Bevezető, fájltípusok, adatbázisok
Mindenki, aki 5 percnél többet ücsörgött már a számítógépe, vagy a kedvenc konzol előtt, bizonyára látta, hogy a mostani modern rendszereket, vagy a rajtuk futó alkalmazásokat nem mindig a leghibátlanabb verzióban hozzák ki. Ám ha még minden figyelmünket megfeszítve sikerül is szinte tökéletes szoftvert alkotni, akkor is előfordul, hogy egy tőlünk független tényező miatt valamiért változtatni kell a kódsoron. Ugyanakkor ha balul sül el egy-egy javítás, nem szeretnénk a milliós projektből egycsapásra hulladékot generálni, így célszerű felvenni a teendőink közé egy online és egy offline verziókövetést is.

A végállomás... Mikor nem tudjuk mit is csináltunk, azt is rosszul.
Ahogy a projekt egyre nagyobb lesz és szépül, fejlődik, úgy lehet szükséges az is, hogy bevonjunk valaki külső személyt is. Mivel manapság senki sem fejleszt jórészt egyedül szoftvert, így a megosztott munka mellett szinte képtelenség lenne követni, hogy ki az aki éppen hónapok óta nem csinál semmit, vagy azt is rosszul csinálja, amit csinál, esetleg ki az, akit jutalmazni illene, mert maga az egyszemélyes csapatmunka.
Munkánk megkönnyítéséhez tehát szükségünk lesz a változásokat követő rendszerre. Ám ne szaladjunk ennyire a probléma közepébe, ugyanis nagyon nem mindegy nekünk, hogy milyen információtartalommal bír a munkánk jelentős része. Előbb vegyük át alapjaitól, hogyan is kategorizáljunk!
Fájltípusok, adatbázisok
Alapvetően, amikor valaki elkezd programozást tanulni, akkor megtanítják, hogy 3 féle fájl fordulhat elő egy gépen:
Hirdetés
a, szöveges fájlok, ebből épül fel a forráskódunk jó nagy része.
b, típusos fájlok: ezek binárisok, de olyan binárisok, aminek a teljes szerkezetében egyetlen adat fajta szerepel. Például ilyenek bizonyos adatbázisok
c, típus nélküli fájlok: na ez az, ami bináris, de fogalmunk nincs mi van benne, mert úgy ahogy van: minden.
Ahogy ezt beírtuk az első és utolsó dolgozatba: gyorsan verjük ki a fejünkből örökre. Ugyanis túlhaladta a technika azt a szintet, hogy a szöveges fájl minden karaktere 8 byte és egyetlen EOF jel sincs benne. Ez már csak egy múló emlék. Jöttek-mentek a szabványok, kezdve az UTF8-cal és sehol véget nem érve.
Minden fájlunk bináris, az is, ami szöveges! Nem a tartalma a fontos, hanem hogy a feldolgozó algoritmusunk mit hoz vissza abból a tartalomból.
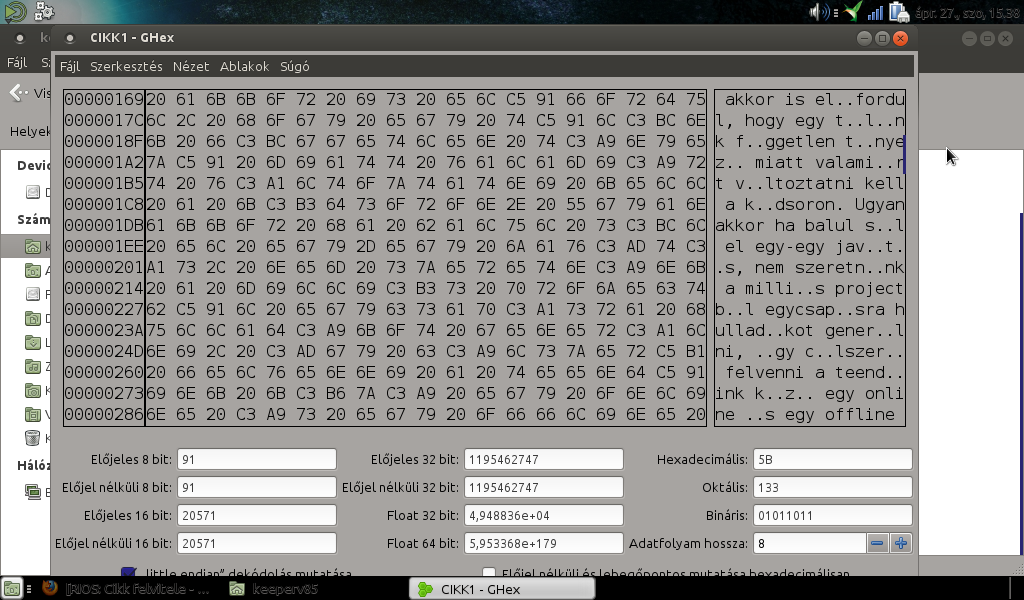
A cikk eddig a "valódi" formájában. Így kicsit nehéz lenne elolvasni...
Hogy miért térünk ki a feldolgozásra? Azért, mert ha valamit figyelni szeretnénk, akkor szükség van rá, hogy pontosan tudjuk annak a tartalmát és ezzel el is jutunk oda, hogy a fenti csoportosításnak miért volt létjogosultsága.
A szöveges fájlok offline követése
Ha egy fájlból kettő eltérő van, az máris felveti azt a kérdést, hogy: "Jó, de melyik az a rész, ami változott?"
Aki Windows alatt szocializálódott, az látta már biztos, hogy a Total Commander ezt nagyon ügyesen megoldja egy kis eszközzel. Ám a gondok akkor kezdődnek, mikor több 100 fájlunk van ugyan abból, de mi nem szeretnénk folyamatosan újra és újra eltenni minden egyes változást. Nekünk csak a változtatott részek kellenek, hogy meg tudjuk nézni mit javított az újonnan felvett kolléga. (Nem-e éppen vírust ír nekünk...).
Szokjunk át a Linuxra, ugyanis egyrészt a programozás itt sokkal könnyebb, másrészt itt már gondoltak 10 évvel ezelőtt is ilyesmire!
Keressük meg a Terminálunk, higgyünk benne, hogy jó barátunk lesz, nem kell tőle félni! Adjuk ki a következő parancsot!
$ sudo apt-get install meld
Adjuk meg a jelszavunk, amit nem láthatunk még mi sem, majd ismételt enter után feltelepül nekünk egy elég okos kis szoftver, a Meld.

...avagy mégsem. Nálam ugyanis már megvolt. :)
Indítsuk el a "meld" paranccsal, majd nyomjuk le a Ctrl+N-t vagy válasszuk a "Fájl" >> "Új" menüpontot.
A következő ablak fogad bennünket:

Elég lehetetlen a magyar fordítás az eredeti és a saját párossal...
A két "Tallózás" gombunkkal keressük meg a két összevetésre szánt fájlunk, majd hagyjuk hadd dolgozzon a program.
Tipp:
Megússzuk ezt a procedúrát, ha tudjuk, hogy a meld paramétereket is kezel! Adjuk ki a:
$ meld fájl1 fájl2
...parancsot, és azonnal összeveti nekünk a kért tartalmakat.
Jobbra és balra láthatjuk az előző és következő állapotunk. Így már megfigyelhetjük mit is alkotott, aki legutóbb a fájlba nyúlt!
Mentsük el a változások listáját a "Fájl" >> "Formázás foltként" opcióval. Itt figyeljük meg, hogy melyik az amiből megyünk a másikba, nehogy visszafelé süljön el a dolog. Meg is tudjuk fordítani a fenti kis opcióval!

Kis monitor, kis hely. Persze hogy nem fér el a lényeges tartalom...
Ezzel elő is állítottunk egy lényegesen kisebb patch fájlt, mint az előzőleg egyben lévő fájlunk. Mihez kezdhetünk vele?
Egyrészt böngészhetjük, hogy mit is alkottak előttünk, másrészt ha csak ezt a fájlt adjuk oda valakinek és az eredeti kódunk, akkor is fel tudja azt javítani pillanatok alatt oda, ahol a nálunk megtalálható verzió tart.
Próbáljuk csak meg! Legyen most az eredeti fájlunk a.txt, a módosított b.txt, a patch fájlunk pedig c.patch
A b.txt fájlt szeretnénk mi megcsinálni, de csak az a.txt és javítás van meg. Irány a Terminal:
$ patch a.txt < c.patch
Látszólag semmi sem történt. Ajaj... Ám nézzük csak meg az a.txt fájlunk! Máris felvette a b.txt változásait egy pillanat alatt!
Jegyezzük meg ezt a megoldást, ugyanis egy több 10 ezer soros fájlnál igencsak jól tud jönni. ráadásul gyakran kaphatunk ilyen patcheket majdani munkahelyünkön, így már tudjuk mire való.
Bináris fájlok
Sajnos a jó életnek máris vége abban a pillanatban, ahogyan egy készre konvertált állományunk van csak. Nem csak azért, mert a bináris kódot Neo tudja csak elolvasni, hanem azért is, mert ezek piszok nagyok is lehetnek.
Lássunk egy egyszerű példát, ami pl. a játékfordítók rémálma: kész a mű, tele van idegen nyelvű videóval. Valahogy rá kéne tenni egy feliratot, de az eredeti programozó erre nem készítette fel. Megkeressük azt a szoftvert, ami fel tudja dolgozni a videóink, majd azt is, amivel bele tudjuk sütni a szöveget... és itt jön a pofára esés: egy videó is több 100 MB. Ha javítani kell benne valamit később, ezt fel-le tölteni egy szerverről sem túl nyerő dolog. Főleg, ha több 10 ezres letöltésre lehet számítani. Ha történetesen a játék a miénk, akkor sem szeretnénk a szerencsétlen userre rávágni több 10 GB letöltést a saját hibáink miatt, a videónak pedig nincsen forráskódja, azt nem lehet darabokban kiadni újra, hogy rakja össze magának.
Mit tehetünk?
Nálunk okosabb emberek kitalálták, hogy két fájlt binárisan is össze lehet vetni, majd a belőlük képzett különbségeket elmentve lényegesen kevesebb helyet foglal a folt, mint a teljes állomány. Nagyjából arról van szó, hogy bitenként végigjárja a fájlunk a program, ahol pedig változás van, azt elmenti. Valójában ennél sokkal komplexebb rekurzív függvényekkel dolgozik, de ezt nekünk nem kell ismernünk.
A Linux alatt két csomag van telepítve a bináris patchek feldolgozása mellé: a bsdiff és bspatch.
Tegyük fel, hogy van tehát két videónk: egyikbe belesütöttük a feliratot. Menjünk most a Terminal-ba, majd adjuk ki a:
$ bsdiff video1 video2 video.p
..parancsot. Ha "ügyesek" voltunk, akkor az égvilágon semmit sem értünk el mert totál más kódolást választottunk a második videó mellé, így nem lesz egyezés. Ám, ha a két videó között, csak a feliratozott képek változtak, akkor most egy pár MB nagyságú fájlt kaptunk.
Mihez kezdhetünk vele? Nos, elküldhetjük a felhasználóknak, egy kis csomag kíséretében, ami a következőt tartalmazza majd:
#!/sbin/sh
bspatch video1 video2 video.p
exit 1
Mentsük is le RunMe!.sh néven a patch mellé és máris kész a normál méretű javítás. Persze írhatunk mellé sokkal komolyabb programot is, illetve máris megismerhetjük a bspatch modernebb verzióját, amit az Android rendszer OTA frissítései használnak főként.
A kis csomag apply_patch névre hallgat és ott lapul az összes Androidos készülékben, illetve a bináris x86 verziót letölthetitek itt is: Letöltés
A használata a következőképpen zajlik:
$ chmod +x applypatch_static
$ ./applypatch_static forrásfájl újfájl újfájl sha1 kulcsa újfájl mérete byte-ban
forrás sha kulcsa:path fájl
(Végig sordobás nélkül, ahogy ide sajnos nem fér el...)
Ez így elsőre elég meredek. Főként azért, mert az SHA kulcsokat nem tudjuk, főként nem azt a fájlt, amit most szeretnénk megkapni. Ám aggodalomra semmi ok, hisz mi adjuk a frissítést most vagy úgy kapjuk, hogy megkapjuk mellé az értékeket is.

Akasztják a hóhért... már nézni is rossz, de higgyük el, nagyon hasznos kis program!
Erre a fajta ellenőrzésre azért volt fokozottan szükség, mert garantálja mindkét (ki és bemeneti) fájl sértetlenségét az SHA1 kulcsok által.
Tipp:
Az SHA1 (Secure Hash Algorithm Version 1) kulcsokat mi is könnyen ellenőrizhetjük a Terminalban. Csak adjuk ki az:
$ openssl sha1 fájlunkneve
...parancsot. Máris láthatjuk a kimenetben a várt számsort, vagy éppen azt, hogy nem sikerült a művelet.
Online verziókövetés, röviden a Github-ról
Az eddig látottak persze mit sem érnek, ha a világ másik felében van a csapat maradék tagja és nincs lehetőség velük kapcsolatot tartani, vagy az elég drága lenne. Itt lépnek be a képbe az online verziókövető rendszerek, melyek közül talán a github.com az egyik legismertebb, ha nem a legismertebb éppen. Megemlíteném még a bitbucket.org-ot is, mint jó alternatívát.
Miután regisztráltuk magunkat és beállítottuk a profilunk, aminek az örömeitől most megkímélem az olvasókat, a következő felület fogad minket:

Nem a szép arcomat kell nézni, az csak mellékes adalék. :D
Kattintsuk át a fenti "Repositories" fülre, majd jobbra a "New" gombra. Itt online beállíthatjuk miről is írtuk a programunk. Illetve jogokat adhatunk rá, megadhatjuk milyen programnyelvet használunk majd főként. Lássuk ezeket sorban:
Repository name -- Tetszőleges név, különleges karakter és szóköz nem lehet benne
Description -- Ez egy leírás, nem kötelező
Public vagy Private -- Egyértelmű. Láthatja bárki, vagy csak akit mi jóváhagyunk. Sajnos a Privát funkció már fizetős lett.
Initialize this repository with a README -- ezt inkább hagyjuk békén, mert nem szeret működni. Amúgy csak egy Readme-t generál nekünk, amit megcsinálhatunk kézzel is helyette.
Végül alul az újabb zöld gomb, csak a kattintásra vár!
Majd megkapjuk a Terminálhoz a parancsokat, amikre alapvetően szükségünk... lenne:
$ touch README.md
$ git init
$ git add README.md
$ git commit -m "first commit"
$ git remote add origin https://github.com/Keeperv85/proba.git
$ git push -u origin master
Én a következőt javaslom...
$ git init
$ git add *
$ git commit -m "Init"
$ git remote add origin https://github.com/Keeperv85/proba.git
$ git push -u origin master
Nézzük sorban mit is csináltunk!
git init -- Letölti a szükséges git kezelő rutinokat, többet nem kell vele foglalkoznunk
git add * -- Hozzáadja az összes már bepakolt forrásunk az előzőleg letöltött tartalomhoz
git commit -m "Init" -- Létrehoz egy commit ágat, innen tudjuk majd később mi és mások is, mit is akartunk éppen frissíteni
git remote add origin https://github.com/Keeperv85/proba.git -- Ez csak első alkalommal kell. Beállítja a git bizonyos paramétereit: az origin ágba dolgozunk a master branch alá. Akkor fontos, ha többféle repo-ban is használjuk ugyan azt a kódot. (Ne az enyém adjátok meg! :D)
git push -u origin master -- Feltöltjük a munkánk gyümölcsét. Azaz feltöltenénk. Adjuk meg a felhasználónevünk és a jelszavunk, amit a regisztráció alatt használtunk. Máris mennie kell.

Első sikeres próbálkozás...
Mint láthatjuk megjelent az új repo-nk a listában. Ha rákattintunk és elmegyünk a commit fülre, ott van az "init" águnk is.
Most pedig lássuk mi történik, ha módosítjuk valamelyik fájlunk. Nos. Persze. Semmi. Mert könyvelnünk kell...
$ git status
Láthatjuk, hogy módosításra váró tartalmaink vannak commit nélkül. Ha friss git verziónk van, akkor szép pirosak...

Nincsenek hozzáadva a fájlok, nincs feltöltés...
$ git add *
..máris megnézhetjük az előbbi (git status) paranccsal, hogy hozzáadtunk-e mindent.
$ git commit -m "first patch"
Megmondjuk miért turkálunk...
$ git push
Feltöltjük a javítást. Megint kérheti az adatokat... és...
Ha most meglátogatjuk az előbbi commit fület és a javításunkra kattintunk, akkor valami ilyesmit látunk:

Az online felület mutatja mit piszkált valaki.
Sajnos bináris megoldást még nem dolgoztak ki az érthető technikai okok miatt, ám erre valószínű nem is lenne túl nagy szükség.
Végszó
Mint azt láthatjátok a programozás nem csak a kódok megírásából áll, hanem azok dokumentálásából és javításából is. Ez a cikk a helyi és emberi korlátok miatt, nyilván nem kíván teljes mélységében mindent bemutatni, csupán kedvet és alternatívát kíván nyújtani egy-egy probléma megoldásához. Mikor a szakdolgozatom írtam, nekem sajnos nem volt olyan szerencsém, hogy ismerjem ezeket a lehetőségeket, így a 200 oldalas forráskódot fájlonként mentettem el minden módosítása előtt. Képzelhetitek, mi lett a több hónapos munka végére a vége. Igazi rémálom volt összerakni. Hogy megérte-e? Ha csak magamnak akartam volna bizonyítani: akkor igen. Amúgy: egyáltalán nem, de ez egy másik történet már...
Jó kódolást kocka társaim!
Sziasztok!




