"Nem azért írtam, mert valaki ezzel ellentéteset állított volna, hanem mert ez van a doksiban."
Ez szép és jó, hogy benne van a doksiban. Úgy érzem, nem árt tisztázni, ki mit állított, mikor én kéretlenül és hozzáértés nélkül beleugattam.
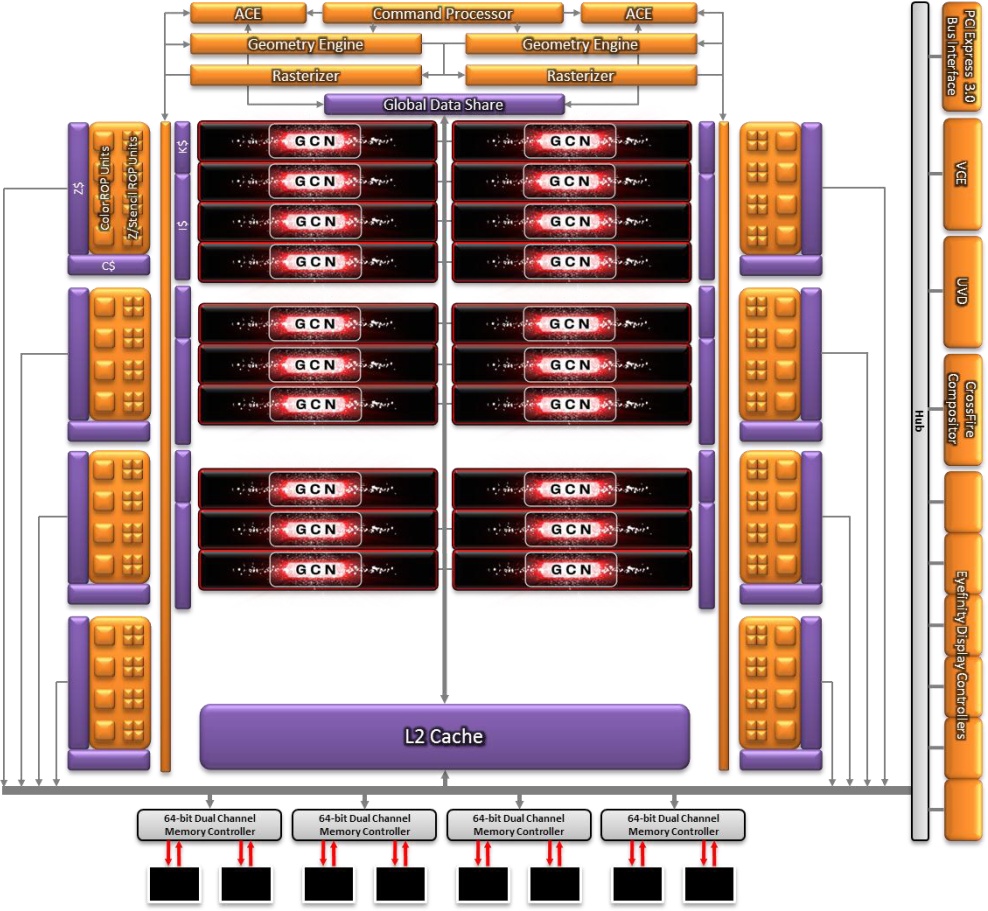
Abu85: "Eddig a ROP blokkokhoz tartoztak a L2 gyorsítótár partíciói"
namaste:
"A GCN-nél a ROP és a hozzátartozó color/depth cache a memóriavezérlőhöz kapcsolódik, semmi köze az L2-höz."
Lehet, hogy Abu nem fogalmazott pontosan, de az biztos, hogy a ROP (és "tartozékai") nem közvetlenül csatlakoznak a memóriavezérlőhöz. A témában nézd meg az Anandtech leírását a GCN megjelenésekor:
"As it turns out, there’s a very good reason that AMD went this route. ROP operations are extremely bandwidth intensive, so much so that even when pairing up ROPs with memory controllers, the ROPs are often still starved of memory bandwidth. With Cayman AMD was not able to reach their peak theoretical ROP throughput even in synthetic tests, never mind in real-world usage. With Tahiti [...] The solution to that was rather counter-intuitive: decouple the ROPs from the memory controllers. By servicing the ROPs through a crossbar AMD can hold the number of ROPs constant at 32 while increasing the width of the memory bus by 50%."
Igaz, Anandék crossbart írtak, Abu meg ring bust mondott, ami nem ugyanaz - talán valami bonyolultabb hibrid összeköttetés van, amire Abu forrása gyűrűs buszként hivatkozott, az Anandteché meg crossbarként. A lényeg most nem is ez, hanem, hogy már az első GCN-ben sem közvetlenül a MC-hez kapcsolódtak a ROP-ok.
A Vegánál ezt írják:
"AMD has significantly reworked how the ROPs (or as they like to call them, the Render Back-Ends) interact with their L2 cache. Starting with Vega, the ROPs are now clients of the L2 cache rather than the memory controller, allowing them to better and more directly use the relatively spacious L2 cache."
Szerintem ez összhangban van azzal, amit Abu mond, de azzal is, amit te a #167-esben írtál. De lehet, hogy csak rosszul látok.
"Az ábrák se pontosak, össze-vissza vannak, pl. egyiken az L2 egy darabból áll, a másikon darabokban a memóriavezérlők mellett. De ez nem baj, mert különböző aspektusokat ábrázolnak és a szövegből ki lehet hámozni a lényeget."
OK, az ábrák nem pontosak, de őszintén szólva a Whitepaperen se könnyű elmenni.
"Az azt akarja szimbolizálni, hogy a ROP-ok bármely memória partícióba írhatnak egy crossbaron keresztül. És ahhoz a csíkhoz kapcsolódnak az egyéb részek egy hubon keresztül, azok se az L2-be dolgoznak, hanem a memóriába."
Ja, de van egy global data share is az L2-vel 
Ezen a ponton egyre inkább úgy látom, hogy túl kevés a pontos, konkrét információ a hivatalos leírásban. Számomra mindenképp. Vagy egyszerűen a felkészültségem nincs meg az értelmezésükhöz. Asszem, kár volt belekotyognom, elnézést. 
[ Szerkesztve ]

















 jó lenne, ha az intelt árversenyre kényszerítené valaki, jelenleg ő diktál és ez a vevőknek rossz, hatalmas fejlesztésre is azért nincsenek rákényszerítve, mert nincs rá okuk
jó lenne, ha az intelt árversenyre kényszerítené valaki, jelenleg ő diktál és ez a vevőknek rossz, hatalmas fejlesztésre is azért nincsenek rákényszerítve, mert nincs rá okuk





 lesz olyan is??
lesz olyan is?? 
![;]](http://cdn.rios.hu/dl/s/v1.gif)















