouse MX

Előnyök
- Cserélhető AA méretű akksi
- Unifying rendszerű ultrakicsi USB receiver
- Menet közben állítható DPI (2 profil, 100-1500 között)
- Menet közben tölthető egy Micro USB csatin keresztül
- Dark Field Laser. Eddig csak a tükrön nem volt hajlandó működni.
Valamint látszólag a tappancsokat úgy tervezték hogy könnyen el lehessen őket távolítani. Remélem ez annyit jelent hogy a későbbiekben lehet hozzá kapni új szetet. Esetleg teflonból.
Hátrányok
- SmartShift hiánya
Bár ez annyira nem hiányzik de nem bánnám ha benne lenne.
A dobozban volt egy USB -> Micro USB kábel. USB hosszabbító. USB csatlakozós hálózati adapter 230V -> 5.15V. Mindezek egy dizájnos műbőr, belül bélelt hosszúkás Logitech szütyőben voltak, amiben ugyan a mellé pakolt egér nem fér bele, de a VX Revolution (ami mellé persze nem adtak hasonlót) kényelmesen elvan benne.
-
Oliverda
Topikgazda
There are only 3 non-overlapping channels available in the 802.11b standard.These are Channels 1,6, and 11. For WiFi access points that are located near each other it is recommended that they each use one of the above non-overlapping channels to minimize the effects of interference.
This overlapping of 2.4GHz channels are better visualized from the chart below.
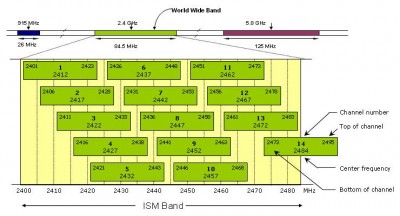
Two WiFi networks operating on the same channel are forced to share bandwidth, as they can't "talk" simultaneously, which halves each network's bandwidth. In order to evade this effect, you need to change your access point's channel, but taking the adjacent one won't do it, as WiFi channels are arranged in an overlapping pattern, as you can see from this scheme:
Channel 1 overlaps channels 2 to 5, which therefore may not be used for a neighbouring WiFi network. If channel 1 is used, you should switch to channel >=6.
There must be a spacing of at least 5 channels (or more) between each WiFi network in order to avoid interferences.
Spectrum assignments and operational limitations are not consistent worldwide. Most of Europe allows for an additional 2 channels beyond those permitted in the U.S. for the 2.4 GHz band. (1–13 vs. 1–11); Japan has one more on top of that (1–14). Europe, as of 2007, was essentially homogeneous in this respect. A very confusing aspect is the fact that a Wi-Fi signal actually occupies five channels in the 2.4 GHz band resulting in only three non-overlapped channels in the U.S.: 1, 6, 11, and three or four in Europe: 1, 5, 9, 13 can be used if all the equipment on a specific area can be guaranteed not to use 802.11b at all, even as fallback or beacon. Equivalent isotropically radiated power (EIRP) in the EU is limited to 20 dBm (100 mW).
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
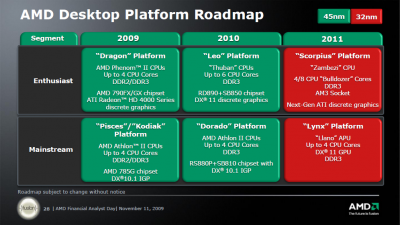
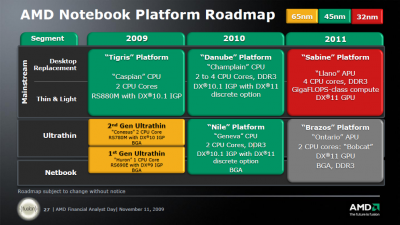
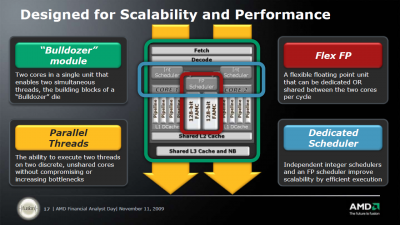
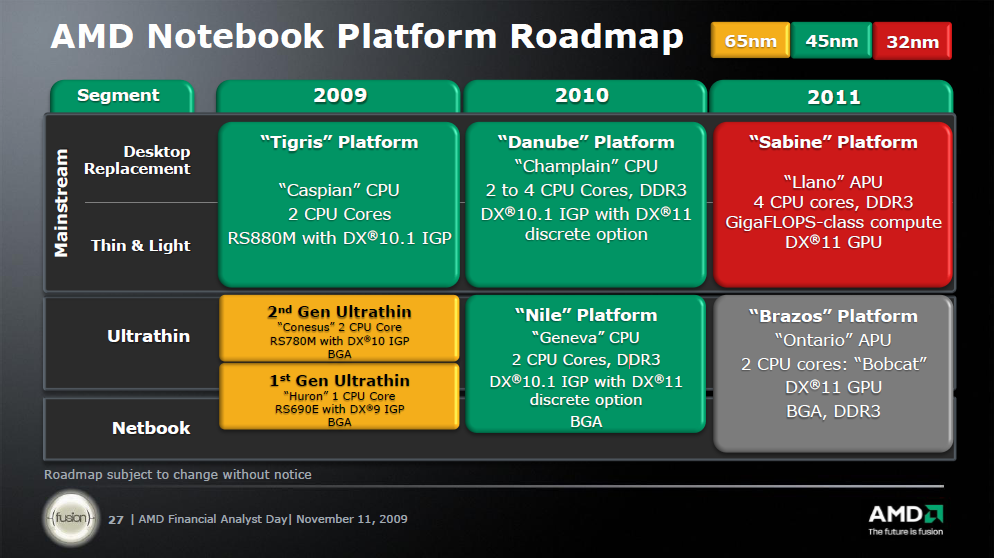
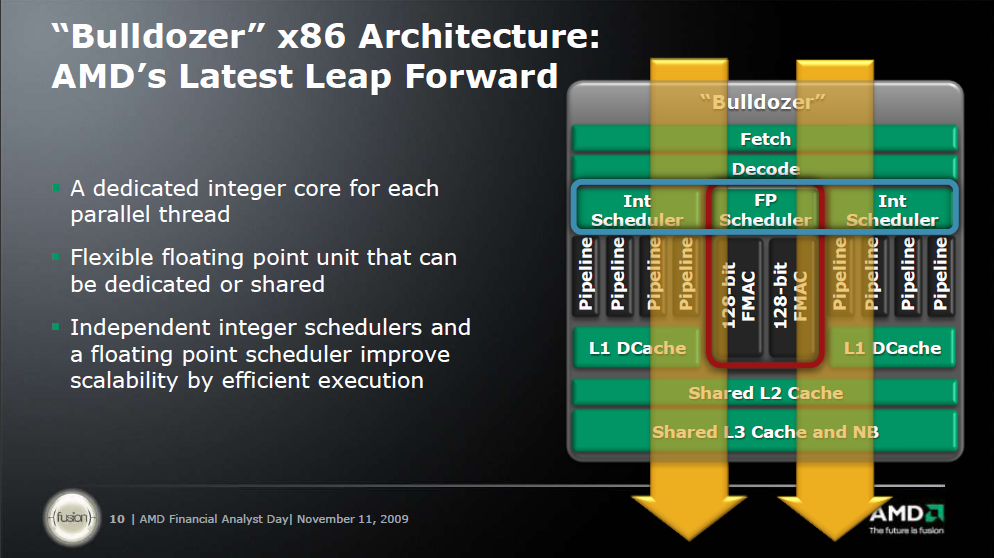
AMD's 2010/2011 Roadmap from the IT Professional’s Perspective
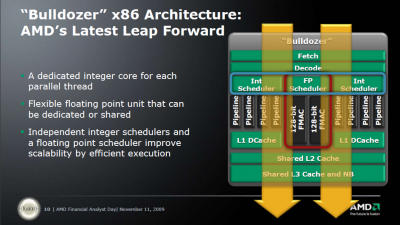
• Two integer clusters share fetch and decode logic but have their own dedicated Instruction and Data cache
• Integer clusters can not be shared between threads: integer cores act like a Chip Multi Processing (CMP) CPU.
• The extra integer core (schedulers, D-cache and pipelines) adds only 5% die space
• L1-caches are similar to Barcelona/Shanghai (64 KB 2-way? Not confirmed)
• Up to 4 modules share a L3-cache and Northbridge
• Two times 4 Bulldozer modules (2 x 8 "cores" or 16 cores) are about 60 to 80% faster than the twelve core Opteron 6100 CPU in SPECInt_rate.
With Bulldozer, AMD finally seems to have designed an aggressive integer core. Since the introduction of the Intel Woodcrest in 2006, Intel’s CPUs have been offering superior integer crunching performance per core. Since integer performance determines the performance of 90-95% of the server application out there, this is a big deal.
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
-
Oliverda
Topikgazda
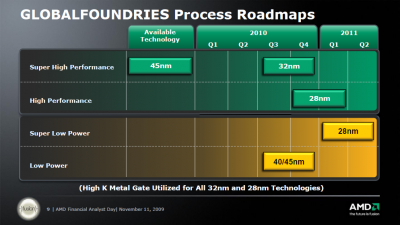
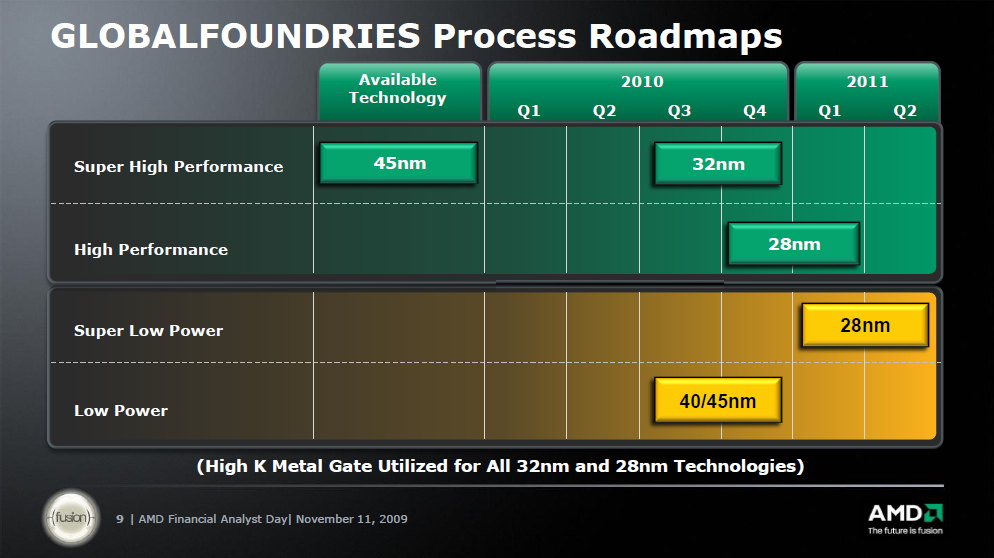
GlobalFoundries Outlines 22 nm Roadmap
"Pellerin also said that GlobalFoundries is no longer pursuing the one-transistor ZRAM developed by Innovative Silicon Inc. (ISI, Lausanne, Switzerland), a capacitor-less design based on SOI substrates. Instead, GlobalFoundries is working on a thyristor-based memory with T-RAM Semiconductor Inc. (Milpitas, Calif.). GlobalFoundries and T-RAM announced in mid-May that GlobalFoundries would co-develop 32 and 22 nm versions of the T-RAM, which is based on SOI technology, for low-power cache applications."
-
Oliverda
Topikgazda
"I asked John on the 5% additional space yields 80% more improvement between two cores. When the original info on CTM estimation came out is was 50% yields 80%. I don't know if this was a mistype that was never corrected, or if he really meant Buldozer will compress effectively two cores into the space of one which I too myself am skeptical, but i have never heard this ~5 corrected either way.
This would mean that AMD could fit two Bulldozer modules (4 cores) in the same space a Intel would require for three Nehalem cores or you could say that 4 bulldozer modules, (8 cores) would be the same size as a 6 core Nehalem processor.
However here the information is old, but still relevant: [link]
Nehalem
Core Area - 97.6 mm2
L2 Area - 7.1 mm2
L3 Area - 45.6 mm2Shanghai
Core Area - 61.2 mm2
L2 Area - 15 mm2
L3 Area - 45 mm2This is what I think John meant and probably stated the first time, but never restated; ~5% for %80% more performance is simply die wise compared to the Nehalem not the K10. Now it makes sense.
Bulldozer core is ~105 mm2 (That's 2 Integer cores and 1 shared FP core) This makes sense because 2 10k cores are 61.2 => 122.4 in size, subtract one of the L2 caches => ~105 mm2
So in effect performance density should be.
Nehalem 125% / 97.6 mm2 > 1.28% per mm2
Buldozer 180% / 105 mm2 > 1.71% per mm2
or Bulldozer will be 33% faster per mm2 then Nehalem" -
Oliverda
Topikgazda
-
Oliverda
Topikgazda
"The important thing is that each Bulldozer dual-core module is claimed to be smaller (in area) than a Nehalem (or Sandy Bridge?) dual-thread core, while achieving 50% better throughput performance."
"If a processor has 2 bulldozer modules, it will have a total of 4 integer cores and it will appear to the OS as 4 distinct cores. While there is a reduction in die size, the performance gain is massive."
"Possibly one processor with 2 modules (4 cores) and one processor with 4 modules (8 cores). On the server side we have 12 and 16 core processors that have, respectively, 6 and 8 modules."
-
-
Oliverda
Topikgazda
AMD shakes up x86 CPU world with two new designs
Interview with AMD's Fred Weber - The Future of AMD Microprocessors (March 31st, 2005)
How about a Hyper Threaded Athlon?
When Intel announced Hyper Threading, AMD wasn't (publicly) paying any attention at all to TLP as a means to increase overall performance. But now that AMD is much more interested and more public about their TLP direction, we wondered if there was any room for SMT a la Hyper Threading in future AMD processors, potentially working within multi-core designs.
Fred's response to this question was thankfully straightforward; he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources." However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree.
-
Oliverda
Topikgazda
"A few points that I'd like to note down from Chuck Moore's presentation since they're not written onto the slides:
- Bulldozer will have improved single-thread performance than today's processors
- He seems to imply that at some point SIMD instructions may be offload to GPU, but it'll be the (post-2011) future era
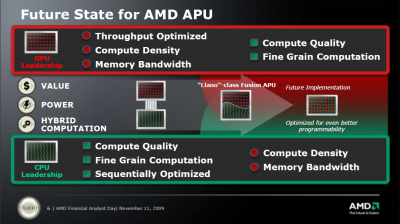
- Larger cache, higher memory integration (stacked memory) are being considered for the future era- Llano has CPU and GPU sharing the same memory controller(s)
- Llano will use currently existing (OpenCL & DirectCompute) programming model
- Llano will have the video processing & display subsystem and integrated PCIe bus- Bobcat core(s) can be integrated with GPU and/or other peripheral functions in the computer
- Future generations of Bobcat will continue to have even lower power- Each Bulldozer module is an optimized dual core
- Each Bulldozer "core" is capable of 2 loads/cycle; each is a 4-way out-of-order machine
- Bulldozer module is not bigger in area than Intel's hyperthreading design
- Bulldozer module can achieve ~80% speedup when running 2 threads (versus ~25% from hyperthreading)
- Multiple Bulldozer modules can share the L2 cache; and multiple of those (module? L2?) can share the L3 and NB
- Each INT scheduler can issue 4 inst./cycle; the FP scheduler can issue 4 inst./cycle
- "Over time" a Bulldozer "core" (INT only?) can be deployed in APU to work with GPGPU (for FP?)Conclusion: Each Bulldozer core is 4-way INT and 2 to 4-way FP (depending on sharing), up from the 3-way each in K8/K10 today."
-
Oliverda
Topikgazda
"Clarkdale" & "Arrandale" - Ahol a tákolás új értelmet nyer.
Két lapka egy nyákra ültetve akárcsak a Core 2 Quad esetében de itt ez utóbbitól eltérően a két lapka különböző csíkszélességgel készül. A CPU 32nm-en még a grafikus vezérlőt is tartalmazó lapka pedig még 45nm-en.

Ezzel még talán nem is lenne baj de bizonyos okból kifolyólag a memória vezérlő nem a CPU-ba került hanem maradt az IGP mellett. A CPU QPI-n keresztül csatlakozik az IGP + mem. vezérlő egységhez ami így ebben a formában meglehetősen hasonló a klasszikus FSB-s felépítéshez, csak az északi híd (jelen esetben az IGP + mem. vezérlő stb. kombó ami eléggé hajaz a G45-re) az alaplapról átköltözött a CPU nyákjára.
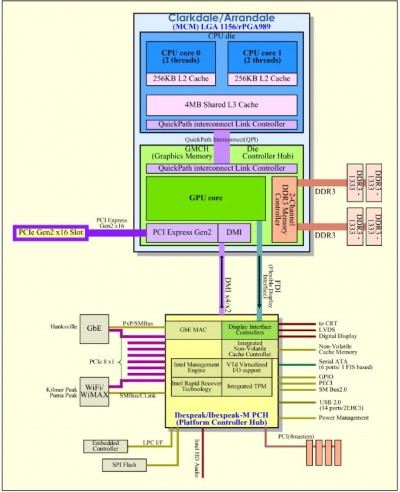
Tehát jelen esetben gyakorlatilag az FSB-t átkeresztelték QPI-re, csiszoltak egy kicsit a GMA 4500-on valamint egy nyákra rakták egy kiherélt/félbevágott és 32nm-en legyártott Bloomfield-vel így elkészült az új Clarkdale/Arrandale.
Értelemszerűen a 45nm-es rész még abban az esetben is üzemelni fog ha az IGP egyáltalán nem lesz kihasználva (pl.: P55-ös alaplapok), mivel azon kívül még ott van a memóriavezérlő is. Ezen felül a CPU-nak még át kell verekednie magát ezen a részen hogy eljusson a P55-ös PCH-hoz. A CPU-n kívül elhelyezkedő memória vezérlő pedig az FSB-s rendszerekhez hasonlóan nem lesz túl jó hatással a memória elérésre.
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
Summary:
- Intel has agreed to an important set of ground rules to a free and open market in the microprocessor industry
- New patent cross-license agreement that gives AMD broad rights and the freedom to operate a business utilizing multiple foundries
- GLOBALFOUNDRIES has agreed to terms that allow them the freedom to operate as an independent world-class leading-edge foundry company, going forward, without being a subsidiary of AMD.
- Intel has agreed to pay AMD $1.25 billion within 30 days of this agreement.
- AMD has agreed to drop all pending lawsuits against Intel as well as all regulatory complaints.
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
"C32 is a new socket but it is based on the physical 1207 mechanics. This means that all of the tooling and development costs for the socket have been amortized and it is at a low cost. And partners know how to deal with it because they have been laying out with 1207 for years.
We swapped some pin assignments so that we could support DDR-3 and higher capacities of memory, so current DDR-2 parts will not work in the new sockets. We added some keying on the socket to ensure that 1207 fits in 1207 and C32 fits in C32, no mixing. That reduces the test matrix for customers and prevents them from having to support DDR-3 on older parts."
John Fruehe
-
Oliverda
Topikgazda
Journalist: Rick you mentioned that you will be sampling Bulldozer and Bobcat in 32nm, Fusion products in the first half of 2010. That would suggest that you either have taped out or is close to taping out all those products. Can you give us some sense off where you are in terms of the development on those cores?
Rick Bergman: We don't really give out inner milestones, but we, obviously you know how the semiconductor industry works. You know, June of 2010 is 7 months from now, it takes a few months to build these things so I don't think your comments are off-target at all we are, we're loading up the gun getting ready with our next wave of these fantastic products
Journalist: You mentioned, I think the roadmap for Global Foundries showed that you had, that they were doing 32nm in the second half of 2010. So how do you actually get those built in the first half?
Dirk Meyer: That was a production question.
Emilio Ghiraldi: That's manufacturing ramp, which is consistent with the...
Journalist: So they are doing the tape-outs now?
Rick Bergman: Oh yeah, absolutely and we have running material, we have material
. -
Oliverda
Topikgazda
"Each bulldozer module will have 2 integer cores and a shared FPU. When you consider that 80-90% of the work is integer, this is a great way to keep the performance up and reduce power consumption.
For those that said HT was such a great technology because for 5% more die space they get a 10-20% performance bump, the word from our engineers is that adding a second integer core to each bulldozer module is ~5% silicon but nets ~80% performance uplift over a single integer core.
I have been saying for a long time that the HT tradeoff was not worth it, this is why.
You'll see bulldozer-based products with generally the same power and thermals that you see on today's products, but with significantly more throughput."
John Fruehe
-
Oliverda
Topikgazda
"Interesting to note are the "two tightly linked cores" sharing ressources. The shared FPU (which seems to be capable of 1x256 bit FMAC or 2x128 bit FMAC/FADD/FMUL in any combination per cycle) has been proposed many years ago by Fred Weber (AMD's CTO at that time). He already said, that two cores might share a FPU sitting between them. The whole thing is a CMT capable processor as speculated before. And if we look at core counts of Bulldozer based MPUs we should remember, that 2 such cores are accompanied by 1 FPU and an 8 core Zambezi actually contains 4 of these blocks shown on the Bulldozer slide.
Further the 4 int pipelines per core/cluster aren't further detailed, while for Bobcat they are. In the latter case we see 2 ALU + 1 Store + 1 Load pipes. For BD I still think, that we'll see 2 ALU + 2 AGU (combined Load/Store) pipes. Those "multi mode" AGUs would simply fit better to achieve a higher bandwidth and be more flexible, because the FPU will also make use of these pipes. BTW compared to the combined 48B/cycle L1 bandwidth (could be used e.g. as 48B load bandwidth) of Sandy Bridge we might only see 32B/cycle L1 bandwidth per core but up to 64B/cycle combined L1 bandwidth per FPU (although shared by 2 threads). Finally, nobody knows clock speeds of these processors, so no real comparison is possible right now.
Today rumour site Fudzilla posted some rumoured details of BD, e.g. DDR3-1866 compatibility, 8 MB L3 (for 8 cores) and "APM Boost Technology". A german site even mentioned some mysterious patents pointing into the same direction... Well, given the time frame and filing dates I see both a chance for a simple core level overclocking like Intels Turbo Boost, because this is covered in AMD patents and a chance for a more complex power management on a core component level as described in my second last blog posting."
"Take the current decoders and add a fourth. This would work most of the time but would work better if you add another small buffer between the predecode and decode stages or if you increase the depth of the pick buffer. Then you continue with 4 pipelines to the reorder buffer and down to four dispatch and four ALU/AGU units. You can't break these apart without redesigning the front end decoder and the dispatch units.
The FMAC units are now twice as fast so you really don't need more than two per pair of cores. Besides you can't keep the same ratio while doubling the speed without busting your thermal limits. Even at that, the L1 Data bus is too small. So, you double the width of the L2 cache bus and get your SSE data directly from there. This leaves the existing L1 Data caches to service the Integer units. That increases the data bandwidth by 50%. The current limit is two 128 bit loads per core. If we allow the same for FP then we have six 128 bit loads per core pair. The current limit is two 64 bit saves per core. They could leave this unchanged on the integer side and beef up the FP unit to allow two 128 bit loads, one 128 bit load plus one 128 bit save, or two 128 bit saves. That would give the FP sufficient bandwidth. The front end doesn't really have to be changed since current FP instructions are already sent to another bus. It's a good question of whether each core gets one FMAC all to itself or whether they can intermingle. Either would be possible since threading the FP pipeline would only require extra tags to tell the two threads apart. Two threads would also break some dependencies and partially make up for the extra volume due to tighter pipeline packing and fewer stalls.
Presumably, widening the pipelines to four would give a good boost to Integer performance. I suppose 33% would be the max unless they beef up the decoders but 20% would be enough. I'm guessing they would also change the current behavior of the decoders which now tend to stall when when decoding complex instructions and would probably reduce the decode time on more of the Integer instructions.
The only reason for a complete redesign would be if the architecture extensions can't fit into the thermal limits."
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
Dirk Meyer, President and Chief Executive Officer
Nigel Dessau, Senior Vice President and Chief Marketing Officer
Emilio Ghilardi, Senior Vice President and Chief Sales Officer
Rick Bergman, Senior Vice President and General Manager, Products Group
Chekib Akrout, General Manager, Technology Group
Thomas Seifert, Senior Vice President and Chief Financial Officer
Highlights








[ Módosította: Thrawn ]
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
First DirectCompute Benchmark Released
A forum member by the name of Pat has recently released a new benchmark tool for DirectCompute. This tool allows you to benchmark DirectX 11 latest general-purpose computing feature by calculating tons of FFT-like data and some memory transfers. DirectCompute is an application programming interface (API) that takes advantage of the massively parallel processing power of a modern graphics processing unit (GPU) to accelerate PC application performance. Be advised that DirectX 11 and the latest display drivers are required to run this benchmark.
Update: A new version (0.25) is now available.
Download this file in our downloads section. -
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
AMD OverDrive™ Utility 3.1.0 (2009-9-20) Update list:
1. Added support for AMD Phenom II X4 965BE CPU
2. Added support for ATI DX11 “Evergreen” graphic cards
3. Added support for additional super IO chip: IT8712
4. Added support for AMD S1g4 and ASB2 socket type CPUs
5. Enhanced the fan speed control and hardware monitoring feature
6. Enhanced AMD Smart Profiles feature
7. Improved the CPU core multiplier settings method to change only the settings of the highest P-state
8. Enhanced the apply settings mechanism for memory timings by only applying the settings that were changed
9. Fixed a bug in AODDriver
10. Fixed the bug that GPU usage cannot be retrieved even with the latest graphic driver -
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
Cuomo Files Federal Antitrust Suit Against Intel
For example, Intel is accused of paying I.B.M. $130 million to hold back on selling a server based on A.M.D.’s Opteron chip, while also threatening to curtail joint projects if I.B.M. marketed A.M.D.’s products. “The question is, can we afford to accept the wrath of Intel?” an I.B.M. executive wrote in a 2005 e-mail message, according to Mr. Cuomo’s office.
A similar e-mail message from an unnamed Hewlett-Packard executive talks about Intel planning to “punish” the company for selling products based on A.M.D.’s chips. -
Oliverda
Topikgazda
-
Oliverda
Topikgazda
John Fruehe - Director of Business Development for Server/Workstation AMD:
You are mistaken about TDP, because both companies deal with it differently.
Intel has 2 power levels: TDP and max power, (and now a third, "sustained power").
Take a look at the X5570 to see: [link]
Maximum power dissipation (W) 197.97; 155.56 (sustained)
Thermal Design Power (W) 95
So the way Intel always measured it in the past, Max power is the maximum power that a CPU can draw. Every transistor firing in a worst case scenario.
TDP is a de-rated value (used to be 80%, but it has been creeping down which is bad). Intel would take the maximum power, assume that the processor would throttle the clock down and then take that measurement (of a throttled processor) as the "TDP".
Since that time they have added a maximum sustained, maybe you can ask them what that means. I am assuming that max power is a spike power and that sustained is something that lasts more than a few milliseconds.
Regardless, the maximum power that the processor could conceivably draw is 197W.
Our TDP is equivalent to their max power, it is the maximum power the processor could draw, every transistor firing in a worst case scenario.
Our ACP is average CPU power. We run standard workloads, run them at 100% utilization and measure power.
Intel is not real open about max power. They used to post it online, but when they started getting pressure from AMD about those max power ratings, they stopped showing up online.
I'd love to have someone from Intel come here to debate this topic, because at this point, the specs (which they try to keep private) are not in their favor.
In designing a system to max power (which you have to do), we are not 42w disavantaged, we are actually 60w advantaged.
We do release max power. It is called TDP.
The reason the thermal design sheet lists TDP is because that is what you use to design systems. TDP is designed for system builders and OEMs. ACP is designed for customers in figuring out what they need for the data center.
ACP came into being a few years back because our TDP was 95W and it was rare that we ever had a part that even got above 50W. Customers were complaining that they were budgeting their racks for a certian amount of power, assuming 95W, and then ending up heavily under utilized. We were getting a lot of complaints from customers that we were too conservative and that this was leading to too much inefficiency in their data centers. I was on the receiving end of a lot of these conversations and they were not pleasant as data center floor space was the most expensive real estate in the building.
If you want a simple rule of thumb, use the following.
Most power a system can draw:
Intel = Max power
AMD = TDP
Typical power draw for standard applications:
Intel = TDP
AMD = ACP
If you are asking "why doesn't AMD just use TDP like the rest of the world" then you are on to something. We actually do. If you bother to go back to the wikipedia link above, you'll see TDP defined as:
"The thermal design power (TDP), sometimes called thermal design point, represents the maximum amount of power the cooling system in a computer is required to dissipate"
That sounds a lot like how AMD defines TDP, but that also sounds like how Intel defines max power. So, in reality, the "hoky" measurement is actually Intel's TDP because it does not represent what the rest of the industry means when they say TDP. -
Oliverda
Topikgazda
VIA Introduces New VIA Nano 3000 Series Processors
"With a host of advanced features including 64-bit support, advanced CPU virtualization technology, SSE4 for enhanced multimedia processing, and the industry-leading encryption and security capabilities integrated in the VIA PadLock Security Engine, VIA Nano 3000 Series processors also provide a secure, high-performance solution for emerging cloud-based computing environments."
Az ION-nal majd egész jó kis kombó lehet.
-
Oliverda
Topikgazda
DDR
DDR400 CL3: 1000/200 = 5 -> 15,0 ns ciklusidő
DDR400 CL2,5: 1000/200 = 5 -> 12,5 ns ciklusidő
DDR400 CL2: 1000/200 = 5 -> 10,0 ns ciklusidő
DDR500 CL2,5: 1000/250 = 4 -> 10,0 ns ciklusidő
DDR500 CL2: 1000/250 = 4 -> 8,0 ns ciklusidő
DDR550 CL2: 1000/275 = 4 -> 7,272 ns ciklusidő
DDR600 CL2,5: 1000/300 = 3,33 -> 8,325 ns ciklusidő
DDR600 CL3: 1000/300 = 3,33 -> 9,99 ns ciklusidőDDR2
DDR2-667 CL5: 1000/333 = 3 -> 15,0 ns ciklusidő
DDR2-667 CL4: 1000/333 = 3 -> 12,0 ns ciklusidő
DDR2-800 CL5: 1000/400 = 2,5 -> 12,5 ns ciklusidő
DDR2-800 CL4: 1000/400 = 2,5 -> 10,0 ns ciklusidő
DDR2-1066 CL5: 1000/533 = 1,87 -> 9,38 ns ciklusidő
DDR2-1066 CL4: 1000/533 = 1,87 -> 7,5 ns ciklusidő
DDR2-1200 CL5: 1000/600 = 1,66 -> 8,3 ns ciklusidő
DDR2-1200 CL4: 1000/600 = 1,66 -> 6,64 ns ciklusidőDDR3
DDR3-1066 CL6: 1000/533 = 1,87 -> 11,22 ns ciklusidő
DDR3-1066 CL7: 1000/533 = 1,87 -> 13,1 ns ciklusidő
DDR3-1333 CL5: 1000/666 = 1,50 -> 7,5 ns ciklusidő
DDR3-1333 CL6: 1000/666 = 1,50 -> 9,0 ns ciklusidő
DDR3-1333 CL7: 1000/666 = 1,50 -> 10,5 ns ciklusidő
DDR3-1600 CL6: 1000/800 = 1,25 -> 7,5 ns ciklusidő
DDR3-1600 CL7: 1000/800 = 1,25 -> 8,75 ns ciklusidő
DDR3-1600 CL8: 1000/800 = 1,25 -> 10,0 ns ciklusidő
DDR3-1866 CL6: 1000/933 = 1,07 -> 6,42 ns ciklusidő
DDR3-1866 CL7: 1000/933 = 1,07 -> 7,49 ns ciklusidő
DDR3-1866 CL8: 1000/933 = 1,07 -> 8,56 ns ciklusidő
DDR3-2000 CL7: 1000/1000 = 1,00 -> 7,00 ns ciklusidő
DDR3-2000 CL8: 1000/1000 = 1,00 -> 8,00 ns ciklusidő
DDR3-2000 CL9: 1000/1000 = 1,00 -> 9,00 ns ciklusidőDDR4
DDR4-2133 CL14: 1000/1066 = 0,94 -> 13,16 ns ciklusidő
DDR4-2133 CL15: 1000/1066 = 0,94 -> 14,10 ns ciklusidő
DDR4-2133 CL16: 1000/1066 = 0,94 -> 15,04 ns ciklusidő
DDR4-2400 CL15: 1000/1200 = 0,83 -> 12,45 ns ciklusidő
DDR4-2400 CL16: 1000/1200 = 0,83 -> 13,28 ns ciklusidő
DDR4-2400 CL17: 1000/1200 = 0,83 -> 14,11 ns ciklusidő
DDR4-2400 CL18: 1000/1200 = 0,83 -> 14,94 ns ciklusidő
DDR4-2666 CL17: 1000/1333 = 0,75 -> 12,75 ns ciklusidő
DDR4-2666 CL18: 1000/1333 = 0,75 -> 13,50 ns ciklusidő
DDR4-2666 CL19: 1000/1333 = 0,75 -> 14,25 ns ciklusidő
DDR4-2666 CL20: 1000/1333 = 0,75 -> 15,00 ns ciklusidő
DDR4-2933 CL19: 1000/1467 = 0,68 -> 12,92 ns ciklusidő
DDR4-2933 CL20: 1000/1467 = 0,68 -> 13,60 ns ciklusidő
DDR4-2933 CL21: 1000/1467 = 0,68 -> 14,28 ns ciklusidő
DDR4-2933 CL22: 1000/1467 = 0,68 -> 14,93 ns ciklusidő
DDR4-3200 CL20: 1000/1600 = 0,63 -> 12,60 ns ciklusidő
DDR4-3200 CL22: 1000/1600 = 0,63 -> 13,86 ns ciklusidő
DDR4-3200 CL24: 1000/1600 = 0,63 -> 15,12 ns ciklusidőDDR4-3200 CL14: 1000/1600 = 0,63 -> 8,82 ns ciklusidő
DDR4-3200 CL15: 1000/1600 = 0,63 -> 9,45 ns ciklusidő
DDR4-3200 CL16: 1000/1600 = 0,63 -> 10,08 ns ciklusidőDDR4-3733 CL16: 1000/1867 = 0,59 -> 8,57 ns ciklusidő
DDR4-3733 CL17: 1000/1867 = 0,59 -> 9,10 ns ciklusidőDDR4-4000 CL15: 1000/2000 = 0,50 -> 7,50 ns ciklusidő
DDR4-4000 CL16: 1000/2000 = 0,50 -> 8,00 ns ciklusidő
DDR4-4000 CL17: 1000/2000 = 0,50 -> 8,50 ns ciklusidő
DDR4-4000 CL18: 1000/2000 = 0,50 -> 9,00 ns ciklusidő
DDR4-4133 CL16: 1000/2066 = 0,48 -> 7,74 ns ciklusidő
DDR4-4266 CL16: 1000/2133 = 0,47 -> 7,50 ns ciklusidőDDR5
DDR5-3200 CL22: 1000/1600 = 0,63 -> 13,75 ns ciklusidő
DDR5-4800 CL34: 1000/2400 = 0,42 -> 14,17 ns ciklusidő
DDR5-5200 CL38: 1000/2600 = 0,38 -> 14,62 ns ciklusidő
DDR5-5600 CL40: 1000/2800 = 0,36 -> 14,26 ns ciklusidő
DDR5-6000 CL42: 1000/3000 = 0,33 -> 14,00 ns ciklusidőDDR5-6000 CL26: 1000/3000 = 0,33 ---> 8,67 ns ciklusidő
DDR5-6000 CL28: 1000/3000 = 0,33 ---> 9,24 ns ciklusidő
DDR5-6000 CL30: 1000/3000 = 0,33 -> 10,00 ns ciklusidő
DDR5-6600 CL32: 1000/3300 = 0,30 ---> 9,70 ns ciklusidő -
Oliverda
Topikgazda
SATA 6G 6.0 Gb/s Performance Preview - Seagate XT drive tested
Remélem hogy idővel lesz belőle 1TB-os verzió is.
-
Oliverda
Topikgazda
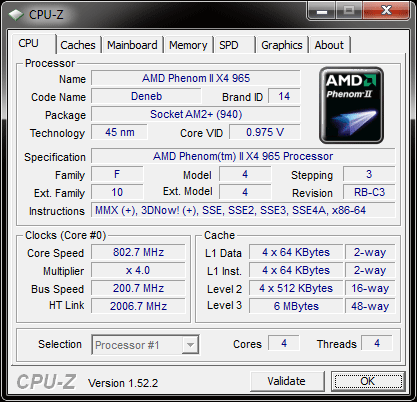
Úgy fest hogy egy kissé elsiették a publikálását. (NDA)
Ez megmaradt a Firefox-ban:

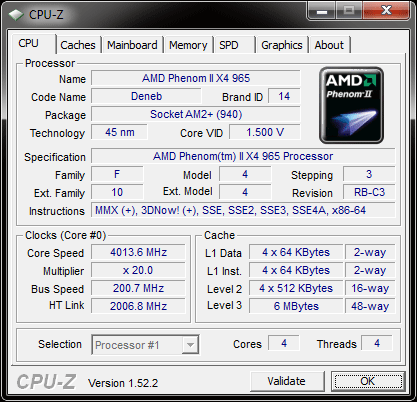
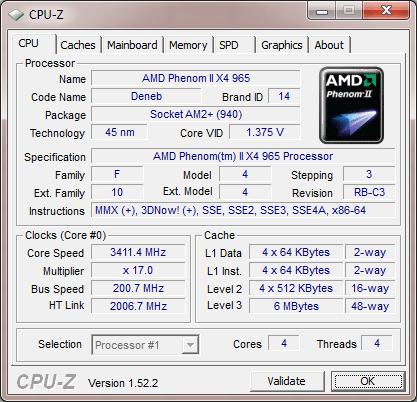
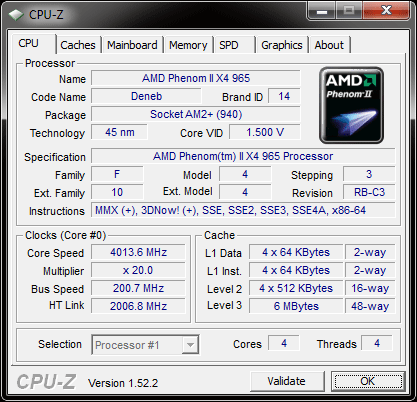
The C3 Revision
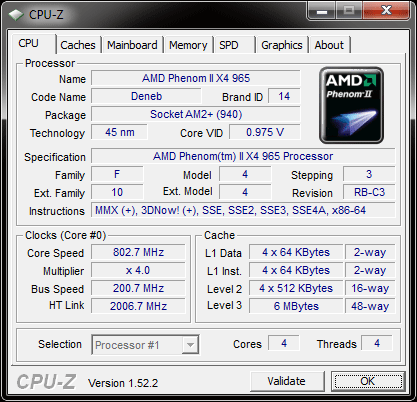
Just like its predecessor, the new Phenom II X4 965 BE runs at 3.4GHz, likewise, there are no changes in the cache architecture. Note, however, the new stepping (3) and the new revision code (RB-C3).
Idle State
Exactly like the older version, the new '965 BE C3" throttles back to a 4 x multiplier for an 800 MHz core clock if there is no load on the CPU.
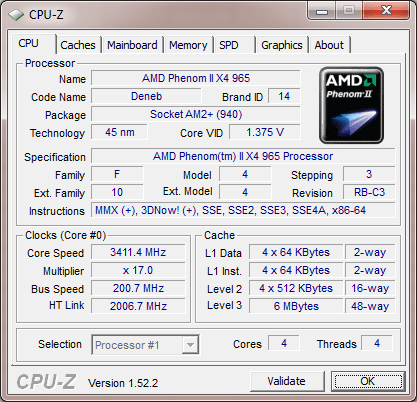
North Bridge
At default setting, the NB is running at 2.0GHz.
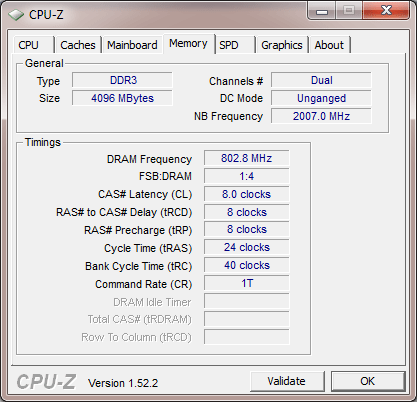
Overclocking
Whereas we had to resolve to somewhat arctic temperatures to squeeze 3.8GHz stable operation out of the previous revision, the C3 revision manages 4GHz at only a minor core voltage increase and air cooling at ambient room temperature.
We were able to get into Win7 at 4.1 GHz but it would be exaggerating to claim stability at that speed. At 4.2 GHz, the CPU still reached the Windows7 desktop but crashed. Bear in mind that all of this was achieved using standard air cooling.
On the NB side of things, 3.0 GHz was also a breeze, and we achieved a score of 16783 in the multithreaded benchmark of Cinebench R10 (4.0GHz/3.0Ghz; 32 -bit binaries in Win7 64).
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
The Golden Era of 3D Acceleration - 1994 / 2003
Érdemes megnézni.
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
AMD ATI Chips Comparison Table (9200-tól)
nVidia Chips Comparison Table (GF4 MX 420-tól)
-
Oliverda
Topikgazda
-
Oliverda
Topikgazda
Windows 7 és SSD, két jó barát
"A korábbi ígéretekhez híven megérkezett az Intel notebook SSD-khez az új firmware, mely már lehetővé teszi a Windows 7 számára a meghajtó optimális kiaknázását. A hasonló előnyök elérése érdekében az Intel szoftveres támogatást ad a korábbi Windowsokhoz."
...és az optimális kiaknázás:



















































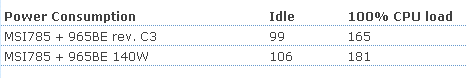


Aktív témák
- Milyen billentyűzetet vegyek?
- BestBuy topik
- Melyik tápegységet vegyem?
- TCL LCD és LED TV-k
- Tesla topik
- One mobilszolgáltatások
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- AMD Ryzen 9 / 7 / 5 / 3 5***(X) "Zen 3" (AM4)
- Milyen Android TV boxot vegyek?
- Star Trek Online -=MMORPG=-
- További aktív témák...
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7600X 32/64GB RAM RX 9060XT 16GB GAMER PC termékbeszámítással
- Motorola Edge 40 Pro 256GB, Kártyafüggetlen, 1 Év Garanciával
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- MacBook felvásárlás!! MacBook, MacBook Air, MacBook Pro
- Lenovo ThinkPad L14 Gen 1 Ryzen 5 pro 4650U, 16GB RAM, 256-512GB SSD, jó akku, számla, gar
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest