Hirdetés
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- sziku69: Szólánc.
- GoodSpeed: Nem vénnek való vidék - Berettyóújfalu
- eBay-es kütyük kis pénzért
- Lalikiraly: Astra kalandok @ Negyedik rész
- Meggyi001: Kórházi ellátás: kuka vagy finom?
- koxx: Bloons TD5 - Tower Defense játék
- sh4d0w: StarWars: Felismerés
- Brogyi: CTEK akkumulátor töltő és másolatai
Új hozzászólás Aktív témák
-
#7551
 Petykemano
veterán
S_x96x_S
#7550
Petykemano
veterán
S_x96x_S
#7550
Petykemano
veterán
válasz
 S_x96x_S
#7550
üzenetére
S_x96x_S
#7550
üzenetére
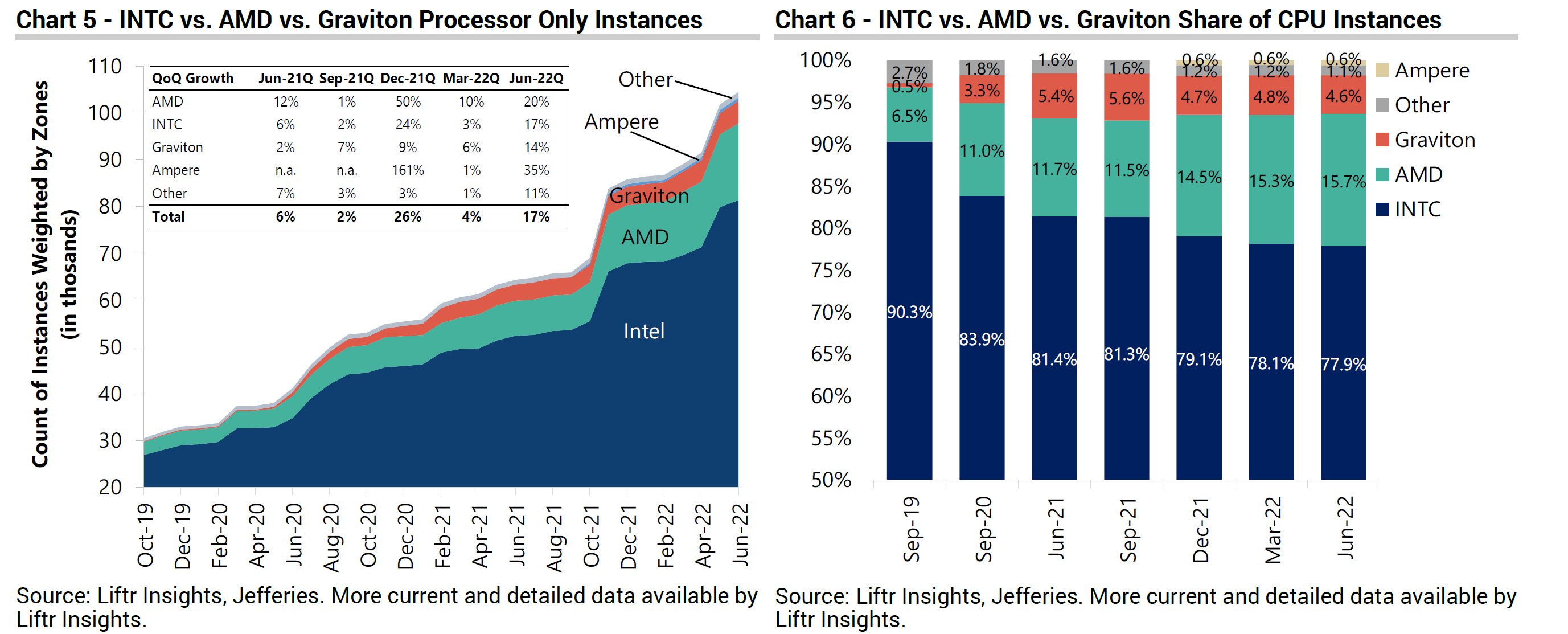
Ez elég tisztességes előrelépés.
Szerintem kevesebb, mint ami az Apple minden kétséget kizáró legyőzéséhez szükséges lenne - tehát bizonyára továbbra is fogunk hallani "az x86-nak vége" típusú megszólalásokat. (Amik persze lehet, hogy nem teljesen alaptalanok, csak azt kívántam kiemelni, hogy ezt a kérdést a zen4 nem fogja azzal zárni, hogy "ugyan, dehogy")Annyit azért hozzátennék, hogy a VCZ ábráin az 5700X kicsit alul van mérve. Ott CB20 ST 558 érték szerepel, a cpumonkey oldalán viszont 588.
De még úgy is közel 30% tempóelőnyt lehet számítani.Ez ugye egy 7700X chip, Vélhetően nem ennek lesz a legnagyobb órajele. Vajon az AMD a >15%-ot úgy értette volna, hogy a 7600X ST mérésben minimum 15%-kal gyorsabb az 5950X-nél?
MT vonatkozásában a 7900X és 7950X, valamint a 7600X valószínűleg ennél nagyobb előrelépést fog hozni az előző generációhoz képest a kitolt TDP keret miatt.
Úgy tűnik, az IPC vonatkozásában mindenki tévedett, de a Chips&cheese által publikált 29-40%-os értékek elég közel álltak a valósághoz. (Még ha részleteiben lehettek is tévedések)
-
#7546
Petykemano
veterán
S_x96x_S
#7545
-
#7540
Petykemano
veterán
S_x96x_S
#7533
Petykemano
veterán
válasz
S_x96x_S
#7533
üzenetére
Én nem vonnék le ebből a ábrából konklúziót a zen3/3D vs zen4 vonatkozásban semmit.
A0, tesztpéldány, stb okból.
Az 5800X3D célpiaca a gaming volt - ott se profitált belőle minden. a Zen4 fejlesztési célja pedig egyértelműen a MT teljesítmény növelése volt. Nem elképzelhetetlen, hogy lesz néhány olyan játék, ahol az 5800X3D megőriz valamit az előnyéből.Mindenesetre 1usmus szerint hülyeség:
"I will say that this is outright nonsense, because the bottle neck of the Zen 4 is the "width of the conveyor belt," not the cache."
[link]
(conveyor belt = futószalag)Esetleg azt is érdemes lehet megemlíteni, hogy nem törvényszerű, hogy csak az L3$-t lehet 3D (vertikális) irányba bővíteni. Mi van, ha a V-cache Gen2 lényege épp az, hogy nem csak az L3$-t fedi le (a megfogalmazás szándékos) és növeli a kapacitását, hanem az L2$-t is, ami fizikailag is ott van az L3$ mellett?

A harmadik dimenziós kiterjedés-növekedés miatt az L2$ késleltetése sem nőne számottevően, de az L2$ és L3$ méretnövekedése együtt már lehet, hogy magyarázná a 30%-os IPC növekedést és hovatovább talán azt is, hogy miért profitál belőle olyan alkalmazás is, amely a victim cache méretnövekedéséből nem. -
#7531
Petykemano
veterán
Alpi.
#7529
Petykemano
veterán
Az 5800X3D esetén épphogy az volt a tapasztalat, hogy szükségtelenné teszi a leggyorsabb (legdrágább) ramra törekvést, remekül elketyeg alcsonyabb frekvenciájú (potato) rammal is. Másként megfogalmazva a nagy cache elfedte a különböző RAM kitek sebességbeli különbséget. [link]
-
#7528
Petykemano
veterán
Petykemano
veterán
MLiD szerint a zen4 v-cache 30% többlet-teljesítményt hoz a zen4-hez képest.
Gondolkodtam, hogy az vajon miként lehet?
Elsőre az jutott eszembe, hogy elképzelhető, hogy a méréseket vagy nem 8 magos (32+64) példányon végezték el, a többlet egy részét magyarázná, ha egy 2 CCD-s modellen végezték volna a tesztet, ami (feltételezésem szerint) egyben látja az egész L3$-t (192MB)
A másik lehetőség az az, hogy az állítólag még mindig N7/N6-on gyártott V-cache már több rétegű.De egyrészt a csökkenő határhasznosság elve (az apu vs CCD és a sima vs V cache modellek alapján minden duplázás jelent kb 10% gyorsulást) miatt a 30% csak úgy jöhet ki, ha az alap 32MB L3$ helyett egy mag számára legalább 256MB L3$ lenne látható és elérhető.
Ez meghaladja az 2 összekapcsolt CCD verziót, amennyiben továbbra is 1 rétegű V-cache van használatban, vagyis legalább 2 réteget feltétekezne
Máskülönben ha az L3$ összekötésre vonatkozó feltétekezésem helytelen, akkor 4 réteg szükséges.Másrészt a fent részletezett méretbeli változásokkal lehetne tovább növelni az előnyt ott, ahol eddig is volt érzékenység, de a 2. Generációs V-cache a bemutatott ábra szerint olyan helyeken is javít, ahol az előző generáció nem tette.
Tehát könnyen lehet, hogy a nagyobb előny oka nem méretre vezethető vissza, hanem arra, hogy már nem "csak úgy" növelték a kapacitást (3d irányba, hogy kicsi legyen a hozzáadott késlektetés), hanem hozzányúltak a szervezéshez/működéshez is.Azért is valószínű ez utóbbi, mert a duplázott L2$ kapacitás miatt épphogy csökkennie kéne a L3$-re nehezedő nyomásnak/terhelésnek, hiszen az L3$ - eddig - victim cache és az kerül bele, ami az L2$-ből kiesik.
Logikusnak tűnne valami prefetcher beépítése.
-
#7527
Petykemano
veterán
Alpi.
#7526
Petykemano
veterán
Az, hogy "a Zen4 fejlesztése csak duplázott L2$-ből áll" nem úgy kell érteni, hogy "csak úgy megduplázzák".
Az AMD a Zen széria esetén mindig odafigyelt arra, hogy a cache méret növelése csak úgy történjen meg, ha a méretnövekedéssel együtt járó késleltetés-növekedéssel együtt is megéri. Nem vállalt be kétes eredményeket.
Mivel a késleltetés leginkább a fizikai kiterjedéssel és a váltási sebességgel függhet össze, a cache méret növekedése mindig akkor történt, amikor a tranzisztorok fizikai kiterjedése csökkent és a váltási sebesség gyorsult, valamint legutóbb akkor, amikor a fizikai kiterjedést egy harmadik dimenzióban sikerült növelni.
-
#7525
Petykemano
veterán
Petykemano
veterán
Van arra utaló jel, hogy a Zen4 azért mégsem teljesen csak egy Zen3 port N5-re AVX512 kiterjesztéssel és duplázott L2$-sel. [link]
Volt egy tweet (https://twitter.com/i/web/status/1559897403532394501), ami már nem él, de a következőket állította:
ROB 320, OP Cache 6.75K
Összehasonlításképp:
zen2: 224 rob, 4k op cache
zen3: 256 rob, 4k op cache
Sunny Cove: 352 rob, 2.25K op cache
Golden Cove: 512 rob, 4K op cacheAzt gondolnám, hogy a micro-op cache méretének növelése jelenékeny mértékben hozzájárulhat ahhoz, hogy magasabb IPC-t tudjon elérni a processzor, amikor két programszálat szolgál ki párhuzamosan (>SMT yield)
-
#7518
Petykemano
veterán
Petykemano
veterán
-
#7517
Petykemano
veterán
Komplikato
#7516
Petykemano
veterán
válasz
 Komplikato
#7516
üzenetére
Komplikato
#7516
üzenetére
Nem ismertem a pontos történetet, ezért rákerestem.
Az Intel CPU-ra való váltás nem közvetlenül a Motorola 68000-ról történt meg, hanem közte volt az IBM, a Motorola és az Apple által közösen fejlesztett PowerPC. Az első néhány találat azt sugallja, hogy az Apple azért váltott az a PowerPC-ről Intelre, mert a míg ők a notebookokban látta a jövőt, a processzor fejlesztési irányaira nagyobb hatással bíró IBM viszont munkaállomás irányba terelgette. És így az igényeik divergáltak.Ezzel csak azt akarom mondani, hogy nem az ISA a lényeg.
Én középtávon versengést, párhuzamos létezést vízionáltam.
De nem elképzelhetetlen, hogy lesz megint valamilyen "buzz thing", ami relatív gyorsan és alapjaiban forgatja fel a piacot.Az Apple és az Nvidia esetén is ez szerintem az integráció.
De ez szerintem nem az x86 vagy Arm ISA jóságáról mond el valamit, hanem vagy az Arm-ra jellemző üzleti modellről, vagy az azt felhasználó cég egyéb kompetenciájáról.
Tehát a "van élet az x86 után" felkiáltás helyett pontosabban írná le a helyzetet ha így fogalmaznánk:
- "vertikális integráció nélkül nincs élet, a különböző beszállítóktól származó részegységek kombinálására épülő model halott"
- "Nincs élet a CUDA-n kívül" -
#7514
Petykemano
veterán
Ueda
#7512
Petykemano
veterán
Érdemes megnézni ezt a 20perces tesztet, ami nagyvonalakban a N6-on készült 6800U és az N4-en készült M2 összehasonlítására fókuszál.
Megalázó vereség helyett egy erős verseny látható. Az M2 előnye a fogyasztás és akkuidő vonatkozásában nagyvonalakban magyarázza a gyártástechnológiai előny.
[link] -
#7513
Petykemano
veterán
Ueda
#7512
Petykemano
veterán
Ezek, hogy az x86 haldoklik és hogy van élet az x86 halálát követően - elég sarkos kijelentések.
Az x86 részleges monopóliumának lehet, hogy vége, de szerintem az, hogy kinyíltak lehetőségek még nem jelenti az x86 halálát.
Az Apple az egyetlen cég, amely az x86 ISAval dolgozó AMD és Intel kínálatával versenyképes (bizonyos szempontból jobb) processzort tudott tervezni ARM alapon. A gyári arm processzorok IPC tekintetében versenyképesek és ezért a szerverek terén láthatólag tudnak érvényesülni, de a desktop/notebook piacon még hiányzik a teljesítmény. (Amit.az apple IPC-vel, az x86tal dolgozó cégek pedig frekvenciávak hoznak)Természetesen a lehetőségek jók. Az Arm alapon tervező cégek nyilván megpróbálnak majd benyomulni azokra a piacokra, ahol jelenkeg X86 van. Desktop, szerver, konzol. De számos kézikonzol valósul meg manapság x86 alapon.
Csábító, hogy arm alapon saját magadnak is tervezhetsz, de olyan területen, ahol korábban x86 volt, komolyan ezzel eddig csak az Apple és az Amazon élt.
Ezzel együtt azt.el kell ismerni, hogy fordított irány.ritkább, az x86 nem nyomul azokra a területekre, ahol az arm dominál. Ennélfogva csak veszíthet.
Viszont amíg nem válik.általánossá.az Apple által arm alapon produkált előny, ami egyértelművé tenné az ARM ISA felsőbbrendűségét, addig én inkább egy hosszabban elhúzódó haláltusát.várnék,.semmint gyors fűbeharapást.
Persze tévedhetek.
-
#7495
Petykemano
veterán
Petykemano
veterán
Nanoreview (???)
7600X
CBR23: 1856/14707
7700X
CBR23: 1826/18039
7900X
CBR23: 1868/27026
7950X
CBR23: 1976/38270Nem tudom, hogy hiteles-e.
Azt állítják: "Please note that the tests on the Ryzen 7 7700X are done on engineering sample provided by our insiders. The data will be more accurate after we get the final version of this CPU."
De ezt bárki mondhassa kitalált/permutált számokkal is.Mondjuk fura, 7600X gyorsabb ST-ben, mint a 7700X...
(via)
-
#7494
Petykemano
veterán
hokuszpk
#7493
Petykemano
veterán
válasz
 hokuszpk
#7493
üzenetére
hokuszpk
#7493
üzenetére
> az 5800XT valami ~1.18 -ra jön ki ( 9.43 / 8 ) :
Elnézésedet kérem, de szerintem ez nem pontos számítás az SMT yieldre. A 9.43 azt mutatja meg, hogy a ST teljesítményhez képest a MT hogy skálázódik. De azt is figyelembe kell venni, hogy ST módban csak egy magot használ és 4.7Ghz-re turbózik, MT módban meg ki tudja (hűtéstől is függ), de biztosan alacsonyabb.
Akkor kapnád meg CB mérésből az SMT yieldet, ha futtatnád bekapcsolt SMT-vel és kikapcsolt SMT-vel is. Vagy esetleg még akkor, ha csak 1 magot engedélyezela BIOS-ban, mert akkor a CB MT mérés csak az SMT szálat tudja pluszban igénybe venni.
Egyébként meglepő módon az AT is hasonló eredményre jutott mint Te [link]
-
#7492
Petykemano
veterán
hokuszpk
#7491
Petykemano
veterán
válasz
hokuszpk
#7491
üzenetére
Szerintem egyik számítás sem helyes.
Az AMD esetén 256 szálat terhelt, abból egy időben 128 teljes értékű mag volt, míg a másik 128 szálat 64 mag szolgálta ki SMT-vel.Nem tudom, melyik processzornál mennyi lehet az SMT yield, de az egyszerűség kedvéért számoljunk 1.3-mal.
Ez azt jelenti, hogy az Intel esetén 112 * 1,3-mal kell osztani a 70000-t
70000/145.6 = 480Az AMD esetén 128 + 64 *1,3-mal kell osztani a 110000-t
110000/211.2 = 520Ha azt feltételezzük, hogy az AMD-nek sikerült jelentősen növelni az SMT yieldet és az nem 1.3, hanem 1.4, akkor:
110000/217.6 = 505És persze az is számíthat, hogy a nem terhelt 128 SMT szál miatt itt-ott picivel magasabb frekvenciát érhet el, mintha terhelve lenne.
Mindenesetre úgy tűnik, az egy processzormagra leosztott teljesítmény (ez nem feltétlenül ekvivalens az egyszálas teljesítménnyel, ami jellemzően magas frekvencián zajlik!) nagyjából kiegyenlített lehet.
Jó pont az AMD-nek, hogy az adott TDP kereten belül jól skálázódik a teljesítmény. Vagyis MT-ben gyorsabb lehet a Genoa annyival, mint amennyivel több processzormagot tartalmaz.A TDP kereteket persze nem tudom.
-
#7490
Petykemano
veterán
Petykemano
veterán
"Sapphire Rapids-SP vs AMD Genoa(Cinebench R23 Max Thread is 256) 70,000 points for SPR-SP and 110,000 for Genoa.."
https://t.co/6wX3Pi7AmH110000 a 192/384 magos Genoa
70000 a 112/224 magos SPRHa jól értem, a CB 256 szálat képes kezelni.
Ha nem áll meg a skálázódás, akkor 128 másodlagos SMT szállal lenne több a Genoa. Nem számoltam ki, de lehet, hogy lenne 120000 is. -
#7489
Petykemano
veterán
szmörlock007
#7488
Petykemano
veterán
válasz
 szmörlock007
#7488
üzenetére
szmörlock007
#7488
üzenetére
Értem, hogy "ott van", de ha mindent a Samsungnál kellene gyártatni, az minden szempontból hatalmas bukta lenne. A Samsung által biztosított frekvencia a GPU-k terén kb 2/3. Lehet, hogy ennek az eredménynek egy része az AMD érdeme, de akkor is a TSMC gyártástechnológiáján érték el és nem biztos, hogy át lehet vinni. Mint ahogy ugyebár amikor a Samsungtól licenszelt 14nm-es gyártástechnológiával dolgoztak a GF-nél, akkor nem is ment.
A másik meg az, hogy az ipar többi része látszólag eléggé le van maradva advanced packaaging technológia terén. A TSMC-nél ez megy, az Intel igyekszik, de mondjuk mikor hallottál Samsungtól 3D packagingről, vagy ilyen csoda high-bandwidth kapcsolatokról?
Nem mondom, hogy nem létezik, csak nem nagyon hallani róla és pláne nem hallani sikerekről, eredményekről. Tehát ha most kényszerből átugrana oda az AMD, akkor legalább akkora lemaradásba kerülne hirtelen, amilyen lemaradásban most az Intel van.Az elmúlt 2-3 évben még lehet, hogy meg lehetett volna tenni, hogy nem itt, hanem ott gyártatom, kicsit rosszabb lesz, de hát ez van. De az AMD már rajta van az advanced packaging úton. Ha nincs advanced packaging, akkor nem picit rosszabb termék van, hanem gyakorlatilag nincs termék.
Egyébként a covid időszak alatt minden cég igyekezett globálisan diverzifikálni a tevékenységét, hogy ne okozzon a jövőben globális problémát a globalizáció egy-egy pontjának szétesése. Csak szerintem ezek az üzemek még nem állnak készen.
-
#7480
Petykemano
veterán
Petykemano
veterán
According to Hungarian tech outlet ProHardver
[link]Abu megint híres lett.
-
#7450
Petykemano
veterán
Petykemano
veterán
-
#7439
Petykemano
veterán
S_x96x_S
#7438
Petykemano
veterán
válasz
S_x96x_S
#7438
üzenetére
"In the AVX512 single-threaded benchmark, the Zen 4-based Epyc Genoa part performs roughly in the same league as the Intel Xeon (Golden Cove) Sapphire Rapids-SP parts. We’re looking at 627 points for Zen 4 (2.15 to 3.5GHz) vs 628 for the Golden Cove (1.9 to 3.7GHz) core. In the multi-threaded AVX512 test, the former scores 15,625 points, higher than any other Sapphire Rapids chip on the list."
-
#7436
Petykemano
veterán
S_x96x_S
#7435
Petykemano
veterán
válasz
S_x96x_S
#7435
üzenetére
> vagyis akkor nagy valószínűséggel lesz benne AVX-512
Úgy tudom, hogy a zen4 AVX512 képessége nem valós. Mármint hogy az FPU csak 256bites, csak tudja az utasítást, hasonlóan ahogy a Zen1 is úgy tudta az AVX2-t, hogy valójában csak 128bites FPU csövekkel rendelkezett.
A Bergamo lehet, hogy úgy tudja az AVX512-t, hogy az FPU a Zen1-hez hasonlóan csak 128 bites.
> - szerintem ez már nagyrészt egy következő generációs 3D-s proci lesz .. (pl. Cache csak 3D-ben lesz )
Szerintem is. Kiemelik a lapkából a L3$-t és akkor elfér a lapkában 2db 8 magos "CCX" (ha lehet így még annak nevezni). Csak a csatlakozókat kell meghagyni.
Nem elképzelhetetlen, hogy a 3D tokozott L3$ pedig már 2x8 mag között megosztott/közös.Volt egy ilyen elképzelés a wccf-től, csak ők Zen5-nek nevezték.
[link] -
#7434
Petykemano
veterán
Petykemano
veterán
közben volt egy AMD + Samsung server témájú előadás
-
#7429
Petykemano
veterán
Petykemano
veterán
Van itt egy kis értekezés:
Old Genoa ES 32C leak from March 2022, Geekbench 5.4.4 on Linux (max boost 3430Mhz) : https://browser.geekbench.com/v5/cpu/13894822
ST score 1126
Newer Genoa ES 32C leak from May 2022, Geekbench 5.4.4 on Linux (max boost 3430Mhz) : https://browser.geekbench.com/v5/cpu/14856290
ST score 1404
Compare with 5950X running at stock, Geekbench 5.4.4 on Linux ( max boost 5000Mhz) : https://browser.geekbench.com/v5/cpu/15913819
ST score 1725
According to above, Zen 4 @ 5.7Ghz max boost should score 1404 x 5.7 / 3.43 ~= 2333 pts on Linux. That is around 2333/1725= 35% higher ST score vs stock 5950X (5Ghz max boost). Per clock, that is (1404 x 5/3.43) / 1725 ~= 1.186 or 18.6%.
[link]
Én is találtam egy mai tesztet, ami még magasabb ST értéket mutat (persze magasabb órajellel):AMD Eng Sample: 100-000000897-03 @ 3.61 GHz
Suma PEH1061002
1454/9043
https://browser.geekbench.com/v5/cpu/compare/16682066Össszehasonlító: [link]
A különbségre azon kívül, hogy az AMD a >15% értékkel esetleg alultájékoztatta a közönséget lehet magyarázat.
Volt egy olyan elméletem, hogy miszerint az 5800X3D esetén a stacked L3$ számára a kapcsolódási pontok miatt probémás volt a magasabb feszültség és emiatt az AMD kénytelen volt visszavenni a frekvenciát és letiltani a húzhatóságot is.
Azzal kapcsolatban is volt már korábban megfigyelés (zen2), hogy hiába emelnék a magok frekvenciáját csak nagyon kis mértékben, vagy egyáltalán nem nőne a teljesítmény - ha nem emelkedik vele együtt az IFCK is.Az elméletem szerint az AMD úgy érhetett el ilyen magas frekvenciákákat, hogy kicsit megvariálta a clock domaineket - vagyis leválasztotta a L3$ frekvenciáját a magokról. Ezáltal a magok lényegesen nagyobb frekvenciát is el tudnak érni, akár V-cache-sel szerelt esetben sincs az 5800X3D-hez hasonló béna korlátozás. De ez azt is jelenti, hogy bár nagyon magas frekvenciát elérni már lehetséges és fogyasztás szempontjából esetleg nem is annyira költséges (mivel nem minden részegység fog olyan magas frekvencián ketyegni), ugyanakkor egy bizonyos frekvencia fölött - mondjuk ami fölé már nem megy az L3$ - a skálázódás lelassul.
Egy ilyen jelenség megmagyarázná, hogy alacsonyabb - az epyc-re jellemző 3-4Ghz - esetén miért tapasztalható nagyobb mértékű előrelépés. És hogy ez miért nem arányosítható általánosságban az 5.7-5.8Ghz frekvenciát elérő procikra.
Ez persze nem azt jelenti, hogy semmilyen művelet nem skálázódik, csak azt, hogy nem minden. Ez magyarázná, hogy a UserBenchmark 243 pontos értéke hogyan jöhetett létre: elképzelhető, hogy olyan műveletekkel mérnek, amire pont nincs komoly hatással a külön, lassabb clock domainnel rendelkező L3$.
És természetesen magyarázná azt is, hogy az AMD miért volt "kénytelen" >15% jelzővel illetni az előrelépést. Merthogy tényleg nagy lehet a szórás.
-
#7426
Petykemano
veterán
S_x96x_S
#7425
Petykemano
veterán
válasz
S_x96x_S
#7425
üzenetére
A rajt eltolására elég logikusan hangzik az, hogy az Intel ne tudjon 13gen vs zen4 slide-okat mutogatni.
De akkor ez azt is jelenti, hogy számos mérés vonatkozásában a RPL jobb, mint a RPH.
Ez nem biztos, hogy azt jelenti, hogy jobb, de mondjuk CB meg GB5 és UB score-okat lehet mutogatni, hatalmas különbséggel. -
#7418
Petykemano
veterán
S_x96x_S
#7417
Petykemano
veterán
válasz
S_x96x_S
#7417
üzenetére
Szerintem a két képet (comp/decomp) együtt érdemes nézni [link]
Nem tudom, hogy a score a két művelet esetén mennyire összevethető, de az ábra alapján a ryzen az, ami a compression értékhez képest lényegesen nagyobb mértékben nagyobb score-t ér el decompression esetén.Az okot nem tudom. Abu mintha egyszer említette volna.
Az 5800X3D teljesítményéből lehet tudni, hogy nem a L3$ mérete az oka.Mindenesetre ha a blenderben nőtt az AMD-nek az SMT yield, akkor lehet feltételezni, hogy ez itt is számítani fog. Majd meglátjuk.
-
#7412
Petykemano
veterán
Yutani
#7410
Petykemano
veterán
Az Intel esetén a PL2 elvileg az a fogyasztás, ami fölé aztán már tényleg nem mehet még tartósan se. A PL2 az a fogyasztás, ami megengedhet magának jellemzően rövidebb ideig. Mondjuk 1 percig. (Ez is beállítás)
Az Intel elhagyta ezt a TDP fogalmat, de ez tulajdonképpen valami olyasmit jelent, hogy a tartós fogyasztás efölé nem mehet. Ennek bizonyára hűthetőségi okai vannak - erre utal a Thermal Design Power kifejezés.
Az AMD esetén a TDP nem ugyanazt jelenti, mint az Intelnél a PL2. A 105W-os TDP-vel rendelkező procik max fogyasztása kb 142W volt. Tehát az AMD PL2 ekvivalens értéke kb TDP*1.35. A 170W-os TDP kerethez tehát valami 230W-os maximális fogyasztás társulhat (PL2). Azzal annyira már nincsenek lemaradva.
Én nem örülök - környezeti szempontból - a TDP keret emelkedésének. Az kevésbé zavar, ha az egyszálas teljesítmény érdekében a proci benyal egy magon 20W-ot, de az már igen, hogy amikor a 100-300W-os tartományban dolgozik, akkor is kivasalnak belőle +5-10%-ot +100-150W árán, ami szerintem eléggé pazarló.
(Persze én értem, hogy mindenki számára lehetőség, hogy leredukálja magának a TDP keretet, de valószínűleg oka van annak, hogy a környezetterhelésre állami szabályok vannak (ha vannak) és nem mindenkinek a lelkiismeretére van bízva. )
-
#7408
Petykemano
veterán
Petykemano
veterán
Állítólag az AmD eltolta a szeptember 15-i rajtot 27-re - ugyanarra a napra, amikor az Intel eseménye van.
-
#7399
Petykemano
veterán
S_x96x_S
#7363
Petykemano
veterán
válasz
S_x96x_S
#7363
üzenetére
Abu is lehozta a kanadai webshop árait.
De hát ki tudja mi az igazság. Mert tényleg lehet placeholder. A kanadai cég gondolkodhatott úgy is, hogy a valódi árakat nem ismervén a zen3 induló áraihoz hozzápasszintott egy 10%-os inflációs értéket és kész.Nem tudni, Greymon honnan szerzi az információit. Az is vagy igaz, vagy nem. Az árazás az utolsó pillanatig változhat és nagyon sokminden befolyásolhatja.
Például az, hogy a Zen3 esetén szűk volt a wafer kínálat, hiszen ugyanakkor indult el a nagyon várt és eléggé wafer igényes PS5/XSX, valamint akkor kellett a Navi2X-szel az akkor elindult Ampere-nek is konkurenciát állítani és nem utolsósorban röviddel utána fel is futott fel a bányászat és persze a Zen3/Milan volt az első az Intel-nél tényleg több szempontból (nem csak magszám) jobb szerverprocesszor.
Ezekből legalább a konzolhatás kiesik és a videokártyák volumen szempontjából jelentős része N6-on marad. Tehát elvileg juthat Zen4 gyártásra bőven.
De persze lehetnek más hatások is. (Túl persze azon, hogy az Intel árazására is oda kell figyelni.) Például az, hogy esetleg kezdetben az alaplapok volumene is lehet alacsony, vagy a PCIE5-ös SSD-k kínálata, vagy a DDR5 ramoké. Persze nem feltétlenül kellene az AMD-nek ilyesmikre figyelnie, de mostanában szorosan együttműködik a Hynix-szel és a Phisonnal, az alaplapgyártókkal meg alap.
Tehát az árazásban figyelembe vehet ilyen partneri szempontokat is: elképzelhető, hogy azért nem lesz olcsó kezdetben, mert ha túl sokan rohamozzák meg a boltokat, akkor az alaplap vagy DDR5 memória szűkössége ezekre nézve úgyis árfelhajtó hatású lesz és akkor megint nem náluk csapódik le a mani.Szóval ezzel csak azt akartam mondani, hogy tökre nem lehet biztosra venni semmit.
Ezért készüljünk inkább úgy, hogy a kanadai árak helyesek. Ez következne abból, hogy az AMD sikeres, sikeres termékeket dob piacra, és hogy az általános piaci hangulat az inflációkövető áremelés.
Így remélhetőleg már csak kellemes meglepetés érhet minket. -
#7398
Petykemano
veterán
S_x96x_S
#7397
Petykemano
veterán
válasz
S_x96x_S
#7397
üzenetére
Köszi. Félig-meddig megválaszoltad: az AMX egy konkurens DL/ML kiszolgálási irány.
Azt értem, hogy milyen előnyökkel járhat dGPU-s megoldással összevetve.
De miért AMX és miért nem egy IGP, ami koherens módon látja ugyanazt a memóriaterületet és oneAPI segítségevel sejtésem szerint elrejthető, hogy tulajdonképpen milyen hardverelem hajtja végre a műveletet? -
#7395
Petykemano
veterán
S_x96x_S
#7382
Petykemano
veterán
válasz
S_x96x_S
#7382
üzenetére
Én ezt az AMX-et nem értem.
Miért volna praktikus mátrix.szorzást.CPU-n végrehajtani és ahhoz külön egységeket, de legalábbis utasításokat beépíteni, amikor ezt a területet viszi a legrosszabb esetben is GPU?
Ugyanez a kérdés persze már a vektor utasításokkal felvetődött. És mindig is az volt az álom, hogy a vektor utasításokat az IGP hajtja végre.Szóval vajon miért tolja az Intel az AMX-et, miközben ott vannak a tensor magok (nvidia és google)?
-
#7356
Petykemano
veterán
hokuszpk
#7355
Petykemano
veterán
válasz
hokuszpk
#7355
üzenetére
Én elég valószínűnek tartom, hogy a 7800X 3D lesz.
Ezekkel az árakkal valószínűtlen az általam vízionált CCD-k közötti kapcsolat.Ezek is lehetnek persze csak placeholderek, a piac szondázása. Eléggé leköveti a zen3 árazást. Ha a 13600K $300-350, akkor ezen az áron a 7600X és 7700X nehezen eladhatónak tűnik. Legalábbis az AMD által publikált számok alapján
Az eddigiek alapján az AMD általában alulígért és túlteljesítette a várakozásokat, de nem számottevően és nem totálisan váratlanul. Ezek az árak azt a teljesítményt tükrözik, ami a UserBenchmark ST számából következne.
-
#7353
Petykemano
veterán
Petykemano
veterán
Zen4 árak [link]
7950X $900
7900X $600
7700X $500
7600X $330 -
#7351
Petykemano
veterán
Petykemano
veterán
-
#7350
Petykemano
veterán
S_x96x_S
#7349
-
#7335
Petykemano
veterán
poci76
#7333
Petykemano
veterán
Értem az érvelésedet.
Viszont a 13900K esetén is kimutattak 40% MT előrelépést a 12900k-hoz képest, ami majdnem beérte az 5950X-t. Az AMD TDP emelése miatt elképzelhető, hogy nőni fog a gap, de attól még versenyképes lesz az Intel. Az 7900X és 7950X közé pletykált $100 pedig arra utal, hogy nem csak a 7900X szinten lesz versenyképes, különben a 7950X ára prémium lenne.Ha az AMD az intelhez áraz, akkor az intelnél is hasonló különbségeket kéne majd látni. Vagyis hogy a nagyobb lapkából készülő13700K és 13900K drága, és a 13600K egy 2+8 maggal kisebb lapkából készül, olcsóbban, jobb kihozatallal.
-
#7327
Petykemano
veterán
#36531588
#7326
Petykemano
veterán
válasz
 #36531588
#7326
üzenetére
#36531588
#7326
üzenetére
Az árak az utolsó pillanatig módosulhatnak. Márpedig itt még több mint három hétről beszélünk.
Az eddigi leak-ek alapján úgy tűnt, hogy a valahol $300-350 környékére várható 13600K a 7600X-nél eléggé, a 7700X-nél pedig kissé erősebb lesz. Persze nem tudom, hogy ez a $300-350-es jóslat már tartalmazza-e az intel jósolt áremelését. Mindenesetre amennyiben a UB benchmark tényleg téves, akkor ez a $200-300-os ár a 7600X-7700X számára nem irreális.
Abból a szempontból sem, hogy ellentétben a zen3 rajtjával, feltehetőleg most van kapacitás, van készlet.
De mi magyarázza a nagy - 2x-es - rést a 7900X és a 7700X között? És mi magyarázza a 7900X és a 7950X közötti kis rést?
A Magasabb TDP biztosan segít majd kihasználni MT szempontjából a több magot.
Én még bízom abban a saját elgondolásomban, hogy a 2 CDD-s sku-k esetén a 64MB L3$ megosztott és így gaming tekintetében is el fog válni egymástól a 8 magos és a 12 magos. Ez magyarázná a nagy különbséget.Nyilván a $300 és 600 közé ($400-500) érkezik még egy 7800X3D
A verseny jó.
-
#7317
Petykemano
veterán
#36531588
#7315
Petykemano
veterán
válasz
#36531588
#7315
üzenetére
Ez alapján én azt mondanám, hogy szerintem nem lesz.
Az Intel valószínűleg pár hónappal később megcsinálja majd a 13900KS-t, ami eléri/meghaladja majd a 6Ghz-et, ha a 13900K esetleg nem tenné.
De az AMD-nél ez az 5.7Ghz lesz a csúcs. Lehetne küszködni, csak nem biztos hogy érdemes, mikor ugyanúgy néhány hónappal később kiadhatják a V-cache-sel szerelt változatot, ami normál fogyasztás mellett lényegesen többet hozhat ott, ahol ez számít. -
#7312
Petykemano
veterán
Petykemano
veterán
"A Zen4 within Zen5 rumor I found on the internet which requires validation:
The Zen5 IOD will not be re-using the 6nm Zen4 IOD instead it will use a new 4nm IOD. That 4nm IOD has been inserted into Zen5 CPU-S/CPU-H. That IOD is a SoC which has Zen4 cores in it.With it comes a change in naming of the chiplets, which are changed to Central [System might be used here] Die and [Central might be used here as well] Computational Die(s).
Edit: Forgot to add something here.
AM5 is stuck with symmetrical computational dies. There is no Zen5+Zen4c(or d) configuration. It is just Central Die with energy-efficient(Zmin-orientated) Zen4 cores and up to two Computational Dies with high-performance(Zmax-orientated) Zen5 cores.Speculation through LNKN/GP/RPDF:
- Zen4 in central die is used majority of the time, most processes in Windows are very low power tasks aka Zmin-orientated workloads.
- Zen5 in computational die is only used as an accelerator rather than previous CCD-style, only used for high power tasks aka Zmax-orientated workloads.
- Given the above, the computational dies use CPU drivers. So, when the dGPU is loaded the computational die is loaded instead of the central die. There is no case where a game will not run on the Zen5 cores. The CCD's are not to be flooded with background tasks w/ ~110ns DRAM<->CCD, bg tasks instead will use the Central die w/ sub~64ns DRAM<->CCX."
[link]
Ez egy elég érdekes koncepció. Fantáziáltunk már erről. Én legalábbis a Dragon Range-t így is el tudnám képzelni: Egy mobil Phoenix lapka, amihez hozzá van csatlakoztatva egy nagyteljesítményű (megkockáztatom, V-cache-sel szerelt) CCD. -
#7309
Petykemano
veterán
Petykemano
veterán
Egyik sem különösebben új, csak megerősítés:
"The “Zen 5” core planned for 2024, which is built from the ground up to extend performance and efficiency leadership across a broad range of workloads."
"AMD CDNA™ 3 graphics architecture featuring 3D die stacking, 4th generation Infinity Architecture, next-generation AMD Infinity Cache™ technology and HBM memory in a single package to power what are expected to be the world’s first data center APUs, AMD Instinct™ MI300 accelerators."
"An expanded data center CPU portfolio, including the first AMD EPYC processor optimized for intelligent edge and communications deployments, codenamed “Siena,” and the “Bergamo” processors, expected to be the highest performance server processors for cloud native computing at their launch planned for the first half of 2023."
[link]
Ha most ősszel tényleg megjelenik a Raphael (6-16 mag) és idén, vagy 2023 elején a Raphael-X (ami egyrészt indokolt lehet a Raptor Lake ellenében a gaming téren és mivel kipróbált technológia, ezért nem is irreális) majd 2023 első felében a Bergamot is ledobják...
Akkor ez alapján én azt várnám, hogy valamikor 2023 nyarán lesz egy asztali processzor frissítés, ami egy normál zen4 CCD-ből áll v-cache-sel és egy "Bergamo" típusú CCD-ből áll.A 2024-re eltolt Zen4 pedig akkor éppenséggel lehet N3.
-
#7302
Petykemano
veterán
awexco
#7301
Petykemano
veterán
-
#7295
Petykemano
veterán
S_x96x_S
#7289
Petykemano
veterán
válasz
S_x96x_S
#7289
üzenetére
A L2$ mérete bizonyos benchmarkok esetén már korábban is jelentett problémát. Amikor a Zen1 megjelent 512Kb L2$-sel, akkor is volt valami benchmark, amiben kiugró eredményt ért, mert belefért az L2$-be az egész feladat.
Külön-külön sem az 1MB L2$-nek, sem az AVX512-nek nem szabadna ilyen kiugrást eredményeznie. Előbbi ugyanis az Alder Lake esetén okozott volna hasonló ugrást, utóbbi pedig a Rocket lake esetén.
Azt tudnám elképzelni, hogy a megnövekedett L2$ és az AVX512 teszt együttállása okozza. Mondjuk hogy az 1MB L2$-be már pont belefér az AVX512-es teszt. Hiszen az 1MB L2$-t az AVX512-képes Rocket lake hiányolta, míg a 1.25MB L2$-sel rendelkező ADL pedig AVX512-t nem tud.
De ez is sántít, mert az ADL megjelenésekor még az E magok letiltásával vissza lehetett nyerni a P magok AVX512 képességét. Kizártnak tartom, hogy soha senki ne futtatta volna le a UB tesztet E magok nélkül - és akkor ki kellett volna jönnie hasonló "anomáliának", aminek hasonló marketing hírverést kellett volna okoznia, hogy "Hahó, tiltsd le az E magokat, mert nyersz vele +20% ST teljesítményt az UB szerint "
Ezúttal az UB nem adott magyarázatot az anomáliára. Ez alapján sajnos arra kell következtessek, hogy az UB processzorgyártó/család alapján más és más teszteket futtat és a más tesztek eredményét közli néhány pontszámba gyúrva, vagy ha a futtatott teszt ugyanaz, akkor processzorgyártó/család alapján a kapott eredményeket máshogy pontozza vagy máshogy súlyozza.
Létezne, hogy az UB úgy működik, hogy van egy elvárt végeredmény és úgy alakítják ki a mintavételezési algoritmust, hogy pont az jöjjön ki?
-
#7293
Petykemano
veterán
S_x96x_S
#7291
Petykemano
veterán
válasz
S_x96x_S
#7291
üzenetére
Nagyon kemény.
Az Intelnek szinte semmi nem jön össze. Bár nem feltétlenül gondolnám, hogy kizárólag arról lenne szó, hogy "elhagyta őket a szerencse". A régi nevén 10nm-es gyártástechnológia csúszása nagyon betett nekik. Világos, hogy mindennek az alapja ez. De kellett 2-3 év, mire felocsúdtak a meglepődöttségből. De a gyártástechnológia (régi 10nm) és a chiplet technológia terén is nagyon bátor, nagyon ugrásszerű előrelépéseket terveztek. A gyakorló lépések kihagyásával lólépéssel akarták előzni a konkurenciát. És ez nem jött össze.Az Intel7 eredileg elég nagy tranzisztorsűrűség-emelkedést ígért, Kobalt használatával és EUV nélkül. Őszintén szólva nem is csodálkozom, hogy nem sikerült. Reméljük, hogy az Intel4 esetén már egy iteratívabb megközelítést alkalmaztak.
De ugyanez figyelhető meg a chiplet technológia terén. A TSMC eddig mindössze két olyan designt csinált, amiben a chipletek egymás felé fordítva szélessávú kapcsolattal rendelkeznek (Apple M1 Ultra és AMD Mi 250) Ezeket is idén. Az Intel pedig úgy gondolta, hogy ő majd mindenki előtt összerakja a a 4 ilyen kapcsolattal bíró Sapphire Rapidst, nem is beszélve a Ponte Vecchioról.
Én legalábbis más különösebb okát nem látom a késlekedésnek, hiszen a SPR nagyjából ugyanazokat a magokat használja, mint az Alder Lake és a rács-szerkezetű busz sem új.
Az AMD megközelítése ezúttal jobbnak bizonyult. Bevállalták a Naples-nél azt, hogy a lapkák közötti késleltetés borzalmas lesz. De végülis hibátlanul működött. És a 3D tokozás tekintetében is csak egy cache bővítést tudtak kipréselni magukból. De végülis működött.
A lesajnáló hangnem annak szól, hogy persze ezek az apró, de sikeres lépések, ha az Intelnek összejön a high-bandwidth kapcsolat, akkor bátortalan tötymörgésnek hatnának.(Arra alapozom a gondolatot, hogy a client-computing szekció az egész jól halad, nincsenek csúszások, mert nem használnak kiforratlan chiplet technológiát.)
-
#7277
Petykemano
veterán
S_x96x_S
#7275
Petykemano
veterán
válasz
S_x96x_S
#7275
üzenetére
Jól értem, hogy a UB azzal vádolja az AMD-t, hogy direkt tették nyilvánossá az egyébként tudottan "mérési hiba" miatt irreálisam kiemelkedő eredményt, hogy learassák a vírusként terjédő marketing hype előnyeit, ahelyett hogy csendben szóltak volna nekik, hogy valami nem stimmel?
-
#7262
Petykemano
veterán
S_x96x_S
#7261
Petykemano
veterán
válasz
S_x96x_S
#7261
üzenetére
Állítólag a UB már le is tekerte AzokNak a részértékeknek a súlyát, amik a kiemelkedő zen4 eredményeket produkálták. Persze értem én, hogy real world benchmarks, de....
Most akkor az összes procit újra kellene mérni? Vagy csak a háttérben újrakalkulálták az egészet? Mi változhatott a zen4-ben,.ami ilyen változást eredményezhet, de nem valós? az L2$ nem lehet, mert abból az intelnél is 1.25-2MB van már.
Vagy processzorcsaládonként külön pontozási profil lenne? Ezért jelentett kilövést az 1MB L2$ az amdnél és nem az intelnél? -
#7256
Petykemano
veterán
Petykemano
#7255
Petykemano
veterán
válasz
 Petykemano
#7255
üzenetére
Petykemano
#7255
üzenetére
Összehasonlítással még durvább a kontraszt.
-
#7255
Petykemano
veterán
Petykemano
veterán
"AMD Eng Sample: 100-000000593-20_Y AM5, 1 CPU, 6 cores, 12 threads Base clock 4.4 GHz, turbo 4.95 GHz (avg)"
Az órajel alapján azt mondtam volna, hogy ez egy Rembrandt.
De ez ugyanaz, mint a múltkor a powerboardos teszt: [link]
Ugyanakkor egy 5600X eredménnyel összehasonlítva durván magas pont jön ki
Fenti 5600X esetén pedig:
Memory 82.2
1-Core 162
2-Core 327
4-Core 647
8-Core 1,036Az ES esetén:
Memory 77.7
1-Core 243 (+50%)
2-Core 417 (+27%)
4-Core 834 (+29%)
8-Core 1,329 (+28%)A System Memory LAtency Ladder nagyon árulkodó még 512Kb és 1MB között.
Továbbra is azt gondolom, hogy a 4.4 és 4.95 nem valós órajelek lehetnek.
De ehhez a 243 pont eléréséhez (amennyiben valós) az 5600X 4.6Ghz-éhez képest kb 6.5Ghz-en kéne mennie, ami egészen elképzelhetetetlen magasság már. -
#7234
Petykemano
veterán
Devid_81
#7233
Petykemano
veterán
válasz
 Devid_81
#7233
üzenetére
Devid_81
#7233
üzenetére
Én úgy tudom, hogy az alacsony szivárgású lapkák energiahatékonyabbak, kevesebb feszültséggel is beérik, de nem tudnak olyan magas frekvenciát elérni. A magas szivárgású lapkák viszont nagyobb feszültséget igényelnek, emiatt kevésbé energiahatékonyak, cserébe magasabb frekvenciát is el tudnak érni.
A zen3-nál ez nagyon jól nyomon követhető volt:
- 5600X: magas szivárgású vágott lapkák
- 5800x: magas szivárgású teljes értékű lapkák
- 5900X: egy magas szivárgású és egy alacsony szivárgású vágott lapka
- 5950X: egy magas szivárgású és egy alacsony szivárgású vágott lapkaAz AT 5950X elemzésében is ez van leírva:
"Some users might be scratching their heads – why is the second chiplet in both of these chips using less power, and therefore being more efficient? Wouldn’t it be better to use that chiplet as the first chiplet for lower power consumption at low loads? I suspect the answer here is nuanced – this first chipet likely has cores that enable a higher leakage profile, and then could arguably hit the higher frequencies at the expense of the power."
[link]A válogatás tehát kétirányú. Nem jó (minőségű) és rossz (minőségű) lapkák vannak, hanem energiahatékony és nagyteljesítményű. És persze nyilván vannak lapkák középúton és persze azért nem zárnám ki annak lehetőségét se, hogy létezhet olyan "selejt", ami hiába nem energiahatékony, mégse képes magas órajelet elérni) De a lényeg, hogy a "jó" minőség valójában két dimenziós.
De szerintem egyértelmű, hogy az alacsonyabb szivárgású lapkákat válogatják a szerverbe és a nagyobb teljesítményt elérőket a Desktopra. minél szélsőségesebben jó valami egyik célra annál inkább selejtje a másik felhasználási módnak.Szerintem ez alapján inkább arra lehet számítani, hogy a 7700X valamint a 7900X és 7950X egyik lapkája továbbra is az energiapazarló típusból kerül ki értelemszerűen ezen belül úgy szétválogatva, hogy a magas frekvencia elérése szempontjából valószínűleg csak harmadrangú lapkákat fog kapni a 7700X. A magas frekvencia elérése szempontjából elsőrangú lapkák mennek nyilván a 7950X-be, de annak második lapkája nem biztos, hogy "épp jó valamire" típusból kerül ki, hiszen a 7950X MT teljesítményét azzal tudják maximalizálni, ha oda egy kifejezetten energiahatékonyság szempontjából jó minőségű lapkát helyeznek el. Persze más kérdés, hogy mi lenne a legjobb és más lehet az, hogy mi jut.
A közepes, egyik szempontból sem kiemelkedő "éppencsak jó valamire" lapkák szerintem a 7600X és a 7900X második lapkájának mennek, ahol se az energiahatékonyság nem fontos szempont a csökkent magok miatt és a kiemelkedően magas frekvencia elérése sem.
-
#7232
Petykemano
veterán
Petykemano
#7231
Petykemano
veterán
válasz
Petykemano
#7231
üzenetére
Az, hogy a 8 magos csak 7700X lesz némiképp megerősíti bennem azt a gondolatot is, hogy lehet valami trükk.
A zen3 esetén főleg az 5800X, 5900X és 5950X között olyan nagyon nagy különbség nem volt gaming terén. Másképp fogalmazva szinte semmilyen haszna nem volt annak, a két CCD miatt kétszer annyi (de nem kétszer akkora) L3$-sel rendelkezett a processzor. (Ez így volt a Zen2 esetén is CCD-n belül)Szóval én még mindig számítok arra, hogy a CCD-k azért ülnek egymáshoz közel, mert átjárható és megosztott a két CCD-ben található L3$. Ez egy olyan feature lenne, amivel a 7950X úgy léphetne élre valós felhasználási területeken, hogy az az eddig nyilvánosságra hozott CB tesztek nem mutatnak ki.
És értelemszerűen ez egy olyan teljesítméynbeli differenciát eredményzet a 12-16 és a 8 magos változat között, ami indokolhatja 1 hely kihagyását. -
#7231
Petykemano
veterán
Devid_81
#7228
Petykemano
veterán
válasz
Devid_81
#7228
üzenetére
Egyesek azzal magyarázzák, hogy a 6+8 magos Raptor Lake (13600K) nagyon versenyképes (MT teljesítményben és értelemszerűen árban is) és emiatt a 8 magos Zen4-et nagyjából azon a szinten lehet eladni, mint amin az 5700X debütált ($299) és nem pedig azon, amin az 5800X ($449)
És persze nyilván jól jön, hogy oda mind teljesítmény, mind ár szempontból befér majd a 7800X3D.Elképzelhető, hogy ellentétben a N7-en induló Zen3-mal, ezúttal nem lesz házon belüli wafer-konkurens és ezért meg is engedhetik majd maguknak, hogy jobban válogassanak, több jusson a mainstream-nek.
-
#7226
Petykemano
veterán
S_x96x_S
#7224
Petykemano
veterán
válasz
S_x96x_S
#7224
üzenetére
az AMD elég sok nevezéktani következetlenséget elkövetett. Nehéz megtalálni a logikát, mert egyáltalán nem arról van szó, hogy arra törekednének, hogy egy generációban mondjuk a processzormagok homogének legyenek - hacsak nem tekintjük a Zen3+-t egy önálló processzorgenerációnak.
Régen ugye egy generációval le voltak maradva az APU-k. Tehát lehetett tudni, hogy x-es generációban x-1-es cpu architektúra van. Ez egészen a 4000-es Renoirig így volt.
Akkor az AMD dönthetett volna úgy, hogy a 4000-es széria megtartja. Elindulhatott volna a zen3 4000-esként. De valószínűleg mivel a Zen3 a Renoirhoz képest elég későn rajtol és mert az APU-k kezdtek felzárkózni - hamar jött a Cézanne - ezért az 5000-es széria megkezdése mellett döntött.
Ez lehetett volna egy ilyen kiegyenlítő esemény is, hogy jó, akkor innentől adott szérián belül az APU-k ugyanazt az architektúrát használják mint a DT/S processzorok.Szerintem egyébként ilyen szempontból hiba volt a Rembrandt-ot 6000-esként elindítani. VAn különbség a Renoirhoz képest, mert az konkrétan javított a processzor architektúrán a 3000-es nevezéktant addigra elfoglaló Picasso-hoz képest.
De a Rembrandt CPU tekintetében alig különbözik a Cézanne-tól. De valahol érthető, hogy mivel már az összes hely 5980HK-ig foglalt volt, már nem nagyon lehetett tovább fokozni.Viszont nagyjából ugyanaz a helyzet lehet, mint a Zen3 esetén volt. 6000-esként már nem lehet elindítani a Zen4-et, mert a küszöbön van a sokkal jobb procival bíró Zen4 apu is.
Szerintem lehet arra számítani, hogy lesz majd egy szintén foghíjas 8000-es széria is.
Mondjuk egy nagyobb APU Zen4 alapon, vagy esetleg csinálnak egy 8+16 magos Zen4 változatot.Nem tudom, mi a jobb: az ilyen ugra-bugrálás, vagy az, ha egy sorozatszám alá tömnek be több különböző generációs terméket. Mellesleg ilyen is volt.
-
#7217
Petykemano
veterán
S_x96x_S
#7215
Petykemano
veterán
válasz
S_x96x_S
#7215
üzenetére
> vagyis a "végitélethez"
![;]](//cdn.rios.hu/dl/s/v1.gif) várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..
várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..
> És a 5950X - még ddr4! vagyis ez így nem fair
Bocsánat, de én nem mondtam, hogy az AMD dicsősége múlna el, vagy hogy a Zen4 ne lehetne nagyonis versenyképes. Ha ezt lehetett belőle kiolvasni, akkor elnézést a félreérthetőségért.Én csak arra utaltam, hogy a (2019!-es) hiper-szuper csúcs MT ász 5950X-et az idén érkező középkategóriás(nak nevezett, az árát majd meglátjuk) lapka eléri.
Ez akkor is így van, ha egyébként az már DDR5. Persze, ez is előny. Elképzelhető, hogy ugyanez a beérés meg fog történni a versenyképes árazású Zen4 processzor esetén is.
-
#7210
Petykemano
veterán
Petykemano
veterán
Így múlik el a dicsőség: [link]
(5950X vs 13600K) -
#7206
Petykemano
veterán
hokuszpk
#7205
Petykemano
veterán
válasz
hokuszpk
#7205
üzenetére
Az IBM SMT8-ra képes processzorai esetén a 2. szál yield-je 80% körül volt. Vagyis amikor 1 processzormagon 2 programszál futott, akkor az egyes programszálak gyorsasága kb 90% volt ahhoz képest, mintha csak 1 programszál futott volna a procin.
Ez jelenti azt, hogy sokat malmozik a proci.
A 40-45% yield (2 programszál esetén 70-75%-os sebesség) még elég messze van. Ha erre ráengednének még egyet, annak yieldje lehet, hogy lenne mondjuk még 15-20%. (3 programszál egyenként 50-55%-os sebesség az egyszálas sebességhez képest)
A 4. szál reálisan már csak plusz 5-10%-ot jelenthet. (4 programszál egyenként 45%-os sebesség az egyszálashoz képest)Ne érts félre, ki nem zárnám, mert a CB MT benchmark megnyerésében sokat segítene akár asztali, akár HEDT szegmensben.
-
#7204
Petykemano
veterán
hokuszpk
#7203
Petykemano
veterán
válasz
hokuszpk
#7203
üzenetére
Háááát. Ha jól emlékszem, a korábbi számokból én azt deriláltam, hogy ha és amennyiben az L2$ méretnövekedése (és a most látható BW növekedés) megdobja az SMT yieldet és abból származik a MT teljesítmény előnye, akkor is az csak 15%.
egy 40-45%-os SMT2 yieldre azért még nem építenék rá SMT4-et.Én kifejezetten nem örülnék neki egyébként. A Cloud szolgáltatók - legalábbis a GCP - újabb magokból nem is kínál már olyan konstrukciót, ami páratlan számú magot lehetővé tenne. Ez nyilvánvalóan azért van, mert 2db vCPU valójában egy fizikai mag 2db SMT/HT szála. Ennek meggőződésem szerint biztonsági okai vannak - hogy ne lehessen SMT/HT-n sérülékenységet kihasználva törni.
Ha bevezetik az SMT4-et, szerintem arra ugyanez a szabály érvényes lesz, csak már úgy, hogy 4 vCPU-t fognak egységben kínálni, ami továbbra is 1db fizikai magot és a hozzátartozó 4 hardveres szálat jelentené. Persze amennyiben ez a 4 vCPU ellenére nem drágább, mint a korábbi 2 vCPU-s konstrukció, akkor jöhet, de én azért tartok tőle, hogy burkolt áremelést hajtanának végre általa.
-
#7194
Petykemano
veterán
Petykemano
veterán
Jönnek a RAptor Lake leak-ek.
A 6+8-as RPL például olyan durva cpu-Z eredményt mutat, ami meghaladja az 5900X MT eredményeit is. Az 5600X-hez képest pedig 2x.Persze világos, hogy ez majd csak a CineBench-ben fog kijönni.
Mindenesetre ezzel együtt is úgy tűnik, hogy a 6 magos Zen4 esetében újra 95W-ra kiterjeszett TDP-vel számolt 45%-os MT teljesítmény növekedés kevés lehet.Vajon lefokozza az AMD a 8 magos SKU-t 7600X-re, hogy stimmeljenek a versengő elnevezések?
És persze mivel nem az elnevezés a lényeg, hanem az ár, ezért vajon lefokozza-e a 8 magos SKU-t $299-ra? (Feltéve, hogy abban az árszegmensben érkezik az 13600K is)Vagy elengedi a szintetikus teszteredményeket - azokat nyerje olyan SKU, amit olyanok vesznek, akiknek tényleg számít a MT - és rábízza a küzdelmet az inkább gamereket érintő középkategóriában a V-cache változatra?
-
#7191
Petykemano
veterán
hokuszpk
#7190
Petykemano
veterán
válasz
hokuszpk
#7190
üzenetére
5.8-at emlegettek, vagy akár még tovább - pletykaszinten.
Az AMD mintha >5.5-öt írt volna.Mindenesetre én azért írtam óvatos 5.2-5.5-öt, mert hát ez mégse egy 7950X, hanem csak egy 7600X mintapéldánya elvileg. A kettő között szokott lenni ~400Mhz difi.
(Egyébiránt gőzöm nincs, hogy a PowerBoard 3.0 benchmark eredménye vajon elválasztja-e egymástól a CPU és GPU score-t vagy egy olyan kombinált eredményt ad, amire hatással lehet a CPU és a GPU is.)
-
#7188
Petykemano
veterán
Petykemano
veterán
Zen4 ES eredmények
A történet szerint a szóbanforgó benchmarkban kb 10%-kal gyorsabb, mint egy 5950X.
Ha tényleg 4.4Ghz-en ment (mármint hogy az volt a max/turbó és nem pedig valami base) akkor az igencsak jól hangozna. Hiszen akkor innen lehetne számolni még +25%-ot 5.5Ghz-ig. Ez sajnos elég valószínűtlenül hangzik.
Reálisabb, hogy a 4.4 csak base clock volt és valójában turbózott az 5.2-5.5Ghz-en is. A korábban demózott teljesítmény-növekedéssel ez állna irányban.
-
#7186
Petykemano
veterán
Yutani
#7185
Petykemano
veterán
Én nem hiszem, hogy költség oldalról ne érné meg.
Elhiszem, hogy GDDR5M nem működött, mert az AMD nagyon pici piaci szereplőként nem tudta standardizálni.
Azt is el tudom hinni, hogy kezdetben a HBM és az interposer ára túl magas volt ahhoz képest, amilyen piaci szegmenst a termékkel meg lehet célozni. Ne felejtsük el, hogy az amd nem apple, tehát nem tud nagy mennyiségben drága de jó cuccot eladni. És a tervezési és gyártási költség meg nem független a volumentől.
Arról nem is beszélve, hogy egy új memóriamodellt kellett volna elfogadtatni, ahol a HBM vagy rendszermemória, vagy csak gyorsító. Ez egyébként hasonló, mint az Intel DRAM+Optane, de még az sem szivárgott le a mainstreambe.De kitömni a lapkát IC-vel, hogy kompenzálja a sávszélesség hiányát szerintem minden korábbi lehetőségnél egyszerűbb - és már csak azért is indokolt lehetne, hogy az OEM gyártók ne tudják bebuktatni az erősebb IGP-t azzal, hogy csak 1 RAM modult tesznek a gépbe.
A Rembrandt 210mm2. Ez 12 CU - IC nélkül
A 16CU-val rendelkező navi24 16MB IC-vel kompletten belefér 107mm2-be.
Szerintem egy 300mm2-es apuba beleférne akár 32CU is 32Mb IC-vel.És azért ez nem jelentene olyan nagy költséget se. $20-30 max.
Mit jelentene ez árban? Hát kb ekkora gpu-kat adnak 8GB GDDR6-tal pcb-vel hűtővel $300-400-ért.
Szerintem egy ilyet, ami bőven rendelkezik egy navi24 teljesítményével $250-300-ért nyereséggel el lehetne adni.Szerintem az állhat a háttérben, hogy a fő vásárlók az oemek. És ők meg nem szeretnének integrált cuccokat, mert szeretnék megválogatni, hogy milyen beszállítótól milyen alkatrészekből milyen terméket raknak össsze.
A minipc és DIY pedig ebből a szempontból niche. -
#7184
Petykemano
veterán
S_x96x_S
#7183
Petykemano
veterán
válasz
S_x96x_S
#7183
üzenetére
> - not support Infinity Cache (large L3 cache)
Egyrészt kár.
Másrészt viszont azt gondolnám, hogy amennyi CU lehet benne, annak valószínűleg nem indokolt.
De azt gondolnám, hogy ha már az RDNA3 úgyis fel lesz szeletelve, akkor egy lépéssel közelebb kerülünk egy olyan nagytesóhoz, ami esetleg már chiplet formában kapja a GCD-t és 3D tokozva az infinity cache-t. (Nem gondolnám, hogy a Phoenix point ilyen lesz.) -
#7177
Petykemano
veterán
S_x96x_S
#7176
Petykemano
veterán
válasz
S_x96x_S
#7176
üzenetére
Elég komoly....
Nagy Márton recessziót vár év végére
Az amd és az nvidia tsmc gyártókapacitást mond vissza.
A kriptopiac bedőlni látszikEközben:
Genoa lineup -
#7171
Petykemano
veterán
Petykemano
veterán
Greymon szerint az AMD 2022Q4-ben már 50k N5 wpm kapacitással fog rendelkezni.
"AMD will have 50K 5nm wafers in Q4." [link]
Az mondjuk, több, mint gondoltam.
-
#7168
Petykemano
veterán
S_x96x_S
#7167
Petykemano
veterán
válasz
S_x96x_S
#7167
üzenetére
Nem teljesen értem.
Nyilván nem vagyok tisztában minden sku teljesítményével.Ebben a tesztben a specint2017 perlbench esetén 7 körül megy az M1 és a mobil zen3 is. Elnézést, most én csak megemlítettem az első csíkot.
Ebben a tesztben az M1 ugyanúgy 7+ ebben a tesztben az X2 pedig nem éri el az 5-t.
Az ADL a zen3-nál elvileg valamivel jobb teszteredményeket ér el. Hogy lesz az X2-nél 11%-kal gyorsabb X3 hirtelen 34%-kal gyorsabb az X2-nél 40%-kal gyorsabb zen3-nál is gyorsabb ADL-nél?
-
#7166
Petykemano
veterán
Petykemano
veterán
/konkurencia - arm/
Bejelentette az arm az A715 és X3 magokat.
Előbbi +5% teljesítményt vagy -20% fogyasztást, utóbbi átlag 11%-os IPC növekedést ígér.
Asszem IPC, tehát valamennyi még jöhet frekvenciából. Nem tudom, hogy arra gyúrtak-e. Ha igen, az még javíthat az összképenMindenesetre hát ez azért elég távol van a korábbi évenkénti 20-30%-os IPC (teljesítmény) növekedéstől.
Ha tippelnem kéne, azt mondanám, hogy talán az lehet az ok, hogy N4-re tervezett design, nem N3-ra.Most így fejből nem mondom meg, hogy mennyi választja el az X3-at felépítésben az M1-től, de teljesítményben szerintem még elég derekas az M1 előnye. Annak ellenére, hogy láthatólag igyekeznej szélesíteni az architektúrát. Az Apple a gyors, de nagy L1 cache-sel talán tényleg szent grált talált.
-
#7164
Petykemano
veterán
Petykemano
veterán
-
#7162
Petykemano
veterán
Petykemano
veterán
"It's been rumored in the last few days that there will be several new products for ZEN3D. It's true, and there will be further information next month."
[link]
Kiváncsi vagyok, mit dobnak le.
Mivel az 5800X3D-re se volt jellemző az extrém melegedés, ezért nem gondolnám, hogy arról lenne szó, hogy megoldottak volna valamilyen fogyasztási/energia/hő kérdést. Hanem csak sikerült megfelelő mennyiséggel ellátni a Milan-X piacokat és már jut ide is.(Persze ne vegyük 100%-nak)
-
#7161
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 7000 mobile (Dragon Range/Phoenix) get first rumored specifications
Ez érdekes.
Azt nem tartom valószínűnek, hogy monolitikusan készítsenek külön egy 8 és egy 16 magos változatot. Viszont az merülhet föl kérdésként, hogy vajon ha már minden chiplet, akkor a CCD és az IOD (cpu rész) feltétlenül monolitikusnak kell-e lennie
Bár az ábrából ez nem látszik, de nekem így lenne logikus, hogy van egy 2CU-s 8magos alap (CCD+IOD vagy monolitikus), ami önállóan is használható akár.
Ha melléteszel még egy CCD-t => Dragon Range
Ha melléteszel még egy GCD-t => Phoenix Point -
#7159
Petykemano
veterán
hokuszpk
#7158
Petykemano
veterán
válasz
hokuszpk
#7158
üzenetére
Hát nem tudom.
Az 5800X3D esetén nem mértek megnövekedett SMT yieldet.Az első generációs v-cache tényleg csak egy extension volt. Azt gondolnám, hogy ha az victim típusú L3$ bővítése előnyösen járulna hozzá egy 3. esetleg 4. szál hasznos működtetéséhez, akkor azt már a 2 szálas működés esetén is kéne érzékelni.
Mondjuk lehet, hogy igazad van. Lehet, hogy azoknál a programoknál, amelyeknél érzékelhető volt a V-cache pozitív hatása (+50-80%) ott az SMT yield emelkedése is hozzájárult a teljesítmény növekedéséhez. Ugyanezen programok esetén lehet, hogy hasznos lehet további hardveres szálak bevezetése
Én azért remélem, hogy a blenderben mért 45%-kal nagyobb MT számítási teljesítmény (ami 31%-kal hamarabb történő feladatvégrehajtást eredményez) nem SMT4-nek köszönhető.
Sajnos nem emlékszem, hogy a slide-okon volt-e említve, hogy hány thread. -
#7157
Petykemano
veterán
Petykemano
veterán
Zen4 - SMT4
Újra előkerült -
#7156
Petykemano
veterán
Petykemano
veterán
Az régóta ismert, hogy
- a különböző típusú részegységek egy chipben különböző mértékben skálázódnak egy kisebb gyártástechmológia.esetén
- valamint hogy a skálázódás egyre inkább csökken.Amikor látunk egy ilyen 1.7-1.8x-os sűrűségszorzót az jellemzően a logic típusú tranzisztorokra érvényes és persze nem is titkolják, hogy az IO csak 1.1-1.2 az SRAM pedig 1.4-1.5x mértékben sűrűsödik csak.
Az N5 esetén valami változott, mármint hogy a megszokottnál kevésbé slálázódott.
Az N7 gyártástechnológiág ha az AMD nem is érte el csak a névleges sűrűség felét-kétharmadát, armos mobil lapka gyártók esetén azért látható volt, hogy elérik a névleges sűrűséget.
N5 esetén ez senkinek nem sikerült.
Ami azt jelenti, hogy valószínűleg az AMD esetén is kisebb lehet a tranyösűrűség emelkedése. Tehát lehet, hogy a zen4 tranzisztormennyisége nem nőtt olyan mértékben, mint azt eddig egyesek számolták.The TRUTH of TSMC 5nm is revealed by Angstronomics!
We detail the following densities:
N5 HD 2-Fin: 137.6 MTr/mm²
N5 HP 3-Fin: 92.3 MTr/mm²
N3E 2-1 FinFlex: 215 MTr/mm²
Measuring transistors on Apple's A15
N5's CNOD
What could N3S be?
N2 and much more!
https://t.co/TJyxpXS7U3
[link] -
#7152
Petykemano
veterán
Petykemano
veterán
/Apple M2/
Hát ez nem valami fényes.
azért fura, mert ugyanakkor nem tűnik úgy sem, hogy az M2-t eredetileg N3-ra tervezték volna. Ha jól emlékszem, az IGP nagyobb mértékben bővült. A CPU talán csak annyi táncfelvarrást kapott, hogy ne érkezzen üres kézzel. -
#7148
Petykemano
veterán
Petykemano
veterán
-
#7147
Petykemano
veterán
-
#7145
Petykemano
veterán
S_x96x_S
#7144
Petykemano
veterán
válasz
S_x96x_S
#7144
üzenetére
Én nem vagyok ebben 100%-ig biztos.
Lisa Su a FAD-on valóban kiemelte, hogy a fő szerver vonalon megmaradnak ugyan X86 vonalon, de fognak ARM processzorokat is tervezni, mivel a Xilinx és a Pensando standalone termékek Arm processzorokkal készültek eddig és azt nem tervezik lecserélni.Bár most a cikkekben úgy jelenik meg, hogy a K12 projektet Jim Keller távozása után lőtték le, a távozásakor voltak arról pletykák, hogy valójában ugye nem ő volt a chief architect a zen fölött, hanem ha nem is tervezője, de szívügye a K12 volt és távozása épp annak köszönhető, hogy azt lestoppolták.
Lisa Su megjegyzése épp elegendő felületet adhat egy ilyen esetben Jim Keller számára, hogy odaszúrjon, hogy "na látjátok, milyen jól jönne most". Ez nem sértettség, legfeljebb afféle szakmai hiúság: "végül nekem lett igazam"Persze nem tudhatjuk, hogy lett-e volna az AMD-nek erőforrása a hasonlóságok ellenére két külön processzor családot fejleszteni. A cikkek is említik, hogy bár lehet, hogy ma jól jönne egy K12 (mai állapotban), de nem biztos, hogy ugyanazokat a kiváló termékeket látnánk ma, ha az AMD-nek meg kell osztania a figyelmét és erőforrásait.
Viszont azt látjuk, hogy az AMD portfóliója növekszik. És itt most nem a Xilinx és Pensando termékekre gondolok, hanem az X86 processzorcsaládokra. Zen3 esetén készült már V-cache-es változat, Zen4-ből már lesz v-cache és egy dense változat is. APU-kból is most már megengedhetik maguknak, hogy ne egy jack-of-all-trades típusú termékkel fedjék le a piacot, hanem legyen egy elfogadható CPU és GPU teljesítménnnyel rendelkező standalone mainstream APU (Phoenix Point) és legyen egy kifejezetten CPU teljesítményre gyúró, de képet adó - akár standalone munkagép, akár dGPU mellé szerelhető high end APU*.
Számos oldalágon történő projektről hallottunk, ezekből egy végül el is készült, a Mendocino.
Tehát azért az AMD-nek érezhetően több kapacitása lett kísérletezgetni.
Ha Jim Kellernek igaza van és az Arm és X86 processzorok tényleg nem különböznek olyan nagy mértékben, és egy kész zen core designban szinte csak a frontendet kell lecserélni, akkor szerintem is láthatunk majd saját ARM processzort az AMD-től.Végülis a Xilinx-nél és a Pensandonál eddig is megvolt a know-how és a talent, hogy gyári Arm magokat beépítsenek. az AMD cpu design team-nek tényleg csak a CPU magot kell megterveznie (átterveznie) nem az egész SoC-t.
De vajon mit nyerne vele?
Nem arról van szó, hogy ha valaki tervez az ARM processzort, akkor az hirtelen 50-100%-kal jobb IPC-t vagy hatékonyságot ér el. Még kevésbé gondolnám, hogy ha a Zen processzorcsaládot terveznék át, akkor azt hirtelen nagymértékben megtáltosodna IPC vagy hatékonyság tekintetében. Itt eddig egyedül az Apple tudott valamit varázsolni és a Nuvia ígérte ugyanazt. Az AMD-nek (és az Intelnek) ugyan nem IPC, hanem frekvencia irányba van nagymértékű tervezési tapasztalata. Ha viszont az AMD úgy kezd el ARM processzor architektúrát fejleszteni, hogy az széles és alacsony frekvenciát ér el, akkor viszont nem kifejezetten jól lehet a két processzorcsalád között technológát megosztani. Bár én szívesen látnám, ha az AMD követné az Apple-t a széles és alacsony frekvenciát elérő architektúra irányába **
Az AMD kifejezte, hogy a hagyományos szerver termékek tekintetében maradnak x86 vonalon.
Vajon a Xilinx és Pensando termékek esetén mit nyernének, ha az azokban dolgozó Arm magok mondjuk 30-40%-kal magasabb teljesítményre lennének képesek - persze fogyasztás árán.* Az a vélekedésem, hogy Raphael egy dupla szubtsztrátú Dragon Range, nem jött be, de jelen információk szerint a legesélyesebb az, hogy valójában ugyanabból az építőkockákból fog épülni.
** Már nem emlékszem, melyik videoban hallottam vagy cikkben olvastam, hogy magas frekvenciát elérni mindig helytakarékosabb, mint magas IPC-t és hogy az Intel és az AMD designjai azért célozzák inkább a magas frekvenciát, mert a rendelkezésükre álló kapacitás a kiszolgálandó piachoz képest nagyon korlátos. Magyarán így tudnak többet eladni.
Abból nekik kevés előnyük származna, ha a termékeik ugyanezt a teljesítményt tudnák hozni, de csak 30%-kal kevesebbet tudnak belőle értékesíteni a kapacitások miatt, miközben mondjuk 50% áramköltséget spórolnak a vevőnek. -
#7143
Petykemano
veterán
thgergo
#7142
Petykemano
veterán
válasz
thgergo
#7142
üzenetére
Abu régóta riogat kis epyc platformmal.
Feltehetően azért nem jött, mert költséghatékonyan tudták lefedni a 24/32 magos piacot is. De a 96 magos 12 csatornás genoával az olló nyílik. (Különösen ha a mainstream megmarad 16 magnak)
A siennával egyszerre fedik ezt a lukat és tudnak versenyezni a 32+ magos HEDT SPR-rel. -
#7138
Petykemano
veterán
Petykemano
veterán
Az Intel - végre - elindítja a 16-32 magos Sapphire Rapids alapú HEDT platformját.
Nekem az a gyanúm, hogy a döcögős termékrajt azért olyan, mint amit a CannonLake/IceLake/TigerLake esetén láttunk, mert ez jön ki a rendelkezésükre álló eszközökből. Bizonyára gyártástechnológiai /packaging hibák és/vagy tervezési bugok miatt küszködnek, de már áll ott a cucc, hogy ezt kiadják.
Ugyanekkor: occó Zen3 TR PRO eladó
-
#7133
Petykemano
veterán
S_x96x_S
#7131
Petykemano
veterán
válasz
S_x96x_S
#7131
üzenetére
Elnéztem volna?
Az alsó két sorra (7800X, 7600X) meg mertem volna esküdni, hogy $550 és $450 a felette levő kettőre nem emlékeztem, de hogy a legalsóban $450 volt az tuti.
De mondjuk nem a tweetet olvastam, hanem csak az értesítőt. Bár úgy tudom, tweetet nem lehet módosítani, legalábbis ingyenes fiókkal nem.
A wccf által felvázolt árakban már semmi kiugró nincs - se pozitív, se negatív irányba. -
#7129
Petykemano
veterán
HSM
#7124
Petykemano
veterán
Kinek mi mit jelent... és mi alapján számítod...
Greymon már törölte a posztot, de
Így volt az ár-előrejelzésének alján egy $450-os 7600X volt. Amennyiben az egy hatmagost jelent, az hát brutál áremelkedés lenne.
Tehát besorolás alapján ez mainstream, de ha abból indulunk ki, hogy ki mit engedhet meg magának, akkor könnnyen belátható, hogy könnyen legnépszerűbb termékké válhat egy négymagos. -
#7123
Petykemano
veterán
S_x96x_S
#7121
Petykemano
veterán
válasz
S_x96x_S
#7121
üzenetére
nem számolgattam, de mintha tényleg egyre hosszabb lenne a nyíl, vagyis mintha tényleg egyre több időt venne igénybe az TSMC-nek is egy új gyártástechnológia piacra dobása.
Az meg aztán teljesen szokatlan, hogy előre ismertetik a különféle változatokat.
Emlékeim szerint az N6, később az N4 még egy-egy később ismertetett leágazás volt, de az különféle utógatokról általában csak véletlenül szereztünk tudomást, mert Abu elkotyogta. Lehet, hogy nem volt titok, de nem is volt nagy dobra verve.
Az N3 esetén az alváltozatok viszont szokatlan nyíltsággal lettek már előre bejelentve
Úgy tűnik, tényleg vége a Finfetnek. Mindenesetre én arra számítok, hogy az N3 már nem lesz zökkenőmentes.Szerencsére persze a épp jókor jött megmentésüknkre a chiplet-technológia. Lehet mindent a megfelelő gyártástechnológiai válozaton gyártani. Végülis lehet, hogy csak ez a magyarázat a 3 különböző változatra...
-
#7122
Petykemano
veterán
S_x96x_S
#7120
Petykemano
veterán
válasz
S_x96x_S
#7120
üzenetére
> - 4nm? ( a videocardz ebbe sorolta )
Elvileg úgy van, hogy a Raphael és Raphael-X N5
Az APU pedig N4
A Zen4c-ben nem vagyok biztos. De ha tippelnem kéne, szerintem az is N4> hogy az AMD próbálja az alsóbb szegmenseket is becélozni
Ha figyelembe vesszük, hogy a Rembrandt már 210mm2 N6-on!, egy ilyen 110-150mm2-es cuccnak azért már nem nagyon szabadna olyan nagyon drágának lennie csak azért, mert N5.
Persze ez a jövő évi kínálat már, és mivel N5, lehet, hogy az árakat nem az gyártási költség határozza meg, hanem a wafer kínálat.Egyébként igen, én is azt gondolom, hogy nagyon népszerű lesz.
Egyben azt is jelenti, hogy miközben persze szélsebesen nő az az egyszálas teljesítmény, csúszunk vissza a 8 magból a 4 magba (mainstream) -
#7118
Petykemano
veterán
S_x96x_S
#7113
Petykemano
veterán
válasz
S_x96x_S
#7113
üzenetére
Ami ebből fontos az szerintem az, hogy a Zen5 tehát 2024-ben érkezik csak.
Amennyiben a Zen4 tényleg megjelenik szeptemberben, úgy a Zen5 2024-es megjelenése legjobb esetben is 16 hónapos intervallumot jelent a két termék között.Ez már nem hangzik annyira jól, mint a 2023 végi megjelenés - ha közben az Intel tartani tudja az 1 éves release ciklusokat.
Az okokról érdemes lehet találgatni. Az N3 késése óta latolgatjuk, hogy vajon késik-e vele a Zen5, vagy megoldják valahogy N4X-en. Nem mondom, hogy ez azt jelenti, hogy akkora Zen5 biztosan N3-on készül, mert könnyen lehet, hogy az N4 kapacitásokból meg az Nvidia miatt szorultak ki.
Mindenesetre ezzel kapcsolatan érdemes egy pillantást vetni az ábrára. Nyilvánvaló, hogy a gyártástechnológia számok csak a CCD-re vonatkoznak, de legalábbis nem tartalmazzák az IOD-t, ami a Zen4 esetén N6-on készül, ami viszont nincs feltüntetve.
Ebből én arra következtetnék, hogy a Zen4 N5, Zen4+V-cache N5 és a Zen4c pedig N4
És elképzelhető, hogy ha az alapvető felépítésen nem változtatnak, vagyis nem bontják tovább a chipletet, akkor a Zen5 és Zen5 v-cache N4-en készül, a Zen5c pedig N3-on.További érdekes kérdés, hogy vajon van-e jelentősége annak, hogy a Zen3 esetén "3D V-cache"-t tüntetnek föl, a többi esetében csak simán "v-cache". Az vajon nem 3D lenne? Fura lenne, mert a V-cache-ben a V-ről eddig azt gondoltam, hogy a Vertical-t jelenti.
Persze eközben 16+ hónap közben az AMD ledobja a Zen4 + V-cache és Zen4c termékeket is.
Ezek lehet, hogy elegendőek lehetnek az elvileg 2023-as Meteor Lake ellen. -
#7103
Petykemano
veterán
S_x96x_S
#7102
Petykemano
veterán
válasz
S_x96x_S
#7102
üzenetére
Ezt a cikket olvastam, amikor eszembe jutott valami.
A Sunny Cove L3 cache-ről:
"Tiger Lake increases L3 slice size to 3 MB, increasing total L3 size to 24 MB. At the same time, the L3 has been changed to not be inclusive of the L2. With 10 MB of total L2, an inclusive L3 would use over 40 percent of its capacity duplicating L2 contents to maintain cache coherency. Changing to a non-inclusive policy dictates changes to the L3’s cache coherency mechanism. Previously, each L3 line would have core valid bits indicating which core(s) might have that line their private L1 or L2 cache. That reduces snoop traffic on the ring interconnect. Tiger Lake’s non-inclusive L3 has to use a different mechanism, since a line can be in a core’s private caches without being in the L3. There’s likely a set of probe filters alongside the L3, like Skylake-X’s setup.
These changes come at the cost of about 9 cycles of extra L3 latency. Lower clock speed from 10nm process deficiencies make latency even worse, meaning that Tiger Lake relies a lot on its enlarged L2 to maintain performance. Ironically, Tiger Lake’s L2-heavy setup is better for maintaining IPC with increasing clock speed. Intel’s uncore clock (which includes the L3) has struggled to keep pace with core clock ever since later Skylake generations started reaching for 5 GHz and beyond. L3 accesses get more expensive as the gap between uncore and core clock increases, so keeping memory accesses within the full speed L2 helps performance at higher clocks."Én úgy tudom (de ha nem, akkor majd valaki kijavít és abban az esetben elnézést), hogy a Zen esetén az L3$ órajele megegyezik a magórajellel. Legalábbis az, hogy az 5800X3D órajel (pontosabban feszültség) limitációja erre utal. Gondolom azért kell az egész cpu-nak limitáltnak lennie, mert az L3$ nem külön frequency domain.
Ha és amennyiben ez a megállapításom helyes, akkor egyrészt a jövőben az egyre gyakoribb 3D varázslások miatt az ebből fakadó imént említetthez hasonló limitációk elkerülése érdekében talán praktikus lehetne az AMD-nek is meglépni, hogy elválasztja egymástól a core+L1+L2 és az L3 frekvencia tartományokat.
Másrészt az jutott eszembe, hogy mi van, ha ezt a zen4 esetén már meg is lépték és épp azért tud annyira magas frekvenciát elérni, mert a böhöm nagy kiterjedésű L3$-t már nem kell azon a nagyon magas frekvencián járatni. A külön szabályozható L3$ frekvencia abból a szempontból is hasznos, hogy a 3D ráépítmény kevésbé nehezíti meg a hűthetőségét, vagy ha a hőtermelés mégiscsak korlátozást jelentene, akkor külön szabályozható az L3$ frekvenciája, tehát például lehetségessé válik, hogy az L3$ 3D felépítmény nélkül magasabb frekvencián ketyegjen, mint 3D felépítménnyel.

















![;]](http://cdn.rios.hu/dl/s/v1.gif) várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..
várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..



Új hozzászólás Aktív témák
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Ford topik
- Call of Duty: Black Ops 7
- Parkside szerszám kibeszélő
- Apple MacBook
- A jövőre utal a CoD: Black Ops 7 egy új beállítása?
- Debrecen és környéke adok-veszek-beszélgetek
- Megtartotta Európában a 7500 mAh-t az Oppo
- Home server / házi szerver építése
- Ezzel jobban keresel, mint az arannyal
- További aktív témák...
- Szép állapotú Wireless Xbox Stereo Headset
- Ryzen 7 5800X3D + Strix B550-A + 32GB Corsair Dominator + RX 7900 XTX NITRO+ 24G + 1200W 80+ plat
- HP ZBook Fury G8 - RTX A3000 - ajándék dokkolóval és laptop hűtővel
- Heatkiller Tube 100 D5 - full extra
- Gigabyte AORUS 17 - i7-12700H - RTX 3070 Ti - 32GB RAM - 1TB M2 SSD -FHD 360H- eredeti csomagolásban
- ÁRGARANCIA!Épített KomPhone i5 14600KF 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- ŐSZI BOMBA AKCIÓK! PSN, STEAM, UBISOFT CONNECT, EA APP, XBOX EREDETI KULCSOK 100% GARANCIA
- ÖNERŐ NÉLKÜL, 12 RÉSZLETRE ELITRO PC BANKMENTES KAMATMENTES RÉSZLETFIZETÉS
- Nagyakkus, mobilnetes - Dell Latitude 5330 i3-1215U 6mag! 16GB 1000GB 13.3" FHD 1 év gar
- REFURBISHED - HP USB-C Universal Dock G1 (DisplayLink)
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest