





Szivárognak már az FM2+-os lapok 
AMD Ryzen 9 5900x - MSI RTX 4070 Super Gaming X Slim - Kingston Fury 2*16GB 3600Mhz - Seasonix GX750 - Samsung 970 EVO Plus 256GB/1TB - Asus GT501 - Dell S2522HG // iPhone 15 128GB Blue

Szivárognak már az FM2+-os lapok
AMD Ryzen 9 5900x - MSI RTX 4070 Super Gaming X Slim - Kingston Fury 2*16GB 3600Mhz - Seasonix GX750 - Samsung 970 EVO Plus 256GB/1TB - Asus GT501 - Dell S2522HG // iPhone 15 128GB Blue

Jó fajták!
V1200 - 18CORE - SUPRIMX

akkor lassan jönnek már az AsRock féle megoldások is.. már csak az a kérdés, lesz-e értelme erre váltani pl Llano-ról (az egységes címtér vonzó adu lehet), vagy inkább kivárni a Kaveri folytatását..
Script Kiddies Do What They Do Best: Infect Themselves / The only man who gets his work done by Friday is Robinson Crusoe..
kérdés, hogy ez a foglalat milyen hosszú életű lesz?

Tudnám, hogy mire jó a Kaveri ... alacsony fogyasztású szervert lehet belőle építeni?

A88X mellett lehetett volna egy kis gddr5 memória is. 
Fanboy Status: PS4:On, Xbox:On, apple:On, samsung:Off, Microsoft:Off, Audi :On,

Ugyanarra, mint a Richland. A Core i3-hoz kepest egy jo ar/ertek aranyu alternativa, arahoz kepest igen jo integralt GPU-val. Nagyjabol ennyi
(#8) Silentfrog

Azért nem dobálják ki gyorsan ezeket a lapokat,mert akkor a meglévő Fm2 tokozásút nem venné senki? ![;]](http://cdn.rios.hu/dl/s/v1.gif)

Szerintem irodába, meg HT-PC-be érdemes venni, ahova nem kell videokártya. Amiben van VGA kártya, ott ez felejtős, semmi értelme.
4 col fölött minden phablet... nekem 4 colnál nagyobb telefon, soha az életben nem kellene. Ha fizetnének se...

Tulajdonképpen már fél évvel megelőzi a korát szóval szerintem viszonylag hosszú.
A PH-n mindenki mindig jobban tudja. Fél óra Google keresés után...
Nem kevered a Kabinivel? 
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Utána kell néznem ennek a Kaverinek akkor. OpenCL-t támogat lelkesen?
Kis, otthoni szerverbe kellene. Kis fogyasztás, általános OpenCL feladatok ...
A Kaveri abban lesz jó, hogy közös memóriát használ a GPU és a CPU.
Novemberben kezd el szivárogni majd, de leginkább jövőre lesz elérhető.
OpenCL-re valószínűleg verhetetlen lesz, és több, mint valószínű, hogy lezs belőle alacsony fogyazstású verzió is.
Egyébként ha hamarabb kell, és kisebb teljesítmény is elég, akkor a Kabini is jó alternatíva OpenCL-ezni - szerintem.
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Bevárom, mert a célfeladathoz jó lesz a közös memóriatér.

A 88x-es variáns tetszetős... és még jól is néz ki... Először úgy is lapot cserélek, de nézzük azért a többi versenyzőt is. Amúgy biztos vagyok benne, hogy már ott áll egy rakat a raktárban(hisz először nyárról volt szó), csak késik a kaveri, meg az előző lapokat is el kell adni. Én amúgy azért várom a kaverit, mert sztem full grafikán tudom futtatni majd a wotot egy integrált wgán, ami nekem bőven elég lesz... 
[ Szerkesztve ]
Lehet akármilyen APU, és bár bennük van a jövő, a dVGA, az dVGA marad örökre!

A Kaveri inkább a konzolokhoz igazodik. Azokat a szolgáltatásokat amiket támogat a két új konzol, átmenti PC-re, így a PC-s portból nem kell kivágni az effekteket/extrákat. Már 2014-ben lesznek ilyenek. 2014-től a Fifának három évig két programkódja lesz. Egy a HSA hardverekhez, és a butított a többi konfighoz.
(#17) Bici: Amelyik konzoljáték az IGP-t használja általános számításokra az portolhatatlan PC-re. Ilyen a Fifa 13. Ezért kap a PC butított portot, amit a PS3 és az Xbox 360. Az AMD azt találta erre ki, hogy partnerkednek az EA-val és két programkód lesz pár évig a PC-s Fifában. Ha van hardvered hozzá, akkor a modernebb portot is eléred. A grafikát meg majd számolja a VGA.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
De az alacsonyabb sebesség miatt sem kell kiszedni egy-egy effektet?
(tudtommal kevesebb számoló lesz a Kaveriben)
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

A Kaveriben 512 Shader részelemes GCN IGP lesz ami kb a HD 7750 szintje ami már azért nem nevezhető olyan gyengének szerintem.
< AMD RYZEN™ POWERS. YOU DOMINATE. >
Értem, de a Kaverivel hogy fog működni a modernebb port, ha kevesebb számoló lesz benne, mint a konzolokban? Vagy eleinte nem lesz kihasználva a konzolok teljes GPU kapacitása?
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Abu leírta,hogy általános számítások mennek az IGP-n a grafikát pedig a dVGA számolja majd.
[ Szerkesztve ]
< AMD RYZEN™ POWERS. YOU DOMINATE. >
Jaaa, hogy az IGP számolja az általános dolgokat és külön a grafikát a GPU?
Így már logikusabb. Elsőre nem így értettem. 
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Azért grafikára sem lesz gyenge a Kaveri
< AMD RYZEN™ POWERS. YOU DOMINATE. >

Megnéztem a hivatalos oldalán a specifikációt. Egyszerűen nem bírom felfogni, hogy Dual Graphicshez miért még mindig a 6000es sorozat alsó-középszintű kártyáit írják elő. Miért max 6670 vagy közel hasonló VGA-val használható? Ha már egyszer azt reklámozzák, hogy a 8000-sel is milyen jó lesz az alaplap, akkor legalább valami komolyabbat is befoghatnának erre a feladatra.
Nem értelek...a Kaveri még be sincs jelentve honnan tudod mi a soecifikációja?,még amd.comon sincs szó Kaveriről.
Meg ki reklámozza hogy milyen 8000-sel lesz jó micsoda? Nem értelek.
[ Szerkesztve ]
< AMD RYZEN™ POWERS. YOU DOMINATE. >
https://www.asus.com/Motherboards/A88XMA/#overview
Lap alja felé: " It allows AMD APUs and selected AMD Radeon™ HD 6000 series graphics cards to work together" és "AMD® A-series Accelerated Processor with AMD Radeon™ HD 7000/8000 Series Graphics."
És ebben mi nem érthető? a 7000/8000 az az APU-ban(mert ez az a APU lényege ugyebár az X86/64-es magok és grafikus shader magok egy szilíciumlapkán laknak) van lásd 5800K with Radeon 7660D IGP
Azért nem lehet a Richland/Trinityk mellé nagyobb dVGa-t tenni mint a 66xx/65xx,mert 7xxx-es szééri már GCN alapú az 5800K és / 6800K IGP-je pedig VLIW4-es architektúrát használ a kettő pedig nem köthető DG-ba.
[ Szerkesztve ]
< AMD RYZEN™ POWERS. YOU DOMINATE. >
Pár hónapja még pozitívan vártad a Kaverit, mostanában viszont elég negatívan.
Talán csak nem a kezed közé került egy?
Ezek szerint a Kaveriben már 7000/8000 van, tehát GCN, ami a 6000-rel nem köthető össze
[link] szerint "The AMD Radeon HD 8670M (sometimes known as the ATI Mobility Radeon HD 8670) is a DirectX 11.1 graphics card for laptops. Just like the 8500M and 8700M series, it is based on the Mars chip (28nm GCN architecture)"
Kicsit benéztem, mivel az APU-ba a D végződésű VGA-k vannak integrálva, szóval nem az előbb említett.
De itt [link] elég határozottan állítják: "AMD Kaveri APU Architecture Detailed – Next Generation APU Featuring Steamroller and GCN Cores"

Az A88XM-Pro lesz még pofás lapocska, hűtőbordás VRM-mel, hátlapi arzenállal.
Abu: s aki csak Kaveri APU-val szerelt pöttöm erőgépet épít, az a konzolos funkciókat kapja mérsékeltebb grafikávál?
Igen a Kaveriben már GCN-s IGP lesz és elég elképzelhető hogy esetleg még a HD 7770-nel is megy majd Dualban.
< AMD RYZEN™ POWERS. YOU DOMINATE. >

Nekem tetszenek ezek... amire elég jobb mint a mostani erőművem, enni szeret de rohadt ritkán használom ki... de egy ok miatt nem váltanék ilyenre.. hogy sima 3 jack dugós panel van rajta nem 6 meg nincs integrálva rá wifi...
Mosoly :)
Most is abszolut pozitivan varom a Kaverit, csak tudni kell helyén kezelni a dolgokat. Nem fogja megvaltani a vilagot, mint ahogy az elodei sem tették/tudták. Az AMD mar nem eloszor probalja forradalmi(nak tuno) technologiakkal elkapraztatni a nagykozonseget, azonban a multbol kiindulva en nem fogadnek ra, hogy tenyleg akkora durranas lesz ez az egesz HSA maszlag. Oke, volt egy-ket baromi jo technologiajuk, amit lemasolt/atvett a konkurencia is (pl. IMC, HyperTransport, x64), de kozben egy csomo otletuk ment a sullyesztobe vagy kiderult rola, hogy a gyakorlatban nem kivitelezheto. A HSA, GCN es ezek kombinacioja helyett en inkabb a direkt GPU programozasban latom a jovot, amire a legjobb megoldasnak jelenleg szamomra az AVX-512 tunik. A HSA/OpenCL-nek nagy overheadje van, raadasul a fejleszto kenytelen kitenni magat a gyartok benazasainak is (bugos compilerek, bugos video driverek, stb). Megirod a jo kis HSA-s kodot egy AMD GPU-n, aztan csodalkozol, hogy a teljesen szabalyosan, a szabvanyokat kovetve megirt kodod nem mukodik rendesen, vagy csak baromi lassan fordul le mondjuk Intel vagy nVIDIA GPU-n; vagy epp kozeleben sincs a valos teljesitmeny az elmeletinek. Na ilyen nem fordul elo, ha direktben programozod a GPU-t, mint anno a hoskorban.
A Kaveri GCN2-es iGPU-t kap, akarcsak a Kabini -- csak persze 3-4x tobb maggal.
A HSA-val nem fordulhat elő, hogy másképp fut a megírt kód a többi gépen. Ez a rendszer egyik alappillére. A fordítást minden gyártónak a saját finalizere végzi. Úgy működik a rendszer mint a Java. Lesz egy runtime, és mögötte a kapott HSAIL kód fordításáért egy gyártói finalizer felel, ami küldi a hardverhez a kódot. Ma is így működik a GPU-s dolog, csak az a különbség, hogy a HSAIL az egy szabványos vISA lesz, míg ma minden gyártó sajátot használ.
Az Intel és az NV GPU-kra eleve nem fordul majd HSAIL kód. Azokra a rendszerekre legacy opció lesz, vagyis a lapkában található processzoron fut majd a kód.
A direkt programozás kizárt. Erről már Johan Andresson is beszélt, nincs rá pénz és idő. Ő már kiadta az ultimátumot, hogy vagy beáll mindenki a HSA mögé, vagy aki nem áll be az így járt.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

Az Intel a tőkéjével ér el sokmindent, miközben az ilyen kis cégeknek, mint az AMD, nem nagyon marad más, mint az kreativitás, szellemi innováció...
Ez a "HSA maszlag", tehát a GPU valós beemelése a rendszerbe (eddig csak mint "külsős" dolgozott) szerintem nagyon is forradalmi dolog.
Az AVX512 a szokványos FPU némi kibővítése, de szerintem hosszabb távon nem bizonyul túl hatékonynak.
Az OpenCL-nek valóban van egy overheadje, a HSA részben pont ennek alapos lefaragása érdekében született.
[ Szerkesztve ]
Tehat lenyegeben ugyanugy 2 szintu forditas lesz, hiszen elso korben a nyers C-szeru kodot le kell forditani HSAIL-re, majd azt a GPU drivere forditja at a GPU nativ gepi kodjara. A vicc az, hogy most is ugyanez van pl. OpenCL-en, es ha ott bugos es sz*rul mukodik, akkor nem vilagos szamomra, hogy a HSA-nal ez miert mukodne jobban.
A direkt programozas temajaban erdemes megnezni, John Carmack milyen velemenyen van. En inkabb neki hiszek, mint annak az AMD-nek, aki a 5 evnyi tokoles es milliardos (USD) koltsegek utan egy ilyen Bulldozert rakott ossze...
A GPU most is beemelheto a rendszerbe, pl. OpenCL vagy CUDA segitsegevel, a HSA csak egy plusz reteg azon a tobbretegu sz*ron, ami mar most se mukodik rendesen.
>Az AVX512 a szokványos FPU némi kibővítése
2x SIMD szelesites, 2x tobb regiszter = "némi" ? A mar most piacon levo Haswell nyers szamitasi teljesitmenye (AVX+FMA-val) is elerheti a 450-500 GFLOPS-ot a "szokványos" FPU-ja segitsegevel, egyszer pontossagot feltetelezve. A Richland VLIW4-es iGPU-ja ehhez kepest 648 GFLOPS. Szorozzuk be a Haswellt kettovel (AVX-512), legyen nagyvonaluan 1 TFLOPS. A vicc az, hogy azzal a nyers erovel mar foghato lenne az iGPU, ha direktben, x86-on programozna az ember. Persze tudom, az csak GPGPU-ra lenne jo, meg a FLOPS/watt mutatoja nem tul kedvezo, de a nyers teljesitmeny AVX-512-vel brutalisan nagy lesz. Egy kis fantaziaval el lehetne kepzelni egy buta iGPU-t (4 EU, a la Silvermont) es 2-vel tobb Haswell CPU-magot, es maris 1.5 TFLOPS-nal jarunk. Ezt programozzuk direktben, es hopp, van egy erdekes koncepcionk. En ebben tobb fantaziat latok, mint a HSA-ban, de majd hosszutavon kiderul, mire megy az AMD a HSA-val.
[ Szerkesztve ]
A HSA nem egy réteg. Nem írom le, mi, hiszen klikkelhetsz: HSA
Most, hogy elolvastad, talán más szemmel nézel rá és az OpenCL/CUDA-val való kapcsolatára is, továbbá a rendszer szintű integráció jelentésével is tisztába kerülhettél.
Ne aggodj, ismerem a HSA-t. Vagy az nem az a reteg, amit az OpenCL-re huznak ra? Milyen nyelven programozod a HSA-t? Nem OpenCL-lel (peldaul) ? En egy olyan architekturat (HSA), amit egy tobbszintu meglevo retegre (OpenCL) huznak ra pluszban, egy plusz retegnek nevezem. Az OpenCL mar onmagaban is tobbszintu, hiszen megirod egy C-szeru nyelven a programot, azt elkuldod forditasra (clBuildProgram), amit az OpenCL driver lefordit egy koztes nyelvre (pl. AMD IL vagy nVIDIA PTX), majd az OpenCL ujra leforditja azt, immar az aktualis GPU nativ gepi kodjara. Vegul persze lefut egy gepi kod a GPU-n, amire a programozonak nincs sem ralatasa, sem kozbeavatkozasi lehetosege. Ha bugos a 2 szintu forditas valahol, akkor igy jartal, nem fog mukodni rendesen es/vagy nem fog mukodni optimalisan a kod. Na most erre a maszlagra ranyomnak egy plusz reteget, ez szamomra nem tunik eletkepes megoldasnak. Plane ugy, hogy a nalam sokkal hozzaertobb emberek is azt szajkozzak, hogy mar onmagaban a Direct3D is tul nagy latencyt eredmenyez, es sokkal durvabb dolgokra lennenek kepesek a jatek engine fejlesztok, ha direktben tudnak programozni a GPU-kat. Nyilvan nem lehet ezt jelenleg me'g elkepzelni, hiszen pl. az AMD onmagaban is 3-4 kulonbozo GPU architekturat futtat parhuzamosan. De en a gyartok helyeben inkabb effele probalnek tendalni, mintsem a meglevo katyvaszt tovabb bonyolitani es tovabb rombolni az egesz rendszer hatekonysagat.
Persze tudom, a HSA-val jon majd az egyseges cimter meg egy csomo mas erdekes nyalanksag is -- amikre azonban semmi szukseg nem lenne, ha a GPU-t a CPU nyers erejevel valtanak ki, vagy koprocesszorkent hasznalnak a GPU-t pl. egy masodik foglalatban. Arrol nem is beszelve, hogy eddig azt szajkoztak mindenhol, hogy ha optimalis CUDA vagy OpenCL kodot akarsz irni, akkor vedd figyelembe a savszelesseg szukosseget (videokartya <-> PCIe <-> CPU <-> rendszermemoria). Most meg majd mindenki eleresztheti a fantaziajat, mert lesz egyseges cimter es az milyen jo dolog? A nagy francokat, hiszen ahhoz kellene egy normalis savszelesseg a CPU-nal, ami nincs es nem is lesz egyhamar, ha az AMD igy folytatja! Nagyon kellett volna a GDDR5, helyette kapunk DDR3-2133-at, ami mar a Richlandnel sem mukodik rendesen...
Sajnos én nem merültem el ebben kimondottan részletesen. Programozás szintjén pedig egyáltalán nem. Nekem úgy tűnik, maga a HSA is változik idővel. Gondolom a hardverek/integráció előrehaladottságával párhuzamosan.
Elvileg a pointerek + zero copy hivatott mérsékelni a pl. Llano esetében sem éppen bőséges sávszélességet.
De a GDDR5 elvetését én sem értem. A Sony is amellett tört lándzsát. Ha másutt nem is Opteron vonalon tán még kifizetődő is lehetne (bár ott a kimondottan nagy mennyiségű memória is szempont).
A HSA-t nem húzzák rá az OpenCL-re (esetleg fordítva), mert ez egy rendszerarchitektúra. A kedvedért ide másolom a linkről:
"Heterogeneous System Architecture
Heterogeneous System Architecture (HSA), maintained by HSA Foundation, is a system architecture that allows accelerators, for instance, graphics processor, to operate at the processing level as the system's CPU. To ease various aspects of programming heterogeneous applications, and to be HSA-compliant, accelerators must meet certain requirements, including:
- Be ISA agnostic for both CPUs and accelerators
- Support high-level programming languages
- Provide the ability to access pageable system memory
- Maintain cache coherency for system memory with CPUs, and so on.[17] HSA is widely used in System-on-Chip devices, such as tablets, smartphones, and other mobile devices.[18] HSA allows programs to use the graphics processor for floating point calculations without separate memory or scheduling.[19]"
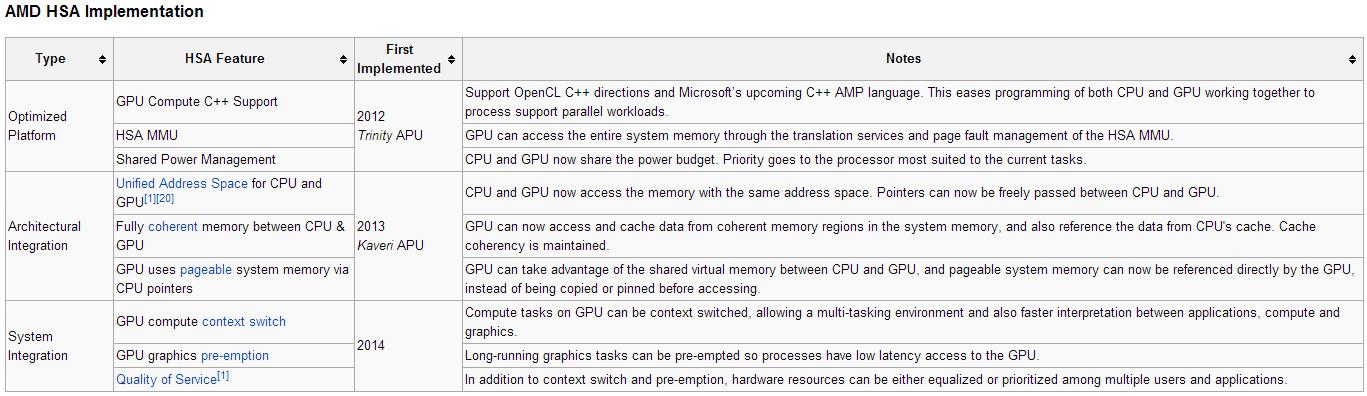
Az OpenCL csak egy lehetőség a több közül a HSA-compliant HW programozására.
Amiket írsz, az első és második bekezdésben is, nos abból nem az jön le, hogy ismernéd és értenéd, sőt éppen ellenkezőleg. A helyedben inkább alaposan utánanéznék, mielőtt nyilatkozok róla.
A HSA többek között éppen, hogy közvetlenebb, egyszerűbb és gyorsabb hozzáférést biztosít a GPU-hoz:
E helyett:
Ajánlott olvasmány(ok): [link]
[ Szerkesztve ]
A sávszéligényt valószínűsíthetően - a DDR4 bevezetése mellett - az Xbox One-nál bemutatkozott ESRAM-mal fogják kielégíteni desktopon/szerver vonalon is a későbbiekben. (Lásd még Intel Iris Pro.)
Oke, akkor ha nem OpenCL-lel programozod a HSA-t, akkor mikepp? C++AMP, CUDA es tarsai ugyanaz a maszlag, mint az OpenCL. Ha nem ezekkel, akkor mit csinalsz, hogy kodot tudj irni egy HSA-s GPU-ra?
Egyebkent rossz helyen kopogtatsz Tobbek kozt OpenCL-re is fejlesztek, szoval van egy egesz kicsi esely ra, hogy tobb ralatasom van erre az egesz temara, mint a WikiPedia alapjan Neked. Tenyleg nem bantani akarlak, es tavol alljon tolem a szemelyeskedes, csak ha mar igy belemerulunk, akkor szeretnem tisztazni a szitut. Nem a levegobe beszelek, amikor az OpenCL f***sagait feszegetem, most is 2 olyan OpenCL compiler buggal kuzdunk, amire az egyik nagy GPU gyarto ceg valasza ez volt:
"I’ve reproduced the issue and filed a bug for our compiler team. I can’t give you a timeframe for resolution"
A masik nagy GPU gyarto ceg valasza pedig ez volt 1 honapja, es azota sem tortent semmi elorelepes:
"I’m giving this issue over to our compiler team to see what they come up with. I’ll let you know once we have root causes and if there is any guidance XXXX has regarding either issue." (XXXX = ceg neve)
Es nehogy azt hidd, hogy egy bonyolult kodot probalunk leforditani OpenCL-re. Egy szogegyszeru, faek kodrol van szo, aminek a nagy resze ugyanaz a sor, azaz egy borzaszto redundans loop unroll kodrol van szo. A 3 nagy cegbol (AMD, Intel, nVIDIA) csak az egyik OpenCL implementacioval mukodik a kodunk, a masik kettovel bugos. Es nem, nem az eredeti kod a bugos, az hibatlan. Szerinted ez egy olyan platform, amire biztonsaggal lehet epiteni? Irsz egy franko kis programot, hogy kihasznald a GPU kepessegeit, aztan vagy mukodni fog egy adott hardveren, vagy nem. Ezt hogyan vallalod, hogyan vallalhatod be szoftver fejlesztokent?
Arrol meg aztan ne is beszeljunk, hogy ha le is fordul vallalhato ido alatt a kod az OpenCL segitsegevel, me'g mindig semmi garancia nincs arra, hogy normalis sebesseggel futni is fog az adott hardveren. Es ahogy irtam fentebb, semmi de semmi ralatasa vagy rahatasa nincs a fejlesztonek arra, hogy mikepp fog futni a kod egy adott hardveren. Lehet persze kormonfont modon specifikusan kodot kesziteni adott architekturakra, de az is csak takolas, es azzal sem lehet extrem optimalizaciokat implementalni.
Ertem en, hogy a HSA azt (is) celozza, hogy egyszerubb, direktebb legyen a hardver meghajtasa, az jo lehet a latency csokkentesere, de sajnos sok mas gubanc is van, amikkel szivatjak a fejlesztoket.
Amit irsz a DDR4-rol meg az eDRAM-rol, az pedig a nagyon tavoli jovo. A realitas az, hogy 2014-ben nem lesz az AMD-nek DDR4 tamogatasu processzora. 2015-ben sem valoszinu, ha az eddigi trendeket vizsgaljuk, hiszen az AMD mindig 1-2 ev lemaradassal koveti a memoriaszabvanyok Intel altali adoptaciojat. Ha pedig az Intel a mainstream szegmensben 2015-ben, a Skylake-kel vezeti be a DDR4-et, akkor 2016-2017 tajekan jon az AMD-nel. Addigra pedig mar annyira megnovekszik a memoria savszelesseg igeny, hogy a DDR4 is baromi keves lesz a "boldogsaghoz".
Az eDRAM-hoz pedig en kicsinek erzem az AMD-t, no offense. Az Intel sem veletlenul kussol a Crystal Well kapcsan: volt 2 review a neten egy betas cuccal, aztan azota nagy semmi. Senkinek nincs, teszt (ES) peldanya sem. Ha engem kerdezel, en gyartasi nehezsegeket szagolok a levegoben. Na most ha az Intel a jol bejaratott 22 nanon is sziv az eDRAM-os CPU-val, akkor nem hiszem, hogy pont az AMD tudna a kozeljovoben gazdasagos gyartassal implementalni 28 nanon. Akkor mar nagyobb eselyt szavazok a GDDR5-nek: talan jovore lesullyed az ara annyira, hogy 8-16 GB-ot elfogadhato aron es elfogadhato teruleten tudjak az alaplapra illeszteni.
[ Szerkesztve ]
Én is programozom (idestova 25 éve). Igaz, a GPU programozással, OpenCL-lel csak mint érdekesség ismerkedem, érintőlegesen (jelenleg nincs rá szükségem és időm sem, bár kedvem lenne szórakozni vele). Mindenesetre tudom, milyen távol tud állni egy rutin/függvény megírása egy rendszerre az utóbbi beható ismeretétől. Meg hát az OpenCL és a HSA más állatfaj. Nem értem, miért esik ennyire nehezedre akár csak az alap pdf elolvasása. Előre eldöntötted, hogy bukásra ítélt hülyeség az egész GPGPU téma, mert hogy jön majd a megváltó AVX512, ezért annyira sajnálod rá az időt, hogy meg sem nézed, pontosan miről is van szó?
Igen, többektől hallottam már, hogy sokat lehet szívni az OpenCL-lel. Kb. ugyanígy van a CUDA-val is (vagy pl. az FPGA-kkal, ehhez képest egy egész iparág foglalkozik vele). Aztán valahogy mégis sikerül összehozni, amit akarnak. Ha kell, kerülőutakon. Egyébként szerintem konzultáljatok lenox-szal (lásd blogja!).
Szóval, jelenleg OpenCL és C++AMP, de nem sokára Java is, aztán C++ és a többi. De valószínű az OpenCL compilernek is könnyebb dolga lesz a HSA-compliant hw-eken (most teljesen más architektúrák között kell hidat képeznie.) A HSA nagyon sokmindent leegyszerűsít, megkönnyít és felgyorsít. Programfejlesztés és végrehajtás terén is.
Az Xbox One-ban is ott van az EDRAM, márpedig ez volt az olcsóbb opció a PS4 GDDR5 ramos megoldásával szemben. Lehet persze, hogy desktopra/mobil vonalra így is drága, nem tudom. Megjegyzem, nem feltétlen kell 128 MB belőle (mint az Iris Pronál), hogy sokat gyorsíthasson a számításokon. A DDR4 nem létszükséglet mellette (inkább a CPU-nak van rá szüksége).
[ Szerkesztve ]
Mikor irtam olyat, hogy bukasra van itelve a HSA? Szo sincs errol. En csak azt irtam, hogy en tobb fantaziat latok a direkt GPU programozasban, mint a HSA-ban. Aztan majd kiderul, kinek a fantaziai jonnek be a valosagban Eleve van kb. 3 ev, mire az AVX-512 implementalva lesz egy x86-os mainstream processzorban; es a HSA sem holnaputan kezdi meg a hoditast. Az ido majd eldonti a kerdest.
En szemely szerint egyszeruen nem fogadom el kritika nelkul a marketing BS-et. Akarmilyen PDF-et meg webes oldalt mutogathatsz, hidd el, nem azzal van a gond, hogy ne tudnam, mire jo a HSA es mikepp lehet fejleszteni (majd) ra. A problema az, hogy nem oldja meg az OpenCL/CUDA problemait, hanem -- SZVSZ -- tovabbi reteg(ek)et rak ra, hiszen ahogy irjak is a PDF-ben:
"The HSA platform is designed to support high-level parallel programming languages and models, including C++ AMP, C++, C#, OpenCL, OpenMP, Java and Python, to name a few."
Tehat nem a felsorolt nyelveket valtja fel, hanem azokra epitkezik. Nem lenne ezzel semmi baj, ha:
1) Nem lenne mar most is problema a latency ezekkel a nyelvekkel. Fenyevekre van az elerheto latencyje egy direkt C++ nyelven (plane assemblyben) programozhato architekturanak az OpenCL-lel/CUDA-val/stb programozhato GPU-ktol.
2) Nem lenne mar most is problema ezekkel a nyelvekkel az optimalizaciok kapcsan. Persze mondhatod, hogy ezek a nyelvek nem errol szolnak, plane a Java, de nezzuk csak meg, hogy pl. Javaban es rokonaiban (pl. .NET) tipikusan milyen szoftvereket is fejlesztenek? Pl. Catalyst Control Center, netbankok, AbevJava, stb. Olyan szoftverek, ahol a portolhatosag az elsodleges, es nem igazan szamit a teljesitmeny. Na most, ha en egy GPU-t akarok meghajtani, akkor pont a vart/megalmodott nagyobb teljesitmeny miatt fordulok a GPU-hoz, es nem a kozvetlenul programozhato CPU-hoz. Ahogy hulyeseg Javaban megirni egy teljesitmeny orientalt szoftver(modul)t, ugy OpenCL/CUDA/tarsain is csak akkor mukodhetne ez a dolog, ha a teljesitmenyt sokkal jobban ki lehetne aknazni.
Jelenleg egyebkent azt ajanlja minden gyarto, hogy hosszan futo, sok szamitast igenylo kodot irjunk a GPU-kra, minel kevesebb host <-> device forgalommal. Ez pont azert van igy, mert az egesz hobelevanc latencyje nem tul kedvezo, es rossz a savszelesseg a host es device kozott. Az utobbira megoldas lehetne a HSA -- pontosabban az egyseges cimter, amihez nem kell HSA, hanem csupan OpenCL 2.0 --, csak ugye az APU-knak me'g jovore sem lesz elegendo savszelessege, tehat eleg korlatozottan lehet kihasznalni az egyseges cimteret is. Egy 4 csatornas memoriavezerlovel + DDR4 memoriaval + eDRAM-mal megspekelt konfiguracional egesz mas lenne a szitu, csak ugye az AMD nem azon a piacon focizik. Ha meg diszkret GPU-t programozol, akkor megsutheted az egyseges cimteret meg a HSA-t, sajnos...
>De valószínű az OpenCL compilernek is könnyebb dolga lesz a HSA-compliant hw-eken (most teljesen más architektúrák között kell hidat képeznie.)
Mi koze az OpenCL compilernek ahhoz, hogy HSA- vagy nem HSA-compliant a hw? A HSAIL --> GPU direkt gepi kodja forditast nem tudod meguszni. Es ha nem HSAIL binarist mellekelsz a szoftveredhez (mert mondjuk nem-HSA-s konfiguraciokon is szeretned, hogy fusson), akkor a source --> HSAIL --> GPU direkt gepi kodja forditasi lanc pont ugyanaz a maszlag, mint most a "sima" OpenCL eseteben. Raadasul, jelenleg hazon belul foglalkoznak az OpenCL forditok a 2 lepcsos forditas mindket szakaszaval, megis elcseszik a forditot a gyartok. Ha ilyen korulmenyek kozott -- amikor csak sajat magukkal kell "egyeterteniuk" -- is ilyen silany munkat vegeznek, belegondolni is rossz, mi lesz majd a mixed HSA meg hasonlo konfiguracioknal. Pl. APU + diszkret GPU, hogy csak egy egyszeru peldat mondjak.
Megjegyzem, ha a HSA egyszerunek tunik, akkor az altalad linkelt PDF-ben ajanlom tanulmanyozasra a 4.1 es 4.2-es abrakat. Ennel szamomra egy piciket egyszerubbnek tunik a direkt programozas Vicces az is, hogy az abrak szerint a CPU-t is HSA-n keresztul hajtjak meg: na az egy baromi hulye otlet. Erdemes kiprobalni, milyen teljesitmenye van a meglevo OpenCL CPU drivereknek: nagyjabol a siralmas es a nevetseges kozotti hatarmezsgyen mozognak, hiaba van bennuk SSE meg AVX vektorizalt optimalizacio is. Ezen pedig vajmi keveset fog segiteni a HSA...
A konzolok pedig fix hardverek, azokra mindig is baromi konnyu volt szoftvert gyartani, compilert irni, hardver-szoftver optimalizaciokat megoldani. Ne hasonlitsunk egy barmilyen konzolt a HSA-s PC-hez. Ha az AMD-nek is csak annyi feladata lenne, hogy egyetlen GPU architektura (GCN2) egyetlen GPU generaciojahoz (Kabini es tarsai) keszitsen egy utos OpenCL compilert, hidd el, semmi baj nem lenne a compilerevel. Megertem egyebkent, hogy benaznak, csak a fejlesztoket pont ezekkel a baromsagokkal idegenitik el. Maga az OpenCL szogegyszeru, mint ahogy a HSA is az lesz, a problema azonban az, hogy a legtobb szoftverbe nehezen illesztheto be ez a fajta megkozelites. Nem veletlen, hogy baromi keves OpenCL-t _rendesen_ kihasznalo szoftver letezik jelenleg.
[ Szerkesztve ]
Pl. #33-asból eléggé ez jött le. Nem tudom, mennyi realitása van, hogy a programozók nekiállnak direktben különféle GPU-khoz low-level kódolni GPGPU-s alkalmazásokat, amikor eleve a CPU-tól is nehezen szakadnak el? Vagy tulajdonképpen az Intel AVX-512 alapú GPU-szerű, x86 alapú chipjeire gondolsz, ami talán véleményed szerint idővel majd kiszorít mindent, így a végén nem kell majd többfelé kódolni? Én meg erre nem fogadnék.
A HSA-nak csak egy része a HSAIL-es megoldás. A HSA kompliancia adott szintjeihez tudnia kell a hw-nek az ezen a képen látható tulajdonságokat. Ezek könnyítik meg a programozó és a compiler dolgát és teszik gyorsabbá a több szinten a folyamatokat. (Talán nem kell ecsetelnem a közös címtér, pointerek, lapkezelés, koherens memória- és cache-kezelés előnyeit. Aztán jön majd a többi.) A HSA tehát a korábbiaknál nagyobb elvárásokat támaszt a GPU-kkal szemben, hogy mindezzel sokkal jobb alapokat nyújtson GPGPU-s célra.
A HSAIL-nek lényeges eleme a portolhatóság (ami manapság igen fontos szempont), de nem csak ezt tudja. Nem ront az eddigi OpenCL-es "helyzeten", hanem javít. Gyorsabbá teszi a funkció invokációt, stb.
Maga az egész HSA nagyban optimalizálja az egész GPGPU-s funkcionalitást. (Nem csak a host <-> device sávszélt.)
Nem tudom, a HSA hogy viszonyul a dGPU-khoz, nem biztos, hogy parlagon hagyja őket.
A HSA Finalizer közvetlenül az adott platform CPU-jára is tud natív kódot fordítani, a HSAIL kihagyásával.
Ha az eDRAM vagy eSRAM cache-ként funkcionál, akkor különösebb szoftveres bűvészkedés nélkül is sokat tud segíteni a sávszélproblémán.
Egyelőre nem nagyon ismerjük az AMD későbbi terveit. Megtehetik, hogy gondolnak egyet, és a dGPU-ik helyére is (brutális) APU-kat tesznek majd... Az Nvidiának is vannak efféle tervei, csak x86 licencek híján ARM alapon.
Sok közös vonás van a HSA és az OpenCL 2.0 között. Ebből is láthatod, hogy nem haszontalan dolgok ezek. Jól megférhetnek egymás mellett, sőt egymást erősítik. Ha egy hw támogatja az OpenCL 2.0-át, onnan már nem sokból áll a HSA támogatása. A HSA jobb kompatibilitást és könnyebb portolhatóságot biztosíthat a programoknak, az OpenCL mellett más nyelveken írottaknak is.
Az AVX-512 kapcsan alapvetoen arra gondolok, hogy ha megnezed az Intel architektura fejlodeset mondjuk a Lynnfieldig visszamenoen, akkor "gyanusan" 2 evente duplazodik az elmeleti lebegopontos SIMD savszelesseg, amennyiben azt FLOPS-kent definialjuk. A Lynnfield 128 bites SSE egysegeihez kepest a Sandy Bridge 2x szelesebb (256 bites AVX), majd a Haswell az FMA-val kvazi megint duplazta ezt. Persze most le fog lassulni a tempo, hiszen a Skylake kapcsan nem varhato az AVX-512 beepitese, de ha csak egy olyan processzort veszunk, ami Haswell + AVX-512, az megint duplazasa a szamitasi kapacitasnak. Raadasul -- ez sem elhanyagolhato szempont -- a dupla pontossagu szamitasi kepessegek sokkal kedvezobb aranyban allnak az egyszeres pontossaguval, mint mondjuk egy Kabini vagy Richland eseteben (ahol 1/16 az arány).
Par eve me'g elkepzelhetetlennek tunt volna egy ilyen eros SIMD FPU, mint amivel most a Haswell buszkelkedhet. Emiatt sem tudtuk volna elkepzelni me'g par eve, hogy egy FPU-val hozni lehet egy also-kozepkategorias GPU szamitasi teljesitmenyet.
Ha eloretekintunk par evet, akkor siman osszejohet az Intel FPU-bol az a szamitasi ero, amit mondjuk a Kaveri fog tudni a GCN2-es iGPU-javal. Innentol pedig csak egy-ket kiegeszito modul vagy szoftveres emulacio szukseges ahhoz, hogy ki lehessen hajitani az egyebkent is erosen problemas Gen7/Gen8-as iGPU-t a Goldmontbol, es mehet minden FPU-val. Es akkor nincs szukseg semmi hokuszpokuszra, direktben lehet programozni a "GPU"-t.
Persze mindez csak elmeletileg lesz/lehet igy, az Intel pontos terveit egyelore nem ismerjuk. Az biztosnak latszik, hogy -- furcsamod -- a Larrabee 512 bit szeles SIMD utasitaskeszlete helyett vagy mellett megkapja a kovetkezo generacios MIC/Xeon Phi (Knights Landing) az AVX-512 tamogatast. Az azonban kerdeses, hogy mikepp fog valtozni a Gen8 utan az Intel mainstream iGPU-ja, pl. lesz-e MIC alapu iGPU, vagy esetleg kihuzzak a mostani architektura patchelgetesevel a Goldmontig -- ami az elso AVX-512 tamogatasu hagyomanyos CPU lesz, ha minden igaz. Nem vagyok egy roadmap magus, igy egyelore nem tudnam megmondani, mikorra varhato a Goldmont, ugyanis tul sok kodnev repked a levegoben Jovore Broadwell, 2015-ben Skylake, utana Skymont, Airmont, Goldmont -- de ezek kozott siman lehet egy-ket Silvermont architekturas low-end proci is 
Mindenesetre, latva az AVX fejlodeset, en siman el tudnam kepzelni, hogy ne legyen szukseg iGPU-ra mondjuk 3-4 ev mulva. Az FPU-t, IMC-t, PCI Express vezerlot (stb) is sikerult kavarasmentesen integralni, pedig azok is kulso egysegkent kezdtek palyafutasukat.
A HSA kapcsan egyebkent nagyon keves a kozos cimter. Segit, jo dolog, de keves. Egy atlagos szoftverbe nehez lesz me'g igy is beilleszteni, foleg mert nem feltetelezheted, hogy minden a gepben levo GPU tamogatja ezeket a fejleszteseket (lasd diszkret GPU-k). Olyan szoftvert pedig csak konzolra lehet irni, ami azt feltetelezi, hogy APU-d van, es nincs semmilyen dGPU-d -- ezert sincs sok ertelme a konzolokat a PC-hez hasonlitani.
[ Szerkesztve ]
Persze hogy sok kozos vonas van, hiszen az AMD az OpenCL fejleszteset a HSA iranyaba lokdosi folyamatosan Irjak a sok blablat, hogy milyen nyelvekkel lehet fejleszteni HSA-ra, de ugyis szinte mindenki OpenCL-en fog. Ezert is fontos az, hogy milyen minosegu, milyen konnyen kezelheto az OpenCL...
Marketingben egyebkent jo vagy, tetszik ahogy es amiket irsz a HSA-rol. Legyen igazad, az AMD-nek kene mar egy sikerelmeny is (a konzolokon meg a Kabinin kivul).
[ Szerkesztve ]





