




"A TSMC a következő elején veti be a 16 nm-es node-ot"
Hát, igen, majd a következő évtizedben..., talán... ![;]](http://cdn.rios.hu/dl/s/v1.gif)
A regisztrációdat véglegesen kitiltottuk a következő ok miatt: III.10.8 Üdvözlettel: PROHARDVER!
(#1) Kotomicuki

"A TSMC a következő elején veti be a 16 nm-es node-ot"
Hát, igen, majd a következő évtizedben..., talán...
A regisztrációdat véglegesen kitiltottuk a következő ok miatt: III.10.8 Üdvözlettel: PROHARDVER!

Ezt a gyártástechnológiát be tudja vetni az AMD is az APU-k esetében, igaz? És kb mennyi esély van rá, hogy a Carrizo körüli kavarás esetleg azért van, mert 2015 végén már tud jönni a 16nm-es utód a mágikus új architekturával?

A Carrizo marad 28 nm-en és a GloFo-nál is. Az még a Kaverinél is újabb HDL-lel készül, és a HDL-t nem lehet annyira gyorsan portolni. Ha most 20 nm-re rakják, akkor nagyobb lesz a lapka, mint 28 nm-en a HDL dizájnnal.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
A GLoFo/Samu 14nm-es node-ja hogy áll a TSMC 16nm-es eljárásához képest időben és várható technikai tulajdonságokban?
Vagyis mit lehet jelenleg tudni róluk AMD vonatkozásban?
[ Szerkesztve ]
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
Amennyiben az új architektúra nem tud erősödni az egy szálon mért teljesítményben - és nem óhajtják megoldani a memória-sávszélesség problémáját, ami most a leginkább visszafogó tényező - , akkor nagyjából az is csak akkora fejlődés lesz, mint a Richland-hoz képest a Kaveri: gyakorlatilag semmi érezhető előrelépés nem történt (még) egy generációváltás után (sem).
Ha igazak a zinteles hírek, akkor addigra ők is elérik azt a GPU-teljesítményt a CPU-jukban, amikor már az elérhető memória-sávszélesség fogja korlátozni az adott központi egység grafikus részlegének a teljesítményét -> utolérik az AMD-t, ezen a téren is és ezek után már szinte semmi sem marad a veresek kezében, amivel a piacon maradhatnának erősödhetnének...
A regisztrációdat véglegesen kitiltottuk a következő ok miatt: III.10.8 Üdvözlettel: PROHARDVER!
A GloFo cucca az a Samsungé. A Samsung idén már megmunkál 14 nm-es wafereket.
Tömeges átállás egyébként most nem lesz. Sok cég a dizájnszoftvert modernizálja, mert az többet ad, mint a gyártástechnológiai átállás. Ma már nem terveznek kézzel fizikai dizájnt. A sematikusból egy szoftver alakítja ki azt. Utóbbira viszont jellemző, hogy a sematikushoz képest a fizikai dizájn 30-40%-kal több tranzisztort jelent. Sokan ezeket a szoftvereket fejlesztették, hogy csak 5-10%-kal legyen több tranyó a fizikai dizájnban.
Az AMD biztos nem vált addig, amíg az új node gyorsabb nem lesz a most alkalmazott kombinációnál. Ez pedig lényegében azt jelenti, hogy amíg a HDL le nem lesz portolva rájuk. Az ultramobil lapkáknál válthatnak, de csak a kisebb platformdizájn miatt. Azért megéri a lassulást bevállalni.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Okés, értem. Köszi! 
A pletykált új x86 mag biztosan 14/16nm-en jön, vagy elképzelhető, hogy még modernebb eljáráson?
Vagy erről még semmit sem lehet tudni?
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html

Remélhetőleg ez már normálisabban sikerül, és majd nem csak alacsony teljesítményű lapkákhoz lehet használni.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
A magas teljesítményű lapkáknál nem lesz lényeges előrelépés. Oda tervezés kell mostantól és nem gyártástechnológiai fejlesztés. Szimplán az egyébként a probléma, hogy elértük azt a határt, ahol a kvantumfizika törvényei uralkodnak és azokat nem teljesen értjük. Tehát hiába az elmélet, hiába a grafikonokon húzott vonal, a valóságban nem lehet lényegesen kevesebb elektronnal bekapcsolni a tranzisztort. Egyszerűen kevés, kb. 50-nél kevesebb elektront nem iagzán lehet statisztikailag nagy tömegként kezelni. Meg kell érteni előbb a kis tömegű dolgok fizikáját, azon belül is jól kell alkalmazni a kvantummechanikát.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Az a baj, hogy így is garantált a kb. két év csúszás az intelhez képest a konkurens lapkáknál.
Sokan mondják, hogy nem csak a nm előtti szám a lényeg, hanem sok más tényező is befolyásolja az adott node-on gyártott lapkák lehetőségeit.
Ezért is lennék kiváncsi, hogy az intel 14nm-ese hogy viszonyul a bérgyártók 14/16nm-es eljárásához a technikai részletek tekintetében.
Eladó régi hardverek: https://hardverapro.hu/apro/sok_regi_kutyu/friss.html
A 28/32 nm-es node-ok óta mindenki megközelítette azt a bizonyos falat, tehát igazából már csak számháború van. Ezért is tömi számos cég a pénzt a dizájnszoftverekbe, mert meglátták, hogy az még előny, ha a sematikus dizájnból csak 5-10%-kal több tranyóból álló fizikai dizájn készül.
Az sem véletlen, hogy az Intel, a TSMC, a Samsung/GloFo 14/16 nm-es node-ja is gyakorlatilag fél éven belül válik elérhetővé. Egyszerűen beszűkültek a fejlesztési lehetőségek. Innentől a szám a nm előtt semmit sem jelent majd.
A gyártók szerintem átrakják a pénz egy részét a szoftveres fejlesztésekbe. Ott óriási kihasználatlan lehetőségek vannak. Ebből sok gyorsulás jöhet a jövőben.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
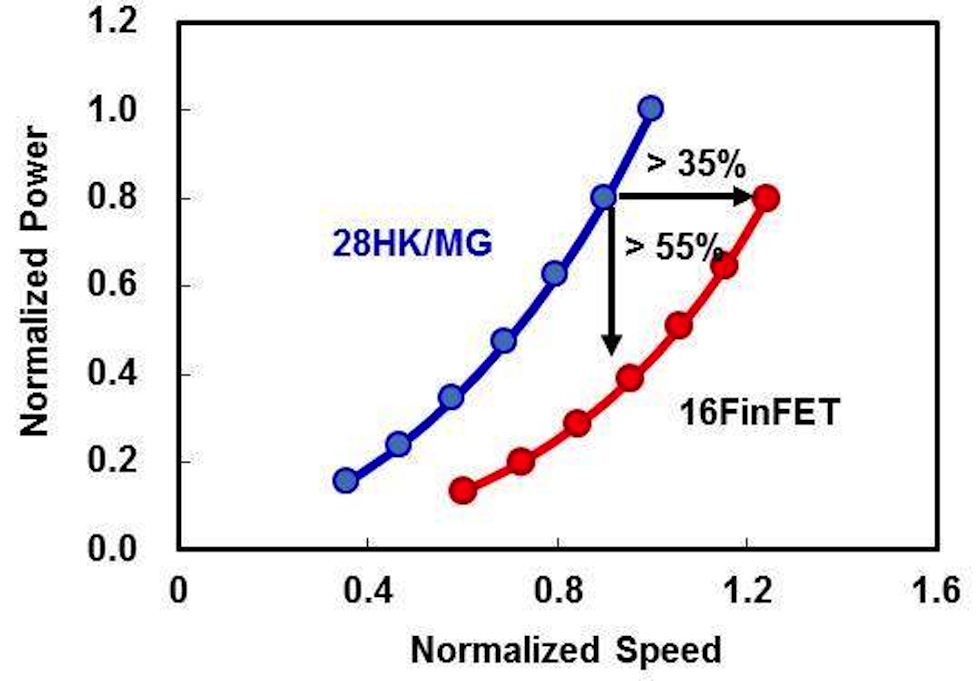
Ez egyszerűen nem így van (pl. lásd fenti grafikon), vagy az összes félvezetőgyártó hazudik.
Bici: Az Intel képes hozni az évek során megszokott tendenciát, amit majd a Broadwell-alapú cuccok alá is fognak támasztani. Itt találhatsz egy csokor adatot a 14nm-es technológiájukról.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
Nem hazudnak, csak elméletet vázolnak. Ugyanakkor a legfőbb gond, hogy a fizika törvényei az elméletet arcul köpik. Egy komplex lapkában egyszerűen nem képesek ezek az elméleti grafikonok működtetni, és az egy tranyó bekapcsolásához szükséges elektrontömeg sem lehet egy bizonyos szintnél alacsonyabb. Mivel ezt a szintet elértük, így a nincs hova tovább, hacsak meg nem értjük hogyan működnek a dolgok a kvantummechanika szintjén. Ugyanakkor ahhoz közelebb állunk, hogy máshol érjünk el javulásokat. Például a threshold voltage megközelítésével.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.

"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."

Arra leszek kíváncsi, hogy mi lesz akkor ha az új nodeok fejlesztése piaci alapon már nem lesz kifizetődő.
(az R&D költség annyira megnyomja a wafferek árát, hogy nem lesz aki kifizesse azokat)
Nyilván nem mindenkinek éri meg a legfejlettebb technológia megvásárlása, de ez számos esetben eddig is így volt.
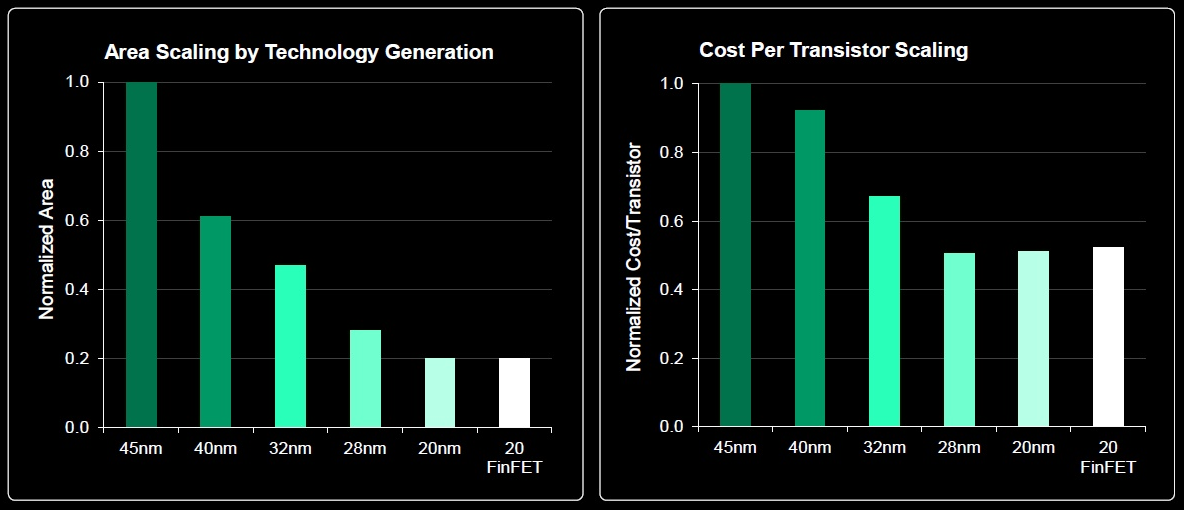
Tegyük fel, hogy kezdenek emelkedni a költségek, és mondjuk 10nm-en már ugyanannyiba kerülne az adott lapka mint 45nm-en, csak éppen 10nm-en jóval több tranzisztort bele tudnak sűríteni adott területbe, alacsonyabb fogyasztás és nagyobb teljesítmény mellett, ergo egy lényegesen versenyképesebb terméket kapnak ugyanannyiért. Ahol verseny van ott ezt be fogják, mert be kell vállalni, ahol nincs, ott értelemszerűen nem.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."

Abu, ne haragudj, nagyon tisztellek meg minden, de teljesen világos, hogy fingod nincs a gyártástechnológiáról.  A legjobb, ha tartózkodnál ezen a téren cikk írástól, mert már sokadszor bebizonyítottad a hozzászólásokkal is, hogy sajna komoly hiányosságokkal küzdesz. Igen, van marketing, vannak fizikai korlátok, de hogy kb két éve azt szajkózod, hogy a gyártástechnológia már nem ér semmit meg csak elmélet blabla. Teljesen alaptalan
A legjobb, ha tartózkodnál ezen a téren cikk írástól, mert már sokadszor bebizonyítottad a hozzászólásokkal is, hogy sajna komoly hiányosságokkal küzdesz. Igen, van marketing, vannak fizikai korlátok, de hogy kb két éve azt szajkózod, hogy a gyártástechnológia már nem ér semmit meg csak elmélet blabla. Teljesen alaptalan  . Ezt csak az a néhány tízmilliárd dollár bizonyítja amit ebbe öl minden cég. Jobb lenne, ha megmaradnál a Mantle és HSA szajkózásnál.
. Ezt csak az a néhány tízmilliárd dollár bizonyítja amit ebbe öl minden cég. Jobb lenne, ha megmaradnál a Mantle és HSA szajkózásnál.
No offense, csak ez már kijött belőlem...
[ Szerkesztve ]
JAJJMÁÁÁÁ

jo kis prezentacio. Az AMD keszit ilyeneket?
-
Sose mondtam azt, hogy a gyártástechnológia nem ér semmit, vagy alaptalan. Azt mondtam, hogy a szám a nm előtt már nem határozó meg annak képességeit, mert túl komplex az egész ahhoz, hogy csak egy 14-gyel, 16-tal vagy 20-szal elintézzük.
Már az előző évtized elején sejtettük, hogy jön a vég, mert a CMOS olyan fizikai összefüggésekre alapszik, amelyek csak bizonyos méret és tömeg fölött működnek. Alatta egyszerűen nem igazak, mert az atomi szinthez közelítve a kvantum mechanika szabályai lesznek limitálók. Persze régen azt hittük, hogy a vég az 1 elektron lesz, de ma már rájöttünk, hogy 100 alatt is gondok vannak.
A szoftvert ne keverjük ide. A sebességen valóban segítenek, de nem a hardveres problémákat számolják fel, hanem a korábbi szoftverek és programozási modellek gondjait.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Azért ezek a késések többnyire nem az AMD-n múltak mostanság, hanem a GloFo-n. Bár nem tudom mennyire kötelezsége az AMD-nek náluk gyártatni.
2015 vége meg nem esik annyira messzire 2016-tól és a Carrizo mobil fronton tartása se arra utal, hogy valamikor 2017 környékén akarnának valóban kijönni az új architekturával.
(#4) Abu85: Tudom, hogy a Carrizo-n már nem variálnak, csak gondoltam logikus lenne, ha csak azért hagyná ki a desktop piacot a cucc, mert a Kaveri refresh-t némileg olcsóbb bevezetni a piacra és kivezetni onnan, ha esetleg év végén jön az új termék. Mobil fronton meg ugye úgyis meglesz a Carrizo és utódja közt az 1 év minimum.
(#6) Kotomicuki: Az a bizonyos "beérés" az aktuális trendek alapján lett előrejelezve. Ehhez még az AMD-nek is kell egy sort töketlenkednie. Nagy kérdés például, hogy a Tonga azonos gyártástechnológia mellett mennyire tudott összemenni a Tahiti-hez képest, mert ugyanezt lehet hozni egy APU-ban is.
Az új architektúra kapcsán meg az a kérdés, hogy az Intel beérése-e a cél (tudtommal nem), vagy a szoftverfejlesztők (OpenCL2.0/C++AMP) kiszolgálása. Szvsz, ha a Puma+ vonalat sikerül annyira újragondolni, hogy c2c a Nehalem-hez közel tudjon kerülni (ez nagy hülyeség?) és bele tudjanak egy APU-ba pakolni 16-32 ilyen magot, akkor azzal sokkal jobban járnak, mintha üldözik az Intelt egyszálas teljesítményben.
első bekezdés teljesen agree. Acceptálva.
Eddig csak az intel 14nm-es nodjáról tudunk lényegi adatokat. Azok alapján rengeteget fejlesztettek. Szívnak is. A többiről csak marketing slideunk van. A TSMC igéreteket meg ismerjük. Amúgy itt elsősorban ők marketingeltek be, de nagyon! Először is azzal, hogy csináltak egy node-t alias 20nm, ahol továbbra is a 28nm-es BEOL (back end of line)-t használják. Ez eddig még elmenne, mondván hogy ők előbb használtak Double patterninget mint az intel és jobb volt a metal/interconnect sűrűségük (ezért majdnem olyan sűrű a TSMC 28nm-e mint az intel 22m,-e). Aztán pofátlanul csináltak egy 16nm-es node-ot. Nem meglepő módon ez egy 20nm-es node csak a tranzisztor már nem planer hanem finfet. Ez is 28nm-es BEOL-t használ. Ennek olyan szar karakterisztikája van a riválisokéhoz képest, hogy marketing slideokon sem sikerült értékelhetőt alkotniuk ezért aztán a finfetek át designolásával kicsit közelítettek az intel/glogfo/samsung publikált adataihoz és csináltak egy mit? Na segítek....16nm Finfet+ nevű node-t . Na ennek a tranzisztor karakterisztikája már közelebb áll a riválisokéhoz, de persze ez is 28nm-es BEOL-al készül.
Tehát nm= MArketing teljesen egyet értek. Ebben a TSMC mindenkit agyon csapot most. Egyszerűen elmondták a marketingesek. a következő node=2x tranyó sűrűséggént kell értelmezni. Ezek után már meg sem kell kérdezni mért nem csökken a marketing slidekon a tranyók ára? Mért ugyan annyi a cost/gate több node-n keresztűl? Hát mert ugyan az a Beol van alatta csak komplikáltabb technikával, drágább waferekkel és valszeg sokkal szarabb kihozatallal gyártva mint az eddigi planer tranzisztorok. A sűrűség előny ott lesz, hogy a litográfival kisebb tranyókat hoznak létre és a finfet driszketizációval is lehet játszani de a metal/interconnect ugyan az lesz. A TSMC csak 10nm-en újít . Tehát lett 3 node. 20nm/16nm/16nmfinfet+. ami igazából 28nm BEOL-t használ. végig 64nm-es interconnectel.
A marketing odacsap. Az is tisztán látszik, hogy miért csökken az intel tranzisztor költésge. Mert náluk a BEOL is fejlődik (pl 52nm-es interconnect lesz). Eddig tradicionálisan szarabb volt a sűrűségük de sokkal jobb a tranyó karakterisztikájuk mint a riválisoké. Most a sűrűség és a tranyókarakterisztikában is az élre állnak és szerintem erről már nem is fognak lemondani. Nem véletlenül van egy törés a diagramjaikon hogy a 14/10nm még agresszívebb. Nos ezért is vannak kb 1év csúszásban. De persze nem kell félteni az intelt sem marketing vezénylés terén. Elég csak a Broadwell/skylake megjelenést nézni. Negyedévenként 1 millirádot buknak a mobil bizniszen de ahelyett, hogy a broadwell M-et kivéve törölték volna a teljes broadwell szériát és csak a skylake jönne mondjuk a tavaszi IDF-en összel a Skylake-M és 2016 tavaszán visszatérve az útra jöhetett volna a 10nm-es Cannonlake helyette jön a tologatás és átrendezés. Hát kérem szépen így nehéz. Ezzel sokkal kevesebbet buktak volna és értelmesebb upgrade alternatívát is tudtak volna kínálni a népeknek. töredékéből a negyedévenkénti 1milliárdos kiadásnak.
Másik dolog: A CMOS korszaknak vannak határai. Mindig kiterjesztik őket. És a vak is látja, hogy ez 2020-ig biztosan így is marad. a 7nm 100% de a roadmappek már mindenhol 3nm-ig mennek le. Teljesen más fajta tranzisztor struktúrák vannak kifejlesztés alatt, és már mindegyiket tesztelik is és mérlegelik a tömeggyártásba helyezésüket. 10-7nm környékén jön A III-V alapú tranyó vagy a Gate all-around tranzisztorok, hogy leváltsák a finfeteket. EZ az ultimate geometria. Utána a kettőt kombinálják attól függően melyik jön előbb. Megoszlik a vélemény. A III-V-t előrébb várta az ipar de majd meglátjuk. Utána ott vannak a T-fetek és heterogén T-fetek az SRAM helyett a közeljövőben az STT-ram. Ezek olyan gyártástechnológia kvantum ugrások lesznek, hogy csak most jön a revolúció. 2020 körül jön a fejvakarás. Ottanra kell okosnak lenni, hogy grafán, spin tronika vagy mi egyéb felé mennek. Szóval az aggodalmakat még 2020-ig tessék félretenni és addigra megint tudni fogjuk mi jön
Ha van három tényező ami meghatározza egy optimális CMOS eszköz teljesítményét akkor az alábbi sorrend: Gyártástechnológia-Arhitektúra-szoftver.
Ehelyett most itt tartunk: Szofver-Szoftver és a Gyártástechnológia és az arhitektúra fej fej mellett. AZ utóbbi csak az utóbbi 5-6évben fejlődött nagyot. Gondolok itt az energiatakarékos kapuzható processzor tervezés és gpu tervezési filozófiákra. De ez hamar kimerül. Minden generációval már csak 20-30% nyerhető jelenleg perf/wattban és ez folyamatosan csökkeni fog. A gyártech garantált 50% előnyt jelent perf/wattban. A szoftver jelenleg pedig 5000000000%-ot.
De lényeg a lényeg, nem kéne temetni a cégeket mert tudják mit csinálnak. Egyre többen maradnak le, mert egyre drágább a kutatás fejlesztés. Az egyetlen dolog ami igaz a slideokból, hogy volumen kell. MErt egyre drágábbak a designok és validációk mert egyre komplexebbek a chipek. De a tranyó/dollár tovább fog zuhanni. Csak egyszerűen az aki nem gyárt 50-100millió chipet ezt nem fogja tudni élvezni.
No ennyi, kalap kabát...
[ Szerkesztve ]
JAJJMÁÁÁÁ

Egy optimalizált design mennyire hibatűrő?



Ezért nincs még 20nm-es GPU, és a TSMC gyártósorairól már valószínűleg nem is lesz. Btw ők már a 32nm-es technológiájukkal is felsültek anno.
Amúgy nem nagyon értem, hogy egy bárgyártó esetében mire jó a marketing bullshit, hisz a partnereket nem lehet megvezetni vele, a sarki fűszeres pedig nem fog legyártatni 5 processzort magának a jobban hangzó, vadiúj xx nanométeres technológián.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
A marketing bullshit inkább a jövőnek szól. Most faszák vagyunk, de ilyen meg olyan jók leszünk, a riválisokhoz képest meg hajjaj! A többi a külvilágnak szól. Mindenki csinálja. Az AMD prezik alapján is a Bulllllldóóóózer nagyon jó lett, aztán mégsem. De ez minden cégre igaz. A jelent próbáljuk meg elmismásolni, mert a jövő úgyis úton és a partnereink már tudnak mindent róla de a jövő az mindig szebb és jobb lesz mint a konkurensnek.
JAJJMÁÁÁÁ
Ebből számomra továbbra sem világos, hogy egy kizárólag vállalatoknak gyártó cég miért rázza a rongyot, amikor semmi haszna nincs belőle, de mindegy is.
Talán a részvényeseknek akarnak imponálni, mást nem tudok elképzelni.
[ Szerkesztve ]
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."

Különösebb változásra úgy látom nem kell számítanom 2016-ig.

Szerintem annyiban igaza van, hogy a kvantum mechanika beleköp a levesbe. Gate stack is azért olyan már, amilyen. Az látszik, hogy egyre bonyolultabb a gyártástechnológia, és ettől drágább lehet a gyártás.
Abu85 Mit értesz "sematikus dizájn" alatt?
[ Szerkesztve ]

Hiaba mondjak, hogy a fizikai korlatok, hotermeles meg kvantummechanika miatt nem lehet gyorsabb a kissebb tranzisztor, ha egyszer 2-3-4x annyi tranyot lehet egysegnyi helyre bepakolni. Ebbol meg egyre bonyolultabb mikroutasitasoknak keszithetnek dedikalt aramkort, ami noveli a teljesitmenyt/csokkenti a hotermelest mikozben az egysegnyi tranyo nem gyorsult semmit. Dragabb, az igaz, de a csucskategoriat el lehet adni sokszoros aron, alatta meg mar az arral is kell versenyezni.
@Oliverda: Mert szerintem erzik, hogy gaz mar 5 eve 28-32 nmen allni, mikozben a konkurencia mar 2 nodeal lehagyta oket es pusztan erobol elveri oket. Kulonosen most, hogy az Intel is vallal bergyartast, mar nem ketszereplos a piac.

abban madj lehet. De nem most. És kitudja mióta haljuk, hogy nincs értelme 20nm alá menni mert nem lesz olcsobb vagy/és gyorsabb vagy/és nem fog kevesebbet enni.
Erre kijöttek az intel prezik [link] és aki fentiben hitt annak koppant az álla.
[ Szerkesztve ]
don't look up, don't look up, don't look up, don't look up, don't look up, don't look up, don't look up...
Rengeteg trükköt be kell vetni ahhoz, hogy jól működjenek ezek az eszközök. A gate stack (HKMG) sem azért van, mert a gyártóknak volt felesleges hafnium raktáron. Én csak ennyit mondtam.
derive Ebbol meg egyre bonyolultabb mikroutasitasoknak keszithetnek dedikalt aramkort
Ennek nincs sok értelme, milyen mikroutasításokra gondolsz?
[ Szerkesztve ]
"Sose mondtam egy nap otnel tobbszor azt, hogy a gyártástechnológia nem ér semmit, vagy alaptalan."
javitottam neked
-

Ha valaki esetleg hozzám hasonlóan vizuális típus:![]()

FD-SOI-ról egyébként mi a véleményed? Úgy tudom (még?) csak IBM alkalmazza a Power 8-hoz 22 nm-en (planar). De Samsung + GloFo is "felvette a listára".
[ Szerkesztve ]
Egyre nehezebb a határokat kiterjeszteni. Egyre költségesebb az egész. Ahogy mondta a DARPA vezére is, 5 nm is terítéken van csak nem biztos, hogy megéri lemenni addig. Még a 7 nm is kérdés üzleti szempontból.
Az III-V tranzisztorok is az üzemfeszültség redukálását célozzák és növelhetik az elektronmobilitás, ettől még ugyanúgy gond lesz a kvantummechanika.
Naná, hogy csak most fejlődik az architektúra. Az 2000-es évek elejéig elvoltunk azzal, amit a gyártástechnológia adott. Ma kevesebbet ad. Újabban jóval, tehát elő kell szedni máshonnan azt a teljesítményt. És akkor még az is probléma, hogy ha előteremted, de nem terjed. Lásd AVX.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Tulajdonképpen kapcsolási rajz. De ez bonyolult, mert a tervezés többszintű. Ma már az EDA eszközök elég jók, és nyilván mindenki ezeket használja a VLSI áramkörök bonyolultsága miatt, de van hova javulni. Amire sok cég felfigyelt, hogy a layout eszközök nem igazán jók, mert ha kézzel terveznék a lapkát, akkor 30-40%-kkal kevesebb tranzisztorból is megoldható lenne. Világos, hogy túl bonyolult az egész és túl rövidek a határidők a kézi tervezésre, így maximum utólagos változtatás jöhet szóba az editorokban, de van egy másik megoldás. A density lib fejleszthető annyira, hogy az automatikusan tervezett lapka csak 5-10%-kal tartalmazzon több tranzisztort az elméleti, kézzel kihozható szinthez képest. Ez a változás gyakorlatilag akkora előrelépés, mintha node-ot váltanának.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Kifelejted, hogy azt a GPU-kra írtam. Nem is nagyon erőltetik a 20 nm-t ezen a területen, mert nem jobb. Pedig a 20 nm jó ideje tömeggyártásban van, és jellemzően a GPU-k voltak az elsők a váltásnál, most meg semmi. Nem hülyék, hogy drágábban gyártsanak rosszabbat. A GPU-nál nem is kritikus extrémkicsi helyre beférni.
De vannak más indokok is, bár ezek inkább specifikusak, mintsem valami általános problémára visszavezethetők. Valószínű, hogy az ultramobil hardverek esetében lesz a legtöbb átállás 20 nm-re, mert kisebb lehet a lapka, és ez kisebb tokozást hoz, ami csökkenti a platformdizájn méretét is, vagyis több hely marad az akkunak. Ez például egy reális indok a váltáshoz.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
imo
avxtől a sw in siliconig.
Így 14nm fele aztán végképp marad tranzisztorbüdzsé, amit a leghtékonyabban célszerű elkölteni és "1mb cache helyen sok minden elfér".
Abu:
"Nem is nagyon erőltetik a 20 nm-t ezen a területen, mert nem jobb."
Nem is csak a 20nm és oké, hogy a TSMC... ezt akarja elhitetni mert marketing de azért így az intel diákat nézve khm.
[ Szerkesztve ]
don't look up, don't look up, don't look up, don't look up, don't look up, don't look up, don't look up...
Vannak olyan egyszerű feladatok, amelyek sűrűn használtak a feldolgozás során, vagy sűrűn lesznek használva a későbbiekben. Ezeket természetesen megírhatod programban, de az egyszerűségük miatt nem túl bonyolult rájuk egy áramkört tervezni, és akkor ez a program csak egy utasítás lenne a hardveren belül.
Példa mondjuk a SAD algoritmus, ami önmagában nagyon egyszerű és sok dologra használják szoftveres szinten. Erre az AMD régóta épít minden ALU-ba egy áramkört, ami ugyanarra jó, és csak egy utasítás az egész, vagyis hatványozottan gyorsabb a leprogramozott algoritmusnál.
A koncepció kiterjesztése a dedikált blokk valamilyen feladatra. Például véletlenszám-generátor, vagy titkosítással kapcsolatos ISA-k.
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
A GPU-knál egész pontosan a TSMC 20 nm-ét nem erőltetik, mert ahogy már feljebb is elhangzott, az továbbra is 28nm-es BEOL-t használ, más opció ugye meg nincs (egyelőre). Ha már lenne elérhető, valódi fejlődést kínáló 20 nm-es process, akkor jönnének, vagy talán már itt is lennének a 20 nm-es GPU-k.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
A GloFo 20 nm-ét sem fogják erőltetni. Pedig az valóban előrelépés lesz a mostan 28 nm-es opciókhoz képest. A GPU-knál egy másik gond a pénz, amit nem biztos, hogy ma a gyártástechnológiába érdemes ölni. Iszonyatos hátrányuk van a hardvereknek abból, hogy a grafikus API-k nem úgy működnek, ahogy a modern architektúrák, tehát hatványozottan nagyobb fejlődési potenciál van a grafikus API-k cseréjében, mint a gyártástechnológia leváltásában, ahol ráadásul az új opció nem is feltétlenül jobb.
A middleware oldalán is vannak problémák, mivel ezeket a fejlesztők elkezdték async feldolgozásra írni, és ebből a PC nem profitál. A futószalagon belül ugyanúgy rések keletkeznek, amiket nem lehet kitölteni az API-k elavultsága miatt. Most inkább a szoftver a fő irány, mert innen jöhet gyorsulás.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Ez mint mindig, most is nagyon jól hangzik, csak éppen API-kkal nem lehet egymás ellen versenyezni.
"Currently working in graphics chip with 1.3 million+ gate count have high level of 20lpm design challenges."
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."
Mégis ki akar egymással versenyezni? Ha most maradunk a grafikai vonalnál, akkor nézd meg az AMD és az NV piacpolitikáját. Gyakorlatilag inverze egymásnak. Az AMD azt mondja, hogy igenis legyen kifejleszthető egy AAA játék gyártói segítség nélkül. Az NV azt mondja, hogy ne legyen. Az AMD azt mondja, hogy hozzák PC-re a konzolos effekteket. Az NV azt mondja, hogy ne. Az AMD azt mondja, hogy legyenek az architektúrák dokumentálva a fejlesztők segítése érdekében. Az NV azt mondja, hogy a fejlesztők ne írjanak saját eljárásokat, hanem használjanak valamilyen middleware-t.
Ezeken a nézetkülönbségeken a grafikus API-k leváltása nem változtat.
[ Szerkesztve ]
Senki sem dől be a hivatalos szóvivőnek, de mindenki hisz egy meg nem nevezett forrásnak.
Felesleges ezekkel sokat foglalkozni. Túl van lihegve az egész cirkusz.
"Minden negyedik-ötödik magyar funkcionális analfabéta – derült ki a nemzetközi felmérésekből."

Akik olyan nagyon hisznek a grafikonban: ha kell csinalok egy olyat, amin van 1nm, extrapolalom az adatokat.
Hogy miert kell a bullshit egy ber gyartonal? A befektetoknek es a reszvenyeseknek, nem a megrendelonek.
Az egyebkent eleg figyelmezteto mondas, hogy "20 nm-es node még a 28 nm-es gyártástechnológiához képest is szinte minden tekintetben rosszabb teljesítmény és fogyasztási karakterisztikával rendelkezik az olyan méretes és sokat fogyasztó lapkákra...". Tkp ez a beismerese annak, hogy itt mar kezdik nagyon kozeliteni a jelenelgi technologia hatarait (persze az utobbi 10 evben mar ez lathato, hogy mennyit szenvedtek a szivargasi arammal, azutan magaval a levilagitassal is. Ezekre olyan megoldasok jottek, mint HKMG, esatobbi).
Meg valami: azt *nagyon* meg kell kulonboztetni, hogyha egy technologia memoria gyartasra (pl SDRAM vagy NAND flash) vagy komplex megoldasok gyartasara (CPU, GPU, nagy ASIC) alkalmas. Egy 14nm NAND/SDRAM technologia nagyon nem egyenlo egy Intel 14nm technologiaval, aki valszeg komplex chip-eket is tud azon gyartani, nem "csak" memoriat. Persze a Samu ARM chipjei egyre komplexebbek lesznek, szoval oneki is erre majd oda kell figyelni.
Acer Predator Helios 500 Ryzen, Samsung 960 Pro NVMe + GeChic 15.6" kulso monitor a mobil irodahoz




