
Divide et impera
Divide et impera
Most röviden vegyük sorra felülről lefele, a modulban megosztott részeket és a fontosabb tudnivalókat róluk. A teljes front-end megosztott. Ez az a rész, amely az x86 utasításokat fordítja le (dekódolja) belső RISC utasításokra. A még le nem fordított utasítások a memóriából először az L1I (utasítás) cache-be kerülnek. Az L1I gyorsítótár a K10-éhez hasonlóan 2-utas asszociativitású és 64 KB méretű lesz.

Az utasítás cache-ből a dekóderbe kerülnek a fordításra váró kódok. A dekóder egy időben már négy utasítás fordítására képes. Viszonyítás gyanánt a Nehalem és az érkezőben lévő Sandy Bridge szintén négy, míg a K10 egyetlen magjában található hasonló célú egység három ilyen utasítás fordítását képes elvégezni párhuzamosan egy órajel alatt. Az további, utasításdekódolás hatékonyságát segítő apparátus (elágazás becslés, utasítás TLB, stb.) egységek újításaival kapcsolatban egyelőre nincs sok hivatalos információ.
Hirdetés
Mielőtt továbbmennénk meg kell említeni, hogy a Bulldozer a több mint 10 éves 3DNow!-t már nem viszi tovább. Cserébe jelentősen bővül a támogatott utasításkészletek sora, ugyanis az eddigiek mellé érkezik az SSSE3, SSE 4.1, SSE 4.2, AVX, AES-NI, XOP és az FMA4. Ez utóbbi kettő a korábbi SSE5 feldarabolása után maradt meg.
A következő állomás az FPU mely rugalmasságából adódóan csak a Flex FP nevet kapta. Ez az egység egy külön ütemezővel ellátott, két, egyenként 128 bites FMAC és kettő, egyenként 128 bites SIMD INTeger egységből tevődik össze. Természetükből adódóan bármelyik képes FADD vagy FMUL (összeadás és szorzás) műveletekre. Ennek okán 128 bites SSE műveletekből párhuzamosan kettőt is végre tud hajtani. A 256 bites AVX műveleteket a dekóder két egy-egy 128 bites részre bontja szét, amelyeket a két 128 bites egység összekapcsolásával akár egyidejűleg is elvégezhet.
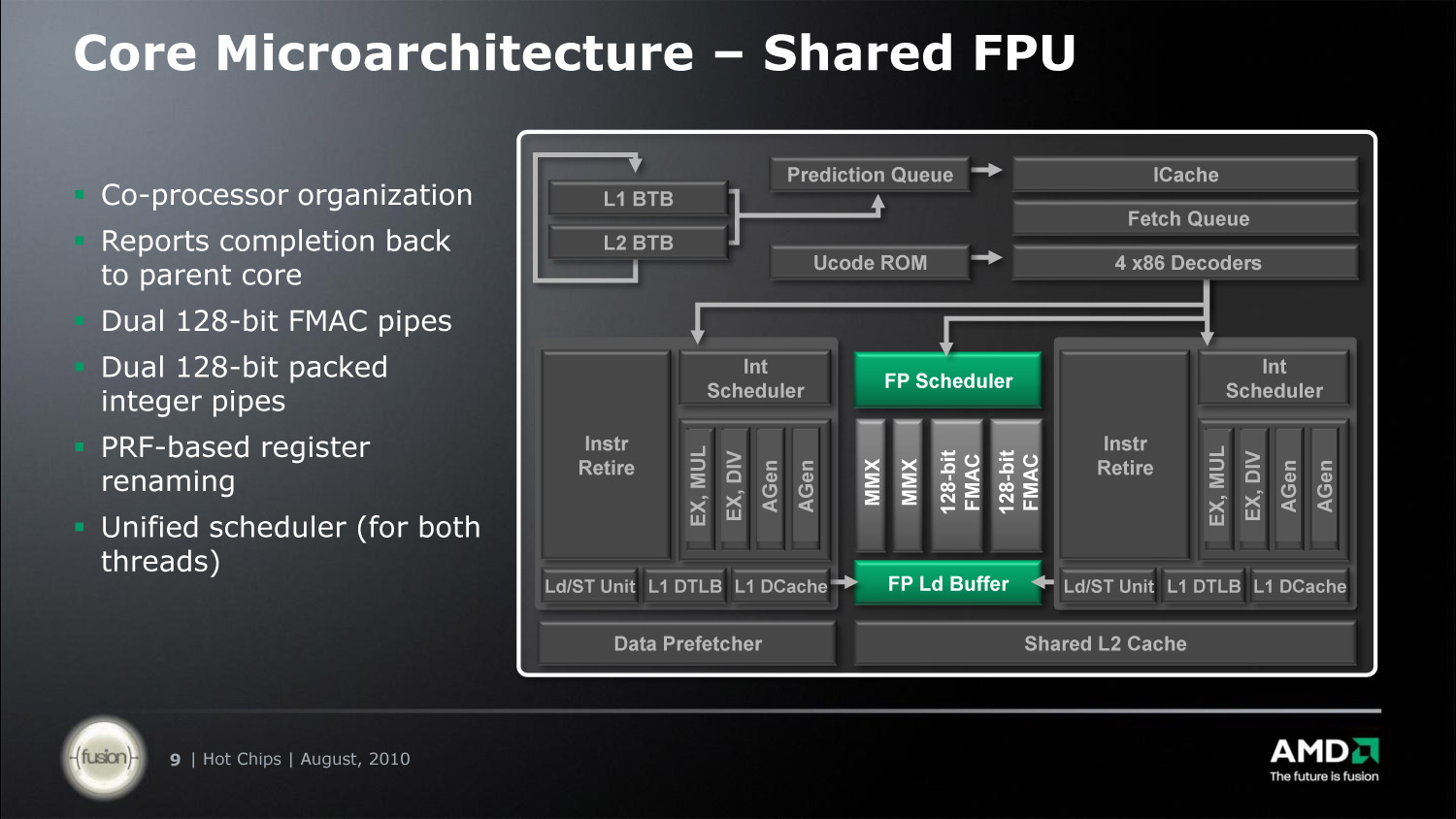
A két 128 bites FMAC pipeline-on mellett szintén kettő, 128 bites integer SIMD egység is található az FPU klaszterben. Ezek a megnevezésből sejthetően egész számos (összeadás/kivonás, szorzás, AND/OR/XOR/NOT) művelteket hajtanak végre több számon egyszerre (SIMD), azaz ezek az integer MMX (64 bit), SSE2 (128 bit) és AVX (256 bit) utasításokat hajtják végre.
Az FPU-t bármelyik mag használhatja, vagy akár a kettő egyszerre is. Több szálon történő 64/128/256 bites végrehajtás esetében arról nincs egyelőre bővebb információ, hogy a pipeline-ok hogyan kerülnek felosztásra; valószínűleg akár egy-egy szál is kisajátíthatja a teljes FPU-t, ha a másik szál nem igényli azt. Versenyhelyzetben 50-50%-os elosztást várhatunk.

Ez a megosztás gyakorlatilag semmilyen hátránnyal nem jár, mivel egy-egy utasítás latency-je (késleltetése) legalább 2 órajel, de jellemzően inkább 4. Magyarul annyi idő múlva kapja meg az egyik mag a következő utasítása az eredmény(eke)t, a köztes időben pedig lehet a másik mag számításait indítani.

Lényegében ez azt jelenti, hogy a tervezésnél sikerült megspórolni egy teljes második FPU-t anélkül, hogy ez a számítási teljesítményben bárhol is visszaütne. Az ebből fakadó előnyök talán egyértelműek: kisebb terület, alacsonyabb fogyasztás.
A megosztott FPU egyik jövőbeni előnye és fejlesztési iránya lehet, hogy a jelenleg még GPU-kban található shader tömbök átvehetik vagy kiegészíthetik az FPU-t. Ez egyébiránt véletlenül(?) pont passzolna is az AMD Fusion-nal kapcsolatos jövőbeni elképzeléseihez.

Az utolsó szinten az adatelőbehívók (data prefetcher), és a viszonylag nagy, szintén megosztott 16-utas asszociativitású 2 MB-os L2 cache található. Az első oldal közepe-alja fele olvasott idézet után már mindenki tudja, hogy ez utóbbi megosztása nem egy teljesen új dolog.
A cikk még nem ért véget, kérlek, lapozz!




