
Bevezető
Bevezető
2001 egy nagyon fontos év volt a videokártyák történetében, ekkor jelentek meg ugyanis a shaderek, így a fix grafikus futószalag helyett a programozó dönthetett úgy, hogy a pixelek és vertexek feldolgozásának módját ő maga írja meg. A programozható pipeline-nal rendelkező videokártyák megjelenésével lehetővé vált azok számítási teljesítményének általános -tehát nem grafikai - célokra való felhasználása. Megszületett a GPGPU (General Purpose Graphics Processing Unit) fogalom. A módszer tehát már régóta létezik, ám nehézkes programozhatósága miatt nem igazán terjedt el. Voltak törekvések a GPU-programozás könnyítésére (Sh, BrookGPU), de az áttörést az nVidia hozta 2006 végén a CUDA-val. Nem kellett többé shaderekkel, textúrákkal trükközni, nem állt a fejlesztő útjában egy grafikai célokra kitalált API. Egyetlen probléma, hogy ez nem egy platformfüggetlen megoldás, lévén a CUDA csak az nVidia hardvereire van implementálva.
Erre a problémára nyújthat megoldást az Apple kezdeményezéséből született OpenCL. Maga az OpenCL tulajdonképpen egy nyílt szabvány, melyet a Khronos Group fejleszt/felügyel (az OpenGL is az ő kezükben van), és bárki implementálhat a saját eszközére. Itt a bárki alatt nem feltétlenül videokártya-gyártókra kell gondolni, az OpenCL ugyanúgy működhet CPU-n, mint GPU-n.

Augusztus 28-án megjelent a Snow Leopard, így publikussá vált az Apple platformján az OpenCL fejlesztői környezet: kaptunk egy OpenCL Framework-öt Xcode-hoz a header és library fájlokkal, a specifikáció egy jó összefoglalását a fejlesztői doksiban, illetve egy pár példaprogramot.
Hirdetés
Írásomban szeretném bemutatni az OpenCL felépítését, működését. Nem célom referenciaszerűen felsorolni minden lehetőséget, csupán egy kis ízelítőt szeretnék adni erről a környezetről. Előre is elnézést kérek az OpenCL terminológiában előforduló kifejezések néhol talán bugyután hangzó fordításáért, de nem találtam jobb szavakat. Sokat gondolkodtam, hogy hagyjam-e meg az angol kifejezéseket, de ha egyszer magyarul írok cikket, akkor magyarul ilik írnom. Azért minden fordítás első előfordulásakor zárójelben jeleztem az eredeti kifejezést is, hogy egyértelmű legyen, miről is írok.
OpenCL nagy vonalakban
A bevezető után nézzük, hogy is néz ki egy OpenCL számolás nagy vonalakban. Az OpenCL eszköz (device) az a hardver, amin a párhuzamos feldolgozás történik. Ezekben a hardverekben egy, vagy több számolási egység (compute unit) van, melyek egy, vagy több feldolgozó egységet (processing element) tartalmaznak - tulajdonképpen ezek hajtják végre az utasításokat. Például egy videokártya minden stream processzora, és egy CPU minden magja is egy feldolgozó egység, az nVidia videokáryák egy multiprocesszora pedig egy számolási egység.

Az ezeken futtatandó kódokat hívjuk kernelnek, kernel függvénynek. Az egyes feldolgozó egységek a kernel függvény egy példányát futtatják, mindegyikük más-más adatokon. A kerneleket OpenCL-C (az Apple hívja így a dokumentációiban, a specifikációban nincs külön néven említve) nyelven írjuk, és minden eszközre külön le kell fordítanunk őket. Az OpenCL eszközre írt kódokat természetesen nem kell egy darab függvénybe süríteni, a kernel hívhat más függvényeket, illetve lehet több kernelünk is. A kernelek, a kiegészítő függvények, illetve a kernel által használt konstansok együtt egy programot alkotnak. A kernelek egy úgynevezett kontextusban (context), környezetben futnak, mely magába foglalja a használható eszközöket, az általuk elérhető memória objektumokat, illetve a kernelek futtatásának ütemezését végző parancslistákat (command queue). A programot, amely létrehozza a kontextusokat, előjegyzi a kernelek futtatását, host programnak nevezzük, az őt futtató hardvert pedig a host eszköznek. A kernel futtatásához a host-nak a következő feladatokat kell elvégeznie: ki kell választani a megfelelő eszközöket, parancs listákat kell létrehozni az eszközön, illetve létre kell hoznia a számoláshoz szükséges memória objektumokat. Ha mindez nem volt teljesen világos, nem kell aggódni, a későbbiekben bemutatom egy konkrét példán keresztül, hogy is működik a dolog.
Platform modell
Az OpenCL működése leírható négy modell segítségével: platform modell, futtatási modell, memória modell, és a programozási modell. Az elsőről tulajdonképpen már írtam az előző bekezdésben: a host/eszköz kapcsolatról van szó. Lássuk, mit takar a többi!
Futtatási modell
Mint már említettem, az OpenCL eszköz egy feldolgozó egysége egy kernel egy példányát futtatja. Egy kernel-példányt munkaegységnek (work-item) nevezünk. Mikor elindítunk egy számolást, meg kell adnunk, hogy összesen hány munkaegységre lesz szükségünk. A munkaegységek összessége az index tér (index space), mely lehet 1, 2, vagy 3 dimenziós. A munkaegységek munkacsopotokba (work-group) szervezhetők. Ez azért fontos, mert az egy munkacsoportba tartozó munkaegységek között lehetséges szinkronizáció, és mindegyikük hozzáfér a csoport lokális memóriájához (erről később bővebben), míg ez a különböző csoportba tartozó egységekről ez nem mondható el.
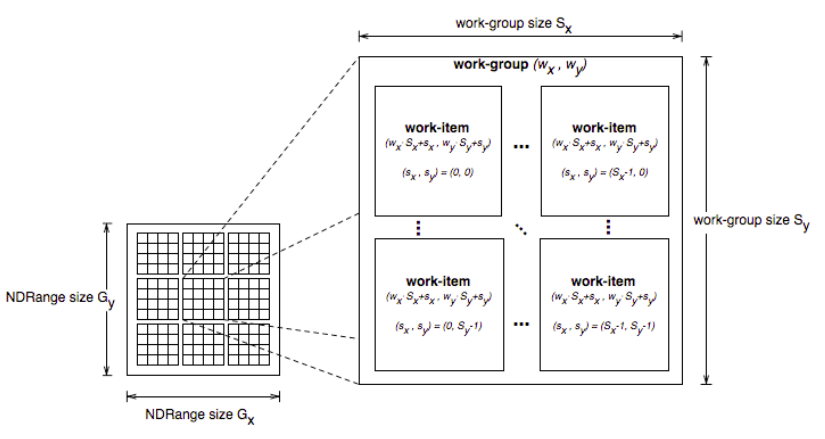
Minden munkaegységnek van egy úgynevezett globális azonosítója (global ID), mely egyértelműen meghatározza annak helyét az index térben. Hasonlóan, minden munkacsoportnak is van egy azonosítója (work-group ID). A munkaegységeknek ezen felül van egy helyi azonosítója (local ID), mely a munkacsoporton belüli helyét határozza meg. A fentiekből következik, hogy a munkaegység pozíciója az index térben meghatározható a csoport azonosító és a helyi azonosító kombinációjával. Az index tér dimenzióinak maximális száma, az egyes dimenziókban a maximális méret, illetve egy munkacsoport maximális mérete eszközönként eltérő lehet, ezt figyelembe kell venni programozás közben! Az OpenCL API természetesen lehetőséget nyújt ezen adatok lekérdezésére.
Memória modell
A munkaegységek/kernelek által hozzáférhető memória négy típusra van osztva. A globális memóriához (global memory) az index tér minden egyes munkaegysége hozzáfér, azt írni és olvasni is tudják. Eszköztől függően a globális memória írása/olvasása lehet cache-elt. A konstans memória (constant memory) a globális memória egy olyan része, melynek tartalma nem változik kernelfuttatás közben, azt csak a host módosíthatja.
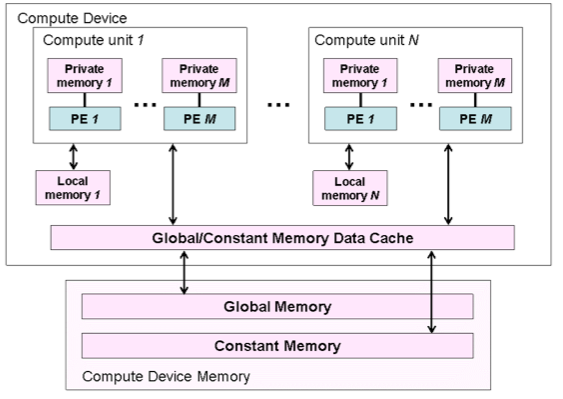
Minden munkacsoport rendelkezik egy lokális memória (local memory) területtel, melyet minden munkaegység a csoportban képes írni/olvasni. A privát memória (private memory) minden egyes munkaegységnek a sajátja, ő írni/olasni tudja, de más munkaegység nem fér hozzá. A CUDA-t ismerőknek: érdemes odafigyelni az elnevezésekre, mert bár a két környezet felépítése hasonló, a terminológia nagyon nem. Ezt azért most hozom fel, mert például a CUDA-féle lokális memória az, amit itt privátnak hívunk, és ami itt lokális memória, az CUDA-ban megosztott (shared memory).
Programozási modell
OpenCL-t használva kétféle párhuzamosítást érhetünk el: data, illetve task parallel módon programozhatunk. Az első az OpenCL fő profilja, ez jelenti azt, hogy sok kernel példány csinálja ugyanazt az index tér más-más elemein. Ha több, más feladatot végző kernelünk van, betehetjük őket egy parancslistába, és az OpenCL megtesz minden tőle telhetőt, hogy ezek optimálisan használják ki a hardvert. Ez utóbbi a task parallel módszer, hiszen egymástól független folyamatok futnak párhuzamosan.
A cikk még nem ért véget, kérlek, lapozz!





