







Meg lehet úgy oldani PL/SQL-ben hogy több mezőt szeretnék kinyerni egy selectből
pl
select first_name into fname,
last_name into lname
from users.

Meg lehet úgy oldani PL/SQL-ben hogy több mezőt szeretnék kinyerni egy selectből
pl
select first_name into fname,
last_name into lname
from users.

select first_name, last_name into fname, lname from users
Még egy kérdésem lenne:
Meg lehet azt oldani, hogy ha egy function-t pl így hívok meg.
termekek('select name from termekek');
Ennek a kimeneteként egy varchar típust szeretnék kapni, amiben vesszővel elválasztva szerepeljenek a termékek nevei.

Nézz rá az "execute immediate ..." szintaxisára. De ez elég csúnya dolog szokott lenni, én inkább a logikán változtatnék.

Persze, meg lehet oldani. Kérdés, hogy ez minek kell neked, mert az SQL általában nem erre való.
Én kérek elnézést!
lehet, de ehhez nem kell újra feltalálni a kereket:
SQL> create table test1(name varchar2(10));
Table created.
SQL> insert into test1 values('Spongyabob');
1 row created.
SQL> insert into test1 values('Patrik');
1 row created.
SQL> insert into test1 values('Tunyacsáp');
1 row created.
SQL> commit;
Commit complete.
SQL> select listagg(name,',') within group (order by name) as nevek from test1;
NEVEK
------------------------------
Patrik,Spongyabob,Tunyacsáp
Ez mondjuk 11.2-es feature, ha ennél régebbi az Oracle, akkor google: oracle string aggregation
[ Szerkesztve ]

Helló!
Valaki tudna segíteni ?
Egy sqlexpress 2012 serverre szeretnék felcsatolni egy db-t de valamiért nem engedi ... :S
valaki tudna segíteni hogy mi a hiba ? 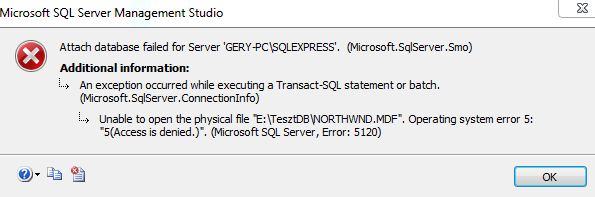
-.-

Nem CD-ről (vagy valamilyen írásvédett médiáról) próbálod felcsatolni véletlenül?
SQL Server szervízt futtató felhasználónak van oda hozzáférési joga?
AE
Csinálok egy adag popcornt, és leülök fórumozni --- Ízlések és pofonok - kinek miből jutott --- Az igazi beköpőlégy [http://is.gd/cJvlC2]
jog is van, meg nem is írásvédettről megy. /menne
-.-
"Access is denied" - ezen mit magyarázzunk?
Esetleg nem lehet oka, hogy más SQL instancia "fogja" ugyanezt a DB-t?
Én kérek elnézést!
Nem. Semmi sem futott.
-.-

Sziasztok,
lehetséges olyat csináni, hogy egy lekérésből kizárni azokat a sorokat amelyekben az url mezo cikk/ -el kezdődik ( url kinézete: cikk/cikk_cime), ha ez lehetségea kkor hogyan
where url not like 'cikk/%'
köszönöm 
Helló!
MSSQL-be ( meg gondolom máshol is ) idegen kulcsnak uniqueidentifier-nek kell lennie, és csak a másik tábla ID-jához kapcsolódhat ami szintén uniqueidentifier ?
Vagy csak annyi a lényeg, hogy a két kulcs egyező típusú legyen ? ( mondjuk int - int )
[ Szerkesztve ]
-.-
nem kötelező uniquedintifier-t használni. A lényeg, hogy összetalálkozzanak a kulcsaid.
Én kérek elnézést!
Akkor ez azt jelenti, mondjuk ha idegen kulcsal szeretnék mutatni egy másik táblában lévő COMPANY_NAME-re ami mondjuk nvarchar(MAX) akkor az általam készített táblába csinálok mondjuk egy FK_C_NAME -et ami szintén nvarchar akkor ez így megfelelő neki ?
-.-
Egyrészt kulcsnak az esetek 99%-ában int-et javaslok. Másrészt alapvetően félreértelmezed az idegen kulcsok működését.
Én kérek elnézést!

Sziasztok!
Találkoztam ezzel a mongoDB-vel csak a nevével, de ez most mégis micsoda? Adatbázis, én úgy olvastam, hogy valami dokument alapú adatbázis, de ez mit jelent? (wikipédiás magyarázatot sem értem így hirtelen)
Én nézegettem neten, és aztláttam, hogy Json alapú, OOP világába jobban illik bele.
Igazából gyakorlban milyen ezt használni, jobb mintha a sima SQL-t használnám?
Például. Weboldalt akarok, ahol van blog, user kezelés, de szeretnék diagramokat is kezelni,
A diagramoknak vannak adatai, id, név, téma, stb. Visszont vannak oszlopok is, értékek, amelyek mindig tetszőleges számúak! Az egyik diagramnak 4 oszlopa van, még a másiknak 8 oszlopa van.
Ebben az esetben MongoDB vagy SQL-t érdemes használni? Indokot is kérnék ha szabad 
Nekem még vadiúj ez a NoSQL világ
Én valahogy idegenkedek a NoSQL-től. Jóllehet bizonyos esetekben kiválthatnak hagyományos funkciókat pl. cookie-kat, session-öket, illetve ezek közötti kommunikációt könnyű NoSQL-lel, szépen adminisztrálható, áttekinthető módon megoldani.
Jól jöhetnek akkor is, ha abszolút változó oszlopszámú rekordokat kell tárolni.
Illetve előnyük még, hogy a szöveg alapú keresésben hatékonyabbak (ez azért relatív), mint a hagyományos relációs adatbázisok.
Hátrányuk, hogy egy szépen felépített adatbázissal, ahol minden mindennel relációban van, egyszerűen nem vehetik fel a versenyt.
És itt jegyezném meg, hogy az ilyen "vannak oszlopok is, értékek, amelyek mindig tetszőleges számúak! Az egyik diagramnak 4 oszlopa van, míg a másiknak 8 oszlopa van." esetek meglátásom szerint túlnyomórészt adatbázis, program rendszer tervezési hibák miatt születő megoldások, ahol a tervezés butaságait a NoSQL sem fogja megoldani, maximum elfedi, sőt a kötetlensége miatt akár fel is erősítheti ezt a jelenséget.
A kétféle SQL használata abszolút nem zárja ki egymást, párhuzamosan is lehet használni őket.
Én kérek elnézést!
Köszi!
Lehet az lesz, hogy próbaképen mindkettőre adattárolási formára ráeresztem majd a webalkalmazást.
Aztán így lehet tapasztalatokat levonni.
A tanulmányokon és tutorialokon kívül nincs gyakorlatom adatbázis tervezésben, így majd lehet itt kérnék tanácsot később
Hello,
Adnátok pár tippet adni, hogyan lehet egy selectet gyorsítani?
hint-ekről esetleg magyar leírás?
megfelelő indexeket létrehozni, statisztikát gyűjteni
végrehajtási tervet megnézni
session trace, majd ott megnézni, hogy mi veszi el sok időt
ha ezek megvoltak, na akkor lehet hintelni
legvégső esetben hidden paraméterek, ha valami nagyon specifikus a probléma
[ Szerkesztve ]
session trace?
Az mi lenne?
Illetve olvastam olyat, hogy Mysql-ben gyorsítja a lekérdezéseket a View-k használata.
Ez igaz az Oracle-re is?
ha bekapcsolod, aprólékosan minden egyes aktivitást, várakozást feljegyez egy trace fájlba, amit később ki lehet értékelni
pl. tkprof-fal lehet ember által emészthető formára hozni, ahol lehet látni pl. minden egyes sql utasításra, hogy milyen tervvel futott, és a terv egyes lépései mennyi ideig tartottak
#1026: a view nem más, mint egy elmentett lekérdezés aminek neve van, semmivel se gyorsabb se mysqlben, se Oracle-ben, csak kényelmesebb
[ Szerkesztve ]
esetleg ha nem túl hosszú vagy titkos a selected, rakd fel ide a fórumba, és ránézünk.
Én kérek elnézést!

Oracleben van lehetőség a Materializált Nézetekre, amivel valóban lehet gyorsítani a selectedet, de ezt körültekintően érdemes használni.
De a legfőbb kérdés, hogy mire akarod használni az adott selectet. A hálózati forgalom pl. minimalizálható, ha nézetet használsz, ám ha ezt a lekérdezést egy sql*plusban adod ki, akkor nem lesz különbség a két (select contra view) között.
=Kilroy was here============================ooO=*(_)*=Ooo=======
Munkahelyi anyagot nem rakhatok netre 
Érdekes, mint kiderült nem is a Select-ekben van a hiba. (~160 sort dolgoz fel a select)
Fájlba történő kiírásnál van a probléma. Néha 1 oerc, néha 3 óra. Pedig ugyan azzal a paraméterrel hívom meg... Ha SQL navigátor debuggerjével megyek át rajta akkor nincs gond...
160 sort??? És ennek fájlba írása 1 perc??? A 3 óráról nem is beszélve...
Én kérek elnézést!
Hát...
Nem tudom mi lehet 
Egyszerű select-el meg lehet tudni, milyen indexen vannak egy táblára, esetleg mezőjére?
Sajnos van 2x indexet hoztak létre egy táblára, és jobb lenne biztosra menni, nem mindet végignézni...
Nem írtad az adatbázist! Oracle-ben pl. az ALL_IND_COLUMNS nézetből lekérdezheted:
select
INDEX_NAME,
LPAD(TABLE_NAME,17) TABLE_NAME,
LPAD(COLUMN_NAME,15) COLUMN_NAME,
LPAD(COLUMN_POSITION,5) COLUMN_POSITION
from ALL_IND_COLUMNS
WHERE TABLE_NAME = upper('&tablename')
order by INDEX_NAME,COLUMN_POSITION;
=Kilroy was here============================ooO=*(_)*=Ooo=======

Sziasztok,
Egy kis gondban vagyok, mert adott egy alkalmazásom, amit bővíteni kellene.
Az alkalmazás tartalmaz egy űrlapot, ahol legördülők vannak, kb 10 db.
Mindegyik legördülő mögött egy tábla van: (név, id) párokkal lényegében.
Eddig ezek egymástól függetlenül léteztek, de most úgy kellene bővíteni a funkcionalitást, hogy egy admin felületen lehetőséget adni az adminnak arra, hogy kiválasztott listák egyes értékeitől tegye függővé, hogy a másik legördülő mit jelenít meg.
Az adatkapcsolat így lehet sok-sok, egy-sok és sok-egy is.
Arra gondoltam, hogy két táblára lenne szükségem
az egyik mondjuk table_connect(melyik_táblát, melyikkel)
a másik pedig a data_tree( melyik_tábla, melyik_adata_id, melyik_táblával, melyik_adatával_id)
Az első tábla adná meg, hogy melyik táblától melyik tábla függjön, a második tábla pedig megadná, hogy az egyik tábla mely konkrét értékekeihez a másik tábla mely értékeit rendeljük.
Nem tudom mennyire érthető, de érdekelne pár tapasztalt adatbányász véleménye.
Köszönettel,
W.
mivel nulla konkrétumot árultál el...
Általánosságban:
Kapcsoló tábla jellemzően a sok a sokhoz esetben kell, a többi esetet sima foreign key-ekkel meg tudod oldani.
Ha már kapcsoló táblád van, érdemes tábla-tábla közé létrehozni egy-egy kapcsoló táblát, legalábbis az ORM-ek ezeket tudják értelmesen feldolgozni, és itt már csak felesleges túlbonyolításnak érzem, egy nagy kapcsoló táblát létrehozni.
De te tudod.
Én kérek elnézést!
Köszönöm
Igen, azért van szükség a kapcsolódó táblára, mivel valószínűleg elő fog fordulni a sok a sokhoz eset, ezt sajnos még nem tudom, a felhasználó fogja eldönteni...
"Ha már kapcsoló táblád van, érdemes tábla-tábla közé létrehozni egy-egy kapcsoló táblát, legalábbis az ORM-ek ezeket tudják értelmesen feldolgozni, és itt már csak felesleges túlbonyolításnak érzem, egy nagy kapcsoló táblát létrehozni."
Itt nem nagyon értem, hogy mire gondoltolál 
"Arra gondoltam, hogy két táblára lenne szükségem
az egyik mondjuk table_connect(melyik_táblát, melyikkel)
a másik pedig a data_tree( melyik_tábla, melyik_adata_id, melyik_táblával, melyik_adatával_id)"
Erre. Javaslom, hogy ez a koncepció helyett minden tábla között, ami között sok-sok kapcsolat lehet, vegyél fel külön kapcsolótáblákat. Ettől még a te ötleted is működik.
Ha pedig 10 tábla közül minden kapcsolódhat mindennel, akkor ott valami alapvetően félre van tervezve.
Én kérek elnézést!
Köszi.
Ez bejött
bármi kapcsolódhat bármivel, de nem minden mindennel.
Egymás alatt vannak a listák, amik egy meghatározott fogalom pontosításait adják
pl: első legördülőben kiválasztom a lehetőségek közül az élőlényt
így a második legördülőben már csak élőlények csoportjai vannak kiválasztom a gerinceseket
a harmadikban így csak a gerincesek vannak, abból kiválasztom az emlősöket,
stb...
vannak listák, amelyek nem függenek semmitől, és tőlük sem függ semmi, de sajnos azt még nem tudom, hogy mi mitől fog függeni, ráadásul ez változhat is, így inkább egy általános modelt próbálok megadni, ami flexibilis.
[ Szerkesztve ]
Ez egy (de legfeljebb kettő) táblában megoldható...
AE
Csinálok egy adag popcornt, és leülök fórumozni --- Ízlések és pofonok - kinek miből jutott --- Az igazi beköpőlégy [http://is.gd/cJvlC2]

Kérdés, adott egy adatbázis, amit szétdobtam az egyik mező adatai alapján évek szerint külön táblákba (tehát minden év összes bejegyzése külön táblában van már).
Amikor az egész egyben volt, akkor az alábbi lekérdezés hibátlanul működött (a jatekosl mező tartalma ugyanaz mint a jatekos mezőé, de kisbetűsítve):
SELECT jatekos, sum(pont) FROM jateklista WHERE pont >='1' GROUP BY jatekosl ORDER BY 2 LIMIT 50
Az évek szerint szétdobott táblák esetén a következő lekérdezést alkalmaztam, hogy a fenti eredményt elérjem (csak 2 évet írok le, mivel a teljes időszak lekérdezését PHPban állítom elő dinamikusan, a hiba úgyis ugyanaz):
(SELECT jatekos, sum(pont) FROM jateklista2005 WHERE pont >= '1' GROUP BY jatekosl) UNION (SELECT jatekos, sum(pont) FROM jateklista2006 WHERE pont >= '1' GROUP BY jatekosl) ORDER BY 2 DESC LIMIT 50
A hiba pedig az, hogy minden játékos annyiszor szerepel, ahány évben beleesik a fenti lekérdezésbe. Nyilván valami alap dolgot rontok el, de remélem tudtok segíteni Esetleg ha valakinek van "szebb" megoldása, megköszönöm.
http://logout.hu/cikk/samsung_led_tv_tudastar_d_szeria/alapok.html
én is két táblát terveztem.
Csak annyi hiányzik, hogy a lekérdezésed most évenként jön fel, szóval kívülre kell még egy group by.
Vagy csinálsz egy nézetet a szétbontott táblákra, és akkor elég egy group by a nézetre.
pl:
SELECT jatekos, sum(pont) FROM
(
SELECT jatekos, pont FROM jateklista2005 WHERE pont >= '1'
UNION
SELECT jatekos, pont FROM jateklista2006 WHERE pont >= '1'
)
GROUP BY jatekos
ORDER BY 2 DESC LIMIT 50
[ Szerkesztve ]
=Kilroy was here============================ooO=*(_)*=Ooo=======
Ez így nem ad eredményt Azthiszem azért, mert az UNION-os cuccot nem lehet GROUP BY-olni...
[ Szerkesztve ]
http://logout.hu/cikk/samsung_led_tv_tudastar_d_szeria/alapok.html
Tedd bele az union-t egy view-ba (vagy temp táblába), és az már majd lehet...
AE
Csinálok egy adag popcornt, és leülök fórumozni --- Ízlések és pofonok - kinek miből jutott --- Az igazi beköpőlégy [http://is.gd/cJvlC2]
Ennyire nem vágom mélyen a MySQL-t, esetleg leírnád hogyan állítsam össze a lekérdezést? Temp táblát nem szeretnék ehhez használni...
Ha ennyire nehéz az évekre bontott táblákból megoldani ezt a fajta lekérdezést, akkor hagyom egyben, de már 428ezer sort tartalmaz az adatbázisnak ez a táblája, s gondoltam az egyes évekre irányuló lekérdezések valamint az új beírások az aktuális évbe gyorsabbak lesznek, ha szétcsapom az egészet évekre...
http://logout.hu/cikk/samsung_led_tv_tudastar_d_szeria/alapok.html

SELECT jatekos, SUM(pont) AS pont FROM (
(SELECT jatekos, sum(pont) AS pont FROM jateklista2005 WHERE pont >= 1 GROUP BY jatekosl)
UNION
(SELECT jatekos , sum(pont) AS pont FROM jateklista2006 WHERE pont >= 1 GROUP BY jatekosl)
) AS sumtable
GROUP BY jatekos
ORDER BY pont DESC
- http://pazsitz.hu -
Nincs eredmény
http://logout.hu/cikk/samsung_led_tv_tudastar_d_szeria/alapok.html
miért ne lehetne az union-t group by-olni?
Másrészt 428 ezer sor miatt szedted szét? 
Majd ha sok millió sor lesz benne. Talán inkább rendesen indexelni kellene, ha a 428 ezer sor lassú.
Én kérek elnézést!


