





Az utolso bekezdest nem ertem. Ha 300 watt fogyasztassal es tobb gigabytenyi HBM-mel csinal valaki apu-t, annal hogy lesz egy dedikalt gyorsito jobb? Mert jelenleg attol jobbak a dedikalt gyorsitok, hogy nagyobb savszelessegen erik el a sajat memjuket, es nagyobb tdp all rendelkezesukre. Ha ezek a korlatok nincsenek, akkor nem tudom mitol lenne jobb egy ugyanolyan tulajdonsagu hw pcie buszra kotve...
Gyorskeresés
Legfrissebb anyagok
- Bemutató Route 66 Chicagotól Los Angelesig 2. rész
- Helyszíni riport Alfa Giulia Q-val a Balaton Park Circiut-en
- Bemutató A használt VGA piac kincsei - Július I
- Bemutató Bakancslista: Route 66 Chicagotól Los Angelesig
- Tudástár AMD Radeon undervolt/overclock
Általános témák
LOGOUT.hu témák
- [Re:] [D1Rect:] Nagy "hülyétkapokazapróktól" topik
- [Re:] [Luck Dragon:] Asszociációs játék. :)
- [Re:] [Sub-ZeRo:] Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- [Re:] Android másképp: Lineage OS és társai
- [Re:] [gban:] Ingyen kellene, de tegnapra
- [Re:] [ldave:] New Game Blitz - 2024
- [Re:] [eldiablo:] Kioxia XG6, BiCS please
- [Re:] eBay-es kütyük kis pénzért
- [Re:] [ubyegon2:] Airfryer XL XXL forrólevegős sütő gyakorlati tanácsok, ötletek, receptek
- [Re:] PLEX: multimédia az egész lakásban
Szakmai témák
PROHARDVER! témák
Mobilarena témák
IT café témák
Hozzászólások


pl. úgy, hogy biztos léteznek olyan feladatok, ahol a APU-ban lévő CPU magok (és a bonyolultabb memóriavezérlő?) feleslegesek, és helyettük okosabb még több feldolgozó egységet a lapkára tenni.
Ezen kívül sima gyorsítóból lehet többet is használni, ha nem érzékeny pont az adatmásolás.
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

Arra az esetre gondolnak, amikor nem APU a CPU. 
Tehát lesz APU... meg ahol nem APU hanem CPU van oda lesz + GPU is, vagy csak GPU (ala Tesla grid pl).
[ Szerkesztve ]
Steam/Origin/Uplay/PSN/Xbox: FollowTheORI / BF Discord server: https://discord.gg/9ezkK3m

freeapro
senior tag
Azt hittem ezt már meglépték korábba is. Nvidiának úgy tudom van már ilyen CUDA-s HPC platformja.

ukornel
aktív tag
Csak tipp: ugyanazt a teljesítményt olcsóbban hozza a dedikált gyorsítóval, hiszen nem akkor ugyanazon a lapkán kell lenniük, brutál méretű csipet eredményezve.

Crytek
veterán
Remélem a sima pc piac is kap értelmes aput majd HBM-el.
Next PC Upgrade: 2022

Fiery
veterán
Oke, szoval az AMD belengette, hogy csinal konkurenciat a Knights Landing-nek. Eleg furcsa, hogy a hirben egy szo sem esik errol, marmint a tenyrol, hogy ez egyertelmuen a Knights Landing ellenfelenek keszul. Amondo vagyok, hajra AMD, kell a piacnak egy eros konkurencia, es ha a HBM-et bevetik near memory-kent, az egy igen-igen erdekes megoldas lenne.
Fiery
veterán
Az AMD ezt mar a Kaverival is meg akarta csinalni, bar me'g GDDR5 (BGA) alapokon, es az sem sikerult nekik. Az APU igeretes volt, de a PC-piac ellenallt, nem volt gyakorlatilag olyan alaplap gyarto, aki bevallalta volna. A HPC piac van annyira specifikus, hogy ott kevesbe problema, ha egyedi megoldast szallit valaki, de a mainstream piacon nem lehet sajnos egyenieskedni. Amikor a memoria modulra rakott DDR3/DDR4 a divat, akkor nem lehet BGA-val egyenieskedni, es ugyanigy a HBM sem mukodne sajnos rendszermemoriakent 

v_peter2012
csendes tag
Én azon lepődtem meg hogy az amd ilyen messzire tervez ![;]](http://cdn.rios.hu/dl/s/v1.gif)
A GCN processzor, mégsem professzor? Várja a kisegítő iskola padja, a Maxwell pedig röhög rajta.

Kristof93
senior tag
Desktopra is jöhetne valami hasonló
Fiery
veterán
A dGPU-knak -- jelenleg -- az alabbi elonyei vannak:
1) Nagyon gyors es egyben nagyon sok memoriat is lehet mellé pakolni. A HBM az AMD HPC APU-janak near memory szerepeben fog mukodni (ha jol ertelmezem), ergo nem lesz rengeteg belole, "csupan" 4 vagy 8 (esetleg 16) GB, a tobbi a "lassu" 4+ csatornas DDR4 rendszermemoriabol lesz hasznalva.
2) Tobb GPU-t is telepithetsz egy konfiguracioba
3) Kicsit szelesebb tartomanyban lehet a TDP-t szabalyozni

lenox
veterán
Furcsa, de nem meglepo .
#11:
1. Egyelore 16 GB gyanusan eleg lenne.
2. Igen, valoszinuleg egy dual apus konfig jo lenne, ha lenne.
3. Nekem az volt a benyomasom, hogy apuknal is eleg szeles tartomanyban lehet.
[ Szerkesztve ]

Abu85
HÁZIGAZDA
Gondolom nekik lesz tempósabb dedikált gyorsítójuk. Elképzelhető egyébként, itt még mindig elviszi a fogyasztási keret egy részét a procirész.
(#7) Fiery: Ez nem a Knights Landing ellenfele. Az AMD korábban is mondta már, hogy kipróbálták a sokmagos koncepciót. Egyrészt directory protokollt igényel, ami azt eredményezi, hogy a tranzisztorok felét csak a cache-be verik, illetve szimuláción sem működött több feladatban 20 magnál jobban a skálázódás. Ugyanezt egyébként az Intel is folyamatosan elmondja, hogy nem a maximális kihasználásra kell törekedni, hanem az optimálisra, mert a Xeon Phi-vel ma is előfordul, hogy kevesebb aktív mag több sebességet ad. Szerintem az AMD valami gyakorlatban is használható rendszert szeretne, aminek lehetséges a programozása.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

stratova
veterán
Fast Forward?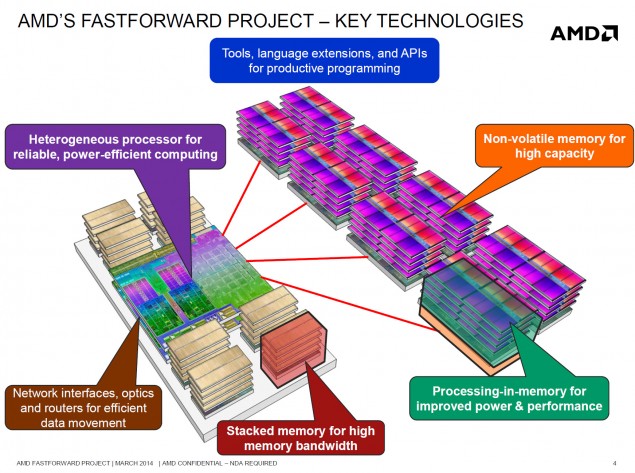

#06658560
törölt tag
Mi az APU lényege? A GPU és CPU rész közötti adatmásolás megúszása. mik a sajátosságai? Olyan feladatra vannak kitalálva, ahol egyszerre kell mindkét rész számítási sajátossága, azonos adatokon. Mik a hátrányai? Adott fogyasztási keret mellett, adott hűtési teljesítmény mellett könnyen bele lehet futni abba az állapotba, hogy egyidejűleg a CPU és GPU részt nem lehet teljes mértékben kihajtani, mert megsülne a rendszer.
A dedikált rendszer hol jó? Ahol kevesebb alkalommal kell adatokat másolni, de olyankor akár nagyobb egységeket is. A CPU és GPU rész külön-külön jobban kihajtható, nem fűtik egymást normálisan felépített rendszer esetén.
Hogy egy végeselemes rendszerben írjak példákat: egy öt rúdból álló rácsszerketzet statikus vizsgálatához nagy valószínűséggel egy CPU is pont elég. Egy hatszázmillió csomópontot tartalmazó, nemlineáris, dinamikus, többparaméteres, esetleg nemstaacionárius paraméteres rendszer vizsgálatánál már nagyobb eséllyel megéri csak GPU részt használni, böhöm clusterbe rakva, ahol a CPU részek csakis az adatmásolással foglalkoznak. Itt a kihasználtság inkább olyan, hogy az elemek egy csoportja bekerül egy memória-címtérbe, amik a legszorosabb kapcsolatban vannak egymással, s adott GPU egység az általa számolt csomópontok eredményeit egyben adja tovább, nem egyesével.
A két állapot között pedig van az a terület, ahol az APU-k, a multi GPU-s, multi CPU-s rendszerek megélnek. Itt mindig a feladat dönti el, milyen rendszer a legjobb, mind szoftverarchitektúra, mind hardverarchitektúra szempontjából.
#12 lenox: HPC, tehát tuti rohadt kevés lenne a 16 GiB.
#8 Fiery: kieg.: HPC piacon belefér, hogy pontosan definiálják az igényt, s az upgrade lépésekbe belefér a mindent egyben cserélni állapot, kisebb léptékben viszotn a memóriaigény szokott leghamarabb megszaladni, s ott nem is tolerálják a vegyél új CPU+GPU+RAM egységet logikát.
[ Szerkesztve ]
Fiery
veterán
1) Dehogy eleg, marmint egyseges rendszer- es videomemorianak. Mar most is 12 meg 16 gigas profi kartyakkal nyomulnak, 2-3 ev mulva mar kozel sem lesz elegendo a 16 giga a HPC piacon. Ne a jatekokbol indulj ki, az semmit nem jelent, hogy egy Radeonon mennyi videomemoria talalhato
2) Nem a dual APU az igazan izgalmas a HPC-piacon, hanem az olyan vadorzo GPU-szerver konfigok, amikben mondjuk van 4 vagy 8 db dual-GPU-s Tesla  Tehat nem az 1 db GPU vs. 2 db GPU az izgalmas kerdes, hanem az 1 db vs. 8/16 db. Az meg mar nagyon nem mindegy. A Knights Landing es ez az AMD HPC APU sem lesz jo mindenre, egy csomo vonalon megmaradnak a Tesla-szeru dGPU-s megoldasok, de sok esetben pedig pont a megosztott memoria miatt nagyon-nagyon jol lehet majd hasznalni ezeket a HPC APU-kat majd. Mint ahogy most is baromi jol lehetne hasznalni a Kaverit bizonyos HPC feladatokra, _ha_ ennel sokkal erosebb lenne az iGPU-ja, es sokkal nagyobb lenne a memoria savszelesseg.
Tehat nem az 1 db GPU vs. 2 db GPU az izgalmas kerdes, hanem az 1 db vs. 8/16 db. Az meg mar nagyon nem mindegy. A Knights Landing es ez az AMD HPC APU sem lesz jo mindenre, egy csomo vonalon megmaradnak a Tesla-szeru dGPU-s megoldasok, de sok esetben pedig pont a megosztott memoria miatt nagyon-nagyon jol lehet majd hasznalni ezeket a HPC APU-kat majd. Mint ahogy most is baromi jol lehetne hasznalni a Kaverit bizonyos HPC feladatokra, _ha_ ennel sokkal erosebb lenne az iGPU-ja, es sokkal nagyobb lenne a memoria savszelesseg.
3) Tipikusan 200-250 Watt korul erkeznek a HPC APU-k, mig egy dGPU-nal ennel kijjebb is lehet tolni a TDP-t. 50-100 Watt pedig marha sokat szamit.
[ Szerkesztve ]
Fiery
veterán
Mit csinaljak ezzel? Slideware.

FM2+-ba mikor jön? Lehetőleg valami ASRock lapba...
[ Szerkesztve ]
"Csak egy dologtól félek. Ha meghalok, az asszony eladja a gépeimet annyiért, amennyit bevallottam neki." KERESEM: Lian Li PC-C50, Silverstone Milo ML03 ..............................................................................................

Thrawn
félisten
Ma is tanultam egy új szakkifejezést 
Different songs for different moods. łłł DIII Thrawn#2856 łłł Look! More hidden footprints! łłł D4BAD łłł WoT: s_thrawn łłł
Fiery
veterán
Mar van ilyen, Kaverinak hivjak Ugyanaz, kicsiben.
Fiery
veterán
Dehogynem a Knights Landing ellenfele. Mindket procit specialis szamitasokra szanjak, mindketto egy dGPU helyet veszi at, mindketto a megosztott memoria koncepciojara epit (bar nem feltetlenul ugyanolyan modon), mindketto tulajdonkeppen egy CPU tokba rakott dGPU, mindkettonel van near memory (tok mindegy, hogy hivjak), de mindketto elsosorban a rendszermemoriaba dolgozik. Ja, es mindketto nagyjabol ugyanolyan TDP-osztalyt celoz. Az, hogy az architektura heterogen vagy homogen, me'g tok ugyanaz a vegcel mindket HPC megoldassal.
"Szerintem az AMD valami gyakorlatban is használható rendszert szeretne, aminek lehetséges a programozása."
((( Kepzelj ide egy big f* facepalmot ))) Mert ugye a Knights Landing-et nem lehet a gyakorlatban programozni. Lassuk csak, irni kell egy 240 szalra skalazott x86 kodot. Jajj, vajon azt hogyan oldja meg a programozo? Az x86 valami tok uj dolog, nem tudom, hogyan fogjak a programozok elsajatitani hirtelen ezt az uj megoldast...
[ Szerkesztve ]
#06658560
törölt tag
Volt oktatásom, Amin ecsetelték a hogyan legyünk jó mérnökök témát: Volt szó a Power Point Poisoningról, mint rossz dologról. De a szünetkülön diát kapott.
lenox
veterán
1. Itt van nalam m6000, k80, w9100, w8100. Nincs rajtuk tobb, mint 16 GB, szoval ha ezekhez eleg, akkor egy apun is eleg lenne. Vagy lehet, hogy az nem jott at, hogy ezt a szokasos sokcsatornas memoria melle kepzelem, nem helyette.
2. Nem tudom, top500-ban nem sok ilyen van, tippem szerint ezzel a top500-nak megfelelo piacra akarnanak menni.
3. Melyik gyorsiton van 250 wattnal nagyobb tdp-ju gpu, amit HPC piacon hasznalnak?
Abu85
HÁZIGAZDA
Nagymértékben meghatározza a rendszer működését a szálkezelés. A legfőbb oka annak, hogy a mai gyorsítók hardveres szálkezelést és hardveres szinkronizációt használnak az, hogy a programozó képtelen lenne biztosítani a manuális kezelésüket és szinkronizálásukat. A Xeon Phi esetében is látszik a probléma, mert se OpenMP, se OpenCL alól nem lehet igazán használni.
A Phi egy újszerű paradigmát igényel. Figyelembe kell venni az algoritmust és nem az a jó, ha mindegyik magot befogják, hanem az, ha annyit fognak be, amennyivel gyors lehet. Ha ez csak 10-20 mag akkor annyit, de érdemes limitálást figyelembe venni, mert sokszor ettől gyorsul. Ez az oka annak is, amiért a Xeon Phi az iparág által el van könyvelve szarnak. Pedig nem rossz, csak nagyon speciális programozást igényel.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Fiery
veterán
1) Near memory-nak eleg a 16 giga, de ez siman meg is valosithato jovore. Marmint, ha az Intel meg tudja csinalni, akkor nyilvan az AMD is meg tudja. Hogy HBM-mel mennyit tudnak pakolni az APU kore, az megint mas kerdes, ez majd kiderul a gyakorlatban. Persze az is lenyeges kerdes, hogy a rendszermemoria fele milyen savszelesseget biztosit az APU: ha mondjuk lenne egy combos 8 csatornas DDR4, akkor eleg lenne kevesebb near memory is.
2) En ugy ertelmezem, hogy a Knights Landing es ez az AMD HPC APU is inkabb specialis feladatkorokre lesz, nem a top500-at ostromolni. Inkabb oda lehetnek ezek jok, ahova a Kaveri lassu, a dGPU nem jo (a memoria masolgatas miatt), es a 4-8 socketes klasszikus x86 (pl. Xeon E7) keves. Ez pedig eleg vekony szelete a piacnak, viszont adott esetben egy nagyon fontos szelete, hiszen a jovo siman lehet, hogy ilyen HPC megoldasokat fog hozni a mainstream piacra is.
3) Tesla K80, ami 300 Watt, ha nem tevedek.
[ Szerkesztve ]
stratova
veterán
Detto 
lenox
veterán
Tesla k80 az ket gpu, nem egy...
Ahova a 8 socketes xeon e7 keves, ott egy apu nem tudom, mit fog kezdeni, szerintem semmit. Mondjuk olcsobb lesz, annyi elonye lehet, meg kevesebbet fogyaszt, de teljesitmenyben tul sokra nem fogja vinni szerintem, vagy legalabbis akkor azt a feladatot nagyon erre kell kihegyezni, nem tudom, mi lehetne az...
[ Szerkesztve ]
#06658560
törölt tag

Balala2007
tag
Huzzanak bele, a KNL mar itt tart:
Innen van. Zavaros a szoveg, keveri a core-t meg a thread-et, de a kep akkor is erdekes, ha "csak" thread, es nem 240 core hasznalatat mutatja.
AIDA64.com
Fiery
veterán
Hadd kerdezzem mar, ennek, amit irtal, mi a frasz koze van barmihez is? Nehogy mar a Xeon Phi-t hasonlitsuk egy Knights Landinghez vagy az AMD HPC APU-jahoz. Teljesen mas megkozelites, mas utasitaskeszlet, mas architektura, minden **rvara mas. A Xeon Phi valoban korulmenyes, plane ha melleteszel egy Teslat. Onmagaban a Xeon Phi sem egy megoldhatatlan problema, hiszen mar reges-reg kitalaltak az x86 piacon a tobbszalu kodoknal a beallithato CPU maszkot Egy 36 magos (2 utas) Xeon E5-nel sem kotelezo mind a 72 threadet kihasznalnia egy x86 szoftvernek, ha gyorsabb kevesebb thread hasznalataval a kod.
Egy Knights Landingnel majd a programozok kimérik, hogy mi az optimalis thread leosztas. Legyen ez az o problemajuk, nemtom miert kellene Neked eldonteni helyettuk, hogy jo lesz-e a KNL nekik vagy sem. Az biztos, hogy nem igenyel uj paradigmat, hiszen x86. Ha az Itanium a nem-x86 architektura miatt bukott meg, akkor a KNL-rol elore eldontjuk, hogy pont az x86 miatt fog elbukni?
Amugy meg, remelem szamodra is teljesen vilagos, hogy se a KNL, se az AMD HPC APU-ja nem a mainstream piac szamara keszul. Egy nagyon specialis, nagyon vekony piaci reteg igenyt igyekeznek ezekkel kielegiteni a gyartok. Amikor pedig ennyire specialis termekrol van szo, hidd el, nem lesz problema a programozokkal megiratni a f*sza kodot. Mint ahogy arrol sem lehet sokat hallani, hogy a Tesla kapcsan problema lenne a programozas. Pedig ott masolgatni kell a memoriat, meg kell tanulni a CUDA-t, stb. Megis elboldogulnak vele azok, akinek ez a feladatuk. A CUDA-val szemben viszont az x86 programozok szama igencsak nagysagrendekkel nagyobb, me'g azoke is, akik adott esetben nem teljesen fogalmatlanok a multi-threaded + SIMD programozas kapcsan sem. Lesz, aki kodot gyartson majd a KNL-hez.
Az AMD HPC APU-ja pedig pont ugyanaz pepitaban, mint a Kaveri. Aki most is gyart kodot a Kaverihoz, az imadni fogja az AMD HPC APU-jat is. A gyakorlatban majd kiderul, melyik a tuti megoldas. Siman lehet, hogy a HSA-val parositva nagyon vonzo platform lesz az AMD HPC APU-ja -- de az is lehet, hogy a konkurens x86-os megoldas miatt megsem.
[ Szerkesztve ]
Fiery
veterán
"Tesla k80 az ket gpu, nem egy..."
Es? Nem az szamit, hany GPU, hanem hogy hany TFLOPS DP-ben. Amugy meg, ha nem tevedek, a dGPU-knal ennel durvabb TDP-t is ki lehetne tuzni, ha meg tudnak oldani a hoelvezetest -- mig az APU-knal mar a 200-250W is neccesnek hangzik.
"Ahova a 8 socketes xeon e7 keves, ott egy apu nem tudom, mit fog kezdeni, szerintem semmit"
Nem ugyanaz a TDP-osztaly, ahogy irod is. Es ezeket az APU-kat is lehet majd klaszterezni.
[ Szerkesztve ]

JColee
őstag
Ez mi, htop?
Abu85
HÁZIGAZDA
Ma az ipar arról beszél, hogy 48 000 Xeon Phi-t nem használ a Thiane-2, mert nem tudják befogni. Ez nem az első eset. Az első Knights terméket az Intel ki sem hozta, mert tudták, hogy rossz. A másodikat kihozták, majd mikor kiderült, hogy nem úgy működik ahogy ígérték megdobták a piacot egy OpenCL meghajtóval. Azokat a megrendelőket, akik direkt azért kértek Xeon Phi-t, hogy úgy használják ahogy az Intel ígérte és ne OpenCL-en keresztül. Mennyi bizalom maradt?
Nem az x86 miatt bukdácsol a Xeon Phi vonal, hanem leginkább amiatt, hogy azok a programozási paradigmák, amelyek kialakultak nem működnek rajta. A hardver egyébként működik az Intel assembly példakódjaival.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Fiery
veterán
Es szerinted a mostani vagy epp az elozo generacios Xeon Phi-nek mennyi koze van a KNL-hez? Szerinted ugyanugy kell programozni?
Az az Intel sara, hogy valaki epit egy balf*sz modon osszerakott szuperszamitogepet, majd nem tud megfelelo kodot kesziteni hozza? Miert vettek meg, ha nem tudjak kihasznalni? Vagy ha arra gondolsz, hogy az egesz csak egy PR-fogas volt, akkor egyetertek, de akkor meg az Intel csinalta jol, hiszen a sz*rt milyen ugyesen tudta promotalni
Abban egyebkent nem fogunk vitatkozni, hogy technikailag nem jo megoldas a mostani Xeon Phi. De ne vetitsuk le azt elore a KNL-re is, mert az tok mas megkozelites. Nagyjabol annyi koze van egymashoz a 2 termeknek, mint mondjuk egy low-end GCN1 dGPU-nak a Carrizohoz.
A bizalom kerdest meg inkabb ne feszegessuk egy alapvetoen AMD-s hirhez kapcsolodo topikban szerintem 
 Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon.
Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon.
[ Szerkesztve ]
Balala2007
tag
Sajnos nem tudom. Valaki *n*x-ban jaratos megmondhatna, esetleg az is kiderulhetne, h ez most 240 core vagy thread.
AIDA64.com
lenox
veterán
Hat per gpu nincs kijebb tolva a tdp, nem tudom, az miert lenne erdekes mondas, hogy pl. 100 gpu-nak nagyobb tdp-je van, mint egy apunak, nyilvan a tdp skalazast per chip erdemes nezni. Szamomra mint irtam skalazhatonak tuntek az apuk eddig is tdp-ben, te irtad, hogy de a dgpu-kat jobban/kijebb lehet, de a valosagban meg nem skalazzak oket 250 watt fole.
De ha jo a klaszter, akkor xeonbol is jok lennenek az 1-2 utasak is, tehat az nem az a feladat, amikor specialis megoldas kell.
Abu85
HÁZIGAZDA
Mivel a szálkezelés és a szinkronizáció nem változik, így a programozónak ugyanazt kell csinálnia.
Annyiban igen, hogy az Intel mondta, hogy a meglévő OpenMP kódok használhatók lesznek. Sokan ezért választották ezt a gyorsítót, mert az Intel így promótálta. Aztán amikor kiderült, hogy ez nem igaz, akkor kidobtak egy OpenCL-t rá. A gond az, hogy az OpenCL alatt a legtöbben úgy közelítik meg a Phi-t, mint a FirePro és a Tesla rendszereket. És ez okozza a rossz megítélést. Nyilván másra nehéz gondolnia egy programozónak, minthogy rossz a hardver, ha egy FirePrón és Teslán tökéletesen működő kód Phi-n nem működik.
Az Intelnek el kell magyaráznia a piacnak, hogy a Phi nagyon specifikus rendszer, amit sokkal nehezebb programozni, mint a GPGPU-kat. Ez biztosíthatná a Phi jövőjét.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Fiery
veterán
Alapvetoen arra gondoltam, hogy ha egyetlen gepben gondolkozol (nem klaszterben), akkor 1 db szerverbe bele tudsz pakolni 4 vagy 8 db dGPU-t is, mig APU-bol csak egyet. Es egy-egy ilyen konfignal nemileg szelesebb tartomanyban tud mozogni a dGPU-k TDP-je, mint az APU-ke. A wattot pedig alapvetoen videokartya vs. APU tokozasra ertettem, tehat egy adott videokartya hany wattbol tud gazdalkodni ill. egy APU. Az reszletkerdes, hogy egy videokartyara 1 vagy 2 db dGPU-t szerelnek, az mar egyeni preferencia kerdese, hogy ki milyet szeretne a szerverbe pakolni. Viszont, APU-bol csak 1 db-ot tudsz hasznalni szerverenkent a megosztott memoria miatt, kiveve persze ha a koherenciarol lemondasz.
Fiery
veterán
Szerintem nem latod a fatol az erdot Probalod ugy beallitani a Xeon Phi-t meg a KNL-et, mintha az azoknak keszult volna, akik hatalmas spilerek GPGPU temaban, pl. OpenCL vagy CUDA alapokon. Mibol gondolod, hogy ez igy van? Mibol gondolod, hogy pl. a KNL nem azoknak keszul, akik jelenleg tobbszalu SIMD _x86_ kodot keszitenek mondjuk Visual Studioban? Mibol gondolod, hogy tobbsegeben vannak azok, akik OpenCL/CUDA platformokrol erkeznek; azokkal szemben, akik x86 programozassal tengetik az eletuket, es esetleg tobbszalu SIMD kodot is kepesek kesziteni valamilyen eszkozzel?
"Az Intelnek el kell magyaráznia a piacnak, hogy a Phi nagyon specifikus rendszer, amit sokkal nehezebb programozni, mint a GPGPU-kat. Ez biztosítaná a Phi jövőjét."
A mostani Xeon Phi-t talan nehezebb programozni, mint az OpenCL ill. CUDA alapu AMD/nVIDIA megoldasokat, de nem igazan ertem, miert lenne olyan nagy varazslat programozni a KNL-et. Mas, ez teny. De ennyi erovel akkor egy 72 szalu (2 utas) Xeon E5-re is ugyanugy nehez programot kesziteni. Vagy ha a hagyomanyos szerver Xeonokkal megbirkoznak a programozok, akkor miert lenne nehezebb boldogulni a Knights Landinggel? Mindketto x86, mindketto sokszalu, mindketto AVXn (n = 1..512 ), mindketto rendszermemoriabol dolgozik nagy cache-ekkel.
[ Szerkesztve ]
Abu85
HÁZIGAZDA
Széles SIMD-ek esetében a koncepció ugyanaz. Az AMD és az NV megoldásai esetében annyi a különbség, hogy a programozónak nem kell törődnie a vektorizálással a SIMT modell miatt, míg az Intel koncepciójában ez egy kritikus rész.
Az Intel nem véletlenül hozott OpenCL-t a processzoraihoz. A helyzet az, hogy ezen egyszerűbb programozni széles SIMD-eket, mint vector intrinsics-szel. Nagyon sokan ezért szeretik az OpenCL-t, és nem feltétlenül a GPGPU-s lehetőségek miatt.
Ne gondold, hogy egyszerűbb vector intrinsics-szel 512 bites SIMD-eket kivágni manuális szinkronizálással 280+ szálra. Az Intelnek arra kellene figyelnie, hogy megértesse a programozókkal, hogy ez nem annyira könnyű, mint a GPGPU paradigmák, amelyeket ráadásul megszokott a piac. Ez sokat segítene a KNL helyzetén.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Fiery
veterán
Tovabbra sem ertem, mi a problemad, es miert kellene az Intelnek barkit is oktatnia a KNL programozasaval kapcsolatban. A SIMD uj dolog? Nem. Az, hogy milyen szeles, masodlagos kerdes, a programozo majd megoldja. Volt eddig is sok szalu konfig? Volt, hogyne lett volna. Aki meg 16 szalra tud kodot irni, az 240-re is tud. Az OpenCL sem egy uj dolog, raadasul egy plusz funkcio, amivel tagulnak a lehetosegek. Az OpenCL kapcsan pont nem az Intelt kellene **szogatni, hiszen az AMD es nVIDIA megoldasaival szemben, a KNL-et lehet direktben is programozni, mindenfele plusz retegek (OpenCL, CUDA) nelkul. Mig ugyanezt az AMD es nVIDIA vonalon nem tul sokan vallaljak be, hiszen baromira nem "coder-friendly" ott a nativ kodolas.
"Az Intelnek arra kellene figyelnie, hogy megértesse a programozókkal, hogy ez nem annyira könnyű, mint a GPGPU paradigmák, amelyeket ráadásul megszokott a piac"
Eloszor is: az Intelnek kellene megertetni a vilaggal, hogy a (SIMD) x86 sz*r? Ennyire hulyenek nezed oket, hogy tökön lovik sajat magukat? Es kulonben is, ha lesz OpenCL tamogatas, akkor minden programozo, sajat hataskorben el fogja tudni donteni, hogy mit akar hasznalni. Ha nem tetszik az x86, lehet OpenCL-t hasznalni. Ha nem tetszik az OpenCL, akkor viszont csak a KNL-en tudsz SIMD x86-ot hasznalni, ami viszont sok embernek sokkal ismerosebb, mint a mindenfele GPGPU-s hobortok.
A megszokott a piacon meg csak nevetni tudok. Miota van x86? Miota van SIMD x86? Miota van OpenCL, amit gyakorlatban is lehet hasznalni? Miota van koherens (SVM) OpenCL? Miota van CUDA? Most akkor melyiket szokta meg tobb programozo? Nem kenyerem a szemelyeskedes, de rajtad qrvara latszodik, hogy nem vagy programozo. Akkora suletlensegeket, amiket irsz, egy programozo sosem irna le. Amivel persze nincs baj, marmint hogy nem vagy programozo, hiszen nem lehet minden informatikaval foglalkozo szakember programozo. De van egy pont, ahol meg kellene allni, es hagyni, hogy a programozok eldontsek maguknak, mi a jo nekik. Es szereny velemenyem szerint a programozok a KNL megjelenese utan nem az x86 miatt fognak eloszor utcara vonulni, kovetelve egy absztrakt GPGPU-s f*szsagot _helyette_. Hangsulyozom: helyette. Mert ugye lehet igy is, ugy is programozni a KNL-et.
[ Szerkesztve ]
Abu85
HÁZIGAZDA
Nekem mindegy, hogy az Intel oktat-e belőle vagy sem. Nekik nem lesz jó, ha nem tudják használni a hardvert.
Ki mondta, hogy a SIMD szar? Ez jó, csak nem olyan könnyű, mint a SIMT. És a Xeon Phi kihasználatlanságához nagyban hozzájárul az, hogy a programozók nem tudják hogyan kell programozni. Ez részben az Intel felelőssége, mert a "plusz két sor a meglévő OpenMP kódba és minden fasza lesz" szöveg mellé adhattak volna támpontot is.
Tehát ha meg tud írni a programozó két szálra egy 128 bites SSE2 kódot, akkor ebből következik, hogy 288 szálra is tudnia kell 512 bites AVX-et?
Hallgass meg egy pár Andrew Richards előadást. Ő dolgozott a Phi-n és megpróbálta meggyőzni az Intelt, hogy ez a koncepció nagyon nehéz lesz a programozóknak.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Fiery
veterán
"A nehezebb és a szart pedig ne keverjük össze."
Ha az Intel elkezdené azt sujkolni a programozokba, hogy az x86 nem eleg jo a KNL-re valo fejlesztes kapcsan, az lenne az igazi PR katasztrofa. Ok nem a Microsoft, hogy maguk alatt vagjak a fat A programozok meg hidd el, eleg okosak ahhoz, hogy eldontsek, x86 SIMD-vel akarnak molyolni, vagy OpenCL-lel probalkoznak inkabb. Nagyban fugg ez attol is, mit csinalsz pontosan, mit akarsz elerni, es hogy van-e mar meglevo kodod. Ha mar van mondjuk egy Xeon E5-re fejlesztett x86 kodod, akkor hulye leszel OpenCL-re portolni azt, ha minimalis modositassal a KNL-en is szakitani fog. De persze a masik oldalrol meg ha OpenCL-ben vagy CUDA-ban mar van egy kesz kerneled, akkor meg nem fogsz nekiallni x86-tal szorakozni, ha az OpenCL kod is remekul fut.
"Tehát ha meg tud írni a programozó két szálra egy 128 bites SSE2 kódot, akkor ebből következik, hogy 288 szálra is tudnia kell 512 bites AVX-et?"
Igy van. Vagy ha nem megy neki, akkor nem eleg jo x86 SIMD programozo az illeto. Ez esetben pedig lehet OpenCL-lel probalkozni.
"Hallgass meg egy pár Andrew Richards előadást. Ő dolgozott a Phi-n és megpróbálta meggyőzni az Intelt, hogy ez a koncepció nagyon nehéz lesz a programozóknak."
Asszem innentol felesleges is tovabb vitazni errol. Te egyetlen ember velemenyebol derivalod le, hogy az egesz KNL koncepcio (ami egyebkent _nem_ azonos a mostani Phi koncepciojaval, csak ezt se igazan vagy kepes megerteni, vagy csak elegansan atleped a kerdest, mint ha nem ez lenne az egyik legfontosabb valtozas) ugy ahogy van, rossz. Tegyel igy, en azt mondom, a piac majd eldonti a kerdest. Ugyanigy, a piac mar sok kerdest eldontott, pl. Seattle, Kaveri GDDR5, Itanium, stb.
[ Szerkesztve ]

Ma az ipar arról beszél, hogy 48 000 Xeon Phi-t nem használ a Thiane-2
Kínában új városok állnak tök üresen, kihasználatlanul:
Welcome to Ordos, China: The World’s Largest “Ghost City”
Fiery
veterán
Egyebkent errol az Andrew Richards-rol van szo?
Mert ha igen, akkor eleg fura, hogy nem irta be az elozo munkahelyei koze az Intelt. Vagy az annyira elhanyagolhato ceg, hogy nem erdemes megemliteni sem, mert ugyse ismeri senki?
Vagy nem is dolgozott valojaban a Xeon Phi-n (ahogy irod), hanem a Xeon Phi-vel dolgozott? Vasarolt egyet, kiprobalta, azt mondta, hogy sz*r? Persze latom en, hogy GPU compilerekkel foglalkozik, de ugye a KNL-en nem kell (ujfajta) compiler, az nem holmi GPGPU, hanem egy sima CPU... Tehat a mostani Xeon Phi sz*r, mert Andrew Richards nem tudott ra GPU compilert irni, ergo a kovetkezo, teljesen mas architekturaju Xeon Phi (azaz a KNL) is az lesz, hiszen ............ <-- es ide jon egy nyakatekert logikai manover, amit kitalaltal?
[ Szerkesztve ]
Abu85
HÁZIGAZDA
Nem értem a PR katasztrófa részét. Az Intelnek azt kell megértetnie a programozókkal, hogy amit eddig tapasztaltak a FirePro vagy a Tesla rendszerekről az a Phi esetében nem teljesen igaz. Amit az egyetemen tanítanak az a Phi-nél nem teljesen igaz. Egyszerűen csak fel kellene erre hívni a figyelmet, és leírni, hogy mire kell optimalizálni. Nagyon sokszor elhangzik az előadásokon, hogy a mai vektorarchitektúráknál a függőségre nem kell figyelni, mert ez már nem limitálja a feldolgozást, de ez a Phi-re nem igaz. Ugyanígy a szinkronizálás és a szálkezelés. Majd megoldja a hardver? Egy csomó rendszer igen, de nem a Phi. Ha ezekről beszámolnak az pont azt szorgalmazza, hogy a programozó jobban megértse a hardvert.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
#06658560
törölt tag
Erre annyit tudok mondani, egyetlen programozónak sincs megtiltva az önálló gondolkodás!
Abu85
HÁZIGAZDA
Andrew Richards a CodePlay elnök-vezérigazgatója volt mindig is. Az Intel egy rakás magasan jegyzett és elismert szakmai zsenit felkért a projekthez, akik segítették a munkát. Ezek az emberek ugyanakkor eltávolodtak az Inteltől, amikor a cég nem fogadta meg a tanácsaikat. Ezek közül a legfőbb az volt, hogy dobják az x86-ot, mert nagyon öreg ISA, és nem is tervezték túl skálázódóra a memóriamodelljét. Persze az Intel kifizette a szakértelmüket attól, hogy nem fogadták meg a tanácsaikat, csak ezek az emberek nem akartak úgy a projektben részt venni, hogy tudták, hogy nem fog működni. Ezért a szerződésüket felbontották.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
lenox
veterán
Hat szerintem aki mar simd, cuda es opencl kodot is optimalizalt, az annal jobban ert hozza, hogy az egyetemi tanulmanyaira visszaemlekezve probaljon phi-re optimalizalni.
Fiery
veterán
A PR katasztrofa akkor alakulna ki, ha az Intel arrol kezdene beszelni, hogy az x86 nem (eleg) jo, es helyette hasznalj valami mast. Nem, ilyen nem fordulhat elo. Az Intel az x86-rol szol, akarcsak a Microsoft a Windowsrol. A Microsoft sem fogja sosem azt mondani, hogy a Windows sz*r, hasznalj helyette mast. Az megint mas kerdes, ha csinalnak egy szuboptimalis (oke, mondjuk ki, sz*r) termeket egy adott koncepciora, majd tobb generacion at foldozgatjak, mig vegul osszeall, es hasznalhato lesz. De me'g ebben az esetben sem lehet azt mondani, hogy hasznalj mast, es nem lehet hatraarcot csinalni. Jo pelda erre a Xeon Phi is, de pl. a Windows is. A Windows Vistanal felresiklott az Microsoft, de nem adta fel, es a Windows 7-re osszerakta a dolgokat, ami megint jo lett. A Windows 8 is felrecsuszott, jott a korrekcio a Windows 8.1-gyel, de me'g mindig nem lett (eleg) jo. Vegul a Windows 10-zel kerulnek a helyere a dolgok (remelhetoleg), _de_ ez nem jelenti azt, hogy a Windows 8.x alapjan elore el lehetne konyvelni f*snak a Windows 10-et. Szerintem varjuk meg mindkettot (KNL, Windows 10), mielott az elozo generacios benazasok okan elore eltemetjuk oket.
"Az Intelnek azt kell megértetnie a programozókkal, hogy amit eddig tapasztaltak a FirePro vagy a Tesla rendszerekről az a Phi esetében nem teljesen igaz."
Mintha el sem olvasnad, amit irok Direkt leirtam, hogy _semmi_ de semmi bizonyitek arra, hogy a KNL-en fejlesztok mas GPGPU platformokrol erkeznek. Es ha x86-rol erkeznek, akkor mi van? Akkor ki a francot erdekel, hogy mi van a Teslaval? Amugy meg, ennyi erovel en ha x86-on programozok mondjuk Pascalban, akkor elore lelkileg fel kellene keszitenie a Google-nak engem arra, hogy milyen megrazkodtatas lesz az androidos fejlesztes Javaban? Hol nem sz*rja ezt le a Google? Ha programozo vagyok, es nem vagyok teljesen bena, akkor meg fogom tudni tanulni az Android+Javat is, nem kell a kis kezemet fogni. Ne nezd mar teljesen gyamoltalan f*sznak a programozokat Van biztos olyan is, de en szemely szerint nem ismerek olyat, aki ne lenne kepes valamilyen szinten x86 SIMD vagy OpenCL/CUDA programozasra, vagy epp a ketto kozott valtani, ha ugy hozza a sors.
"Majd megoldja a hardver?"
Ha OpenCL stack lesz a KNL-re (marpedig lesz), akkor igen, a hardver megoldja, ha azt szeretned.

Témaindító írás:

Mai Hardverapró hirdetések
prémium kategóriában
- Playstation 5 lemezes,5 honapos,19 ho garanciával
- MSI H61M-P31/W8 LGA 1155 alaplap
- Teljesen új ASUS ZenBook UX325EA-KG666W (Intel i5 1135G7) laptop eladó (bontatlan+garanciás)
- Új, bontatlan Samsung S24+ 256 GB black
- Dell Latitude E7270, 12,5" HD Kijelző, i5-6300U CPU, 8GB DDR4, 256GB SSD, W10, Számla, Garancia
