


Kapcsolódó cikkek (szükséges lehet a cikk megértéséhez):
Harmadik dimenzió / A reformok kora
Kapcsolódó leírások (szükséges lehet a cikk megértéséhez):
Architektúra fogalomtár / Processzor fogalomtár / Memória fogalomtár / Grafikus fogalomtár
Eljött újra a harc ideje … Szinte egy időben startoltak az NVIDIA és az AMD új generációs grafikus chipjei a felhasználók kegyeiért. Az AMD-nek története legnagyobb csatáját kellett megvívnia, és ennek érdekében soha nem látott titkolózás és felkészülés előzte meg az új RV770 kódnevű chip megjelenését. A zöld oldal elsősorban a rendkívül magabiztos nyilatkozatokkal próbálta felhívni magára a figyelmet jelezvén, hogy a Radeon-ok már egyáltalán nem veszélyesek a GeForce-ok által uralt piacra. Ezzel finoman utaltak arra, hogy a G200 nevű fejlesztés megsemmisítő erejű lesz a konkurenciára nézve. Mivel egyik chip sem épül új architektúrára az elemzés elsősorban A reformok kora című cikkben leírtakra lesz alapozva.
ALU:Tex arány
Mielőtt belekezdenénk a vizsgálódásokba egy, az iparágban régóta használt fogalmat érdemes tisztázni. Ez nem más, mint az ALU:Tex arány, ami azt adja meg, hogy a shader kódban egy textúrázó utasításra hány számláló instrukció jut. Ez az arányszám ugyan minden shader kódban más, de a technológia fejlődése mellett általánosan elfogadott, hogy növekvő tendenciát mutat. Az ALU:Tex arány szempontjából természetesen a különböző chipeket is lehet jellemezni, ilyenkor az aránypár azt jelenti, hogy a chipnek milyen ALU:Tex arányú shader kód futtatása az ideális.
AMD-ATi RV770 (Shader Modell 4.1)
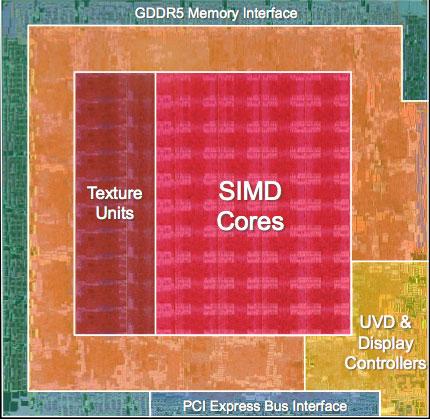
Az új chip fejlesztésénél egyértelmű szempont volt a teljesítmény drasztikus növelése. Az R600 alapjai erre maximálisan alkalmasak, hiszen technikailag a jelen legkorszerűbb architektúrájáról beszélünk. Az alapvető felépítés nem igazán változott, így továbbra is a feladat-végrehajtó Shader tömbök képzik a rendszer magját. A számuk azonban 4-ről 10-re növekedett. Gyors fejszámolás után kiderül, hogy ez összesen 160 darab Szuperskalár Shader processzort eredményez.
(nagyítható)
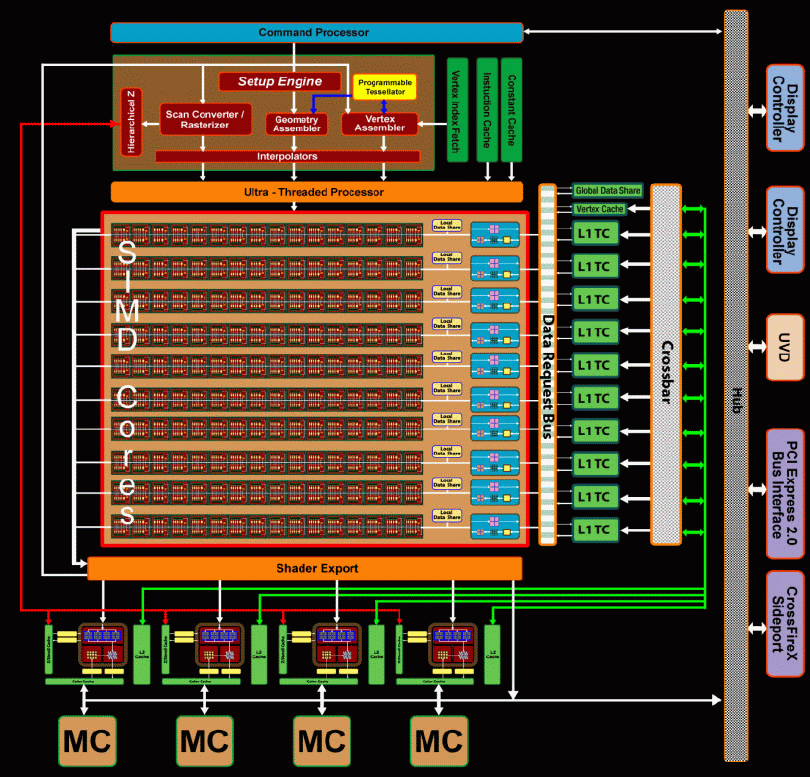
A textúrázásért felelős rész logikai működése is némileg át lett alakítva. Mostantól a textúrázó blokkok nem a Shader tömbök egy-egy szeletéhez, hanem magához a Shader tömbhöz kapcsolódnak. Ez valamilyen szinten kikényszeríttet változtatás, ami a működésre, hatékonyság szempontjából minimális hatással van. Egész egyszerűen arról van szó, hogy az eddig alkalmazott ALU:Tex arányt a tervezők nem akarták növelni, így az R600-ban megálmodott felépítés mellett a 160 darab Szuperskalár Shader processzor elhelyezése nagyon problémás lett volna. Gondoljunk csak bele, ha maradt volna a 4 darab Shader tömb, akkor az Arbiter és a Sequencer 40 darab Szuperskalár Shader processzort etetne, ami rengeteg VLIW minta irányítását eredményezné, ezt az Ultra-Threading Dispatch Processzor a jelenlegi formájában nem tudná abszolválni.
(nagyítható)
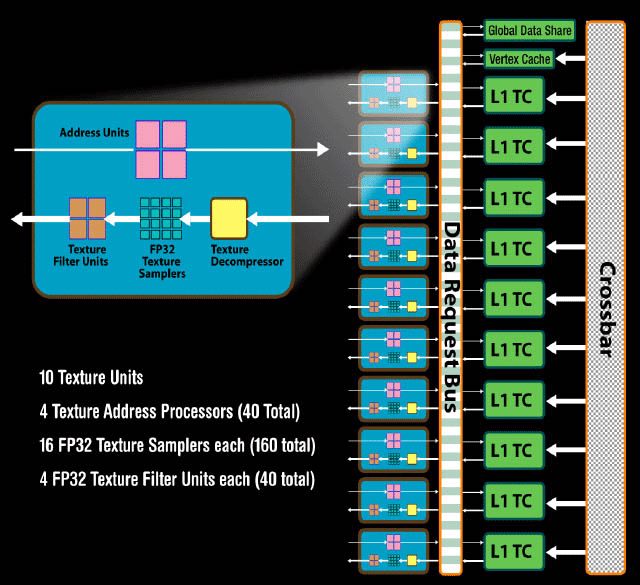
Mint a képen is látható, a 10 darab Textúrázó blokk saját L1 gyorstárt kapott, emellett a blokkok felépítése is átalakult a korábbi generációhoz képest. Az AMD mérnökei ugyanis kivették a szűretlen mintákkal visszatérő csatornát. A butítás magyarázata nagyon egyszerű, az R600-ban ez a csatorna főleg a Vertex Texture Fetch gyors végrehajtásáért felelt. A fejlesztők azonban nem igazán használták ezt a technikát, és nagy valószínűséggel már nem is nagyon fogják, mivel a VTF-fel megvalósítható eljárások az esetek többségében, valamely Geometry Shader alapú algoritmussal gyorsabban is elvégezhetőek. A szűrt mintákat kreáló csatorna felépítése változatlan maradt.
A Shader Export-hoz továbbra is 4 darab ROP blokk kapcsolódik. Minden egyes ilyen blokk kiegészült fejenként plusz 8 darab Z mintavételezővel az előző generációhoz képest, így mostantól már 16 darab foglal helyet a négy Blending egység mellett.
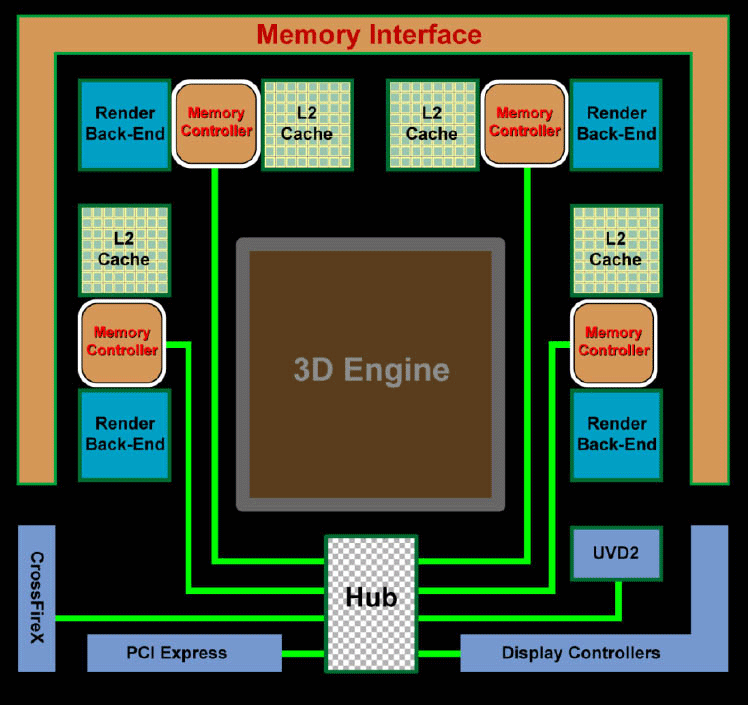
Nem kis meglepetésre új memóriavezérlő mutatkozott be az RV770-ben. Bár az előző generáció Ringbus alapú megvalósítása is bőven felülmúlta a konkurencia technikáját, egyetlen hátránya azonban akadt a rendszernek. Ritka esetekben előfordult, hogy a vezérlés rossz útvonalat választott az adat célba juttatásához, ami meglehetősen magas késleltetést eredményezett.
(nagyítható)
Az új elv egy nagysebességű Control Hub. Ezen egységhez közvetlen kapcsolódik a 4 darab 64bit-es memóriacsatorna, melyekhez egy-egy L2 gyorstár társul. A megoldás lényege egyértelmű, minden esetben minimálisra csökkenteni az elérési időt.
A tesszellátor végre működésben
A programozható tesszellátor már a Radeon HD2000 széria óta része rendszernek, de eddig még nem lett élesben bemutatva a benne rejlő tudás. A Catalyst 8.3-as drivernek köszönhetően, minden akadály elhárult a technológia támogatása elől. Készül is az első futtatható technikai demonstráció „Froblins” néven. A lenti képen jól látszanak a tesszellátor képességei.


(nagyítható képek)
NVIDIA G200 (Shader Modell 4.0)

A G200 GPU a régebbi G80 architektúrára épít. Alapeleme továbbra is a Texture Processor Cluster (TPC), melyből 10 darab került a chipbe. Ezek etetésére természetesen a G80-nál robusztusabb globális ütemezőre volt szükség, ami több tranzisztort is emésztett fel.

(nagyítható)
A TPC-k belső felépítése is megváltozott az eredeti koncepcióhoz képest. A szokásos textúrázó blokk mellett, mostantól nem kettő, hanem három Streaming Shader Processzor dolgozik. A bővítésre minden bizonnyal a programok növekvő ALU:Tex aránya adta az indokot.

A Streaming Shader Processzorokon belül változatlanul 8 darab Stream processzort és 2 darab Speciális Funkció Egység-et (SFU) találunk a G80-nál megszokott elrendezésben. A fő változás, hogy a Stream processzorokhoz tartozó regiszter fájl méretét a tervezők megduplázták. Ezenkívül a G200 számos optimalizációnak köszönhetően sokkal többször képes Dual-Issue módban működni, mint elődje. Az előző cikkben már megemlítettük ennek lényegét, azaz a Stream egységek egy órajel alatt az adaton egy MAD, és annak eredményén egy MUL utasítást is végre tudnak hajtani (az SFU segítésével). A G80-nál azonban ütemezési problémák végett, sok esetben foglalt volt az SFU, így az extra MUL végrehajtása is a Stream processzorokra hárult. A G200 ütemezője azonban a Dual-Issue módban végrehajtható utasításokat kiemelten kezeli, és a lehető legtöbb esetben próbálja kihasználni az SFU számítási kapacitását. Fontos, hogy a Dual-Issue módban futtatható kód nem élvez magasabb prioritást más kódnál, azonban az ütemezőt ért optimalizálásoknak következtében a rendszer kihasználhatósága ténylegesen megnőtt.
A textúrázó blokkokban nyolc textúra címző teljesít szolgálatot 8-8 darab mintavételező és szűrő mellett. A Crossbar memóriavezérlő 512bit-esre bővült, ami 8 darab 64bit-es csatornára oszlik. Minden csatorna egy-egy ROP blokkhoz csatlakozik, melyek felépítése teljesen megegyezik a G80-nál leírtakkal.
Stream out probléma megoldva
Az architektúra ezen része meglehetősen fontos változáson ment keresztül a tervezés során. Szemlátomást gyenge pont volt a G80 működési elveiben a nagy mennyiségű Stream Out adat kezelése. A G200 belső gyorstárainak összmérete, az elődhöz képest közel hatszorosára lett növelve. Ezzel tulajdonképpen elegendő hely lett teremtve az ideiglenes stream out adatok tárolására. Az alkalmazott megoldás mégis érdekes. Működés szempontjából nyilván rendben van a dolog, de amit anno a zöldek "kispóroltak" a G80-ból, azt most aránytalanul nagy tranzisztortöbblettel volt lehetőség beépíteni. A chip gyártásának elemzésénél látható lesz mekkora problémát jelent ez.
Direct3D 10.1 támogatás még mindig nincs
Persze sokan gondolhatják, hogy nincs is rá igény, mert nem használja ki semmi. A D3D10.1 valójában nem igény kérdése, a technológiára elsősorban szükség van. Egyre több fejlesztő ír Deferred Rendering elven működő leképzési algoritmust. Márpedig az ehhez hasonló kódoknál a manapság használatos Multi-Sampling Anti-Aliasing nincs támogatva. Jelenleg három megoldás lehetséges:
A legjobb a D3D10.1 API-ba épített eljárás, a Multisample Access. Ennek segítségével az AA számításhoz szükséges szín- és mélységinformációk (Color Subsample és Z Subsample) bármikor elérhetőek, így lehetséges egyéni, shader alapú AA rutint írni a programba, ami akár a Deferred Rendering fázissal párhuzamosan is futhat (ez a sebesség szempontjából nagyon előnyös). A D3D10-ben csak a színinformációk érhetők el ami megnehezíti a dolgokat, mert szükségesek a mélységinformációk is. Ehhez egy speciális kódot kell írni, ami kimenti a Z adatokat egy Render Target textúrába. Emellett persze külön fázist igényel a shader alapú AA számítása is. Az eredmény tulajdonképpen ugyanaz lesz mindkét megoldás esetén, csak a DX10 mellett a fejlesztőnek többet kell vele dolgozni, és lassabb is az eljárás sebessége az extra fázis végett. A harmadik opció egy kényszermegoldás. Ennek a neve Deferred SuperSampling. Lényege a dolognak, hogy egy éldetektáló shadert futtatnak a képkockán, és ahol él található ott blur shaderrel lesznek elsimítva a „recék”. Ez az eljárás azonban iszonyat teljesítményigényes. A rengeteg számítás átlagosan 50-80%-os teljesítményvesztést is eredményezhet, viszont nem szükséges hozzá a D3D10 API használata.
Mivel a G200 nem rendelkezik D3D10.1 támogatással, így a Multisample Access használata sem lehetséges a hagyományos úton. Ezt CUDA támogatással próbálják ellensúlyozni, ami lehetővé teszi a szín- és mélységinformációk elérhetőségét. A probléma azonban a PC-s játékipar helyzete. A fejlesztők egyszerűen nem látnak akkora pénzt a piacban, hogy a minimálisnál nagyobb erőfeszítés mellett írják át a konzolra kiadott programjaikat. Az egyes felmerülő problémákra mindenképp a lehető legegyszerűbb megoldást fogják választani, ami jelen esetben a D3D10.1 Multisample Access használata. A jövőben sajnos nemegyszer elő fog fordulni az az esemény, hogy az NVIDIA termékpalettáján még a méregdrága GeForce 200 széria sem lesz képes az Anti-Aliasing támogatására.
RV770 kontra G200 gyártási költségek
Mivel az utasítás- és a mikroarchitektúra szintjén már felületesen ismerjük a két rendszert, érdemes új vizekre evezni. Főleg annak tudatában, hogy eszközszinten sok eltérést találunk. Talán azzal nem mondok újdonságot, hogy a mai chipek nagyon sok tranzisztorból épülnek fel. Ez a szám az RV770-nél nagyjából 956 millió, míg a G200-nál 1,4 milliárd körül alakul. A gyártástechnológia is az AMD-nek kedvez, mivel ők 55nm-es csíkszélességet használnak, míg az Nvidia 65nm-rel dolgozik. Egy kissé bonyolult számítással és némi átváltással a két adatból ki fog jönni, hogy az RV770 256mm² alapterületű, szemben a G200 576mm²-es értékével.

(nagyítható)
Most, hogy tudjuk a chipek területét, megismerkedhetünk a wafer-ral. Ezt az alapanyagot használják a chipek gyártásához. Szerencsére mindkét cég a TSMC gyártósorait használja fel, és ugyanúgy 300mm-es wafer-ral dolgoznak, tehát az anyagköltségek mondhatni megegyeznek. Egy ilyen wafer ára 5000 dollár körül van, ami bizony nem kis pénz. Az adatok tudatában kiszámolható, hogy egy 300mm-es wafer-ből 95 darab G200-at, míg RV770-ből 222 darabot lehet gyártani. Ha a gyártás hatékonysága 100%-os lenne, akkor már most is eloszthatnánk a darabszámmal a wafer árát, de nem tesszük, mert selejtarány mindig van. Ez az a pont ahol tudományos megközelítésünk megfeneklett, mivel nincs hivatalos információnk a hibaszázalékról. Mostantól csak a kiszivárgott információkból élhetünk. Reálisnak tűnik az az adat, hogy a G200-at kb. 35-45%-os hatékonysággal lehet gyártani, míg az RV770-et kb. 75%-ossal. Ebből már könnyen kikalkulálható, hogy egy eladható G200 ára 120-150 dollár, míg az RV770-é 30 dollár körül alakul. Az árkülönbség elég nagynak mondható, főleg annak tudatában, hogy a G200-ra épülő legerősebb GeForce grafikus vezérlő teljesítménye alig 25%-al jobb a legerősebb RV770-es kártyáénál.
Multi-GPU stratégia
Az utóbbi időkben elszaporodtak az úgynevezett Multi-GPU-s megoldások is. Az NVIDIA az SLI, míg az AMD pedig a CrossFire technológiára építkezik. Mivel a grafikus feldolgozás során nagyon jól párhuzamosítható a munkavégzés, nem meglepő, hogy mindkét cég lát jövőt az elképzelésben. Az AMD a CrossFireX megjelenésével már csak az AFR (Alternate Frame Rendering) módot alkalmazza, míg az Nvidia meghagyta alapértelmezettnek az SFR-t (Split Frame Rendering) is. A Radeon HD3000 szériával azonban egy érdekes stratégiát is felvállalt az AMD. Az elgondolás lényege, hogy a piac felsőkategóriáját olyan VGA-val célozzák, ami két GPU-t tartalmaz egy nyomtatott áramkörön. Az ötlet tulajdonképpen a mostani viszonyok közt nagyon is kifizetődött, hiszen 2 darab RV770 gyártási költsége meg sem közelíti egy G200-ét, de a CrossFireX technológia hatékonysága az esetek nagy többségében magasan az Nvidia zászlóshajója fölé repítheti a Multi-GPU-s megoldás teljesítményét. Persze az AFR alapú feldolgozásnak vannak buktatói is. Erre a DX10-ben bemutatkozó Stream Out eljárás nagyszerű példát szolgáltat. Az AFR alapon dolgozó GPU nem az egymás után következő képkockák számításáért felel. Tehát két GPU esetén minden második, három GPU esetén pedig minden harmadik képkockát számolja egyazon grafikus processzor, és így tovább. A Stream Out eljárás használata mellett olyan adatokra is szükség van, amit az előző képkocka kalkulálása alatt mentett ki a rendszer. Tehát a Stream Output tartalmát valahogy el kell juttatni a „szomszédos” GPU-ba, ami bizony nem egyszerű feladat. A CrossFire Bridge 0,9 GB-os sávszélessége ugyan elegendőnek tekinthető az összekötött GPU-k ezirányú kommunikációjára, de a Stream Out adatok célba juttatása speciális rutinok elkészítését követeli majd a meghajtóprogram fejlesztőitől. Ennek ellenére az AMD lelkesedése töretlen.
Fontos megjegyezni, hogy az RV770 chipbe integrálásra került, a Rambus FlexIO rendszer alapjaira építkező, CrossFire Sideport nevű kommunikációs csatorna. A jelenlegi, Radeon alapú Multi-GPU kártyákon azonban ez még nincs aktiválva. Valószínűleg kísérleti jelleggel döntöttek a beépítés mellett a kanadaiak, ami arra enged következtetni, hogy a következő generációs fejlesztéseknél a fenti technológia nagyon fontos szerepet fog majd betölteni.
Hova tovább NVIDIA?
Az RV770 jelenlegi győzelme kétségtelen, de talán érdemes elgondolkodni, mire is lehet számítani az NVIDIA-tól a közeljövőben. Már bejelentették, hogy gőzerővel készül az 55nm-es G200 verzió. A baj csak az, hogy a cég még ezzel sincs kisegítve, hiszen a legjobb esetben is csak 30 dollárt lehet spórolni chipenként, és ez még mindig messze van az RV770 költségeitől. Ezek mellett több chip is átesik gyártástechnológia váltáson, ami arra enged következtetni, hogy nincs az NVIDIA kezében új architektúra, márpedig jelen pillanatban ez az egyetlen lehetőség a kontrázásra. A G80 architektúráról az előző cikkben sem volt jó véleményem. Az R600-hoz viszonyítva rendkívül „fapados” rendszernek minősül. A Direct3D10.1 támogatása pedig még sok tranzisztor beépítését követeli a zöldektől. Az AMD azért került vissza a csúcsra, mert most jött ki az R600 alapelvének az előnye, ami egy minden szempontból egyenletes teljesítményt nyújtó rendszer, a lehető leggazdaságosabb felépítéssel. Mindemellett kis befektetések árán is drasztikusan lehet növelni a rendszer teljesítményét. Persze nem csak a piac felsőkategóriája van veszélyben. A HD3000 szériás Radeonok elég olcsók lettek, hogy meggyőzzék a „kispénzű” vásárlókat is. Az olcsóbb GeForce rendszerek alacsony ALU:Tex aránya is komoly hátrányt okozhat a jövőben (különösen a Geforce 9600GT kártyák tulajdonosai vannak veszélyben). A fejlesztők egyértelmű szándéka az ALU:Tex arány növelése, amit az NVIDIA a G200-as chipjével tulajdonképpen alá is írt.
Kicsit ironikus a helyzet, hiszen nemrég halhattunk olyan nyilatkozatokat az NVIDIA emberkéitől, amik kimondták, hogy az AMD „vesztett”, most pedig azt látjuk, hogy egyetlen piaci szegmensben sem tudnak versenyképes technikát felvonultatni a zöldek. A kiút egyértelműen a Multi-GPU-s megoldások felé vezet, ha teljesítményben nem is fogható be az AMD, a kisebb méretű chipek mellett sokkal jobban lehet játszadozni az árakkal. Éppen ezért nem lepne meg, ha a következő Geforce GPU egy középkategóriába fejlesztett Direct3D11-et támogató chip lenne. Kérdés, hogy ez mikor fog megjelenni, hiszen az eddig alkalmazott „betonbiztos” stratégiát, a semmiből előtörve alapjaiban rombolta le a „vörös hadsereg”.





