







Gyorskeresés
Legfrissebb anyagok
- Bemutató Route 66 Chicagotól Los Angelesig 2. rész
- Helyszíni riport Alfa Giulia Q-val a Balaton Park Circiut-en
- Bemutató A használt VGA piac kincsei - Július I
- Bemutató Bakancslista: Route 66 Chicagotól Los Angelesig
- Tudástár AMD Radeon undervolt/overclock
Általános témák
LOGOUT.hu témák
- [Re:] [DarthSun:] Retro kedvenceim 5. A P4 korszak a 423- tól a 478- ig
- [Re:] PLEX: multimédia az egész lakásban
- [Re:] [sziku69:] Fűzzük össze a szavakat :)
- [Re:] [sziku69:] Szólánc.
- [Re:] [hcl:] Panasonic TZ-100 vs. szárnyashangya
- [Re:] [callmeakos:] A bukott koncepció, amiért háromszor is fizettem.
- [Re:] Elektromos rásegítésű kerékpárok
- [Re:] [gban:] Ingyen kellene, de tegnapra
- [Re:] [D1Rect:] Nagy "hülyétkapokazapróktól" topik
- [Re:] [Luck Dragon:] Asszociációs játék. :)
Szakmai témák
PROHARDVER! témák
Mobilarena témák
IT café témák
GAMEPOD.hu témák
Hozzászólások
(#2) Krugszvele

Krugszvele
aktív tag
az 1M-et nekem CPU-n kiszámolta 3 másodperc alatt ez valami új algoritmus? 


Furcsák a weboldalon lévő eredmények...
A GTX980 a 144GF DP teljesítményével 33s alatt végez, az R9 290 pedig 22sec alatt a 606 GF DP teljesítménnyel.
Vagyis több, mint négyszeres DP erővel csak másfélszer gyorsabb.
Egészen biztos, hogy DP-vel számol? 
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

Zoli0726
aktív tag
Lehetséges, hogy nem sikerült épp optimálisra a kihasználtság 
32Millió számjegy:
4.0ghz 4670K: 41 másodperc.
R9 280X: 2 másodperc.
Láttam már jobb skálázódást is.
[ Szerkesztve ]

bacsis
Közösségépítő
nagyjából mint az Intel Vs AMD processzoroknál is... ott is, azonos nyers erejű AMD CPU harmada olyan sebességgel futtatja
(#6) macilaci78

macilaci78
nagyúr
Ad lehetőség a program a 9 számjegyes blokkokat kimenteni csv-ba, txt-be, akárhova?
Már ha valaki látni szeretné egy végtelen tizedes tört első egymillió karakterét. 
Ha minden kötél szakad, nem kell félni az akasztástól!
Nem hiszem, hogy erről van szó, mert 17-szeres sebességgel futtatja a radeon, mint egy csúcs i7, ami szerintem 100GF körül van DP-ben.
Szerintem ez szimpla pontosság lesz, mert az magyarázná mindkét kérdést.
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

Rive
veterán
Nem tudok eleget a használt algoritmusról (és nem, nem is akarok többet tudni róla ), de az eredeti SuperPi az biz' szigorúan egyszálas volt.
Elég nehéz az adott feladatot egy masszívan többszálas architektúrára optimalizálni, szóval úgy sejtem, ez az inplementáció se kifejezetten többszálas.
Azaz: nem tudom, hogy a végrehajtóegységenkénti teljesítmény szerint is irreálisak az eredmények, vagy csak a kumulált teljesítmény szerint.
Ha érthető, mire gondolok.
/// Nekünk nem Mohács, de Hofi kell! /// Szíriusziak menjetek haza!!!
Érthető, de az a logikátlan számomra, hogy egy elméletben 600Gf DP teljesítményű GPU 17-szer gyorsabban futtatja azt, mint a 100GF körüli CPU. Ez azt jelentené, hogy egy elméletileg univerzálisabb CPU-n aránytalanul lassan fut. Ehhez jön még hozzá, hogy az nV-n pedig megmagyarázhatatlanul gyorsan fut, vagyis egy 144GF DP erejű GPU ~11-szer gyorsabban futtatja, mint a 100GF DP körüli i7.
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

pakriksz
őstag
akkor vagy valami másik bottleneck van, vagy SP-vel számol. Egyébként mire jó ez az extrém nagy pontosságú pi számolás?
[ Szerkesztve ]
Troll (nemhivatalos definíció): az akinek véleménye nem tetszik nekünk/nem értünk vele egyet. (10-ből 9 fanboy ezt ajánlja) || Fanboy 8 in 1 (Intel, AMD, Nvidia, konzol, PC,+minden politikai oldal) hiszen "ahol nem mi vagyunk, ott az ellenség"
A weboldaluk szerint valóban DP-vel műxik.
Akkor vagy az nV nagyon jó openCL-ben, vagy az intel (és az AMD is) van izomból lemaradva e téren, mert a 11szeres differencia kissé soknak tűnik nekem tudva azt, hogy a gtx980 asima pontosság 1/32-szeresével működik DP-ben.
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Rive
veterán
Aha, átolvastam még egyszer. Szóval valami párhuzamos algoritmust használ.
Innentől kezdve viszont sejtelmem szerint a párhuzamosan futó szálak közötti adatmegosztás és az optimalizáció lesz a legfontosabb tényező, nem a futtató hardver elméleti max. teljesítménye.
/// Nekünk nem Mohács, de Hofi kell! /// Szíriusziak menjetek haza!!!
KTTech
veterán
Az nVidia mindig is nagyon jó volt az OpenCL/GL támogatásban... lehet, itt is ez köszönt vissza (ellentétben az AMD-vel).
[ Szerkesztve ]
www.kttech.hu //A szgépem/fényképezőm configja az adatlapomon

flash-
veterán
szuper, erre vágytam ,most már tudok aludni
"Embrace our fellow man, no longer vilified"
Az intelhez képest is túl jó ez az érték, itt méginkább feltűnő.
Persze, valószínűleg - ahogy Rive írja - maga a szoftver van így megírva.
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Jack@l
veterán
Vagy örüljünk ennek is, hogy ennyire ki tudták használni az opencl adta lehetőségeket, mert elég kevés feladat van ami fekszik a gpu-knak.
Nálam kb 15x-ös a sebesség a cpu-hoz képest, azt hiszem ez is igen szép teljesítmény tőlük.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
KTTech
veterán
Az Intel is még csak most kezdi bontogatni az OpenCL driverét, amúgy sem erősségük a driverkészítés (lásd a saját GPU drivereik)... egyre jobbak, ez igaz, de még van bőven tennivalójuk optimalizálás terén. Sztem egyszerűen itt jött ki a különböző gyártók különböző OpenCL driverének optimalizáltsága...
www.kttech.hu //A szgépem/fényképezőm configja az adatlapomon

Neovenator
senior tag
A játékok optimalizálása egy dolog, az általános számításokra használt OpenCL driver egy egészen másik. Az Intel OpenCL driverével nincs különösebb probléma, ne általánosítsunk.
"The problem of leadership is inevitably: Who will play God?"

BatchMan
senior tag
Igen, szeretném ellenőrizni, jól számolt-e.
Ha elcseszi a 263 852. jegyet, onnantól hiába számolja a maradékot...

Abu85
HÁZIGAZDA
Pontosan. Pláne, hogy az OpenCL-nél a legtöbb szoftverfejlesztő egy implementációra optimalizál, de arra nagyon. Tehát a sebesség attól függ, hogy az adott fejlesztő kire írta a programot. Az Adobe, Corel, Sony, Cyberlink, Strongene, VideoLan például AMD-re optimalizál. A Cyberlink és Strongene H.265, illetve a VLC scaling máson nem is hajlandó futni, tehát még a lehetőséget sem kapják meg az Intel és az NV OpenCL implementációi. Az NV a CUDA-val foglalkozik, míg az Intel például azokban a programokban, amelyek optimalizáltak az Intel OpenCL-ére nagyon is jó. Lásd LuxRender. Mostanában kapnak Adobe optimalizációkat, szóval kezdenek feljönni ott is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Jack@l
veterán
Butaságot beszélsz, nincs olyan hogy amd vagy nv-re optimalizálnak egy opencl kódot, olyan van, hogy gpu-ra, olyan is van hogy 1 bizonyos gpu-ra, vagy konkrét cache/cu méretre darabolják a részfeladatokat.
Meg olyan is van egy programnál, hogy lekérdezi az opencl device nevét, és ha van benne amd akkor engedi futtatni...
Plusz ami opencl 1.2 kompatibilis kód, az valószínűleg nem fog futni nv kártyán, ha az csak ocl 1.1-et tud.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
Abu85
HÁZIGAZDA
Sajnos az egyes GPU-architektúrák között nem portolható a kód teljesítménye. Éppen ezért specifikus optimalizálásra van szükség, akár OpenCL implementációkhoz szabva. A szoftverfejlesztők kiválasztanak egy architektúrát/implementációt, amit céloznak, majd onnan portolnak és optimalizálnak másra.
Sajnos vannak olyan esetek is, amikor az adott kód nem portolható rövid időn belül. Lásd a WinZip 16.5, ami csak AMD-n futott, majd sok hónappal később jött a 17-es verzió, ami már elindult NV-n és Intelen is. Ugyanez a helyzet a Strongene és a Cyberlink esetében is, vagy a VLC OpenCL scaling modullal. Egyszerűen annyira jelentős módosításra van szükség a többi implementáció támogatásához, hogy egyelőre gyártóspecifikus a kód. Nem marad így, de rövidtávon nincs más lehetőség.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Jack@l
veterán
Mondom hogy nem, látom nem hiszel Fiery -nek és azoknak az embereknek akik már dolgoztak opencl-el(beleértve magamat is)...
Nincs portolás, egy opencl kód van, max lehetnek kompiler switch-ek a különböző cache méretek kihasználására.
Ugyanaz a kernel fut minden eszközön, a cpu-n is.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
Abu85
HÁZIGAZDA
Ha ez így működne a gyakorlatban, akkor nem látnád azt, hogy egy OpenCL kód nem képes futni valamelyik cég OpenCL implementációján. Ez egy komplex probléma sajnos. A SPIR a complier rendszer problémáján sokat segít, de ettől még egy x architektúrára optimalizált kód nem fog jól futni y architektúrán, ha nem optimalizálják specifikusan.
XY szoftvercég nem azért tiltja le az OpenCL kódot egyes gyártó implementációin, mert szereti manipulálni a piacot, hanem azért, mert a kód nem fut jól.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Jack@l
veterán
SPIR-t se érted mire jó konrétan úgy látom. Az egy köztes bináris, arra jó hogy ne plain textben kelljen tárolni az opencl kódot... (azt amit a driver fordít az adott eszközre első futtatáskor)
Semmi másra nem jó, csak hogy ne lophassák el egyszerűen a forráskódodat.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
Abu85
HÁZIGAZDA
Az OpenCL problémája alapvetően az, hogy minden gyártónak külön OpenCL fordítója van. És sajnos ezekre optimalizálni is kell, különben gondok lesznek a fordításnál. Senkit sem érdekel a kód ilyen formában történő megvédése, mert arra eddig is kínált opciót az OpenCL. A SPIR arra kínál megoldást, hogy legyen egy olyan egységes reprezentációs szint, ahonnan garantált, hogy az adott OpenCL, vagy most már SPIR kód futni fog az adott hardveren. Sajnos a jelenlegi SPIR nélküli implementáció ezt nem garantálja.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

---Lasali---
Közösségépítő
Azért jó hogy lett ilyen PI program is.
Én tesztem: 270X Toxic: 01m 14.240s
Kicsit elmarad az oldalon szereplő 290X től 
BatchMan
senior tag
Elfogadva tényként, hogy az egyes OpenCL változatok egyediek, nem bírom megérteni, miért nem lehet az egyes implementációkat úgy megcsinálni, hogy a futási eredményük ne különbözzön.
Azért Open az open, hogy mindenkinek egyforma legyen a futási eredménye, és biztosítsa az átjárhatóságot - csökkentve a programozók munkáját, de felvállalva, hogy a hatékonysága kisebb, mint egy típus-hardverre szabott kódszabványnak.
Jack@l
veterán
Erről azért beszélj Fiery-vel... Nem szeretném, ha nagy népbutítás lenne ezen a téren is egy magát szakmainak mondó oldalon. (legyen az akár szándékos, vagy tudatlanságból fakadó)
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.

huszar90
aktív tag
Érdekes kis progi, a super pi-t gyakran használtuk 
Abu85
HÁZIGAZDA
[link] - volt már róla szó.
(#28) BatchMan: Ez egy "Khronos betegség". A GLSL és az OpenCL fordítása is teljesen a gyártók oldalán valósul meg. Ez rengeteg problémát felvet a fordítás szempontjából. Az a modell jobban működik, amikor van egy meghatározott egységes fordító, ami csinál egy szabványosított bájtkódot, és onnan lesz fordítva a gyártók specifikus fordítójával a végleges kód. Erre megy a SPIR is, legalábbis addig nem lehet gond ezzel, amíg a Clang opciót használja mindenki.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Zoli0726
aktív tag
Azért elég furcsa dolgok történnek itt, az oldalon demózott R9 290 a 280X-emre kereken egy 2x eredménnyel (42 vs 21 másodperc)ver rá, miközben dupla pontosság mellett lassabb nála és egyszeres pontosságnál is kb 25% van a kettő között.

csib41
aktív tag
[link] Meg is van a célközönség.

Cathulhu
addikt
Hat azert par eve ha 128 bites blokkokban olvastad a memoriat, azzal jol keresztbe tudtal tenni egy nV-nek (nem tudom azota ez hogy valtozott) ezert votl celszeru 64-ben gondolkodni, az kb egyforman jo volt AMD-re es nV-re is.
[ Szerkesztve ]
Ashy Slashy, hatchet and saw, Takes your head and skins you raw, Ashy Slashy, heaven and hell, Cuts out your tongue so you can't yell

con_di_B
tag
A SPIR absztrakcios szintje valojaban nem sokkal melyebb, mint az OpenCL C forraskodoke, ezen tenyleg nem segit semmit. Ha melyebbet, "egysegesebbet" akarsz, akkor ott van a HSA IL, de valojaban az is virtualis gep, szoval a hatekony mapping az aktualis architekturara ugyanugy gyartospecifikus marad.
A kod megvedesere pedig nem kinalt szabvanyos opciot az OpenCL. Az egyetlen lehetoseged az volt, hogy minden egyes architekturara/driver verziora stb. kulon csomagolsz binarist a programoddal, de ez nem megoldas, foleg, hogy a jovobeni kompatibilitas meg adott gyarton belul sem garantalt.
[ Szerkesztve ]
Abu85
HÁZIGAZDA
Viszont a SPIR addig gyakorlati megoldás, amíg mindenki a Clang verziót használja. Tudtommal ebből a szempont egyetértés van. Ez már előrelépés lesz az iparágnak.
Ugyanezekkel a problémákkal máshol is meg fognak küzdeni a fejlesztők (Mantle, DirectX 12, OpenGL NG). Viszont a programfuttatást akkor is garantálni kell, ha teljesítményben a futtatott kód nem optimális az adott hardvernek.
A bináris szállításának valóban vannak kellemetlenségei. Folyamatosan kell biztosítani az új binárist az új hardvereknek és implementációknak. Aki így szállítja a programját, annak vállalnia kell az ezzel járó felelősséget is.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

7time
senior tag
Jack@l
(PH! addikt)
Butaságot beszélsz, nincs olyan hogy amd vagy nv-re optimalizálnak egy opencl kódot, olyan van, hogy gpu-ra, olyan is van hogy 1 bizonyos gpu-ra, vagy konkrét cache/cu méretre darabolják a részfeladatokat.
Ha így lenne akkor minden ami opencl és játék jobban futna az Intelen de egyértelmű hogy nem így van, akkor mégis van optimizálás egy adott architektúrára.
con_di_B
tag
Igazad van, hogy komplex problema, de a cel altalaban az, hogy egy forraskoddal le lehessen fedni minden gyartot, mert megis ki a fene akarna a sajat karbantartasi koltsegeit megtobbszorozni feleslegesen? Aztan, hogy mennyire kell megiscsak elagazni a gyakorlatban, az is egy masik problema.
Ha eleve ugy kezdesz el egy uj projectet, hogy azt mondod, hogy oke, OpenCL 1.1, mert azt a hulye is tudja, es desktopon minimum annyit megcsinalsz, hogy mindig teszteled Intel CPU-n, GPU-n, AMD CPU driverrel (nem is feltetlenul AMD CPU-n!), AMD GPU-n, es NVIDIA-n, es ugy haladsz, h mindig utanajarsz amikor az egyik elkezd nem mukodni, akkor olyan nagy bajod nem lesz, es ha betartod a fokozatossag elvet, akkor ez tenyleg minimalis erofeszites.
Azt szoktak elrontani a sracok, hogy kipreselnek magukbol par tizezer sort (device oldali kodrol beszelek), aztan vinnek at mashova, es csak annyit latnak, h "nem fut", "lassu", akarmi, aztan ha egy het bogyoreszes utan is lassu, akkor inkabb letiltjak a francba. De ez ugyanaz a tortenet, mint amiert mindig azt magyarazom, hogy akkor is cross-platform kell fejleszteni valamit, ha nem felhasznaloi igeny (egyelore!), hogy cross-platform legyen, mert kesobb megterul.
Az, hogy a teljesitmeny mennyire hordozhato, reszben az is fejlesztesi metodus kerdese. Altalanossagban nyilvan nem hordozhato, de ha mondjuk valaki a "make it work, make it right, make it fast" diszciplina sorrendiseget nem ugy ertelmezi, hogy veletlenul sem profilozza/meri le, hogy mit csinalt, mondjuk ugy a megjelenes elotti ket hetig bezarolag, akkor azert meg idoben fel fog tunni, ha valami valahol nem stimmel, es akkor meg program design szinten lehet ra reagalni, ha muszaj. Vagy kuldeni a bug reportot az Intelnek, hogy mar megint ugyesek voltak.
A hordozhatosag kesobb persze nyilvan fuggvenye annak is, hogy mennyire akarjuk csutakra optimalizalni adott szoftvert, de amennyi hulyeseget ezen a fronton mar lattam elkovetni (aminek a vegen a generikus kod gyorsabb lesz, mint a hardver specifikusan "optimalizalt"), illuzioink azert ne legyenek. Amit generikus koddal el lehet erni, az doszt eleg lesz, 90%-ban.
[ Szerkesztve ]
Jack@l
veterán
Te gpgpu fejlesztő vagy? Csak hogy felmérjem van e közöd egyáltalán a témához.
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.
con_di_B
tag
A SPIR csak a "fogyasztast" szabvanyositja, a generalast nem, viszont ahogy te is mondtad, mivel mindenki a Clang-et hasznalja, addig lenyegeben a generalas is tekintheto egysegesnek, pipa.
Viszont ez meg mindig csak a front-end! Minden ami izgalmas, platform-specifikus, es tenyleges optimalizacionak tekintheto, az ez utan tortenik!
Vannak bizonyos problemak, amiket ez megold, ugyanis a regebbi OpenCL C specifikaciok (szerintem nem, de a kozertelmezes szerint) nyitva hagytak par kerdest, peldaul, hogy pontosan mikor tortenik scalar-to-vector upcast implicite stb. amikben lehettek ertelmezesi elteresek, ha meg mindenki ugyanazt a front-endet hasznalja, akkor legalabb emiatt nem kell szivni.
Viszont az, hogy par hete azert kellett frissitenem az Intel GPU drivert az elozo "legujabbrol", mert egy ponton tul mindenen elhalt ami 64bites integereket hasznalt (core feature), szoval sanszos h a conformance testen se felelt volna meg, es tudtommal az a verzio is mar vidaman hasznalta a Clang-ot, szoval eselyes, hogy a back end halt ki alola, de mivel hiba uzenetet elfelejtett dobni... Szoval, igen, szerintem is logikus, hogy emiatt majd jobbnak kene lennie egy kicsit a dolgoknak, de ez inkabb arra lesz jo, hogy egyaltalan valahogy fusson a kod, de a teljesitmenyt erinto (back-end) reszletekre ennek semmilyen hatasa nincs.

bandika0626
senior tag
Nekem el sem indul.
AMD RYZEN R7 1700, Cooler Master MasterLiquid 240, MSI X370 SLI PLUS, Corsair 2x4GB DDR4 3600MHz,Asus dual 1060 3G , Gigabyte GTX 1060 3G , Coolermasters GX 450, WD Caviar black sata3 500GB, SSD samsung 830 64GB.

oPalRx7
tag
ezaz, 8 mag 8 szálon terhel, meg gpu is új cpu+gpu terhelési teszt, hajrá tápegységek

norbert1998
veterán
nekem a hf7850-em tuning nélkül 1,4 mp alatt számolja ki
az fx-8320 tuning nékül 11,7 s alatt
de gondolom számía többi érték is
32m karakter, 64-es redukció
[ Szerkesztve ]

JHC
tag
Nem semmi az FX proci. Nekem az öreg Phenom 1100T 21,8 másodperc alatt nyomta le a tesztet, ugyan ilyen beállítással.

Dexar007
veterán
Valaki azt mondta,szamolni kell valamit? ![;]](http://cdn.rios.hu/dl/s/v1.gif) Coin jön-e belole?
Coin jön-e belole?
Give me your cum,bull!

Baryka007
őstag
Ilyenkor gondolkozok el azon... hogy mennyit fejlődik a VGA piac egy pár év alatt... 2009 es csúcs videó kártya HD 5870 teljesítménye a "nagy" kártyákhoz képest ezekből a számokból ítélve... nem valami nagy
Device: AMD Cypress (20 CUs, 850 MHz)
OpenCL 1.2 AMD-APP (1573.4) is ready.
Compiling OpenCL kernels ... done.
Calculating 1.000.000.000th digit of PI. 20 iterations.
Allocated device memory : 335546368 Bytes
Batch Size : 20M
Reduction Size : 64
00h 00m 00.465s Batch 1 finished.
00h 00m 03.040s Batch 2 finished.
00h 00m 05.656s Batch 3 finished.
00h 00m 10.011s Batch 4 finished.
00h 00m 18.110s Batch 5 finished.
00h 00m 25.259s Batch 6 finished.
00h 00m 27.837s Batch 7 finished.
00h 00m 30.455s Batch 8 finished.
00h 00m 34.646s Batch 9 finished.
00h 00m 42.274s Batch 10 finished.
00h 00m 49.035s Batch 11 finished.
00h 00m 51.607s Batch 12 finished.
00h 00m 54.222s Batch 13 finished.
00h 00m 58.541s Batch 14 finished.
00h 01m 06.623s Batch 15 finished.
00h 01m 13.751s Batch 16 finished.
00h 01m 16.319s Batch 17 finished.
00h 01m 18.937s Batch 18 finished.
00h 01m 23.127s Batch 19 finished.
00h 01m 30.769s Batch 20 finished.
00h 01m 37.246s PI value output -> 5895585A0
Device time for pi calculation: 96.209 s
Device time for memory reduction: 1.037 s

troller
senior tag
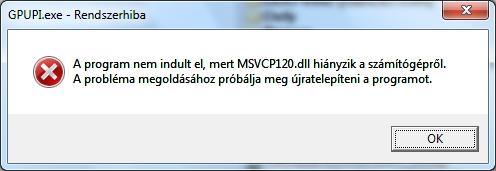
Ezt írja ki, ha futtatni akarom
Asus P8H67M-LE; i5 3330; 2x4GB DDR3; Gigabyte GTX 1060 3GB WINDFORCE OC
Tedd fel ezt: [link]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Jack@l
veterán
Ezt cpu számolta.
[ Szerkesztve ]
A hozzászólási jogosultságodat 2 hónap időtartamra korlátoztuk (1 hsz / 10 nap) a következő ok miatt: Az ÁSZF III 10/8. pontjának megsértése - trollkodás - miatt. Többször és többen is kértek már, hogy hozzászólás írásakor használd a linkelés funkciót, mert ennek elmaradása sokak számára zavaró.

Témaindító írás:

