Hirdetés
- Luck Dragon: Asszociációs játék. :)
- sziku69: Fűzzük össze a szavakat :)
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- droidic: Videó letöltés yt-dlp-vel (profi módszer)!!!
- vamzi: Vodafone te csodálatos... (Volt UPC)
- Parci: Milyen mosógépet vegyek?
- Lenry: Melléképületblog - 4. rész - Kocsibeálló
- Elektromos rásegítésű kerékpárok
- Wiz Khalifa: Grand Theft Auto VI - Érdekességek, látványosságok, képek, infók egy helyen.
- CsST: Mi az az instant túra?
Új hozzászólás Aktív témák
-

ADrew68
újonc
Sziasztok!
nekem az lenne a kérdés hogy van egy Asus radeon R9 380 4Gb nevezetű videókártyám és mellé van egy AMD fx 6300 as processzorom (alap órajel nincs húzva), és az lenne a kérdésem hogy egy gyengébb gépen miért mennek jobban a játékok mint ezen a gépen, pl a Need For Speed 2015 akár low akár high ugyan úgy laggol, gta 5 úgy szintén szokott laggolni már midum-high beállítástól, de nagyon irritáló hogy egy ilyen erős videókártya nem viselkedik úgy ahogy kéne! És örülnék ha erre végre lenne valami megoldás
Full konfigom:
Asrock 970 extreme2
AMD Fx 6300
Asus radeon r9 380 4gb
Cheiftech 500w táp
Kingstone hyperx 2x4gb 1600mhz
1 ssd
1 hdd
alap hűtés
és FHD -
#64
 honda 1993
senior tag
honda 1993
senior tag
honda 1993
senior tag
Es megegy kerdes.
Meddig egeszseges emelni a felszultseget?
jelenleg 1.5 felett van egy picivel, mert kisebb feszen mar nem birja a magasabb orajelet.
Illetve nem tudom hogy hogy a ram feszultseget is emelnem kellene-e. ( kingston hyperX 1600 mhz ddr3 )
kingston hyperX 1600 mhz ddr3
Chiefteec ctg 500 a-80
fx 6100
gygabyte ga 970a-ds3 -
#63
honda 1993
senior tag
honda 1993
senior tag
Sziasztok.
Az lenne a kerdesem hogy gyari allapotban (3.3 ghz) mekkora pontszamot ert el a proci ?
mert en elfelejtettem meg a gyari allapotban letesztelni, es mostmar 4.2 ghz-en uzemel. ( es szeretnem ha lenne valami osszehasonlitasi alapom.)
-
#62
 compifan12
csendes tag
compifan12
csendes tag
compifan12
csendes tag
2 dolog.1:A teszt fantasztikus
2:van aztán itt gpu limit.Mondjuk nekem is hasonló lesz.Csak hd 7950 vga-val.

-

P.H.
senior tag
Nem csak érzed, valóban "flexibisebb" bizonyos tekintetben, de ez nagyrészt a szerkezetéből adódik: a GCN-végrehajtók int32/int64/float32/float64 adattípuson tudnak dolgozni (ebbe konvertálnak fel memóriaolvasáskor és ebből le íráskor, összekötve a vektoradatok átrendezésével; a byte- és 16 bites word-feldolgozás hiányzik ugyanúgy, mint az extended precision 80 bites FP; egy pixel nekik int32 típusú, az ezeken végzett műveletek egy része is csak int24) és a vektoradatokat már betöltéskor ill. kiíráskor is át tudják rendezni (ez nem gather-eset, az több memóriacímről olvas, ez pedig egyetlen folyamatos memóriaterületet, csak átrendezi a vektorelemeket). Ezért izmos memóriahozzáférési pipeline-okkal rendelkeznek, amikkel egy CPU nem. Azok más szempontból vannak kigyúrva: (a GCN in-order jellegével ellentétben) OoO végrehajtás mellett kezelik azokat ez eseteket, amikor ugyanarra a címre történik írás, mint ahonnan olvasás is (pl. store-to-load forwarding, memory disambiguation), ez GCN esetében nem bírna gyakorlati jelentőséggel.
Jobb lenne természetesen, ha nem lennének a végrehajtók specializálva, de ez mind-mind tranzisztorigényes feladat. Pont az AMD-nek van régi tapasztalata abban, hogy hogyan lehet olyan felépítést alkotni, amelyben minél több végrehajtó lát el azonos feladatkört (pl. az ütemezők 'rovására', egyszerűsítése érdekében, mint a K7/K8/K10 3 szinte azonos képességű ALU+AGU+ütemezője).
Példa: a Llano Store/Convert Unit-ja (a konvertálás is specializált az FMAC0-ra Bulldozer/Piledriver esetén), Store Align-je, vagy a Load/Store 1-2 Unit, majdnem akkora méretű, mint a az FPU műveletvégző egységei vagy a 64 KB-os L1D.
-

Abu85
HÁZIGAZDA
Ok ez így érthető köszi. Viszont ami feltűnt most a leírásod alapján, hogy eléggé korlátozottnak érzem, hogy a négy végrehajtóból három bír egyedi feladattal. Ennél egy GPU-t, mondjuk egy GCN CU multiprocesszort sokkal "flexibilisebbnek" érzek. Nem lenne kifizetődőbb olyan 128 bites egységeket használni, amelyek közül mondjuk kettő-kettő képes speciális feladatra?
-

mickemoto
őstag
(OFF)Update: A cikk elkészültének napján megjelent az új FX széria. 10% körüli teljesítmény javulás, hajszállal alacsonyabb fogyasztás és jobb tuning potenciál jellemzi a leírások alapján. Az ára egyelőre ismeretlen, de a legfőbb erősségei, hátrányai nem változtak lényegesen.(/OFF)
Ez a három sor szerintem feleslegessé teszi a Vishera-s cikket.

-

giigz
veterán
Nekem is ilyen procim van, meg vagyok vele elégedve, megérte a pénzt.
 3,8 GHz-en megy, a biosban 1,30V-os feszültséget állítottam be, de a droppolás miatt ez kevesebb a valóságban, viszont így még stabil, mert 3,9 vagy 4 GHz-en már nem stabil, bár 1,30-on biztos az lenne, de prime alatt csak 1,20 körül van a feszültség... Lehetne a biosból feljebb venni, de azt meg hűtéssel nem bírom...
3,8 GHz-en megy, a biosban 1,30V-os feszültséget állítottam be, de a droppolás miatt ez kevesebb a valóságban, viszont így még stabil, mert 3,9 vagy 4 GHz-en már nem stabil, bár 1,30-on biztos az lenne, de prime alatt csak 1,20 körül van a feszültség... Lehetne a biosból feljebb venni, de azt meg hűtéssel nem bírom...Nem mintha nem lenne elég a 3,8 GHz
Egy jó hűtéssel viszont 4-4,5 GHz-et is ki lehet hozni belőle...Jó írás lett, szépen bemutatja a 6100-at.

-
P.H.
senior tag
Ezt már többször olvastam tőled, hogy a "úgy tervezték a FlexFP-t, hogy szétváljon, ha nem AVX kódot kap.". Nem, nem így tervezték; nem, nem válik szét, sőt 'össze sem kapcsolódik', ha AVX kódot futtat.
Ez a FlexFP sematikus rajza szerintük:
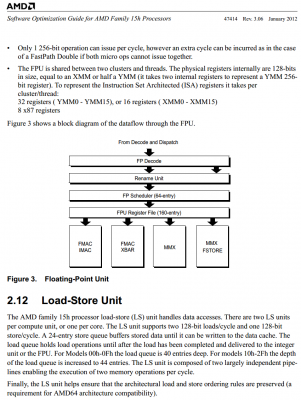
4 db 128 bites végrehajtó, közülük 2 dolgozik alapvetően egész számokon (MMX) és 2 lebegőpontos számokon (FMAC). Ezenkívül 3 bír speciális feladatkörrel, olyannal, amelyet semelyik másik nem tud ellátni, tehát szükségszerűen mindkét szálat ki kell szolgálják »egyszerre« (pl. csak az FSTORE tud memóriába írni, az XBAR adattípustól függetlenül vektorelemeket átrendezni, ...).
Továbbá egyrészt ott a "Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together." mondat, csakhogy szinte az összes AVX utasítás Fastpath Double, azaz 2 db - ebben az esetben 128 bites - micro op-ra fordul le.
Másrészt ha az egyik szál 128 bites (akár SSE-)műveletének szüksége van egy L2-ben (18-21 órajel), L3-ban vagy rendszermemóriában levő adatra, akkor a fél FlexFP ne működjön, hanem várja meg azt, vagy addig hajtsa végre teljes mellszélességgel a másik szál készen álló utasításait, amelyeknek nem kell várnia adatokra?A legegyszerűbb eset a leggyorsabb is egyben, ugyanaz az elv, mint a HT-nél, itt is órajelenként felváltva kapja meg az egységes FP-ütemező a 2 szál utasításait. Amely műveletek bemeneti értéke rendelkezésre áll, azokat végrehajtja (nem téve különbséget a thread-ek között); ha több ilyen van utasítás van, amely adott pillanatban készen áll a futtatásra, akkor a legrégebben bekerülteket indítja.
Átalában az AVX utasítások két 128 bites felének egyszerre érkezik meg a bemeneti adata (előző utasítástól vagy a memóriából, mivel magonként 2 AGU van a két 128 bites memóriaolvasásnak), de ha 2 AVX utasításnál (= 4 db 128 bites félnél) áll fenn ez egyszerre, mert mondjuk két különböző szálból valók (a 2 magban 4 AGU van), akkor egy-egy FMAC egymás után futtatja le az adott utasítás két felét, az egyenlőség elvét követve.
Ez minden ütemező működési elve, legyen szó akár egy egyszerű egyszálas OoO-ütemezőről is. Minden más elv csak lassítana rajta, vagy a statikus/dinamikus működési ("szétválik"/"összekapcsolódik") váltás feleslegesen növelné a tranzisztorigényt és eredménye se lenne; egyszerűen csak az FP-ütemező nem tesz különbséget a két szál között, csak egy adag 128 bites micro op-ot lát és kezeli őket. -

Kroni1
veterán
És mire használod amugy a gépet?! Mekkora FX-et tervezel venni?
Mert pont azt boncolgattuk itt, hogy a legtöbb (általában játékra koncentráló) felhasználó számára teljesen felesleges a PhenomII X4-t lecserélni egy újabb AMD procira... nekem is egy ilyen 955BE procim van, és hidd el jó kis proci ez! Hogy rudi-t idézzem: "a 955BE máig a legpotensebb AMD CPU, legutoljára azzal sikerült az aktuális csúcs Intel CPU közelében maradni. Lényegében ez nem is csoda, mert utána indultak el a fúziós irányba, ami nem a CPU-ról szól."
Szóval nem az FX-eket akarom lehúzni, de egy PII X4-ről (ami relatívan az órajel és magszám szerinti teljesítményben erősebb az FX-eknél), ha átlag felhasználásra, játékra kell akkor nem feltétlenül éri meg váltani szerintem.
-
Kroni1
veterán
A +50% teljesítmény pedig nem rossz szerintem sem az X4 980-hoz képest!
De a sok okos "szakértő" biztosan azt várta, hogy relatív is megegyező lesz a Vishera teljesítményszintje a Denebhez képest, mármint hogy 4 helyett a ~8mag ~100% teljesítmény növekedéssel fog járni.. Ez meg ugye a teljesen új felépítés és egyéb tényezők miatt is lehetetlen egyenlőre..
-

joysefke
veterán
Nem nem így értette, legalábbis nem ezt próbálta közvetíteni:
"Sajnos ha AMD vonalon maradsz akkor nem nagyon éri meg lecserélned a PHII X4-et. De ha váltasz kékekre ott már fogsz tapasztalni gyorsulást. Esetleg egy 3930K?"
általánosságban írogat és fröcsög. Általánosan meg 50% a teljesítményelőny a Visheránál a P2X4-hez képest. Pont.
Játékoknál mutass nekem valakinél beüzemelt, (nem hipotetikus konfigot 2x7950-el meg 2x Gf680-el), ahol megéri bármilyen AMD processzorra lecserélni egy X4-980-at, vagy mutass egy valós felhasználásra szánt konfigot, amelyben érdemes lecserélni egy i7-870-et egy másik intel processzorra. Játékok egy bizonyos teljesítményszint fölött, (amelybe a három évvel korábbi leggyorsabb négymagosok még beletartoznak) nem skálázódnak tovább a processzorerő növelésével.
J.
-
Kroni1
veterán
Szerintem arra értette, hogy a felépítésbeli különbségek miatt az új procik még mindig nem hozzák azt a relatív teljesítményt a magok számához mérten, illetve azonos órajeleket figyelembevéve mint a Deneb-ek. És vszleg a legtöbbek számára fontos szempontot, vagyis a játékok alatt mérhető teljesítményt vette figyelembe.
Egy 4 magos PhenomII X4-ről egy ~8magos (vagy 4 modulos) 8350-re áttérve nem lesz olyan jelentős előrelépés (főleg a jelenlegi, nem erre optimalizált játékok alatt), mint amire sokan számítottak. Elgondolkodtam én is, hogy lecserélem az X4 955BE-t, de még látom szükségesnek. Ettől függetlenül akinek AM3+ alaplapja van annak el kell dönteni, hogy mire használná és megéri-e, aztán szíve joga áttérni, árban szerintem nagyon jók az új procik!
-
Ami itt igazan faj, az a prefetch es leginkabb a dekoder. A steam rollerben nem veletlenul fogjak duplazni. Az jo kerdes, hogy mit hivunk egy magnak, de anno a tobb integer feldolgozo beepitesenel sem kezdtek elnevezni a processorokat, hanem elneveztek szuperskalarnak. Az elvet az AMD kiterjesztette, ezert hajlok leginkabb arra, hogy inkabb modulokrol beszeljek, mint magokrol, tehat az FX-6 az 3 modulos. 1 modul egy "szuper-szuper skalar" cimet is kaphatna, vagy CMT modulnak is lehetne hivni. A CMT-vel bevezetett modulon beluli magok kozotti fugges miatt viszont nem hivnam magnak azt, amit az AMD magnak hiv.
Mar irtam, hogy nem a FlexFP a gond szerintem, hanem a dekoder reszleg, ami nem tudja megfelelo sebesseggel kihordani az ujabb tal rizst a konyhabol a ket gyerekenek, hogy a te hasonlatod vigyem tovabb.
"Ha az integer feladatokat nézed, akkor a Bulldozer modul kapott egy extra integer clustert, vagyis logikus, hogy két integer clusterrel jöhet 80% plusz." Erre reagaltam, hogy ez elmeleti 80%. A szamitasaiknak a fele erheto el a gyakorlatban atlagolva. Valamiert az az erzesem van folyamatosan, hogy az AMD a jovonek probal tervezni, de valamiert a jelenben nem tudja ugy eladni a termekeit, ahogy kellene.
-
Abu85
HÁZIGAZDA
Mi van azzal, hogy az utolsú gyorsítótár bizonyos processzorokban közös? Mert nem egy ilyen van. Akkor az hány mag? Mert az is megosztott erőforrás.
Ezt mond a mérnököknek, akik úgy tervezték a FlexFP-t, hogy szétváljon, ha nem AVX kódot kap. A modul a programok 99,99%-ában két magként funkcionál, ennyi. Ettől lehet 2 magnak vagy egy modulnak hívni, de más megfogalmazás nem helyes.
Melyik része nem érthető, hogy az AMD számolta a 80%-ot? Logikusan le van vezetve, csak ahogy mondtam hülyeség. Ezért nem értem, hogy miért hoztad ezt fel, de mindegy.
-
Nem, az athlon 1 mag + HT. A bull pedig 1 modul, amiben ket nem teljes mag van osszenovesztve. Egy maghoz tartozik prefetch, dekodr, regizterek, FPU es minden mas. Ennek egy resze a bullnal kozos.
A bull sem tud szetvalni, mert a modulban levo masik mag terhelese csokkenti a masik magon futo program sebesseget a kozos reszek miatt. Az elmeleti skalazodas ertelmetlen, mert a gyakorlatban nem tudja felmutatni, max egy ket program eseteben.
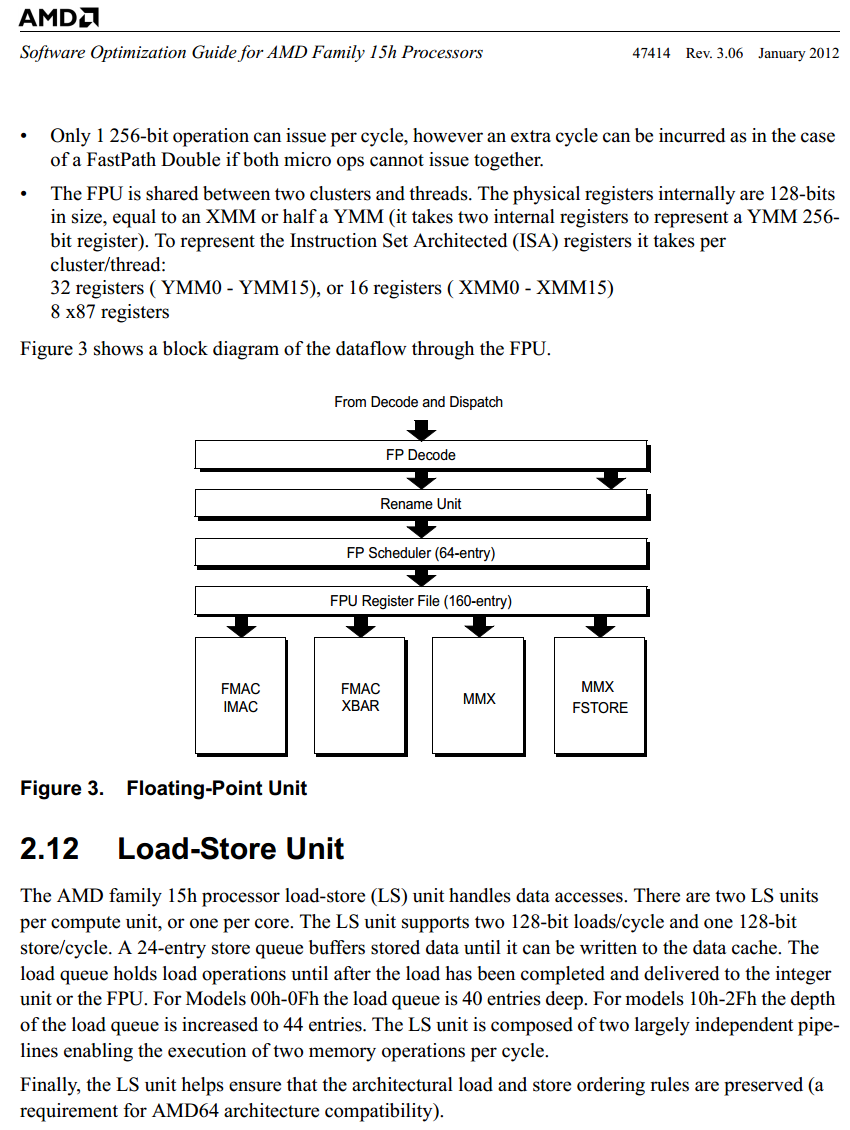
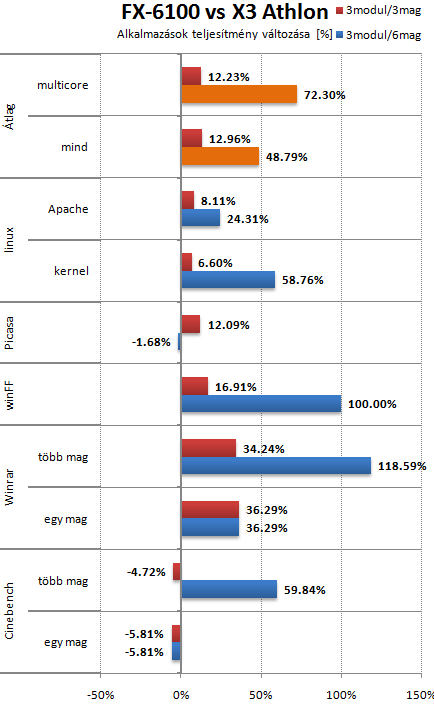
Athlon X3 440-hez hasonlit az alabbi grafikon, ami nem eppen acelos az X3-mak kozott. Egy korrekt X3 Phenommal 10-15%-al csokkentene az FX elonyet. A LinX es Vantage eredmenyeket kivettem, az applikaciok erdekesebbek. A multicore eredmenyeket nezve csak 72% az FX elonye, amibol 12-ot az uj cache, utasitaskeszlet stb. hozott. Ha ezt levonod, akkor mar csak 60% a modulos felepitesbol szarmazo elony, bar ez igy szammagia. Ertelmesebb nem csak a multithread atlagot nezni. Igy az elonye cca. 49%. Szoval nem latom az elmeleti 80% elonyt, csak a winFF (uj utasitaskeszletet ki tudja hasznalni, szinte megtaltosodik tole) es a WinZip hozza majdnem ezt.
Meg lehet probalni merni. Ha ez vakteszteket jelent, akkor ugy. Audiofil cuccok jelentos reszenel sem merhetoek, csak hallhatoak a valtoztatasok. Nem rossz az irany, de akkor lesz igaz az, hogy megvan a sw korites, ha a programok jelentos resze kihasznalja majd a GPU-t peldaul megjelenitesre, filterekre, arcfelismeresre, hang/vido ki-be kodolasra. A win 8 hatalmas lepes ebben az iranyba.
-
Abu85
HÁZIGAZDA
Mi az ami megérdemli a mag nevet? Mi ennek a definíciója? Mert amit te írsz az szimplán a teljesítményt veszi figyelembe, de ebből a szempontból, akkor az Atom is 0,2 magos. Ez így nyilván hülyeség.
A sziámi ikrek nem tudnak szétválni a programok 99,99%-ában. Csinálhatsz programot, de az a 80% az elméletben számolt. Megvan a termék elméleti számítási teljesítménye, amiből ezeket kiszámolják. Ezért mondom, hogy hülyeség.
Rég megvan a szoftveres körítés. A gond, hogy ez nem mutatható ki számokban. Ezért csinálta az AMD a vakteszteket, hogy az emberek mást látnak-e, mert már ők sem bíztak magukban. Aztán a vaktesztekből kiderült, hogy az emberek az AMD-s gépet tartották jobbnak, vagyis azt látták, amit az AMD-nél a tervezők. Ezután jött az, hogy ha ezt számokba nem lehet önteni, akkor adjuk oda az APU-kat ingyen az embereknek, cserébe a Facebookon reklámozzák azokat. Minden user experience dologgal ez a gond. Nem lehet számokba önteni.
-
Amit magnak nevez az AMD, az valojaban nem erdemli meg a mag nevet.
Nem csak az ujtasitas keszlet fejlodott. Egy modul nem teljes erteku ket mag, legalabbis nem a klasszikus ertelemben. Leginkabb sziamiikerhez hasonloak, akiknek a szerveik nagy resze kozos, bar az agyuk nem. A 80%-os teljesitmeny ugrashoz mindjart megcsinalom a grafikont, de addig Oliverda cikkere hivatkoznek. O is 50%-ot tudott kimutatni X4-hez, de azt is csak a 8350-el az elozo generaciohoz kepest. Sajnos nalla nincs 1 core-modul eredmeny, pedig korrektebb lenne, mint az Athlon X3 elleni merkozes. Szoval a hivatkozott 80%-ot nem latom igazoltnak.
A Consumer piacra gyuras nem rossz strategia, csak kell melle a megfelelo szoftveres korites. Az is jon, csak lassan. Hasonloan az Apple sem a legcsucsabb hardverre, hanem a user experienc-re gyur, csak ott a sajat fejlesztesu OS megadja a pluszt.
En forditva kozelitenem meg, de teljesen egyetertek. Az AMD mas teruleten nyujt nagyot, mint az Intel. Amire hasznalod, ahhoz valassz processzort, APU-t, tabletet vagy SFF PC-t...
-
#44
 huntermati
aktív tag
huntermati
aktív tag
huntermati
aktív tag
Jó kis teszt

-
joysefke
veterán
Terelsz.
ezt írtad:
Sajnos ha AMD vonalon maradsz akkor nem nagyon éri meg lecserélned a PHII X4-et.Erre írtam, hogy a 8350 50%-al gyorsabb, mint a PIIX4 980, amely a leggyorsabb Phenom 2.
Ha valaki AMD vonalon akar maradni, és kell neki a plusz teljesítmény, akkor a grafikonok szerint megérheti váltania.te pedig fröcsögsz össze vissza, olyan hozzászólásokat írogatsz, amelyek azt sugallják, hogy a Vishera alig gyorsabb, mint a phenom2, pedig a tesztek tanulsága szerint a leggyorsabb vishera a debütáló bandából keresztben nyeli le a leggyorsabb, legutolsóként piacra dobott X4-et. 50% különbségről beszélünk, te meg úgy csinálsz, mintha nem lenne előnye.
Milyen alaplapról beszélsz te egyáltalán? AM3/AM3+-ba megy bele. akinek phenom kettese van, annak jó eséllyel megfelelő a lapja a Visherához és a Dózerhoz is, legalábbis jobban, mint egy ivy I5-höz.
J.
-

KAMELOT
titán
-
KAMELOT
titán
Igen a legtöbb szoftver még mindig 1-2 magot használ. Főleg a programokat kéne optimalizálni, hogy a procikban rejlő erő ki legyen használva. Ugye ez a része eléggé elmaradott. Hiába van brutál procid ha a program a régi dolgokat tudja cska használni.
E5200-al a winrar ugyan olyan gyorsan csomagol szét mint i5-3450-el.
Max játékokban érezhető, hogy az erős proci tudja hajtani a jó VGA-t. Meg tervező progiknál adobe corel autocad stb. ott érezhető a több magos proci ereje. Ugye ezeket a progikat 20-ből 1 ember használja többi meg net office mail game. -
Abu85
HÁZIGAZDA
A nyilvánvaló dolgokkal nem vitázom, csak a mag-modul fogalmát akarom tisztázni, mert ezt sokan át fogják venni, és a 1,5 mag mint magyarázás a lehető legrosszabb alternatíva.
Az új utasításokat a programok 0,000001%-a használja. Az 1 mag vs 1 modul témában a sebességelőnyt az adja, hogy a modul tulajdonképpen két mag. Innen írja rá az AMD a 80% pluszt, csak ez mint mondtam kisarkított példa, mert a mag-modul összehasonlítást lehet úgy csinálni, hogy az utóbbi legyen nagy előnyben, vagy úgy, hogy az utóbbinak legyen egy kis hátránya. Az AMD nyilvánvaló okokból a modult helyezte előnybe.
Az AMD egy ideje már a user experience részre gyúr. Ezért adnak a GPU-ra. Ma el kell dönteni, hogy felhasználói élményt akarsz, vagy sebességet. Éppen ezért a Trinity és az Ivy Bridge olyan helyzetben van, hogy a piacon kiegészítik egymást. A Trinity inkább az élmény szempontjából közelít, míg az Ivy Bridge a számokat tartja fontosnak. Előbbi nyilván ott ütközik problémákba, hogy a felhasználói élmény számokban nem kimutatható. De nyilván a koncepció megvan benne, hiszen a Windows 8 az IGP jobb kihasználása felé megy. Ott az új Unified Video API, ami a videógyorsítást belerakta a DX11 futószalagba. Ezzel teremtett egy egységes alapot a rendszereknek, és megoldotta a buffer megosztást is, ami a DXVA2 gondja volt, de teremtett egy teljesítménykényszert is, mert mostantól az alkalmazások rugalmasabban írhatnak post-process effekteket, és így a filmlejátszás sebességét erősen befolyásolhatja az IGP sebessége. Ergo az erősebb IGP a felhasználói élményt a tartalomfogyasztás szempontjából növelni fogja. Ez egy koncepcionális eltérés az AMD és az Intel stratégiája között. Pontosan ezért egészíti ki a Trinity az Ivy Bridge-et. Más koncepció szerint született.
Gyakorlatilag egyre inkább afelé megyünk, hogy nincs fekete és fehér termék. Minden eszköz szürke, és az dönti el, hogy mi a jó neked, hogy mire fogod használni.
-
Elso oldalon leirtam, hogy mire keresem a valaszt:
"- Erősen GPU limites környezetben számít-e a processzor?"
Ha a cel a processzorok koztti kulonbseg kimutatasa lett volna, akkor 720p-ben tesztelek. Abban az esetben viszont masok reklamaltak volna. Pont ezert exact celok kerultek kituzesre, amiket az elso oldalon olvashatsz.
KAMELOT: A hasonlo sommas megallapitasok soha nem igazak. Tobb peldat is tudok idezni a tesztbol, ahol erdemes valtani. Az ajanlott Intel nem eppen egy arban van a teszt alanyaval.
-

Yodamest
veterán
Nagyon jó hiánypótló teszt! Egyedül annyi, hogy jobb lett volna kevésbé VGA limites beállításokat használni, mert így minden CPU ugyanúgy teljesít pl.: a Crysis 2 mindenhol 40fps kiváncsi lettem volna, hogy mondjuk medium beállításon vagy alacsonyabb felbontáson, ahol kijönne egy fix 60-70 fps azt melyik proci tudná hozni.
-
Jó cikk szerintem is! Úgy látom azért egy Phenom X4-et nem érdemes lecserélni erre, szóval megtartom még egy darabig
-
Pont ezert irtam, hogy az FP szerintem zsenialis. A frontend viszont jelen esetben szuk keresztmetszet. Erre jo pelda a kernel forditas, ahol nem fogsz FP utasitasokat talalni, max csak elvetve, tehat marad a fronted, a memoria es a diszk alrendszer, mint szuk keresztmetszet.
A memoriat es a merevlemezt kilonem, mert a modulok szamaval aranyosan skalazodik, de a mag/modullal nem. Lehet meg a cache is, ami eleg 3 maghoz, de hathoz mar nem, de 2 modullal is hasonlo eredmenyre jutottam, sot egyel sem sokkal jobb az arany.
Tehat 1 K10 mag vs. 1 Bull modulra gondolsz? Igen, ott van amiben hozza, de ez nem tisztan a modulos felepites erdeme, eleg sok uj utasitas es mas optimalizacio is benne van a kepben. Ma mar nem, de holnap osszevetem az X3-mat, az FX-6100 ket beallitasaval. Mondjuk nem lesz korrekt, mert Athlon 440, de a semminel jobb, hogy mennyit jelent az ujabb proci optimalizacioja, utasitaskeszlete es mennyit a modulos felepites.
Gondolom a A8-4555Mre gondolsz. GPU-ban igen jo, hazon belul nagy elorelepes. A gond az, hogy hazon kivuli CPU-bol inkabb egy i7-3667U-t szeretnek a gepemben latni. Egyelore nincs szuksegem GPU-ra, a regi GMA is megteszi RHEL ala.
-
Abu85
HÁZIGAZDA
A frontend feladata csak az etetés. Az etet akkor is, ha különálló, és akkor is, ha közös. A két külön dekóder nem éppen olyan sok tranyó. Sokkal fontosabb, hogy az FP legyen közös, mert az a legnagyobb tranyózabáló.
Ha pontosan úgy értelmezed, ahogy az AMD mondta, akkor hozza. De ez mondom logikus, mert az AMD egy K10 maghoz hasonlította a modult, vagyis egy extra integer volt az előny. Két gyerek hamarabb megeszik egy tál cseresznyét. De ez az összehasonlítás hülyeség, mert szándékosan hátrányba kerül a K10.
Trinity-ből 17 wattos verzióban is van. Ezt a Llanóval nem lehetett megtenni. Ezt a részét nem kell magyarázni, mert az energiahatékonyság kézzel fogható. Ráadásul ugyanaz a node.
-
Az emberek tobbsegenek tok mindegy, lehet benne 2 mag vagy 32, csak repesszen a legujabb agyonlolek 13. Ha a felepitest nezed, akkor sem igaz a ket mag, ugyanis fontos reszek kozosek, azok nem dedikaltk. A regiszterek es a vegrehajtok igen, de a frontend miatt nem mondanam nyugodt szivvel, hogy ket mag. A flexFP viszont zsenialis huzas szerintem. Erdekes, de a steam rollernel visszalepnek a teoriaban a kulon-kulon dekoderrel, tranzisztorokat pocsekolnak, hogy a jobban kihasznaljak a ket "majdnem" magot.
Teljesitmeny szempontjabol nem hozza a 80%-ot. Talan lehet talalni egy vagy ket programot, ahol igen, de atlagban talan a felet ha fel tudja mutatni. Ebben termeszetesen benne van a programok multithread tamogatasanak hianya is reszben, de az is, hogy szuk keresztmetszet van a modul felepiteseben.
Azt hiszem nem kell magyaraznod, hogy mi a modulok mogotti elmeleti megfontolas. Szimplan nem skalazhato a regi felepites es a sok szal fele indultak el. Az altalanos CPU-nal is , de a masszivan parhuzamosithato, GPU-ra tolhato szamitasoknal fokent. Az otlet tenyleg jo, csak a kivitelezessel, illetve a szoftver oldallal vannak gondok jelenleg:
- Magasabb a fogyasztas, alacsonyabb az orajel, nem igazan energia hatekony (APU-nal, ha kihasznaljuk a GpGPU-t, akkor ez mar nem igaz.)
- A modulokban a kozos reszeknel bottlenecket vezettek be (Reszben kivasaljak a steamrollerrel)
- A programok jelentos resze meg mindig keves, de gyors magot igenyel (A jatekfejlesztok tamogatasa egy fntos teruletet valtoztat meg ilyen teren.)
- A GpGPU meg mindig csak kamaszodik (De mar kamaszodik ) -
Abu85
HÁZIGAZDA
Igazából az egészet teljesen rossz oldalról közelíted meg. Csak a teljesítményt veszed figyelembe, és nem a logikai felépítést. Ha így nézed, akkor az Atom az 0,2 mag, de mégsem annyi. Ez a hülyeség ebben. A modul az két mag, mert mindkét szál dedikált erőforrásokat kap.
Mert nem érted, hogy az AMD mire mondta a 80%-os előnyt. Ha az integer feladatokat nézed, akkor a Bulldozer modul kapott egy extra integer clustert, vagyis logikus, hogy két integer clusterrel jöhet 80% plusz. A Bulldozer modul az egy extra integer maggal kiegészített K10 magként is felfogható, de ez már értelmezés kérdése. De ebből a szempontból eléggé logikus, hogy 80% pluszt hoz, mert az összehasonlítási alap nem rendelkezik azzal az extra dedikált erőforrással, amivel a Bulldozer igen. Inkább ezt hívnám marketingnek, mert ezt így eleve hülyeség összemérni. Nyilvánvaló, hogy két gyerek jóval hamarabb megeszik egy tál cseresznyét, mintha csak egy gyerek lenne befogva erre.
A kódok nem olyanok, hogy most akkor csak integer vagy csak FP. A mai programok nagy átlagát tekintve a feladatok jelentős része az integer magot terheli.
A Bulldozer fő szempontja a throughput teljesítmény kitolása volt, amihez elővették Pollack szabályát. Ha egy szálon várod a teljesítményt, akkor nem az volt a cél, hogy ott jó legyen. Ha a throughput tempót várod, akkor az növekedett. Fejjel megyünk minden évben egy kihasználtsági fal felé, amit el is érünk. Minden fejlesztésnek az a célja, hogy ezt a falat valahogy megkerülje. Nyilván az elmúlt öt év kísérleteiből kiderült, hogy áttörni nem lehet. A legéletképesebb koncepciója erre a heterogén feldolgozás, mert ez az amivel a teljesítményt limitáló fal alatt át tudsz surranni. Viszont Pollack szabálya egy értékelhető alternatíva, hogy a falat told magad előtt, amíg nem tudsz alatta átjutni.
A fal tologatásából viszont a mobil megoldás előnyt szerzett, hiszen látod, hogy a Trinity mennyire takarékos. Ez is a dizájnból ered, mert a gyártástechnológiából már ezt nem lehet megnyerni az alávaló fizikai törvények miatt. -
Az 1modul=1.5 mag kicsit poen volt, nem kell erte harapni. Ha megnezed a hozzaszolasaimat, akkor tobbszor leirtam, hogy inkabb hivom 3 modulosnak, mert a 6 magot tulzonak talalom. 3 magnal meg joval erosebb es nem is igaz, hogy 3 magos. Szerintem maradjunk a modulnal.
A bull mag nem teljes erteku, de marketingkent eladhato. A bull modul/mag felepites legjobb esetben sem eri el az AMD altal deklaralt 80%-os teljesitmeny novekedest. A legtobb, amit mertem -41.55% lassulas 1 mag/modulnal, ami atszamolva 1.71 gyorsulast jelent. Tisztan integer terhelesnek a kernel forditas tekintheto, ahol ennel kisebb a kulonbseg (1.49). Tehat ha elmeletben ket kulon magkent is mukdik, a gyakorlatban nem kepes hozni az elvart/beigert gyorsulast.
Szerintem nincs igazan nagy problema a magokkal es fikent nem a flexFP-vel, de a frontend nem tudja etetni oket. Erre utal az is, hogy a steam rollernel a decodereket duplazzak, novelik az L1 cache-t.
-
Abu85
HÁZIGAZDA
Sajnos a Hyper-Threading hibát nem javították teljesen. Van rá egy workaround a BF3-ban, de nem teljes javítás. Ahhoz át kellene írni elég sok részt a kódban. A Frostbite 2-t ott elszúrták, hogy minden szempontból a Bulldozerre optimalizálták. Leghamarabb ezt a gondot egy nagyobb főverzió frissítésnél tudják teljesen normálisan orvosolni. Addig a Hyper-Threadingre marad egy alap workaround, ami csökkenti az akadós jelenséget, de nem tünteti teljesen el. Arra jó a részleges javítás, hogy az i7-nél ne legyen úgymond reálisan érezhető, de i3-nál már kevés az erőforrás ahhoz, hogy reálisan meg lehessen ezt oldani..
A magok szempontjából szerintem érdemes lenne ezt a másfél magot elfelejteni. Vagy két mag, vagy egy modul. A 1,5 mag a legrosszabb definíció, mert szimplán lehetetlenné teszi az értelmezést. Amúgy a dolog tök egyszerű. A FlexFP feldolgozó csak az AVX kódok alatt nem kerül megosztásra, vagyis a modul a ma elérhető alkalmazások 99,99%-ánál két magként működik. Abban a 0,001%-nál sem másfél mag, mert nem mindegyik szál használ lebegőpontos számítást, vagyis attól, hogy az egyik integer mag megkapja a teljes FlexFP-t még lehet, sőt, a szintetikus programokat leszámítva kifejezetten jó esély van rá, hogy nincs is szüksége rá a másik integer magnak, vagyis tulajdonképpen nem vesztett semmit a rendszer azzal, hogy a másik integer magnál nem pihen kihasználatlanul egy FP feldolgozó.
Amiért ezt az AMD így csinálta az az, hogy a FlexFP az SSE2+ kódoknál is maximális kihasználást élvez így, míg a korábbi, nem modulos megvalósítással a 256 bites FP feldolgozók elméleti teljesítményének fele kihasználatlan lenne. Ez ugye a tranyófelhasználás miatt fontos, mert az AMD a data-parallel számításokra úgyis IGP-t fog használni, ergo maradjon az IGP-nek több tranyó. -
-
Mert az Intel erosebb processzora is kevesebbet eszik. Irhattam volna azt is, hogy a versenytars i3-nal durvan 2x annyit eszik.
Taragas: Win 8 RT, de szerintem nehany honap es nem lesz kulonbseg a ket Windows kozott.
Gaboo007: Elso oldalon leirtam, hogy mire keresem a valaszt:
"- Erősen GPU limites környezetben számít-e a processzor?"
Az emberek tobsege hasonlo GPU vagy kozel GPU limites modban hasznalja a gepet, nem 1024x600-ra vesz 7850-et, GTX660-at.
Tobbieknek: koszonom, arra voltam csak kivancsi, ami altalaban kimarad. gondoltam megosztom veletek. Mindenki maganak dontse el, hogy jo-e neki az adott processzor.
-

Dominó85
addikt
Először is köszönet a cikkért. Nagyon jó lett. Ez csak még jobban meggyőzött, hogy ha tehetem i5-re váltsak a c2d-ről.
 Még mielőtt az AMD fanok nekem esnek, csak közlöm az FX proci is tetszik, de engem nem győzött meg, no meg volt már nekem Intel és AMD gépem is nem is egy... (Athlon 64, Athlon II X4 640, P4 HT, C2D-ből egy rakat) Egyik pártját sem fogom.
Még mielőtt az AMD fanok nekem esnek, csak közlöm az FX proci is tetszik, de engem nem győzött meg, no meg volt már nekem Intel és AMD gépem is nem is egy... (Athlon 64, Athlon II X4 640, P4 HT, C2D-ből egy rakat) Egyik pártját sem fogom. -

BoB
veterán
Egy észrevétel:
- "Az egy árban lévő i3-nál szerintem kiegyensúlyozottabb teljesítményt mutat fel"
- "Terhelve többet eszik, mint az Intel i5, aminél viszont gyengébb"Nem értem hogy utóbbit negatívumnak végülis miért lehet felhozni, ha - amint írtad - nem az i5 az ellenfele.?
Amúgy jó teszt., tetszik!
-

Don77
tag
Csatlakozok én is a klubhoz: nekem kb fél éve van meg a proci, asrock 970extreme 4, g.skill ramokkal, cooler master hyper tx3, asus 7770 társaságában. Össze vissza nyúztam már, nagyon meg vagyok vele elégedve, ha bárkinek kérdése van, csak bátran, ha tudok segít a tapasztaltakból.
-
Gamerous
tag
Nagyon tetszett a teszt! Gratulálok! Már több hete azon gondolkodom, hogy karácsonyra egy FX 6100-et vagy egy "kis" Ivy-t / 3220-3225 / vegyek-e. Tetszik a bulldog, de sokat eszik és a kis Ivy kisebb étvággyal is hozza azt a teljesítményt. Bár az utóbbival meg a 2 mag a bajom.

-
#3
 strike-force
őstag
strike-force
őstag
kb egy héten belül majd ugyanilyen konfig jön össze nálam is: fx-6100, 16g ram, hd5850, giga 970-es lap. ezek után aludni sem fogok tudni!!!!!!


















 Tanulságos volt, köszönjük a korrekt cikket!
Tanulságos volt, köszönjük a korrekt cikket!


 3,8 GHz-en megy, a biosban 1,30V-os feszültséget állítottam be, de a droppolás miatt ez kevesebb a valóságban, viszont így még stabil, mert 3,9 vagy 4 GHz-en már nem stabil, bár 1,30-on biztos az lenne, de prime alatt csak 1,20 körül van a feszültség... Lehetne a biosból feljebb venni, de azt meg hűtéssel nem bírom...
3,8 GHz-en megy, a biosban 1,30V-os feszültséget állítottam be, de a droppolás miatt ez kevesebb a valóságban, viszont így még stabil, mert 3,9 vagy 4 GHz-en már nem stabil, bár 1,30-on biztos az lenne, de prime alatt csak 1,20 körül van a feszültség... Lehetne a biosból feljebb venni, de azt meg hűtéssel nem bírom...

































Új hozzászólás Aktív témák

lo Közép teljesítményű FX 3 modullal, vagy akinek úgy tetszik 6 maggal. Mire elég?
- iPhone topik
- eBay
- Moderátort keresek a fórumhoz!
- Formula-1
- NVIDIA GeForce RTX 5070 / 5070 Ti (GB205 / 203)
- Spórolós topik
- Intel Core i3 / i5 / i7 8xxx "Coffee Lake" és i5 / i7 / i9 9xxx “Coffee Lake Refresh” (LGA1151)
- Hammer Blade Va - nem is úgy néz ki
- The Division 2 (PC, XO, PS4)
- Cyberpunk 2077
- További aktív témák...
- L15 Gen2 15.6" FHD IPS i3-1115G4 16GB DDR4 256GB NVMe SSD magyar billentyűzet gar
- Samsung Galaxy S23, 8/256 Gb, gyártói garancia 2026.10.01-ig, hibátlan újszerű állapot
- Apple Macbook Pro 13 2020 - M1 - 8GB/256GB SSD - Touch Bar - 102 Ciklus - 99% Akku - Ezüst - MAGYAR
- Macbook Air M1 (2020) 16GB RAM 512 SSD
- Apple iPhone 14 Pro 128GB 90% Akku. Újszerű,Kártyafüggetlen,Tartozékaival. 1év garanciával!
- Telefon felvásárlás!! Apple Watch Series 9/Apple Watch Ultra/Apple Watch Ultra 2
- Apple iPhone 14 128GB, Kártyafüggetlen, 1 Év Garanciával
- 98 - Lenovo Yoga Pro 9 (16IRP8) - Intel Core i7-13705H, RTX 4060
- Így lesz a Logitech MX Keys magyar billentyűzetes
- LG 27GR95UM - 27" MiniLED - UHD 4K - 160Hz 1ms - NVIDIA G-Sync - FreeSync Premium PRO - HDR 1000
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest