




Fogyasztása meg mint billencses ZIL-nek hegymenetben.
Tudom ahová készül ott lényegtelen de na’ ![;]](http://cdn.rios.hu/dl/s/v1.gif)
Ja és ez ki ne maradjon: “akkor kihajcsa’ a krájziszt?!” 
Még nincs kész, de már majdnem elkezdtük!

Fogyasztása meg mint billencses ZIL-nek hegymenetben.
Tudom ahová készül ott lényegtelen de na’
Ja és ez ki ne maradjon: “akkor kihajcsa’ a krájziszt?!”
Még nincs kész, de már majdnem elkezdtük!


Azért az mem és fabric bandwidth az nem teljesen reális/összehasonlítható
Itt gondolom csak fogták a külön chiprészlegekhez allokált ramokat és összeszorozták  De ettől még nem fér hozzá folyamatosan minden "ALU" elem minden RAM elemhez, hogy ez érvényes legyen. Ettől függetlenül nagyon érdekes a cucc, és biztos benga erős is (amire használják).
De ettől még nem fér hozzá folyamatosan minden "ALU" elem minden RAM elemhez, hogy ez érvényes legyen. Ettől függetlenül nagyon érdekes a cucc, és biztos benga erős is (amire használják).
10^12 azaz billió lesz az, magyarul. Angolul az a trillion. Félre lett fordítva.

És az összes helyen a korábbi cikkben is.
> Azért az mem és fabric bandwidth az nem teljesen reális/összehasonlítható
a céges PR-ok sose a realitásra törekednek, hanem az előnyők túlhangsúlyozására ..
de azért nem olyan rossz, persze FP16 -ban még fejlődnie kell.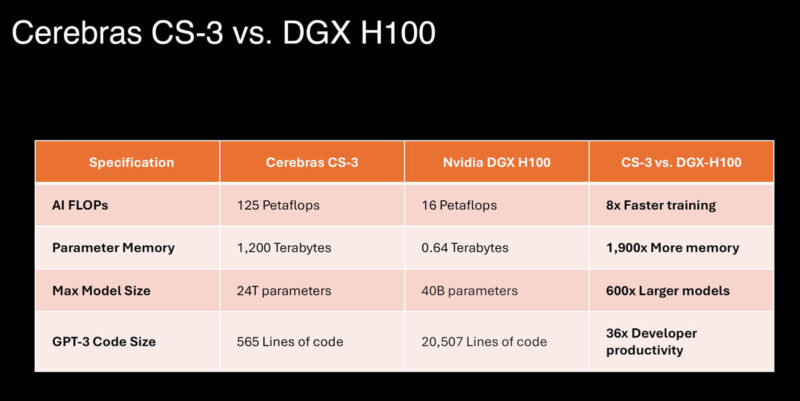

"One major advantage Cerebras has is memory bandwidth. Thanks to the 44GB of onboard SRAM — yes, you read that correctly — Cerebras' latest accelerator boasts 21PBps of memory bandwidth, compared to the 3.9TBps the H100's HBM3 maxes out at.
That's not to say Cerebras' systems are faster in every scenario. The company's performance claims rely heavily on sparsity.
While Nvidia is able to achieve a doubling in floating point operations using sparsity, Cerebras claims to have achieved a roughly 8x improvement.
That means Cerebras' new CS-3 systems should be a little slower in dense FP16 workloads than a pair of DGX H100 servers consuming roughly the same amount of energy and space at somewhere around 15 petaFLOPS vs 15.8 petaFLOPS (16x H100s 989 teraFLOPS.) We've asked Cerebras for clarification on the CS-3's dense floating performance; we'll let you know if we hear anything back.
https://www.theregister.com/2024/03/13/cerebras_claims_to_have_revived/
bővebb elemzés:
https://www.nextplatform.com/2024/03/14/cerebras-goes-hyperscale-with-third-gen-waferscale-supercomputers/
[ Szerkesztve ]
Mottó: "A verseny jó!"

Hátránnyal indul a cucc mert nem kártya, nem tudom ekkora hátrányt le lehet e dolgozni
főleg a 16nm-es variáns, húúú
ja meg túl egyszerű lenne az anti cheat a játékokban hogyha ilyen lenne a szerver
ez is hátrányos
(bizonyos szemszögből biztos így van )
> Hátránnyal indul a cucc mert nem kártya,
> nem tudom ekkora hátrányt le lehet e dolgozni
> ..
> ja meg túl egyszerű lenne az anti cheat a játékokban
ez másra való .. High-end szuperszámítógépekbe ..
és a H100 a versenytársa ..
Mottó: "A verseny jó!"
be kéne állítani szarkazmus detektort
az én nézőpontomból a kérdésed/megjegyzésed
elég alapvetőnek tűnt, ( láma .. )
és igyekeztem udvarias maradni a válaszadás során.
[ Szerkesztve ]
Mottó: "A verseny jó!"

Ezeket esélytelen kimatekozni (reális időbefeltetéssel)... Ha pl. a paramétereket sokkal ritkábban kell újra bemozgatni a compute "magok" SRAM-jába itt, mint H100-nél, az óriásit dobhat a teljesítményen. Szóval kéne látni konkrát benchmarkot, hogy neszetek, itt az akármelyik komkrét baromi nagy LLM model (Grok talán a legnagyobb, ami midenkinek elérhető), ez ennyi Wh-ból, meg ennyiért vett vassal, ennyi és kérést darált le, ennyi idő alatt.




