


Nem egy high-end script, annyit tud, hogy ahol lefuttatjuk a scriptet (mappában, vagy a merevlemez gyökerében) ott összeszedi a duplikált fájlokat, majd ezeket név szerint kigyűjti egy txt fájlba. Hogy mire jó? Talán arra, hogy fényt deríthessünk rá, hogy mennyi duplikált objektumunk van (ahol objektum lehet bármi, szöveges állomány, kép, zene, film stb..)
Az, hogy két fájl ugyanaz-e, névegyezőség, és méretegyezőség szerint dől el, nem az igazi, de már így is sokáig fut a script, így ennél erősebb vizsgálatot nem akartam betenni.
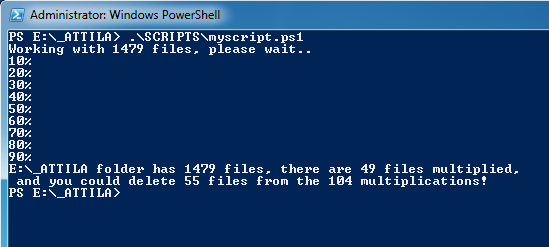
Nálam a 230 gigás ADAT merevlemez gyökeréből indítva, ~17000 fájlt megvizsgálva 45 percig futott a script, de fény derült arra is, hogy ha venném a fáradtságot akkor több mint 2000 fájlt (zenét, képet etc) törölhetnék ki, mert ezeknek létezik másik példánya is.
Az eredmény egy multiples.txt állományban található abban a mappában, ahol futtattuk a scriptet.
-----------------------------------------------------------------------------------------------------------
UPDATE: a cikk alján van egy gyorsabb megoldás!
A script letölthető innen. Nyissunk meg egy PowerShell ablakot (C:\WINDOWS\system32\WindowsPowerShell\v1.0\powershell.exe) rendszergazdaként (jobb klikk, run as administrator), majd navigáljunk el abba a mappába, ahol a lekérdezést futtatni akarjuk, majd hívjuk meg a scriptet.
Példa:
Ha a myscript.ps1 scriptet az D:\Downloads mappába mentettük, akkor a következő paranccsal tudjuk futtatni:
PS D:\> .\Downloads\myscript.ps1
Ekkor a D meghajtó egész tartalmát monitorozni fogja és nem a D:\Downloads mappáét!
-----------------------------------------------------------------------------------------------------------
$loc = get-location
$files = get-childitem -Path $loc -Recurse | where {$_.Length -gt 0}
$length = $files.length
$multiples = @()
$rows = 0
$groups = 0
write-host "Working with $length files, please wait.."
[int]$10n = $length*0.1
[int]$20n = $length*0.2
[int]$30n = $length*0.3
[int]$40n = $length*0.4
[int]$50n = $length*0.5
[int]$60n = $length*0.6
[int]$70n = $length*0.7
[int]$80n = $length*0.8
[int]$90n = $length*0.9
[int]$100n = $length
for($i=0;$i -lt $length;++$i){
$ismultiple = 0
$tempi = $files[$i]
switch($i)
{
$10n { write-host "10%" }
$20n { write-host "20%" }
$30n { write-host "30%" }
$40n { write-host "40%" }
$50n { write-host "50%" }
$60n { write-host "60%" }
$70n { write-host "70%" }
$80n { write-host "80%" }
$90n { write-host "90%" }
$100n { write-host "100%" }
}
if($multiples -contains $tempi.FullName){ } else {
for($j=$i+1;$j -lt $length;++$j){
$tempj = $files[$j]
if($tempj.Name -eq $tempi.Name -and $tempj.Length -eq $tempi.Length){
$multiples += $tempj.FullName
$rows++
$ismultiple = 1
}
}
if($ismultiple){
$multiples += $tempi.FullName
$rows++
$groups++
$multiples += "`n"
}
}
}
write-host "$loc folder has $length files, there are $groups files multiplied,`n and you could delete $($rows-$groups) files from the $rows multiplications!"
$multiples += "$loc folder has $length files, there are $groups files multiplied,`n and you could delete $($rows-$groups) files from the $rows multiplications!"
$multiples > multiples.txt
-----------------------------------------------------------------------------------------------------------
UPDATE Ez a lenti kód már 45 perc helyett 15 másodperc alatt csinálja meg ugyanazt.
$loc = get-location
$files = get-childitem -Path $loc -Recurse | where {$_.Length -gt 0}
$length = $files.length
$fileMap = @{}
$duplicates = @()
for($i=0;$i -lt $length;++$i){
$file = $files[$i]
$key = $file.Name +" "+ $file.Length +"byte"
if($fileMap.ContainsKey($key)){
$fileMap[$key] += $file.FullName
} else {
$fileMap[$key] = @($file.FullName)
}
}
foreach ($item in $fileMap.GetEnumerator()) {
if($item.Value.Length -gt 1){
$duplicates += $item.Name+":"
$duplicates += $item.Value
$duplicates += "`n"
}
}
$duplicates > fileMap.txt
Címkék: powershell, duplikátumok, duplikált fájlok, egyezőségek, fájlba írás




![;]](http://cdn.rios.hu/dl/s/v1.gif) Amúgy igen, biztos egyszerűbb úgy, de tudod azért szerkesztettem ilyenre a bejegyzést, illetve raktam a végére Címke felhőt, hogy kereshető legyen, mert valakinek még szüksége lehetne valamire a kódból
Amúgy igen, biztos egyszerűbb úgy, de tudod azért szerkesztettem ilyenre a bejegyzést, illetve raktam a végére Címke felhőt, hogy kereshető legyen, mert valakinek még szüksége lehetne valamire a kódból










