
Bevezető
Bevezető
2001 egy nagyon fontos év volt a videokártyák történetében, ekkor jelentek meg ugyanis a shaderek, így a fix grafikus futószalag helyett a programozó dönthetett úgy, hogy a pixelek és vertexek feldolgozásának módját ő maga írja meg. A programozható pipeline-nal rendelkező videokártyák megjelenésével lehetővé vált azok számítási teljesítményének általános -tehát nem grafikai - célokra való felhasználása. Megszületett a GPGPU (General Purpose Graphics Processing Unit) fogalom. A módszer tehát már régóta létezik, ám nehézkes programozhatósága miatt nem igazán terjedt el. Voltak törekvések a GPU-programozás könnyítésére (Sh, BrookGPU), de az áttörést az nVidia hozta 2006 végén a CUDA-val. Nem kellett többé shaderekkel, textúrákkal trükközni, nem állt a fejlesztő útjában egy grafikai célokra kitalált API. Egyetlen probléma, hogy ez nem egy platformfüggetlen megoldás, lévén a CUDA csak az nVidia hardvereire van implementálva.
Erre a problémára nyújthat megoldást az Apple kezdeményezéséből született OpenCL. Maga az OpenCL tulajdonképpen egy nyílt szabvány, melyet a Khronos Group fejleszt/felügyel (az OpenGL is az ő kezükben van), és bárki implementálhat a saját eszközére. Itt a bárki alatt nem feltétlenül videokártya-gyártókra kell gondolni, az OpenCL ugyanúgy működhet CPU-n, mint GPU-n.

Augusztus 28-án megjelent a Snow Leopard, így publikussá vált az Apple platformján az OpenCL fejlesztői környezet: kaptunk egy OpenCL Framework-öt Xcode-hoz a header és library fájlokkal, a specifikáció egy jó összefoglalását a fejlesztői doksiban, illetve egy pár példaprogramot.
Írásomban szeretném bemutatni az OpenCL felépítését, működését. Nem célom referenciaszerűen felsorolni minden lehetőséget, csupán egy kis ízelítőt szeretnék adni erről a környezetről. Előre is elnézést kérek az OpenCL terminológiában előforduló kifejezések néhol talán bugyután hangzó fordításáért, de nem találtam jobb szavakat. Sokat gondolkodtam, hogy hagyjam-e meg az angol kifejezéseket, de ha egyszer magyarul írok cikket, akkor magyarul ilik írnom. Azért minden fordítás első előfordulásakor zárójelben jeleztem az eredeti kifejezést is, hogy egyértelmű legyen, miről is írok.
Hirdetés
OpenCL nagy vonalakban
A bevezető után nézzük, hogy is néz ki egy OpenCL számolás nagy vonalakban. Az OpenCL eszköz (device) az a hardver, amin a párhuzamos feldolgozás történik. Ezekben a hardverekben egy, vagy több számolási egység (compute unit) van, melyek egy, vagy több feldolgozó egységet (processing element) tartalmaznak - tulajdonképpen ezek hajtják végre az utasításokat. Például egy videokártya minden stream processzora, és egy CPU minden magja is egy feldolgozó egység, az nVidia videokáryák egy multiprocesszora pedig egy számolási egység.

Az ezeken futtatandó kódokat hívjuk kernelnek, kernel függvénynek. Az egyes feldolgozó egységek a kernel függvény egy példányát futtatják, mindegyikük más-más adatokon. A kerneleket OpenCL-C (az Apple hívja így a dokumentációiban, a specifikációban nincs külön néven említve) nyelven írjuk, és minden eszközre külön le kell fordítanunk őket. Az OpenCL eszközre írt kódokat természetesen nem kell egy darab függvénybe süríteni, a kernel hívhat más függvényeket, illetve lehet több kernelünk is. A kernelek, a kiegészítő függvények, illetve a kernel által használt konstansok együtt egy programot alkotnak. A kernelek egy úgynevezett kontextusban (context), környezetben futnak, mely magába foglalja a használható eszközöket, az általuk elérhető memória objektumokat, illetve a kernelek futtatásának ütemezését végző parancslistákat (command queue). A programot, amely létrehozza a kontextusokat, előjegyzi a kernelek futtatását, host programnak nevezzük, az őt futtató hardvert pedig a host eszköznek. A kernel futtatásához a host-nak a következő feladatokat kell elvégeznie: ki kell választani a megfelelő eszközöket, parancs listákat kell létrehozni az eszközön, illetve létre kell hoznia a számoláshoz szükséges memória objektumokat. Ha mindez nem volt teljesen világos, nem kell aggódni, a későbbiekben bemutatom egy konkrét példán keresztül, hogy is működik a dolog.
Platform modell
Az OpenCL működése leírható négy modell segítségével: platform modell, futtatási modell, memória modell, és a programozási modell. Az elsőről tulajdonképpen már írtam az előző bekezdésben: a host/eszköz kapcsolatról van szó. Lássuk, mit takar a többi!
Futtatási modell
Mint már említettem, az OpenCL eszköz egy feldolgozó egysége egy kernel egy példányát futtatja. Egy kernel-példányt munkaegységnek (work-item) nevezünk. Mikor elindítunk egy számolást, meg kell adnunk, hogy összesen hány munkaegységre lesz szükségünk. A munkaegységek összessége az index tér (index space), mely lehet 1, 2, vagy 3 dimenziós. A munkaegységek munkacsopotokba (work-group) szervezhetők. Ez azért fontos, mert az egy munkacsoportba tartozó munkaegységek között lehetséges szinkronizáció, és mindegyikük hozzáfér a csoport lokális memóriájához (erről később bővebben), míg ez a különböző csoportba tartozó egységekről ez nem mondható el.
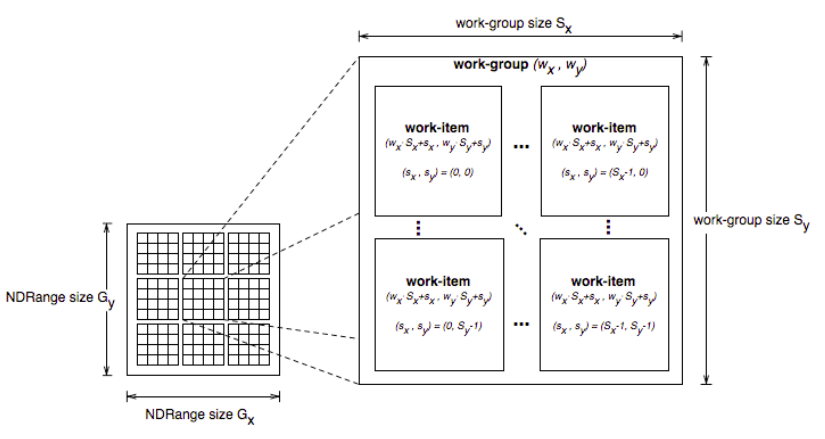
Minden munkaegységnek van egy úgynevezett globális azonosítója (global ID), mely egyértelműen meghatározza annak helyét az index térben. Hasonlóan, minden munkacsoportnak is van egy azonosítója (work-group ID). A munkaegységeknek ezen felül van egy helyi azonosítója (local ID), mely a munkacsoporton belüli helyét határozza meg. A fentiekből következik, hogy a munkaegység pozíciója az index térben meghatározható a csoport azonosító és a helyi azonosító kombinációjával. Az index tér dimenzióinak maximális száma, az egyes dimenziókban a maximális méret, illetve egy munkacsoport maximális mérete eszközönként eltérő lehet, ezt figyelembe kell venni programozás közben! Az OpenCL API természetesen lehetőséget nyújt ezen adatok lekérdezésére.
Memória modell
A munkaegységek/kernelek által hozzáférhető memória négy típusra van osztva. A globális memóriához (global memory) az index tér minden egyes munkaegysége hozzáfér, azt írni és olvasni is tudják. Eszköztől függően a globális memória írása/olvasása lehet cache-elt. A konstans memória (constant memory) a globális memória egy olyan része, melynek tartalma nem változik kernelfuttatás közben, azt csak a host módosíthatja.
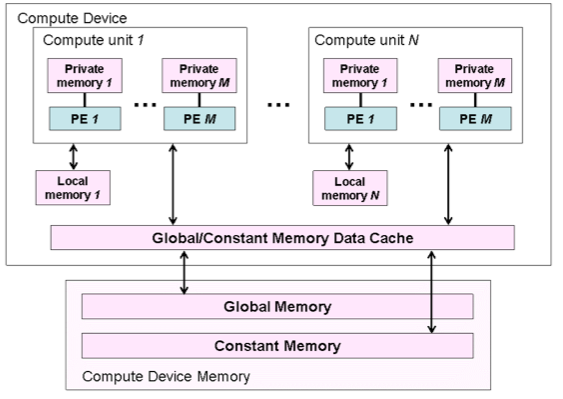
Minden munkacsoport rendelkezik egy lokális memória (local memory) területtel, melyet minden munkaegység a csoportban képes írni/olvasni. A privát memória (private memory) minden egyes munkaegységnek a sajátja, ő írni/olasni tudja, de más munkaegység nem fér hozzá. A CUDA-t ismerőknek: érdemes odafigyelni az elnevezésekre, mert bár a két környezet felépítése hasonló, a terminológia nagyon nem. Ezt azért most hozom fel, mert például a CUDA-féle lokális memória az, amit itt privátnak hívunk, és ami itt lokális memória, az CUDA-ban megosztott (shared memory).
Programozási modell
OpenCL-t használva kétféle párhuzamosítást érhetünk el: data, illetve task parallel módon programozhatunk. Az első az OpenCL fő profilja, ez jelenti azt, hogy sok kernel példány csinálja ugyanazt az index tér más-más elemein. Ha több, más feladatot végző kernelünk van, betehetjük őket egy parancslistába, és az OpenCL megtesz minden tőle telhetőt, hogy ezek optimálisan használják ki a hardvert. Ez utóbbi a task parallel módszer, hiszen egymástól független folyamatok futnak párhuzamosan.
Példaprogram - Előkészületek
Kernel függvény
OK, most, hogy átrágtuk magunkat a száraz tényeken, következzen egy konkrét feladat megvalósítása OpenCL-ben. A mellékelt forráskódot érdemes nyitva tartani olvasás közben, illetve természetesen az OpenCL specifikáció is hasznos olvasmány. Ez utóbbit azért is célszerű olvsani, mert a használt API függvények argumentumait nem mutattam be részletesen, csupán leírtam, hogy adott paraméterezéssel mit csinál az adott függvény.
Példának egy egyszerű dolgot választottam: a BLAS csomag SAXPY függvényét fogjuk megvalósítani. A SAXPY fog két vektort, az elsőt megszorozza egy skalárral, majd az eredményt hozzáadja a második vektorhoz (y = a * x + y). Ha nem párhuzamos megvalósításban gondolkodnánk, akkor ezt valószínűleg egy ciklussal oldanánk meg, valahogy így:
for (int i = 0; i < n; ++i)
{
y[i] = a * x[i] + y[i];
}
A ciklus bejárja a vektorok elemeit, és elvégzi rajtuk a megfelelő műveletet. Szépen sorban, egymás után. Egy i-edik elem kiszámolásához csak a két vektor i-edik elemeire, és a konstansra van szükség - tehát az egyes számolások teljesen függetlenek egymástól, így a probléma szinte felkínálja magát párhuzamosításra. A terv az, hogy írunk egy kernelt, ami elvégzi a SAXPY-t egy vektor egy elemére, majd egy (n elemű vektorokkal számolva) n elemből álló index térre rászabadítjuk ezt a kernelt. Egyszerűen hangzik, fogjunk is neki!
Első lépésként írjuk meg a kernelt!
__kernel void saxpy(__constant float * x, __global float * y, __private const float a)
{
const uint i = get_global_id(0);
y[i] += a * x[i];
}
Ennyi az egész. A __kernel kulcsszó - meglepő módon :) - azt jelzi, hogy az adott függvény egy kernel függvény.(FIGYELEM! A következő rész át lett írva, és a forráskód is javítva lett. Az ok a 32-es hsz-ben található. Köszönet karics-nak, hogy felhívta a figyelmemet a hibára) Egy kernel argumentumai a __private névtérben kell legyenek, és alapértelmezetten oda is kerülnek, ezért az "a" változó elől akár el is hagyhatnánk a __private kulcsszót. Ha egy argumentum mutató (a mi kernelünk esetében ez ugye igaz x-re és y-ra is), megmondhatjuk, hogy a __global, __local és __constant névterek melyikébe mutasson. Az x a __constant névtérbe mutat, ugyanis az x vektor értékei nem fognak változni a program futása során (ez CUDA architektúrán gyorsabb, mintha a __global címtérbe mutatna, ugyanis a konstans memória cache-elt). Az y vektorba tesszük a számolás eredményét, ezért az a __global névtérbe mutat.
A get_global_id(0) függvény az adott munkaegység globális azonosítójának első koordinátáját adja vissza. Erre azért van szükség, hogy tudjuk, hogy egy adott kernelpéldány a vektor hányadik elemének számolásáért felel. Mivel vektorokon dolgozunk, az index terünk egydimenziós, így valóban csak az első koordinátára van szükségünk. Ezután a kernel már csak elvégzi a megfelelő műveleteket a vektorok megfelelő elemein, és az eredményt visszaírja a második vektor megfelelő elemébe.
Platformok
A számoláshoz szükségünk van egy OpenCL eszközre. Ahhoz, hogy létrehozhassunk egy eszközt, szükségünk lesz egy platform ID-re. Az elérhető platformok listáját a a következőképpen szerezhetjük meg:
cl_uint num_platforms;
cl_platform_id * platforms;
clGetPlatformIDs(0, NULL, &num_platforms);
platforms = malloc(sizeof(cl_platform_id) * num_platforms);
clGetPlatformIDs(num_platforms, platforms, NULL);
Ez a kódrészlet az első clGetPlatforms hívással kideríti az elérhető OpenCL platformok számát, lefoglal egy megfelelő méretű tömböt a platform ID-knek, majd a második hívással lekárdezi őket. A mellékelt példaprogramban az első elérhető platformot használjuk.
Eszközök
Ha megvan a platform azonosítónk (platform_id), lekérdezhetjük az elérhető eszközök listáját:
cl_uint num_devices;
cl_device_id * devices;
clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_ALL, 0, NULL, &num_devices);
devices = malloc(sizeof(cl_device_id) * num_devices);
clGetDeviceIDs(platform_id, CL_DEVICE_TYPE_ALL, num_devices, devices, NULL);
Ez nagyon hasonlít az előző kódrészlethez, a különbség annyi, hogy itt eszközökről szerzünk listát. A clGetDeviceIDs második paramétere meghatározza, hogy milyen típusú eszközökkel szeretnénk foglalkozni. Most minden elérhető eszközt felsoroltattunk, de lehetne pl. csak a GPU-kat (CL_DEVICE_TYPE_GPU), vagy csak a CPU-kat (CL_DEVICE_TYPE_CPU). Egy megjegyzés: ha a platform id (a clGetDeviceIDs első paramétere) NULL, akkor a specifikáció szerint a függvény viselkedése implementációfüggő. Az Apple példaprogramjaiban NULL-t használ. Bár erről külön nem írnak sehol, gondolom azért, mert úgyis csak egy platform van, annak az ID-jét használja.
Környezet
Most, hogy megvan az eszköz, létre kell hozni egy környezetet a számoláshoz. Erre való a clCreateContext API függvény:
cl_context context;
context = clCreateContext(0, 1, &device_id, NULL, NULL, &err);
Ez a függvény létrehoz egy környezetet a harmadik paraméterben megadott azonosítójú eszközhöz (vagy eszközökhöz, ugyanis többet is megadhatunk - a második paraméter közli a függvénnyel ezek számát). Az err változóban egy hibakódot kapunk vissza, melynek értéke sikeres végrehajtás esetén CL_SUCCESS. Ezt érdemes ellenőrizni egy programban. Környezetet nem csak ily módon hozhatunk létre, lehet pl. minden, adott típusú eszközhöz környezetet kreálni. GOTO OpenCL doksi :)
Parancslista
OK, van környezetünk, most kell hozzá egy parancslista, ahová majd a végrehajtandó kerneleket pakoljuk.
cl_command_queue commands;
commands = clCreateCommandQueue(context, device_id, 0, &err);
Ez a hívás a device_id azonosítójú eszközhöz hoz létre egy parancslistát. Több parancslistát is létrehozhatnánk, de a kitűzött feladat elég egyszerű, egy lista is elég. Több lista esetén, amennyiben az egyes parancsok használnak közös objektumokat, figyelni kell a szinkronizálásra; erről bővebben olvashattok a OpenCL specifikációban. Még egy dolog a parancslistákkal kapcsolatban: több eszköz esetén mindegyiknek saját listára van szüksége!
Foglaljuk össze mink van eddig! Kiválasztottunk egy OpenCL platformot, és erről a platformról egy eszközt, amin számolni fogunk. Ehhez az eszközhöz készítettünk egy környezetet, melyhez létrehoztunk egy parancslistát. Ja, és írtunk egy kernel függvényt is. Most már csak pár dolgot kell végrehajtanunk: kellenek memória objektumok, amikben átadjuk a kernelnek a két vektort, illetve visszakapjuk az eredményt. A kernelfuttatáshoz szükségünk lesz egy kernel objektumra, amit csak egy, az adott eszközhöz felépített program objektumból nyerhetünk ki. Folytassuk tehát a munkát, készítsük el a program objektumot!
Program objektum
Programot készíthetünk forráskódból, illetve binárisból is. A gyorsabb inicializálás érdekében célszerű az első futtatáskor lefordítani a forrást, majd a kapott binárist (több OpenCL eszköz esetén az eltérő gépi kód miatt binárisokat) elraktározni, s következő alkalommal abból készíteni a program objektumot. Lássuk, hogy forrásból hogyan készítünk programot (a binárisból készítésre az írásban nem térek ki, a példaprogi forrásában viszont ott van, ki lehet lesni :) )!
cl_program program;
program = clCreateProgramWithSource(context, 1, &kernel_source, NULL, &err);
OK, van egy programunk, de ez még csak a forráskódót tartalmazza, tehát le kell fordítanunk:
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
Ha a függvény visszatérési értéke nem CL_SUCCESS, valami hiba történt a fordításkor. Erről bővebb információt a clGetProgramBuildInfo függvény szolgáltat, ha elkérjük tőle a build logot:
if (err != CL_SUCCESS)
{
size_t size;
clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, 0, NULL, &size);
char * log = malloc(size);
clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, size, log, NULL);
printf("%s\n", log);
exit(1);
}
Kernel objektum
Miután sikeresen felépítettük a programot, kinyerhetjük belőle a kernel objektumot.
cl_kernel kernel;
kernel = clClreateKernel(program, "saxpy", &err);
Mint látható, a kernel objektum gyártás elég egyszerű művelet, csupán egy lefordított programra, és a kernel függvény nevére van szükségünk hozzá.
Példaprogram - Pufferek, futtatás, eredmény
Memória objektumok
Nos, van már kernelünk, amit tudnánk futtatni, csak egy probléma van: nincsenek adataink, amin dolgozhatunk. No problemo, csinálunk memória objektumokat, s feltöltjük őket a vektorainkkal. OpenCL-ben az eszköz memóriáját kétféle objektumon keresztül érhetjük el: puffer és kép (image) objektumok. A pufferekbe bármilyen adatot tehetünk, míg a kép objektumok kettő, vagy három dimenziós képek tárolására alkalmasak. A kép objektumokkal most nem foglalkozom részletesebben, kitűzött célunk eléréséhez nincs is szükség rájuk, a vektorokat pufferekben tároljuk:
cl_mem dev_x;
cl_mem dev_y;
dev_x = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float) * VECTOR_SIZE, NULL, NULL);
dev_y = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * VECTOR_SIZE, NULL, NULL);
Ez a két függvényhívás létrehozza az adott kontextusban az x és y vektoroknak megfelelő puffereket. Az x vektort csak olvasni fogjuk, így a CL_MEM_READ_ONLY flaggel hozzuk létre, míg az y vektorhoz szükség van a CL_MEM_READ_WRITE flagre, hiszen abba írjuk majd a végeredményt. Lehetőség van a puffer készítésekor megadni egy host pointert (negyedik paraméter), és az adatot, amire mutat, rögtön felmásolni a pufferbe. Ehhez szükséges megadni a CL_MEM_COPY_HOST_PTR flaget. Puffert létrehozhatunk a host memóriájában is (CL_MEM_ALLOC_HOST_PTR), illetve felhasználhatunk már lefoglalt host memóriaterületet is (CL_MEM_USE_HOST_PTR).
A vektorokat a következő módon töltjük fel az eszköz memóriájába:
clEnqueueWriteBuffer(commands, dev_x, CL_TRUE, 0, sizeof(float) * VECTOR_SIZE, x, 0, NULL, NULL);
clEnqueueWriteBuffer(commands, dev_y, CL_TRUE, 0, sizeof(float) * VECTOR_SIZE, y, 0, NULL, NULL);
A clEnqueueWriteBuffer API függvény előjegyez egy pufferbe írást a megadott parancslistában. Itt konkrétan a host memóriában lévő x és y vektorokat másoljuk a dev_x és dev_y memória objektumokba. A függvény utolsó három paraméterét most nem használjuk, de azért elmondom, mire jók. Minden olyan függvény, ami a parancslistához ad elemeket, kér egy cl_event típusú pointert (utolsó paraméter). Az így visszaadott cl_event-tel lehet lekérdezni a parancs aktuális állapotát (pl. végzett-e?), illetve más parancsok várólistájához lehet adni a parancsot. A várólistában szereplő összes parancsnak le kell futnia, mielőtt az adott parancs lefuthatna. A clEnqueueWriteBuffer hetedik argumentuma a lista mérete, a nyolcadik pedig maga a várólista (cl_event típusú tömb).
Kernel futtatás
OK, már majdnem kész vagyunk, már csak futtatnunk kell a kernelt. Egyszerűen hangzik, de azért ez nem csak annyiból áll, hogy meghívunk egy függvényt, aztán fut. Be kell állítani a kernel-argumentumokat, meg kell határozni a munkacsoportok és munkaegységek számát, és elő kell jegyezni a kernelt a parancslistában.
clSetKernelArg(kernel, 0, sizeof(cl_mem), &dev_x);
clSetKernelArg(kernel, 1, sizeof(cl_mem), &dev_x);
clSetKernelArg(kernel, 2, sizeof(float), &a);
Ezek az API hívások állítják be a kernel argumentumokat. Az egyes argumentumokat a kernel függvény fejlécében elfoglalt helyük alapján azonosítjuk, ez a szám a clSetKernelArg függvény második paramétere. A munkaegységek száma megegyezik a vektorok méretével. Azt, hogy ez hogyan van felosztva munkacsoportokra, most teljesen mindegy (az egyes vektor elemek teljesen függetlenek egymástól, a munkaegységeknek nincs szüksége közös memóriára), ezért az OpenCL-re bízzuk.
const size_t work_items = VECTOR_SIZE;
clEnqueueNDRangeKernel(commands, kernel, 1, NULL, &work_items, NULL, 0, NULL, NULL);
Ezzel a függvénnyel előjegyeztük a kernelfuttatást, megadtuk az index tér dimenzióinak (harmadik paraméter), és a munkaegységeknek (ötödik paraméter) a számát. Nos, ha minden jól ment, ezen hívás után már fut is a kernelünk.
Eredmény olvasása
A számolás eredménye persze az eszköz memóriájában van, tehát ki kell olvasnunk onnan. Ehhez persze biztosnak kell lennünk benne, hogy a számolás befejeződött. Ezt a clFinish függvénnyel biztosíthatjuk, ami csak akkor tér vissza, ha a paraméterként megadott parancslista minden parancsa befejeződött.
Az eredmények host memóriába olvasása:
clEnqueueReadBuffer(commands, dev_y, CL_TRUE, 0, sizeof(float) * VECTOR_SIZE, result, 0, NULL, NULL);
Amikor ez lefut, a dev_y memória objektum tartalma a host memóriában lévő result vektorba másolódik. A pufferekbe írásnál kimaradt, most megemlítem: ha a harmadik paraméter CL_TRUE, az olvasás/írás befejeztéig nem tért vissza a függvény, ha CL_FALSE, nem várja meg a műveletek befejeztét.
Végeztünk a számolással, de még nem fejeződött be a dolgunk. Illik eltakarítani magunk után, szabadítsuk fel az OpenCL erőforrásokat!
clReleaseMemObject(dev_x);
clReleaseMemObject(dev_y);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(commands);
clReleaseContext(context);
Végszó
Még mielőtt befejezem, egy megjegyzést engedjetek meg nekem, mely az Xcode használóknak szól: a Snow Leopard már csak az Intel platformot támogatja, így az OpenCL Framework nem is tartalmaz PPC binárisokat. Alapértelmezetten a C/C++ projectek Release konfigurációban fordítanának PPC-re is, de a hiányzó OpenCL binárisok miatt ez természetesen nem sikerül. A megoldás: a project Properties lapján a Build tabon a Valid Architectures listából ki kell venni a PPC architektúrákat.
Most már tényleg végeztünk :) Remélem érthető voltam, és talán néhányatoknak meghoztam a kedvét egy kis videokártya-programozáshoz. Természetesen minden kérdést/kritikát/javaslatot szívesen fogadok. Köszönöm, hogy elolvastátok az írást!
Kapcsolódó anyagok, források
BrookGPU - A Stanford University GPGPU megoldása
Sh - Egy metaprogramozási nyelv GPU-khoz
CUDA - Az nVidia GPGPU API-ja
Khronos OpenCL API Registry - A Khronos Group OpenCL-lel kapcsolatos anyagai
OpenCL Programming Guide for Mac OS X - Az Apple OpenCL doksija
Példaprogram forráskód: [link]
OpenCL Info Browser - első Cocoa progim, a gépen elérhető OpenCL platform/eszköz infókat mutatja




