


Kapcsolódó leírások (szükséges lehet a cikk megértéséhez):
Architektúra fogalomtár / Processzor fogalomtár / Memória fogalomtár / Grafikus fogalomtár
Ki gondolkozott már el azon, hogyan is történik a képkockák kiszámítása egy-egy három dimenziós grafikával rendelkező program futtatásakor? Valószínűleg nem sokan, hiszen ez nem a felhasználó feladata. Vásárlásnál viszont minden bizonnyal meglepően sokszor átgondoljuk, mire költsük kemény munkával összekapart pénzecskénket. Márpedig aki tartani akarja a lépést a fejlődéssel viszonylag sokszor kényszerül újítani valamit a masináján. A grafikus kártya az IBM PC piacának legdinamikusabban fejlődő komponense, teljesítményük generációváltásonként gyakorlatilag megduplázódik. Ilyen ütemű fejlődés mellett csak akkor tudunk megfelelően választani, ha állandóan lépést tartunk a rendszerek fejlődésével. De ne is rohanjunk ennyire előre, első lépésként inkább vegyük át a kép számításának aprólékos lépéseit.
A képkocka számításának lépései
A feldolgozás menete több egymástól függő lépésre osztható. Ezek sorrendben a következők: program számítási feladatai (Application tasks), képkocka információk számítása (Scene level calculations), transzformáció és megvilágítás (Transform and Lighting), háromszögek beállítása és levágása (Triangle Setup and Clipping), Renderelés (Rendering).
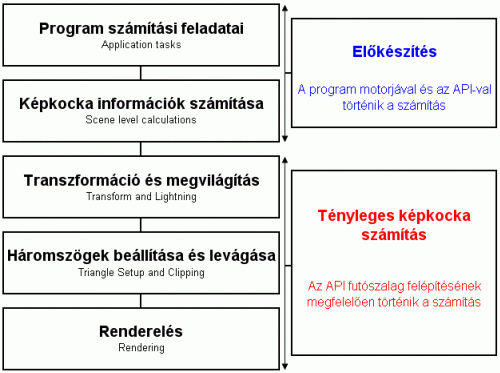
Program számítási feladatai (Application tasks): A futtatott program irányítja a tárgyak és a nézőpont mozgását, illetve ezek egymással történő kölcsönhatását. Általában az alkalmazás ezen elemét hívjuk motornak. Minden egyes képkocka alapja egy kimentett részlet, a teljes virtuális világ adott pontjában lemodellezett állapotából. Ezen információk segítségével akár már el is kezdődhetne a tényleges geometriai rajzolás, azonban ennek egyelőre nem sok értelme lenne. Logikusan átgondolva miért is pazarolnánk erőforrást olyan objektumok leképezésére, amit a felhasználó a meghatározott nézőpont alapján lényegében nem is lát. Mivel a világ interakciója ezen a ponton már lemodellezettnek tekinthető, a továbbiakban már csak az a lényeges, hogy a nézőpontban látható információkat átadjuk a program használójának.
Képkocka információk számítása (Scene level calculations): Mindent alárendelünk a kamera látómezejének, ami ebbe a térbe nem tartozik bele, azzal nem foglalkozunk a továbbiakban. Ezt az eljárást nevezzük kiválogatásnak, azaz culling-nak. Az érdemi munka elkezdése előtt már csak egy feladat van hátra, a LOD (Level Of Detail), magyarul a részletességi szintek meghatározása. Erre azért van szükség, mert egyes modellek annyira messze vannak a nézőponttól, hogy a képkockán csak néhány pixelnyi helyett foglalnának el. Ilyenkor nincs értelme a legrészletesebb modellt használni a leképezésnél, mert érdemben nem lenne látható különbség az alacsonyabb részletességű verzióhoz képest. Az alacsonyabb részletességű modell, viszont kevésbé terheli a rendszer erőforrásait, így sebességet nyerünk a használatával. Minden információ rendelkezésre áll a tényleges képszámítás megkezdéséhez. Ezek úgynevezett objektumok formájában jutnak el a feldolgozás következő szintjére.
Transzformáció és megvilágítás (Transform and Lighting): Ezen a szinten az objektumadatokból ténylegesen kirajzolható a geometria. Ehhez meg kell határozni a vertex-ek helyét. Ezek lesznek a háromszögek, poligonok csúcspontjai. Egy vertex térbeli meghatározásához három koordináta szükséges (x, y, z). Az egy objektumhoz tartozó vertex-eket összekötve kapjuk az aktuális modell geometriai vázát. Ezután a modellek az aktuális nézetnek megfelelően lesznek transzformálva (forgatva illetve méretezve), továbbá leképezésre kerül a megvilágítási modell.
Háromszögek beállítása és levágása (Triangle Setup and Clipping): Ez a szint kiszámítja a szükséges paramétereket a renderelés elvégzéséhez, és levágja a nem látható háromszögeket az egyes modellekről, illetve azok mögül.
Renderelés (Rendering): A képkocka számításának legfontosabb része. Többféle algoritmus létezik a képszámítás utolsó szakaszára, jelen esetben a raszterizálás lesz tárgyalva. Jelenleg kész van egy háromdimenziós tér egy nézőponttal, viszont egy a monitor által emészthető képkockára van szükség. Ideje egy „fényképet” készítenünk eddig végzett munkáról. Ehhez először fel kell textúrázni a geometriai vázat, majd meghatározni a végső pixel színét, ezt az eljárást raszterizációnak nevezzük. A Pixel színének számításához az alpixelek (fragment-ek) értékeire van szükség. Minden pixel négy alpixelből áll, ezek rendre: piros, zöld, kék, átlátszóság. Először is meg kell határozni a Z-Buffer eljárás segítségével, hogy melyik poligon fedetlen az adott pixelen. Ha ez megtörtént, akkor egyéb számítások és hatások mellett, az alkalmazott szűrésnek megfelelően, a poligont fedő textúra texeljeiből, pontosabban altexeljeiből, kiszámítjuk az alpixel színét. Egy pixel rengeteg texelt magába foglalhat, ezért szűrést kell végrehajtani a jó minőségű eredmény érdekében. Mivel a teljes pixel színét az alpixelek határozzák meg lényegében kész is van a számítás. Már csak egy végleges képkockává kell alakítani az információkat (blending). A végső képkockát a frame bufferbe kell helyezni, ezt a megfelelő időben a monitor jeleníti meg.
A motor és az API
Minden háromdimenziós program alapja egy úgynevezett motor. Ez felel lényegében a teljes rendszer működésért. A megjelenítésért felelős rutinokat, egy vagy több grafikus API-ra írják meg. Ez egy olyan interfész, ami kapcsolatot létesít a program és a videokártyát vezérlő meghajtó (driver) között. Ez lehetőséget teremt a fejlesztőnek olyan programok írására, amely bármely, az API-t támogató hardveren lefut. Mára két ilyen rendszer maradt életben, a Microsoft által fejlesztett DirectX és a SGI keze alatt megjelent OpenGL. Mindkettő rendkívül elterjedt platform, de az idők során a Microsoft marketing és fejlesztési tevékenységének köszönhetően a DirectX került fölénybe. A cikk további részében ennek az API-nak a fejlődésével fogunk foglalkozni.
A grafikus chipek fejlődése
Fentebb vázolva lett, hogy a képkocka számítása több összefüggő lépésben történik. Ezeket a CPU (központi processzor) és a Grafikus chip (a DirectX 7-től kezdve GPU, azaz grafikus processzor) számolja. A kezdetekben a renderelésen kívül minden szint számítása a CPU-ra hárult, de a fejlődő grafikus chipek egyre okosabbak lettek, és az évek során fokozatosan átvették a képkocka számításának terheit.

[+]
Látható, hogy a hetedik DirectX generációtól kezdve, megjelent az úgynevezett hardveres T&L támogatás, ezzel teljesen a videokártyára háríthatók a tényleges képkocka számítás szintjei. Ettől a ponttól nevezhető igazán a grafikus chip, grafikus processzornak (GPU). Azonban meglehetősen komoly korlátjai voltak az ilyen rendszereknek. A legnagyobb probléma az volt, hogy a GPU egy előre „bedrótozott” algoritmust használt a transzformáció és megvilágítás szintjének kalkulálásához. Ha valaki ki akarta használni az új videokártyában rejlő erőforrást, meg kellett elégednie egy alapértelmezett számítási modellel. Bár a fejlesztők örültek az újdonságoknak, mégis szomorúan vették tudomásul, hogy az alkotói szabadság némileg behatárolt volt. A következő generáció viszont mosolyt csalt az orcájukra.
Shaderek (árnyalók)
A programozók igazi messiásként várták a DirectX 8.0 megjelenését, az új API a történelemben először ad lehetőséget a „beégetett” eljárások mellőzésére. Alapjaiban arról van szó, hogy a fejlesztő a saját ötleteire támaszkodva árnyalási algoritmusokat programoz le, és ezek alapján történik a leképzés. A következő, kilencedik generációs DirectX szabvány is a nyolcadik generációban lerakott alapokra épít, csak némileg kibővítve a lehetőségeket. Az árnyalók fejlődésének szakaszait Shader Modell szabványokban határozták meg. Minden egyes verzió kibővítése az előző rendszernek, ennek megfelelően a modellek visszafelé kompatibilisek egymással.
Shader kódot mára egyszerűen lehet írni a magas szintű nyelvek segítségével. Ilyen nyelv például az AMD-Ati ASHLI, és az nVidia cg. Azonban elterjedtebbek az API-k saját megvalósításaik, mint a DirectX HLSL, vagy OpenGL GLSL. A magas szintű nyelvben leírt kódot, egy complier (fordító) segítségével lefordítjuk a grafikus kártyák meghajtójának megfelelő assembly típusú nyelvi szintjére. Ezután a driver (természetesen optimalizálással), a GPU-nak is emészthető gépi kódra fordítja az algoritmust.
A grafikus processzorok architektúrája jellemzően RISC elvű, ennek megfelelően az utasításkészlet viszonylag kisméretű. A shader kódok utasításai három csoportra oszthatók: számláló, textúrázó és vezérlő. Teljesítmény szempontjából az általános számláló utasításokon van a hangsúly, ezek rendre a következők: ADD (x+y), MUL (x*y), MAD (x*y+z) - az x, y, z változó, pixel shader kód esetén lehet az alpixel szín- vagy átlátszóság értéke, vertex shader kódnál pedig a vertex koordinátáit tárolják). Az adattípusok különböző Shader Modell szabványoknál eltérőek lehet. A 2.0-ás verzió esetén vertexre FP32-es (azaz 32bit-es lebegőpontos), alpixelre pedig FP24-es pontosságot használ. 3.0-nál már mindkét elemre FP32 van előírva.
Az egyes pixel és vertex shader verziók különbségeit az alábbi táblázatok foglalják össze:

Vizsgálódások
Az elméleti rész felületes ismeretének tudatában itt az ideje megvizsgálni egy pár GPU felépítését. Természetesen a grafikus kártyák „őskora” nem kerül tárgyalóasztalra, de a népszerű DirectX9-es rendszerek nem ússzák meg a kivesézést. A 2002-ben megjelenő API igen hosszú életűre sikerült, három generáción át ellátta feladatát. Minden új architektúrát az első megjelent chippel fogok bemutatni, de ha a fél évvel későbbi ráncfelvarrás komolyabb újdonságokat hozott, akkor kitérünk a javított chip elemzésére is. Mivel főleg felépítés vizsgálata lesz a téma, így a GPU-kat kódnevük szerint nevezem, de természetesen leírom melyik kártyán kaptak helyet a chipek.
Első generáció
ATi R300 (pixel shader 2.0, vertex shader 2.0)

A kanadai gyártó fennállásának legnagyobb eredményeit elérő grafikus processzora 2002 szeptemberében jelent meg, és a Radeon 9700 típusú kártya alapját szolgáltatta. Gyakorlatilag 3 hónappal megelőzte az új DirecX9-es API kiadását, de már teljes mértékben támogatta azt. A chip négy vertex shader processzorral rendelkezett. Minden egyes ilyen egység tartalmazott egy FP32-es Vec4+Skalár ALU-t MAD, MUL, ADD utasítások támogatásával. (A Vec4 az négykomponenses vektort jelent, az ilyen egység egy órajelciklus alatt négy adaton tudja végrehajtani egyazon utasítást. Nyilván a Vec2 és Vec3 az kettő- illetve háromkomponenses ALU, az egy komponenst feldolgozó egységeket pedig skalár ALU-nak nevezzük.) A vertex shader ALU-k felépítése a DirectX 9.0 alatt nem igazán változik, egyszerűen a fentebb vázolt kialakítás a leghatékonyabb erre a területre.
Pixel Shader futószalagból nyolc darab kapott helyet a chipben, négyes csoportokba rendezve. Felépítésük relatíve egyszerű, de ez tette hatékonnyá a rendszert. A teljes egység két részre osztható, az első rész végzi a fő számításokat, míg a második, úgynevezett mini-ALU adatmozgató és adatmódosító feladatkört lát el. A fő ALU 3+1 Co-issue képességű, ami azt jelenti, hogy egy órajelciklus alatt két egymástól nem függő utasítás is elvégezhető (az R300-ban azonban megkötés, hogy a skalár feldolgozó csak MUL utasítást képes végrehajtani). Minden pixel shader processzorhoz egy ROP egység tartozik, ezek fejezik be a renderelést.
A memóriavezérlőt is átalakították az előző generációhoz képest. Egyrészt az eddig egysávos rendszerről átváltottak Crossbar-ra. Ez azt jelenti, hogy az adatok nem egy széles buszon közlekednek, hanem több kisebb sávszélességűn, valamelyest növelve a hatékonyságot. Másrészt összesen 256bit-es lett a szélessége, amely 4 darab 64bit-es részre lett osztva.
NVIDIA NV30, NV35 (pixel shader 2.0a, vertex shader 2.0a)

A zöldek óriási marketingtevékenység közepette mutatták be 2003 elején a GeForce FX szériát. Az NV30-ra épülő FX5800 már az első tesztek alkalmával kudarcot vallott az ellenfél lefegyverzésében, de a történet itt még koránt sem ért véget. A chip három vertex shader processzort tartalmazott, amelyek lebegőpontos sorba voltak kötve. Ennek a módszernek az előnye, hogy csökkenti a Setup időt (ilyenkor méri fel a Setup motor, hogy milyen feladatok érkeztek).
Pixel futószalagok tekintetében szépen elferdítették a valóságot, ugyanis a legtöbb technikai bemutatón nyolc darabot füllentettek. Ez azonban ebben a formában nem igazán állta meg a helyét. Valójában négy futószalagos volt a rendszer egy ügyes, de nem teljesen logikus trükkel, az úgynevezett „Z-only” rendereléssel. Ez tipikusan akkor jött jól, amikor a program Stencil buffert használt az árnyékok leképzésére. Ilyenkor a chip egy pixelen két műveletet tudott elvégezni. A probléma ott ütötte fel a fejét, hogy nagyon kevés program renderelt így (akkoriban talán a ID Tech 4 motorra épülő játékok voltak az egyedüliek – Doom 3).
Mind a négy futószalag egy darab, rendkívül bonyolult felépítésű pixel shader processzorral büszkélkedett. Ez elég sokáig rányomta a bélyeget a teljesítményre, ugyanis a meghajtó fordítóprogramja eleinte nem tudott olyan VLIW mintákat előállítani, amely hatékonyan használja a rendelkezésre álló erőforrásokat. A fő ALU-hoz két textúrázó kapcsolódik, azonban fontos megjegyezni, hogy a fő egység és a textúrázok, egyszerre nem működhetnek. Tovább haladva két darab FX12-es (12bit-es fixpontos) mini-ALU található, ezek különlegessége, hogy órajelciklusonként két MUL utasítást tudnak végrehajtani. A két 64bit-es részre bontott (összesen 128bit-es) memóriabusz sem adott bizakodásra okot, de ellensúlyozva a szűkös sávszélességet gyors DDR2-es memóriákat kapott, ez azonban igen drágává tette a kártya gyártását.

Az nVidia hamar ráeszmélt, hogy nem sok esélye van az R300 ellen. Magyarázkodás helyett az NV30 átszabása mellett döntöttek, és rekordidő alatt tálalták az NV35 nevű újdonságukat. Őkelmének azonban már a ráncfelvarráson átesett R300 utóddal kellett szembeszállnia. A főbb változtatások két szemlátomást gyenge pontra irányultak. Megnövelték a memóriabuszt 256bit-esre (a csatornák továbbra is 64bit-esek maradtak), és átdolgozták a pixel shader processzorok felépítését. Az új egységekben lecserélték az FX12-es mini-ALU-kat FP16/FP32-esekre. Ezek majdnem olyan képességekkel rendelkeztek, mint a fő ALU, de egy ponton gyengébbek. A MAD utasítást ugyanis csak FP16-os precizitás mellett képesek abszolválni. A változtatások rögtön éreztették hatásukat a teljesítményben, így reálisan versenyképes alternatívának látszottak az új 5900-as jelzésű FX kártyák. Teljesítményük azonban a Shader kódok futtatása esetén nem volt elfogadható. Minél komplexebb algoritmus futtattak rajta annál nagyobb volt a hátrány a konkurencia modelljeihez képest.
Az okok vizsgálatánál érdemes abból kiindulni, hogy mi a legszembetűnőbb különbség az aktuális Radeon és GeForce között. Az ábrák alapján rögtön adja magát az ALU-k precizitásának eltérése. A DirectX9 szabvány, pixel shader esetén FP24-es pontosságot követel meg, amit az R300 család maradéktalanul be is tart. Az Nvidia megoldása azonban pont ezt a módot nem támogatja, helyette az FP32-es precizitást vezette be. Ez első pillantásra nem baj, hiszen az API követelményeit nemhogy kielégíti, de még felül is múlja. Jobban átgondolva azonban komoly problémák adódhatnak. A Shader Modell 2.0 pixel shaderre vonatkozó előírásai 12 darab általános regisztert követelnek. Ez a feltétel lényegében teljesül is, de ha FP32-es precizitássál történik a számolás, akkor az adatút 256bit-es szélessége elég szűkös, hiszen csak két 128bit-es (32bit komponensenként) operációt lehet végezni, így egyes utasítások elvégzése két órajelciklust vett igénybe. Mivel a GPU nem támogatta az FP24-es minimum előírást kénytelen volt jobb minőségű módban dolgozni, a képminőség elfogadható szintet tartása végett. Ennek megfelelően a teljesítmény meglehetősen alacsony lett. Az Nvidia két „megoldást” próbált bevetni. Az egyik, hogy a pontosságot lecsökkentik FP16-ra, ezzel ténylegesen gyengébb minőségű képet állítanak elő a konkurenciánál, de legalább gyorsan futott a program. A másik lehetőség sokkal komplikáltabb volt, a meghajtó fordítóprogramját úgy programozták, hogy minimális alkalommal ütközzön a számítás a fentebb vázolt szűk keresztmetszetbe. Egyik módszer sem vált be igazán, de ahhoz elég volt, hogy a teljesítménytesztek eredményeit pozitív irányba manipulálják, ezzel a lehető legkisebb veszteséget felmutatva kihúzzák a következő generáció megjelenéséig.
Második generáció
ATi R420 (pixel shader 2.0b, vertex shader 2.0)
Az 2004 tavaszán debütáló új generációs Ati architektúra nem változott komoly mértékben az R300-hoz képest, mivel a kanadaiak abban az időben gőzerővel munkálkodtak az XBox360 Xenos nevű, forradalmian új elvekre épülő grafikus processzorán. Tulajdonképpen az új chip a régi kibővített változata, 256bit-es (64bit-es csatornákkal) Crossbar memóriavezérlővel, 6 vertex és 16 pixel shader processzorral. Kereskedelmi forgalomba Radeon X800 néven került. Az egyetlen érdemleges újítás a saját fejlesztésű 3Dc textúratömörítés, amely a szokásos 4:1 arányú tömörítés mellett kimagaslóan jó képminőséget biztosít.
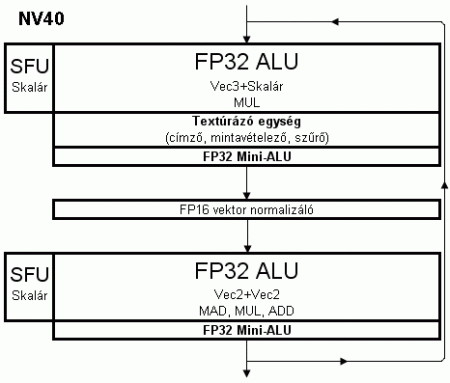
NVIDIA NV40 (pixel shader 3.0, vertex shader 3.0)
Sokkal komolyabb fejlesztéseken esett át, az R420-hoz hasonlóan, szintén 2004 tavaszán befutott, új Nvidia chip. Nevéből elhagyták a rossz emlékű FX jelzőt, és szimplán GeForce 6-nak nevezték el. Az NV40 alapjaira építkező 6800-as sorozat volt az első teljesen DirectX9.0c kompatibilis grafikus kártya. A felújított API-ban jelent meg először a Shader Modell 3.0-s verziója, amely jelentősen kibővítette az árnyalók lehetőségeit. A chipben található hat vertex shader egység legfontosabb újítása, hogy képesek voltak a textúrából történő mintavételezésre, ezzel lehetőséget teremtettek a vertex textúrázásra (Vertex Texture Fetch). Vitathatatlanul az új szabvány legnagyobb újítása volt ez. A technológia lényegének a megértéséhez azonban ne olyan textúrákra gondoljunk amelyek „tapétaként” feszülnek a felületeken. Sokkal inkább információs térkép szerepét töltik be. Ezek segítségével elmozdíthatóak a vertex-ek a pozíciójukból, az elmozdulás mértékénél a Displacement map tartalmára hagyatkozik a feldolgozó egység. A régebben megjelent Matrox Parhelia GPU is rendelkezett egy hasonló lehetőséggel, de ott egyfajta virtuális megoldásról volt szó, eltorzította az objektumok megjelenését, de nem javította a geometriai részletességet (ehhez megjelenésben hasonló eljárás a Relief vagy a Parallax Occlusion mapping). Persze a tényleges eredmény rendkívül meggyőző volt a Matrox esetében is. A vertex textúrázás számtalan lehetőséget teremt a látvány élethűvé varázsolásához, lehetőség van például a virtuális sárban megjeleníteni egy autó keréknyomait, vagy esetleg vízhullámok szimulálására is megfelel a technika. Erre az alábbi ábra szolgál például.

A pixel shader processzorok is jelentős változtatásokon estek át. Számuk immár 16-ra nőtt, és négyes csoportokba rendeződtek. Felépítésüket alapjaiban átgondolta az Nvidia, és kivételesen hatékony rendszert alkottak. Az új elv egy komplex és hosszú csővezeték. Ennek megfelelően két fő FP32-es ALU kapott helyet. Az első ALU-hoz kapcsolódik textúrázó egység, amely kimeneti adataival rögtön végezhet egy műveletet a második ALU. Fontos, hogy az első ALU csak MUL utasítást volt képes elvégezni, ami némileg korlátozta a használhatóságát. Az új futószalag mindkét egysége Co-issue képességű, az első 3+1, míg a második 2+2 módot használhat. Amennyiben a két ALU egy órajelciklus alatt két különböző Co-issue módban működik azt Dual-issue módnak nevezzük.
Mindkét fő ALU-hoz tartozik még egy SFU (amely komplex műveletekre jelentett megoldást, mint például az 1/x és a 2^x ) és egy mini-ALU (a Radeon-nál megszokott adatmozgató és adatmódosító műveleteket végzi). Megpillantható még egy új FP16-os vektornormalizáló (NRM) egység is. Ez a normal mapping használata esetén lehet teljesítménynövelő hatású.
A memóriavezérlő maradt az NV35-ben bevezetett négy csatornára osztott 256bit-es Crossbar.
Dynamic Branching
Egy statikus branching-gal működő GPU nagyon pazarló a pixel shader kódok futtatása alkalmával, mivel azt az összes pixelre lefuttatja. A Pixel Shader 3.0 szabványban megjelenő dinamikus branching esetén lehetőség adódik a kódot többnyire azokra a pixelekre alkalmazni, amelyeknél érdemi eredménye is van a számolásnak.
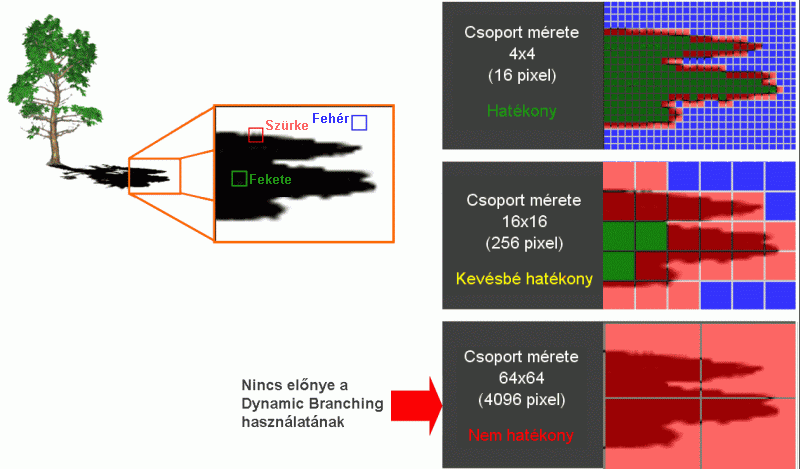
(nagyítható)
A fenti kép szemlélteti a lényeget. A feladat, hogy lágy szélű, azaz valósághű árnyékokat kell létrehozni (ha ezt nem tesszük meg akkor az eredeti árnyék széle rendkívül éles lesz, ami eléggé illúzióromboló). A dinamikus branching esetében a shader kód úgynevezett batch-ekre, jelen esetben pixel tömbökre lesz futtatva. A számítás szempontjából csak az árnyék széle a fontos, hiszen ez a terület lesz az átmenet az árnyékos és az árnyékon kívüli rész között. Ha egy fontos pixel beleesik az előre meghatározott méretű batch-be akkor arra a pixel tömbre le kell futtatni az algoritmust. A batch mérete teljesen a GPU képességeitől függ. Minél kisebb tömböt képes feldolgozni annál jobb lesz a hatásfok. A NV40 architektúra ebből a szempontból eléggé sebezhető volt, mivel a hosszú csővezeték elve miatt igen nagy pixel tömbökön dolgozott.
Harmadik generáció
NVIDIA G70 (pixel shader 3.0, vertex shader 3.0)
2005 közepén startoló G70 nem más, mint egy kibővített NV40. Komoly változásokra nem volt szükség. A memóriavezérlőt ennek megfelelően érintetlenül is hagyták, ám a „több nyers erő mindig jól jön” elvnek megfelelően a vertex shader egységek számát 8-ra, míg a továbbra is négyes blokkokba rendeződő pixel shader egységekét 24-re növelték. Minimálisan azért belenyúltak a pixel shader processzorokba. Az új első fő ALU a MUL mellett, már a MAD és az ADD utasításra is képes volt. Érdekes azonban, hogy a ROP egységek száma (16 darab) alacsonyabb lett a pixel shader egységekhez képest. Ezt azért volt célszerű meglépni, mert egyre kevésbé befolyásolták a valós teljesítményt. A Fill-Rate értékek ugyanis már nem képeztek szűk keresztmetszetet az új GPU-kon.

Dynamic Branching dilemma
A Geforce 6-ban bemutatkozó új branching technikával az előnyök mellett sikerült egy nagy hátrányt is teremteni. Ennek megértéséhez vissza kell menni a kezdetekhez, amikor a renderelés pusztán a textúrák „kifeszítésén” alapult. Ahhoz, hogy a textúra felkerüljön a helyére, meg kell címezni, azaz meg kell találni a memóriában. Mihelyst meghatározásra került a címe, be kell tölteni. Ezt nevezzük texture fetch-nek. Eddig teljesen jól állnak a dolgok, de egy probléma merül fel. A memória a grafikus processzor feldolgozásához képest lassú, ennek következtében a texture fetch időbe kerül. Ezt hívjuk elérési időnek. Ennek mértéke függ a memória képességeitől, de átlagosan 80-100 nanoszekundumot veszít vele a GPU, mivel adat nélkül nem lehet dolgozni. A legtöbb GPU azonban képes előbetöltésre, ha ez sikeres volt, akkor a következő címzés tartalma megtalálható lesz egy, a chipbe helyezett kisméretű gyorstárban, így az elérési idő töredéke ment kárba. A módszer jól alkalmazható volt a textúrákhoz, azonban a mai komplex grafikát előállító rendszereknél a shaderek is adatot követelnek a futáshoz, és ezeket jellemzően információs térképekben tárolják. A shaderek számára már nem alkalmazható hatékonyan az előbetöltés, így más megoldáshoz kellett folyamodni.
Az NV40 és G70 chipeknél említettem, hogy a pixel shader processzoruk a két fő ALU egység között, amolyan hosszú csővezeték elvet követ, rengeteg ideiglenes szakasszal. Az első ALU-hoz tartozik a textúrázó, ami megkezdi a betöltést, ilyenkor kerülnek a számításra váró pixelek a szakaszokkal teli „csőbe”, mire betöltődik a textúra, addigra a szakaszok megtelnek pixelekkel, ezzel lefedve az elérési idő kiesést. A probléma a dynamic branching esetén jön, mivel az így keletkező pixel tömb igencsak méretes lesz. Többnyire ezért működik alacsony hatásfokkal a GeForce 6-7 szériánál ez az eljárás. Természetesen az Nvidiának nem volt más választása, két relatíve rossz megoldás közül, úgymond a jobbikat választotta (kis pixel tömb esetén kiesne az elérési idő, ami cseppet sem könnyítené meg a helyzetet).
ATi R520 (pixel shader 3.0, vertex shader 3.0)

Az Ati 2005 őszén ismét felkavarta az állóvizet, amikor kiadta az R520 chipet a Radeon x1800 széria alapjaként. Teljesen új elveknek megfelelően dolgozták ki a rendszert, megoldást szolgáltatva a kor legnagyobb problémáira. A kanadaiaknak ugyanis sikerült olyan felépítést tervezni, ami alacsony pixel tömb használata mellett is képes lefedni az elérési idő kiesését, ennek köszönhetően a Dynamic Branching magas hatékonysággal működött. Az egész elgondolás alapja, hogy a pixel feldolgozó motort teljesen különválasztott egységekből építették fel. Az eddigi GPU-kban ugye több külön futószalag volt, és az ezekben elhelyezkedő pixel shader processzorokra lett a munka kiosztva. Egy ilyen egység állt pixel shader ALU-kból, regiszterekből és textúrázó egységekből. Az új chipben ezt a felépítést megszüntették. Létrehoztak egy nagyméretű (256KB-os) általános regisztertömböt, ahol az adatok tárolódnak ideiglenesen, a pixel shader egységeket és a textúrázókat pedig egy úgynevezett Ultra-Threading Dispatch processzorral vezérelték. A 16 darab pixel shader egység felépítése a régebbi Radeon-okhoz képest mindössze annyiban változott, hogy az ALU-k pontossága 32bit-es lebegőpontos lett, de továbbra is négyes csoportokba voltak rendezve. Ezek összesen négy, 16 utas MIMD tömböt alkottak (egy tömbben négy egység volt, és egy ilyen egység 4 utas – piros, zöld, kék, átlátszóság). Ebből rögtön következik, hogy a dinamikus branching 16 pixelt tartalmazó tömbre lett alkalmazva, ami a fenti ábra alapján jó teljesítményt nyújt. (Itt érdemes megjegyezni, hogy a később kiadott R580 chip már 48 pixel shader egységből állt, és a szokásos négyes csoportok négy darab 48 utas MIMD tömböt alkottak, így a Dynamic Branching 48 pixeles batch-re lett leképezve.) Textúrázóegységből szintén 16 került a chipbe - a későbbi R580 azonban változtattak a szokásos TMU felépítésen és egy címzőhöz négy mintavételezőt társított (ezzel az egyes HDR eljárások teljesítményét lehetett valamelyest növelni).
Az elérési idő átlapolásához egy ügyes trükköt vetettek be a tervezők. Amikor texture fetch-re volt szükség a Dispatch processzorhoz irányult a kérés, ekkor az aktuális állapotot elmentve felszabadult a pixel shader egység, és más feladatok számolását lehetett rábízni. Amint megérkezett a korábbi művelethez szükséges adat visszaállítódott az előbb felfüggesztett állapot, és folytatódhatott tovább a munka. Természetesen az elmentett állapotokat tárolni kellett. Az architektúra elméletben maximum 512 szálat futtathat, de ez a szám csökkenthető, ha a szálaknak több tárhelyre van szükségük. Ez teszi a rendszert rendkívül rugalmassá, így a várható elérési időhöz alakítható a szálak száma is.
Megújult a memóriavezérlő is. A régi Crossbar rendszeren aránytalanul magas tervezési időt, és tranzisztormennyiséget igényelne, ha az eddigi négy csatornát nyolcra növelnék. Ennek megfelelően az Ati inkább új megoldást vezetett be. Az új Ring típusú vezérlő, két ellentétes irányú 256bit-es, gyűrű alakú belső buszból állt. Ezek négy, úgynevezett állomáshoz csatlakoznak, melyek mindegyike két 32bit-es szélességű busszal csatlakozott a memóriához (a teljes sávszélesség 8x32bit, azaz 256bit). Az írás műveletek esetében továbbra is segíti a vezérlést egy Crossbar kapcsoló.

Vertex Texture Fetch nélkül is van élet
Az R520-ban vertex shader egységek száma nyolcra nőtt, ám itt egy hatalmas hiányossággal kell szembesülni. Ezek az egységek ugyanis nem tartalmaznak textúra címzőt és mintavételezőt. Gyakorlatilag képtelenek a Vertex Texture Fetch-re. Mivel a Vertex Shader 3.0 szabvány legnagyobb újításáról beszélünk, nem lehet elmenni mellette szó nélkül. Felvetődik a kérdés, hogy miként kapta meg az új GPU a Vertex Shader 3.0 jellemzést? Egyszerűen, mivel a tervezők találtak egy kiskaput a szabvány dokumentációjában. A Microsoft ugyanis semmilyen formátumot nem ír elő kötelezően a vertex textúrázás támogatására, így használható az Ati R300-ban is megtalálható R2VB, azaz a Render-to Vertex Buffer nevű eljárása. Ez a megoldás a pixel feldolgozó motorban végez texture fetch-et, és az adatokat visszaírja a vertex buffer-be. De elfogadható-e ez a módszer? Az eredmény szempontjából nyilván ugyanazt kapjuk, de képzeljük el a fejlesztők helyzetét, ők szabvány szerint dolgoznak, ha az adott GPU nem támogatja az eljárást, akkor más megoldást kell keresni a leképzésre. Persze mindez az eredeti ütemtervhez képest pluszmunkát jelent, így közel sem biztos, hogy megírják az algoritmust a hiányos tudású GPU-ra.
Ki a hibás? A Microsoft vagy az ATi? Lényegében teljesen mindegy, azonban a szabvány fennmaradása mindenkinek az érdeke, márpedig az ilyen akciók, erősen megkérdőjelezik az egységes API létjogosultságát.
Konklúzió
Az utóbbi évek izgalmas összecsapásokat hoztak. Természetesen a két nagy chipgyártón kívül próbálkoztak még a kisebbek is, de annyira jelentéktelen szeletet kaptak a piacból, hogy nem érdemes velük foglalkozni. Véleményem szerint az S3 Chrome szériája volt az egyetlen, ami alacsony fogyasztásával és fejlett multimédiás képességeivel sikeres tudott lenni. A három generáción keresztül tartó harcban, az első csatát egyértelműen az R300 nyerte. A második menetet a fejlettebb NV40 chipnek adom, még akkor is, ha az R420, és utódai átlagos sebességben jobbak voltak. A harmadik ütközet azonban nagyon véleményes. Egyrészt van egy forradalmian új tervezésű R520 nevű szörnyeteg, ami megoldás talált a kor nagy problémáira, másrészt ott a G70, ami nem keresett kibúvókat a Shader Modell 3.0 szabvány támogatása alól. Talán igazságos lenne a döntetlen, de szakmai szemmel nézve, egyszerűen nem tudom elfogadni a Vertex Texture Fetch hiányát. Meggyőződésem, hogy az Ati szándékosan értelmezte félre a szabvány követelményeit, felmentve magát, a nem kevés tranzisztort felemésztő textúrázók, vertex shader egységekbe történő beépítése alól. Ez a magatartás számomra nem elfogadható, így ha keserű szájízzel is, de a G70-t kell kihoznom győztesnek.
A DirectX9-es korszak csatáit tehát 2:1-re az Nvidia nyerte. Ezzel le is zárult egy közel 3 évig tartó időszak az IBM PC történelmében, de a háborúnak még közel sincs vége, hiszen már a nyakunkon vannak a DirectX10-es rendszerek. Persze ez már egy másik cikk témája.







