
Kapcsolódó cikkek (szükséges lehet a cikk megértéséhez):
Harmadik dimenzió
Kapcsolódó leírások (szükséges lehet a cikk megértéséhez):
Architektúra fogalomtár / Processzor fogalomtár / Memória fogalomtár / Grafikus fogalomtár
Sokat halottunk már a Direct3D 10-ről annak képességeiről és előnyeiről. A legtöbb felhasználó azonban nem ismeri el új grafikus API-ként, átverésnek tartják, amivel a Microsoft az igencsak harmatosra sikerült Vista operációs rendszerét próbálja eladni. Első blikkre tényleg lehúzás szaga van a dolognak, jobban utánajárva azonban a D3D10 API soha nem látott újításokat tartalmaz.
Windows Display Driver Model (WDDM)
A Windows Vista színrelépésével megváltozott az eddig alkalmazott Driver Model. A legfontosabb szempont a stabilitás és a teljesítmény növelése. Az új sablon két részre osztja a meghajtót: User-Mode Driver és Kernel-Mode Driver.

A Display Driver a régebbi Windows operációs rendszerekhez hasonlóan továbbra is kernel módban fut, viszont a meghajtó többi része kikerült a felhasználói rétegbe. Ezzel jelentősen nőtt a stabilitás hiszen egy esetleges meghajtó hiba nem vezet rögtön rendszerösszeomláshoz. A DXG kernel modul további finomságokat is tartalmaz. A GPU ütemező lehetővé teszi, hogy az éppen futó folyamat (process) gyakorlatilag szálként (thread) legyen lekezelve. Ennek következtében egyszerre több olyan alkalmazás is futtatható a rendszeren ami igénybe veszi a GPU képességeit. A Videó memória manager segítségével pedig lehetőség nyílik a Videó memória virtualizálására úgy, hogy a fizikai memóriában tároljuk el a lapot. Ez a megoldás a rendszer teljesítményét hivatott növelni, hiszen eddig erre a célra a merevlemezen tárolt virtuális memóriát használtuk fel.
Maga a WDDM nem része ugyan a D3D10-nek, de rendkívül szorosan kapcsolódik hozzá. Gyakorlatilag egymást egészítik ki. Ebből már látszik, hogy az új API portolása korábbi Windows rendszerekhez meglehetősen problémás lenne. Elméleti alapokon természetesen kivitelezhető a dolog, de rengeteg olyan újítást elveszítene ami teljessé teszi az interfészt.
A Direct3D 9 problémái
A Direct3D 9.0 2002 decembere óta hódít. Hosszú életének titka, hogy a Shader Modell szabványok tulajdonságait igén tág korlátok közé sikerült rögzíteni. Voltak azonban komoly hibái a rendszernek amelyek igencsak rányomták a bélyeget a teljesítményre és az alkotói szabadságra. Legnagyobb probléma a CPU és a GPU közötti adatátvitelből adódó késleltetés. Ez erősen korlátozza az egy képkockán megjeleníthető objektumok számát, mivel a rendszer egy bizonyos szint felett komoly CPU limitbe fut. Minden objektum megrajzolásához szükséges egy rajzolási parancs az API-n belül. Ez a parancs a D3D9 működésében mindig egy fix késleltetést eredményezett ami alatt az API a display driver-rel kielemezte, hogy hogyan kell végrehajtani a parancsot az adott hardveren.

(nagyítható)
Hasonlóan lehangoló a helyzet az effektek létrehozásánál is. Ezek ugyanis az API-n belül rengeteg állapotváltást eredményeznek. A fejlesztőknek sajnos a minél szebb és részletgazdagabb látvány helyett inkább arra kellett törekedni, hogy a lehető legritkábban fussanak CPU limitbe. Tovább nehezítette a programozók dolgát, hogy a GPU gyártók esetenként különböző képességeknek feleltették meg a rendszereiket (ezeket hívjuk Vendor Specific Caps biteknek), így a programozóknak több specifikus kódot is szükséges írni a tökéletes működéshez. Arról nem is beszélve, hogy a D3D9 futószalagja úgy volt kialakítva, hogy több hardver gyártó igényeit kellett egy működő maszlaggá összetákolni. Ez helyenként igencsak kötött lehetőségeket teremtett. Végül a program futása alatt történő erőforrás érvényesítése is elég sok időt vett el a CPU-tól. Az érvényesítésre azért volt szükség, mert a különböző GPU képességek miatt, nem lehetett előre tudni, hogy a lefuttatásra kerülő parancs formailag megfelel-e a hardver problémamentes működéséhez.
A Direct3D 10 megoldásai
Kulcsfontosságú volt a D3D10 tervezésekor a Microsoft stratégiája. Az API fejlesztésében, a saját csoportjukon kívül maguk a 3D-s programfejlesztők és a GPU gyártók is aktívan részt vehettek. A D3D10 legfontosabb fejlesztési szempontja, hogy az alapoktól újraépítették a rendszert megfeleltetve azt a kor követelményeinek. Első lépésként eltörölték a visszafele való kompatibilitást. Az új API csak D3D10-es GPU-kat támogat. Ez jelentősen leegyszerűsíti a GPU vezérlését és platform közeli programozhatóságát. Teljesítmény növeléséhez az elsődleges szempont az API késleltetések időigényének jelentős csökkentése. Ennek megfelelően több kritikus ponton is átdolgozták a rendszert ezáltal a CPU használat nagymértékben csökkent. Ezt három új eljárással sikerült elérni: Texture Array, Predicated Draw, Stream Out.
A Texture Array lehetőséget ad a GPU-nak egy 512 textúrából álló tömb egyszerre történő feldolgozására. Ez lehetővé teszi a Multi-textúrázást a CPU használata nélkül.
A Predicated Draw nagyon fontos szerepet tölt be, hiszen ez az eljárás jelzi, hogy melyik objektum van más objektum által takarásban a feldolgozandó képen. Amennyiben az eltakart objektum nem látszik felesleges erőforrás pazarolni rá. A D3D9-ben hasonló megoldás található Occlusion Query néven azzal a különbséggel, hogy a régebbi API-ban a CPU és a GPU közösen munkálkodott a feladaton, míg a D3D10-ben teljesen a GPU-ra terhelődik a munka. Az eljárás úgy működik, hogy a rajzolás előtt a komplex objektumok helyett először olyan tégla alakú dobozok lesznek elhelyezve amelyek az objektum adatait hordozzák. A Z tesztek lefuttatása után azon objektumok nem lesznek megrajzolva, amelyek nem fognak látszani a végső képkockán.
A Stream Out segítségével a fejlesztő képes kimenteni a vertex és geometria adatokat a memóriába (Stream Output) még a raszterizálás előtt. A D3D9-nél végig kellett menni a logikai futószalagon, mert csak a Pixel Shader egység írhatott a memóriába.
Az erőforrás érvényesítése is megváltozott. Az új API-ban elég a program futtatásának megkezdésénél egyszer megtenni az érvényesítést, mert a D3D10 kompatibilis GPU biztos, hogy képes az összes szabványban leírt eljárást kezelni. Szemléltetésképpen az alábbi ábra jelzi, hogy mennyivel kevesebb idő szükséges a program utasításainak végrehajtásához a D3D10-ben.
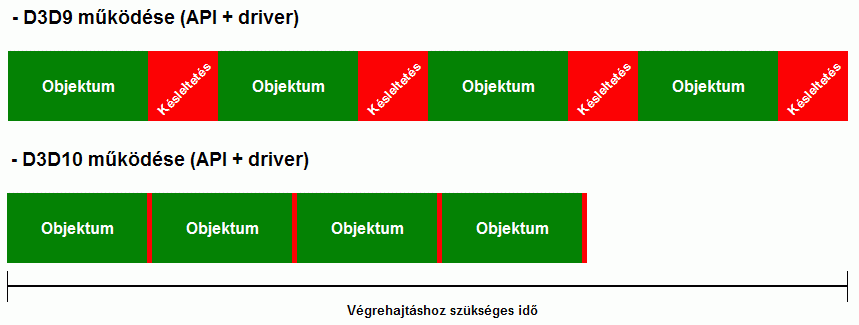
(nagyítható)
További újítások
Nem túl nagy meglepetés, hogy új Shader Modell szabványt köszönthetünk 4.0 jelzéssel. Annál nagyobb dolog azonban, hogy az eddig is igen magasra tett lécet sikerült tovább emelni. A sablon felépítése erősen elpártolt a diszkrét Shader egységekből álló architektúrák támogatása mellől. Ez a lépés nem váratlan, hiszen elég sokszor lehet olyan eseteket találni a 3D-s programokban, ahol a vertex vagy a pixel feldolgozás szűkös kapacitása hátráltatja a képkocka számítását.

A képen látható két merőben eltérő eset szemlélteti, hogy bizonyos képkockák számítása esetén meglehetősen eltér a GPU egységeinek a terhelése. Erős Vertex Shader terhelés esetén a Pixel Shader egységek egyszerűen munka nélkül maradnak és fordítva. Ezen segít az új Unified Shader felépítés.

Eme sablon mellett nincsenek fix funkciókkal bíró Shader processzorok. Rengeteg általános feldolgozó van, amelyek egyenletesen osztják el egymás közt a munkát.
A Shader Modell 4.0 az előző verzióhoz képest, még jobban kiterjeszti az eddigi programozhatósági lehetőségeket. Egyszerűen fogalmazva többet kapunk mindenből. Természetesen az a cél, hogy a fejlesztők minél komplexebb programokat hozhassanak létre.

(nagyítható)
Észrevehető, hogy az általános regisztereknél viszonylag nagyot ugrottunk előre. Valójában a 4096-os érték indexelt regiszterkészletnek tekinthető, tehát fizikailag a hardvernek nem kell ennyi általános regisztert tartalmaznia, ott továbbra is elég a 32 darab.
Input Assembler
Az Input Assembler a D3D logikai futószalagjának első állomása. Itt lépnek be a feldolgozáshoz szükséges adatok. Jelentős újítás a D3D9-hez képpest az Instancing 2.0 támogatás. Ez a technika arra jó, hogy a Shader futószalag bármely pontján képes a rendszer, bármilyen eddig betöltött objektumot lemásolni és ismét kirajzolni egyetlen utasítással. Ez a tulajdonság már az előző generációs API-ban is benne volt, de ott az objektum kirajzolását módosítás nélkül lehetett csak végrehajtani. A D3D10-ben módosíthatók a lemásolt objektum tulajdonságai (eltérő textúrák, shaderek használhatók).


(nagyítható képek)
Shader futószalag

Ahogy az a képen látható új Shader típussal találkozunk az D3D10 API-ban. A Geometry Shader geometriai alakzatokkal, azaz több vertexszel képes egyszerre dolgozni. Az alkalmazott kódtól függően másolni, nagyítani, kicsinyíteni tudja őket. Ezenkívül további primitíveket hozhat létre, illetve törölhet vertexeket. A több vertexszel való munka lehetőséget teremt arra, hogy megvizsgálja a rendszer azt, hogy a szomszédos vertexek milyen helyzetben vannak egymáshoz viszonyítva. Ez a képesség olyan algoritmusok létrehozására ad lehetőséget amivel realisztikus felületi hatások érhetők el, továbbá a Stream Output használatával rendkívül egyedi részecske effektek hozhatók létre.
Output Merger
Az API logikai futószalagjának utolsó eleme. A Shader Modell 4.0 alapján mostantól 8 Render Target van támogatva. Ez lehetővé teszi, hogy több Pixel szín értéket csoportosítsunk különböző felületekhez. Ennek köszönhetően sokkal komplexebb Pixel Shader programok kreálhatók.
Tulajdonképpen röviden ezek lennének az API újításai. Úgy gondolom, hogy a szabvány átalakítása minden ponton előnyére válik a fejlesztőnek. Szomorú azonban, hogy többen is visszaélnek a DX10 marketinghatásával. Rengeteg 3D-s program (főleg játék) jelenik meg reklámozva az új API-t, holott gyakorlatilag köze sincs hozzá. Neveket nem szívesen említek mivel cikkünk nem teljesen ezzel foglalkozik, de jelenleg mindenképp negatívan állítják be a DX10 újításait az események.
Vizsgálódások
Természetesen most sem marad el az utóbbi időben megjelent architektúrák elemzése. Korábbi cikkünkhöz hasonlóan főleg felépítés vizsgálata lesz a téma így a GPU-kat kódnevük szerint nevezem, de leírom, hogy melyik kártyán kaptak helyet a chipek.
Első generáció
NVIDIA G80 (Shader Modell 4.0)
2006 végén debütált az első DX10-es Nvidia chip. A dátum azért kiemelten fontos, mert bő fél évvel megelőzte a Vista megjelenését, és ezzel az új API kiadásának időpontját. A G80 kódnevű produktum GeForce 8800GTX-en kapott helyett (persze voltak kisebb testvérek is GTS névvel, sőt Ultra jelzéssel még egy bratyó is született).
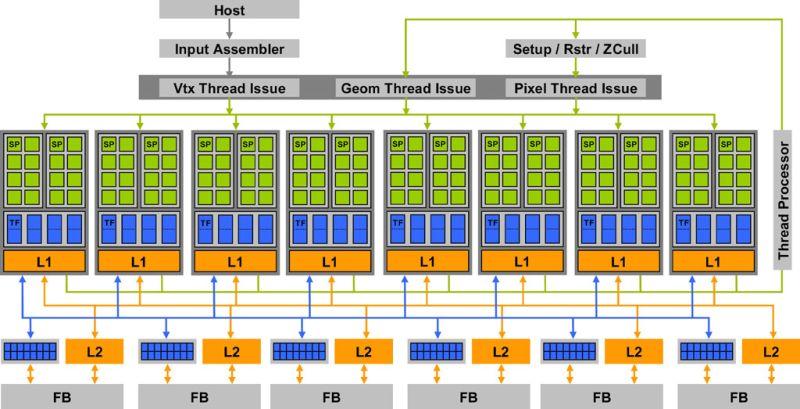
(nagyítható)
Amint a képen is látható Unified Shader architektúra tárul elénk. A rendszer legfontosabb alkotóeleme a Texture Processor Cluster (TPC), melyből 8 darab került a chipbe. Ezek a komplex egységek végzik a számítást. A működtetésükön egy globális ütemező dolgozik.

Egy TPC tartalmaz egy textúrázó blokk-ot és két Streaming Shader Processzort. Fontos, hogy a Shader Processzorok nem a GPU órajelén dolgoznak, hanem az úgynevezett Shader órajelen, emellett a TPC-n belüli szálvezérlésről is ők gondoskodnak. A Shader processzoron belül 8 darab általános Stream processzort találunk, amelyek logikailag négyes csoportokra vannak osztva. Ezen csoportokhoz tartozik egy-egy Speciális Funkció Egység (SFU). Az efféle felépítés újdonság a GPU-k világában. A régebbi rendszerek főleg vektoros egységeket tartalmaztak. Az új elrendezés alapvetően módosítja a feldolgozás folyamatát is. Az adatok mostantól úgynevezett komponens folyamonként érkeznek feldolgozásra. Az elnevezés egy kicsit ijesztően hangzik, de nézzük meg a gyakorlatban, hogy miről is van szó. Példaként most elemezzünk két rendszert pixel számítás alapján (vertex esetén is hasonló a működés). Tudjuk, hogy egy pixel 4 elemből áll (piros, zöld, kék, átlátszóság), ezen elemek értékei alapján kapjuk meg a végső pixel színét. A G70, az architektúrája szerint 4 pixelt számol egy futószalagon. Ez összesen 16 elemet jelent (4 pixel és pixelenként 4 elem). A G80 ezzel szemben 16 pixelnek egy elemét számolja egyszerre egy TPC futószalagon (lehet ez akár piros, zöld, kék vagy átlátszóság). Az elméletet terjesszük ki 16 pixelre. A G70-nek ezen feladat számításához egy futószalagon 4 ciklusra lesz szüksége (minden ciklusban számolunk 4 pixelt, azaz összesen 64 elemet). A G80-nak egy TPC blokk-on szintén négy ciklusra van szüksége, mivel négyszer számolja 16 pixel egy elemét (összesen 64 elem). Első ránézésre nincs különbség a két architektúra közt, de ne kapkodjuk el a dolgokat. A valóságban igen sokszor előfordulnak olyan Pixel Shader kódok ahol nincs szükség a számításhoz mind a négy komponensre. Ilyen esetben a G70-nek mindenképp szükséges a 4 ciklus lefuttatása, mivel a Shader egység különböző komponenseket számol. Abban az esetben, amikor az átlátszóság információi nem szükségesek, a Shader egység elméleti teljesítménye kihasználatlan marad. A G80 esetében egészen más a helyzet. Például ha nincs szükség az átlátszóság információira, akkor a negyedik ciklus egyszerűen nem fut le. Eredmény szempontjából ugyanott van a két feldolgozási elv, viszont a G80 három pixel elem számításánál mintegy 25%-al hatékonyabb. Minél kevesebb pixel elemre futtatjuk a Shader kódot, annál kevesebb ciklus fut le a G80-on.
A Stream processzorok saját regiszter területtel rendelkeznek, és a MAD, ADD, MUL számláló utasításokat támogatják FP32-es precizitással. Az egységek egy órajel alatt az adaton egy MAD, és annak eredményén egy MUL utasítást is végre tudnak hajtani (A MUL-t a Speciális Funkció Egység segítségével végzik úgynevezett Dual-Issue módban. Ennek előnyeit sajnos ritkán lehet kihasználni ütemezési problémák végett). A Speciális Funkció Egységek trigonometrikus és transzcendens (EXP, LOG, RCP, RSQ, SIN, COS) utasításokat támogatják, viszont egy utasítást négy ciklus alatt hajtanak végre. A feldolgozás sebességének eltérése miatt előfordulhat, hogy üres ciklust futnak a Stream processzorok, amíg a speciális utasítás eredménye nem érkezik meg.

(nagyítható)
A TPC-ben elhelyezkedő textúrázó blokk egyenként 4 darab textúra címző egységet tartalmaz. Minden textúra címzőhöz 2 darab bilineáris textúra szűrő, és 1 darab textúra mintavételező kapcsolódik. A textúra címző és a textúra szűrő egységek arányát a teljesítményvesztés nélküli trilineáris szűrés miatt alakították így, mivel az ilyen szűrés alkalmazásához két bilineáris minta szükséges.
A ROP egységek esetén is változott a felépítés az előző generációhoz képest. A G80 6 darab ROP blokk-ot tartalmaz, és minden egyes blokk 4 Blending egységet tudhat magáénak. Jelentős fejlődésen eset át a Z mintavételező is, mivel órajelenként már 8 mintát dolgoznak fel.
Minden ROP blokk 64bit-es csatornával kapcsolódik a VGA memóriájához. Ez 384bit-es Crossbar vezérlést eredményez.
A G70 architektúra komoly problémáját, a Dynamic Branching hatékonyságának alacsony hatásfoka, a G80-ban kijavították. A Pixel feladatkiosztó 32-es batch méretet használ, ami elég jónak nevezhető. Vertex feladatkiosztó viszont 16-os batch-ekre futtatja a Shader kódot, ami azonban esetenként nem lapolja át a memória elérésnél bekövetkező késleltetést.
AMD-ATi R600 (Shader Modell 4.0)
Az előző generációs Ati termék óta a kanadaiakkal sok minden történt. A legfontosabb esemény, hogy a céget az AMD felvásárolta. Az akvizíció okát most nem kívánom részletezni, de igencsak érdekes dolgok készülnek az AMD konyhájában. Az Ati-nak is jót tett a felvásárlás, mivel az AMD segítsége nélkül talán nem fejezték volna be időben az új R600 kódnevű chipet, amely a Radeon HD2900 alapjául szolgált. A kártya 2007 májusában került piacra, nagyjából egy időben a Vista megjelenésével.
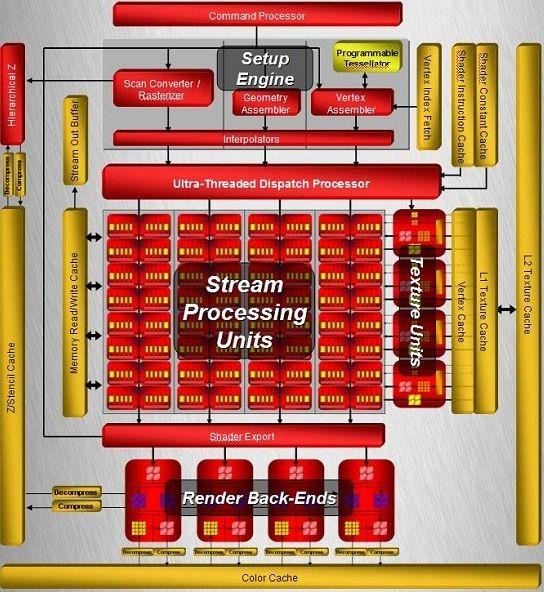
(nagyítható)
A kiindulási alap a Microsoft Xbox360 nevű konzoljába fejlesztett radikálisan új elvekre épülő Xenos GPU volt. Az architektúra legfontosabb része az Ultra-Threading Dispatch Processzor. Ez vezérli és látja el feladattokkal az R600-ban megbúvó 4 darab feladat-végrehajtó Shader tömböt. Minden ilyen tömbben 16 darab szuperskalár shader processzor foglal helyet. Ezeken lesznek lefuttatva a feldolgozásra beérkező szálak. Minden szál először a megfelelő besoroló egységbe jut, attól függően, hogy az vertex, geometry vagy pixel shaderre vonatkozik a folyamat. A vertex három, a geometry kettő, míg a pixel besoroló egység négy szálat tud tárolni. Ezek egyikét a megfelelő időben, azaz valamelyik szuperskalár shader processzor felszabadulásakor lefuttatja. Egy Shader tömb működését két Arbiter és két Sequencer egység biztosítja. Az Arbiter gondoskodik a feldolgozás alatt lévő, vagy éppen feldolgozásra váró szálak irányításáról, míg a Sequencer a futtatási sorrendet állítja fel. Hasonlóan az előző generációs Ati chiphez az elérési idő átlapolásáról most is a Dispatch processzor gondoskodik. Amikor textúra vagy adat fetch-re kerül sor az Arbiter-hez irányul a kérés, ekkor az aktuális állapotot elmentve felszabadul a szuperskalár shader processzor, és más feladatok számolását lehetett rábízni. Amint megérkezett a korábbi művelethez szükséges adat az Arbiter visszaállítja az előbb felfüggesztett állapotot, és folytatódhat tovább a munka.

(nagyítható)
A szuperskalár shader processzorban, 4 darab skalár és 1 darab speciális végrehajtó egység van. A skalár shader processzorok a MAD, ADD, MUL számláló utasításokat támogatják FP32-es precizitással, míg a speciális végrehajtó egységeknél a MAD, ADD, MUL instrukciókon kívül a trigonometrikus és transzcendens (EXP, LOG, RCP, RSQ, SIN, COS) utasítások is futtathatók. A rendszer 1+1+1+1+1 co-issue képességű, aminek köszönhetően egy órajel alatt öt egymástól nem függő utasítást képes végrehajtani. Ez a feldolgozási elv jelentősen különbözik a G80 Streaming Shader Processzoraitól, hiszen az Nvidia rendszere SIMD utasítás folyamokat dolgoz fel, ami alapból garantálja, hogy nem alakulhat ki függőség. Az R600-nál a futtatásra kerülő shader kódokban lévő függőségek kezelését a driver fordítója végzi. A meghajtó az egymás után következő utasításokból optimalizált végrehajtási sorrend felállítása után hosszú és komplex, főleg 5 matematikai és 1 vezérlő utasításból álló VLIW mintákat hoz létre. Ezen utasításszavakkal történik szuperskalár shader processzorok táplálása. Azonnal észrevehető, hogy a hardver már eleve nagymértékben párhuzamos munkavégzésre optimalizált kódot dolgoz fel, így a chip működésének hatékonysága főleg a driver fordítómodulját író rendszerprogramozóktól függ. Az ütemezés tulajdonképpen a VLIW minták generálásával statikusan van megoldva. A hardver pusztán a minták végrehajtásának sorrendjéről dönt. Regiszterkezelésben is eléggé eltér a G80-tól az AMD chipje, itt ugyanis a végrehajtó egységek közös regiszterterülettel rendelkeznek, míg a szuperskalár shader processzorok az ideiglenes adatok tárolására egy nagysebességű 64 KB-os Memory Read/Write Cache-t kaptak. Ehhez a gyorstárhoz kapcsolódik a Stream Out Buffer, ami a stream out műveletek sebességét kívánja meggyorsítani.

Az R600 Shader tömbjeit négy egyenlő részre lehet felosztani. Mindegyik ilyen terület 4 darab szuperskalár shader processzort tartalmaz. Ezekhez kapcsolódik egy-egy Textúrázó blokk. Minden ilyen blokk két textúrázó csatornát tartalmaz egy szűretlen és egy szűrt mintákkal visszatérőt. A szűretlen mintákat kreáló csatorna 4 darab textúra címzőt és 4 darab mintavételezőt tartalmaz, és általában Vertex Texture Fetch-re alkalmazható. A másik csatorna szintén 4 darab textúra címzőt tartalmaz 4 darab textúra szűrővel, viszont 16 darab mintavételező ékelődik közéjük. Hasonló felépítésű volt már az R580 is textúrázás szempontjából. Mivel egy címzőhöz négy mintavételező tartozik, így lehetőség van a Fetch4 nevű eljárás alkalmazására. Amikor a textúra egyik texeljéből mintát veszünk, akkor négy értéket kapunk meg (piros, zöld, kék és az átlátszóság). Azonban előfordulnak olyan esetek is, amikor az adott texelből csak egy értékre van szükség. Ilyenkor a Fetch4 eljárással a mintavételezők képesek az adott texelt környező további három texelből is mintát venni. Ez a technika lényegében növelheti néhány HDR eljárás teljesítményét, illetve egyes szűrések hatékonyságát (Percentage Closer Filtering).
ROP egységek tekintetében 4 darab blokk található a chipben. Minden egyes blokk 4 darab Blending és 8 darab Z-mintavételező egységet tudhat magáénak. Az R520-ban debütáló Ring memóriavezérlő felépítése ugyan egyszerűsödött, de a hatékonysága tovább nőt. Mostantól két-két 256bit-es csatorna gyűrűzik a chip körül, egymással ellentétes irányban. Ez összesen 1024bit-es belső buszszélességet eredményez. A külső memória partíciók összesen 8 darab 64bit-es csatornán kommunikálnak a 4 darab megállóval (Ring stop).
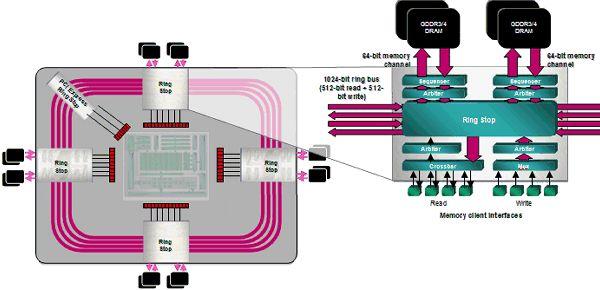
(nagyítható)
Programozható tesszellátor
Az Xbox 360 Xenos grafikus hardverének legnagyobb erőssége a tesszellátor alkalmazása. Alapvetően a Geometry Shader lehetőséget ad tesszellált felület létrehozására, de az eljárás egy speciális célegységgel sokkal gyorsabb lehet.

Az R600-ban lévő tesszellációs egység lényegében egy alacsony poligonszámú felületből, Displacement Map segítségével kreál egy magas poligonszámút. Mindezt úgy, hogy a rendszer erőforrásait az eredeti alacsony részletességű modellel terheli. Az előnyöket gondolom nem kell ecsetelni, jóval nagyobb részletesség a sebesség minimális csökkenésével. A probléma azonban ott jelentkezik, hogy DX10 API-ban nincs benne tesszellátor egység támogatása, így a HD Radeonok ezen képességét egy kis trükk segítségével az API-t megkerülve lehet csak elérni. Ilyenkor a driver a feladattal pontosan a tesszellációs egységet címzi, onnan pedig a feldolgozás a hagyományos úton megy tovább.
Kérdés, hogy a képességet mikor használják ki. Vélhetőleg csak olyan program része lesz ezen tulajdonságok kiaknázása, ami elkészült Xbox 360-ra, mivel más esetben nem fognak a fejlesztők olyan eljáráshoz nyúlni ami nem szabványos.

G80 kontra R600 architektúra
Tökéletesen látszik, hogy mennyire eltérő elvek alapján sikerült a két chipet megtervezni. Ennek megfelelően a teljesítmény is esetenként meglehetősen szétszórt lett. Az G80 felépítéséből az következik, hogy főleg az egyszerű feladatok gyors végrehajtására tervezték. Az R600 gyakorlatilag ennek a gyökeres ellentéte, itt a tervezők inkább a bonyolult feladatok gyors végrehajtására helyezték a hangsúlyt. Ez helyenként jelenthet előny és hátrányt is. Fontos, hogy az R600 bármilyen Shader típusnál (Pixel, Vertex, Geometry) ugyanúgy viselkedik, míg a G80 eltérő feldolgozási elveket alkalmazhat.
Pixel Shader programok a mai napig relatíve egyszerűek, és tipikusan fekszenek a stream alapú feldolgozáshoz, így az Nvidia rendszerének nem sok problémája adódhat velük. A G80 TPC-je pixel feldolgozás esetén 32-es batch mérettel dolgozik, míg az R600 64-essel. Tehát Dynamic Branching esetén az Nvidia chip előnyre tesz szert a hatékonyságát tekintve. Az AMD-nek a magasabb batch méret egy egészséges kompromisszum az R600 komplex felépítése miatt. A fő probléma azokban az esetekben fordul elő amikor nem lehet olyan VLIW mintát kialakítani ami teljes hatékonysággal működtetné a 5 utas szuperskalár shader processzorokat. Szekvenciális, skalár adattípussal operáló shader kódok esetén az R600 szuperskalár processzora nem képes co-issue üzemmódban működni, mert az utasítások függenek egymástól. Ilyenkor a magas batch méret garantálja, hogy az adat fetch esetén bekövetkező elérési idő kiesése megfelelően át lesz lapolva.
Vertex Shader esetén a G80 Vertex ütemezője már 16-os batch méretre csökkent. Ez főleg annak köszönhető, hogy a jelen vertex shader progjamjai kis késleltetési toleranciát követelnek, így a Branching hatékonyságát az Nvidia most is előrébb helyezte a fontossági listán. Ez azonban problémát is jelenthet, mert így a TPC processzorok teljesítménye nincs teljes mértékben kihasználva, ami komoly vertex shader igénybevételt követelő feladatokban visszaüthet. Tovább tetézi a bajokat, hogy a G80 Triangle Setup teljesítménye is gyengébb az R600-nál, így az is limitálja a feldolgozás folyamatát. Tulajdonképpen amekkora általános előny van a G80 kezében az R600-hoz képest a pixel feladatok végrehajtásánál, legalább akkora, vagy még nagyobb hátrányt sikerült teremteni vertex programok futtatásakor. Szerencsés helyzetben van az Nvidia, hogy az előző generációs diszkrét shader alapú felépítés miatt a Pixel Shader programok dominanciája terjedt el. Amíg ez gyökeresen meg nem változik addig nem lesz nagy probléma, azonban ha a vertex programok jelentősége és használata a közeljövőben nagymértékben megnő, akkor elég komoly teljesítmény problémák elé nézhet a GeForce rendszer.
Geometry Shader új terület a képfeldolgozás elméleti lépcsőin. Az új technikák implementálása mindig nehéz, mert nem lehet előre tudni, hogy a hardver mely területei hatnak limitálóan a feldolgozás folyamatára. Az alapvető különbségeket, a két rendszer között, érdemesnek tartom egy példa alapján szemléltetni. A feladat elméletben egyszerű: tesszellált felület létrehozása. Van két háromszög „A” és „B”, ezeket kell szétbontani több kisebb háromszögre, és az „A” háromszögből keletkezett poligonokat kell előbb kirajzolni. A párhuzamos feldolgozás annak függvénye, hogy van-e elég regiszter vagy gyorstár terület a GPU-ban. Az R600-nál ebből a szempontból nincs probléma, hisz a Shader tömbökhöz kapcsolódik egy Memory Read/Write Cache, ami képes elég nagy mennyiségű ideiglenes adat tárolására. A feldolgozás így teljesen egyszerű és gyors lesz, az „A” háromszöget a chip felbontja a „B” háromszöggel párhuzamosan, majd megfelelő sorrendben kirajzolja őket. Ha nem lenne elég memória a GPU-ban a művelet párhuzamos elvégzéséhez, akkor a feladat tulajdonképpen nem hajtható végre, mivel a rendszer egy idő után elhasználja az ideiglenes tárolásra fenntartott erőforrásait. A G80-nál ez a helyzet előállhatna, mert nem rendelkezik nagy mennyiségű adatok tárolására alkalmas gyorstárral. Ennek megfelelően az Nvidia a problémát a másik véglet felől közelítette meg. A Geometry Shader ütemezője tulajdonképpen ellenőrzi minden feladat végrehajtása előtt, hogy elméletben lehetséges-e a párhuzamos feldolgozás. Ha nincs elég méretes gyorstár a chipben az „A” és „B” háromszög egyszerre történő felbontására, akkor a feladat nem lesz engedélyezve párhuzamos feldolgozásra. Minél több helyigénnyel rendelkezik egy Geometry Shader alapú feladat annál kevesebb Stream processzor lesz befogva munkavégzésre, mivel a többi Stream egység regiszter fájljait is felhasználja az ütemező az adatok tárolására. Ennek megfelelően a rendszer elméleti teljesítménye radikálisan visszaesik. A Cube Map tömbök alkalmazásakor is temérdek ideiglenes adat kerül felhasználásra, így jelenleg észrevehető, hogy ezen a területen nagyon vérzik a G80 architektúra működési elve.
Második generáció
NVIDIA G92 (Shader Modell 4.0)
2007 végén elérkezettnek látta az időt az Nvidia, hogy leváltsa a G80-as technológiát egy új olcsóbban gyártható chippel. A G92 tulajdonképpen egészen minimális változásokat tartogatott. Elsősorban a ROP Blokk-ok számát 6-ról 4 egységre redukálták, mely lépéssel a memóriabusz szélessége is csökkent 4 darab 64bit-es csatornára. A másik változás a Texture Processor Cluster-t érinti, ugyanis a textúrázó blokk 4 darab textúra címző egységét 8-ra növelték.
A változások minimálisak, viszont a gyártástechnológia fejlesztésével olcsóbban lehetet előállítani a chipet, ami az árcédulán is meglátszott.
AMD-ATi RV670 (Shader Modell 4.1)
A G92-vel majdnem egyidőben debütált az AMD-Ati új chipje, ami már Direct3D 10.1 támogatással rendelkezett. Ezenkívül főbb változás, hogy a memóriavezérlő külső buszszélessége 512bit-ről 256bit-re módosult. A csatornák száma viszont nem változott.
A gyártástechnológiában hatalmas előrelépés történt, ugyanis az RV670 az elérhető legmodernebb eljárással készült a megjelenésekor, ennek köszönhetően az előállítási költsége hihetetlenül alacsony volt, ami kifejezetten jót jelentett az AMD-nek, mivel szüksége volt a cégnek a nagyobb bevételekre.
Direct3D 10.1
Még ki sem hűlt a D3D10 máris átesett az első ráncfelvarráson. Az új 10.1-es verzió a Vista SP1-es javítócsomagjában érkezik, és több fontos területen kiterjeszti elődje képességeit. Csúnyán fogalmazva a Microsoft most fejezte be valójában a D3D10-et. A Shader Modell 4.1 kiterjesztés pusztán egy apró módosítást kapott a 4.0-hoz képpest. A beviteli regiszterek számát 16-ról 32-re növelték a Vertex programok esetén. Drasztikus változás nem várható ettől a lépéstől, de „több regiszter mindig jól jön” elv a GPU-knál is maximálisan érvényes szabály.
Sokkal radikálisabb módosítások és bővítések érték a rendszer más részeit. Ahhoz, hogy ezek működését megértsük tisztázni kell a Render Target fogalmát. Minden VGA memóriájában van egy Frame Buffer nevű terület, ahol tárolódik az éppen kirajzolt képkocka. A GPU azonban dolgozik folyamatosan a következő képkockán, amit a Back Buffer-ben tárol (amint kész az új képkocka a Back Buffer és a Frame Buffer tartalma felcserélődik, és a monitorra új kép lesz kirajzolva). Tulajdonképpen a Back Buffer az alapértelmezett Render Target. A képkocka számításának folyamatában azonban olyan eljárásokat is használhatnak a fejlesztők, amik több Render Target-et követelnek (Multiple Render Targets). A Deferred Rendering alapon leképzett effektek például ilyen technikák. Ezek elméleti alapjai közel két évtizede ismertek, de a Shader Modell szabványok adtak először lehetőséget, hogy használják a fejlesztők az eljárásokat. Az egész technika azon alapötleten alapul, hogy a GPU ne végezzen felesleges munkát. Alapvetően egy fényforrás által megvilágított objektum megrajzolása egy lépést vesz igénybe, de ha több fényforrás is van a jelenetben, akkor annyiszor kell kirajzolni az objektumot, ahány fényforrás van. Nyilvánvaló, hogy rengeteg felesleges erőforrást vesz igénybe a rendszer az objektum állandó kirajzolgatásával. A Deferref Rendering technikák lényege, hogy a rajzolási lépések számát csökkentsük minimálisra. Ennek érdekében a leképzés több fázisra lesz szétválasztva. Az első fázisban ki kell rajzolni minden olyan objektumot megvilágítás nélkül, ami a képkockán látható, egy Render Target textúrába (előfordulhat, hogy több textúrát is létre kell hozni). Ezek után az összes fényforrásra egyenként le kell futtatni a megvilágítási fázist. Ezen módszer segítségével az objektumok többszöri kirajzolását kerültük el. A több Render Target természetesen sok helyet foglal a memóriában, e textúrák összességét G-Buffer-nek szokás nevezni. A Deferred Rendering viszont egy súlyos problémát is magával hozz előnyei mellett. A jelenleg alkalmazott Multi-Sample Anti-Aliasing technikák nem kompatibilisek vele, mert a mintavételezés az első nem megvilágított Render Target textúrán történik, ami közel sem a végleges képkocka (tulajdonképpen ezért nincs hivatalos Multi-Sampling alapú elsimítás a legtöbb jelenleg megjelenő programban).
A D3D10.1 a jobb Deferred Rendering érdekében több újdonságot is bevezet a technika problémamentes és magas hatásfokú alkalmazására. Mostantól a Pixel Shader programok kimenetei egyszerre több Render Target-hez is írhatnak. Továbbá az élsimítás kompatibilitása is megnőtt, mivel az új API lehetőséget teremt a programozóknak, hogy a mélység és színmintákat egy Multi-Sample Buffer-be irányítsák, amely elérhető a Pixel Shader egység segítségével, így a fejlesztők maguk hozhatnak létre tetszőleges algoritmusokat, aminek következtében az Anti-Aliasing megfelelően és némileg gyorsabban lesz megjelenítve.
A textúrázásért felelős rész is javult. A D3D10.1-ben kötelezően támogatni kell az FP32-es precizitású szűrési eljárásokat, és szabvány szinten bevezetésre került a Gather4 nevű technika, ami tulajdonképpen ugyanaz, mint az Ati Fetch4 eljárása. Emellett a LOD utasítások támogatása is helyet kapott az új API-ban, így bárki létrehozhatja saját textúra szűrési eljárását.
Indexelt Cube Map tömbök
Ez az eljárás kapta talán a legkisebb figyelmet a D3D10.1-es ismertetőkben, pedig itt rejlik talán a legtöbb innováció a rendszerben. Segítségével valós idejű Global Illumination effekt hozható létre. Hogy mit is jelent ez? Röviden és tömören a valósághoz nagyon közel álló fénymegjelenítési és árnyékolási technikát. A Global Illumination nem ismeretlen vagy új keletű eljárás, hiszen évek óta alkalmazzák az előre renderelt filmek gyártásánál. A valós idejű renderelésnél azonban eddig tabu volt a rendkívül magas erőforrás igénye miatt. A jelenleg valós időben alkalmazott fénykezelési technikák direkten csak a fényforrás által kibocsátott fénysugarakra koncentrálnak, figyelmen kívül hagyva a felületek által visszavert vagy megtört fénysugarakat.


A Global Illumination technika segítségével lehetőség van tulajdonképpen végtelen mennyiségű dinamikus fényforrás fénysugarainak indirekt módon történő kezelésére. A Cube Map tömbök alkalmazásával a jelenetet rengeteg kis virtuális kockára bontják. Minden kis kocka belsejében a középpont azt vizsgálja, hogy a kockán áthaladó fénysugarak és az objektumok hogyan lépnek kölcsönhatásba egymással. A feldolgozott információkat pedig egy Cube Map textúrába menti. A textúrák feldolgozása során a középpontban elhelyezkedő kisgömbhöz viszonyítva Geometry Shaderrel kideríthető a fénysugár iránya és színe. Mivel rengeteg kocka gyűjti a jelenethez tartozó információkat, így magas lesz a teljesítményigény. Ezen a D3D10.1 úgy segít, hogy a lehetőség van több Cube Map textúra egyidejű írására és olvasására egy renderelési fázisban.
Az Indexelt Cube Map tömbök alkalmazása tipikusan olyan eljárás, ami rengeteg ideiglenes adattal jár, nem véletlen, hogy szabványosan ezt a technikát még csak az AMD támogatja, mert jelenleg csak ők rendelkeznek olyan architektúrával, ami megfelelő sebességgel futtatja az ilyen úton leképzett jeleneteket.
Konklúzió
Alapvetően bajban vagyok, amikor értékelni akarom a megjelent DX10-es rendszereket. A G80 architektúráról elmondható, hogy gyors a napjainkban alkalmazott eljárásokban, viszont számos ponton megkérdőjelezhető a működése. Az R600 és főleg az RV670 minden szempontból megújult architektúra, kifejezetten magas számítási kapacitással. Ebből azonban csak a jövőben fog profitálni, amikor a fejlesztők elkezdik kihasználni a DX10 API számos új és innovatív eljárásának előnyeit.
Itt van akkor az a kérdés, hogy most melyiket vegye az ember. Tulajdonképpen mindkettő ajánlott. Aki sokszor cseréli a grafikus kártyáját annak egyértelműen a GeForce 8 és 9-es VGA-k az ajánlottak, hiszen jelenleg ezek a rendszerek gyorsabbak, és mire a Radeon-ok befogják őket, addigra már úgyis másik VGA fog dübörögni a gépben. Aki hosszú távra tervez, illetve szeretne élsimítást a jövőben megjelenő programokban, annak érdemes kifejezetten a HD Radeon 3000-es szériából válogatni. Sok panasz éri még az nVidia rendszerek memória partícióinak gyenge vezérlését. Nagyon fontos, hogy GeForce kártyából minimum 512MB-osat kell venni, sőt érdemes ennél több memóriával ellátott modelleket is figyelni. Az AMD Radeon-ok viszont nagyságrendekkel hatékonyabban kezelik a memóriát, így 512MB-os modelleknél nem érdemes nagyobbat vásárolni, sőt az esetek többségében még a 256MB-os verziók is megfelelnek a célnak.
Bár nem túl sportszerű tőlem, de ezúttal szeretnék kibújni az eredményhirdetés alól. Ha a felmutatott eredményeket nézzük, akkor a G80 architektúra jobban vizsgázott. Ha viszont figyelembe vesszük, hogy mennyi területen vérzik a rendszer akkor az R600 a győztes. Egy dolog biztos, hogy választ csak a jövőben kapunk a felmerült kérdésekre. Az árak szerencsére rendkívül jól pozícionáltak a jelenlegi erőviszonyokat figyelembe véve, így tulajdonképpen rossz választás nem igazán van.




