







Én is így sok sok joinnal oldottam meg pont, csak mondom hátha van rá valami kíméletesebb megoldás is.
Külön táblázást nagyon nem szeretem, mindig elszúrom valahol....
PH Konfigom: Gigabyte GA-H97M-D3H, i7 4790K,GTX 960, Seasonic SS-620GM

Én is így sok sok joinnal oldottam meg pont, csak mondom hátha van rá valami kíméletesebb megoldás is.
Külön táblázást nagyon nem szeretem, mindig elszúrom valahol....
PH Konfigom: Gigabyte GA-H97M-D3H, i7 4790K,GTX 960, Seasonic SS-620GM

Szvsz, mindent vigyél fel, mint általános kategóriát valahogy így:
Hirdetés
hirdetés_id, feltöltő_id, hirdetés_típusa_id, hirdetés_címe, hirdetés_szöveg
Hirdetés típus
hirdetés_típus_id, hirdetés_típus_szöveg
Kategória_típus
kategória_id, hirdetés_típus_id, kategória_név, kategória_leírás
Hirdetés_kategória_értékek
hirdetés_id, kategória_id, érték
Lekérdezés
SELECT
h.hirdetés_id,
h.hirdetés_címe,
h.hirdetés_szöveg,
t.hirdetés_típus_szöveg,
k.kategória_név,
e.érték
FROM
hirdetés h
JOIN Hirdetés_kategória_értékek e ON h.hirdetés_id = e.hirdetés_id
JOIN Hirdetés típus t ON h.hirdetés_típusa_id = t.hirdetés_típusa_id
JOIN Kategória_típus k ON e.kategória_id = k.kategória_id
WHERE
h.hirdetés_id IN (
SELECT hi.hirdetés_id FROM
hirdetés hi
JOIN Hirdetés_kategória_értékek ei ON hi.hirdetés_id = ei.hirdetés_id
JOIN Kategória_típus ki ON ei.kategória_id = ki.kategória_id
WHERE
ki.kategória_név = "Szobák száma" AND ei.érték = 3
)
[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...

Tele van inner joinnal. Rendesen indexelt táblákkal nincs ebben semmi kíméletlen.
Az adatbázistól elkérheted egy lekérdezés execution plan-jét (legalábbis Oracle alatt biztosan), abból ki lehet bogarászni, hogy hogyan optimalizálja azt, és hol lehet gyorsítani rajta.
Természetesen ha nem használod pl. a kategória3-mat, nem kell belevenni a lekérdezésbe. Továbbá biztosan nem lesz szükséged az összes tábla összes mezőjére, így a select * helyett a szükséges mezőnevek felsorolása célszerű.
Az ember mindig elszúrja valahol, ez természetes dolog. Azért gyakorlunk, hogy minimalizáljuk ezt.
Egy normális adatbázis több tíz, száz, ezer táblát tartalmaz - sémákba rendezve -, mindegyiknek megvan a célja. Egyes táblák akár sokszáz oszloppal rendelkezhetnek, bennük több milliárd rekorddal. Ha ezen táblák tartalmát egy táblába gyűjtenénk az adatbázis szerintem már az indexelésnél összeomlana.
Viszont ezzel, hogy mindent "belehánysz" egy táblába, azt éred el, hogy borzasztóan sok _felesleges_ adattal duzzasztod azt fel. Szerencsétlen adatbázis minden teszemazt ingatlanos lekérdezésnél kénytelen végigfutni az autós meg az összes többi irreleváns hirdetések adatain/indexein is. Egy kicsit is tágabb szűrést adsz meg véletlenül, és csodálkozol, hogy miért lett ez ilyen tetü lassú.
Én úgy vélem, hogy ne hagyjuk az adatbázist feleslegesen dolgozni, ha van más lehetőség. Nagyon könnyen teljesítmény problémákba futhatsz bele, és azokon már nehezebb javítani, mint pár elrontott lekérdezésen.

Sziasztok!
MySQL-el kapcsolatban remélem jó helyen kérdezek.
WHERE IN-ben létezik joker karater? Pontosan arra gondolok, hogy pl. a következőben:
WHERE T.mezo IN ($elemek)
ha azt szeretném hogy ne legyen szűrés, csak a $elemek változónak adnék egy "joker" értéket, hogy minden rekord belekerüljön a lekérdezésbe.
Az idő sebessége: 1s/s

szerintem az üres karakterrel ezt fogod elérni, de azért joker karakternek nem nevezném.
Én kérek elnézést!
Sajnos nem azt csinálja. Ha pl. $elemek egy üres változó, vagy akár változó nélkül üres karaktert adok paraméterként az IN-nek, akkor nem ad vissza semmit a lekérdezés. Gondolom olyan rekordokat adna vissza aminek a "mezo" mezője üres...
Az idő sebessége: 1s/s
WHERE T.mezo IN (SELECT mezo FROM Tabla)
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
Francba, összekevertem az IN-t a LIKE-al.
Én kérek elnézést!
Belegondoltál-e már abba, hogy amit szeretnél, azt nem így kellene megoldani? Gondolom PHP-ban ügyködsz, és van egy összekonkatenált sql query-d, aminek a végén mindig ott van ez a where.
De miért van ott, amikor bizonyos esetekben egyszerűen nem kellene, hogy ott legyen? Alakítsd át a kódodat, és ha már átalakítod, akkor a konkatenálást is csináld meg normálisra.
Én kérek elnézést!
Jó kérdés, mit csinál az IN.
IN-t átalakítani nem túl egyszerű, ha konkatenált értékek vannak, szvsz egyszerűbb megírni valami ilyesmire (php):
WHERE (T.mezo IN ($elemek) OR " . strlen($elemek) . " = 0)
Persze SQL Injection ellen még mindig meg kell védeni a query-t. És nem elég az, hogy az értékek a form checkbox-okból jönnek - legfeljebb az, ha felasználó által nem manipulálható másik lekérdezésből...
[ Szerkesztve ]
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...

Ehelyett össze is köthetné "mezo" mentén a két táblát, nem? Esetleg még DISTINCT, ha duplikálódna.
Válaszolva a felmerülő kérdésekre:
Igen belegondoltam mit szeretnék, eddigi kódjaimban én is ezt a módszert követtem, hogy legeneráltam a megfelelő sql kérést, így ami nem kell az nincs ott a where-ben. Most viszont a sok táblakapcsolat és a sok where feltétel miatt gondoltam hogy jó lenne ha mindig minden ott lenne, megfelelő paraméterrel.
Egyébként sztanozs "WHERE T.mezo IN (SELECT mezo FROM Tabla)" megoldásával sikerült megoldani a problémát, és minden variációban jól működik így a lekérdezés.
Köszönöm!
[ Szerkesztve ]
Az idő sebessége: 1s/s

Plz help! Van egy nagyon noob kérdésem, nem értem, miért azt az eredmény kapom amit.
Van két táblám. "telepulesek" és "utcak"
Ha az utcak táblából lekérdezek:
select telepulesid, nev from utcak where telepulesid = '12300' and nev like 'Ác%'
ezt kapom:
telepulesid;nev
12300;Áchim András tér
12300;Ács utca
tehát két sor.
A telepulesek táblából lekérdezek:
select id, telepulesnev from telepulesek where id = '12300'
ezt kapom:
id;telepulesnev
12300;Veszprém
Viszont ha joinnal csinálom:
select telepulesid, irsz , utcak.nev as utcanev from telepulesek
inner join utcak on utcak.telepulesid = telepulesek.id
where telepulesnev = 'Veszprém' and utcak.nev like 'Ác%'
telepulesid;irsz;utcanev
12300;8200;Ács utca
Az első pár betűre szűrést csak azért raktam bele, hogy ne legyen olyan hosszú az eredmény. Kipróbáltam több id-vel is, a legelső sort lehagyja. Ilyenbe eddig még nem futottam bele. Valami ötlet? 
[ Szerkesztve ]
Citizen Diopapa / Commander Diopapa "SC csomag olyan, mint a barackfa, unokáidnak veszed - .tnm / De pálinkát nemlehet főzni belűle - *SkyS1gn"
Beraktam SQL Fiddle-be a kérdéses részt, hátha segít... tehát a gondom, hogy join után az első sor nem jelenik meg.
Közben meglett, de már nem törlöm ki a postot.. Valami vezérlőkarakter van az első sorban.... grrrrr 

Citizen Diopapa / Commander Diopapa "SC csomag olyan, mint a barackfa, unokáidnak veszed - .tnm / De pálinkát nemlehet főzni belűle - *SkyS1gn"

NoSQL adatbázis rendszerekkel van valakinek tapasztalata? Napi ~0,5-1 Gb adat (kb. ~100 millió rekord/hónap) tárolásához kéne. Oracle KVLite NoSQL megoldásáról mik a vélemények?

mongoDB?
dinosaurs are jesus ponies
Nem az a kérdés, hogy mennyi adatot kellene tárolni NoSql-ben (jelzem havi 100 millió adat nudli, bármelyik TSQL-nek is, már ha nem egy Pentium 4-esen futtatod, 1Gb ram mellett), hanem az a kérdés, hogy milyen komplex lekérdezéseitek, riportjaitok lesznek.
Addig aranyos dolog a NoSql, amíg csak tolja bele az ember az adatokat, de amikor azokat ki is kellene szedni, netán bizonyos relációkat megvalósítani, akkor elég gyorsan ki fog derülni, hogy csodák nincsenek. 
Ettől még igenis van létjogosultsága a NoSql-nek bizonyos területeken, csak jelezni akartam, hogy amikor döntötök, akkor több szempontot is vegyetek szemügyre, ne csak a havi 100 millió rekordot, ami egyébként abszolút nem sok, még ha nektek soknak is tűnik elsőre.
Ha meg a hype miatt szeretnétek NoSql-t, akkor érdemes megnézni a NewSql-eket is, mert ez a legújabb hype: [link]
Én kérek elnézést!
 Még nem biztos a NoSQL mellett döntés, csak feljött mint opció, emiatt kérdeztem. De asszem ezek alapján kicsit más oldalról is körbejárjuk még a dolgot.
Még nem biztos a NoSQL mellett döntés, csak feljött mint opció, emiatt kérdeztem. De asszem ezek alapján kicsit más oldalról is körbejárjuk még a dolgot.
Üdv! olyan kérdésem lenne h: eddig Windows 8.1 volt fent a gépemen és bírtam használni az sql servert. Most h Windows 10-re frissítettem,nem bírom elindítani,mert sqlunirl.dll nem tudja megnyitni,vagy hiányzik,vagy nem tudom. Tudna esetleg valaki segíteni? próbáltam a 2014-es változatát,de az teljesen más és nem tudtam használni.
Telepítsd újra 
2014-esen mit nem bírsz használni? Tök ugyanaz a kezelőfelülete, mint bármelyik régebbinek.
Én kérek elnézést!
hát azé 15 év alatt teljesen más lett. nem lehet telepíteni a 2000-est,ezt írja ki:
[ Szerkesztve ]
Ja várjál már, ne viccelődjünk. Nem írtad, hogy te eddig SQL 2000-rel szórakoztál, fel se tételeztem, hogy SQL 2005-nél régebbit bárki is használ manapság pár nagybankon kívül (vagy talán már ők sem).
Hát ez zseniális 




Miért nem akarsz rögtön clipper-es adatbázist - vagy mi is volt annak idején a dos-os förmedvények alatt - futtatni a 2015 augusztusában kijött win10 alatt?
De hogy konstruktív is legyek, én a helyedben tennék fel egy virtuális gépben windows XP-t, arra simán fel kell tudnia menni az SQL 2000-nek. Más kérdés, hogy jó sok erőforrásba fog kerülni a gépeden csak azért virtuális gépet futtatni, hogy végül azon fusson az SQL 2000, és még jóval lassabb is lesz, mint eddig.
[ Szerkesztve ]
Én kérek elnézést!
bocs,tényleg nem írtam. hát a munkámhoz kell a 2000-es server,de nem értem hiszen win 8.1 alatt gond nélkül futott.

Én is besz...tam most, mert az új laposra most akarom felrakni a 2012-es sql szervert, csúnya lett volna, ha kiderül, hogy nem megy 10-en.
"Debugging is like being the detective in a crime movie where you're also the murderer."

miért nem telepítesz VM-re?

Sziasztok, kéne egy lekérdezés nekem.
Meg kell keressem egy DATA oszlopban több adott kifejezést. Ez a DATA oszlop viszont 4 sorból ál. Egy adatfolyamot ment bele de mivel limitált az egy cellába írható adatmennyiség, így tördeli. 4-5-6 de van hogy csak 3 sorban írja ki. Természetesen van hogy amit keresek az 1 es sorban van és van hogy a 5 ösben. De van hogy 2-3 as is érintett. Mivel lehetséges, ha lehetséges ennek a lekérdezése, hogy sorrendben legyenek?
Valami összevonásra gondoltam először, (Hogy csináljon minden sorban lévő DATA oszlopból egyet és abban kérdezzem le.) de ilyet nem találtam.
Köszi előre is.
Plug and Pray... :)
MS SQL-ben LIKE operátor:
select *
from tábla
where oszlop LIKE '%feltétel%'
[ Szerkesztve ]
"Debugging is like being the detective in a crime movie where you're also the murderer."

ez nem működik olyankor, amikor a feltétel string közepén törte el az adatot a rendszer.
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis

Itt találsz hozzá egy jó topicot ami alapján meg lehet csinálni. Máshol láttam CTE-s recursive megoldást is, de az még ennél is komplexebbnek tűnt.
[ Szerkesztve ]
Things that try to look like things often do look more like things than things
Köszi sajnos, töri a sorokat, (Ahogy bambano is írta) így ez nem megoldás. (Illetve az lenne, ha előbb össze tudnám vonni.)
Realradical: Köszi nézem. Ezzel az lesz a bajom, hogy olyan nagy adatmennyiség van a sorban, hogy nem képes kiírni az SQL, pont ezért töri a sorokat, mert nem képes több adatot egy sorban tárolni.
Megnézem hogy lehet ezt esetleg megnövelni. Akkor jöhet ez a megoldás.
[ Szerkesztve ]
Plug and Pray... :)
kérdés: ha olyan nagy mennyiségű adatot kell tárolnod, hogy úgyis eltöri az sql, akkor miért nem töröd a maximális mezőméret felére, és akkor tudnád konkatenálni a mezőket és simán ellenőrizni?
tehát pl. ha az ms sql 65536 bájtot tud tárolni egy mezőben (csak hasraütéssel, a példa kedvéért), és neked így kell 4 sor az adathoz, akkor miért nem veszed le a mezőméretet 32768-ra, akkor kellene 8 sor, viszont két egymás utáni sorban levő adatot egymás mellé tudnál rakni és akkor könnyen tudnál keresni.
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis
a másik ötlet, hogy két lépésben keresel, egyszer simán az adatokon, másodszor minden adatmező elejéről és végéről levágsz egy-egy stringet, ami olyan hosszú, mint a keresési string, ezeket megfelelően összekonkatenálod és ezen kerestetsz.
lehet, hogy erre akár egy nézettáblát is fel lehetne húzni.
Egy átlagos héten négy hétfő és egy péntek van (C) Diabolis

Erre ugye a megfelelő adattípus használata a megoldás, és szerintem az összes mainstream adatbáziskezelőben van erre CLOB vagy TEXT vagy ahogy éppen hívják típus.
Mundjuk ahhoz nem árt ektivált fulltext search engine, vagy egy full table scan lesz a vége óriási időigénnyel.
JOGI NYILATKOZAT: A bejegyzéseim és hozzászólásaim a személyes véleményemet tükrözik; ezek nem tekinthetők a munkáltatóm hivatalos állásfoglalásának...
Milyen adatok ezek, hogy ilyen hosszúak? Nem lehetne a betöltés pillanatában ellenőrizni a keresési feltételeket? Vagy csinálni egy temp táblát, ahová eleve értelmezhető bontásban tárolnád az adatokat? És akkor arra lehetne keresni is.
A lényeg, hogy túl kevés az info a megoldáshoz.
"Debugging is like being the detective in a crime movie where you're also the murderer."
Inkább varchar(max), mostani verziókon, de igen, igazad lesz, befér az
Things that try to look like things often do look more like things than things
Na mivel banki rendszer, így a kiírást nem tudom befolyásolni.
Le kell kérdezzem, hogy valóban kiírta-e az adatokat. Úgy ahogy elvárják.
Beírom ide mi a baj jelenleg.
Jelen példa: Ez van a 3. Sorbanelőtte persze az ami számomra lényegtelen...:
"><element><FinIdentSchemeCode
tableNo='2233'>COMO</FinIdentSchemeCode><FinIdent"
Itt a sortörés, és ez van a 4. sorban
"No>9601201</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>INT</FinIdentSchemeCode><FinIdentNo>U_AVS_W_750000</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>ISIN</FinIdentSchemeCode><FinIdentNo>DE0007500001</FinIdentNo></element><element><FinIdentSchemeCode tableNo='2233'>VALO</FinIdentSchemeCode><FinIdentNo>412006</FinIdentNo></element><element><FinIdentSchemeCode "
Ha csak egy sorban lenne akkor sima like.
Ez a lényeg:
like '%2233%COMO%9601201%'
like '%2233%INT%U_AVS_W_750000%'
STB...
De random, hogy melyik sort töri meg, random, hogy 2 vagy 5 sorba írja ki az adatokat. Tehát egy kicsit nehéz a dolog.
[ Szerkesztve ]
Plug and Pray... :)
Szia!
Ezek a "sorok" egyetlen rekordot jelentenek? Ha igen, nem jó rá egy replace() + char(10) kombó, amivel kiszeded a sortöréseket, hogy utána LIKE-kal kereshess?

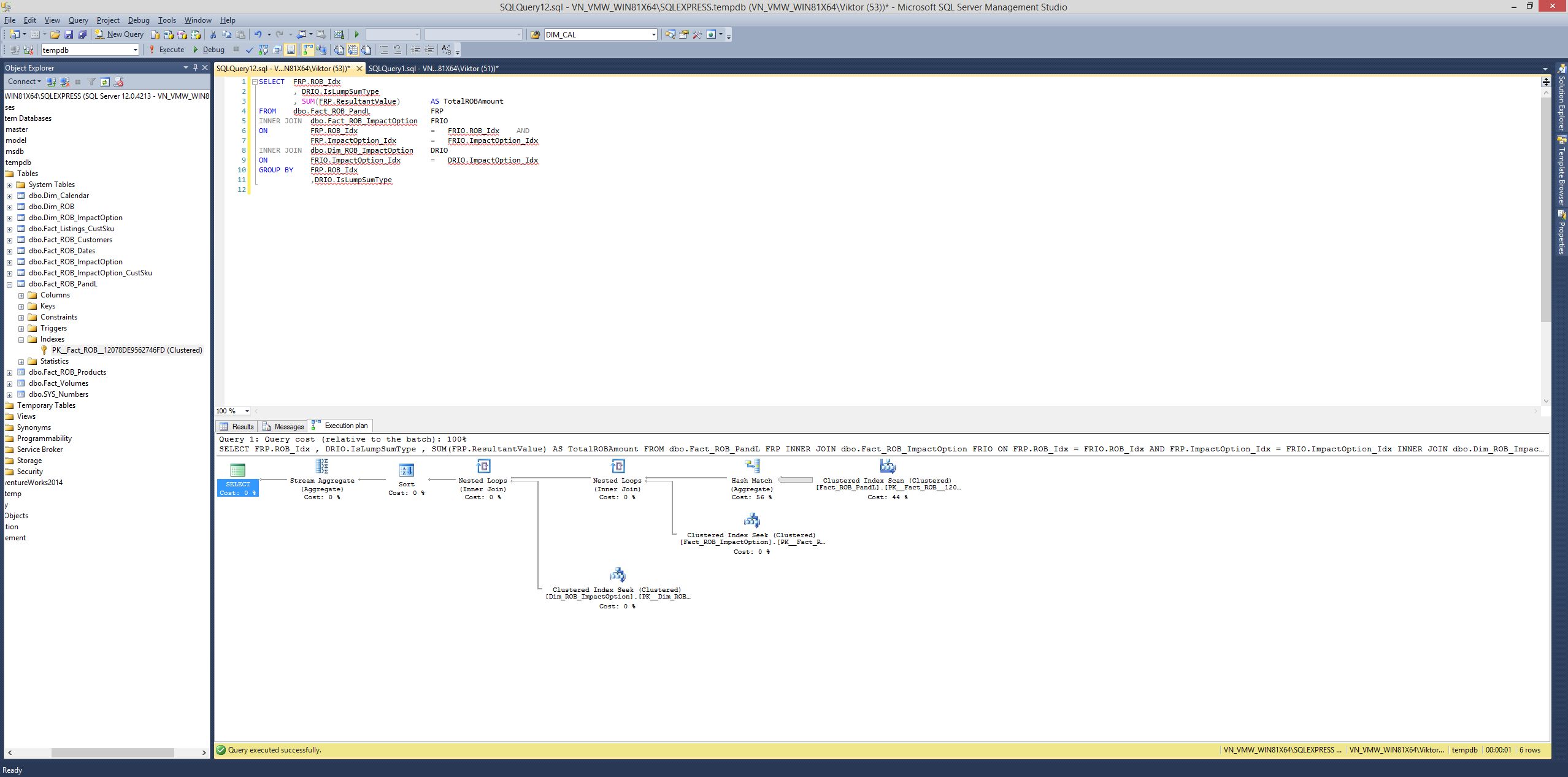
Sziasztok,
Gyors kerdes - tudom ez picit random igy, de tesztfeladat....az alabbi scriptet kellene optimalizalni.
Osszessegeben annyi a gond, h nem tudom hogyan.
Gondolom vagy az indexet kellene modositani (a PK-nak maradnia kell, ezert max uj indexet tudunk csinalni), vagy pedig valahogy a join-t megoldani h effektivebb legyen.
Otletek?
Elore is koszi.
BackToTheUKBlog:[backtotheukblog.wordpress.com] 2019/09/05: Brexitgráf IV — őrültek és csirkék háza
Nem egyetlen sajnos.
Ez lesz a megoldás, csak még ki kell googlizzam hogy is viszem be ezt db2 őbe..
(Egy barátom segített...)
define finIdents as varchar[2000]
define inPayLoad as boolean
quere_result is
select * from XXX.scito
where mand_id = 'VALAMI'
and scito_tst_ab > current timestamp -1 hour
and operationname = 'sendDelivMgtExec'
order by sub_row_id
inPayLoad = 0
for row in query_result
do
if (finIdents == '' and exists(row.daten, '<finIdentDetailsList>'))
then
finIdents = replace(row.daten, '%<finIdentDetailsList>', '<finIdentDetailsList>')
inPayLoad = 1
continue
end
if (inPayLoad == 1)
then
if (exists(row.daten, '</finIdentDetailsList>'))
then
finIdents = concatenate(finIdents, replace(row.daten, '</finIdentDetailsList>%', '</finIdentDetailsList>'))
break
else
finIdents = concatenate(finIdents, row.daten)
end
end
end
echo finIdents
[ Szerkesztve ]
Plug and Pray... :)
ÉS a végső megoldás ez lett!
select row_id, daten
from
(select row_id,
replace(
replace(
replace(
xmlserialize(XMLAGG(XMLELEMENT(NAME "x", daten) ) as varchar(32672))
, '</x><x>', ',')
, '<x>', '')
, '</x>', '') as DATEN
from DB.TÁBLA
where mand_id = 'VALAMI'
and scito_tst_ab > current timestamp -5 hour
group by row_id)
where daten like '%2233%COMO%9601201%2233%INT%U_AVS_W_750000%2233%ISIN%DE0007500001%2233%VALO%412006%2233%WM%750000%'
;
Plug and Pray... :)
Azért jó, hogy végül ki tudtátok használni az XML-függvényekkel, hogy mégiscsak strukturált adathalmazról volt szó.

Sziasztok,
Paraméterezhető MySQL tárolt függvényben van e lehetőség foglalkozni az SQL injection elleni védelemmel, illetve kell e foglalkozni vele? Próbáltam keresni a témában de csak PHP-related topikokat találtam, konkrétan arra példát, hogy pusztán SQL oldalon, hogy lehet prepared statement-eket használni, olyat nem. Valaki tud egy ilyet linkelni?
Thx.
but without you, my life is incomplete, my days are absolutely gray
Na pasztmek.
Jókormán'
but without you, my life is incomplete, my days are absolutely gray

sziasztok.
1) létezik valami hatékony módszer lebackupolni egy táblát, amiben 86 millió rekord (16GB) van? ms sql-ről van szó.
ma elindítottam egy generate script félét, ami ugye sql fájlba menti ki. fél óra után szóltak hogy gáz van a szeróval, persze a query nyomatta 100%-on a procit. 20gb volt a fájl, mikor cancelt nyomtam neki.
2) más adatbázisban is le akarom csekkolni, hogy van-e ilyen gázos tábla. egy select count is ennyire proci igényes, hogy legyilkolja a szerót?
egyébként production szerverről van szó
[ Szerkesztve ]
1. ne viccelődjünk már, MS SQL-t rohadtul nem generate scripttel kell backupolni, hanem a backupolás funkcióval, ami meglepő módon pont erre van kitalálva. Akár még tömöríti is neked közben az adatot. Tudom durván el van rejtve, a te képernyőmentéseden pl. a totál váratlan Back Up menü pont néven szerepel 5-tel a Generate Script felett.
2. a select count nem erre való, noha rossz gyakorlatként gyakran használják erre. Nálunk pl. a legnagyobb táblában lévő pár milliárd sornál, ha kiadsz egy select count-ot, akkor simán leáll a 64 magos, 256Gb-s szerver is. Ellenben van egy rakás analitikai beépített függvény, simán le tudod kérni az összes tábla adatait. Mondjuk így: [link]
Én kérek elnézést!
backup nem tudtam hogy tabla backupolasra is jo. nem neztem akkor elegge korul.
plusz azert scriptet generaltam, mert egy masik tablaba (backup tabla) akarom insertelni ugyanazon db-be.
[ Szerkesztve ]
Ja vár, elsiklottam a felett, hogy te csak egy darab táblát akarsz backupolni. A backup az a komplett DB backupra jó, bár lehet, hogy meg lehet neki mondani, hogy csak egy táblát akarsz backupolni, még sose próbáltam csak egy táblát backupolni vele.
Másrészt ha ugyanazon DB-n belül akarsz backupolni, akkor miért nem:
insert into backuptabla
select *
from eredetitabla
vagy select * into backuptabla from eredetitabla
hirtelenjében nem tudom melyik a nyerő szintaxis.
Én kérek elnézést!
Köszi, közben select into-t én is megtaláltam.
kettes feladvány megoldása ez lett végül:
EXEC sp_MSforeachdb
'Begin
USE [?]
IF EXISTS(SELECT name FROM [?]..sysobjects WHERE name = ''titkostablanev'')
BEGIN
DECLARE @rowCounter INT
SELECT @rowCounter = row_count FROM sys.dm_db_partition_stats
WHERE object_id = OBJECT_ID(''titkostablanev'');
Print ''?'' + ''-> number of rows of titkostablanev table: '' + cast(@rowCounter as NVARCHAR(20))
END
End'
sp_spaceused-al nem tudtam volna printelni. spaceused is innen (sys.dm_db_partition_stats ) szedi ki az infókat és így lehetett printelni is.
a backupolásról még beszélek valakivel, nem merem még a select into-t lefuttatni, nehogy legyilkolja.
[ Szerkesztve ]


