Hirdetés
- GoodSpeed: Te hány éves vagy?
- weiss: Autó költségek
- Luck Dragon: Alza kuponok – aktuális kedvezmények, tippek és tapasztalatok (külön igényre)
- Geri Bátyó: Agglegénykonyha különkiadás – Bors
- Luck Dragon: Asszociációs játék. :)
- sziku69: Szólánc.
- sziku69: Fűzzük össze a szavakat :)
- Klaus Duran: Minden drágul. Vajon a fizetések 2026-ban követi minimálisan?
- Cifu: Űrhajózás 2025 - Összefoglaló írás
- D1Rect: Nagy "hülyétkapokazapróktól" topik
Új hozzászólás Aktív témák
-

Hege1234
addikt
random adatokat adtam hozzá a json-hoz
(ez így még csak kiírja, a két kiválasztott csapat adatait)
a 2 kiválasztott csapatot akarod végül összehasonlítani?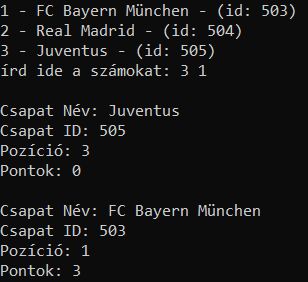
for idx, stuffs in enumerate(data_resp['data'], start=1):
print(f"{idx} - {stuffs['participant']['name']} - (id: {stuffs['participant']['id']})")
selected_indices = input("írd ide a számokat: ").split()
selected_indices = [int(i) for i in selected_indices]
print()
for idx in selected_indices:
if 1 <= idx <= len(data_resp['data']):
s_participant_datas = data_resp['data'][idx - 1]
s_participant_name = s_participant_datas['participant']['name']
s_participant_id = s_participant_datas['participant']['id']
s_position = s_participant_datas['position']
s_points = s_participant_datas['points']
print(f'Csapat Név: {s_participant_name}')
print(f'Csapat ID: {s_participant_id}')
print(f'Pozíció: {s_position}')
print(f'Pontok: {s_points}')
print()
else:
print(f"nincs ilyen...: {idx}") -
Hege1234
addikt
válasz
 sztanozs
#4263
üzenetére
sztanozs
#4263
üzenetére
nem én írtam egy sorba, és fura is volt így ömlesztve látni
viszont nem gondoltam, hogy problémát okozhatna mert
kb. minden powershell-es line-ba amit találtam a PATH-hoz az elválasztás az ez volt hozzá;$env:Path -split ';'( ha új sorba van írva akkor nem si kerül a végére a
;) -
Hege1234
addikt
-
Hege1234
addikt
válasz
sztanozs
#4253
üzenetére
Ha nincs python a path-on, akkor hogy futtatod ezt a python fajlt?
hát erre valóban nem gondoltam, így hogy nálam az már hozzá van adva a path-hoz

és akkor egy cmd-vel vagy inkább egy .bat fájlt használva megoldható lenne?
@echo off
set /p spec_python_ver=add python dir: (eg.: Python39) write here:
set "scripts_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\Scripts\"
set "python_dir=%LOCALAPPDATA%\Programs\Python\%spec_python_ver%\"
echo scripts_dir: %scripts_dir%
echo python_dir: %python_dir%így az útvonalat megkapom, de batch-el mivel tudom hozzáadni közvetlenül a PATH-hoz?
-
Hege1234
addikt
sziasztok!
szeretném megoldani, hogy ha nem lett bejelölve a python win installálásnál az add to path
akkor futtatva a script-et, hozzáadja a PATH-hoz, és akkor nem kell újrainstallálni vagy manuálisan szórakozni vele..mivel minden ilyen módosításhoz admin jog kell, lehetséges lenne ezt python alól megoldani?
ilyesmivel próbálkozok, de mivel nem ad ki írási hibát így gondolom még csak meg se próbálja hozzáadni
import os
spec_python_ver = input('add python dir: (eg.: Python39) write here: ')
scripts_dir = os.path.join(os.environ['LOCALAPPDATA'], f'Programs\\Python\\{spec_python_ver}\\Scripts\\')
python_dir = os.path.join(os.environ['LOCALAPPDATA'], f'Programs\\Python\\{spec_python_ver}\\')
dirs_to_add = [scripts_dir, python_dir]
for directory in dirs_to_add:
if directory not in os.environ['PATH']:
os.environ['PATH'] += os.pathsep + directory
print(f"'{directory}' added to PATH")
else:
print(f"'{directory}' already in PATH")
print("\nUpdated PATH:")
print(os.environ['PATH']) -
#4229
Hege1234
addikt
Atomantiii
#4228
Hege1234
addikt
válasz
 Atomantiii
#4228
üzenetére
Atomantiii
#4228
üzenetére
sztem az valahogy így nézne ki:
edited_tv_programs = re.sub(r'<desc.*hu.*(\(.*\.\) )', r'<desc lang="hu">', edited_tv_programs)ha csak tényleg a (0.) ami nem kell akkor így
edited_tv_programs = re.sub(r'<desc.*hu.*(\(0.\) )', r'<desc lang="hu">', edited_tv_programs) -
#4226
Hege1234
addikt
Atomantiii
#4225
Hege1234
addikt
válasz
Atomantiii
#4225
üzenetére
az elejére akkor ezt add még hozzá:
import reedited_tv_programs = ... alatt pedig ez legyen:
edited_tv_programs = re.sub(r'( clumpidx=.*\")', r'', edited_tv_programs) -
#4221
Hege1234
addikt
Atomantiii
#4220
Hege1234
addikt
válasz
Atomantiii
#4220
üzenetére
esetleg fontold meg a "credits" kiszedését is
akkor úgy kb. 40 MB lesz összesennot_needed = ["url", "previously-shown", "rating", "credits"] -
#4219
Hege1234
addikt
Atomantiii
#4218
Hege1234
addikt
válasz
Atomantiii
#4218
üzenetére
valami ilyesmi (biztos van jobb megoldás is rá)
(sokkal amúgy nem lett kisebb a fájl..)import requests
import xml.etree.ElementTree as ET
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}
xml_content = requests.get('ide írd a linket', headers=headers).content
root = ET.fromstring(xml_content)
not_needed = ["url", "previously-shown", "rating"]
for programme in root.findall(".//programme"):
for element_name in not_needed:
elements = programme.findall(f".//{element_name}")
for element in elements:
if element in programme:
programme.remove(element)
edited_tv_programs = ET.tostring(root, encoding='unicode')
with open('edited_tv_programs.xml', 'w', encoding='utf-8') as file:
file.write(edited_tv_programs) -
#4217
Hege1234
addikt
Atomantiii
#4215
Hege1234
addikt
válasz
Atomantiii
#4215
üzenetére
ezt nem probléma megcsinálni ezzel a modullal:
xml.etree.ElementTree
azthiszem alapból benne van a python 3-baa példád csak egy programra mutat
hogyan néz ki amikor van pl. 2 vagy 3 benne? -
Hege1234
addikt
köszönöm!

így szuperül működik
egyenlőre eddig ilyen, te is ilyesmire gondoltál?
import re
import glob
log_file_pattern = ".\\drmfiles\\programok\\firefox-log\\log.txt.moz_log.*"
log_files = glob.glob(log_file_pattern)
found_tokens = set()
patterns={
"app_key":[r"header=.app_key..value=.(.*)..merge=0]"],
"azukiapp":[r"E/nsHttp...AzukiApp:.(.*)"],
"azukiststoken":[r"E/nsHttp...AzukiSTSToken:.(.*)"],
"natcho":[r"E/nsHttp.uri=.*natco_key=(.*)&device_type=WEB&channel_number="],
"Device_Id":[r"header=.Device-Id..value=.(.*)..merge=0]"],
"bff_token":[r"header=.bff_token..value=.(.*)..merge=0]"],
"azudrm":[r'D/n.*?AzukiApp.*?[^.].*?[^.]\"AzukiDRM\" value=\"(.*?)\"',
r"E/nsHttp...AzukiApp:..*.*[^?].*[^?.].*[^?.]E/nsHttp...AzukiDRM:.(.*)"],
"sess_id":[r"https://.*wv_getlicense.*session_uid=(.*?)&"],
"acc_ount":[r"E/nsHttp.uri=.*user_token=(.*)&session"],
"get_lic":[r"E/nsHttp uri=(.*wv_getlicense.*token.*)"]
}
results = {}
while found_tokens != set(patterns.keys()):
for file_path in log_files:
try:
with open(file_path, 'r') as file:
tdata = file.read()
for key, patternlist in patterns.items():
if key not in found_tokens:
for pattern in patternlist:
try:
token = re.findall(pattern, tdata)[0].strip()
results[key] = token
found_tokens.add(key)
except IndexError:
pass
except Exception as e:
print(f"Error processing {key}: {e}")
except (IndexError, FileNotFoundError):
print(f"File not found: {file_path}")
except Exception as e:
print(f"Error processing file {file_path}: {e}")
app_key = results["app_key"]
azukiapp = results["azukiapp"]
azukiststoken = results["azukiststoken"]
natcho = results["natcho"]
Device_Id = results["Device_Id"]
bff_token = results["bff_token"]
azudrm = results["azudrm"]
sess_id = results["sess_id"]
acc_ount = results["acc_ount"]
get_lic = results["get_lic"] -
Hege1234
addikt
axioma, atty_hor köszönöm az ötleteket!
így most már szépen ki tud lépni, de lehet csak azért mert így még csak 1 fájlban keres
tesztelem olyan adattal ami csak a 2. vagy 3. fájlban lehetne, ott már lehet majd el fog vérezni megint..(csak, hogy itt az oldalon jobban átlátható legyen ezért most csak az app_key-t tettem bele a többit kiszedtem..)
import re
import time
import glob
log_file_pattern = ".\\drmfiles\\programok\\firefox-log\\log.txt.moz_log.*"
tokens_to_find = 10
found_tokens = set()
while len(found_tokens) < tokens_to_find:
log_files = glob.glob(log_file_pattern)
found_all_tokens = True
for file_path in log_files:
cutted_file_path = re.findall(r'\\([^\\]+)$', file_path)[0].strip()
if file_path in found_tokens:
continue
try:
with open(file_path, 'r') as file:
tdata = file.read()
app_key = re.findall(r"header=.app_key..value=.(.*)..merge=0]", tdata)[0].strip()
print(f"Token found in {cutted_file_path}: app_key: {app_key}\n")
found_tokens.add(file_path)
except (IndexError, FileNotFoundError):
print(f"Token not found in {file_path}. Waiting for the next attempt.")
found_all_tokens = False
except Exception as e:
print(f"Error processing {file_path}: {e}")
found_all_tokens = False
if found_all_tokens:
break
time.sleep(2) -
Hege1234
addikt
Sziasztok!
hogyan tudnék kilépni ebből a loopból?
a firefox log fájljában kerestetek 10 token-t
a fájlok nem egyből kerülnek bele a mappába, hanem folyamatosan
és minden 100MB adat után csinál egy új fájlt
log.txt.moz_log.0
log.txt.moz_log.1
log.txt.moz_log.2így elképzelhető, hogy valamelyik token majd csak a 2. vagy 3. fájlban lesz megtalálható..
script:
import re
import time
import glob
log_file_pattern = ".\\firefox-log\\log.txt.moz_log.*"
tokens_to_find = 10
tokens_found = 0
processed_files = set()
while tokens_found < tokens_to_find:
log_files = glob.glob(log_file_pattern)
for file_path in log_files:
cutted_file_path = re.findall(r'\\([^\\]+)$', file_path)[0].strip()
if file_path not in processed_files:
try:
with open(file_path, 'r') as file:
tdata = file.read()
app_key = re.findall(r"header=.app_key..value=.(.*)..merge=0]", tdata)[0].strip()
azukiapp = re.findall(r"E/nsHttp...AzukiApp:.(.*)", tdata)[0].strip()
azukiststoken = re.findall(r"E/nsHttp...AzukiSTSToken:.(.*)", tdata)[0].strip()
natcho = re.findall(r"E/nsHttp.uri=.*natco_key=(.*)&device_type=WEB&channel_number=", tdata)[0].strip()
Device_Id = re.findall(r"header=.Device-Id..value=.(.*)..merge=0]", tdata)[0].strip()
bff_token = re.findall(r"header=.bff_token..value=.(.*)..merge=0]", tdata)[0].strip()
sess_id = re.findall(r"https://.*wv_getlicense.*session_uid=(.*?)&", tdata)[0].strip()
acc_ount = re.findall(r"E/nsHttp.uri=.*user_token=(.*)&session", tdata)[0].strip()
try:
azudrm = re.findall(r'D/n.*?AzukiApp.*?[^.].*?[^.]\"AzukiDRM\" value=\"(.*?)\"', tdata)[0].strip()
except:
azudrm = re.findall(r"E/nsHttp...AzukiApp:..*.*[^?].*[^?.].*[^?.]E/nsHttp...AzukiDRM:.(.*)", tdata)[0].strip()
get_lic = re.findall(r"E/nsHttp uri=(.*wv_getlicense.*token.*)", tdata)[0].strip()
print(f"Token found in {cutted_file_path}: app_key: {app_key}\n")
print(f"Token found in {cutted_file_path}: azukiapp: {azukiapp}\n")
print(f"Token found in {cutted_file_path}: azukiststoken: {azukiststoken}\n")
print(f"Token found in {cutted_file_path}: natcho: {natcho}\n")
print(f"Token found in {cutted_file_path}: Device_Id: {Device_Id}\n")
print(f"Token found in {cutted_file_path}: bff_token: {bff_token}\n")
print(f"Token found in {cutted_file_path}: sess_id: {sess_id}\n")
print(f"Token found in {cutted_file_path}: acc_ount: {acc_ount}\n")
print(f"Token found in {cutted_file_path}: azudrm: {azudrm}\n")
print(f"Token found in {cutted_file_path}: get_lic: {get_lic}\n")
tokens_found += 1
processed_files.add(file_path)
except (IndexError, FileNotFoundError):
print(f"Token not found in {cutted_file_path}. Waiting for the next attempt.")
except Exception as e:
print(f"Error processing {cutted_file_path}: {e}")
time.sleep(2)
print(f"All tokens found! Press Enter to exit.")
stopsdf = input('\stop now!')még a loopban lévő print:
Token not found in log.txt.moz_log.0. Waiting for the next attempt.
Token not found in log.txt.moz_log.0. Waiting for the next attempt.
Token not found in log.txt.moz_log.0. Waiting for the next attempt.
Token found in log.txt.moz_log.0: app_key: ex****k
Token found in log.txt.moz_log.0: azukiapp: 3**
Token found in log.txt.moz_log.0: azukiststoken: AuthTok****
Token found in log.txt.moz_log.0: natcho: T****0P
Token found in log.txt.moz_log.0: Device_Id: 95d6****a4
Token found in log.txt.moz_log.0: bff_token: AuthTok****
Token found in log.txt.moz_log.0: sess_id: e4ab****f91
Token found in log.txt.moz_log.0: acc_ount: 100****001
Token found in log.txt.moz_log.0: azudrm: bd****C0=
Token found in log.txt.moz_log.0: get_lic: htt****lsemajd miután a log.txt.moz_log.0 betelt és létrejön a log.txt.moz_log.1 a mappában
elkezdi azt is csekkolni több száz sort nem teszek be róla, de az így néz ki:Token not found in log.txt.moz_log.1. Waiting for the next attempt.
.
.
Token not found in log.txt.moz_log.1. Waiting for the next attempt.
Token not found in log.txt.moz_log.1. Waiting for the next attempt.
.
.
Token not found in log.txt.moz_log.1. Waiting for the next attempt.
Token not found in log.txt.moz_log.2. Waiting for the next attempt.
Token not found in log.txt.moz_log.3. Waiting for the next attempt.
Token not found in log.txt.moz_log.1. Waiting for the next attempt.azt nem értem, hogy a loop-ból miért nem tud kilépni amikor a mostani helyzetben már az 1. fájlban megtalál minden token-t amit kerestetek és a print jelzi is..

lehet kellene valahova egy break és az, hogy megadom hogy 10 tokent találjon meg az nem elég a kilépéshez?
vagy más ok miatt mehet mégis a következő fájlra? -
Hege1234
addikt
igen, ha van egy jó alapja onnan már könnyen boldogul

(egyébként ezt rosszul értelmezte a gpt, mert amit komment-be tettem az csak nekem infó, hogy tudjam, hogy mit csinál a
tv_or_radio mert az csak ezt a kettő valamelyikét adhatja vissza
True False)amúgy kb. 4 órán keresztül szórakoztam a különböző gpt-kkel, de egyik se tudta azt megoldani, hogy a continue-val tudjon a következő iter-re ugrani, ha a fájl már létezik
olyat tudott összehozni, hogy a fájlokat megtalálta erre elkezdte letölteni újra
(a glob-ot egyébként egyik gpt se hozta fel csak az os.walk-ot bár szerintem azzal is megoldható lett volna, de addigra már meguntam..)jahh + el se akarta hinni, hogy én használhatom a continue-t azon a részen
-
Hege1234
addikt
válasz
sztanozs
#4101
üzenetére
a glob valóban megoldotta
köszi, szuperül működik!if elem['tv_or_radio'] == True:
#tv_or_radio = 'Rádió'
from glob import glob
s_pattern = fr"Downloads\\befejezett\\NAVA\\**\\*id#{elem['clean_id']}*mp3"
file_list = glob(s_pattern, recursive=True)
if file_list:
for file_path in file_list:
print(f'[INFO] ez a fájl már létezik itt: {file_path}')
continue
elif elem['tv_or_radio'] == False:
#tv_or_radio = 'Videó'
from glob import glob
s_pattern = fr"Downloads\\befejezett\\NAVA\\**\\*id#{elem['clean_id']}*mkv"
file_list = glob(s_pattern, recursive=True)
if file_list:
for file_path in file_list:
print(f'[INFO] ez a fájl már létezik itt: {file_path}')
continue -
Hege1234
addikt
sziasztok,
hogyan lehetne megoldani, hogy az itt lévő főmappában
Downloads\\befejezett\\NAVA
és a benne található almappákban is keressen a fájlok között
egy id-t?
ebben:find_this_id = f"id#{elem['clean_id']}"
pl.: id#3973922
ha megtalálta akkor csak menjen a következőre a continue-val, ha nem található akkor pedig csak foytatja a script-etez jelenleg csak azt tudja, hogy ha van találat akkor átugrik a következőre
ami jól is működik, de nem tud a főmappában és az almappákban keresni az id#...-vel szereplő fájl után:if elem['tv_or_radio'] == True:
#tv_or_radio = 'Rádió'
path_to_file = 'Downloads\\befejezett\\NAVA\\!kereső\\'+tv_or_radio+'\\'+replace_invalid_chars(ch_dir_name)+'\\'+replace_invalid_chars(title)+'.mp3'
path = Path(path_to_file)
if path.is_file():
print(f'{sarga} [INFO] ez a fájl már létezik itt: {path_to_file}')
continue
elif elem['tv_or_radio'] == False:
#tv_or_radio = 'Videó'
path_to_file = 'Downloads\\befejezett\\NAVA\\!kereső\\'+tv_or_radio+'\\'+replace_invalid_chars(ch_dir_name)+'\\'+replace_invalid_chars(title)+'.mkv'
path = Path(path_to_file)
if path.is_file():
print(f'{sarga} [INFO] ez a fájl már létezik itt: {path_to_file}')
continue
jelenleg, a példa id# itt is megtalálható:Downloads\befejezett\NAVA\Egy jenki Arthur király udvarában - A jenki, mint kóbor lovag (id#3973922).mkv
és itt is:Downloads\befejezett\NAVA\!kereső\Videók\M2\Egy jenki Arthur király udvarában - A jenki, mint kóbor lovag - id#3973922 - 2022#08#19 11#30#43.mkvez amiatt történt mert az előző verzióba más útvonalat használtam és így most újra végigmegy rajta amikor az már megvan...
-
Hege1234
addikt
köszi az ötleteket!
végül a unicodedata-t használtam hozzáimport os
import unicodedata
def has_accented_chars(s):
return any(unicodedata.combining(c) for c in unicodedata.normalize('NFD', s))
def has_accented_directory(thrd_dir):
for root, dirs, _ in os.walk(thrd_dir):
for dir_name in dirs:
if has_accented_chars(dir_name):
return True
return False
currentFile = __file__
realPath = os.path.realpath(currentFile)
dirPath = os.path.dirname(realPath)
dirName = os.path.basename(dirPath)
parentDir = os.path.dirname(dirPath)
sec_dir = os.path.dirname(parentDir)
thrd_dir = os.path.dirname(sec_dir)
paths_to_check = [dirPath, parentDir, sec_dir, thrd_dir]
for path in paths_to_check:
if has_accented_chars(path):
print(f"\n[HIBA] Az elérési útban ékezetes karakterek találhatók: \n'{path}'")
ex_it_0 = input(f'\nKilépéshez Enter...')
exit() -
Hege1234
addikt
sziasztok!
hogyan tudnám megakadályozni a script továbbfutását, ha az elérési útban
ékezetes karakter található?
windows rendszerről van szóa thrd_dir tartalmazza az ékezetes utat, de mégis simán továbbfut és nem áll meg
regex101 oldalán megnéztem és ennek[\x80-\xFF]fel kellene ismernie, hogy ékezetvalakinek esetleg valami ötlet vagy ehhez is külső modul kellene vagy csak én bénázok el valamit?
import os
import re
def has_accented_directory(thrd_dir):
for root, dirs, _ in os.walk(thrd_dir):
for dir_name in dirs:
if re.search(r'[\x80-\xFF]', dir_name):
return True
return False
currentFile = __file__
realPath = os.path.realpath(currentFile)
dirPath = os.path.dirname(realPath)
dirName = os.path.basename(dirPath)
parentDir = os.path.dirname(dirPath)
sec_dir = os.path.dirname(parentDir)
thrd_dir = os.path.dirname(sec_dir)
print(f'Elérési utak:')
print(f'dirPath: {dirPath}')
print(f'parentDir: {parentDir}')
print(f'sec_dir: {sec_dir}')
print(f'thrd_dir: {thrd_dir}')
paths_to_check = [dirPath, dirName, parentDir, sec_dir, thrd_dir]
for path in paths_to_check:
if has_accented_directory(path):
print(f"\n[HIBA] Az elérési útban ékezetes karakterek találhatók: \n'{path}'")
ex_it_0 = input(f'\nKilépéshez Enter...')
exit()Elérési utak:
dirPath: I:\_v2\új mappa\files\programok\hianyzo-modulok
parentDir: I:\_v2\új mappa\files\programok
sec_dir: I:\_v2\új mappa\files
thrd_dir: I:\_v2\új mappa -
Hege1234
addikt
sziasztok!
a cél az lenne, hogy ha már létezik ott egy ugyan olyan mappa az abban lévő fájlt csak simán írja felűl, de a shutil már az ugyan olyan mappára kiakad..
a fájlig el se tudtam még jutnihogyan lehetne megoldani?
def move_or_copy(src, dest):
if os.path.isdir(src):
if not os.path.exists(dest):
shutil.copytree(src, dest)
print(f"A mappa áthelyezve: {os.path.abspath(dest)}")
else:
for src_item in os.listdir(src):
src_file = os.path.join(src, src_item)
dest_file = os.path.join(dest, src_item)
move_or_copy(src_file, dest_file)
elif os.path.isfile(src):
if os.path.exists(dest):
print(f"A fájl '{os.path.abspath(dest)}' már létezik, felülírás...")
shutil.move(src, dest)
print(f"A fájl áthelyezve: {os.path.abspath(dest)}")
src_path = ripper_dir + '\\Downloads\\'
trg_path = dirPath + '.\\Downloads\\befejezett\\Prime\\!VT HD!\\Series'
for src_item in os.listdir(src_path):
src = os.path.join(src_path, src_item)
dest = os.path.join(trg_path, src_item)
move_or_copy(src, dest)error:
Traceback (most recent call last):
File "C:\Users\@\AppData\Local\Programs\Python\Python39\lib\tkinter\__init__.py", line 1885, in __call__
return self.func(*args)
File "I:\python v3\main.py", line 59820, in vt_amzn_Series_hd_01
shutil.move(src_file, dest)
File "C:\Users\@\AppData\Local\Programs\Python\Python39\lib\shutil.py", line 801, in move
raise Error("Destination path '%s' already exists" % real_dst)
shutil.Error: Destination path 'I:\python v3\Downloads\befejezett\Prime\!VT HD!\Series\Odaat.S07.1080p.AMZN.WEB-DL.DDP2.0.H.264-\Odaat.S07.1080p.AMZN.WEB-DL.DDP2.0.H.264-' already exists -
Hege1234
addikt
sztanozs
köszi így már értem, az egészet ott csesztem el, hogy a response1 = .... végére odaírtam már az elején a .text-etígy simán kiadja a linket
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get('https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8', headers=headers)
response_url = response.url
print(response_url)
#https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8sonar
köszi, így már értem a te hozzászólásodat isJoinR
szerk:
jogos, az egészet túlgondoltam
mivel statikus bárhol hivatkozhattam volna rá egy külön string-el.. -
Hege1234
addikt
válasz
sztanozs
#4038
üzenetére
amiket linkeltél ott egyik se tér ki arra, hogyan lehetne visszakapni
azt a linket amit a get-be megadtamHasznald a response1.text property-t, ha a visszaadott oldal rendesen formazott.
a text-et jól visszakaptam amiből meg is lett av9/prog_index.m3u8
azzal nincsen problémarequests.get-ből kellene ez a link:
https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8 -
Hege1234
addikt
válasz
sztanozs
#4036
üzenetére
igen sry, hogy nem fejtettem ki korábban
import requests
import re
headers1 = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}
response1 = requests.get('https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8', headers=headers1).text
grab_Connection = headers1['Connection']
grab_User_Agent = headers1['User-Agent']
print(grab_Connection)
#keep-alive
print(grab_User_Agent)
#Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36a headers1-et ki tudom olvasni, hogy mi van benne mint pl a user-agent-et
de a response1 már csak a text-et adja vissza és a https linket ami statikusan meg van adva azt már nemtext_from_response1 = re.findall(r'BANDWIDTH=.*RESOLUTION=1920x1080.*[^?](.*)', response1)[0].strip()
print(text_from_response1)
#v9/prog_index.m3u8a scriptet folytatva mivel így meglett a
v9/prog_index.m3u8most kelle elérnem valahogy ebből a https linket-et egy string-beresponse1 = requests.get('https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8', headers=headers1).textha az meglenne akkor megkapom ezt egy string-be pl. get_url
https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8és abból így már a re-vel megkapom a base_url -t
(.*)master.m3u8base_url+text_from_response1
#https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/v9/prog_index.m3u8ha nem adok meg text-et a végére akkor megkapom a status-t, de egy olyan megoldást se találtam ami vissza tudná adni a benne megadott linket
response1 = requests.get('https://devstreaming-cdn.apple.com/videos/streaming/examples/img_bipbop_adv_example_fmp4/master.m3u8', headers=headers1)
print(response1)
#<Response [200]> -
Hege1234
addikt
sziasztok!
response = requests.get('https://service.prd.tv/v2/hls/episode/........./master.m3u8', params=params, headers=headers).textvan arra esetleg mód, hogy miután megtörtént a get kiszedjem belőle egy string-be a benne lévő 'https://service.prd.tv/v2/hls/episode/........./master.m3u8' linket?
-
Hege1234
addikt
regex-el hogyan lehetséges a különböző linkek végéről leszedni ezt
/a-a9fvalt?a fő gond, hogy valamikor tartalmaz a link ilyen + toldást
/a-a9fvalt
valamikor meg csak a link van ami az id-ig tart emiatt nem jövök rá, hogyan lehetne megoldani, hogy minden linkről le legyen szedve az a rész (random persze, hogy mi van ott..)a 3 linkből ezek az id-k kellenének
"e20b1uf" "e1rlpt3" "e1tb9q9"
https://podcasters.spotify.com/pod/show/bozsik-gazda-podcast/episodes/Vilghr-magyar-nemests-nvnyek---70-Bozsik-gazda-podcast-e20b1uf/a-a9fvalt
https://podcasters.spotify.com/pod/show/daniel-csirke/episodes/11--insight---Anyaknt-sem-lltam-le-az-tletelssel--csak-j-utakat-kerestem-a-kreativitsomnak-e1rlpt3
https://podcasters.spotify.com/pod/show/mandiner/embed/episodes/Ki-brja-tovbb-tartalkokkal-a-hbort---Somkuti-Blint-e1tb9q9én csak eddig jutottam el, de ha éppen nem tartalmaz az elején e betűt akkor borul az egész
-(e.{6}) -
Hege1234
addikt
sziasztok!
argparse-nál hogyan lehetne megváltoztatni, hogy ne a
-dhívja le
a params-ban lévő "d"-t ?
hanem pl.script.py --params-dvagy valami hasonló, csak ne egy betűs legyen?#headers
parser.add_argument('--challengecustomdata', type=str, help='challengecustomdata header')
#params
parser.add_argument('-d', help='params d')
args = parser.parse_args()
headers = {}
if args.challengecustomdata:
headers['challengecustomdata'] = args.challengecustomdata
params = {}
if args.d is not None:
params['d'] = args.dpl. így szokott kinézni:
params = {
'd': 'kwscx.d2k',
} -
#3965
Hege1234
addikt
arcoskönyv
#3960
Hege1234
addikt
válasz
 arcoskönyv
#3960
üzenetére
arcoskönyv
#3960
üzenetére
az úgy egy jóval macerásabb művelet lenne...
eddig a herokuapp féle cors-os megoldással jutottam a legtovább
[kép]szépen betöltötte, de ezt is csak akkor, ha a gépemen van a pyscript.js és a pyscript.css
ha a linkről tölti be a python-t akkor az xml-t megpróbálja szerkeszteni és az úgy elég katasztrófa lesz..egy jó kis xmltodict, json modul, ha még elérhető lenne hozzá akkor
szépen lehetne formázgatni is egyből az xml-t<!DOCTYPE html>
<html>
<head>
<link rel="stylesheet" href="pyscript.css" />
<script defer src="pyscript.js"></script>
<style>
h1 {
font-size: 20px;
color: green;
text-transform: uppercase;
text-align: center;
margin: 0 0 35px 0;
text-shadow: 0px 1px 0px #f2f2f2;
}
</style>
</head>
<body style='font-size: 20px;'>
<h1>PyScript - teszt XMLHttpRequest</h1>
<label for="edited_string_date">from zulu date:</label>
<div id="edited_string_date"></div><br />
<div id="request_output"></div>
<py-script>
from datetime import datetime, timedelta
string_date = "2023-02-24T19:34:57Z"
date_obj = datetime.strptime(string_date, "%Y-%m-%dT%H:%M:%SZ")
new_date_obj = date_obj + timedelta(hours=1)
new_string_date = new_date_obj.strftime("%Y-%m-%d %H:%M")
pyscript.write('edited_string_date', new_string_date)
from js import XMLHttpRequest
req = XMLHttpRequest.new()
req.open("GET", "https://cors-anywhere.herokuapp.com/https://www.youtube.com/feeds/videos.xml?channel_id=UC2Th9fjegtGqBQ7UMXTDWuQ", False)
req.send()
output = str(req.response)
pyscript.write('request_output', output)
</py-script>
</body>
</html>youtube-os oldalhoz pont nem kell a headers meg hasonló, de pl. ha egy másik oldallal próbálkozom ahol kell a headers, cookies, params vagy a POST-hoz a data
azokat hova írom bele?ez elé
req = XMLHttpRequest.new()
mehet pl aheaders = {
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'hu,en;q=0.9',
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="102"',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36',
}a False elé pedig mehet, hogy headers=headers,?
-
Hege1234
addikt
pyscript-et próbálgatta már valaki?
dátum konvertálás meg egyéb alap python scriptekkel el lehet vele szórakozni,
hogy fut a python a böngészőben
(lokálisan használom a pyscript.css és pyscript.js is a gépen van..)
web scrape-re használnám, de se a requests se az urllib3
nem használható vele?
mit tudnék helyettük használni hozzá?a fetch-et emlegetik, de akkor meg megint ott vagyok mint javascript-nél, hogy
az állandó cors hiba szivat meg... -
Hege1234
addikt
hogyan lehet a regex-et úgy használni, hogy ezen a
.*mk.*-n
kívül minden linket megtaláljon a location-ben?(mindig egy link van benne csak a request-től függ
éppen milyen link szerepel benne..)ezzel szoktam megtalálni:
<location>(.*mk.*)</location>de arra nem jövök rá, hogyan tiltom
-
Hege1234
addikt
oké, én még mindig nem értem, hogy lesz valami csak egyszer printelve a fájlban
amikor van for isfgh = '#EXTM3U'
for item in response3['list']:
names = item['name']
id_s = item['id']
nums = item['number']
extinf = f'#EXTINF:0,{nums}) {names}'
print(fgh+'\n'+f'{extinf}', file=open("teszt.m3u8", "a+", encoding="utf-8")) -
Hege1234
addikt
csak amiatt fontos, hogy a .m3u8 fájl
végül így nézzen ki#EXTM3U
#EXTINF:0,1) M2
https://.....m3u8
#EXTINF:0,2) M5
https://.....m3u8
#EXTINF:0,3) RTL
https://.....m3u8
#EXTINF:0,4) RTL Kettő
https://.....m3u8
#EXTINF:0,5) RTL Három
https://.....m3u8
...stbpersze csak az én gondolatmenetemen indultam el, hogy ennek csak a legelején kell benne lennie az 1. sorban
#EXTM3U -
Hege1234
addikt
sziasztok!
hogyan lehet a for-ba megadni valamit amit csak egyszer printeljen?
ezt csak a legelején egyszer szeretném megjeleníteni:
print('#EXTM3U')for item in response3['list']:
names = item['name']
id_s = item['id']
nums = item['number']
print('#EXTM3U')
extinf = f'#EXTINF:0,{nums}) {names}'
print(f'{extinf}') -
Hege1234
addikt
ezzel így egy fájl lesz belőle:
pyinstaller --noconfirm --onefile --console --add-data "I:/portable teszt/ffmpeg;ffmpeg/" "I:/portable teszt/myscript.py"a dist-ből azt a kapott exe fájlt már bárhol indíthatod
legalábbis, ha a script-ed erre fel van készítve..
ffmpegből kiindulva gondolom nem mindent egy mappán belűl kezelsz valami kész/befejezett mappád csak van
vagy valami hasonló azt script-el hozasd létre, mert különben nem fog tudni abba a mappába dolgozni..de, amit ír sztanozs attól, hogy nem abba a könyvtárba dolgozik ahol az exe van
attól még ugyan úgy ki kell bontania és emiatt a c local temp könyvtárba hozza hozzá létre a
szükséges dolgokat (nem az output fájlra gondolok)nálam most pl innen dolgozott:
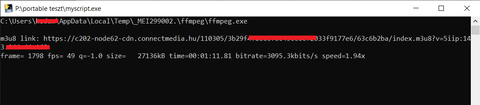
befejezve:

import os
import pathlib
import subprocess
from pathlib import Path
currentFile = __file__
realPath = os.path.realpath(currentFile)
dirPath = os.path.dirname(realPath)
dirName = os.path.basename(dirPath)
ffm = dirPath + '.\\ffmpeg\\ffmpeg.exe'
print(ffm)
m3u8 = input('\nm3u8 link: ')
subprocess.run([ffm, '-v', 'quiet', '-stats', '-y', '-i', m3u8, '-c', 'copy', 'output.mkv']) -
Hege1234
addikt
lehetne valahogy a shutil.move-t úgy használni, hogy a már mappában lévő fájlt/fájlokat auto
felülírja, ha pedig még nem létezik csak simán mozgassa át a fájlokat?vagy esetleg shutil helyett egy jobb megoldás rá?
src_path = '.\\encoding'
trg_path = '.\\encoding\\befejezett\\'+dir_title+''
for src_file in Path(src_path).glob('*.*'):
shutil.move(src_file, trg_path) -
#3886
Hege1234
addikt
Oryctolagus
#3885
Hege1234
addikt
válasz
Oryctolagus
#3885
üzenetére
gányolós megoldással valahogy így
from datetime import datetime
import re
date_form = '%Y-%m-%d %H:%M:%S'
str_dt1 = '2022-11-28 10:32:00'
str_dt2 = '2021-10-26 15:21:00'
dt1 = datetime.strptime(str_dt1, date_form)
dt2 = datetime.strptime(str_dt2, date_form)
minus = dt2 - dt1
minus_zeros = re.findall(r'(.*):', str(minus))[0].strip()
to_dot = re.sub(':', '.', minus_zeros)
minus_text = re.findall(r',.(.*)', str(to_dot))[0].strip()
print(minus_text)
#4.49szerk:
ok látom már miért nem lesz jó
hozzáírja a napot is mennyi telt el...
javítottam -
Hege1234
addikt
válasz
sztanozs
#3876
üzenetére
olyan esetben, ha nem lenne a
[*][*].clips[0].product.seasonszám beleír egy 1-es számot
így emiatt elvileg mindennek ugyanannyinak kellene lenniede így már nem tudja sorrendbe tenni
mert ami eddig 3 részből állt így már csak kettő lett['0002']['0002', '0009']
['0002']['0002', '0010']azt gondoltam, összetéve így fogja megjeleníteni,
['0002', '0002', '0009']
vagy így[('0002', '0002', '0009')]
de ahol ugyan azok a számok vannak azokat egybetette[('0002', '0009')] -
Hege1234
addikt
-
Hege1234
addikt
sztanozs
ezt használtam hozzá:[0-9]+
köszi, átírtam a \d+ -rasikerült megoldani, de nagyon sokat kellett hozzá trükközni, hogy minden sorozatot lefedjen, mivel a listában lévő szezont se mindig töltik ki..
rövidíteni még esetleg lehetne ezen a részen?
eléggé összetákolósra sikeredett..jsonpath_expression0 = parse('[*][*]')
merged_links = []
for match0 in jsonpath_expression0.find(my_responses):
value = match0.value
value1 = parse(f'[*][*].clips[*].program.code').find(value)[0].value
vid_program = f'{value1}'
value2 = parse(f'[*][*].clips[*].id').find(value)[0].value
vid_clip_id = f'{value2}'
value3 = parse(f'[*][*].clips[*].code').find(value)[0].value
vid_clip_code = f'{value3}'
valuexx = parse(f'[*][*].clips[*].code').find(value)[0].value
vid_clip_code_filter = f'{valuexx}'
x_ep_code = re.findall(r'\d+', vid_clip_code_filter)
ep_code_nums = [str(item).zfill(4) for item in x_ep_code]
valuexx_season = parse(f'[*][*].clips[*].product.season').find(value)[0].value
vid_clip_codes_sea = f'{valuexx_season}'
vid_clip_codes_sea = re.sub('None', '1', vid_clip_codes_sea)
kk_season = [str(item2).zfill(4) for item2 in vid_clip_codes_sea]
merged_links.append(f'{kk_season}{ep_code_nums} https://www.rtlmost.hu/{vid_program}-p_{sorozat_id}/{vid_clip_code}-c_{vid_clip_id}')
merged_links.sort()
##["['0002']['0002', '0009'] https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-9-resz-c_12947039","['0002']['0002', '0010'] https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-10-resz-c_12947042"]
##findall for just links
jsonpath_expressionxx = parse('[*]')
merged_jsons3 = []
for matchxx in jsonpath_expressionxx.find(merged_links):
filter_out = matchxx.value
##['0002']['0002', '0009'] https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-9-resz-c_12947039
##['0002']['0002', '0010'] https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-10-resz-c_12947042
just_links = re.findall('(https://.*)', filter_out)[0].strip()
print(just_links)
##https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-9-resz-c_12947039
##https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-10-resz-c_12947042
merged_jsons3.append(f'{just_links}')illetve amire rájöttem, hogy az egysoros for-okat nem tudom egybefűzni
azt hogyan is kellene? -
-
Hege1234
addikt
válasz
 kovisoft
#3867
üzenetére
kovisoft
#3867
üzenetére
köszi a részletezést!
vagyis akkor én fókuszáltam rossz felé mert tartalmaz ilyen részeket
csak arra koncentráltam, hogy a linkekhez kiszedjem az adatokat..
[kép]
vagyis akkor ezeket kellene feltöltenem nullkkal és a következő lépésben felhasználnom a sorbatételhez?[*][*].clips[0].product.season
[*][*].clips[0].product.episodea szezonban lévő számot kiegészítem az S betűvel
az epizódot pedig E-vel
így valami hasonlót kellene használnom hozzá amit disney-nél is használtam?regex2 = r'S([1-9]*[0-9])\s?E([1-9]*[0-9]):?'
def replacer2(y):
a, b = y.groups()
return 'S' + a.rjust(2, '0') + 'E' + b.rjust(2, '0')S02E05
-
Hege1234
addikt
válasz
kovisoft
#3865
üzenetére
köszi, a ValueError nagyon jól jött
így már a "randomok" benne
szépen a végére kerülneka sorba rendezett id-kat elkezdtem requests-el kibontogatni
amiből összeillesztem az évadban lévő linkeketegy részlet belőle, mert túl hosszú lenne a hsz. az összes részt betenni ide
['https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-169-resz-c_12873171','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-17-resz-c_12873019','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-170-resz-c_12873172','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-171-resz-c_12873173','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-178-resz-c_12873180','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-179-resz-c_12873181','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-18-resz-c_12873020','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-180-resz-c_12873182','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-181-resz-c_12873183','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-182-resz-c_12873184','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-183-resz-c_12873185','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-19-resz-c_12873021','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-1-resz-c_12947030','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-10-resz-c_12947042','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-100-resz-c_12947296','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-101-resz-c_12947344','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-109-resz-c_12947352','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-11-resz-c_12947046','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-110-resz-c_12947353','https://www.rtlmost.hu/elif-a-szeretet-utjan-p_8201/elif-2-evad-111-resz-c_12947354']mivel pár sorozatnál az évadon belül sem figyeltek a sorrendre
ezért listába tettem a linkeket és simán a.sort()-ot használtam hozzá
mivel a linkek miatt a sort_key-es replace nem tud működni, mit lehetne helyette használni,
hogy az egyjegyű, többjegyű számok ne borítsák meg a sorrendet? -
Hege1234
addikt
kovisoft
köszönöm szépen, szuperül működik!egy másik sorozaton átfuttatva is
[
'1. évad 1-15. rész - 26013',
'1. évad 16-30. rész - 26265',
'1. évad 31-45. rész - 26267',
'1. évad 46-60. rész - 26269',
'1. évad 61-75. rész - 26271',
'1. évad 76-83. rész - 26273',
'2. évad 1-15. rész - 28357',
'2. évad 16-30. rész - 28486',
'2. évad 31-45. rész - 28487',
'2. évad 46-60. rész - 28488',
'2. évad 61-68. rész - 28879',
'3. évad 1-15. rész - 29457',
'3. évad 16-30. rész - 29652',
'3. évad 31-45. rész - 29750',
'3. évad 46-60. rész - 29895',
'3. évad 61-75. rész - 30050',
'3. évad 76-81. rész - 30172',
'4. évad - 30793'
]amúgy persze, hogy elvétve egy-egy listában akár mondatokat, dátumokat is beleírkálnak abba a részbe

ilyen esetben merre kellene elindulnom?ez a mondat
"Nézd vissza a tévés adás után!"
a legutolsót jelenti
a keletkezett ValueError jelenthetné, hogy ezt tegye a végére vagy, hogy ne foglalkozzon vele?eredeti:
['7. évad - 31592', 'Nézd vissza a tévés adás után! - 26057', '6. évad - 28482', '5. évad - 24711', '4. évad - 19457', '3. évad - 13455', '2. évad - 8298', '1. évad - 8617']
def_sort_key:
# x kiprintelve
['7', 'évad', '31592']
['Nézd', 'vissza', 'a', 'tévés', 'adás', 'után!', '26057']
Exception in Tkinter callback
Traceback (most recent call last):
File "C:\Users\@\AppData\Local\Programs\Python\Python310\lib\tkinter\__init__.py", line 1921, in __call__
return self.func(*args)
File "I:\rtl_extract\rtl.py", line 2505, in rtlmost_check
merged_jsons_title.sort(key=sort_key)
File "I:\rtl_extract\rtl.py", line 2488, in sort_key
return [int(x[0]),int(x[2])]
ValueError: invalid literal for int() with base 10: 'Nézd'[
'7. évad - 31592',
'Nézd vissza a tévés adás után! - 26057',
'6. évad - 28482',
'5. évad - 24711',
'4. évad - 19457',
'3. évad - 13455',
'2. évad - 8298',
'1. évad - 8617'
]itt ennél agyfa@ kaptam

['201-300. rész - 30837','101-200. rész - 30650','1-100. rész - 30440','2021. július - 28075','2021. június - 27910','2020. november - 25179','2020. október - 24793','2020. szeptember - 24257',] -
Hege1234
addikt
olyankor amikor a .sort() nem elegendő
hogyan lehetne egy kicsit még tovább finomhangolni rajta?így kellene lennie:
(amit a .sort() majdnem meg is oldott)[
'1. évad 1-50. rész - 27895',
'1. évad 51-100. rész - 27896',
'1. évad 101-150. rész - 27897',
'1. évad 151-183. rész - 27898',
'2. évad 1-100. rész - 30456',
'2. évad 101-200. rész - 30457',
'2. évad 201-230. rész - 30458'
]print('\neredeti:')
jsonpath_expression0 = parse('program_subcats[*]')
merged_jsons_title_orig = []
for match in jsonpath_expression0.find(response):
value = match.value
value1 = parse(f'title').find(value)[0].value
ser_cat_title = f'{value1}'
value2 = parse(f'id').find(value)[0].value
ser_cat_id = f'{value2}'
merged_jsons_title_orig.append(f'{ser_cat_title} - {ser_cat_id}')
print(merged_jsons_title_orig)eredeti:
[
'2. évad 1-100. rész - 30456',
'2. évad 101-200. rész - 30457',
'2. évad 201-230. rész - 30458',
'1. évad 1-50. rész - 27895',
'1. évad 51-100. rész - 27896',
'1. évad 101-150. rész - 27897',
'1. évad 151-183. rész - 27898'
]print('\nsorted:')
jsonpath_expression0 = parse('program_subcats[*]')
merged_jsons_title = []
for match in jsonpath_expression0.find(response):
value = match.value
value1 = parse(f'title').find(value)[0].value
ser_cat_title = f'{value1}'
value2 = parse(f'id').find(value)[0].value
ser_cat_id = f'{value2}'
merged_jsons_title.append(f'{ser_cat_title} - {ser_cat_id}')
merged_jsons_title.sort()
print(merged_jsons_title)sorted:
[
'1. évad 1-50. rész - 27895',
'1. évad 101-150. rész - 27897',
'1. évad 151-183. rész - 27898',
'1. évad 51-100. rész - 27896',
'2. évad 1-100. rész - 30456',
'2. évad 101-200. rész - 30457',
'2. évad 201-230. rész - 30458'
] -
#3859
Hege1234
addikt
justmemory
#3858
Hege1234
addikt
válasz
 justmemory
#3858
üzenetére
justmemory
#3858
üzenetére
threading-et még nem használtam
az itt lévő utolsó minta alapján próbálkoztam, de így is csak akkor fut tovább, ha eltűnt a notif
(persze az is benne van, hogy nem is jól értettem meg a threading használatát )import threading
import os
def task1():
print("Task 1 assigned to thread: {}".format(threading.current_thread().name))
print("ID of process running task 1: {}".format(os.getpid()))
def task2():
import PySimpleGUI as sg
menu02a = 'HandBrakeCLI'
output = 'testfile.mkv'
tray = sg.SystemTray()
tray.notify(menu02a, output+'\n re-encode kész!', fade_in_duration=200, display_duration_in_ms=3000, alpha=2)
if __name__ == "__main__":
# creating threads
t1 = threading.Thread(target=task1, name='t1')
t2 = threading.Thread(target=task2, name='t2')
# starting threads
t1.start()
t2.start()
# wait until all threads finish
t1.join()
t2.join()
print('encode kész\n felugró notif közbe látszódik ez is')
next = input('\n és ez is') -
Hege1234
addikt
sziasztok!
a HandBrakeCLI-vel az mkv encode befejezést követően felugrik egy befejezve szöveg
kb 10 mp..
ez a része jól működik, ami a "probléma", hogy addig a 10 másodpercig
a py fájl nem fut tovább csak miután eltűnik a notifimport PySimpleGUI as sg
menu02a = 'HandBrakeCLI'
output = 'testfile.mkv'
tray = sg.SystemTray()
tray.notify(menu02a, output+'\n re-encode kész!', fade_in_duration=200, display_duration_in_ms=3000, alpha=2)ezt át lehetne esetleg úgy alakítani, hogy megmaradjon a 10 mp de eközben a python kód is tovább futhatna?
-
Hege1234
addikt
válasz
sztanozs
#3839
üzenetére
ahogy néztem a renditionName-ben mindenhol a Magyar jelenti a magyar feliratot
a forced-et pedig a hu--forced--
emiatt sikerült külön szedniThe Walking Dead - S11E12 |Magyar szinkron||HD| A szerencsések
The Walking Dead - S11E13 |Magyar szinkron||Magyar forced||HD| Hadurak
The Walking Dead - S11E14 |Magyar szinkron||Magyar felirat||Magyar forced||HD| Fejétől bűzlikregex2 = r'S([1-9]*[0-9])\s?E([1-9]*[0-9]):?'
def replacer2(y):
a, b = y.groups()
return 'S' + a.rjust(2, '0') + 'E' + b.rjust(2, '0')
jsonpath_expression0 = parse('[*].data.DmcEpisodes.videos[*]')
for match0 in jsonpath_expression0.find(my_responses):
value = match0.value
value1 = parse(f'text.title.full.series.default.content').find(value)[0].value
value2 = parse(f'seasonSequenceNumber').find(value)[0].value
value3 = parse(f'episodeSequenceNumber').find(value)[0].value
value4 = parse(f'text.title.full.program.default.content').find(value)[0].value
list5 = parse(f'mediaMetadata.captions[*].renditionName').find(value)
value5 = any(a.value.lower().split()[0] in "magyar" for a in list5)
list6 = parse(f'mediaMetadata.audioTracks[*].renditionName').find(value)
value6 = any(b.value.lower().split()[0] in "magyar" for b in list6)
list7 = parse(f'mediaMetadata.captions[*].renditionName').find(value)
value7 = any(c.value.lower().split()[0] in "hu--forced--" for c in list7)
value8 = parse(f'mediaMetadata.format').find(value)[0].value
out = f'{value1} - S{value2}E{value3} {kek+"|Magyar szinkron|"*value6}{zold+"|Magyar felirat|"*value5}{sarga+"|Magyar forced|"*value7+feher}{"|"+value8+"|"} {value4}'
final_out = re.sub(regex2, replacer2, out)
print(final_out)nagyon szépen köszönöm
sok újdonságot tanultamegy kérdésem lenne még f-string -el kapcsolatban
próbáltam megadni, ha nincsen pl. Magyar szinkron akkor is írjon oda valamit{"|van Magyar szinkron|"*value6 if *value6 not in *value6 "|nincs Magyar szinkron|"}vagy ezt az any hoz kellene beleírni?
-
Hege1234
addikt
válasz
sztanozs
#3837
üzenetére
így ezt adja vissza:
Traceback (most recent call last):
File "D:\json extract\test2.py", line 89, in <module>
value5 = any(a.value.lower().split()in("hunmagyar")for a in list5)
File "D:\json extract\test2.py", line 89, in <genexpr>
value5 = any(a.value.lower().split()in("hunmagyar")for a in list5)
TypeError: 'in <string>' requires string as left operand, not list -
Hege1234
addikt
válasz
sztanozs
#3832
üzenetére
keyerror hibát ír,
Traceback (most recent call last):
File "D:\json extract\test.py", line 141, in <module>
value1 = parse(f'{full_path}.text.title.full.series.default.content').find(value)[0].value
File "C:\Users\hadam\AppData\Local\Programs\Python\Python310\lib\site-packages\jsonpath_ng\jsonpath.py", line 265, in find
for subdata in self.left.find(datum)
File "C:\Users\hadam\AppData\Local\Programs\Python\Python310\lib\site-packages\jsonpath_ng\jsonpath.py", line 265, in find
for subdata in self.left.find(datum)
File "C:\Users\hadam\AppData\Local\Programs\Python\Python310\lib\site-packages\jsonpath_ng\jsonpath.py", line 265, in find
for subdata in self.left.find(datum)
[Previous line repeated 7 more times]
File "C:\Users\hadam\AppData\Local\Programs\Python\Python310\lib\site-packages\jsonpath_ng\jsonpath.py", line 613, in find
return self._find_base(datum, create=False)
File "C:\Users\hadam\AppData\Local\Programs\Python\Python310\lib\site-packages\jsonpath_ng\jsonpath.py", line 625, in _find_base
return [DatumInContext(datum.value[self.index], path=self, context=datum)]
KeyError: 0
de ez jót jelenthet mert az s01e01 -ben valóban nincsen magyar feliratszerk:
(kiprinteltem, hogy lássam mit szed össze)
[kép]
vagy rögtön elakadt az 1. résznél? -
Hege1234
addikt
válasz
sztanozs
#3825
üzenetére
hmm valamiért közbe-közbe kihagyva írja oda
pl.
The Walking Dead - S11E22 - Hitfor match1,match2,match3,match4,match5 in zip(jsonpath_expression1.find(my_responses),jsonpath_expression2.find(my_responses),jsonpath_expression3.find(my_responses),jsonpath_expression4.find(my_responses),jsonpath_expression5.find(my_responses)):
print(f'{match1.value} - S{match2.value}E{match3.value} - {match4.value}{zold+" |Magyar felirat|"*any(a.lower()in("magyar")for a in match5.value)}')
epizod = my_responses[10]['data']['DmcEpisodes']['videos'][21]['text']['title']['slug']['program']['default']['content']
felirat = my_responses[10]['data']['DmcEpisodes']['videos'][21]['mediaMetadata']['captions'][21]['renditionName']
print('\n'+epizod+' - '+felirat)
#hit - Magyarkülön kiprintelve mutatja, hogy a hit részhez is lenne magyar felirat
[kép]próbáltam úgy is, ahogy írtad
("hu","hun","magyar")
de így egy találat se voltami még fura, hogy akkor is van találat, ha valami random betűket írok bele
{zold+" |Magyar felirat|"*any(a.lower()in("dsfgdfgh")for a in match5.value)}
ilyenkor ezeket találja meg:
[kép] -
Hege1234
addikt
huhh ez a zip-es megoldás nagyon jó
köszönöm, tökéletesen működikamire még kíváncsi lennék, hogy mivel a 177 részből csak 155 -höz van magyar felirat
jsonpath_expression5 = parse('[*].data.DmcEpisodes.videos[*].mediaMetadata.captions[*].renditionName')
ebben általában van 20-30 adat
pl.
Japanese
de--forced--
Magyar
Chinese (Traditional)
Español (Latinoamericano)nekem innen csak akkor kell, ha valamelyik sorban szerepel benne a Magyar
erre esetleg rá tudok szűrni és egybegyúrni a zip-es megoldással?
így jól látható lenne melyik részhez van/nincs magyar feliratfor match1,match2,match3,match4,match5 in zip(jsonpath_expression1.find(my_responses),jsonpath_expression2.find(my_responses),jsonpath_expression3.find(my_responses),jsonpath_expression4.find(my_responses),jsonpath_expression5.find(my_responses)):
print(f'{match1.value} - S{match2.value}E{match3.value} - {match4.value} --- {match5.value}') -
Hege1234
addikt
egy listában lévő 11 link adata kerül egy nagyobb listába..
az alsó 4 for részt, hogyan lehetne átírni, hogy ne csak a legutolsó adatot tudjam kiprintelni hanem az egészet?
(összesen 177 epizód van benne)from jsonpath_ng.ext import parse
import requests
import json
my_responses = []
for lnk in merged_jsons:
payload = requests.get(lnk).json()
my_responses.append(payload)
print(my_responses, file=open("all.json", "w", encoding="utf-8"))
jsonpath_expression1 = parse('[*].data.DmcEpisodes.videos[*].text.title.full.series.default.content')
jsonpath_expression2 = parse('[*].data.DmcEpisodes.videos[*].seasonSequenceNumber')
jsonpath_expression3 = parse('[*].data.DmcEpisodes.videos[*].episodeSequenceNumber')
jsonpath_expression4 = parse('[*].data.DmcEpisodes.videos[*].text.title.full.program.default.content')
for match1 in jsonpath_expression1.find(my_responses):
ser_name = match1.value
for match2 in jsonpath_expression2.find(my_responses):
ser_num = match2.value
for match3 in jsonpath_expression3.find(my_responses):
ep_num = match3.value
for match4 in jsonpath_expression4.find(my_responses):
ep_title = match4.value
print(f'{ser_name} - S{ser_num}E{ep_num} - {ep_title}')
#The Walking Dead - S11E24 - Nyugodjék békében#3816 sztanozs
köszi át is írtam -
Hege1234
addikt
üdv,
egy log fájlba folyamatosan íródnak adatok
115 x 2 másodpercenként keresi a linket majd leáll
ez jól is működik, de csak akkor, ha a findall-ban nincsen | ORattempts = 115
while attempts > 0:
try:
tdata2 = open("log.0").read()
linkek = re.findall(r"E/nsHttp.uri=(https://.*v.mp4)|E/nsHttp.uri=(.*master.m3u8.*)|E/nsHttp.*uri=(https://vid.*md5.*expires.*)", tdata2)
linkek = linkek[0].strip()
print(linkek, file=open("videolink.txt", "w", encoding="utf-8"))
except IndexError:
attempts -= 1
time.sleep(2)
continue
except:
print('')
breakszeretnék egyszerre több regex-re is szűrni
de így már egy nagyon fura listát csinál a findall
amiből nem tudom kiszedni a linket[
('',
'https://.........',
''),
('',
'https://.........',
'')
]az, hogy hol lesz a link az a regex találattól függ
[('','link','')]az lenne a kérdésem, ha nem a findall akkor mit tudnék hozzá használni
vagy én bonyolítom túl és a listában lévő link/linkek simán kiszedhetőek? -
Hege1234
addikt
üdv,
hogyan oldható meg, hogy ha egymás alatt lévő sorok vannak
azokat oszlopokba tudjam rendezni?elég macerás, hogy állandóan görgetni kell...
194 sor van ezeket szeretném több oszlopba rendezni
import json
while True:
try:
fgq = open('mycanal.json', 'r', encoding='utf8')
except FileNotFoundError:
print('\n[ERROR] nincs json file\n')
import re
index = 1
title = json.load(fgq)
for thevalue in title.values():
gg = f"{index:03}"+' # '+' - '+thevalue["name"]
print(gg)
index += 1
all = index -1
print('\n összes csatorna: '+str(all)+'\n')
def process(text):
for match in re.finditer(r'(\d+-\d+)|\d+', text):
x = match.group()
if '-' in x:
a, b = x.split('-')
for i in range(int(a), int(b)+1):
yield i
else:
yield int(x)
text = input('\nírd ide a számot: ') -
Hege1234
addikt
válasz
sztanozs
#3779
üzenetére
ez, ami a linkben volt nagyon király
több mint 40 function-t használok
a különböző menükhöz..és csak bele kellett tennem a menükbe és már
működött is változtatás nélkül
köszi!import win32gui, win32com.clientshell = win32com.client.Dispatch("WScript.Shell")shell.SendKeys('%')win32gui.SetForegroundWindow(hwnd) -
Hege1234
addikt
üdv,
tkinter-el meglehet valahogy oldani, hogy ha egy gomb behoz egy új ablakot
akkor utána átváltson a cmd ablakba?vagy esetleg ctypes-el?
ctypes-el szoktam a cmd ablak-ot elneveznictypes.windll.kernel32.SetConsoleTitleW('____'+'_Decr'+' '+VERSION+'____'+dirPath+'____'+menu02a+'____'+output+'____')
de arra nem találtam semmi megoldást amivel előtérbe lehetne hozni az ablakot -
Hege1234
addikt
sziasztok!
azt gondoltam, hogy a lenti regex az egyben egy sorrendet is jelent
de úgy tűnik nem...
a .sort -ot lehet esetleg regex-el kombinálni?vagy esetleg egy jobb módszer rá, hogy kövesse a regex-ben lévő sorrendet?
a gond, hogy nem csak dash hanem hls link is található a hd-links.txt-ben amire nincs szükségem
hd = open("hd-links.txt").read()
un_sorted = re.findall(r".*1080p.*dash.*|.*dash.*1080p.*|.*720p.*dash.*|.*dash.*720p.*|.*hd_dash.*|.*sd_dash.*|.*dash.*540p.*|.*540p.*dash.*", hd)
un_sorted.sort(reverse=True)
hd_link = un_sorted[0]
print('1080p \ 720p \ 540p: \n'+hd_link)
print(hd_link, file=open("dash.txt", "w")) -
Hege1234
addikt
válasz
sztanozs
#3741
üzenetére
köszi a gyors választ
innen néztem ki:
[link]
ha nem windows-on próbáltad akkor lehet gond vele
Note: A file's ctime on Linux is slightly different than on Windows.
Windows users know theirs as "creation time".
Linux users know theirs as "change time".a fájl tulajdonságait megnézve valós a nov. 02 létrehozott dátum
-
Hege1234
addikt
sziasztok,
szeretném a 20221102 napon létrehozott acc-info.json fájlt
törölni a mappából akkor, ha eltelt 5 nap vagy több
így futtatva a .py fájlt 20221107.-én vagy 08.-án
akkor már a törléssel kezdenea dátumok megvannak hozzá, viszont az if-el elakadtam
már, ha egyáltalán kelleni fog hozzáimport os, time, datetime
from datetime import date
import glob
filename = ".\\Downloads\\info\\acc-info.json"
today = date.today()
current_local_date = today.strftime("%Y%m%d")
print('\n jelenlegi dátum: ',current_local_date)
created = os.path.getctime(filename)
year,month,day,hour,minute,second=time.localtime(created)[:-3]
created_date = "%02d%02d%02d"%(year,month,day)
print('\n fájl létrehozva: ',created_date)
add_day = '+5'
added_days = "%02d%02d%02d"%(year,month,day+int(add_day))
print(' hozzáadva '+add_day+' nap: ',added_days)ezzel szoktam a fájlokat törölni
ebbe, hozzá lehet adni a "dátumos törlést"
vagy van erre jobb megoldás is?delete_this = glob.glob(filename)
for f in delete_this:
os.remove(f) -
Hege1234
addikt
válasz
 cousin333
#3724
üzenetére
cousin333
#3724
üzenetére
bocsi azt nem fejtettem ki, hogy
request.get -hez használnám a params-ba, hogy az időt mozgatva + - ba
le tudjak kérni adatokat
így néha a now-ra van szükségem néha pedig egy külső fájlból adva van
egy pár nappal ezelőtti dátum ahonnan az időből el kell venni perceket...ezért keveredett bele a now és a startTime-is
köszönöm a példákat is, szuperül működik!
-
#3721
Hege1234
addikt
Capricornus
#3720
Hege1234
addikt
válasz
 Capricornus
#3720
üzenetére
Capricornus
#3720
üzenetére
köszi, ha semmi mással nem megoldható
akkor szuper megoldás ez is!elsősorban külső modulok nélküli megoldást keresnék
+ehhez még kell más egyéb modul is a működéséhez -
Hege1234
addikt
sziasztok!
ha ilyen formában van az idő
startTime=2022-10-26T11:50:00Z
endTime=2022-10-26T13:05:00Zmeglehetne valahogy oldani, hogy
perceket tudjak + - -ba "állítani" úgy, hogy a dátum is forduljon, ha úgy adódik?én valami ilyesmire gondoltam, de úgy tűnik belekavarodtam mert csak NameError-t tudok vele összehozni
from datetime import timedelta
startTime = '2022-10-26T20:00:00Z'
time_test_minus = datetime.datetime.utcnow().strftime(startTime, '%Y-%m-%dT%H:%M:%SZ')
time_test_minus + timedelta(minutes=-45)
print(time_test_minus) -
Hege1234
addikt
hogyan lehetne egy dict-ből
a megismétlődött "list1" vagy a "list3"-at a teljes hozzátartozó részével együtt kiszedni belőle olyankor, ha a linkek ugyan azok?
(a link az sose változik max törlik, de akkor
úgyse íródik már bele a fájlba)így mondjuk a list sorszámozásban lesz majd egy hiány, de szerintem azt majd egy újra indexeléssel meg lehet majd oldani
{
"list1": {
"cim2": "Egy év a jégtáblán - 2. rész",
"sorozat": "A fagy birodalma - Egy év a jégtáblán -",
"link": "https://www.rtlmost.hu/a-fagy-birodalma-egy-ev-a-jegtablan-p_22246/2-resz-c_12953864"
},
"list2": {
"cim2": "Superman és Lois 1. évad 2. rész",
"sorozat": "Superman és Lois -",
"link": "https://www.rtlmost.hu/superman-es-lois-p_22494/superman-es-lois-1-evad-2-resz-c_12961614"
},
"list3": {
"cim2": "2. rész",
"sorozat": "A fagy birodalma - Egy év a jégtáblán -",
"link": "https://www.rtlmost.hu/a-fagy-birodalma-egy-ev-a-jegtablan-p_22246/2-resz-c_12953864"
},
"list4": {
"cim2": "Craig Charles UFO-összeesküvések - 4. rész - Rendlesham",
"sorozat": "Craig Charles UFO-összeesküvések -",
"link": "https://www.rtlmost.hu/craig-charles-ufo-osszeeskuvesek-p_22315/4-resz-rendlesham-c_12955921"
}
} -
Hege1234
addikt
válasz
sztanozs
#3689
üzenetére
köszi ezzel így tökéletes
audio = dirPath + glob.glob('.\\files\\0vid*.m4a')[0]a pont és a dupla backslash valamiért mindenképp kellett hozzá
pedig így a dwnlo mappa kapott egy . -ot is, persze ez csak kiprintelve látszikI:\dwnlo.\files\0video.french.07.m4a
de ezzel így már megtalálta -
Hege1234
addikt
sziasztok!
át lehetne ezt valahogy alakítani, hogy elérjem a fájlokat?
ha fix a fájlnév akkor nincs probléma
csak persze az egyik külső program feature-ként kapott egy olyan funkciót, hogy toldja meg a fájlnevet egy + változó "tag"-el...
import os
currentFile = __file__
realPath = os.path.realpath(currentFile)
dirPath = os.path.dirname(realPath)
dirName = os.path.basename(dirPath)
video = dirPath + '/files/0vid*.mp4'
audio = dirPath + '/files/0vid*.m4a'
videoout = dirPath + '/files/1videoO*.mp4'
audioout = dirPath + '/files/1audioO*.m4a' -
Hege1234
addikt
válasz
 Hege1234
#3652
üzenetére
Hege1234
#3652
üzenetére
eddig ennyire jutottam
while True:
try:
zk, yc = list(map(int, input("ettől-eddig: ").split('-')))
x = range(zk, yc+1)
for number in x:
print(number)
except ValueError:
for number in input('\nírd ide a számot vagy számokat: ').split():
print(number)annyival még meg lehetne toldani, ha valaki az ettől-eddig: részbe csak egy számot vagy számokat ír be akkor azt ne kelljen újra beírni a ValueError: utáni részbe mégegyszer?
ettől-eddig: 3-7
3
4
5
6
7
ettől-eddig: 5 9 18
írd ide a számot vagy számokat: 5 9 18
5
9
18
ettől-eddig: -
Hege1234
addikt
sziasztok!
1 - video 1
2 - video 2
3 - video 3
4 - video 4
5 - video 5
6 - video 6
7 - video 7
8 - video 8
9 - video 9
10 - video 10
listában lévő mennyiség: 10
írd ide a számot vagy számokat:ebből a listából, hogyan tudnék így lekérni információt?
írd ide a számot vagy számokat: 5-9
vagy pl.
írd ide a számot vagy számokat: mindenmost még csak így működik, hogy
írd ide a számot vagy számokat: 1
vagy
írd ide a számot vagy számokat: 3 4 5 10while True:
try:
fgq = open('videok.json', 'r', encoding='utf8')
except FileNotFoundError:
print('\n[ERROR] ehhez előbb az info listába gombot kell használni!\n')
index = 1
title = json.load(fgq)
for thevalue in title.values():
print(f"{index:5}"+' - '+thevalue['cim'])
index += 1
all = index -1
print('\n listában lévő mennyiség: '+str(all)+'\n')
for number in input('\nírd ide a számot vagy számokat: ').split():
id_ = title['list'+str(number)]['j_id']
print('\n'+str(id_)) -
Hege1234
addikt
sziasztok!
kodi-ba küldeném el a webkiszolgálós felhasználónevem és a jelszavam
viszont ilyen hibát kapokcredentials = b''+kodi_user+':'+kodi_pass+''
TypeError: can't concat str to bytesamit ír error-t
hogyan lehetne a kodi_user-t és a kodi_pass-t átalakítani bytes-ra?
vagy esetleg valami más lesz a gond?credentials = b''+kodi_user+':'+kodi_pass+''
encoded_credentials = base64.b64encode(credentials)
authorization = b'Basic ' + encoded_credentialsezzel így sikerül lekérnem az adatokat a kodiból:
credentials = b'kodi:kodi'ezzel próbálkoztam még:
credentials = b'{kodi_user}:{kodi_pass}'
de ezzel is hibát dobott
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0) -
Hege1234
addikt
válasz
Hege1234
#3631
üzenetére
visszatérve arra, hogy lenyomom a számot és az beilleszti a böngésző nevét a listából
át lehetne alakítani olyanra, hogy magától végigmenjen minden elemen ami a listában szerepel?
options = ["chrome", "edge", "firefox", "brave"]
res = pick(options)
picked_browser = options[res]
func = getattr(browser_cookie3, picked_browser)
brows_er = func()
print(brows_er, file=open('all_'+picked_browser+'_cookie.txt', 'w'))így magától elkészítené mind a 4 txt fájlt amikben findall-al már tudok kerestetni
all_chrome_cookie.txt
all_edge_cookie.txt
all_firefox_cookie.txt
all_brave_cookie.txt -
Hege1234
addikt
sziasztok!
van esetleg ötletetek miért nem sikerül eljuttatnom a picked_browser -t a
browser_cookie3 részhez?pl. így néz ki amikor működik
get_c = browser_cookie3.chrome()import browser_cookie3
import requests
import re
def pick(options):
print("\nmelyik böngésző?")
for idx, element in enumerate(options):
print("{} = {}".format(idx + 1, element))
i = input("\nböngésző kiválasztása: ")
try:
if 0 < int(i) <= len(options):
return int(i) - 1
except:
pass
return None
options = ["chrome", "firefox", "opera", "edge", "chromium", "brave", "vivaldi"]
res = pick(options)
picked_browser = options[res]
print('\n kiválasztva: '+picked_browser+'\n')
get_c = browser_cookie3.picked_browser()output:
melyik böngésző?
1 = chrome
2 = firefox
3 = opera
4 = edge
5 = chromium
6 = brave
7 = vivaldi
böngésző kiválasztása: 4
kiválasztva: edge
Traceback (most recent call last):
File "I:\py cookie\get_cookie.py", line 26, in <module>
get_c = browser_cookie3.picked_browser()
AttributeError: module 'browser_cookie3' has no attribute 'picked_browser'





























Új hozzászólás Aktív témák
- Víz- gáz- és fűtésszerelés
- AMD Navi Radeon™ RX 7xxx sorozat
- CES 2026: felcsavarta az AI-t az AMD, de örülhetnek a játékosok is
- CES 2026: Látható gyűrődés nélküli hajlítható kijelzőt hozott a Samsung
- Projektor topic
- Házimozi haladó szinten
- Okos Otthon / Smart Home
- Autóápolás, karbantartás, fényezés
- EAFC 26
- Mini-ITX
- További aktív témák...
- HP EliteBook 840 G9 i7-1265U 16GB 512GB 14" FHD+ 1 év teljeskörű garancia
- Újszerű Acer Aspire A515 - 15.6"FHD IPS - i5-1335U - 16GB - 512GB SSD - Win11
- HP EliteOne 800 G5 All-in-One i5-8500 32GB 1000GB 23.8" Érintőkijelző!! 1 év garancia
- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max
- darkFlash CF8 Pro
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest